
본 포스트는 고려대학교 강필성 교수님의 강의를 수강 후 정리를 한 것입니다. 작성 및 설명의 편의를 위해 아래 포스트는 반말로 작성한 점 양해부탁드립니다.
거리 기반 이상치탐지
K-Nearest Neighbor-based Anomaly Detection
-
각 데이터에 대한 Anomaly Score를 K개의 근접 이웃까지의 거리를 이용하여 계산한다. 이웃까지의 거리가 다른 데이터에 비해 크다면, 해당 데이터는 이상치일 확률이 높다.
-
기존에는 거리 계산 방법으로는 다음 3가지 방법들을 이용해왔지만, 해당 거리 계산 방법으론 찾아내지 못하는 케이스들이 존재했다.
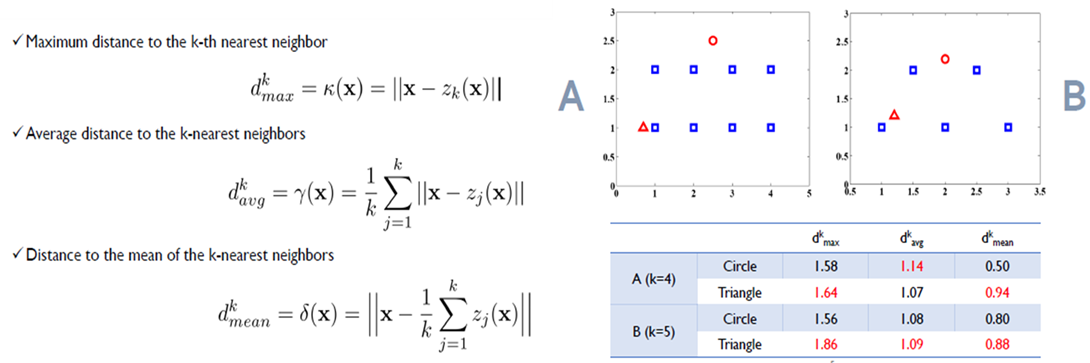
-
이를 극복하기 위해 새로이 convex-hull distance를 도입해하고, 이를 활용하여 hybrid distance를 정의해줌으로서 탐지 성능을 향상시켰다.

군집 기반 이상치탐지
K-Means Clustering-based Anomaly Detection
- 군집화를 수행하고 군집에 할당하지 않는 객체들은 이상치로 취급한다.
- Anomaly Score by K-Means Clustering-based Anomaly Detection(KMC)
① 절대적 거리 : A anomaly score (a1) = B anomaly score (b1)
② 상대적 거리 : A anomaly score (a1/a2) < B anomaly score (b1/b2)
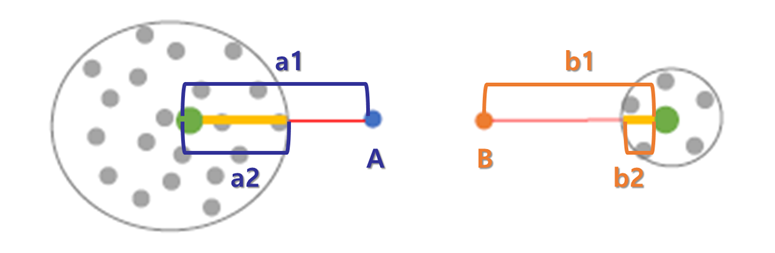
PCA-based Novelty Detection Method
- 기본 PCA의 목적은 사영 후 분산을 최대화하는 것이다. PCA기반 이상치 탐지는 기존에 사영했던 것을 다시 복원을 수행하여 기존의 값과 차이가 많이 나면 이상치일 확률이 높은 것으로 간주한다.
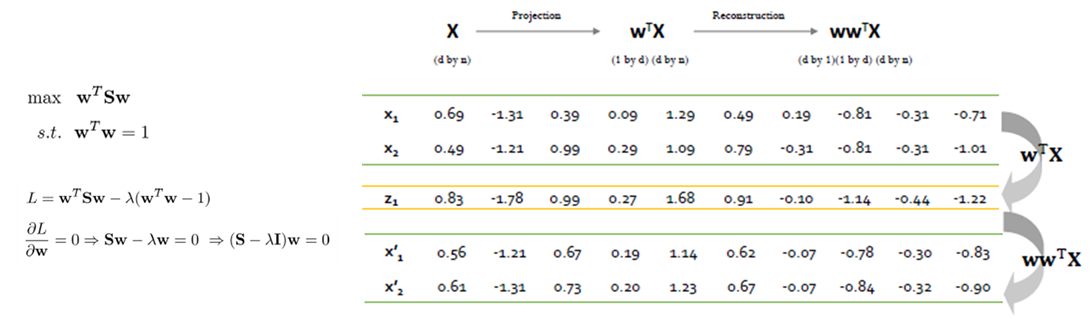
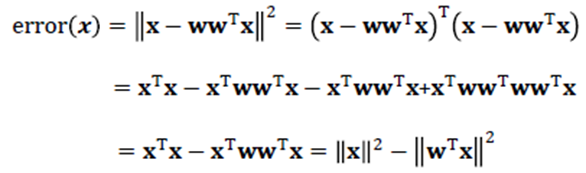
Auto-Encoder
-
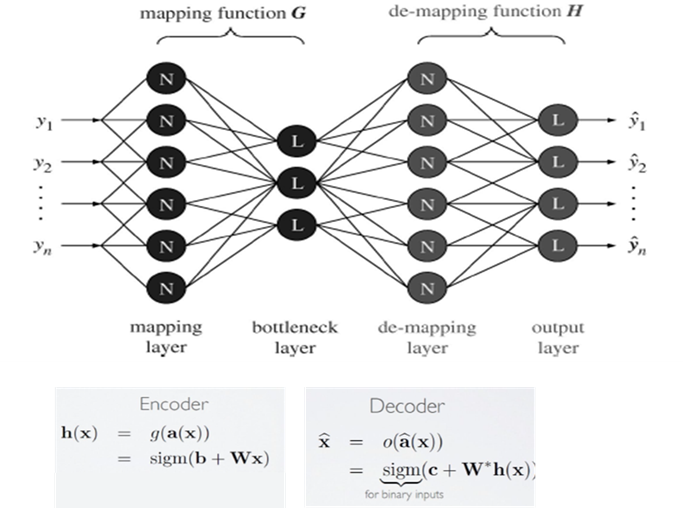
Auto Encoder는 모델의 출력 값과 입력 값이 비슷해지도록 학습이 수행되며, 아래와 같이 4개의 Layer로 이루어져 있다.
-
Mapping Layer(Encoder)
Encoder에서는 Input 데이터를 Bottleneck Layer 로 보내 Input 정보를 저차원으로 압축하는 역할을 수행한다.
-
Bottleneck Layer
-
Demapping Layer(Decoder)
Decoder에서는 압축된 형태의 Input 정보를 원래의 Input 데이터로 복원한다.
-
Output Layer
-
Auto-Encoder의 목표는 input 데이터와 동일한 데이터를 예측하는 것이므로 Output Layer를 통해 나오는 예측 값과 실제 값의 차이를 Loss Function으로 정의하고 학습을 수행하며, 해당 Loss Function을 Reconstruction Error라고 한다.
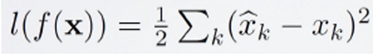
-
훈련 데이터(정상 데이터)와 상이한 특징을 지닌 비정상 데이터인 Abnormal Data를 입력하면 Reconstruction Error가 커지게 되어, 이러한 Reconstruction Error를 Anomaly Score 로 사용할 수 있다.
Support Vector-based Novelty Detection
- 정규 및 비정상 관측치를 구분하는 함수를 찾아 직접 정규 영역의 경계 정의해주는 방법론
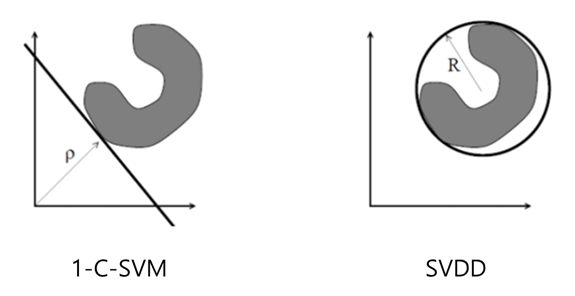
1-C-SVM (One-class SVM)
- 데이터를 커널에 해당하는 feature space 상에 매핑하여 정상데이터를 원점으로부터 최대한 멀어지도록 구분하는 것이 주목적이다.
-
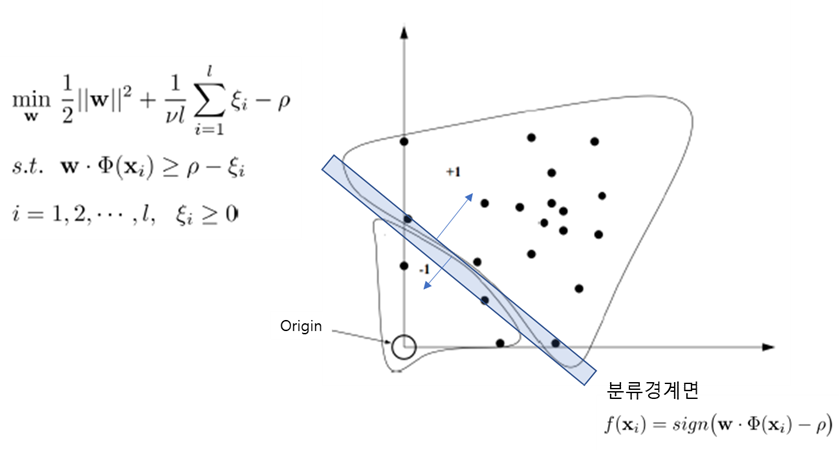
Formulation (Primal, Dual을 통해 증명될 수 있다)


-
Support Vector of 1-SVM

vl의 의미(역할)
1. 우리가 가질 수 있는 support vector의 최소 개수 vl개
2. margin을 벗어나서 있을 수 있는 최대의 support vector 개수 vl개
v의 의미(역할)
1. v는 support vector의 하한 비율 (lower bound for the fraction of support vector)
2. v는 에러의 상한 비율 (upper bound for the fraction of errors)
3. v가 클수록 복잡한 decision boundary가 생성된다.
SVDD (Support Vector Data Description)
-
데이터를 커널에 해당하는 feature space 상에 매핑하여 정상데이터를 감싸 안을 수 있는 초구(hypershere)를 구하는 것이 주목적이다.
-
formulation

-
Support Vector of SVDD

-
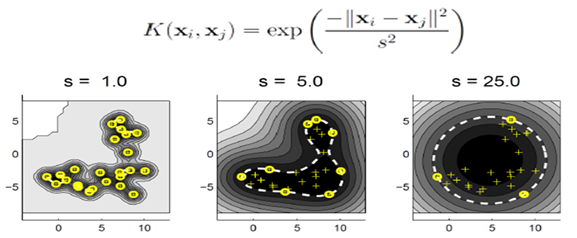
s의 역할 (RBF커널 사용 시) : 작을수록 복잡도가 커지고, 클수록 구에 가까워진다.
Isolation Forest
- 특정 객체를 다른 데이터와 분리(고립)하는 과정을 통해 정상 데이터와 이상 데이터를 판별하는 방법이다.
Motivation
① 이상치 데이터는 고립시키기가 상대적으로 쉬울 것이다. (= 적은 split이 필요할 것이다)
② 정상 데이터는 고립시키기가 상대적으로 어려울 것이다. (= 많은 split이 필요할 것이다)
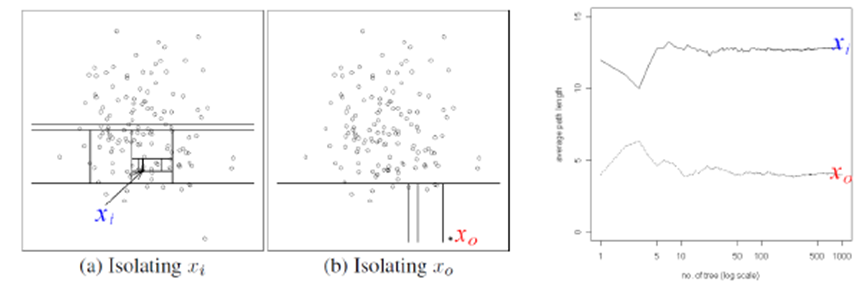
- 데이터를 분리 시, 임의의 변수, 임의의 값을 사용하여 분리를 수행한다. Isolation Tree에서 특정 개체의 고립까지 필요한 split의 개수들의 평균(average path to the terminal node)를 Isolation Forest의 novelty score로 이용한다.
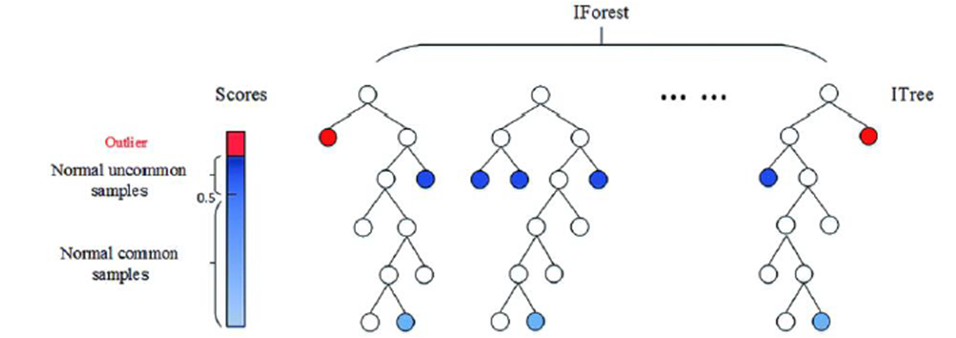
용어정리
(1) Isolation Tree(iTree)
- 전체 dataset에서 X dataset을 sampling하고, 이렇게 선택된 X를 지속적으로 random하게 선택된 variable과 value로 분할한다.
- 이때, |X|=1이거나, 각 terminal node에 있는 Instance의 값이 모두 같거나, hyper parameter로 정해 둔 height limit에 걸리면 학습을 멈춘다.
(2) Path Length
- Isolation 될 때까지 사용된 split의 개수를 의미하며, 오일러 상수를 통해 정규화가 될 수 있다.
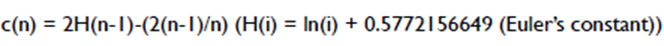
(3) Novelty Score
- 이상치 점수는 아래 식으로 아래와 같이 정의되며, 특정 객체의 평균 path length가 큰 경우(정상 데이터일 확률이 클 경우), s(x,n)는 0으로 근사하고, 반대로 path length가 작은 경우(이상치 데이터일 확률이 클 경우)는 1에 근사하게 된다.
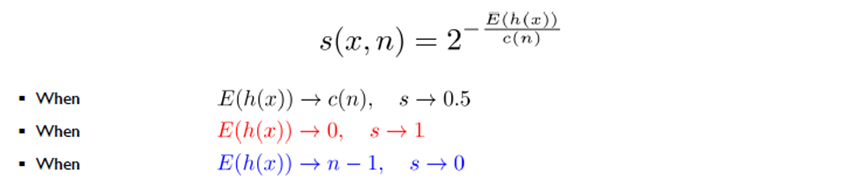
(참고) Extended Isolation Forest
-
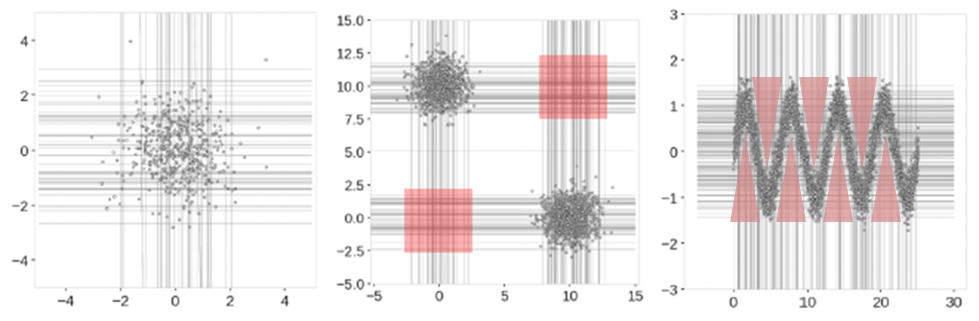
Isolation Forest는 일반적으로 수평선 또는 수직선만을 이용하여 데이터 포인트를 고립시킨다. 하지만, 이와 같은 방법으로는 몇 가지 유형의 데이터에 대해서는 이상치 구간을 정상영역이라고 보는 경우가 존재한다.
-
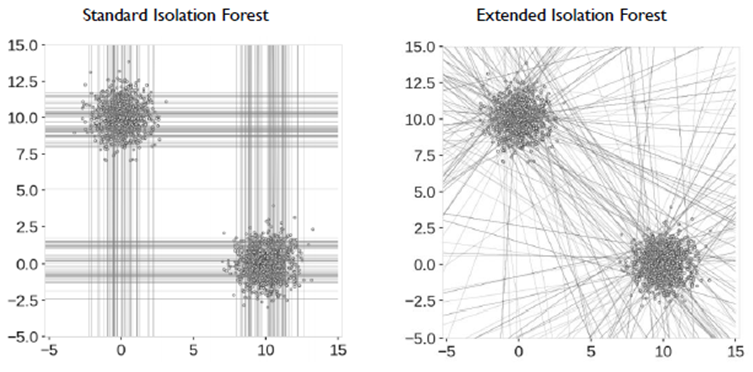
이러한 단점을 극복하기 위해 축에 수직이 아닌, slope를 통한 random cut 방식을 제안한 것이 Extended Isolation Forest이다.
긴 글 읽어주셔서 감사합니다 ^~^
