
순전파와 역전파
신경망(Neural Network)은 어떤 입력 데이터에 대해 실행되는 중첩된 함수들의 집합체입니다. 신경망을 아래 2단계를 거쳐 학습됩니다 :
- 순전파(Forward Propagation)
- 역전파(Backward Propagation)
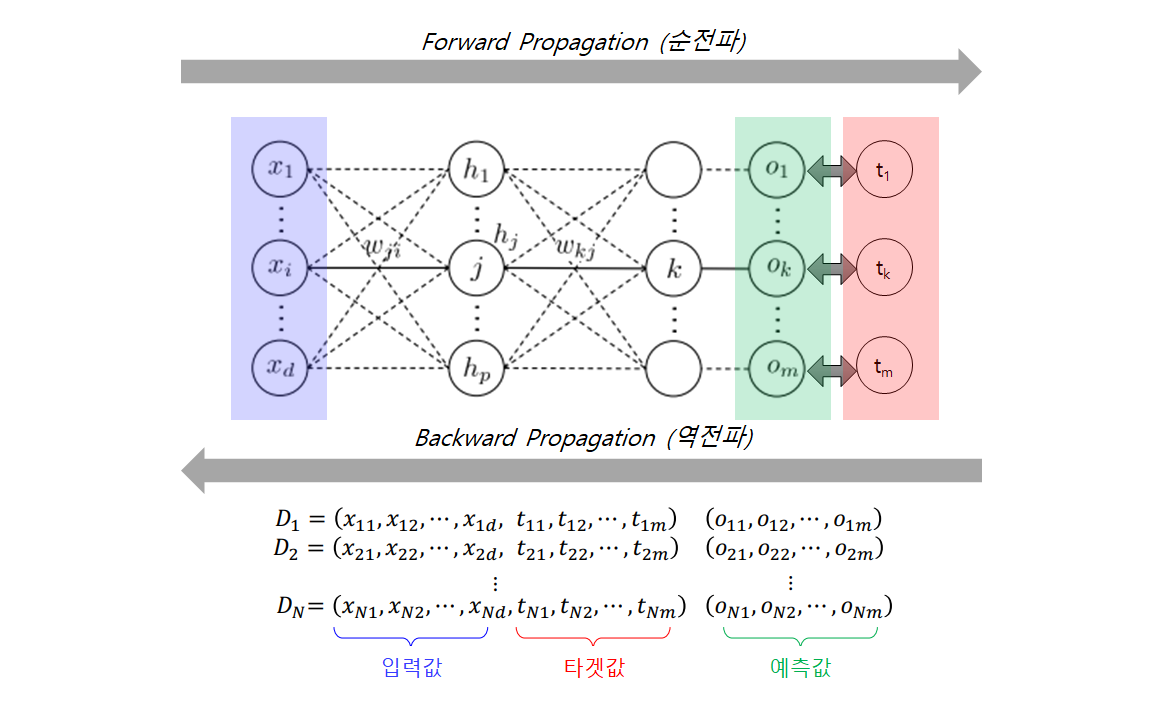
Forward Propagation (순전파)
Forward Propagation(순전파) 단계에서, 신경망은 정답을 맞추기 위해 최선의 추측(best guess)을 합니다. 이렇게 추측을 하기 위해서 입력 데이터를 각 함수들에서 실행합니다.
Back Propagation (역전파)
Back Propagation (역전파) 단계에서, 신경망은 추측한 값에서 발생한 error에 비례하여 파라미터들을 적절히 업데이트합니다. 출력(output)로부터 역방향으로 이동하면서 오류에 대한 함수들의 매개변수들의 미분값(gradient)을 수집하고, 경사하강법(gradient descent)을 사용하여 매개변수들을 최적화 합니다.
뉴럴네트워크 학습 알고리즘
- 모든 가중치 w를 임의로 생성
[Forward Propagation] - 입력변수 값과 입력층과 은닉층 사이의 w값을 이용하여 은닉노드의 값을 계산
(선형결합 후 activation한 값) - 은닉노드의 값과 은닉층과 출력층 사이의 w값을 이용하여 출력노드의 값을 계산
(선형결합 후 activation한 값)
[Back Propagation] - 계산된 출력노드의 값과 실제 출력변수의 값의 차이를 줄일 수 있도록 은닉층과 출력층 사이의 w값을 업데이트
- 계산된 출력노드의 값과 실제 출력변수의 값의 차이를 줄일 수 있도록 입력층과 은닉층 사이의 w값을 업데이트
- 에러가 충분히 줄어들 때까지 2번 ~ 5번을 반복
Autograd 개념
pyTorch를 이용해 코드를 작성할때 이러한 역전파를 통해 파라미터를 업데이트하는 방법은 바로 Autograd 입니다. 차근차근 코드를 통해 알아보도록 합시다. Autograd에 대해 살펴보기 위해 간단한 MLP(Mulyi-Layer Perceptron)을 예시로 살펴볼까요?
import torch
먼저 pyTorch를 사용하기 위해서 다음과 같이 pyTorch를 import해줍니다. 이때, torch.cuda의 is_available()함수를 통해 현재 파이썬이 실행되고 있는 환경이 GPU를 이용해서 계산을 할수 있는가를 확인할 수 있습니다.
💻 코드
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device💻 결과
# GPU 사용이 가능할 때
device(type='cuda')
# GPU 사용이 불가능할 때
device(type='cuda')BATCH_SIZE
BATCH_SIZE는 딥러닝 모델이 파라미터를 업데이트할 때 계산되는 데이터 묶음의 개수입니다. 앞에서 Neural Network이 Forward Propagation(순전파)와 Backward Propagation(역전파)를 수행하면서 파라미터를 업데이트를 한다고 소개 드렸는데, 이러한 업데이트를 수행하는 데 사용되는 데이터 단위(갯수)가 되는 것이 바로 BATCH_SIZE입니다. 아래 예시에서 BATCH_SIZE로 32를 지정해줬는데, 이는 코드 작성자 마음대로(?) 정해주는 하이퍼파라미터입니다.
💻 코드
# 하이퍼파라미터 지정
BATCH_SIZE = 32INPUT_SIZE, HIDDEN_SIZE, OUTPUT_SIZE, LEARNING_RATE
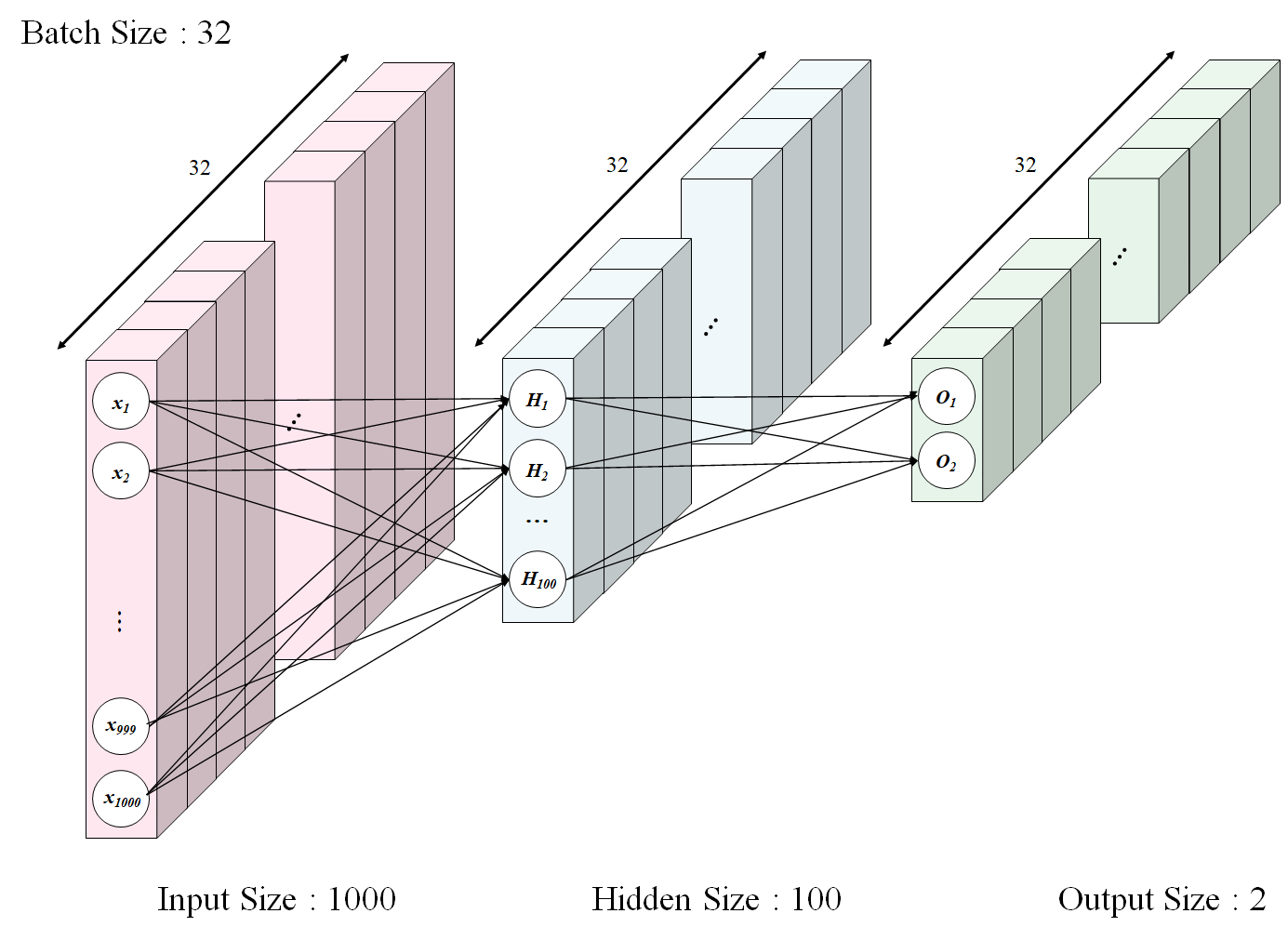
INPUT_SIZE는 딥러닝 모델의 입력값의 크기이며, 입력층의 노드 수를 의미합니다.HIDDEN_SIZE는 입력값에 다수의 파라미터를 사용하여 계산되는 값의 개수로, 은닉 층의 노드 수를 의미합니다.OUTPUT_SIZE는 은닉값에 다수의 파라미터를 사용하여 계산되는 결과값의 개수로, 출력 층의 노드 수를 의미합니다.LEARNING_RATE은 Gradient를 업데이트할 때 곱해주는 0과 1사이에 존재하는 값입니다. 좀 더 느리지만 섬세하고 촘촘히 업데이트를 원하면 작은 rate을, 좀 더 빠르게 업데이트를 원하면 큰 rate를 줄 수 있습니다.
💻 코드
# 하이퍼파라미터 지정
INPUT_SIZE = 1000
HIDDEN_SIZE = 100
OUTPUT_SIZE = 2
LEARNING_RATE = 1e-6- 하이퍼파라미터를 선언했으면 실험을 해봐야겠죠? 일단 실험환경을 위해 다음과 같이 임의의 값으로 input(X), output(Y), Weights(W1, W2)를 정의해줍니다.
- 이때,
requires_grad=True는 autograd 에 모든 연산(operation)들을 추적해야 한다고 알려줍니다.
💻 코드
# 임의의 X, Y, Weight 정의
# x : input 값 >> (32, 1000)
x = torch.randn(BATCH_SIZE,
INPUT_SIZE,
device = device,
dtype = torch.float,
requires_grad = False)
# y : output 값 >> (32, 2)
y = torch.randn(BATCH_SIZE,
OUTPUT_SIZE,
device = device,
dtype = torch.float,
requires_grad = False)
# w1 : input -> hidden >> (1000, 100)
w1 = torch.randn(INPUT_SIZE,
HIDDEN_SIZE,
device = device,
dtype = torch.float,
requires_grad = True)
# w2 : hidden -> output >> (100, 2)
w2 = torch.randn(HIDDEN_SIZE,
OUTPUT_SIZE,
device = device,
dtype = torch.float,
requires_grad = True) Train Model (iteration = 500)
- 본 포스트은 Autograd를 확인해보는 포스트이므로, 단순하게 for문을 이용하여 500번 iteration을 수행하도록 코드를 작성하였습니다.
torch.mm(): mm은 matrix multiplication의 줄임말으로, 행렬의 곱셈을 의미합니다.torch.nn.ReLU(): ReLU함수, ReLU는 max(0, x)를 의미하는 함수인데, 0보다 작아지게 되면 0이 되고, 그 이상은 값을 유지한다는 특징을 가지고 있습니다.loss.backward(): loss에 대하여.backward()를 호출한 것으로, autograd는 각 파라미터 값에 대해 미분값(gradient)을 계산하고 이를 각 텐서의.grad속성(attribute)에 저장합니다.with torch.no_grad(): 미분값(gradient) 계산을 사용하지 않도록 설정하는 컨텍스트-관리자(Context-manager)입니다. 해당 모드는 입력에 requires_grad=True가 있어도, 이를 requires_grad=False로 바꿔줍니다.
💻 코드
from torch import nn
# 500 iteration
for t in range(1, 501):
# 은닉값
hidden = nn.ReLU(x.mm(w1))
# 예측값
y_pred = hidden.mm(w2)
# 오차제곱합 계산
loss = (y_pred - y).pow(2).sum()
# iteration 100 마다 기록하도록
if t % 100 == 0:
print(t, "th Iteration: ", sep = "")
print(">>>> Loss: ", loss.item())
# Loss의 Gradient 계산
loss.backward()
# 해당 시점의 Gradient값을 고정
with torch.no_grad():
# Weight 업데이트
w1 -= LEARNING_RATE * w1.grad
w2 -= LEARNING_RATE * w2.grad
# Weight Gradient 초기화(0)
w1.grad.zero_()
w2.grad.zero_()- 500번의 반복문을 실행하면서 점점 Loss가 줄어드는 것을 확인할 수 있습니다.
💻 결과
100th Iteration:
>>>> Loss: 926.969116210
200th Iteration:
>>>> Loss: 6.41975164413
300th Iteration:
>>>> Loss: 0.06706248223
400th Iteration:
>>>> Loss: 0.00112969405
500th Iteration:
>>>> Loss: 0.00011484944심화 개념
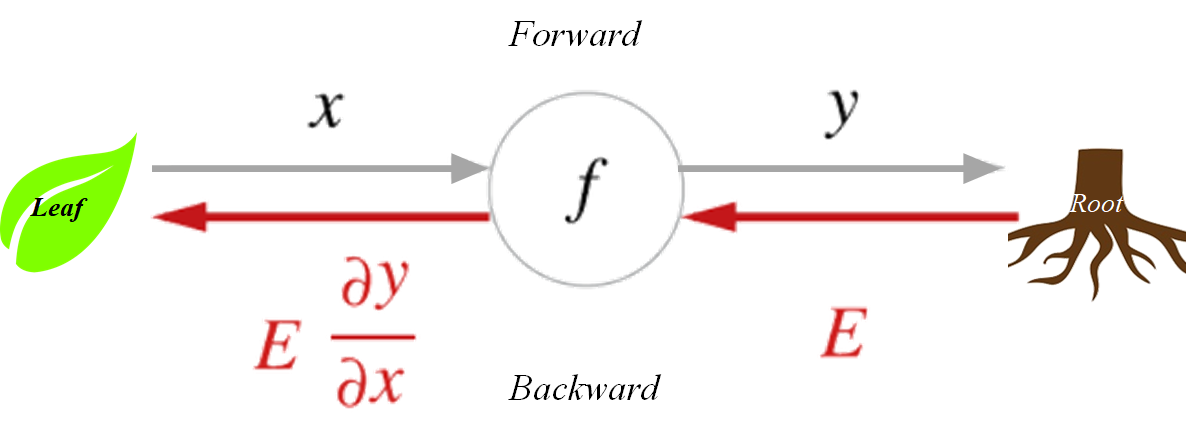
Computational Graph (연산 그래프)
autograd는 데이터(텐서)의 및 실행된 모든 연산들의 기록을 객체로 구성된 방향성 비순환 그래프(DAG; Directed Acyclic Graph)에 저장(keep)합니다.- 방향성 비순환 그래프(DAG)의 NN의 전반적인 계산과정을 그래프로 나타낸 것으로, 잎(leave)은 입력 텐서(데이터)이고, 뿌리(root)는 결과 텐서(데이터)입니다.
- 이러한 방향성 비순환 그래프(DAG)를 뿌리에서부터 잎까지 추적하면 연쇄 법칙(chain rule)에 따라 기울기(gradient)를 자동으로 계산할 수 있는 구조입니다.
순전파 단계 에서, autograd는 아래 두 가지 작업을 동시에 수행합니다.
- 요청된 연산을 수행하여 결과 텐서를 계산하고,
- DAG에 연산의 gradient function을 유지(maintain)합니다.
역전파 단계 는 DAG 뿌리(root)에서 .backward() 가 호출될 때 시작됩니다. autograd 는 아래 세 가지 작업을 순차적으로 수행합니다.
- 각
.grad_fn으로부터 gradient를 계산 - 각 텐서의
.grad속성에 계산 결과를 저장(accumulate) - 연쇄 법칙을 사용하여, 모든 잎(leaf) 텐서들까지 전파(propagate)
참고 개념
- 연산 그래프와 autograd는 복잡한 연산자를 정의하고 도함수(derivative)를 자동으로 계산하는 매우 강력한 패러다임(paradigm)입니다. 하지만 대규모 신경망에서는 autograd 그 자체만으로는 너무 저수준(low-level)일 수 있습니다.
torch.nn, torch.optim
-
PyTorch는 신경망(neural network)를 생성하고 학습시키는 것을 도와주기 위해서
torch.nn,torch.optim이 제공됩니다.-
torch.nn : 다양한 뉴럴 네트워크를 생성할 수 있는 패키지입니다.
torch.nn.Module: 함수처럼 동작하지만, 또한 상태(state)를 포함할 수 있는 호출 가능한 오브젝트를 생성합니다. 이는 포함된 Parameter들이 어떤 것인지 알고, 모든 기울기를 0으로 설정하고 가중치 업데이트 등을 위해 반복할 수 있습니다.torch.nn.Parameter: Module 에 역전파 동안 업데이트가 필요한 가중치가 있음을 알려주는 텐서용 래퍼입니다. requires_grad 속성이 설정된 텐서만 업데이트 됩니다.torch.nn.functional: 활성화 함수, 손실 함수 등을 포함하는 모듈이고, 물론 컨볼루션 및 선형 레이어 등에 대해서 상태를 저장하지않는(non-stateful) 버전의 레이어를 포함합니다.
-
torch.optim: 앞에서는
torch.no_grad()로 학습 가능한 매개변수를 갖는 텐서들을 직접 조작하여 모델의 가중치(weight)를 갱신하였습니다. 이는 간단한 최적화 알고리즘에서는 크게 부담이 되지 않지만, 실제로 신경망을 학습할 때는 AdaGrad, RMSProp, Adam 등과 같은 더 정교한 옵티마이저(optimizer)를 사용하곤 합니다. 이에 PyTorch의 optim 패키지는 최적화 알고리즘에 대한 아이디어를 추상화하고 일반적으로 사용하는 최적화 알고리즘의 구현체(implementation)를 제공합니다.
-
Dataset, DataLoader
-
데이터 샘플을 처리하는 코드는 지저분하고 유지보수가 어려울 수 있습니다. 더 나은 가독성(readability)과 모듈성(modularity)을 위해 데이터셋 코드를 모델 학습 코드로부터 분리하는 것이 이상적입니다.
-
PyTorch는
torch.utils.data.DataLoader와torch.utils.data.Dataset의 두 가지 데이터 기본 요소를 제공하여 미리 준비해된(pre-loaded) 데이터셋 뿐만 아니라 가지고 있는 데이터를 사용할 수 있도록 합니다.-
torch.utils.data.Dataset: 샘플과 정답(label)을 저장하고, len 및 getitem 이 있는 객체의 추상 인터페이스입니다.
-
torch.utils.data.DataLoader: 모든 종류의 Dataset을 기반으로 데이터의 배치들을 출력하는 반복자(iterator)를 생성합니다.
-
긴 글 읽어주셔서 감사합니다 ^~^

안녕하세요 torch autograd 관련 검색하다 발견하여 게시하신 코드로 실습해보다 에러가 생겨 문의드립니다. Jupyter notebook을 사용중입니다.
hidden = nn.ReLU(x.mm(w1))에서 아래와 같은 에러가 나오더군요.
'ReLU' object has no attribute 'mm'
해결방안을 알려주시면 정말감사하겠습니다.