
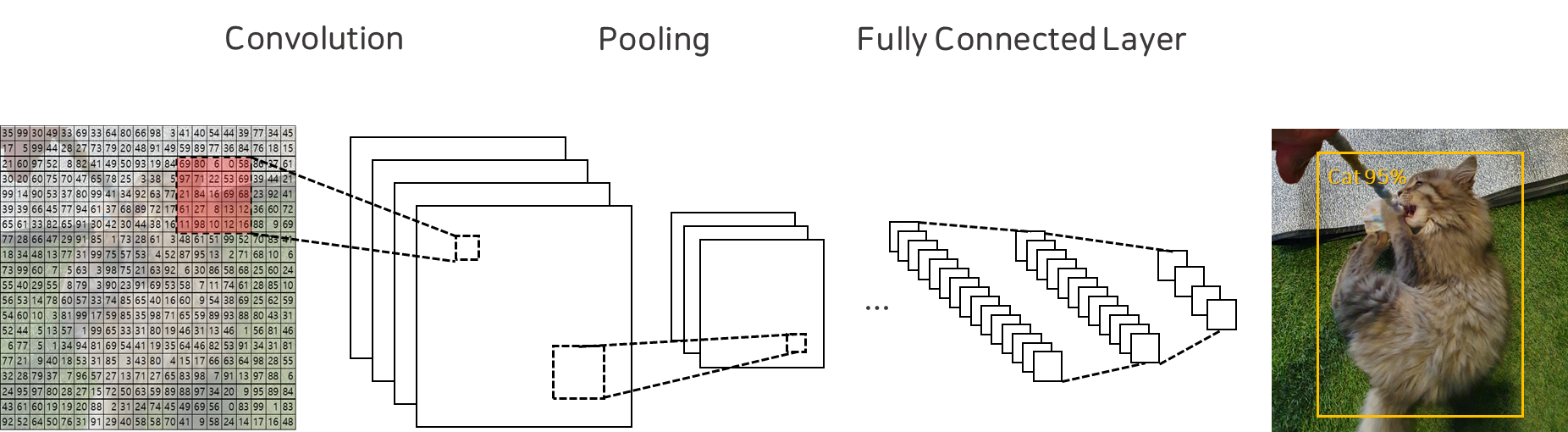
오늘은 MNIST데이터로 Convolutional Neural Network(이하 CNN)을 구현하고 돌려보는 시간을 갖도록 하겠습니다!
먼저, CNN은 크게 아래와 같은 구성요소로 이루어져있습니다.
- 합성곱 연산(CNN) : 이미지의 특성 추출
- 맥스풀링(Max Pooling) : 이미지의 특성 축약
- 완전연결 신경망(Fully Connected Network) : 추출 및 축약된 특징을 입력에 사용하여 downstream task 수행
Import Library
가볍게 어떤 모델들을 import할지 살펴볼까요?
import torch
import torch.nn as nn # 신경망들이 포함됨
import torch.optim as optim # 최적화 알고리즘들이 포함됨
import torch.nn.init as init # 텐서에 초기값을 줌
import torchvision.datasets as datasets # 이미지 데이터셋 집합체
import torchvision.transforms as transforms # 이미지 변환 툴
from torch.utils.data import DataLoader # 학습 및 배치로 모델에 넣어주기 위한 툴
import numpy as np
import matplotlib.pyplot as pltSet Hyperparameter
학습에 필요한 Hyperparameter를 정의해볼까요?
-
batch_size: batch size는 한 번의 batch마다 주는 데이터 샘플의 size로, 나눠진 데이터 셋을 뜻하며, iteration는 한번의 epoch를 batch_size로 나누어서 실행하는 횟수라고 생각하면 됩니다. -
learning_rate: learning_rate은 어느 정도의 크기로 기울기가 줄어드는 지점으로 이동하겠는가를 나타내는 지표로, 학습이 얼마나 빨리 진행되는가를 정해주는 지표라고 생각하면 됩니다. -
num_epoch: 한 번의 epoch는 인공 신경망에서 전체 데이터 셋에 대해 forward pass/backward pass 과정을 거친 것을 말합니다. 즉, 전체 데이터 셋에 대해 한 번 학습을 완료한 상태라고도 볼 수 있는데요. 이렇게 전체 데이터셋을 몇번 볼 것인가를 num_epoch를 통해 정의해주게 됩니다.
batch_size = 100
learning_rate = 0.0002
num_epoch = 10Load MNIST Data
학습용 데이터셋인 MNIST를 가져와보겠습니다. 각각 함수는 다음과 같이 정의될 수 있습니다.
root="원하는 경로"
- root는 우리가 데이터를 어디에다가 저장하고, 경로로 사용할지를 정의해줍니다.train=True(또는 False)
- train은 우리가 지금 정의하는 데이터가 학습용인지 테스트용인지 정의해줍니다.transform=transforms.ToTensor()
- 데이터에 어떠한 변형을 줄 것인가를 정의해줍니다.- 해당
transforms.ToTensor()의 경우, 모델에 넣어주기 위해 텐서 변환을 해줌을 의미합니다.
- 해당
target_transform=None
- 라벨(클래스)에 어떠한 변형을 줄 것인가를 정의해줍니다.download=True
- 앞에서 지정해준 경로에 해당 데이터가 없을 시 다운로드하도록 정의해줍니다.
mnist_train = datasets.MNIST(root="../Data/", train=True, transform=transforms.ToTensor(), target_transform=None, download=True)
mnist_test = datasets.MNIST(root="../Data/", train=False, transform=transforms.ToTensor(), target_transform=None, download=True)Define Loaders
DataLoader는 앞에서도 말씀드렸듯이 DataLoader는 학습 및 배치로 모델에 넣어주기 위한 툴입니다. 앞에서 정의한 데이터셋을 DataLoader에 넣어주게 되면 우리가 정의해준 조건에 맞게 모델을 Train, Inference할 때 데이터를 Load해주게 됩니다.
batch_size=batch_size
- 정의된 데이터를 batch_size개수만큼 묶어서 모델에 넣어주겠다는 의미입니다.shuffle=True
- 데이터를 섞어줄 것인가 지정해주는 파라미터입니다.num_workers=2
- 데이터를 묶을때 사용할 프로세서의 개수를 의미합니다.drop_last=True
- 묶고 남은 데이터를 버릴 것인가를 지정해주는 파라미터입니다.
train_loader = DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=2, drop_last=True)
test_loader = DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=2, drop_last=True)Define CNN(Base) Model
먼저 class를 통해 CNN class를 정의해보겠습니다. torch의 nn.Module을 사용하여 nn.Module class를 상속받는 CNN을 다음과 같이 정의할 수 있습니다.
class CNN(nn.Module):
def __init__(self):
# super함수는 CNN class의 부모 class인 nn.Module을 초기화
super(CNN, self).__init__()
# batch_size = 100
self.layer = nn.Sequential(
# [100,1,28,28] -> [100,16,24,24]
nn.Conv2d(in_channels=1,out_channels=16,kernel_size=5),
nn.ReLU(),
# [100,16,24,24] -> [100,32,20,20]
nn.Conv2d(in_channels=16,out_channels=32,kernel_size=5),
nn.ReLU(),
# [100,32,20,20] -> [100,32,10,10]
nn.MaxPool2d(kernel_size=2,stride=2),
# [100,32,10,10] -> [100,64,6,6]
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5),
nn.ReLU(),
# [100,64,6,6] -> [100,64,3,3]
nn.MaxPool2d(kernel_size=2,stride=2)
)
self.fc_layer = nn.Sequential(
# [100,64*3*3] -> [100,100]
nn.Linear(64*3*3,100),
nn.ReLU(),
# [100,100] -> [100,10]
nn.Linear(100,10)
)
def forward(self,x):
# self.layer에 정의한 연산 수행
out = self.layer(x)
# view 함수를 이용해 텐서의 형태를 [100,나머지]로 변환
out = out.view(batch_size,-1)
# self.fc_layer 정의한 연산 수행
out = self.fc_layer(out)
return outdevice를 아래와 같이 선언하여 gpu가 사용 가능한 경우에는 device를 gpu로 설정하고, 불가능하면 cpu로 설정해줄 수 있습니다.
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")CNN().to(device)선언을 통해 정의한 모델 객체를 선언하고, 이를 지정한 장치(device)로 올려줍니다.
model = CNN().to(device)모델이 학습을 수행하려면, 손실함수와 최적화함수가 필요한데 이는 아래와 같이 정의할 수 있습니다. (손실함수는 Cross Entropy, 최적화함수는 Adam Optimizer을 사용하였습니다)
또한, model.parameters()와 lr=learning_rate을 torch.optim.Adam()로 감싸줌으로써 모델의 파라미터들을 사전에 정의한 learning_rate로 업데이트 해주고자 합니다.
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)Train Model
train_loader에서 image와 label의 쌍을 batch_size만큼 받아서 모델에 전달하여 손실을 계산하고, 손실에 대한 경사하강법을 진행하여 모델을 업데이트합니다. 이때 1000번째 iteration마다 loss를 출력하고, 이를 loss_arr에 추가하도록 코드를 작성하였습니다.
enumerate(train_loader)함수를 통해 각각 batch의index(j)와[image,label]를 받아서 x, y로 정의해줍니다optimizer.zero_grad()를 통해 지난 loop에서 계산했던 기울기를 0으로 초기화해줍니다.loss.backward()호출을 통해 각각의 model(weight) parameter에 대한 기울기를 계산하고,optimizer.step()함수를 호출하여 인수로 들어갔던model.parameters()에서 리턴되는 변수들의 기울기에learning_rate를 곱하여 빼주면서 이를 업데이트하게 됩니다.
loss_arr =[]
for i in range(num_epoch):
for j,[image,label] in enumerate(train_loader):
x = image.to(device)
y= label.to(device)
optimizer.zero_grad()
output = model.forward(x)
loss = loss_func(output,y)
loss.backward()
optimizer.step()
if j % 1000 == 0:
print(loss)
loss_arr.append(loss.cpu().detach().numpy())Test Model
마지막 부분은 학습된 모델을 바탕으로 테스트 데이터에 대하여 검증하는 부분입니다.
-
model.eval():model.eval은 해당 모델의 모든 레이어가 eval mode에 들어가게 해줍니다. 이 말은 곧, 학습할 때만 사용하는 개념인 Dropout이나 Batchnorm 등을 비활성화 시킨다는 것을 의미한다. -
torch.no_grad(): with torch.no_grad()는 pytorch의 autograd engine을 비활성화 시킵니다. 즉, 더이상 gradient를 트래킹하지 않음을 의미하고, 이에 따라 필요한 메모리가 줄어들고 계산속도가 증가하게 됩니다.
correct = 0
total = 0
# evaluate model
model.eval()
with torch.no_grad():
for image,label in test_loader:
x = image.to(device)
y= label.to(device)
output = model.forward(x)
# torch.max함수는 (최댓값,index)를 반환
_,output_index = torch.max(output,1)
# 전체 개수 += 라벨의 개수
total += label.size(0)
# 도출한 모델의 index와 라벨이 일치하면 correct에 개수 추가
correct += (output_index == y).sum().float()
# 정확도 도출
print("Accuracy of Test Data: {}%".format(100*correct/total))긴 글 읽어주셔서 감사합니다 ^~^

잘 보고 갑니다! 다시 한번 복습하는 계기가 되었어요~ ㅎㅎ