[강의노트] LangChain Academy : Introduction to LangGraph (Module 3)

랭체인(LangChain)과 랭그래프(LangGraph)는 대규모 언어 모델(LLM)을 활용한 애플리케이션 개발을 위한 도구들입니다. 위 강의는 LangChain에서 운영하는 LangChain Academy에서 제작한 "Introduction to LangGraph" 강의의 내용을 정리 및 추가 설명한 내용입니다.
- 강의 링크 : https://youtu.be/29XE10U6ooc
- 랭체인 : https://www.langchain.com/
이번 포스트는 "Module3"내용을 다룹니다:
- Lesson 1: Streaming
- Lesson 2: Breakpoints
- Lesson 3: Editing State and Human Feedback
- Lesson 4: Dynamic Breakpoints
- Lesson 5: Time Travel
Lesson 1: Streaming
- 본 강의에서도 지난번에 사용했던 요약 LLM Agent를 사용하여 실습을 수행합니다.
from IPython.display import Image, display
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage, RemoveMessage
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import StateGraph, START, END
from langgraph.graph import MessagesState
# LLM
model = ChatOpenAI(model="gpt-4o", temperature=0)
# 상태
class State(MessagesState):
summary: str
# 모델을 호출하는 로직 정의
def call_model(state: State):
# 요약이 있으면 가져옴
summary = state.get("summary", "")
# 요약이 있으면 추가
if summary:
# 시스템 메시지에 요약 추가
system_message = f"이전 대화의 요약: {summary}"
# 새로운 메시지에 요약 추가
messages = [SystemMessage(content=system_message)] + state["messages"]
else:
messages = state["messages"]
response = model.invoke(messages)
return {"messages": response}
def summarize_conversation(state: State):
# 먼저 기존 요약을 가져옴
summary = state.get("summary", "")
# 요약 프롬프트 생성
if summary:
# 이미 요약이 존재함
summary_message = (
f"지금까지의 대화 요약: {summary}\n\n"
"위의 새로운 메시지를 고려하여 요약을 확장하세요:"
)
else:
summary_message = "위의 대화를 요약하세요:"
# 프롬프트를 히스토리에 추가
messages = state["messages"] + [HumanMessage(content=summary_message)]
response = model.invoke(messages)
# 가장 최근 2개의 메시지를 제외한 모든 메시지 삭제
delete_messages = [RemoveMessage(id=m.id) for m in state["messages"][:-2]]
return {"summary": response.content, "messages": delete_messages}
# 대화를 종료할지 요약할지 결정
def should_continue(state: State):
"""다음에 실행할 노드를 반환합니다."""
messages = state["messages"]
# 메시지가 6개 이상이면 대화를 요약
if len(messages) > 6:
return "summarize_conversation"
# 그렇지 않으면 종료
return END
# 새 그래프 정의
workflow = StateGraph(State)
workflow.add_node("conversation", call_model)
workflow.add_node(summarize_conversation)
# 시작점을 대화로 설정
workflow.add_edge(START, "conversation")
workflow.add_conditional_edges("conversation", should_continue)
workflow.add_edge("summarize_conversation", END)
# 컴파일
memory = MemorySaver()
graph = workflow.compile(checkpointer=memory)
display(Image(graph.get_graph().draw_mermaid_png()))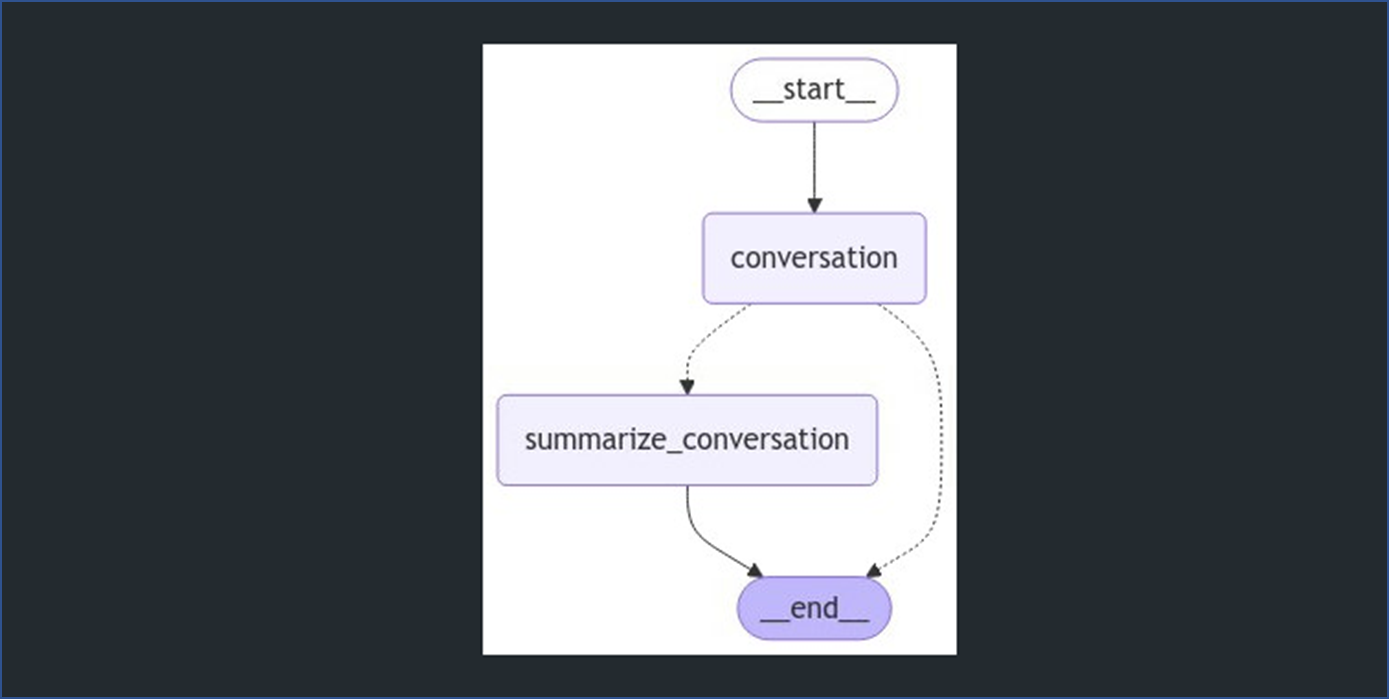
개요
Langraph의 Streaming 기능은 에이전트가 작업 중 발생하는 이벤트와 상태를 실시간으로 확인할 수 있는 기능입니다.
주요 개념
스트리밍 매서드
- LangGraph의
.stream()과.astream()메서드는 그래프 실행 중 상태를 스트리밍하는 두 가지 주요 방법입니다. 이 두 메서드의 차이점과 사용 방법을 설명해드리겠습니다:
-
.stream()- 동기 방식 스트리밍:-
.stream(): Stream은동기식(Synchronous)방식으로, 각 노드가 호출될 때마다 상태 업데이트를 스트리밍합니다. -
동기적으로 작동한다는 것은, 작업을 하나씩 순차적으로 처리하는 것을 의미합니다. 앞의 작업이 완료되지 않으면 뒤의 작업이 실행되지 않습니다.- 예를 들어, 친구에게 전화를 걸어서 친구가 전화를 받기 전까지 기다리는 상황을 생각해 보세요. 전화를 받기 전까지 다른 일을 할 수 없는 것처럼, 동기 방식은 하나의 작업이 끝날 때까지 대기한 후 다음 작업을 진행하는 방식입니다.
-
LangGraph에서
.stream()메서드는 동기 방식으로 작동합니다. 즉, 각 노드가 완료될 때까지 기다린 후 그 결과를 받아오는 방식입니다. 예를 들어, 그래프의 첫 번째 노드가 실행을 완료해야 두 번째 노드가 실행될 수 있습니다.for chunk in graph.stream(inputs, stream_mode="values"): print(chunk) # 각 노드 실행 후 출력- 이 코드에서는 첫 번째 노드의
실행이 끝나야그 결과(chunk)가 출력되고, 그 후에야 두 번째 노드가 실행됩니다. - 모든 작업이 순서대로 이루어지기 때문에 코드의 흐름이 예측 가능하고 직관적입니다. 그러나 작업이 오래 걸릴 경우, 그 작업이 끝날 때까지 아무것도 할 수 없습니다.
- 이 코드에서는 첫 번째 노드의
-
-
.astream()- 비동기 방식 스트리밍:-
.astream(): A-Stream은비동기식(Asynchronous)방식으로 상태 업데이트를 스트리밍합니다. -
비동기적으로 작동한다는 것은, 작업을 동시에 처리할 수 있다는 것을 의미합니다. 앞의 작업이 끝날 때까지 기다리지 않고, 다른 작업을 진행할 수 있습니다.- 다시 전화를 거는 예시로 돌아가면, 친구가 전화를 받을 때까지 기다리지 않고 다른 일을 할 수 있는 상황을 상상해 보세요. 친구가 전화를 받으면 그때 다시 통화로 돌아올 수 있습니다.
-
LangGraph에서
.astream()메서드는 비동기 방식으로 작동합니다. 즉, 한 작업이 끝날 때까지 기다리지 않고 다른 작업을 동시에 처리할 수 있습니다. 이 방식은 특히 많은 시간이 걸리는 작업(예: 네트워크 요청, 데이터베이스 접근 등)을 효율적으로 처리하는 데 유리합니다.async for chunk in graph.astream(inputs, stream_mode="values"): print(chunk) # 각 노드 실행이 끝날 때까지 기다리지 않고 처리- 이 코드에서는 첫 번째 노드의 실행이
완료되기 전에두 번째 노드가 실행될 수 있습니다. - 비동기 방식 덕분에 여러 작업을 동시에 처리할 수 있지만, 그로 인해 코드의 실행 순서가 복잡해질 수 있습니다.
- 이 코드에서는 첫 번째 노드의 실행이
-
🤔 언제 동기/비동기를 사용해야 할까?
- 동기: 작업이 비교적 빠르게 끝나고 순차적으로 실행해야 할 때 사용합니다.
- 예를 들어, 작은 규모의 프로그램이나 한 번에 하나씩 처리해야 하는 작업에서 동기 방식을 사용하는 것이 좋습니다.
- 비동기: 비동기는 여러 작업을 동시에 처리해야 할 때 특히 유용합니다.
- 예를 들어, 네트워크 요청, 파일 읽기/쓰기, 데이터베이스 접근과 같이 시간이 오래 걸리는 작업에서 비동기 방식을 사용하는 것이 더 효율적입니다.
스트리밍 모드
-
스트림 모드는 LangGraph가 실행되는 동안 그래프의 상태를 어떤 방식으로 모니터링하고 확인할 것인지를 결정하는 옵션입니다.
-
각 모드는 그래프가 실행될 때 생성되는 데이터를 어떻게 스트리밍할지에 대한 방식을 정의합니다. 쉽게 말하면, 스트리밍 모드는 실행 중 발생하는 정보(상태나 결과물)를 실시간으로 어떻게 보고할 것인지를 나타냅니다.
주요 스트림 모드

-
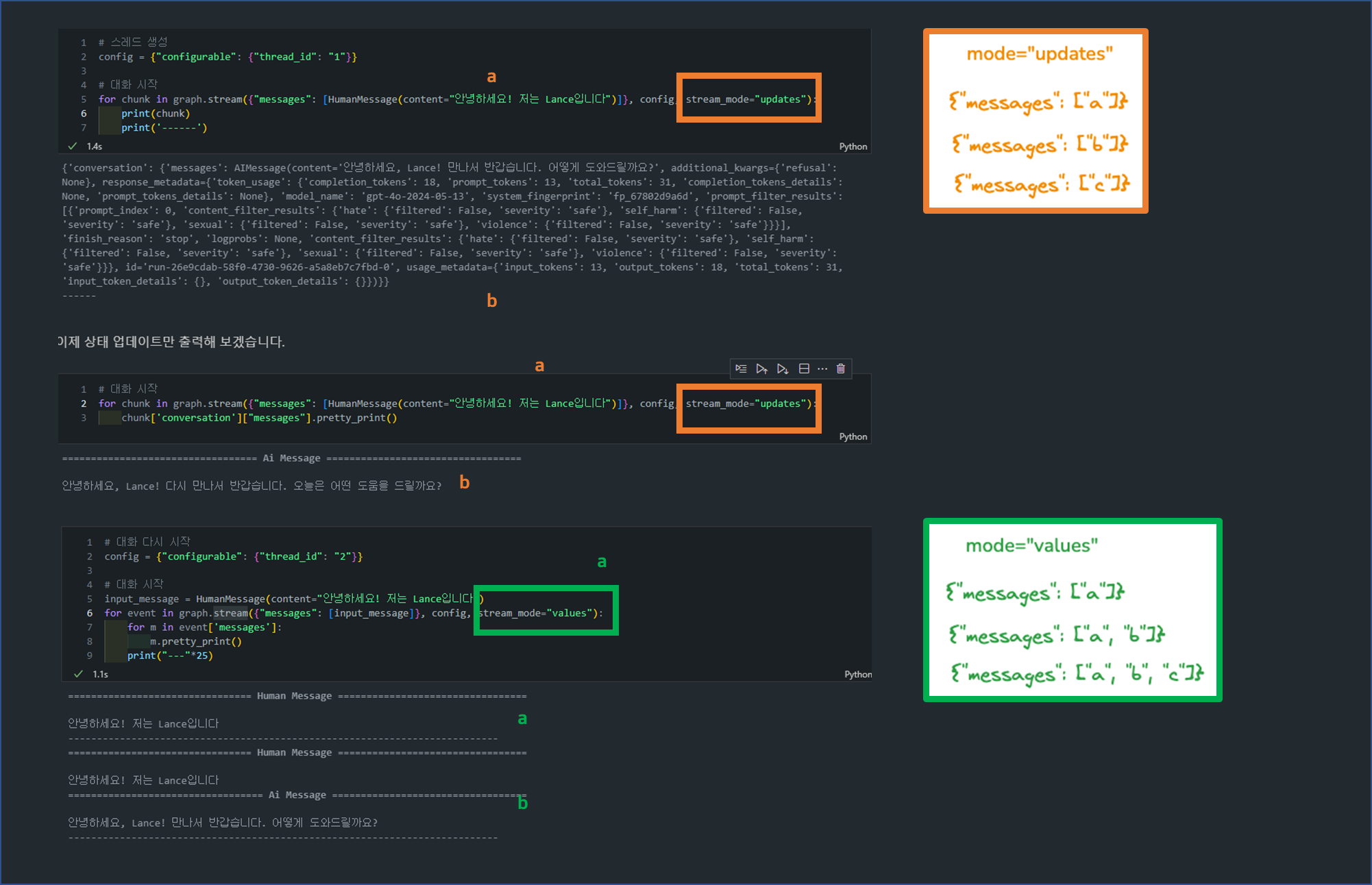
"values" 모드:
- 그래프의 각 노드가 실행된 후, 전체 상태를 스트리밍합니다.
- 즉, 노드가 실행된 후 현재까지의 모든 상태를 확인할 수 있습니다.
- 예를 들어, 노드가 실행될 때마다 전체 작업 흐름의 스냅샷을 제공받는 것과 같습니다. 이 방법은 각 노드 실행 후 전체 상태를 검토할 때 유용합니다.
사용 예시:
for chunk in graph.stream(inputs, stream_mode="values"): print(chunk) # 각 노드 실행 후 전체 상태 출력 -
"updates" 모드:
- 각 노드 실행 후 변경된 부분만 스트리밍합니다.
- 즉, 상태가 변한 부분만 실시간으로 볼 수 있어, 불필요한 데이터를 줄이고 관심 있는 부분만 확인하는 데 유리합니다.
- 예를 들어, 대규모 데이터를 처리하는 그래프에서 변화가 있는 부분만 확인하고 싶을 때 유용합니다.
사용 예시:
for chunk in graph.stream(inputs, stream_mode="updates"): print(chunk) # 변경된 상태만 출력
- LLM 토큰 스트리밍: LLM 토큰 스트리밍은 LangGraph에서 대형 언어 모델(LLM)이 생성하는
텍스트를 실시간으로 모니터링하는 기능입니다.- LLM은 주로 긴 텍스트를 생성하는데, 모든 결과가 한 번에 반환되는 대신 토큰이라는 작은 단위로 결과를 점진적으로 제공할 수 있습니다.
- 이때 스트리밍을 통해 모델이 생성하는 텍스트를 한 번에 기다리지 않고 실시간으로 확인할 수 있는 장점이 있습니다. 이 기능은 대화형 시스템, 긴 텍스트 생성 작업에서 특히 유용합니다.
💡 LLM 토큰 스트리밍의 목적
1. 실시간 응답 제공: LLM이 응답을 생성하는 동안 즉각적인 피드백을 사용자에게 제공하여 기다리는 시간을 줄이고, 사용자 경험을 향상시킬 수 있습니다.
2. 세밀한 모니터링: LLM이 중간에 생성하는 텍스트를 관찰하여 시스템의 성능을 평가하거나 문제를 디버깅할 수 있습니다.
3. 유연한 제어: 특정 노드에서 발생하는 토큰만을 실시간으로 확인하고, 필요한 경우 중간에 개입하거나 제어할 수 있습니다.
스트리밍 토큰의 주요 개념
- 이벤트 기반 스트리밍:
- LLM이 텍스트를 생성하는 동안 이벤트가 발생하며, 이러한 이벤트를 기반으로 토큰이 스트리밍됩니다.
- LangGraph에서
.astream_events()메서드를 사용해 이러한 이벤트를 비동기적으로 처리할 수 있습니다.
config = {"configurable": {"thread_id": "3"}}
input_message = HumanMessage(content="피파에서 대한민국은 어느정도 실력인가요?")
async for event in graph.astream_events({"messages": [input_message]}, config, version="v2"):
print(f"노드: {event['metadata'].get('langgraph_node','')}. 유형: {event['event']}. 이름: {event['name']}")-
출력 예시:
노드: . 유형: on_chain_start. 이름: LangGraph 노드: __start__. 유형: on_chain_start. 이름: __start__ 노드: __start__. 유형: on_chain_end. 이름: __start__ 노드: conversation. 유형: on_chain_start. 이름: conversation 노드: conversation. 유형: on_chat_model_start. 이름: ChatOpenAI 노드: conversation. 유형: on_chat_model_stream. 이름: ChatOpenAI (중략) -
이 코드는 그래프의 특정 노드에서 발생하는 이벤트를 실시간으로 추적하여, 각 노드가 어떤 작업을 하고 있는지 상태 정보를 얻습니다.
-
해당 코드 및 출력 결과에서
event['metadata'],event['event'],event['name']등은 LangGraph에서 발생하는 이벤트의 구성 요소입니다.- 이러한 구성 요소들은 그래프 실행 중 발생하는 이벤트에 대한 메타데이터를 제공합니다. 이를 통해 어떤 노드에서 어떤 유형의 이벤트가 발생했는지, 그 이벤트의 이름이 무엇인지를 실시간으로 추적할 수 있습니다.
-
예를 들어, 위 출력 마지막에 대화형 AI에서 현재 LLM이 "on_chat_model_stream" 이벤트를 통해 현재 해당 노드에서 응답을 생성하는 중임을 확인할 수 있습니다.
-
이벤트 구조:
-
event: 발생한이벤트의 유형을 나타냅니다. 예를 들어, LLM이 스트리밍하는 이벤트는"on_chat_model_stream"혹은"on_chain_stream"같은 유형으로 표시됩니다.-
on_chat_model_stream: LLM(대형 언어 모델)이 생성하는 토큰을 실시간으로 스트리밍하는 이벤트입니다. LLM이 입력을 받아 응답을 생성하는 과정에서 생성된 부분적인 텍스트(토큰)들이 실시간으로 전송됩니다. -
on_chain_stream: 그래프의 특정 노드에서 발생하는 일반적인 이벤트 스트리밍을 나타냅니다. 모든 노드에서 발생할 수 있는 이벤트이며, 각 노드가 실행되면서 일어나는 작업의 상태를 스트리밍합니다.
-
-
name:이벤트의 이름으로, 어떤 노드에서 발생한 이벤트인지 명시합니다. -
data:이벤트와 관련된 데이터를 담고 있습니다. LLM이 생성하는 실제 텍스트 데이터(토큰)를 포함합니다. 이 데이터는AIMessageChunk와 같은 형태로 제공됩니다. -
metadata: 이 필드는추가적인 메타 정보를 포함합니다. 여기에는 이벤트가 발생한 노드(예:langgraph_node)에 대한 정보도 포함됩니다.
-
스트리밍 방법
- 특정 노드의 토큰 스트리밍:
- LLM이 여러 노드에서 호출될 수 있기 때문에, 특정 노드에서 발생하는 토큰만을 스트리밍하고 싶을 때가 있습니다.
- 이를 위해
metadata['langgraph_node']값을 이용해 특정 노드의 출력을 필터링할 수 있습니다.
on_chain_stream:
- 이 코드는 특정 노드(예:
conversation)의 일반적인 상태 변화나 그래프 실행 상태를 추적하기 위한 용도로 사용됩니다.- LLM의 토큰 생성과는 직접적인 관련이 없으며, 그래프의 노드 상태 변화를 추적하는 방식입니다.
# on_chain_stream
node_to_stream = 'conversation'
config = {"configurable": {"thread_id": "1"}}
input_message = HumanMessage(content="피파에서 대한민국은 어느정도 실력인가요?")
async for event in graph.astream_events({"messages": [input_message]}, config, version="v2"):
# 특정 노드의 상태 변화 추적하기
if event["event"] == "on_chain_stream" and event['metadata'].get('langgraph_node','') == node_to_stream:
print(event["data"])on_chain_stream: 그래프의 상태 변화나 노드 실행 상태가 바뀔 때 발생하는 이벤트입니다. LLM의 응답 생성이 끝나고 그래프의 상태가 변하면 이 이벤트가 발생하며, 이때 전체 응답이 나온 이유는 LLM이 답변을 완료했기 때문이 아니라, 그래프 내 노드의 상태가 변화했기 때문입니다.
node_to_stream = 'conversation'
config = {"configurable": {"thread_id": "2"}}
input_message = HumanMessage(content="피파에서 대한민국은 어느정도 실력인가요?")
async for event in graph.astream_events({"messages": [input_message]}, config, version="v2"):
# 특정 노드에서 채팅 모델 토큰 가져오기
if event["event"] == "on_chat_model_stream" and event['metadata'].get('langgraph_node','') == node_to_stream:
# if event["event"] == "on_chain_stream" and event['metadata'].get('langgraph_node','') == node_to_stream:
print(event["data"])
(중략)
on_chat_model_stream:
- 이 코드는 LLM의 응답이 점진적으로 생성될 때마다 발생하는 이벤트를 스트리밍합니다.
on_chat_model_stream이벤트는 LLM이 응답을 생성할 때 부분적으로 생성된 텍스트(토큰)를 실시간으로 추적하는 데 사용됩니다.
# on_chat_model_stream
node_to_stream = 'conversation'
config = {"configurable": {"thread_id": "2"}}
input_message = HumanMessage(content="피파에서 대한민국은 어느정도 실력인가요?")
async for event in graph.astream_events({"messages": [input_message]}, config, version="v2"):
# 특정 노드에서 채팅 모델 토큰 추적하기
if event["event"] == "on_chat_model_stream" and event['metadata'].get('langgraph_node','') == node_to_stream:
print(event["data"])on_chat_model_stream: LLM이 토큰 단위로 점진적으로 응답을 생성할 때마다 발생하는 이벤트입니다. LLM이 긴 응답을 생성할 때 각각의 토큰(작은 텍스트 단위)이 실시간으로 스트리밍되어 결과가 나오는 것입니다. 이 방식은 실시간으로 토큰을 추적하며, 긴 응답을 기다리지 않고 중간 결과를 빠르게 확인할 수 있습니다.
{'chunk': AIMessageChunk(content='대한', additional_kwargs={}, response_metadata={}, id='run-f5d6eb65-2633-4bfe-bb73-82cc16348735')}
{'chunk': AIMessageChunk(content='민국', additional_kwargs={}, response_metadata={}, id='run-f5d6eb65-2633-4bfe-bb73-82cc16348735')}
{'chunk': AIMessageChunk(content=' 축', additional_kwargs={}, response_metadata={}, id='run-f5d6eb65-2633-4bfe-bb73-82cc16348735')}
{'chunk': AIMessageChunk(content='구', additional_kwargs={}, response_metadata={}, id='run-f5d6eb65-2633-4bfe-bb73-82cc16348735')}
{'chunk': AIMessageChunk(content=' 국가', additional_kwargs={}, response_metadata={}, id='run-f5d6eb65-2633-4bfe-bb73-82cc16348735')}
{'chunk': AIMessageChunk(content='대표', additional_kwargs={}, response_metadata={}, id='run-f5d6eb65-2633-4bfe-bb73-82cc16348735')}
{'chunk': AIMessageChunk(content='팀', additional_kwargs={}, response_metadata={}, id='run-f5d6eb65-2633-4bfe-bb73-82cc16348735')}
{'chunk': AIMessageChunk(content='은', additional_kwargs={}, response_metadata={}, id='run-f5d6eb65-2633-4bfe-bb73-82cc16348735')}
{'chunk': AIMessageChunk(content=' 아', additional_kwargs={}, response_metadata={}, id='run-f5d6eb65-2633-4bfe-bb73-82cc16348735')}
{'chunk': AIMessageChunk(content='시아', additional_kwargs={}, response_metadata={}, id='run-f5d6eb65-2633-4bfe-bb73-82cc16348735')}
{'chunk': AIMessageChunk(content='에서', additional_kwargs={}, response_metadata={}, id='run-f5d6eb65-2633-4bfe-bb73-82cc16348735')}
{'chunk': AIMessageChunk(content=' 강', additional_kwargs={}, response_metadata={}, id='run-f5d6eb65-2633-4bfe-bb73-82cc16348735')}
{'chunk': AIMessageChunk(content='력', additional_kwargs={}, response_metadata={}, id='run-f5d6eb65-2633-4bfe-bb73-82cc16348735')}
(중략)- 토큰 데이터 추출:
- 이벤트에서
event['data']값이AIMessageChunk형태로 제공되며, 이를 사용해 실제 토큰 데이터를 추출합니다. chunk키를 사용하여 스트리밍된 텍스트 데이터를 얻고, 이를 실시간으로 확인할 수 있습니다.
- 이벤트에서
config = {"configurable": {"thread_id": "222"}}
input_message = HumanMessage(content="피파에서 대한민국은 어느정도 실력인가요?")
async for event in graph.astream_events({"messages": [input_message]}, config, version="v2"):
# 특정 노드에서 채팅 모델 토큰 가져오기
# if event["event"] == "on_chat_model_stream" and event['metadata'].get('langgraph_node','') == node_to_stream:
if event["event"] == "on_chain_stream" and event['metadata'].get('langgraph_node','') == node_to_stream:
data = event["data"]
print(data["chunk"]['messages'].content)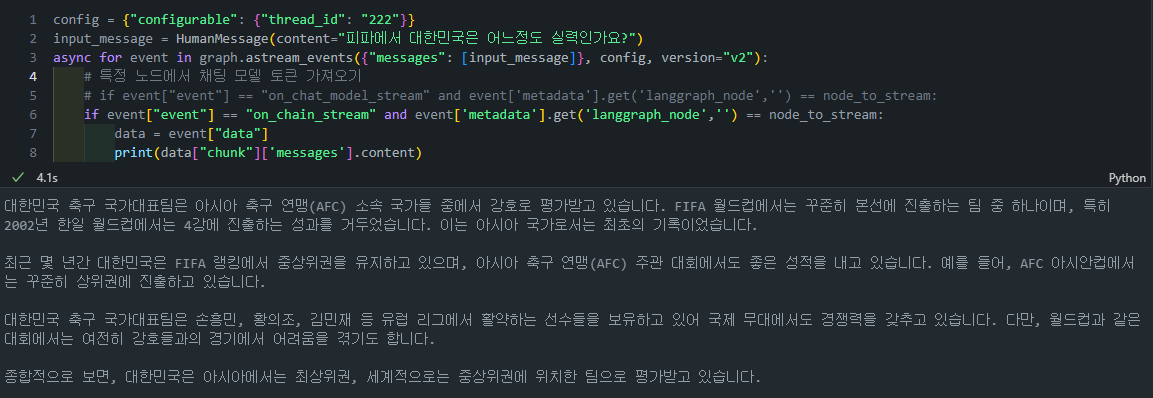
Lesson 2: Breakpoints
개요
Breakpoints는 작업 흐름에서 특정 지점에서 그래프의 실행을 멈추고, 사용자가 검토하거나 작업을 중단할 수 있게 해주는 기능입니다.
- 이는
Human-in-the-Loop워크플로우에서 중요한 요소로, 민감한 작업(예: 데이터베이스 쓰기, 외부 시스템에 쓰기)에 대해 사람이 승인을 할 수 있도록 해줍니다.
주요 개념
-
Human-in-the-loop (인간 개입)개념:- AI 시스템의 작동 과정에 인간이 개입하여 감독, 수정, 승인 등을 수행하는 방식입니다.
- 이는 AI의 결정이나 행동을 검토하고 필요시 조정할 수 있게 해줍니다.
-
LangGraph에서의
Human-in-the-loop동기:
a)승인 (Approval):- AI 에이전트의 특정 행동이나 결정을 사용자가 승인할 수 있습니다.
- 중요한 결정이나 위험한 작업 전에 인간의 검토를 받을 수 있습니다.
b)
디버깅 (Debugging):- 그래프 실행을 되돌려 문제를 재현하거나 피할 수 있습니다.
- 오류가 발생한 지점을 정확히 파악하고 수정할 수 있습니다.
c)
편집 (Editing):- 그래프의 상태를 수정할 수 있습니다.
- 실행 중 필요한 변경사항을 적용할 수 있습니다.
-
브레이크포인트 (Breakpoints):- 그래프의 특정 단계에서 실행을 중단하는 기능입니다.
- 사용자가 그래프의 상태를 검사하고 필요한 조치를 취할 수 있게 합니다.
- 주로 승인 프로세스에 사용되며, 특정 노드 실행 전에 중단점을 설정할 수 있습니다.
브레이크포인트 (Breakpoints)
Interrupt Before또는Interrupt After를 통해 브래이크포인트를 설정할 수 있습니다.
- Interrupt Before: 특정 노드가 실행되기 전에 그래프 실행을 중단합니다.
- Interrupt After: 특정 노드 실행 후에 그래프를 멈춥니다.
- 스트리밍과의 연계:
- 스트리밍을 통해 그래프 실행 중 출력을 실시간으로 볼 수 있습니다.
- 브레이크포인트와 결합하여 더 세밀한 제어와 모니터링이 가능합니다.
예제
- 예전에 모듈1에서 수행했던 실습 예제를 응용해보겠습니다:
multiply,add,divide함수가 정의되어 있습니다. 이들은 간단한 산술 연산을 수행합니다.- 이 함수들은 tools 리스트에 포함되어
bind_tools를 통해 LLM에 바인딩됩니다.
from langchain_openai import ChatOpenAI
def multiply(a: int, b: int) -> int:
"""a와 b를 곱합니다.
인자:
a: 첫 번째 정수
b: 두 번째 정수
"""
return a * b
# 이것은 도구가 될 것입니다
def add(a: int, b: int) -> int:
"""a와 b를 더합니다.
인자:
a: 첫 번째 정수
b: 두 번째 정수
"""
return a + b
def divide(a: int, b: int) -> float:
"""a를 b로 나눕니다.
인자:
a: 첫 번째 정수
b: 두 번째 정수
"""
return a / b
tools = [add, multiply, divide]
llm = ChatOpenAI(model="gpt-4")
llm_with_tools = llm.bind_tools(tools)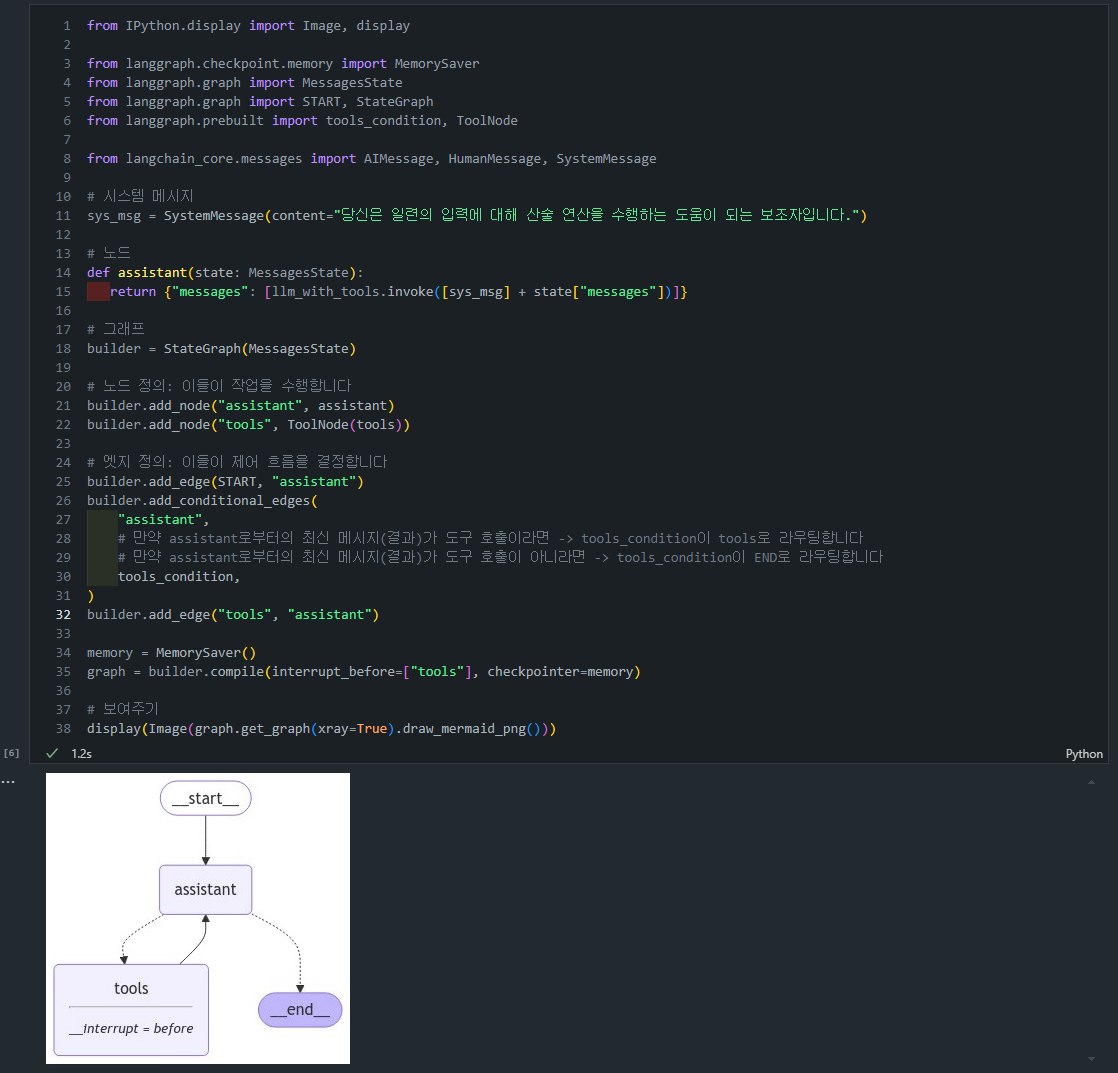
- 그래프 구조 및 컴파일 정의:
assistant 노드: LLM을 사용하여 사용자 입력에 응답합니다.tools 노드: 실제 산술 연산을 수행합니다.add_conditional_edges메서드에tools_condition을 사용하면, 자동으로 도구 호출 여부에 따른 조건부 라우팅이 설정됩니다.- 도구 호출이 있으면 "tools" 노드로 라우팅합니다.
- 도구 호출이 없으면 "END"로 라우팅합니다.
interrupt_before=["tools"]: tools 노드 실행 전에 그래프가 중단됩니다.MemorySaver를 사용하여 상태를 저장하고 관리합니다.
- 그래프 실행 및 상태 확인:
- "2와 3을 곱하세요"라는 초기 입력으로 그래프를 실행합니다.
graph.stream()을 사용하여 실행 과정을 스트리밍합니다.- 각 이벤트마다 메시지를 출력합니다.
graph.get_state()를 사용하여 현재 그래프의 상태를 가져옵니다.state.next를 통해 다음에 실행될 노드를 확인할 수 있습니다.
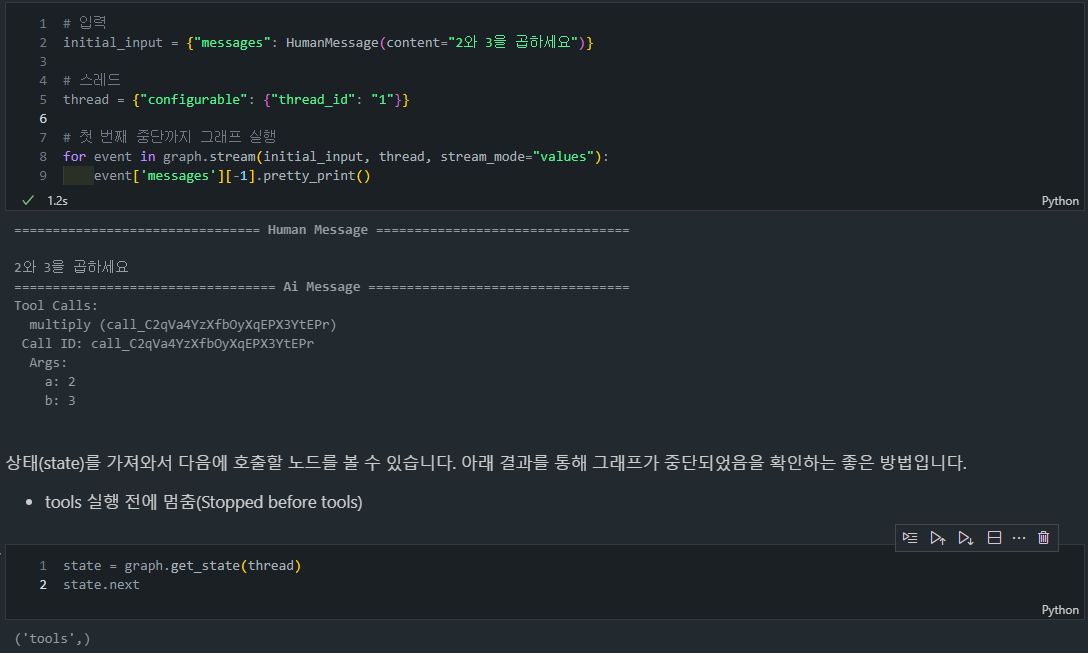
- 중단점(breakpoint): 중단점을 설정하면 그래프가 특정 노드에서 실행을 멈추고, 그 시점의 상태를 저장합니다. 사용자는 이 시점에서 그래프의 상태를 조회하거나, 입력을 받아 그래프의 실행을 계속할지 결정할 수 있습니다.
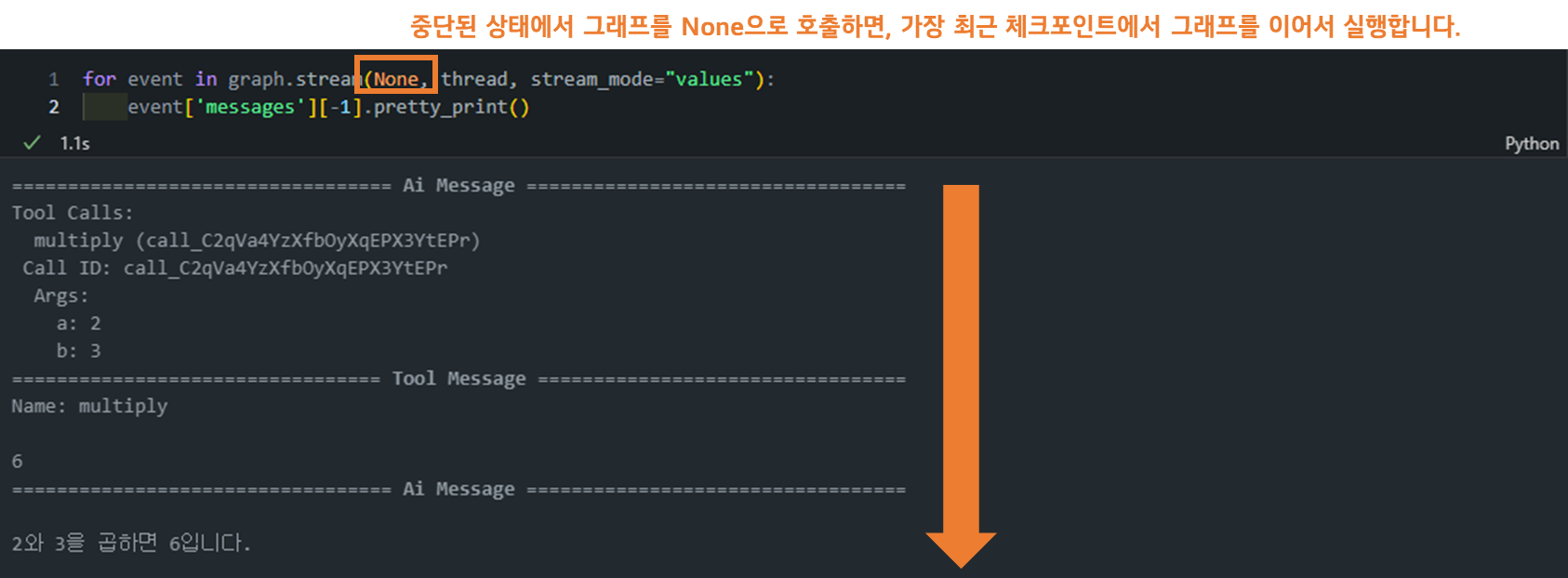
- 재실행 (None을 사용): 중단된 상태에서 그래프를 None으로 호출하면, 가장 최근 체크포인트에서 그래프를 이어서 실행합니다. 이는 그래프를 중단점에서 다시 시작하는 매우 간단하고 강력한 방법입니다.
예제
- 사용자 승인과 조건부 실행: 예를 들어, 사용자가 도구 호출을 승인하면, 그래프는 중단된 상태에서 도구 노드를 실행하고, 그 결과를 대화 모델에 전달하여 최종 응답을 생성합니다.
# 입력
initial_input = {"messages": HumanMessage(content="2와 3을 곱하세요")}
# 스레드
thread = {"configurable": {"thread_id": "3"}}
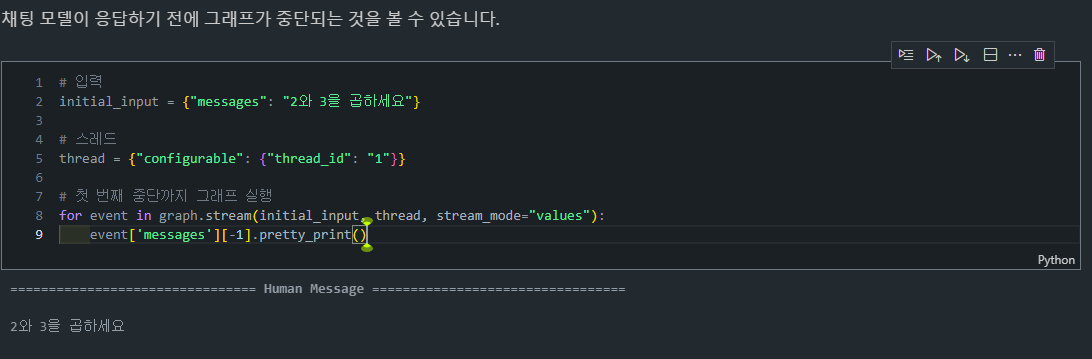
# 첫 번째 중단까지 그래프 실행
for event in graph.stream(initial_input, thread, stream_mode="values"):
event['messages'][-1].pretty_print()
# 사용자 피드백 받기
user_approval = input("도구를 호출하시겠습니까? (예/아니오): ")
# 승인 확인
if user_approval.lower() == "예":
# 승인된 경우, 그래프 실행 계속
for event in graph.stream(None, thread, stream_mode="values"):
event['messages'][-1].pretty_print()
else:
print("사용자에 의해 작업이 취소되었습니다.")Lesson 3: Editing State and Human Feedback
개요
LangGraph는 중단점(Breakpoints)을 활용하여 그래프의 상태를 관리하고, 특히 사람이 개입하는 흐름에서 상태를 수정하거나 확인할 수 있는 과정을 보여줍니다.
주요 개념
중단점(Breakpoints) 설정
-
중단점의 개념: 그래프의 특정 노드에서 실행을 일시 중단하고, 사용자의 개입을 기다리거나 상태를 수정하는 기회를 제공하는 메커니즘입니다. 아래의 목적으로 사용됩니다.
- 승인(Approval): 사용자가 특정 도구 호출을 승인하거나 거절할 수 있습니다. (Lesson2 소개)
- 디버깅(Debugging): 그래프가 중단된 상태에서 현재 상태를 검토하고, 문제를 해결할 수 있습니다. (Lesson2 소개)
- 편집(Editing): 그래프가 중단된 시점에서 상태를 수정하여, 원하는 대로 진행되도록 조정할 수 있습니다.
코드 예시
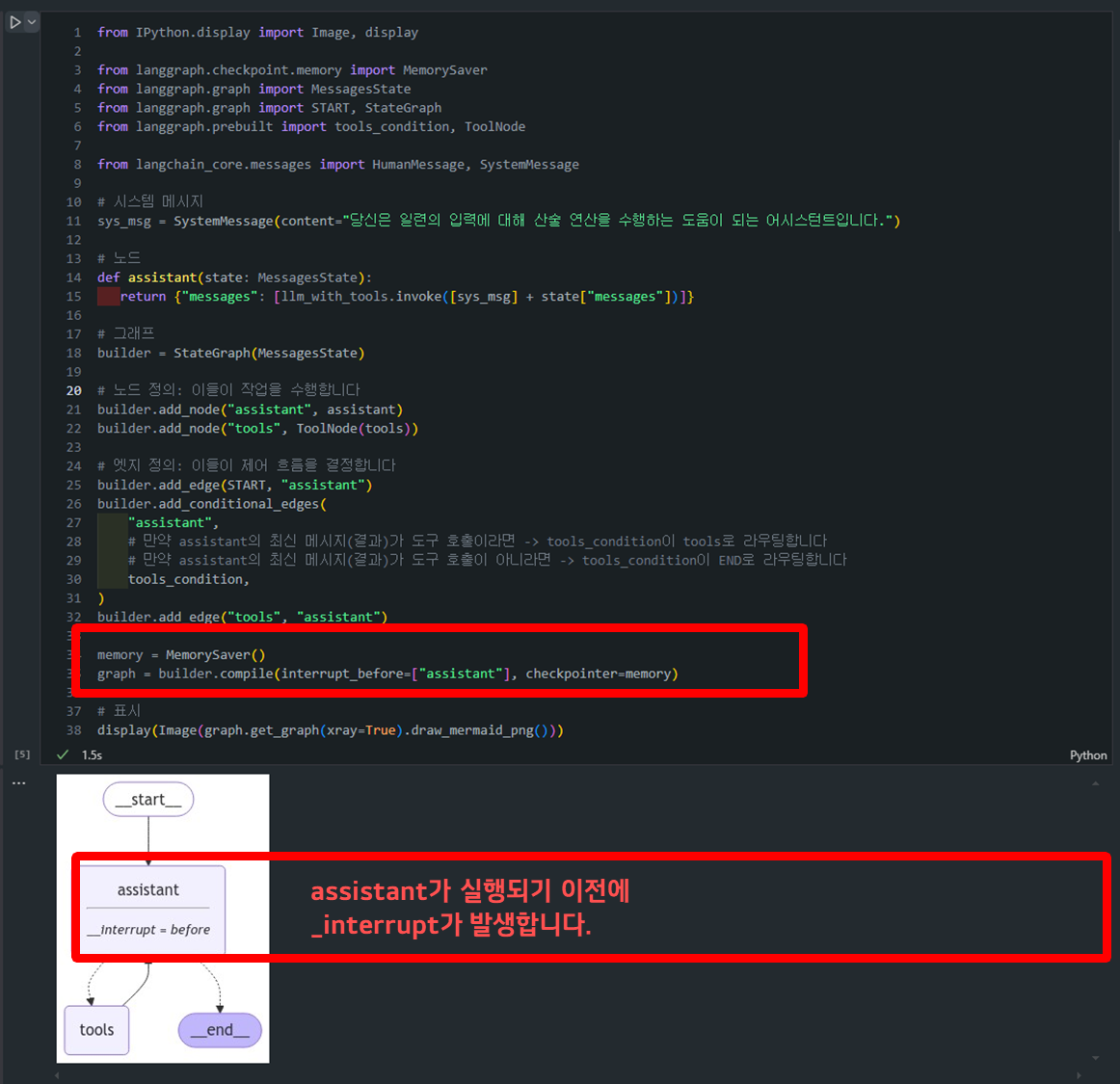
- 위 코드를 수행하면 assistant를 수행하기 이전에 interupption이 발생하게 됩니다. (
interrupt_before=["assistant"])
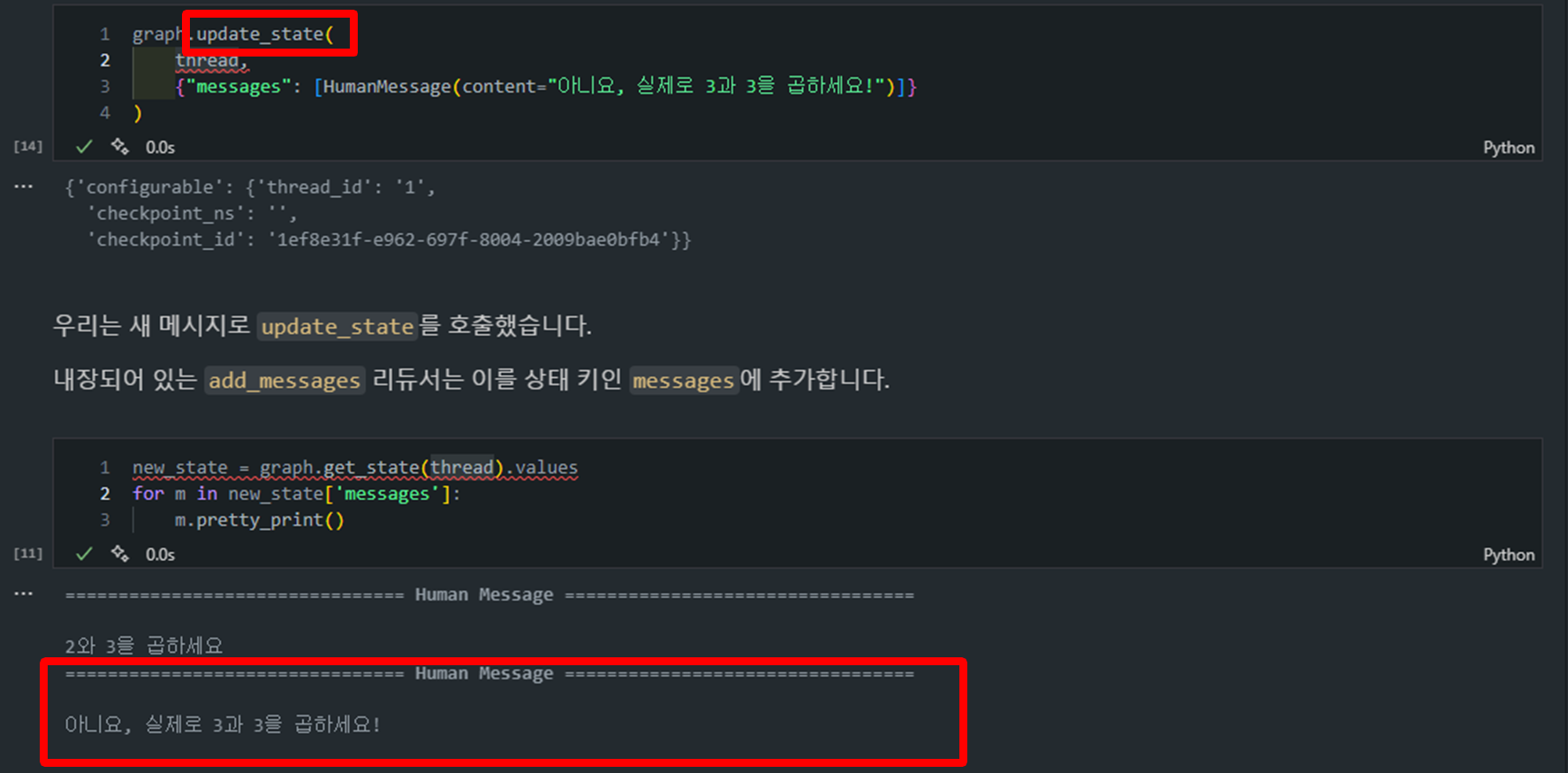
상태 업데이트 (graph.update_state)
graph.update_state(
thread,
{"messages": [HumanMessage(content="아니요, 실제로 3과 3을 곱하세요!")]}
)-
상태 업데이트: 이 코드는 현재 그래프의 상태를 업데이트하는 예시입니다.
thread는 해당 그래프 실행의 고유 ID로, 어떤 상태를 업데이트할 것인지를 식별하는 데 사용됩니다.
-
MessagesState: 메시지 상태를 관리하는 LangGraph의 내장된 클래스입니다. 이 클래스는 메시지들의 상태를 추적하고 업데이트할 때 사용됩니다.
-
Graph.update_state()호출할 때, MessagesState는 메시지를 추가하거나 업데이트하는 작업을 내부적으로 처리하며, 이 과정에서리듀서(reducer) 역할을 수행합니다.-
메시지 저장:
messages 키를 통해 메시지 상태를 유지 및 관리합니다. -
상태 업데이트:
update_state()메서드를 사용하여 새로운 메시지를 추가하거나 기존 메시지를 수정할 때,MessagesState클래스는 이를 자동으로 처리합니다. -
추가/덮어쓰기 로직: 메시지가 추가될 때
id가 없으면새로운 메시지를 리스트에 추가하고,id가 있으면해당 메시지를 덮어쓰는 방식으로 동작합니다.
-
-
💡(참고)
graph.update_state()메서드를 호출하면 기본적으로 다음과 같은 동작이 수행됩니다:
- "messages" 키에 대한 기본 리듀서 함수가 실행됩니다. 이 리듀서는 다음과 같이 동작합니다:
- 새 메시지의 ID가 기존 메시지와 일치하면 해당 메시지를 대체합니다.
- ID가 일치하지 않으면 새 메시지를 기존 메시지 목록의 끝에 추가합니다.
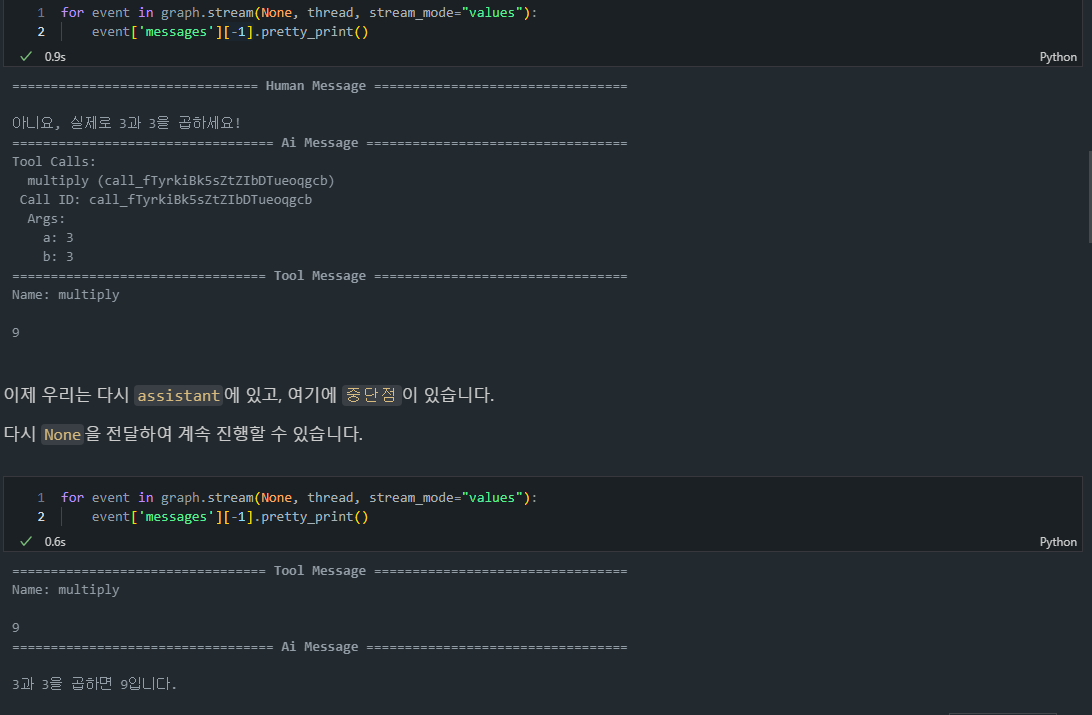
상태 업데이트 후 그래프 재실행
-
graph.stream(None, thread, stream_mode="values"): 그래프를 재실행하면서, 중단되었던 지점에서 상태를 확인하고, 상태가 업데이트된 후 남은 노드를 실행합니다.
-
재실행 과정:
- 그래프 상태를 업데이트하고,
None을 전달하여 중단된 지점에서 다시 실행을 계속합니다. - 그래프가 진행되면서 최종 도구 호출 및 AI 모델 응답을 수행하게 됩니다.
- 그래프 상태를 업데이트하고,
Dummy Node와 피드백 적용
-
이 기법은 실시간 사용자 개입을 통해,
LLM과의 상호작용을 보다 동적으로 만들 수 있는 방법입니다. -
사용자는 특정 노드에서 실행 중단 후 상태를 수정할 수 있으며, 그 이후로도 그래프가 자연스럽게 계속 실행됩니다.
-
이를 통해 더 복잡한 작업 흐름에서 인간 피드백을 반영할 수 있습니다.
-
Dummy Node란?: Dummy Node는 실제로는 아무 작업도 하지 않지만, 특정 시점에서 사용자의 피드백을 받을 수 있도록 중단점을 만들어 주는 가상의 노드입니다.- 이 노드는 실질적인 연산이나 상태 변경을 하지 않고, 그래프를 일시 정지하여 사용자가 개입할 수 있는 지점을 만들어 주는 역할을 합니다.
-
피드백 적용: Dummy Node는 사용자의 피드백을 받을 수 있는 구간을 제공하며, 그래프 실행을 잠시 중단합니다. 이후 사용자가 상태 업데이트를 요청하면, 그 피드백을 받아 그래프 상태에 반영합니다.- 사용자의 입력(피드백)은 그래프 상태에 직접 주입되어, 그 후에 이어지는 노드의 실행에 영향을 미칩니다. 이를 통해 사용자가 그래프 실행 과정에 동적으로 개입할 수 있습니다.
-
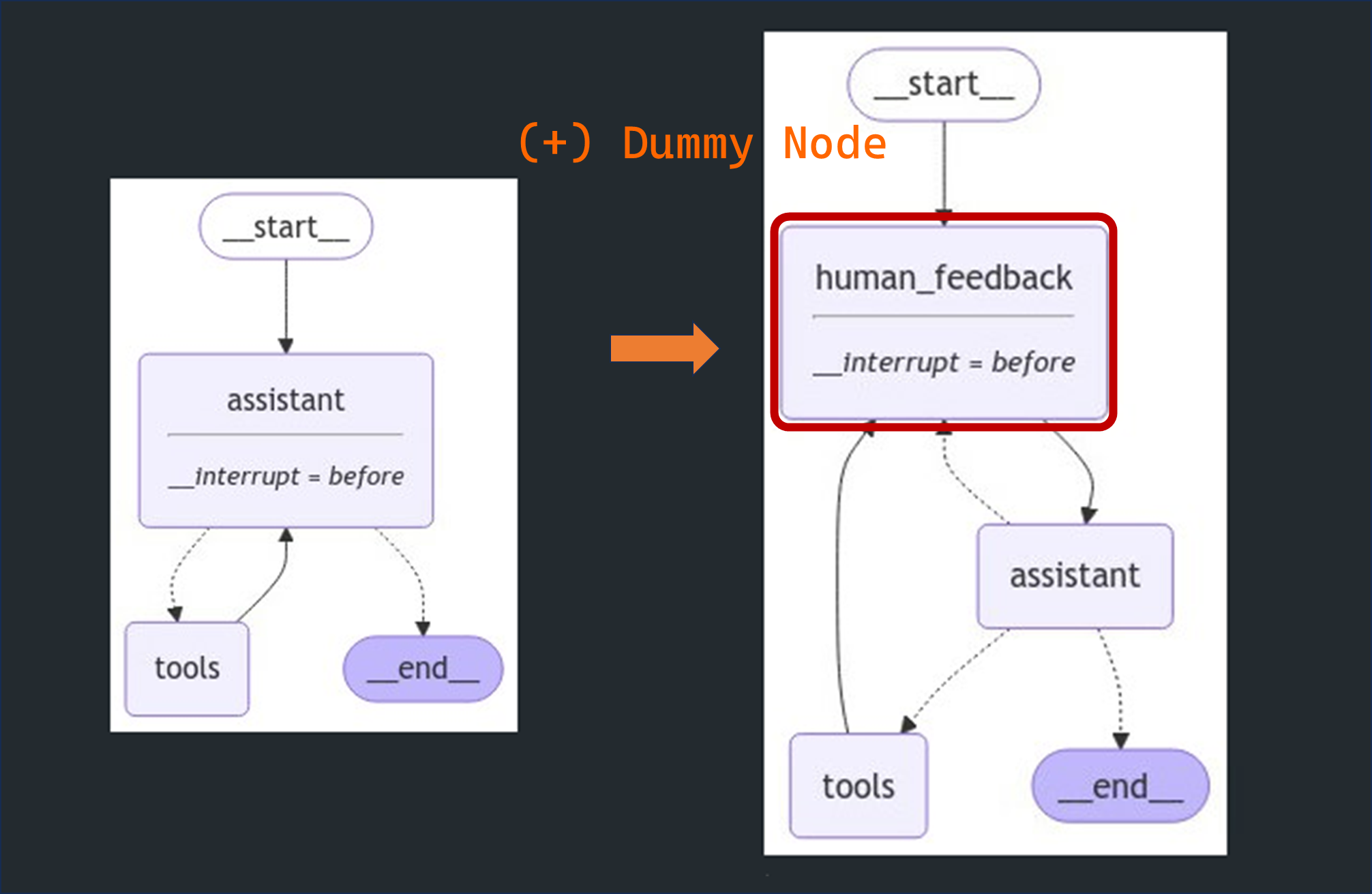
-
그래프 정의 : 위 그래프에는 3개의 주요 노드가 있습니다:
-
human_feedback: 사용자가 피드백을 제공할 수 있는 가상의 노드(Dummy Node)입니다.- 이 노드에서는 아무 작업도 하지 않지만, 사용자 피드백을 받을 지점을 만듭니다.
-
assistant: 사용자 입력과 LLM을 이용해 도구 호출 등의 연산을 수행하는 노드입니다. -
tools: 도구 호출을 담당하는 노드로, 실제 연산(예: 덧셈, 곱셈)을 수행합니다.# 시스템 메시지 sys_msg = SystemMessage(content="당신은 일련의 입력에 대해 산술 연산을 수행하는 도움이 되는 어시스턴트입니다.") # 중단되어야 하는 무작동 노드 def human_feedback(state: MessagesState): pass # 어시스턴트 노드 def assistant(state: MessagesState): return {"messages": [llm_with_tools.invoke([sys_msg] + state["messages"])]} # 그래프 빌드 builder = StateGraph(MessagesState) builder.add_node("assistant", assistant) builder.add_node("tools", ToolNode(tools)) builder.add_node("human_feedback", human_feedback)
-
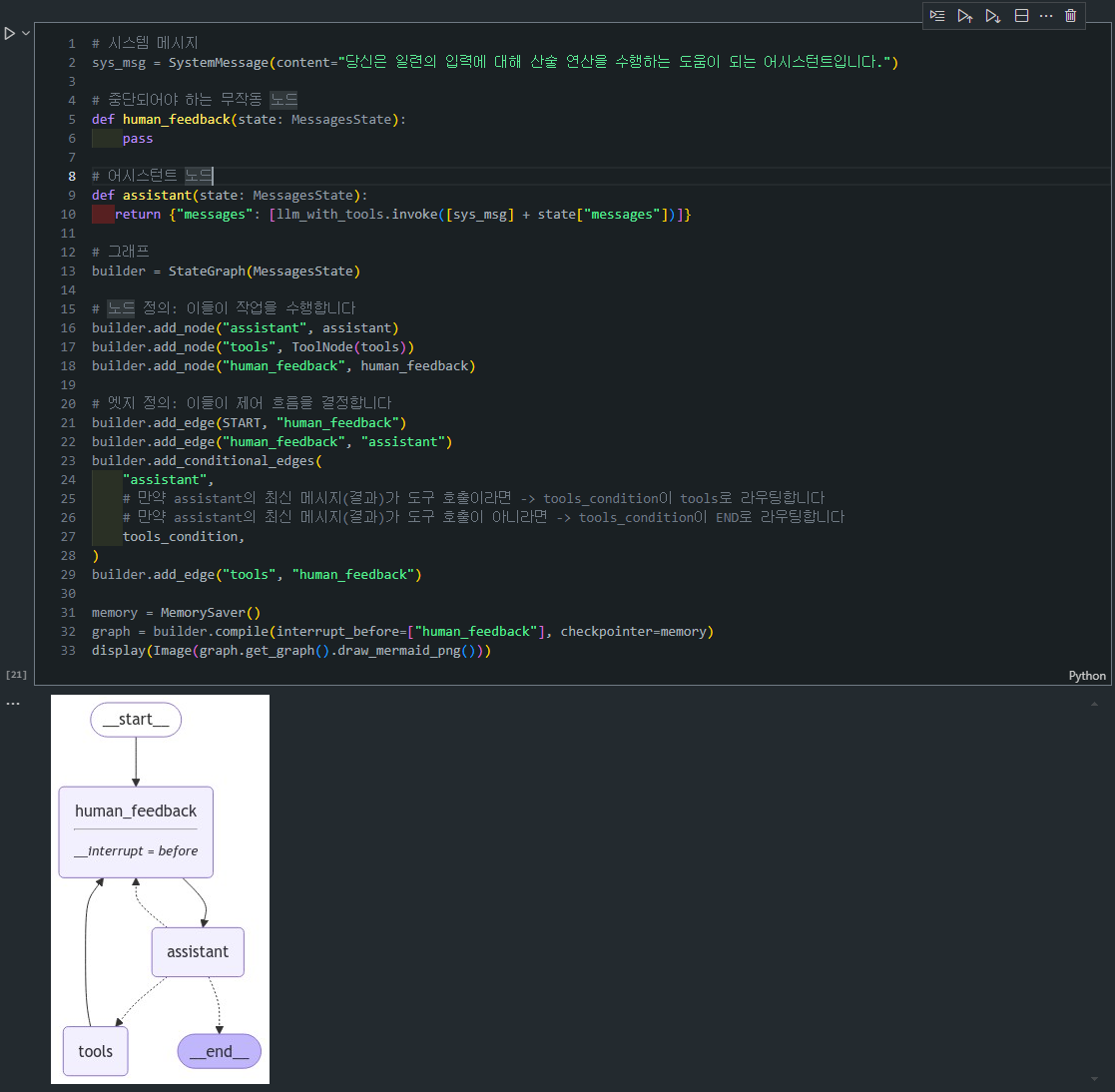
-
중단점 정의
- 이 코드에서는 중단점(interrupt)을
human_feedback노드에 지정했습니다. 즉, 이 노드에 도달할 때 그래프 실행이 멈추고 사용자의 피드백을 기다리게 됩니다. interrupt_before=["human_feedback"]부분이 이 역할을 담당합니다.
# 그래프를 human_feedback 노드 전에 중단 graph = builder.compile(interrupt_before=["human_feedback"], checkpointer=memory) - 이 코드에서는 중단점(interrupt)을
-
실행 중 피드백 받기
- 그래프는 처음에 사용자 입력을 받아
human_feedback노드까지 실행된 후 멈춥니다. - 그 후 사용자의 피드백을 기다리며,
input()을 통해 피드백을 받습니다. - 사용자가 입력한 피드백은
graph.update_state()메서드를 통해human_feedback노드의 상태에 반영됩니다.
# 사용자로부터 피드백 받기 user_input = input("상태를 어떻게 업데이트하고 싶은지 말씀해 주세요: ") # human_feedback 노드인 것처럼 상태를 업데이트 graph.update_state(thread, {"messages": user_input}, as_node="human_feedback") - 그래프는 처음에 사용자 입력을 받아
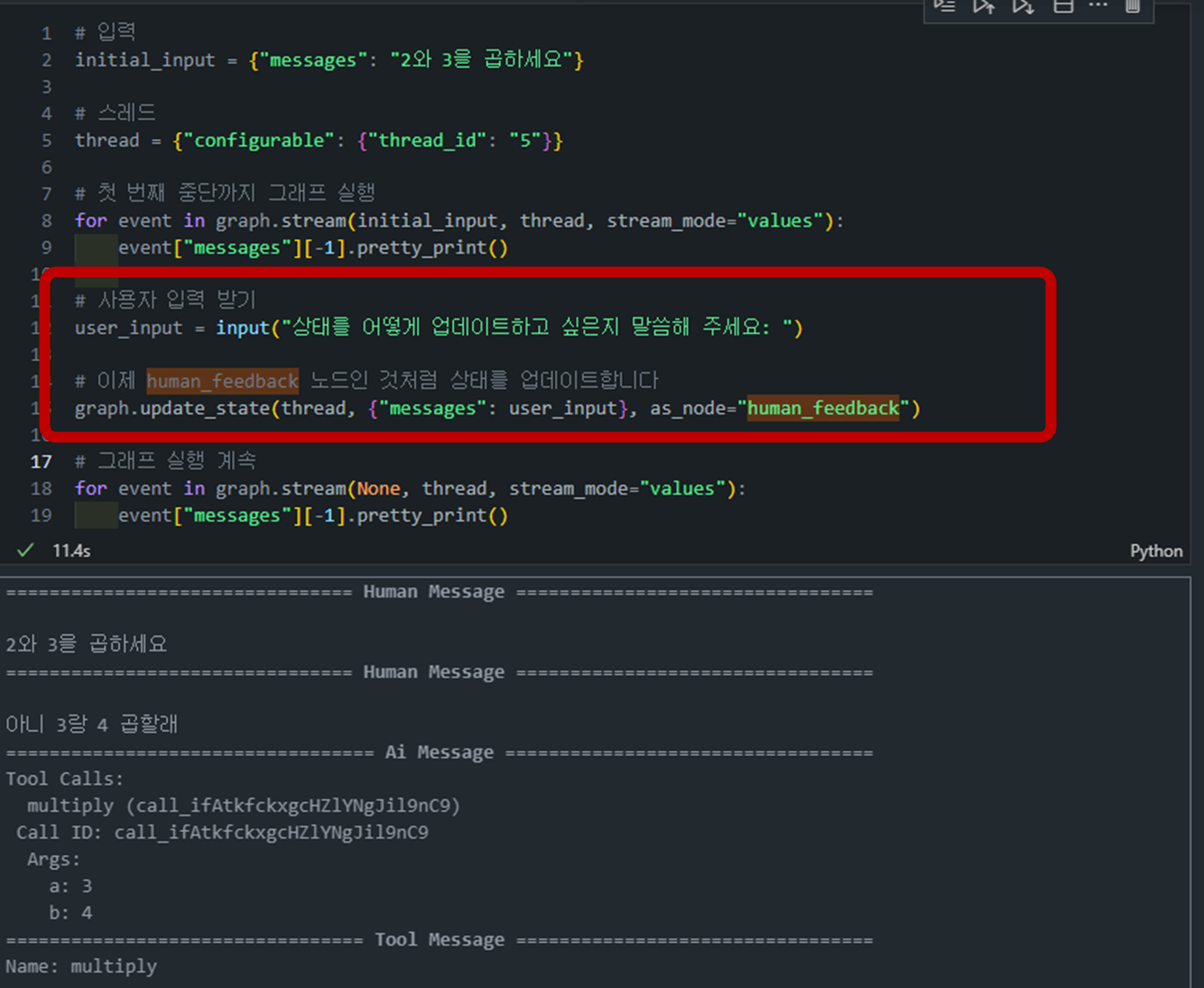
-
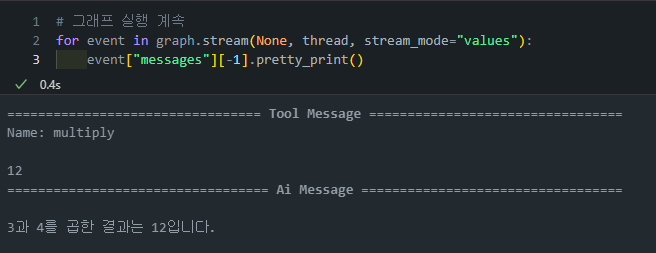
상태 업데이트 및 실행 재개
- 피드백을 받은 후,
graph.update_state()를 통해 해당 피드백을 상태에 반영한 뒤 그래프 실행을 계속합니다. - 사용자의 피드백에 따라 이후의 도구 호출이나 어시스턴트 응답이 달라질 수 있습니다.
# 그래프 실행 계속 for event in graph.stream(None, thread, stream_mode="values"): event["messages"][-1].pretty_print() - 피드백을 받은 후,
Lesson 4: Dynamic Breakpoints
개요
- 동적 중단점(Dynamic Breakpoints)은 그래프 실행 중
특정 조건에 따라자동으로 발생하는 중단점입니다.- 즉, 실행되는 중간에
특정 상태나조건을 감지하여 자동으로 멈추고, 이후 상태를 수정하거나 추가적인 입력을 받는 형태로 이어질 수 있습니다. - 동적 중단점은 특히 입력이
예상치 못한 값을 가질 때,상태 업데이트가 필요할 때, 또는특정 조건이 충족될 때매우 유용합니다.
- 즉, 실행되는 중간에
주요 개념
동적 중단점(Dynamic Breakpoints)의 목표
-
일반적인 중단점은 그래프가 특정 노드에 도달할 때 수동으로 설정되지만, 동적 중단점은
그래프가 스스로 특정 조건에 따라 중단하도록 할 수 있습니다. -
이를 통해 그래프는 내부에서 스스로 상태를 점검하고 필요시 중단하여, 상태
업데이트또는수정이 가능하게 만듭니다.
동적 중단점(Dynamic Breakpoints)의 이점
-
조건부로 중단: 개발자가 정의한 특정 로직에 따라 조건부로 중단이 가능합니다.
- 예를 들어, 입력값이 너무 길거나 특정 기준을 초과할 경우 자동으로 중단됩니다.
-
중단 이유 전달: 중단점이 발생한 이유를 사용자에게 명확히 전달할 수 있습니다.
NodeInterrupt에 전달할 정보를 포함시켜 왜 중단이 발생했는지를 설명할 수 있습니다.
코드 실습
1. 그래프 설정
- 먼저,
StateGraph를 사용하여 간단한 3단계 그래프를 설정합니다.- 이 그래프는
step_1,step_2,step_3으로 구성되며, step_2에서 입력값의 길이가 5자 이상일 경우 자동으로 중단시키는NodeInterrupt를 사용합니다.
- 이 그래프는
from typing_extensions import TypedDict
from langgraph.checkpoint.memory import MemorySaver
from langgraph.errors import NodeInterrupt
from langgraph.graph import START, END, StateGraph
# 상태 정의
class State(TypedDict):
input: str
# 1단계: 상태를 그대로 출력
def step_1(state: State) -> State:
print("---1단계---")
return state
# 2단계: 입력의 길이가 5자를 넘으면 중단 발생
def step_2(state: State) -> State:
if len(state['input']) > 5:
raise NodeInterrupt(f"5자보다 긴 입력을 받았습니다: {state['input']}")
print("---2단계---")
return state
# 3단계: 상태를 그대로 출력
def step_3(state: State) -> State:
print("---3단계---")
return state
# 그래프 설정
builder = StateGraph(State)
builder.add_node("step_1", step_1)
builder.add_node("step_2", step_2)
builder.add_node("step_3", step_3)
builder.add_edge(START, "step_1")
builder.add_edge("step_1", "step_2")
builder.add_edge("step_2", "step_3")
builder.add_edge("step_3", END)
# 메모리 설정
memory = MemorySaver()
# 그래프 컴파일
graph = builder.compile(checkpointer=memory)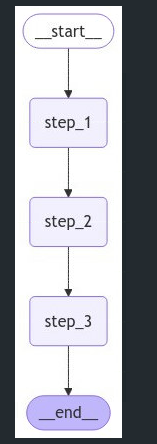
2. 그래프 실행 및 중단점 발생
입력값이 5자보다 길면 그래프는 step_2에서 중단됩니다.
initial_input = {"input": "hello world"}
thread_config = {"configurable": {"thread_id": "1"}}
# Run the graph until the first interruption
for event in graph.stream(initial_input, thread_config, stream_mode="values"):
print(event)실행 결과:
{'input': 'hello world'}
---1단계---
{'input': 'hello world'}이 시점에서 그래프는 step_2에서 멈추게 되고, 상태를 확인할 수 있습니다.
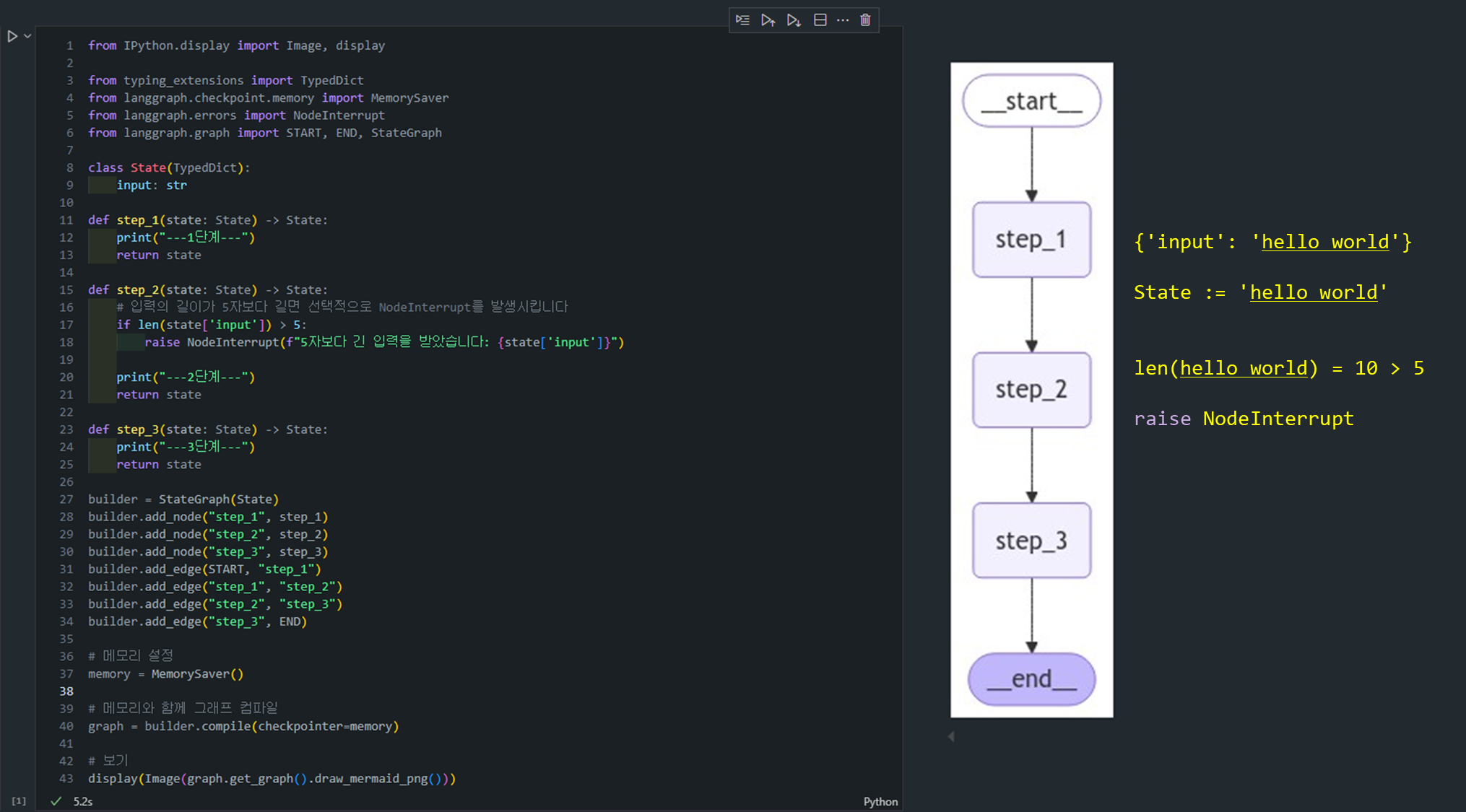
현재 상태를 조금 더 명확하게 설명하자면, NodeInterrupt가 발생했기 때문에 노드와 엣지 간의 정확한 위치를 구분하는 것이 중요합니다.
-
노드 위치 관점에서: 실행 흐름은
step_1을 완료하고step_2를 실행하는 도중에 중단되었습니다. 이는 아직step_2의 실행이 완료되지 않았음을 의미하므로, 현재는step_2에 도달한 상태입니다. -
엣지 위치 관점에서:
step_1에서step_2로의 전이가 이루어졌으나,step_2가 완료되지 않았으므로 1-2 엣지"에서step_2로 넘어가는 중에 멈춘 상태라고도 볼 수 있습니다.
3. 상태 확인 및 수정
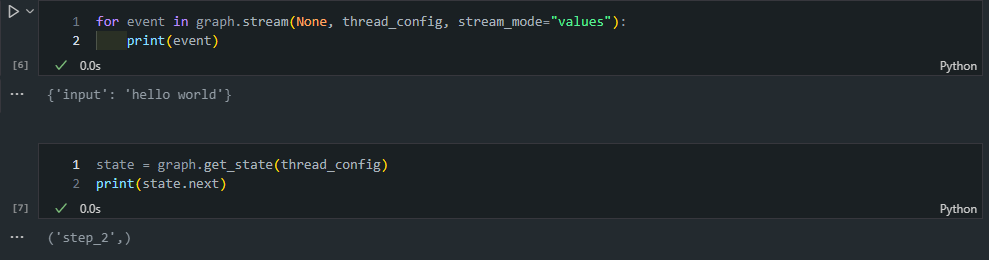
그래프가 중단된 상태에서 다음 실행할 노드가 step_2임을 확인합니다.
state = graph.get_state(thread_config)
print(state.next) # ('step_2',)그리고 중단점이 발생한 이유도 확인할 수 있습니다.
print(state.tasks)(PregelTask(id='ec5598b4-c9cc-ce9e-8387-5f27e35742a5', name='step_2', path=('__pregel_pull', 'step_2'), error=None, interrupts=(Interrupt(value='5자보다 긴 입력을 받았습니다: hello world', when='during'),), state=None),)4. 상태 업데이트 및 그래프 재실행
상태를 변경하지 않으면 같은 노드에서 계속 멈춰있게 됩니다.
상태를 "Hello"으로 변경하여 그래프를 재실행합니다. 변경 후에는 그래프의 끝까지 정상적으로 실행되는 것을 확인할 수 있습니다.
# 상태 업데이트: 입력을 "Hello"으로 변경
graph.update_state(
thread_config,
{"input": "Hello"},
)
# 그래프 재실행
for event in graph.stream(None, thread_config, stream_mode="values"):
print(event)업데이트 후 실행 결과:
{'input': 'Hello'}
---2단계---
{'input': 'Hello'}
---3단계---
{'input': 'Hello'}✨ 동적 중단점의 핵심 개념
1. 자동 중단점 설정: 그래프는 특정 조건(예: 입력 길이 초과)을 만족할 때 자동으로 멈추고, 중단점을 발생시킵니다.
2. 상태 확인 및 업데이트: 그래프가 중단되면 현재 상태를 확인하고, 필요시 상태를 업데이트할 수 있습니다.
3. 그래프 재실행: 상태가 업데이트된 후, 그래프는 중단된 시점부터 다시 실행됩니다.
4. 유연한 워크플로우 구성: 동적 중단점을 사용하면, 사용자의 승인, 디버깅, 상태 수정 등을 유연하게 처리할 수 있습니다.
Lesson 5: Time Travel
개요
Time Travel은 그래프의 이전 상태로 돌아가거나, 그 상태를 재생하여 과거의 실행 흐름을 살펴보고 문제를 분석하는 데 유용한 기능입니다.
- 이 기능은 그래프가 실행된 모든 상태를 기록하고, 그 중 어느 지점에서든 다시 시작할 수 있도록 해줍니다.
- Time Travel은
디버깅,성능 최적화,여러 경로 탐색등에 도움을 줍니다.- 재생(Replay)과 분기(Fork)의 두 가지 핵심 개념을 통해 그래프의 실행 흐름을 수정하거나 다양한 시나리오를 실험할 수 있습니다.
주요 개념
-
Replay(재생):
- 특정 체크포인트에서 그래프를 다시 재생하여 과거의 실행을 복원합니다.
- 그래프의 모든 상태가 저장되기 때문에 이전에 완료된 작업을 반복 실행할 필요 없이 그 상태를 그대로 재생할 수 있습니다.
- 이는 문제를 재현하거나 분석할 때 매우 유용합니다.
-
Fork(분기):
- 특정 체크포인트에서 상태를 수정하여 새로운 실행 흐름을 탐색할 수 있습니다.
- 이 기능은 그래프의 특정 지점에서 다른 경로로 진행하도록 상태를 업데이트한 후, 그 경로에 따른 실행 결과를 확인하는 방식으로 활용됩니다.
- Fork는 새로운 시나리오를 테스트하거나, 예상치 못한 입력에 따른 흐름을 실험할 때 유용합니다.
Time Travel의 주요 단계
0. Agent Define
- 이전과 마찬가지로 agent를 정의해보겠습니다. 계속해서 사용하던 agent이므로 자세한 설명은 생략하겠습니다.
from langchain_openai import ChatOpenAI
def multiply(a: int, b: int) -> int:
"""a와 b를 곱합니다.
인자:
a: 첫 번째 정수
b: 두 번째 정수
"""
return a * b
# 이것은 도구가 될 것입니다
def add(a: int, b: int) -> int:
"""a와 b를 더합니다.
인자:
a: 첫 번째 정수
b: 두 번째 정수
"""
return a + b
def divide(a: int, b: int) -> float:
"""a를 b로 나눕니다.
인자:
a: 첫 번째 정수
b: 두 번째 정수
"""
return a / b
tools = [add, multiply, divide]
llm = ChatOpenAI(model="gpt-4")
llm_with_tools = llm.bind_tools(tools)
from IPython.display import Image, display
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import MessagesState
from langgraph.graph import START, END, StateGraph
from langgraph.prebuilt import tools_condition, ToolNode
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
# 시스템 메시지
sys_msg = SystemMessage(content="당신은 일련의 입력에 대해 산술 연산을 수행하는 도움이 되는 어시스턴트입니다.")
# 노드
def assistant(state: MessagesState):
return {"messages": [llm_with_tools.invoke([sys_msg] + state["messages"])]}
# 그래프
builder = StateGraph(MessagesState)
# 노드 정의: 이들이 작업을 수행합니다
builder.add_node("assistant", assistant)
builder.add_node("tools", ToolNode(tools))
# 엣지 정의: 이들이 제어 흐름을 결정합니다
builder.add_edge(START, "assistant")
builder.add_conditional_edges(
"assistant",
# 어시스턴트의 최신 메시지(결과)가 도구 호출이면 -> tools_condition이 tools로 라우팅합니다
# 어시스턴트의 최신 메시지(결과)가 도구 호출이 아니면 -> tools_condition이 END로 라우팅합니다
tools_condition,
)
builder.add_edge("tools", "assistant")
memory = MemorySaver()
graph = builder.compile(checkpointer=MemorySaver())
# 표시
display(Image(graph.get_graph(xray=True).draw_mermaid_png()))
1. 현재 상태 조회
- LangGraph에서
get_state메서드를 호출하여 그래프의 현재 상태를 확인할 수 있습니다. 이는 현재 실행 중이거나 완료된 그래프의 상태를 가져옵니다.
state = graph.get_state({'configurable': {'thread_id': '1'}})
print(state)- 이를 통해 현재 그래프의 모든 메시지, 메타데이터, 체크포인트 ID 등을 확인할 수 있습니다.
2. 상태 히스토리 조회
get_state_history메서드를 사용하면 그래프 실행 동안 발생한 모든 상태의 히스토리를 조회할 수 있습니다. 이 히스토리는 각 단계에서 그래프가 어떤 상태를 가졌는지 보여줍니다.
history = graph.get_state_history(thread)
for state in history:
print(state)- 이 히스토리는 각 상태의 체크포인트를 기록하며, 개발자는 이 히스토리를 통해 이전 상태를 재생하거나 수정할 수 있습니다.
history = graph.get_state_history(thread)
for i, state in enumerate(history,1):
print(i)
print(state)
(참고) 중간 정리
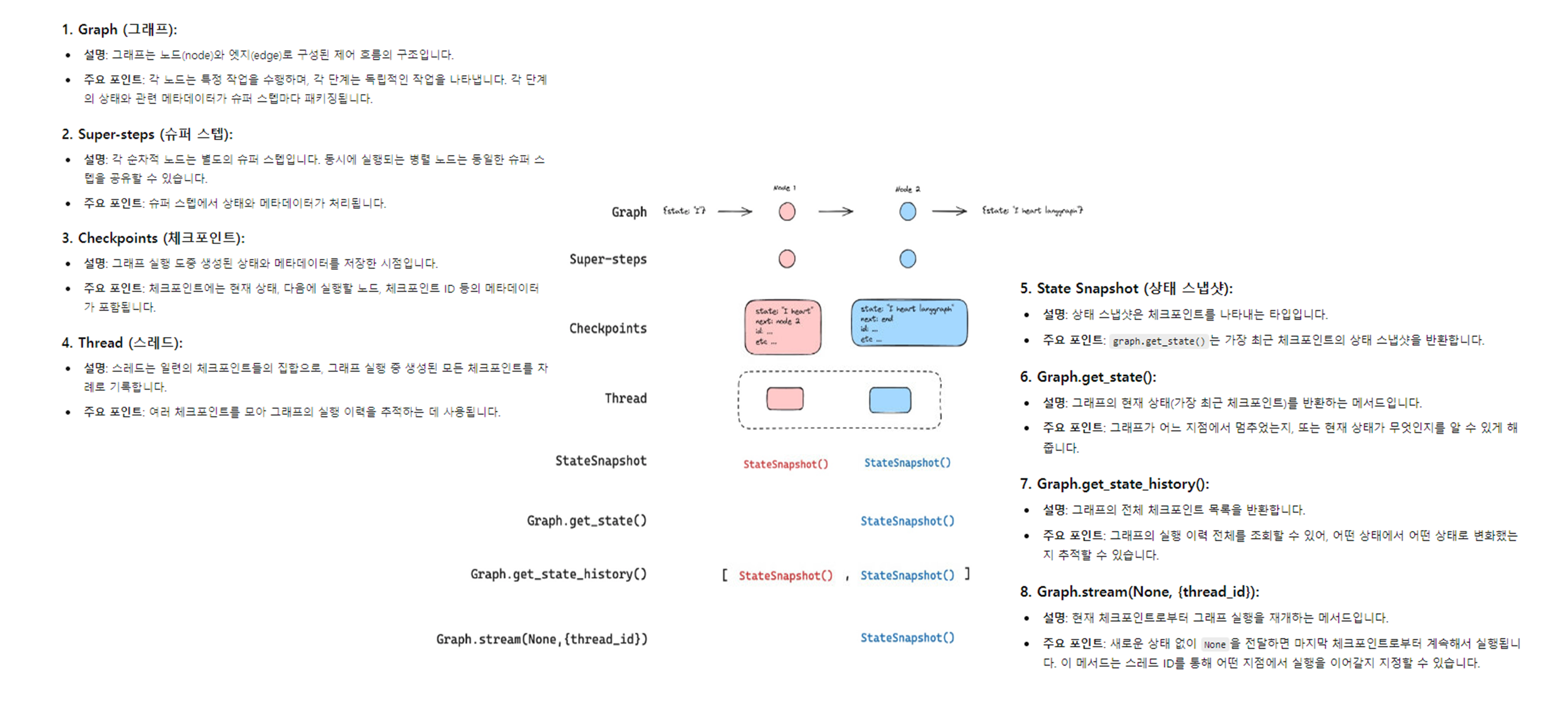
체크포인트는 여행 중 찍은 사진 한 장이고,스레드는 그 여행의 전체 사진 앨범이라고 할 수 있습니다.
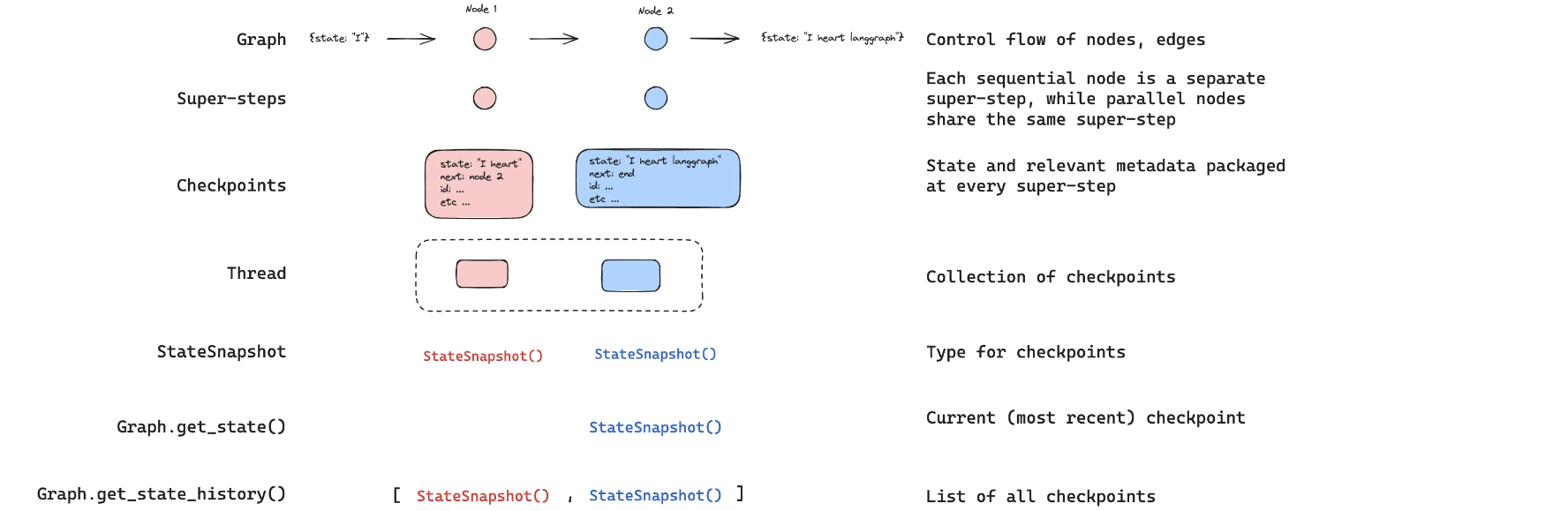
-
Graph: 그래프는
노드와엣지로 구성되어 있는컨트롤 플로우입니다.- 각 노드는 어시스턴트, 도구 사용 등의 특정 단계(상태, state)를 나타냅니다.
-
Checkpoints:
체크포인터(checkpointer)가 각노드의 상태를 체크포인트로 기록합니다.체크포인트에는 상태 정보와 함께 '다음에 어디로 갈지'와 같은 메타데이터도 포함됩니다.
-
Thread: 스레드(thread)는
체크포인트의 모음입니다. -
StateSnapshot: 상태 스냅샷(StateSnapshot)은
체크포인트의 데이터 타입니다. -
Graph.get_state():
현재(가장 최근의) 체크포인트를 반환하는 함수입니다. -
Graph.get_state_history():
모든 체크포인트의 리스트를 반환하여, 상태 변화의 히스토리를 제공합니다.
3. Replay (다시 재생)
Replay는 그래프 실행이 완료된 후, 특정 체크포인트에서 그래프를 다시 실행하지 않고 그 상태를 그대로 재생하는 기능입니다.- 이는 과거 상태에서 문제가 발생한 지점을 재현하거나, 분석을 위한 디버깅 목적으로 사용됩니다.
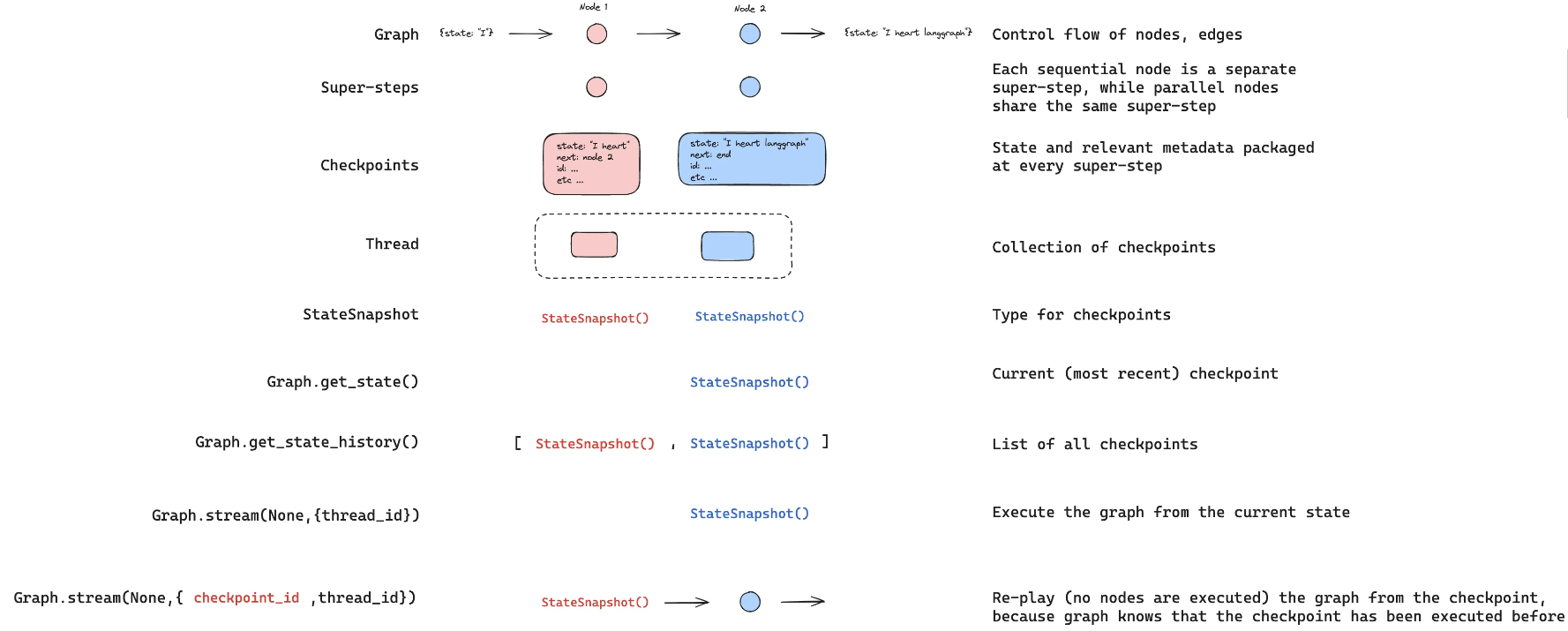
- Graph.stream(None,{thread_id}): 이 함수는
현재 상태에서 그래프를실행합니다.
- 결과값으로
StateSnapshot()을 반환합니다.
- Graph.stream(None,{checkpoint_id, thread_id}): 이 함수는 특정 체크포인트에서 그래프를
다시 실행(re-play)합니다.
- 주목할 점은
실제로 노드들이 실행되지 않는다는 것입니다.
# 특정 체크포인트 ID를 기반으로 재생
checkpoint_id = history[-2]['config']['checkpoint_id']
graph.stream(None, {'configurable': {'thread_id': '1', 'checkpoint_id': checkpoint_id}}, stream_mode="values")- Replay는 이미 실행된 체크포인트를 재생하기 때문에, 그래프의 노드를 다시 실행하지 않고 기록된 상태를 빠르게 복원할 수 있습니다.
4. Forking (분기)
Forking은 특정 체크포인트에서 상태를 수정하고 새로운 실행 흐름을 만드는 기능입니다.- 이를 통해 사용자는 그래프의 상태를 변경하여 다른 경로를 탐색하거나 실험할 수 있습니다.
- 예를 들어, 특정 단계에서 새로운 입력을 주어 다른 결과가 나오는지 확인할 수 있습니다.
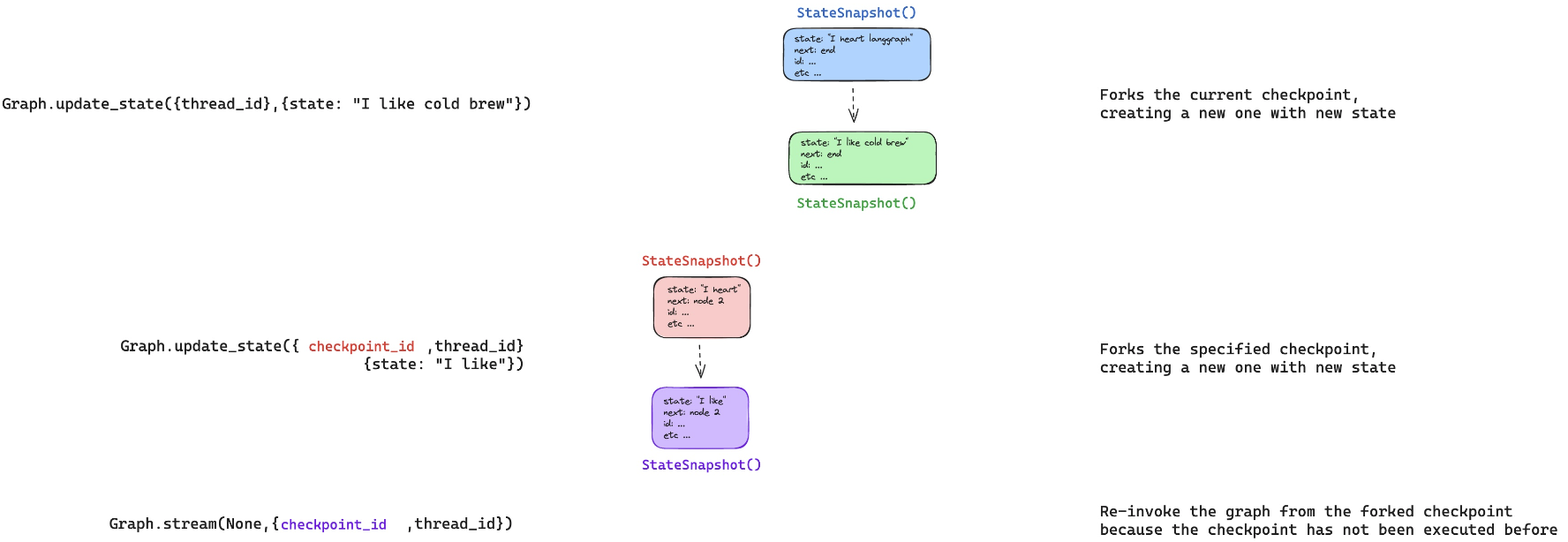
-
① 현재 상태에서 포킹
-
우리는 LangGraph의
Graph.update_state메서드를 사용하여 현재 상태를 포킹할 수 있습니다. -
예를 들어, 다음과 같은 코드를 통해 상태를 업데이트할 수 있습니다:
Graph.update_state({thread_id}, {state: "I like cold brew"}) -
위 코드를 실행하면 thread_id의 현재 그래프 상태가 업데이트되면서 새로운 체크포인트가 생성됩니다. 이를 "현재 상태에서 포킹"한다고 표현할 수 있습니다.
-
상태가 기록되고 새로운 체크포인트가 생성되면, 포크된 새로운 상태 스냅샷(StateSnapshot)이 만들어집니다.
-
위 그림의 첫번째 예시에서는 "
I heart Langchain" ⟶ "I like cold brew"라는 상태로 새로운 체크포인트가 만들어집니다.

-
-
② 과거 체크포인트에서 포킹
-
포킹의 또 다른 방식은 과거의 특정 체크포인트에서 새로운 상태를 포킹하는 것입니다.
-
이를 위해, 우리는 특정
checkpoint_id를 제공하여 그 시점의 상태를 기반으로 포크할 수 있습니다. -
예를 들어, 다음과 같은 코드로 특정 체크포인트에서 상태를 포킹할 수 있습니다:
Graph.update_state({checkpoint_id}, thread_id, {state: "I like"}) -
이 경우, 이전에 생성된 특정 체크포인트에서 상태가 업데이트되고 새로운 체크포인트가 생성됩니다.
-
과거의 상태를 기반으로 새로운 상태를 만들어 포크하는 과정이라고 할 수 있습니다.
-
이를 통해 특정 시점으로 돌아가 새로운 실행 흐름을 만들 수 있습니다.

-
💬 Re-play vs Re-Execute
- 재생(Replaying): 이미 실행된 체크포인트를 다시 실행할 때, 그래프는 그 상태가 이미 실행되었음을 인지하고 재생합니다. 즉, 같은 상태를 그대로 유지한 채 실행이 반복됩니다. 예를 들어, 이전에 실행된 상태 스냅샷을 전달하면, 그 상태에 따라 그래프가 이미 실행된 것처럼 동작하게 됩니다.
- 재실행(Re-executing): 반면, 새로운 체크포인트를 통해 그래프를 실행하면, 그래프는 이전에 이 상태가 실행된 적이 없다는 것을 인식하고 새롭게 실행을 시작합니다. 이를 재실행이라고 부릅니다. 포크된 체크포인트가 처음 실행되는 경우, 새로운 상태를 바탕으로 그래프가 다시 실행됩니다.
-
상태 덧붙임(Appending)과 덮어쓰기(Overwriting)
-
상태 업데이트 시 중요한 부분은 덧붙임(Appending)과 덮어쓰기(Overwriting)입니다.
-
예를 들어, 메시지와 같은 상태는 기본적으로 덧붙여지지만, 특정
id를 전달하면 해당 메시지가 덮어쓰기 됩니다. -
이는
add messages reducer와 같은 방식에서 발생합니다.📋 주의
messages에 대한 리듀서가 어떻게 작동하는지 기억하세요!- 메시지 ID를 제공하지 않으면 뒤에 추가(append)합니다.
- 상태에 추가하는 대신 메시지를 덮어쓰기(overwrite) 위해 메시지 ID를 제공해야합니다!
Graph.update_state({checkpoint_id}, thread_id, {state: "I like", id: "message_id"}) -
위 코드를 수행하면 새로운 메시지가 추가되지 않고 기존 메시지가 덮어씌워지며 업데이트됩니다.
-
메시지 상태를 어떻게 관리할지에 따라 덧붙일지 또는 덮어쓸지를 결정할 수 있습니다.
-
-
상태 히스토리 관리
-
각 상태 업데이트는 그래프의 히스토리에서 새로운 체크포인트를 생성합니다. 예를 들어, "I like cold brew"라는 상태를 업데이트하고 새로운 체크포인트가 생성되었다면, 이 체크포인트는 히스토리에 기록됩니다.
-
여러 번 상태를 업데이트하면, 각 상태는 고유한 체크포인트로 관리되고, 필요한 경우 과거의 특정 체크포인트로 돌아가 새로운 포크를 만들 수 있습니다.
-
히스토리에서 새로운 체크포인트를 추가하는 방식으로 상태를 관리할 수 있으며, 그래프의 각 스레드는 여러 체크포인트로 구성됩니다. 이렇게 하면 매우 유연하게 상태를 관리할 수 있습니다.
-
-
포크된 체크포인트로 재실행
-
포크된 체크포인트를 통해 그래프를 다시 실행할 때, LangGraph는 해당 체크포인트가 이전에 실행된 적이 없는지 확인하고 재실행합니다.
-
예를 들어, 새로운
checkpoint_id로 재실행을 하면, 과거 상태에서 새로운 실행 흐름이 시작됩니다. -
다음과 같이 새로운 포크된 체크포인트를 제공하여 재실행할 수 있습니다:
Graph.stream(None, {checkpoint_id}, thread_id) -
이 코드를 통해 포크된 체크포인트로 그래프가 재실행되고, 그에 따라 새로운 상태가 생성됩니다.
-
이 강의 내용은 Langraph의 다양한 기능과 Human-in-the-Loop의 활용 방안을 중심으로 구성되어 있으며, 각각의 기능은 실제 워크플로우에서 매우 유용하게 사용됩니다. 각 레슨의 세부 내용을 철저히 이해하면 Langraph를 이용한 고급 작업 흐름을 쉽게 구현할 수 있을 것입니다.
