[강의노트] LangChain Academy : Introduction to LangGraph (Module 4)

랭체인(LangChain)과 랭그래프(LangGraph)는 대규모 언어 모델(LLM)을 활용한 애플리케이션 개발을 위한 도구들입니다. 위 강의는 LangChain에서 운영하는 LangChain Academy에서 제작한 "Introduction to LangGraph" 강의의 내용을 정리 및 추가 설명한 내용입니다.
- 강의 링크 : https://youtu.be/29XE10U6ooc
- 랭체인 : https://www.langchain.com/
이번 포스트는 "Module4"내용을 다룹니다:
- Lesson 1: Parallelization
- Lesson 2: Sub-graphs
- Lesson 3: Map-reduce
- Lesson 4: Research Assistant
Lesson 1: Parallelization
개요
- 병렬화(Parallelization)는 작업을 여러 개의 노드로 나누어 동시에 처리하여 성능을 높이는 방법입니다.
- 그러나 병렬로 실행된 노드들이 동일한 상태 키를 업데이트할 때 상태 충돌이 발생할 수 있으므로, 이를 해결하기 위해 리듀서(Reducer)를 사용하여 결과를 안전하게 병합할 수 있습니다.
주요 개념
- 병렬화 개념
팬아웃(fan-out): 한 노드에서 여러 노드로 작업이 확장되는 과정입니다.- 예를 들어, 노드 A에서 B와 C를 동시에 실행하는 것을
팬아웃이라고 할 수 있습니다.
- 예를 들어, 노드 A에서 B와 C를 동시에 실행하는 것을
팬인(fan-in): 여러 병렬 작업이 모두 완료된 후 하나의 노드로 다시 합쳐지는 과정입니다.- 예를 들어, B와 C의 작업이 완료되면 D 노드로 합쳐지는 것이
팬인입니다.
- 예를 들어, B와 C의 작업이 완료되면 D 노드로 합쳐지는 것이
-
병렬 노드 실행:
- 작업을 여러 노드로 분배하여 동시에 실행하는 작업을 의미합니다.
- 여러 노드가 동시에 실행될 때 상태를 안전하게 업데이트하기 위한 조치가 필요합니다.
-
리듀서(Reducer):
- 병렬로 실행된 노드가 동일한 상태 키를 업데이트할 때 이를 병합하는 역할을 의미합니다.
- 병렬 노드가 상태 키에 추가하는 데이터를 리스트로 병합하는 등의 작업을 수행합니다.
코드 예시
- 기본적인 병렬화 처리 예시:
- 기본적으로 직렬 실행되는 그래프에서 A, B, C, D 순서대로 노드가 실행됩니다.
- 아래 그래프는 각 단계에서 상태를 덮어쓰는 간단한 선형 그래프입니다.
from IPython.display import Image, display
from typing import Any
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
class State(TypedDict):
# operator.add 리듀서 함수는 이것을 추가 전용으로 만듭니다
state: str
class ReturnNodeValue:
def __init__(self, node_secret: str):
self._value = node_secret
def __call__(self, state: State) -> Any:
print(f"{self._value}를 {state['state']}에 추가합니다")
return {"state": [self._value]}
# 노드 추가
builder = StateGraph(State)
# 각 노드를 node_secret으로 초기화
builder.add_node("a", ReturnNodeValue("나는 A입니다"))
builder.add_node("b", ReturnNodeValue("나는 B입니다"))
builder.add_node("c", ReturnNodeValue("나는 C입니다"))
builder.add_node("d", ReturnNodeValue("나는 D입니다"))
# 흐름
builder.add_edge(START, "a")
builder.add_edge("a", "b")
builder.add_edge("b", "c")
builder.add_edge("c", "d")
builder.add_edge("d", END)
graph = builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))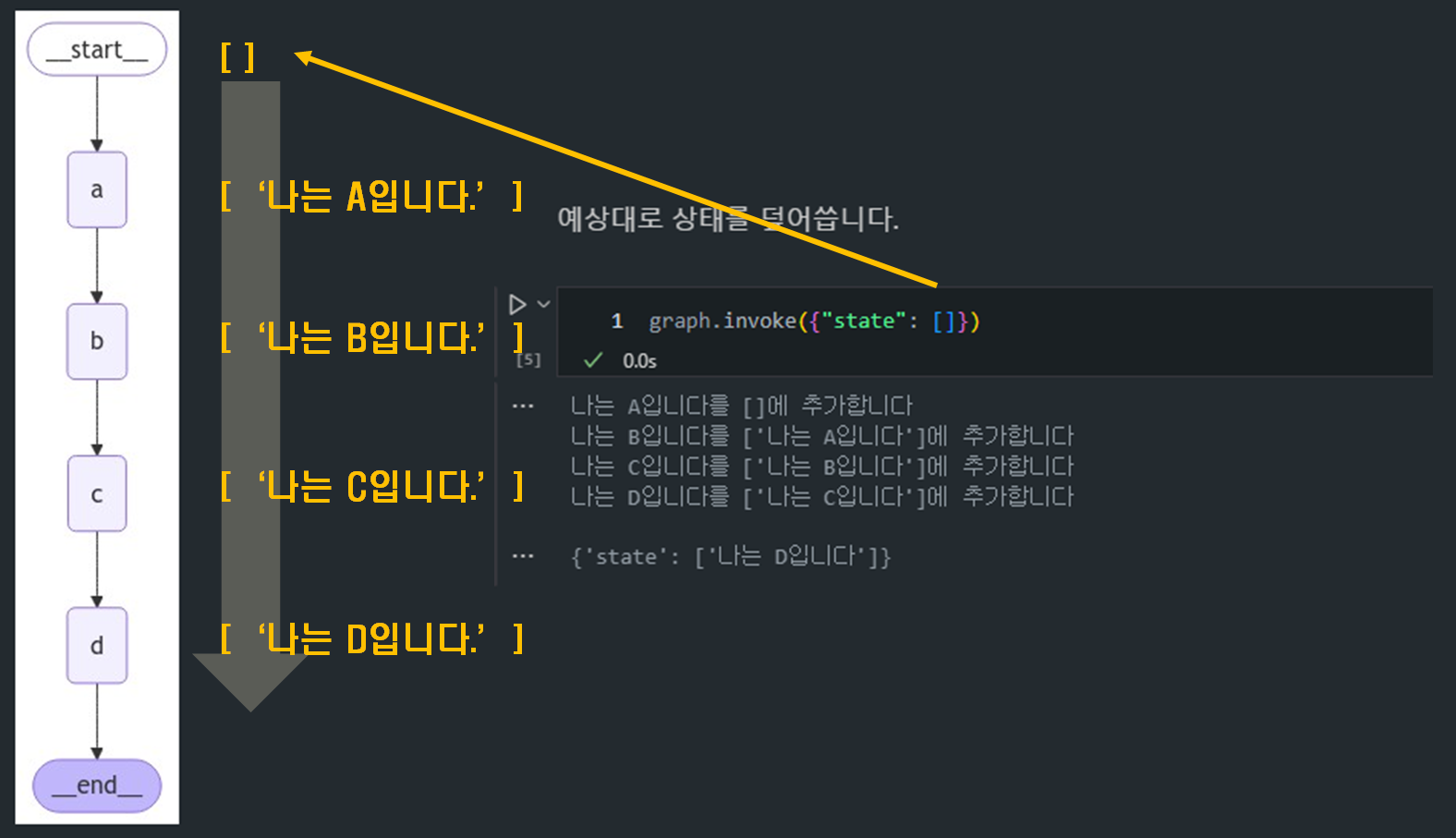
- 병렬화 처리:
- 이제 A에서 B와 C가 병렬로 실행되도록 팬아웃 구조를 설계합니다.
builder = StateGraph(State)
# 각 노드를 node_secret으로 초기화
builder.add_node("a", ReturnNodeValue("나는 A입니다"))
builder.add_node("b", ReturnNodeValue("나는 B입니다"))
builder.add_node("c", ReturnNodeValue("나는 C입니다"))
builder.add_node("d", ReturnNodeValue("나는 D입니다"))
# 흐름
builder.add_edge(START, "a")
builder.add_edge("a", "b")
builder.add_edge("a", "c")
builder.add_edge("b", "d")
builder.add_edge("c", "d")
builder.add_edge("d", END)
graph = builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))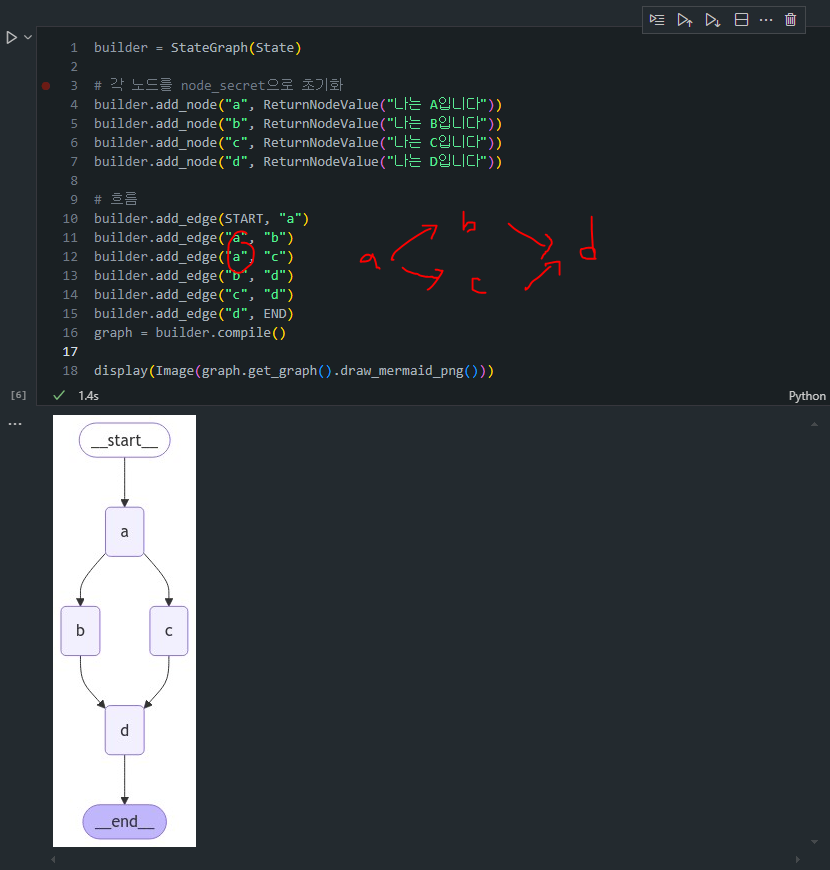
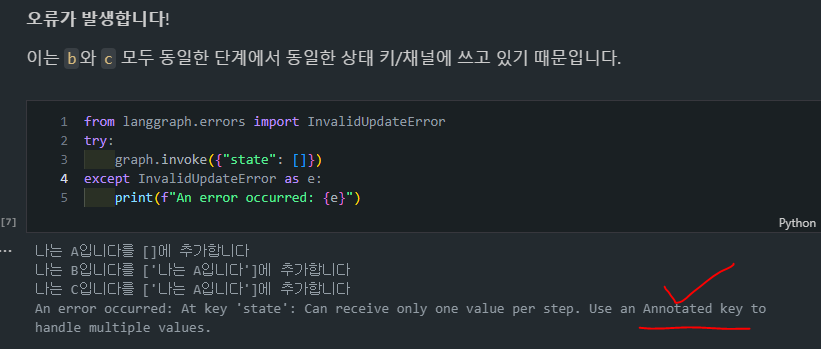
- 에러 발생
- 구조는 위와 같이 쉽게 정의할 수 있지만, 막상 실행해보면, B와 C가
동시에 동일한 상태 키를 업데이트하려 하므로 충돌이 발생하여 에러가 발생하게 됩니다.
- 리듀서를 통한 충돌 해결:
- 병렬 노드 B와 C가 동시에 리스트에 값을 추가하도록 리듀서를 사용하여 상태 충돌을 해결합니다.
- 팬 아웃을 사용할 때는 단계가 동일한 채널/키에 쓰는 경우 리듀서를 사용해야 합니다.
- 모듈 2에서 언급했듯이
operator.add는 Python의 내장 operator 모듈의 함수입니다. operator.add가 리스트에 적용되면 리스트 연결을 수행합니다.
import operator
from typing import Annotated
class State(TypedDict):
# operator.add 리듀서 함수는 이것을 추가 전용으로 만듭니다
state: Annotated[list, operator.add]
# 노드 추가
builder = StateGraph(State)
# 각 노드를 node_secret으로 초기화
builder.add_node("a", ReturnNodeValue("나는 A입니다"))
builder.add_node("b", ReturnNodeValue("나는 B입니다"))
builder.add_node("c", ReturnNodeValue("나는 C입니다"))
builder.add_node("d", ReturnNodeValue("나는 D입니다"))
# 흐름
builder.add_edge(START, "a")
builder.add_edge("a", "b")
builder.add_edge("a", "c")
builder.add_edge("b", "d")
builder.add_edge("c", "d")
builder.add_edge("d", END)
graph = builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))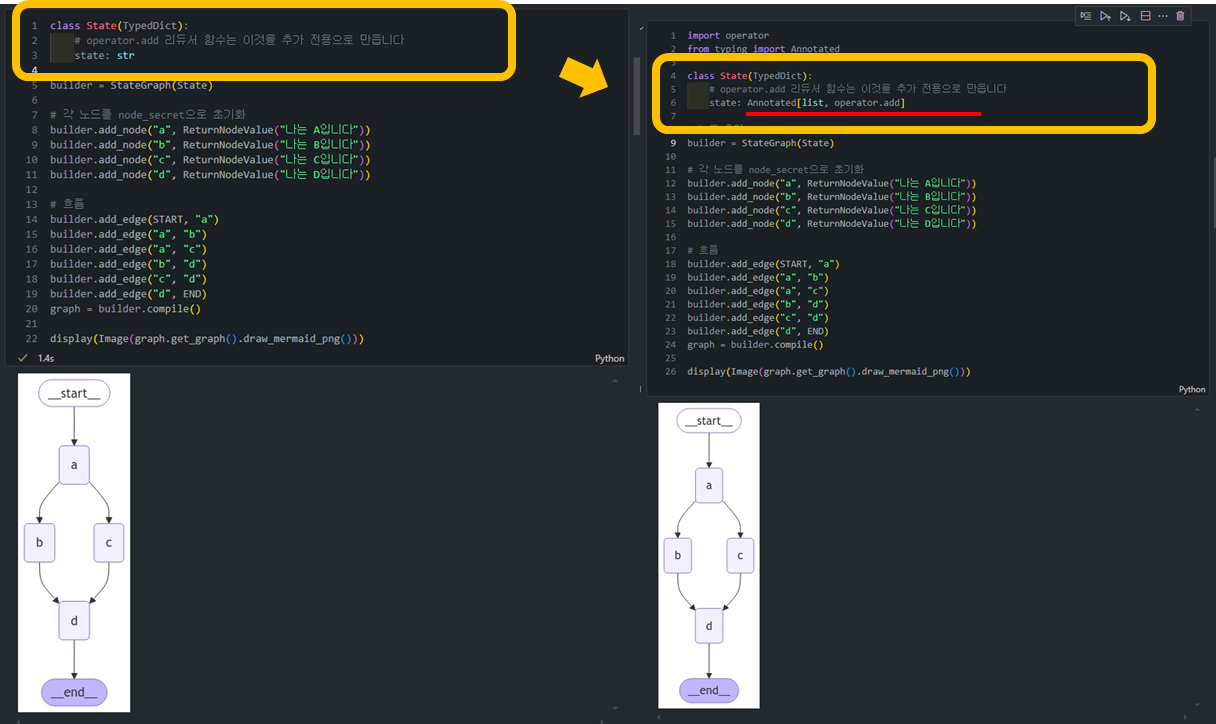
graph.invoke({"state": []})- 위와 같이 그래프를 수행하면 의도한 것처럼 끝까지 실행되는 것을 확인할 수 있습니다.
나는 A입니다를 []에 추가합니다
나는 B입니다를 ['나는 A입니다']에 추가합니다
나는 C입니다를 ['나는 A입니다']에 추가합니다
나는 D입니다를 ['나는 A입니다', '나는 B입니다', '나는 C입니다']에 추가합니다
{'state': ['나는 A입니다', '나는 B입니다', '나는 C입니다', '나는 D입니다']}- 이제
b와c가 병렬로 수행한 업데이트가 상태에 추가되는 것을 볼 수 있습니다.
- 추가 실습
- 좀 더 복잡한 병렬 그래프에서도 제대로 작동하는 것을 확인할 수 있습니다.
- 이 경우
b,b2,c는 모두 동일한 단계의 일부입니다. - 그래프는
d단계로 진행하기 전에 이 모든 것들이 완료될 때까지 기다립니다.
class State(TypedDict):
# operator.add 리듀서 함수는 이것을 추가 전용으로 만듭니다
state: Annotated[list, operator.add]
# Add nodes
builder = StateGraph(State)
# Initialize each node with node_secret
builder.add_node("a", ReturnNodeValue("I'm A"))
builder.add_node("b", ReturnNodeValue("I'm B"))
builder.add_node("b2", ReturnNodeValue("I'm B2"))
builder.add_node("c", ReturnNodeValue("I'm C"))
builder.add_node("d", ReturnNodeValue("I'm D"))
# Flow
builder.add_edge(START, "a")
builder.add_edge("a", "b")
builder.add_edge("a", "c")
builder.add_edge("b", "b2")
builder.add_edge(["b2", "c"], "d")
builder.add_edge("d", END)
graph = builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))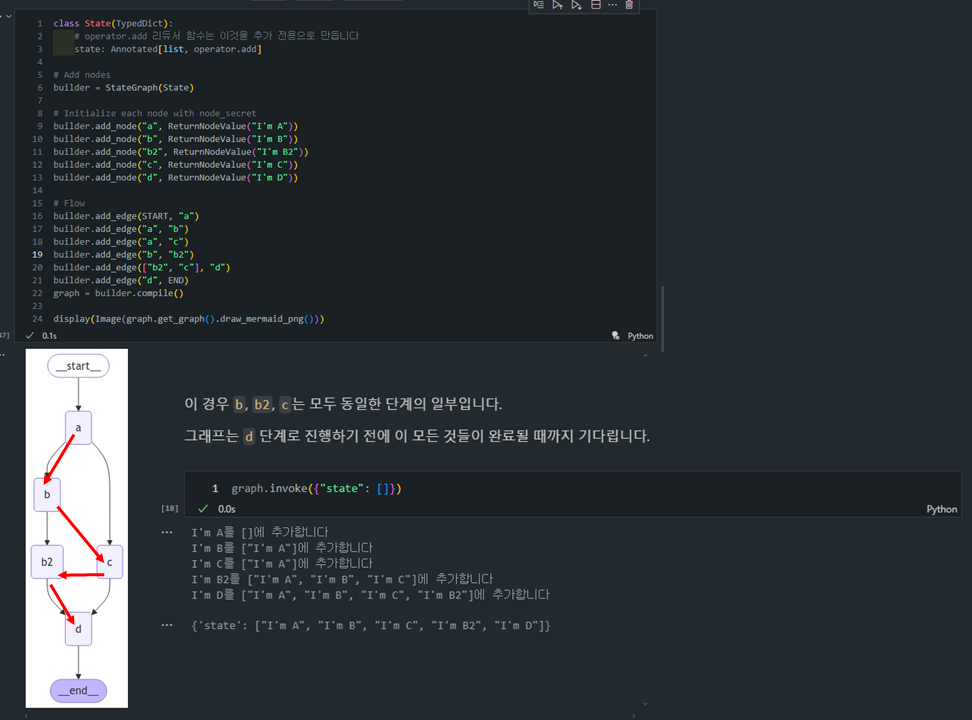
b와c는 병렬로 실행이 되기때문에 먼저 실행이 되고,.addoperator로 인해서 append된 순서대로 출력이 되는 것을 확인할 수 있습니다.
{'state': ["I'm A", "I'm B", "I'm C", "I'm B2", "I'm D"]}- 그래프 병렬화 순서 제어
-
기본적으로
LangGraph는 병렬로 실행되는 노드들의 업데이트 순서를자동으로 결정합니다. -
위에 4번 예제에서도 이는 우리가 제어하지 않는 그래프 토폴로지에 기반하여 LangGraph가 결정론적 순서를 정해준 것을 확인할 수 있습니다.
- 위에서 우리는
c가b2전에 추가되는 것을 볼 수 있습니다. - 하지만, 만약 사용자가
특정 순서로 결과를 처리하고 싶다면, 커스텀 리듀서(Custom Reducer)를 정의하여 이 순서를 직접 제어할 수 있습니다.
- 위에서 우리는
def sorting_reducer(left, right):
""" 리스트의 값들을 결합하고 정렬합니다"""
if not isinstance(left, list):
left = [left]
if not isinstance(right, list):
right = [right]
return sorted(left + right, reverse=False)
class State(TypedDict):
# sorting_reducer는 상태의 값들을 정렬합니다
state: Annotated[list, sorting_reducer]
# 노드 추가
builder = StateGraph(State)
# 각 노드를 node_secret으로 초기화
builder.add_node("a", ReturnNodeValue("나는 A입니다"))
builder.add_node("b", ReturnNodeValue("나는 B입니다"))
builder.add_node("b2", ReturnNodeValue("나는 B2입니다"))
builder.add_node("c", ReturnNodeValue("나는 C입니다"))
builder.add_node("d", ReturnNodeValue("나는 D입니다"))
# 흐름
builder.add_edge(START, "a")
builder.add_edge("a", "b")
builder.add_edge("a", "c")
builder.add_edge("b", "b2")
builder.add_edge(["b2", "c"], "d")
builder.add_edge("d", END)
graph = builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))- 이제 리듀서가 업데이트된 상태 값을 정렬하는 것을 확인할 수 있습니다.
{'state': ["I'm A", "I'm B", "I'm B2", "I'm C", "I'm D"]}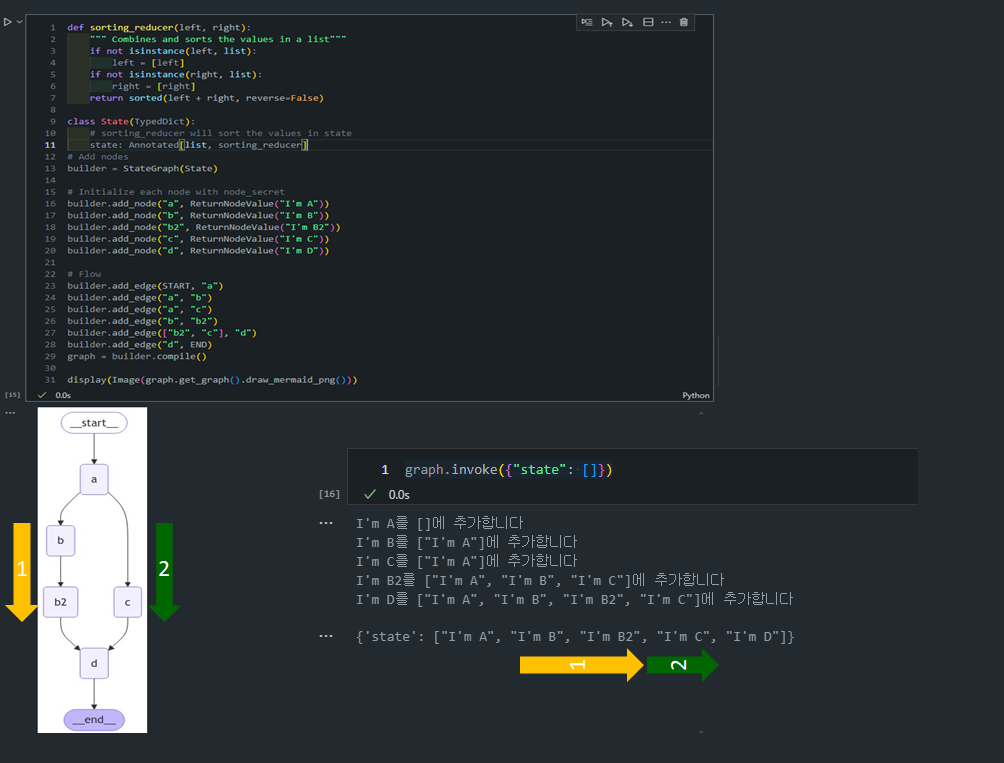
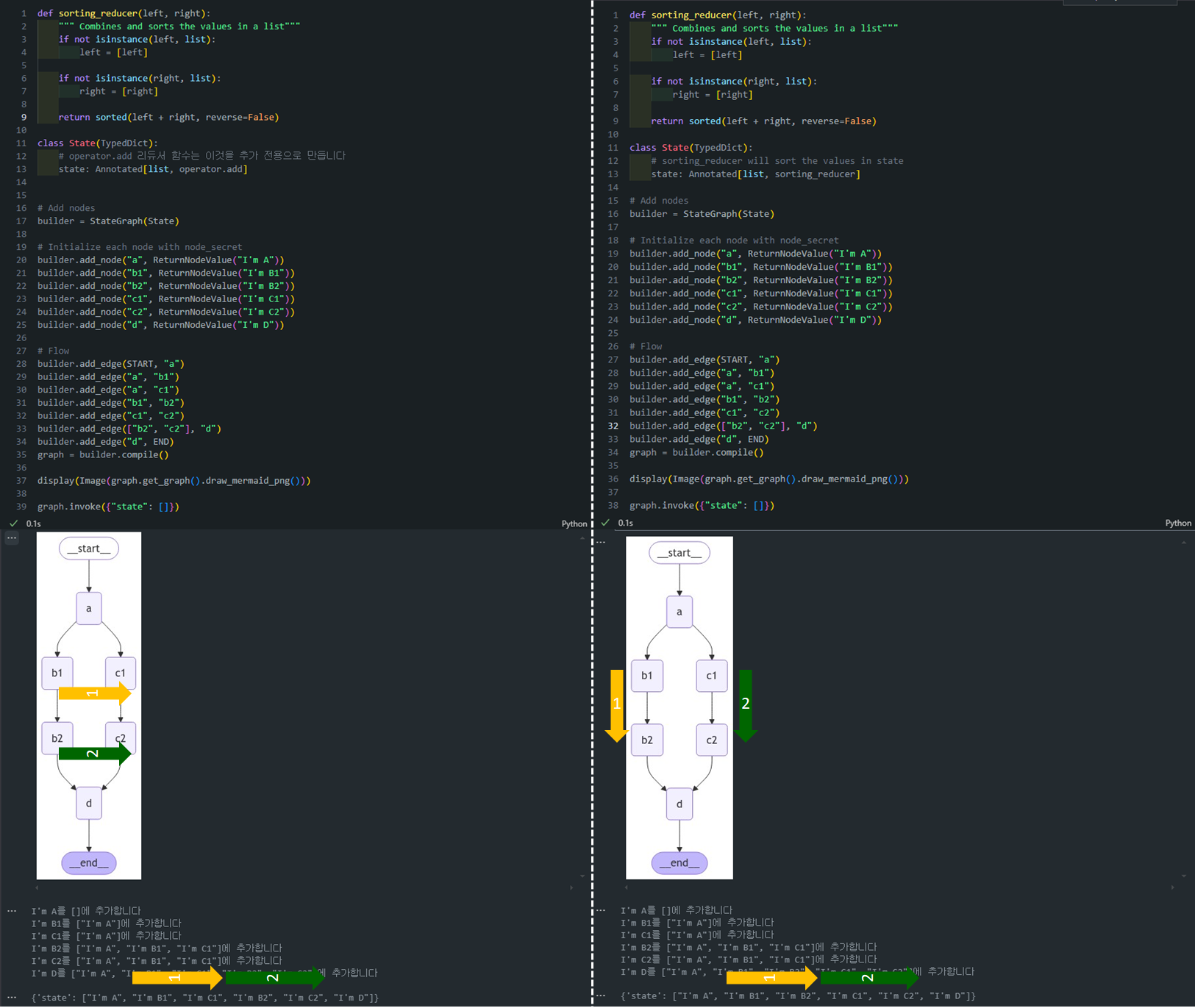
- (응용) 그래프 병렬화 순서 제어
- 좀 더 어려운(?) 모양으로 그래프를 만들고 한번 더 실습을 해보겠습니다.
1) 기존 operator.add 리듀서 사용한 경우:
class State(TypedDict):
# operator.add 리듀서 함수는 이것을 추가 전용으로 만듭니다
state: Annotated[list, operator.add]-
이 방식에서는 노드가 순차적으로 값을 추가하는 방식입니다.
-
각 노드에서 생성된 값은 순서대로 상태 리스트에 추가됩니다.
-
"b1"과"c1"이 병렬로 실행되고, 그 후에"b2"와"c2"가 실행되어 그 결과들이 합쳐진 다음"d"로 이동합니다. -
이때는 약간의 DFS처럼 동작합니다. 즉, 한 경로를 따라 끝까지 실행한 다음, 다른 경로를 따라갑니다.
-
따라서 출력은
"I'm A", "I'm B1", "I'm C1", "I'm B2", "I'm C2", "I'm D"와 같이 나타납니다. -
아래 흐름을 살펴보면:
a실행 후b1과c1병렬로 실행.b1가 실행되고 나서b2로 이동.c1이 실행되고 나서c2로 이동.b2와c2가 병렬로 실행되고 그 후d로 이동.
-
결과:
{'state': ["I'm A", "I'm B1", "I'm C1", "I'm B2", "I'm C2", "I'm D"]} -
이것은 마치 DFS에서 한 경로를 쭉 따라가면서 실행하고, 그 후 다른 경로로 진행하는 흐름과 유사합니다.
2) sorting_reducer를 사용한 경우:
def sorting_reducer(left, right):
"""Combines and sorts the values in a list"""
if not isinstance(left, list):
left = [left]
if not isinstance(right, list):
right = [right]
return sorted(left + right, reverse=False)
class State(TypedDict):
# sorting_reducer will sort the values in state
state: Annotated[list, sorting_reducer]-
sorting_reducer를 사용하면, 병렬로 실행된 노드들의 값이 정렬되어 상태 리스트에 추가됩니다. -
이 방식은 BFS처럼 작동합니다. 즉, 동일한 레벨에 있는 노드들이 병렬로 실행되고, 그 후에 다음 레벨로 진행됩니다.
-
"b1"과"c1"이 병렬로 실행된 후,"b2"와"c2"가 병렬로 실행됩니다. -
상태에 추가될 때는 알파벳 순서대로 정렬되기 때문에
"I'm B1","I'm B2","I'm C1","I'm C2"의 순서로 정렬됩니다. -
아래 흐름을 살펴보면:
a실행 후b1과c1이 병렬로 실행.b1과c1의 결과가 병합되고,b2와c2가 병렬로 실행.b2와c2의 결과가 병합되고 정렬됨.- 그 후
d가 실행됨.
-
결과:
{'state': ["I'm A", "I'm B1", "I'm B2", "I'm C1", "I'm C2", "I'm D"]} -
이는 마치 BFS에서 한 레벨의 노드를 모두 실행한 후 다음 레벨로 넘어가는 방식과 유사합니다. 병렬로 실행된 노드들이 항상 정렬된 형태로 상태에 저장됩니다.
- (심화) 정보 검색 그래프 구현
-
여기서 두 개의 검색 작업을 병렬로 실행하는 그래프를 정의합니다:
- 웹 검색(Web Search): 질문을 기반으로 웹에서 관련 문서를 검색합니다.
- 위키피디아 검색(Wikipedia Search): 질문을 기반으로 위키피디아에서 정보를 검색합니다.
-
두 검색 결과는 모두 context라는 상태 키에 저장됩니다.
-
아래 코드는
웹 검색과위키피디아 검색을 병렬로 실행한 후, 검색 결과를 통합하여 LLM을 통해 질문에 대한 답변을 생성하는 과정을 보여줍니다.
0) Import Libraries
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_community.document_loaders import WikipediaLoader
from langchain_community.tools.tavily_search import TavilySearchResults1) search_web 함수
def search_web(state):
""" 웹 검색에서 문서 검색 """
# 검색
tavily_search = TavilySearchResults(max_results=3)
search_docs = tavily_search.invoke(state['question'])
# 형식 지정
formatted_search_docs = "\n\n---\n\n".join(
[
f'<Document href="{doc["url"]}"/>\n{doc["content"]}\n</Document>'
for doc in search_docs
]
)
return {"context": [formatted_search_docs]} -
역할:
search_web함수는 사용자의 질문을 받아서 웹에서 문서를 검색합니다.- 여기서는 TavilySearchResults를 사용하여 최대 3개의 문서를 검색하고, 그 결과를 포맷팅하여 반환합니다.
-
tavily_search.invoke: 질문을 입력받아 웹 검색을 수행하고 결과 문서들을 반환합니다. -
리스트 컴프리헨션: 검색 결과는 HTML 형식의 태그로 지정되며, 각 문서는
<Document>태그로 감싸져 있습니다.search_docs리스트의 각 요소doc에 대해 반복합니다.- 각
doc는 딕셔너리로,url과content키를 가집니다. - 각
doc를<Document>태그로 감싸고,href속성에url값을, 태그 안에content값을 넣습니다. - 이 과정을 통해 각 doc를 문자열로 변환합니다.
-
문자열 결합: 리스트 컴프리헨션을 통해 생성된 문자열 리스트를
"\n\n---\n\n"문자열로 결합합니다.- 이 결합 문자열은 각 문서 사이에 구분선을 추가하는 역할을 합니다.
-
출력: 포맷팅된 문서 리스트(
formatted_search_docs)는context에 저장되어 반환됩니다.
2) search_wikipedia 함수
def search_wikipedia(state):
""" 위키피디아에서 문서 검색 """
# 검색
search_docs = WikipediaLoader(query=state['question'],
load_max_docs=2).load()
# 형식 지정
formatted_search_docs = "\n\n---\n\n".join(
[
f'<Document source="{doc.metadata["source"]}" page="{doc.metadata.get("page", "")}"/>\n{doc.page_content}\n</Document>'
for doc in search_docs
]
)
return {"context": [formatted_search_docs]} -
역할:
search_wikipedia함수는 사용자의 질문을 받아서 위키피디아에서 관련 문서를 검색합니다. -
WikipediaLoader: 주어진 질문을 사용하여 위키피디아에서 최대 2개의 문서를 로드합니다. -
형식 지정: 검색 결과는
<Document>태그로 포맷팅되어 문서의 출처와 페이지 정보를 포함합니다.formatted_search_docs변수는 리스트 컴프리헨션을 사용하여 각 문서를 특정 XML 형식으로 변환한 문자열들을 결합한 결과입니다.- 각 문서는
<Document>태그로 감싸져 있으며, 문서의 출처와 페이지 정보가 포함됩니다. 이 정보는doc.metadata딕셔너리에서 가져옵니다. - 문서의 실제 내용은
doc.page_content에서 가져옵니다.
-
출력: 포맷팅된 위키피디아 문서 리스트가
context에 저장되어 반환됩니다.
3) generate_answer 함수
def generate_answer(state):
""" 질문에 답변하는 노드 """
# 상태 가져오기
context = state["context"]
question = state["question"]
# 템플릿
answer_template = """이 맥락을 사용하여 {question} 질문에 답하세요: {context}"""
answer_instructions = answer_template.format(question=question,
context=context)
# 답변
answer = llm.invoke([SystemMessage(content=answer_instructions)]+[HumanMessage(content=f"질문에 답하세요.")])
# 상태에 추가
return {"answer": answer}-
역할:
generate_answer함수는웹 검색및위키피디아 검색결과를 사용하여 사용자의 질문에 답변을 생성합니다. -
템플릿: 검색된 컨텍스트와 질문을 결합하여 LLM(Large Language Model)에 전달할 텍스트를 생성합니다.
-
LLM 사용: 생성된 템플릿을
SystemMessage와HumanMessage로 LLM에 전달하여 답변을 생성합니다. -
출력: 생성된 답변은 상태에 추가되어 반환됩니다.
4) 그래프 노드 추가 및 흐름 설정
# 노드 추가
builder = StateGraph(State)
# 각 노드를 node_secret으로 초기화
builder.add_node("search_web",search_web)
builder.add_node("search_wikipedia", search_wikipedia)
builder.add_node("generate_answer", generate_answer)
# 흐름
builder.add_edge(START, "search_wikipedia")
builder.add_edge(START, "search_web")
builder.add_edge("search_wikipedia", "generate_answer")
builder.add_edge("search_web", "generate_answer")
builder.add_edge("generate_answer", END)
graph = builder.compile()
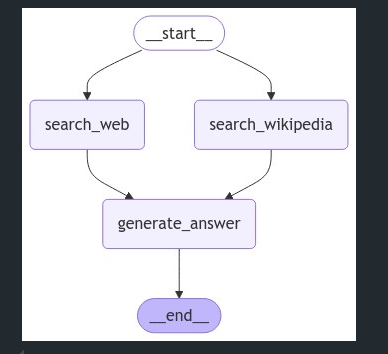
display(Image(graph.get_graph().draw_mermaid_png()))-
흐름: 이 그래프는 병렬로 검색 작업을 처리하고, 그 후 검색 결과를 이용하여 답변을 생성합니다.
-
실행 흐름 설명:
- 사용자가 질문을 입력하면, 위키피디아와 웹 검색이 동시에 실행됩니다.
- 검색된 문서들이 각각 포맷팅되어
context상태에 저장됩니다. - 그 후, 두 검색의 결과가 병합되어
generate_answer노드에서 LLM을 통해 답변이 생성됩니다.
-
결과적으로, 검색된 문서들을 바탕으로 질문에 대한 최종 답변을 생성하는 시스템입니다.
5) 질문 입력
- 아래와 같이 질문을 입력하면 TAVILY와 WIKIPEDIA SEARCH를 통해서 질문에 대한 답변을 수행합니다.
result = graph.invoke({"question": "LG전자의 2024년 3분기 실적은 어땠나요?"})
print(result['answer'].content)- 아래는 위 질문에 대한 답변 예시입니다:
LG전자의 2024년 3분기 실적은 다음과 같습니다:
- 매출: 22조1769억원, 전년 동기 대비 10.7% 증가
- 영업이익: 7511억원, 전년 동기 대비 20.9% 감소
매출은 3분기 최대치를 기록했으며, 이는 가전제품과 전장 부문의 지속적인 성장 덕분입니다. 그러나 영업이익은 물류비 급등 및 마케팅비 증가로 인해 감소했습니다.Lesson 2: Sub-graphs
개요
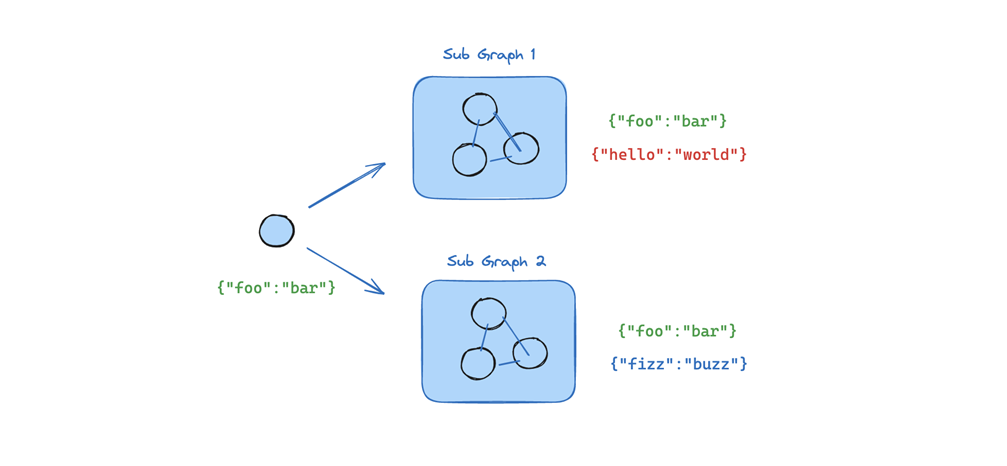
서브그래프(Sub-graph)는 큰 그래프의 일부분으로, 독립적으로 관리할 수 있는 작업 단위입니다.
-
서브그래프는 상태 키를 공유하거나 독립적으로 관리할 수 있으며, 멀티 에이전트 시스템에서 각 에이전트가 독립적인 작업을 수행하면서도 부모 그래프와 상호작용할 수 있습니다.
-
간단한 예를 살펴봅시다:
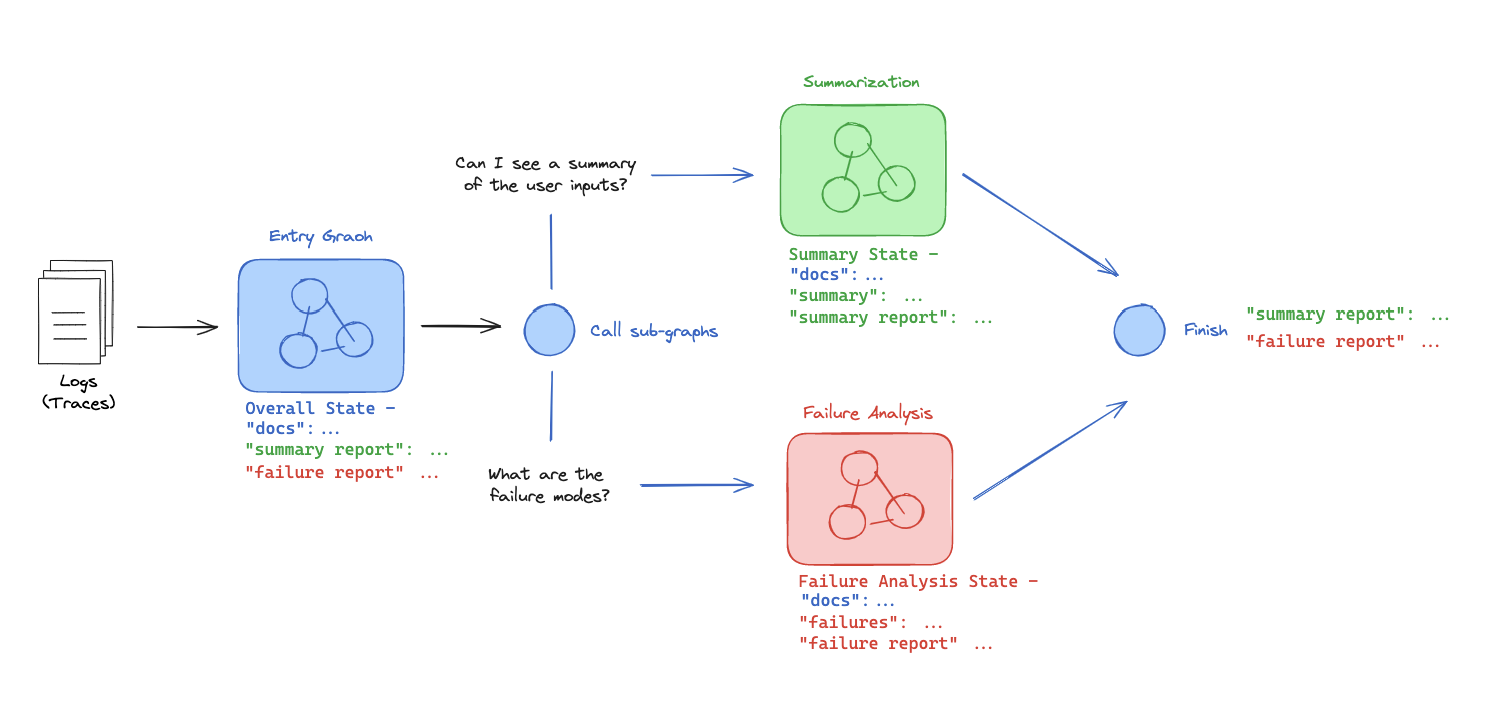
- 로그를 받는 시스템이 있습니다
- 이 시스템은 서로 다른 각각의 에이전트(Summary Agent, Failure Analysis Agent)에 의해 두 가지 별도의 하위 작업을 수행합니다(문서요약, 오류분석)
- 이 두 가지 작업을 두 개의 다른 서브 그래프에서 수행하고 싶습니다.
-
여기서 중요한 것은 그래프들이 "어떻게 통신을 할까"라는 것입니다.
-
간단히 말해, 통신은 겹치는 키를 통해 이루어집니다:
- 서브 그래프는 부모로부터 docs에 접근할 수 있습니다
- 부모는 서브 그래프로부터 Summary Agent 또는 Failure Analysis Agent에 접근할 수 있습니다
주요 개념
-
서브 그래프와 부모 그래프 간의 상태 공유:
서브 그래프와부모 그래프간에 데이터를 교환하기 위해 상태 키가 중복될 수 있습니다.- 특정 상태는 서브그래프 내에서만 관리되며 부모 그래프에는 영향을 주지 않습니다.
-
출력 스키마:
- 서브 그래프의 출력 상태를 제한하여 불필요한 상태 키를 부모 그래프에 반환하지 않도록 합니다.
코드 예시
- 이번 코드 실습은 두 개의 서브-그래프(
Failure Analysis 서브-그래프와Question Summarization 서브-그래프)를 부모 그래프(EntryGraph)로 통합하여, 주어진 로그 데이터를 처리하고 분석하는 시스템을 구현한 예제입니다.- 이 시스템은 병렬로 두 개의 서브그래프를 실행한 후, 각각의 결과를 종합하여
최종 보고서와요약을 생성합니다.
- 이 시스템은 병렬로 두 개의 서브그래프를 실행한 후, 각각의 결과를 종합하여
# 필요 라이브러리 임포트
from operator import add
from typing_extensions import TypedDict
from typing import List, Optional, Annotated1. 로그 구조 정의:
- 먼저,
Log클래스는 로그 데이터를 관리하는 데 사용됩니다. 각 로그는 질문과 답변, 평가 정보 및 피드백을 포함합니다.
class Log(TypedDict):
id: str
question: str
docs: Optional[List]
answer: str
grade: Optional[int]
grader: Optional[str]
feedback: Optional[str]
- id: 로그의 고유 식별자.
- question: 사용자의 질문.
- docs: 질문에 대해 검색된 문서들.
- answer: 제공된 답변.
- grade: 로그의 평가 (예: 품질 점수).
- grader: 평가자 정보.
- feedback: 평가와 관련된 피드백.
2. Failure Analysis 서브그래프:
Failure Analysis서브그래프의 목표는 실패한 로그를 식별하고, 그 결과를 요약하는 것입니다.
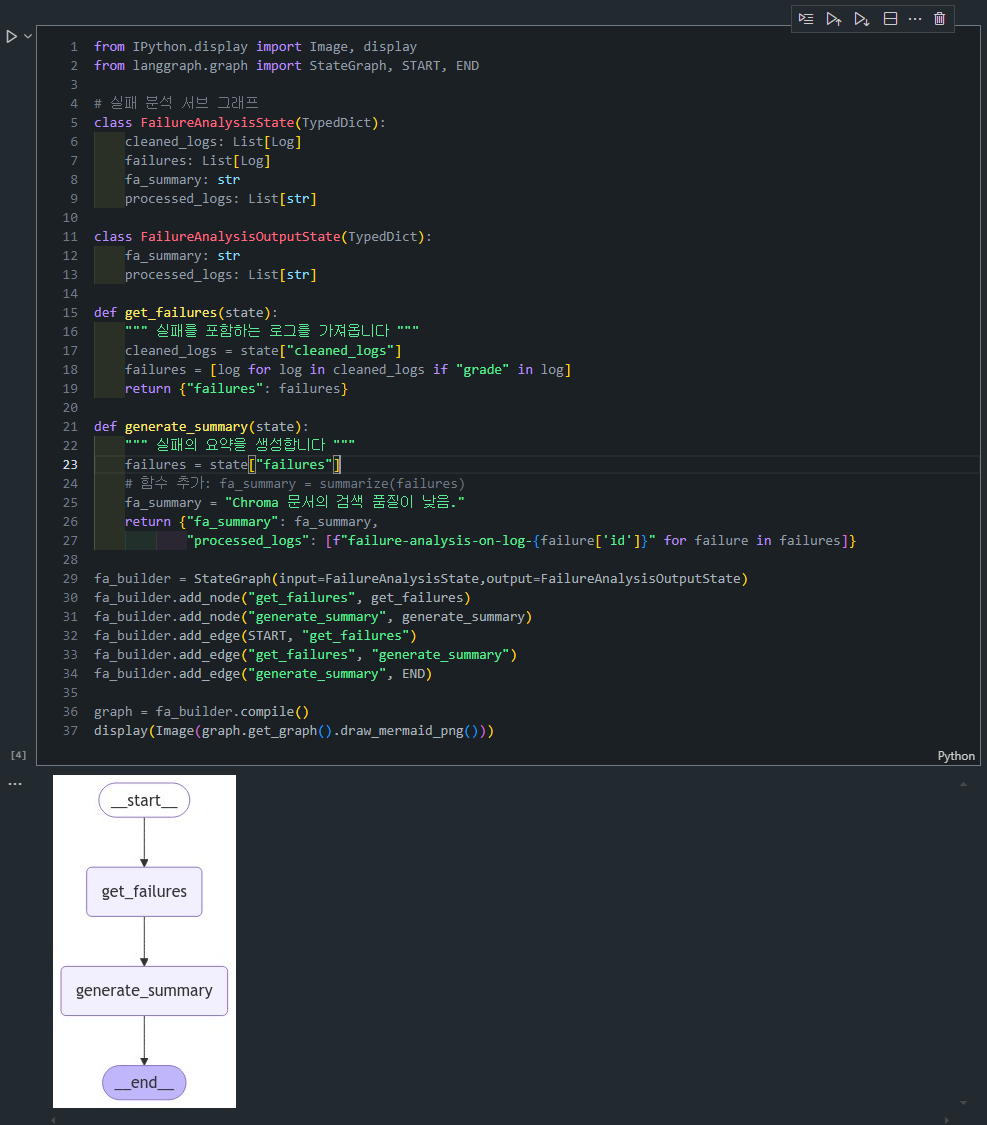
FailureAnalysisState는 실패 분석 서브그래프에서 관리할 상태를 정의하며, 주로 실패한 로그에 대한 요약과 처리된 로그를 관리합니다.
class FailureAnalysisState(TypedDict):
cleaned_logs: List[Log] # 처리된 로그
failures: List[Log] # 실패한 로그 목록
fa_summary: str # 실패 분석 요약
processed_logs: List[str] # 처리된 로그 정보
FailureAnalysisOutputState는 실패 분석 서브그래프의 출력 스키마를 정의합니다. 해당 출력 스키마는 위에와는 다르게 유저에게 전하고 싶은 정보만 가지고 있습니다.
class FailureAnalysisOutputState(TypedDict):
fa_summary: str
processed_logs: List[str]
- get_failures: 실패한 로그(grade가 포함된 로그)를 필터링하여 반환합니다.
def get_failures(state):
""" 실패를 포함하는 로그를 가져옵니다 """
cleaned_logs = state["cleaned_logs"]
failures = [log for log in cleaned_logs if "grade" in log]
return {"failures": failures}
- generate_summary: 필터링된 실패 로그들을 기반으로 요약을 생성하고, 이를
processed_logs로 기록합니다.
def generate_summary(state):
""" 실패의 요약을 생성합니다 """
failures = state["failures"]
# 함수 추가: fa_summary = summarize(failures)
fa_summary = "Chroma 문서의 검색 품질이 낮음."
return {"fa_summary": fa_summary,
"processed_logs": [f"failure-analysis-on-log-{failure['id']}" for failure in failures]}
- sub-graph 정의: 아래 코드를 통해서 sub-graph를 정의합니다.
fa_builder = StateGraph(input=FailureAnalysisState,output=FailureAnalysisOutputState)
fa_builder.add_node("get_failures", get_failures)
fa_builder.add_node("generate_summary", generate_summary)
fa_builder.add_edge(START, "get_failures")
fa_builder.add_edge("get_failures", "generate_summary")
fa_builder.add_edge("generate_summary", END)
graph = fa_builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))3. Question Summarization 서브그래프
Question Summarization서브그래프는 로그를 요약하고, 최종 보고서를 생성하는 역할을 합니다.
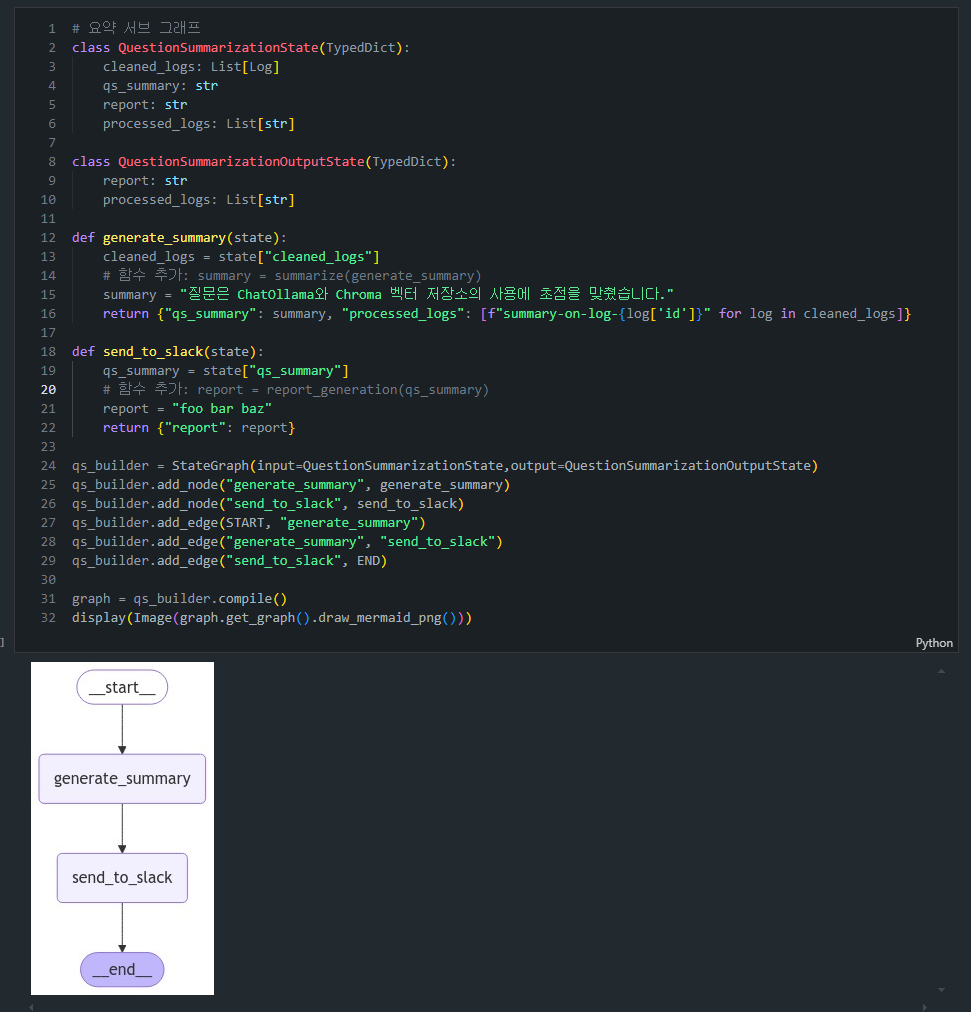
QuestionSummarizationState는 질문 요약 서브그래프에서 사용할 상태를 정의하며, 주로 질문에 대한 요약과 보고서를 생성합니다.
class QuestionSummarizationState(TypedDict):
cleaned_logs: List[Log] # 처리된 로그
qs_summary: str # 질문 요약
report: str # 보고서
processed_logs: List[str] # 처리된 로그 정보
QuestionSummarizationOutputState는 질문 요약 서브그래프의 출력 스키마를 정의합니다. 해당 출력 스키마는 위에와는 다르게 유저에게 전하고 싶은 정보만 가지고 있습니다.
class QuestionSummarizationOutputState(TypedDict):
report: str
processed_logs: List[str]
- generate_summary: 질문 로그를 요약하고, 각 로그의 요약 결과를
processed_logs에 기록합니다.
def generate_summary(state):
cleaned_logs = state["cleaned_logs"]
# 함수 추가: summary = summarize(generate_summary)
summary = "질문은 ChatOllama와 Chroma 벡터 저장소의 사용에 초점을 맞췄습니다."
return {"qs_summary": summary,
"processed_logs": [f"summary-on-log-{log['id']}" for log in cleaned_logs]}- send_to_slack: 생성된 요약을 보고서로 변환합니다(단순한 더미 예시에서 "foo bar baz"라는 결과를 반환).
def send_to_slack(state):
qs_summary = state["qs_summary"]
# 함수 추가: report = report_generation(qs_summary)
report = "foo bar baz"
return {"report": report}
- sub-graph 정의: 아래 코드를 통해서 sub-graph를 정의합니다.
qs_builder = StateGraph(input=QuestionSummarizationState,output=QuestionSummarizationOutputState)
qs_builder.add_node("generate_summary", generate_summary)
qs_builder.add_node("send_to_slack", send_to_slack)
qs_builder.add_edge(START, "generate_summary")
qs_builder.add_edge("generate_summary", "send_to_slack")
qs_builder.add_edge("send_to_slack", END)
graph = qs_builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))📚 (참고) EntryGraphStates
- 우리는
EntryGraphState클래스로 부모 그래프를 만들 수 있습니다.- 아래처럼 정의해서 서브 노드를 추가할 수 있습니다.
entry_builder.add_node("question_summarization", qs_builder.compile())entry_builder.add_node("failure_analysis", fa_builder.compile())EntryGraphState클래스를 살펴보면,cleaned_logs와processed_logs에Annotated[List[Log], add]가 사용되는 것을 확인할 수 있습니다.# 진입 그래프 class EntryGraphState(TypedDict): raw_logs: List[Log] cleaned_logs: Annotated[List[Log], add] # 이것은 두 서브 그래프에서 모두 사용됩니다 fa_summary: str # 이것은 FA 서브 그래프에서만 생성됩니다 report: str # 이것은 QS 서브 그래프에서만 생성됩니다 processed_logs: Annotated[List[int], add] # 이것은 두 서브 그래프에서 모두 생성됩니다
- 위의
EntryGraphState에서 각각 cleaned_logs와 processed_logs에Annotated[List[Log], add]리듀서가 사용되는 이유는, 두 서브그래프가 병렬로 실행되면서 동일한 상태 키를 참조하거나 업데이트하기 때문입니다.- 각각의 리듀서를 정의해줌으로써
Annotated[List[int], add]병렬 실행 시 발생할 수 있는 상태 충돌을 방지하고, 여러 값을 안전하게 병합할 수 있도록 도와줍니다.
📚 (심화)
cleaned_logs: Annotated[List[Log], add]cleaned_logs: Annotated[List[Log], add]
- 두 서브그래프에서 공통으로 사용:
cleaned_logs는 Failure Analysis 서브그래프와 Question Summarization 서브그래프가 공통으로 사용하는 상태입니다. 하지만 이 상태는 두 서브그래프에서 수정되지 않고 참조만 됩니다.- 병렬 실행 시의 상태 충돌 방지: 병렬로 실행되는 두 서브그래프가 같은 상태 키(
cleaned_logs)를 참조하지만, 그 결과를 반환할 때 동일한 키를 반환하기 때문에, 이 키에 대한 상태 병합이 필요합니다. 리듀서를 사용하지 않으면 두 서브그래프가 반환하는 상태가 충돌할 수 있습니다.add리듀서의 역할:add리듀서는 각 서브그래프에서 반환된cleaned_logs리스트를 병합해 하나의 리스트로 만들며, 이때 원본 리스트는 수정되지 않고 그대로 유지됩니다. 즉, 두 서브그래프가 같은cleaned_logs를 반환하더라도,add리듀서를 통해 안전하게 병합할 수 있습니다.
📚 (심화)
processed_logs: Annotated[List[int], add]processed_logs: Annotated[List[int], add]
- 두 서브그래프에서 생성되는 값:
processed_logs는 Failure Analysis 서브그래프와 Question Summarization 서브그래프가 각기 다른 값을 생성하는 상태입니다. 각 서브그래프는 자체적으로 처리된 로그의 ID 또는 관련 정보를processed_logs에 기록합니다.- 병렬 실행 시 각 서브그래프에서 값 추가: 두 서브그래프가 병렬로 실행되면서, 각각의
processed_logs값을 반환합니다. 만약 리듀서를 사용하지 않으면, 두 서브그래프가 반환한 값이 충돌하여 한 서브그래프의 값만 반영되거나 상태가 덮어씌워질 수 있습니다.add리듀서의 역할:add리듀서는 두 서브그래프에서 반환된 리스트를 병합하여, 두 서브그래프의 모든 로그가 안전하게 기록되도록 합니다. 즉, 두 서브그래프가 각기 다른 값을 생성해도,add리듀서가 각 값들을 결합하여processed_logs에 저장합니다.
🤔 (심화) 각각 둘다 공통적인 파라미터를 공유하다보니 그런거라고 이해할 수 있는데 다른 클래스라서 상관없지 않나?
- 좋은 질문입니다! 겉보기에는
FailureAnalysisState와QuestionSummarizationState가 서로 다른 클래스이고, 각 서브그래프 내에서 독립적으로 정의된 상태이기 때문에cleaned_logs와processed_logs가 겹치더라도 문제가 없어 보일 수 있습니다. 하지만 이들이 동일한 상위 그래프(Entry Graph)에서 병렬로 실행될 때는 상황이 다릅니다.cleaned_logs와processed_logs가 독립된 클래스에서 정의되었지만, Entry Graph(상위 그래프)에서는 이들 서브그래프가 병렬로 실행되기 때문에 두 서브그래프의 상태가 상위 그래프의 상태로 병합됩니다. 즉, 두 서브그래프는EntryGraphState에 정의된cleaned_logs와processed_logs를 공유하게 됩니다.- 서브그래프가 병렬로 실행될 때, 동일한
cleaned_logs와processed_logs상태를 참조하거나 반환하게 되므로, 이 상태를 안전하게 병합하지 않으면 상태 충돌이 발생할 수 있습니다.
cleaned_logs: 두 서브그래프에서 참조만 하므로 실제로 수정되지 않습니다. 그러나 두 서브그래프가 병렬로 실행된 후, 각각 cleaned_logs를 동일한 키로 반환하므로, 상위 그래프에서는 이를 병합해야 합니다. 이때add리듀서가 병합 충돌을 방지합니다.processed_logs: 각 서브그래프에서 생성한 처리 로그 정보를 추가하므로, 병렬 실행 후 각각의 처리 결과가 상위 그래프의 processed_logs에 누적되어야 합니다. 이때도add리듀서가 있어야 병합 충돌 없이 각각의 결과가 한 리스트로 모아집니다.
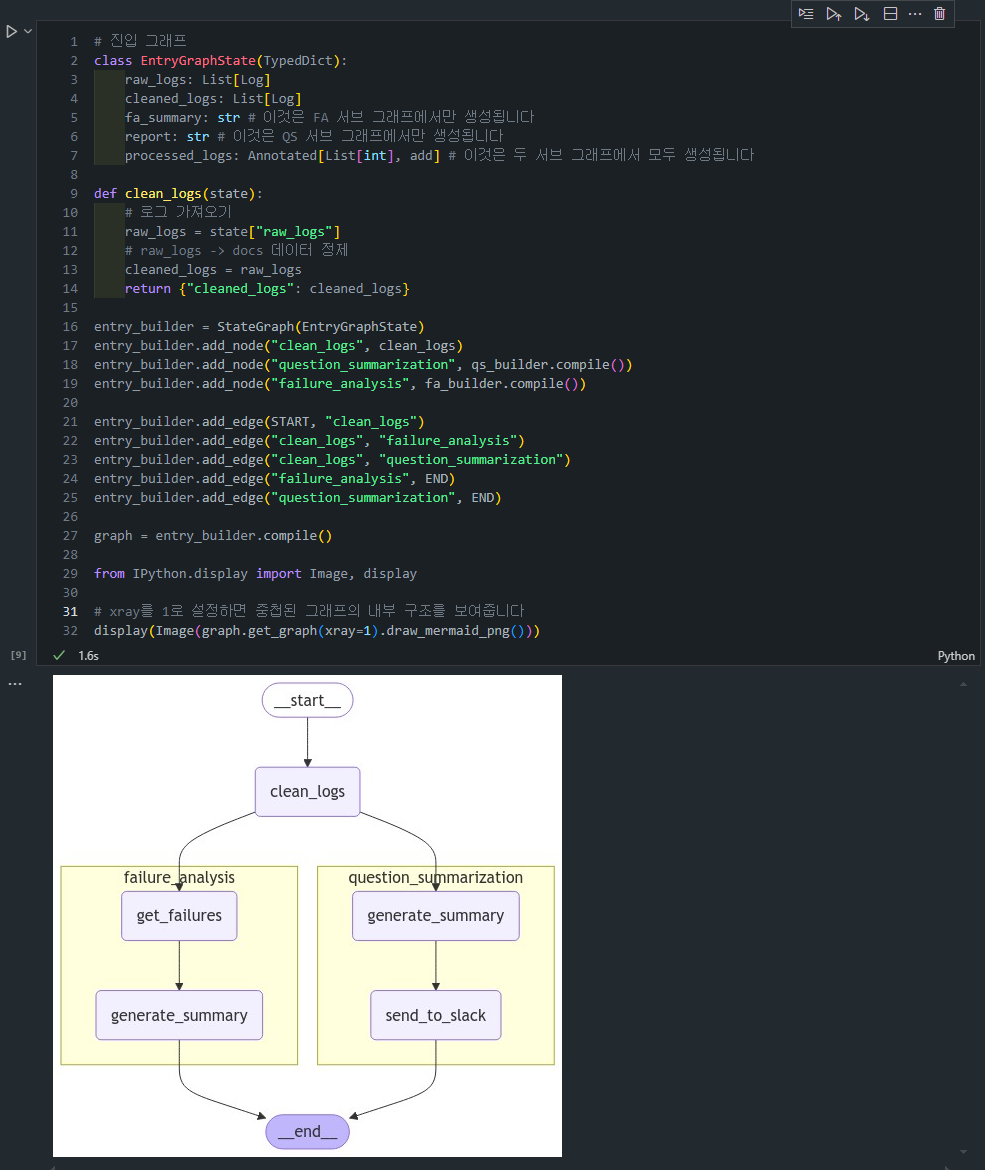
4. 부모 그래프 (EntryGraph)
- 이제
부모 그래프에서는 두 서브그래프를병렬로 실행하고 그결과를 종합합니다.
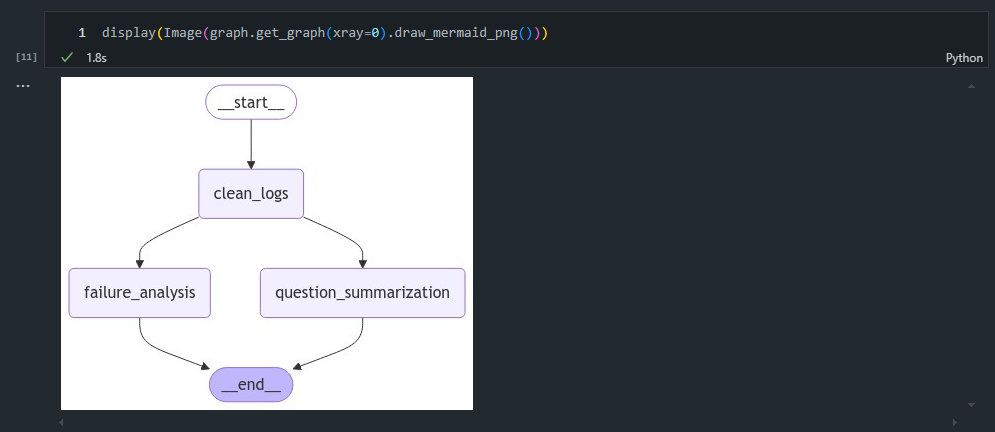
- (참고)
xray=0값으로 주었을 때의 시각화 결과
EntryGraphState는 부모 그래프에서 관리할 전체 상태를 정의합니다.
class EntryGraphState(TypedDict):
raw_logs: List[Log] # 원시 로그 데이터
cleaned_logs: List[Log] # 정제된 로그 (두 서브그래프에서 사용)
fa_summary: str # 실패 분석 요약 (FA 서브그래프에서 생성)
report: str # 질문 요약 보고서 (QS 서브그래프에서 생성)
processed_logs: Annotated[List[int], add] # 처리된 로그 목록 (두 서브그래프에서 생성)
-
fa_summary: Failure Analysis 서브그래프에서 생성된 실패 분석 요약.
-
report: Question Summarization 서브그래프에서 생성된 보고서.
-
processed_logs: 두 서브그래프에서 공통으로 생성된 처리된 로그 목록을 병합합니다.
-
cleaned_logs: 원시 로그 데이터를 정제하여
cleaned_logs상태로 변환합니다. 이 상태는 두 서브그래프에서 공통으로 사용됩니다.def cleaned_logs(state): # 로그 가져오기 raw_logs = state["raw_logs"] # raw_logs -> docs 데이터 정제 cleaned_logs = raw_logs return {"cleaned_logs": cleaned_logs}
🤦♂️ 잠깐!! 어!? 여기 cleaned_logs에는 리듀서가 없는데요?
# 진입 그래프 class EntryGraphState(TypedDict): raw_logs: List[Log] cleaned_logs: List[Log] fa_summary: str # 이것은 FA 서브 그래프에서만 생성됩니다 report: str # 이것은 QS 서브 그래프에서만 생성됩니다 processed_logs: Annotated[List[int], add] # 이것은 두 서브 그래프에서 모두 생성됩니다
- 이것은 특이 케이스로, 앞에서 각각 FailureAnalysis와 QuestionSummarization의
OutputState(FailureAnalysisOutputState,QuestionSummarizationOutputState)를 정의하여, clean_logs를 output으로 보내지 않고 processed_logs만 보내주고 있습니다.
- 이에
processed_logs: Annotated[List[int], add]만 별도로 리듀서 처리해준 것이라고 합니다.

5. 서브그래프의 통합 및 병렬 실행
두 서브그래프는 clean_logs가 완료된 후 병렬로 실행됩니다. 이 때 두 서브그래프는 같은 cleaned_logs 상태를 참조하지만 수정하지는 않습니다.
entry_builder.add_node("cleaned_logs", cleaned_logs)
entry_builder.add_node("question_summarization", qs_builder.compile())
entry_builder.add_node("failure_analysis", fa_builder.compile())
entry_builder.add_edge("cleaned_logs", "failure_analysis")
entry_builder.add_edge("cleaned_logs", "question_summarization")
entry_builder.add_edge("failure_analysis", END)
entry_builder.add_edge("question_summarization", END)
graph = entry_builder.compile()cleaned_logs: 부모 그래프에서 원시 로그 데이터를 정제하는 역할을 합니다.question_summarization: Question Summarization 서브그래프를 부모 그래프에 추가합니다.failure_analysis: Failure Analysis 서브그래프를 부모 그래프에 추가합니다.
6. 실행 예제
- 더미 로그 예시:
# 더미 로그
question_answer = Log(
id="1",
question="ChatOllama를 어떻게 임포트할 수 있나요?",
answer="ChatOllama를 임포트하려면 다음을 사용하세요: 'from langchain_community.chat_models import ChatOllama.'",
)
question_answer_feedback = Log(
id="2",
question="Chroma 벡터 저장소를 어떻게 사용할 수 있나요?",
answer="Chroma를 사용하려면 다음과 같이 정의하세요: rag_chain = create_retrieval_chain(retriever, question_answer_chain).",
grade=0,
grader="문서 관련성 회상",
feedback="검색된 문서들은 벡터 저장소에 대해 일반적으로 논의하지만, Chroma에 대해 구체적으로 다루지 않습니다",
)- 예시-1:
raw_logs = [question_answer, question_answer_feedback]
graph.invoke({"raw_logs": [question_answer]})- 출력 결과-1:
{'raw_logs': [{'id': '1',
'question': 'ChatOllama를 어떻게 임포트할 수 있나요?',
'answer': "ChatOllama를 임포트하려면 다음을 사용하세요: 'from langchain_community.chat_models import ChatOllama.'"}],
'cleaned_logs': [{'id': '1',
'question': 'ChatOllama를 어떻게 임포트할 수 있나요?',
'answer': "ChatOllama를 임포트하려면 다음을 사용하세요: 'from langchain_community.chat_models import ChatOllama.'"}],
'fa_summary': 'Chroma 문서의 검색 품질이 낮음.',
'report': 'foo bar baz',
'processed_logs': ['summary-on-log-1']}- 예시-2:
ans = graph.invoke({"raw_logs": [question_answer_feedback]})
ans- 출력 결과-2:
{'raw_logs': [{'id': '2',
'question': 'Chroma 벡터 저장소를 어떻게 사용할 수 있나요?',
'answer': 'Chroma를 사용하려면 다음과 같이 정의하세요: rag_chain = create_retrieval_chain(retriever, question_answer_chain).',
'grade': 0,
'grader': '문서 관련성 회상',
'feedback': '검색된 문서들은 벡터 저장소에 대해 일반적으로 논의하지만, Chroma에 대해 구체적으로 다루지 않습니다'}],
'cleaned_logs': [{'id': '2',
'question': 'Chroma 벡터 저장소를 어떻게 사용할 수 있나요?',
'answer': 'Chroma를 사용하려면 다음과 같이 정의하세요: rag_chain = create_retrieval_chain(retriever, question_answer_chain).',
'grade': 0,
'grader': '문서 관련성 회상',
'feedback': '검색된 문서들은 벡터 저장소에 대해 일반적으로 논의하지만, Chroma에 대해 구체적으로 다루지 않습니다'}],
'fa_summary': 'Chroma 문서의 검색 품질이 낮음.',
'report': 'foo bar baz',
'processed_logs': ['summary-on-log-2', 'failure-analysis-on-log-2']}📋 예제 흐름 정리
- 부모 그래프에서
원본 로그 데이터를 정제하여cleaned_logs로 변환합니다.
- 예제에서는 이를 위해 "더미 로그"를 생성 후 넣어주고 있습니다
cleaned_logs는 Failure Analysis 서브그래프와 Question Summarization 서브그래프에 전달됩니다.
- Failure Analysis 서브그래프는 실패한 로그(question_answer_feedback)를 식별하고, 그 결과로 실패 요약(fa_summary)을 생성합니다.
- Question Summarization 서브그래프는 질문 로그(question_answer)를 요약하고, 그 결과로 보고서(report)를 생성합니다.
- 두 서브그래프에서 처리된 로그 정보는
processed_logs에 기록됩니다.
- 최종 결과로, 각 서브그래프의 결과(
fa_summary와report)와 처리된 로그 목록이 출력됩니다.
Lesson 3: Map-reduce
개요
MapReduce는 대규모 데이터셋을 병렬로 처리하기 위한 두 가지 기본 단계인 Map 단계와 Reduce 단계로 나뉘는 프레임워크입니다. 여기서 각 단계의 핵심 내용은 다음과 같습니다:
- Map 단계: 주어진 작업을 여러 개의 작은 작업으로 분할하고 이를 병렬로 처리하여 중간 결과를 생성합니다.
- Reduce 단계: Map 단계의 중간 결과들을 하나로 통합하는 작업을 수행하여 최종 결과를 얻습니다.
주요 개념
LangGraph에서의 Map 단계 구현
-
예제에서 다음과 같은 순서로 Map 단계를 구현합니다:
-
주제 생성:
- 첫 번째 단계에서는 사용자가 제공한 주제를 기반으로 LangGraph가 여러 개의 관련 주제(subject)를 생성합니다.
- 이 과정은 LangGraph의
sendAPI를 사용하여 여러 개의generate joke노드로 확장됩니다. - 이때 각 주제별로 LangGraph가 별도의 노드를 자동으로 생성하여 병렬적으로 joke을 생성하도록 합니다.
-
joke 생성:
- 각 주제에 대해 LangGraph는
generate joke노드에서 해당 주제에 맞는 joke을 생성합니다. - 이 노드는 입력으로 주제를 받고, 해당 주제에 맞는 joke을 생성하여 결과를 jokes 리스트에 추가합니다.
- LangGraph의 add reducer 기능을 통해 생성된 joke들이 하나의 jokes 리스트로 통합됩니다.
- 각 주제에 대해 LangGraph는
-
LangGraph에서의 Reduce 단계 구현
-
Reduce 단계에서는 생성된 모든 joke 중에서 가장 우수한 것을 선택합니다. 주요 과정은 다음과 같습니다:
- 최고의 joke 선택:
- 모든 joke이 jokes 리스트에 추가되면, LangGraph는 해당 리스트를 한 문자열로 합쳐 best joke prompt로 전달합니다.
- 모델은 전체 joke 리스트를 평가하고, 가장 재미있는 joke의 인덱스를 반환합니다.
- 반환된 인덱스는 best joke로서 최종 결과에 포함됩니다.
- 최고의 joke 선택:
코드 예시
- LLM 및 State 정의
- 농담 생성 및 선택을 위한
LLM을 정의합니다. - 그래프의
진입점을 정의합니다. 이 진입점은:- 사용자 입력 주제(topic)를 받습니다
- 그로부터 농담 주제 목록(subject)을 생성합니다
- 각 농담 주제를 위의 농담 생성 노드로 보냅니다
- 이때 생성된 농담을 리듀서로 저장해둘
jokes키 정의
- 농담 생성 및 선택을 위한
from langchain_openai import ChatOpenAI
# 사용할 프롬프트
# subjects_prompt = """다음 전체 주제와 관련된 3개의 sub-topics 목록을 생성하세요: {topic}."""
# joke_prompt = """{subject}에 대한 농담을 생성하세요"""
# best_joke_prompt = """아래는 {topic}에 대한 여러 농담입니다. 가장 좋은 것을 선택하세요! 가장 좋은 농담의 ID를 반환하세요, 첫 번째 농담의 ID는 0부터 시작합니다. 농담들: \n\n {jokes}"""
subjects_prompt = """Generate a list of 3 sub-topics that are all related to this overall topic: {topic}."""
joke_prompt = """Generate a joke about {subject}"""
best_joke_prompt = """Below are a bunch of jokes about {topic}. Select the best one! Return the ID of the best one, starting 0 as the ID for the first joke. Jokes: \n\n {jokes}"""
# LLM
model = ChatOpenAI(model="gpt-4", temperature=0)
joke_model = ChatOpenAI(model="gpt-4", temperature=1.0)import operator
from typing import Annotated
from typing_extensions import TypedDict
from pydantic import BaseModel
class Subjects(BaseModel):
subjects: list[str]
class BestJoke(BaseModel):
id: int
class OverallState(TypedDict):
topic: str
subjects: list
jokes: Annotated[list, operator.add]
best_selected_joke: str
-
코드 설명
-
Subjects: 하위 주제들을 포함하는 구조체로, 각 주제별로
joke를 생성하기 위해Map단계에서 사용됩니다. -
BestJoke: 가장 재미있는
joke의 인덱스를 저장하여,Reduce단계에서 최상의 joke를 선택할 때 사용됩니다. -
OverallState: 전체
MapReduce과정의 상태를 관리하는 구조체로, 주어진 주제에서하위 주제,생성된 joke 리스트,최종 선택된 joke까지의 모든 상태를 저장합니다.
-
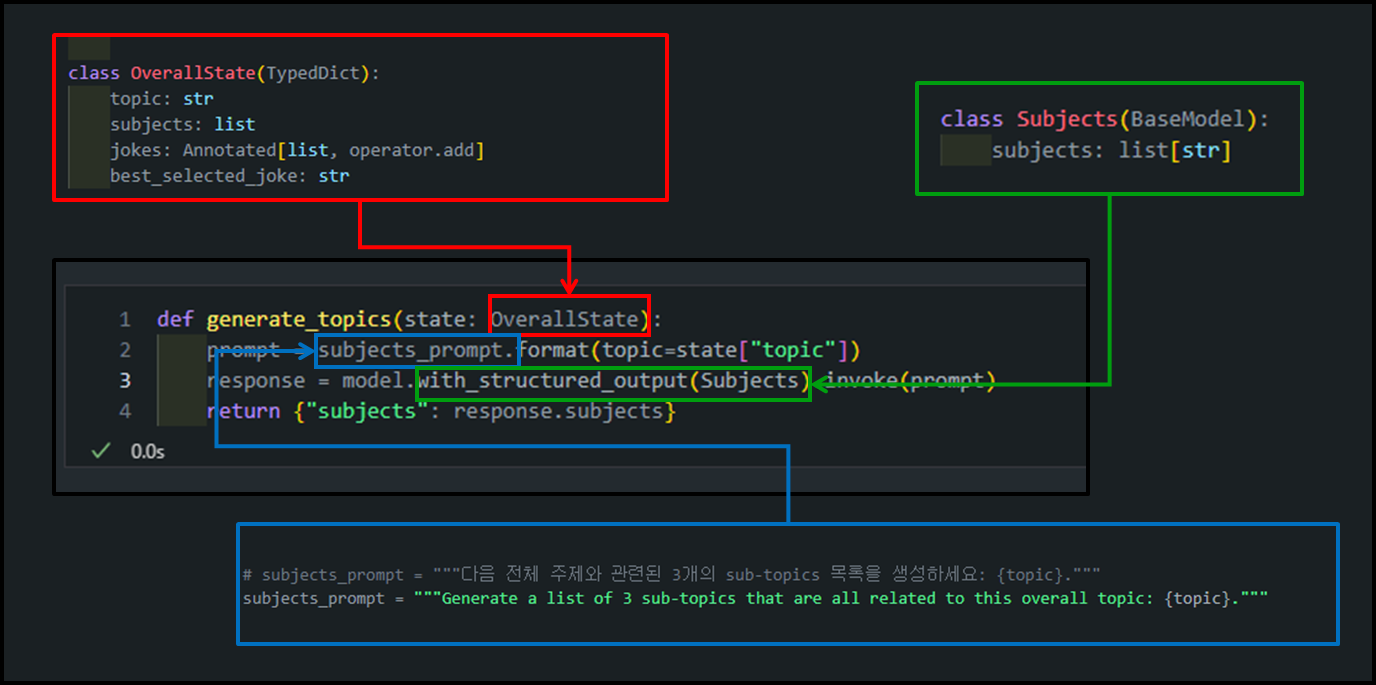
- 주제에 대한 하위 작업 생성 (Map 이전 단계) -
generate_topics함수
-
역할:
generate_topics함수는 주어진 주제(topic)에 대해 관련 있는 하위 주제 목록을 생성하는 역할을 합니다.def generate_topics(state: OverallState): prompt = subjects_prompt.format(topic=state["topic"]) response = model.with_structured_output(Subjects).invoke(prompt) return {"subjects": response.subjects}-
동작:
-
subjects_prompt를 통해 사용자가 제공한 주요 주제(topic)를 기반으로 LangChain 모델에 전달할 프롬프트를 생성합니다. -
model.with_structured_output(Subjects).invoke(prompt)를 사용하여 LangChain 모델에서Subjects스키마에 맞는 응답(리스트, 아래 참고)을 생성하도록 지정합니다.
class Subjects(BaseModel): subjects: list[str]- 이렇게 함으로써 모델의 응답은
Subjects스키마에 정의된 형태(subjects: list[str])를 가지며, 정확한 리스트 형식으로 주제들이 반환됩니다. - 반환된 주제 목록은
subjects로 저장되어 이후Map단계에서 각 주제에 대한 joke 생성 작업에 사용됩니다.
-
-
상태: 현재 상태(state)는
subjects: list[str]의 리스트 형태를 가지고 있습니다. langgraph의 Send API를 사용하여 continue_to_jokes 함수에 각각의 subjects 리스트 원소들을 넘겨줄 수 있습니다.
-
-
Send와continue_to_jokes함수from langgraph.constants import Send def continue_to_jokes(state: OverallState): return [Send("generate_joke", {"subject": s}) for s in state["subjects"]]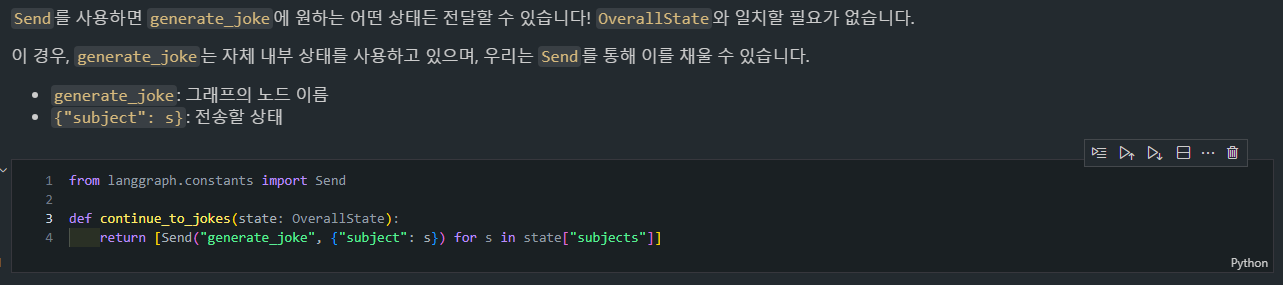
-
Send는 각 주제를 기반으로generate_joke노드로 작업을 전달하여 병렬적으로 joke를 생성하도록 합니다. -
continue_to_jokes는generate_joke노드로의 전송을 설정하는 역할을 합니다. -
동작:
state["subjects"]리스트에서 각 주제s에 대해Send객체를 생성합니다.Send("generate_joke", {"subject": s})는generate_joke노드에{ "subject": s }형태로 상태를 전달합니다.- 이 전달되는 상태가
OverallState와 일치할 필요는 없으며,generate_joke노드는 자신의 상태에 맞게 이 정보를 활용할 수 있다는 것입니다.
- 이 전달되는 상태가
- 결과적으로
Send를 통해 각 주제를 병렬로generate_joke에 전달하여 각 주제에 대한 joke를 생성하도록 합니다.
-
-
하위 주제에 대한 농담 생성 (Map 단계) -
generate_joke함수-
역할:
generate_joke는 각 주제에 대해 joke를 생성하고, 이를OverallState의jokes리스트에 추가하는 역할을 합니다.class JokeState(TypedDict): subject: str class Joke(BaseModel): joke: str def generate_joke(state: JokeState): prompt = joke_prompt.format(subject=state["subject"]) response = model.with_structured_output(Joke).invoke(prompt) return {"jokes": [response.joke]} -
동작:
-
state["subject"]값을 이용해joke_prompt를 작성하고, 이를 프롬프트로 사용하여 LangChain 모델을 호출합니다. -
model.with_structured_output(Joke).invoke(prompt)를 사용하여Joke스키마에 맞는 응답을 생성하도록 지정합니다.- 모델의 응답은
Joke스키마에 정의된 형태(joke: str)로 반환되며, 정확한 문자열 형식의 joke가 생성됩니다.
- 모델의 응답은
-
반환된 joke는 리스트로 감싸져
{ "jokes": [response.joke] }형식으로 반환됩니다.- 이는
OverallState의jokes키에 추가되며, 여기서jokes키는add reducer를 통해 리스트로 자동 집계됩니다.
- 이는
-
-
-
최고의 농담 선택 (Reduce 단계) -
best_joke함수-
역할:
best_joke함수는OverallState에 있는 여러 개의 joke 중에서 가장 재미있는 joke를 선택하는 기능을 합니다.# Reduce 단계: 가장 재미있는 농담 선택 def best_joke(state: OverallState): jokes = "\n\n".join(state["jokes"]) prompt = best_joke_prompt.format(topic=state["topic"], jokes=jokes) response = model.with_structured_output(BestJoke).invoke(prompt) return {"best_selected_joke": state["jokes"][response.id]} -
동작:
state["jokes"]리스트에 저장된 모든 joke를\n\n로 구분하여 하나의 문자열로 결합합니다.best_joke_prompt를 사용하여 주어진 topic과 결합된 joke 리스트를 LangChain 모델의 프롬프트로 작성합니다.with_structured_output(BestJoke).invoke(prompt)를 호출하여 LangChain 모델이BestJoke 스키마에 맞는 응답을 생성하도록 합니다.- 이 모델은 가장 재미있는
joke의 인덱스를 반환하며,response.id에 해당 인덱스가 저장됩니다.
- 이 모델은 가장 재미있는
- 최종적으로
state["jokes"][response.id]에 해당하는 joke를best_selected_joke키에 저장하여 반환합니다.
-
-
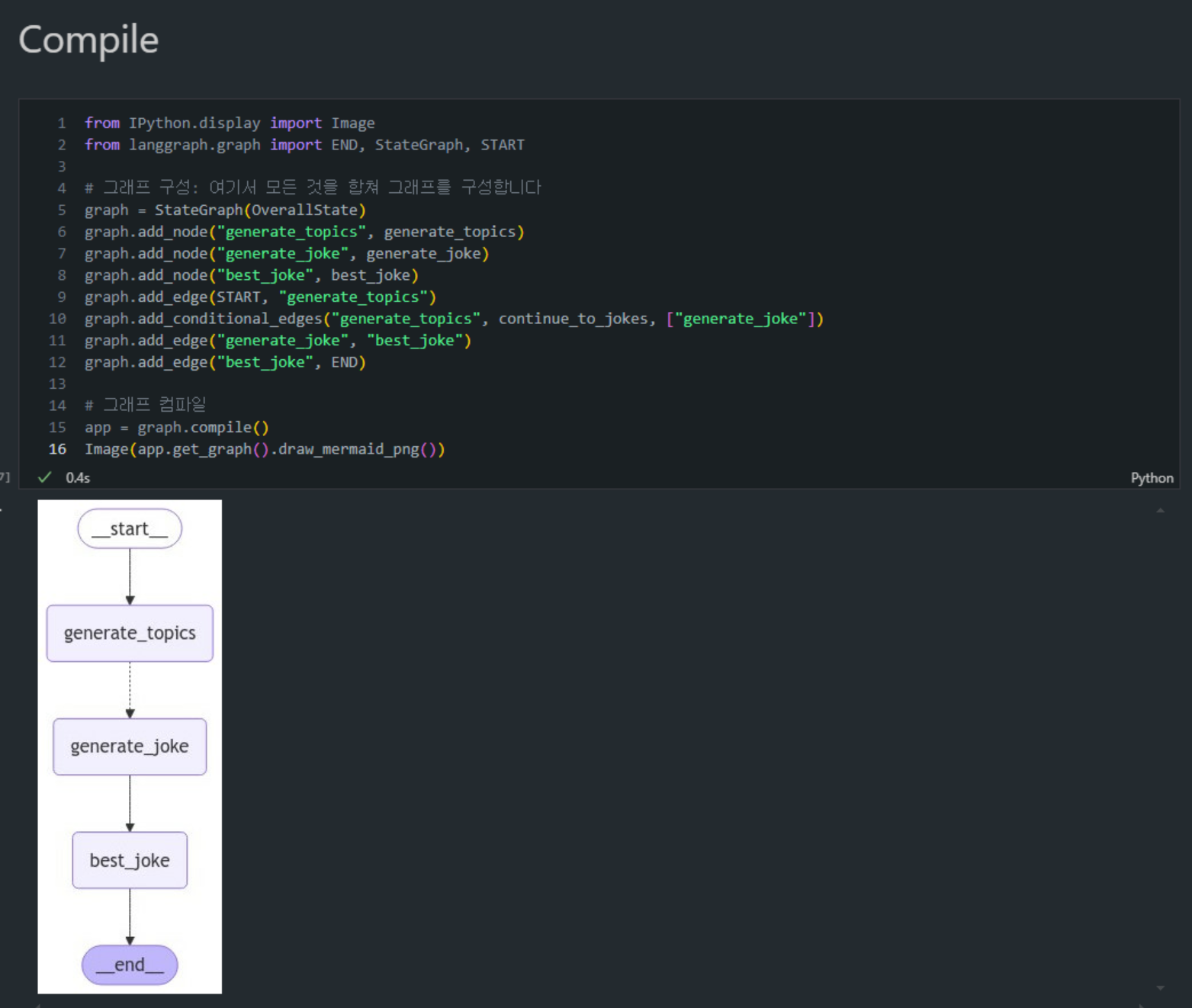
StateGraph 구성 및 컴파일 단계
-
역할:
StateGraph는 전체 MapReduce 흐름을 한 그래프 내에서 구성하는 역할을 합니다.from IPython.display import Image from langgraph.graph import END, StateGraph, START # 그래프 구성 graph = StateGraph(OverallState) graph.add_node("generate_topics", generate_topics) graph.add_node("generate_joke", generate_joke) graph.add_node("best_joke", best_joke) graph.add_edge(START, "generate_topics") graph.add_conditional_edges("generate_topics", continue_to_jokes, ["generate_joke"]) graph.add_edge("generate_joke", "best_joke") graph.add_edge("best_joke", END) -
동작:
OverallState를 상태로 사용하는StateGraph 객체를 생성합니다.generate_topics,generate_joke,best_joke노드를 각각 그래프에 추가하여 각 작업 단계를 설정합니다.- 시작점(START)에서
generate_topics노드로 이동하도록add_edge메서드로 엣지를 추가합니다. generate_topics단계 이후 각 주제에 대해조건부 엣지(add_conditional_edges)를 추가하여generate_joke로 연결되도록 합니다.- 각
generate_joke작업 이후best_joke 단계로 연결되며,best_joke에서 최종 결과를 생성하여 종료점(END)으로 연결됩니다.
-
실행 예제
- 아래와 같이
science라는 topic을 주면, LLM이 유사 주제 3개를 만들고, 이와 관련된 joke 생성 후 best joke를 생성하는 것을 볼 수 있습니다.
# 그래프 호출: 여기서 농담 목록을 생성하기 위해 호출합니다
for s in app.stream({"topic": "science"}):
print(s)Generated Subjects: ['Physics', 'Biology', 'Chemistry']
{'generate_topics': {'subjects': ['Physics', 'Biology', 'Chemistry']}}
{'generate_joke': {
'jokes': ["Why did the biologist look forward to casual Fridays? Because they're allowed to wear genes to work!"]}}
{'generate_joke': {
'jokes': ["Why can't you trust an atom? Because they make up everything!"]}}
{'generate_joke': {
'jokes': ["Why do chemists like nitrates so much? Because they're cheaper than day rates!"]}}
{'best_joke': {'best_selected_joke': "Why can't you trust an atom? Because they make up everything!"}}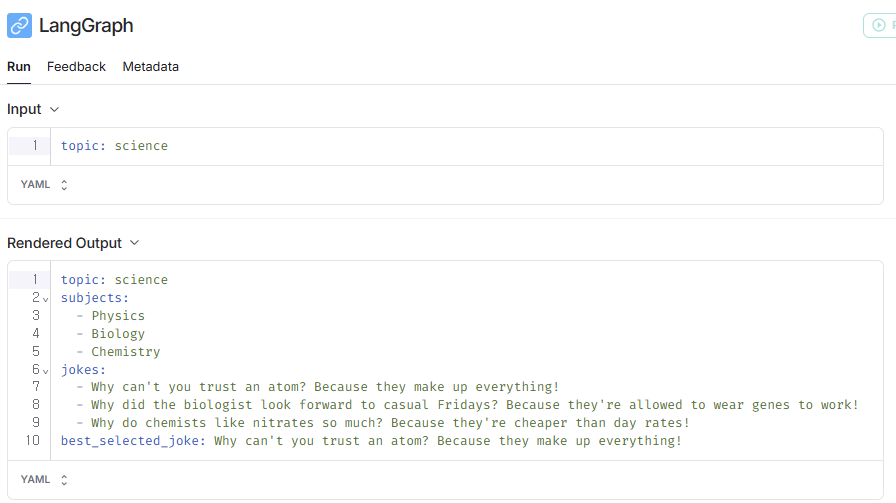
Lesson 4: Research Assistant
개요
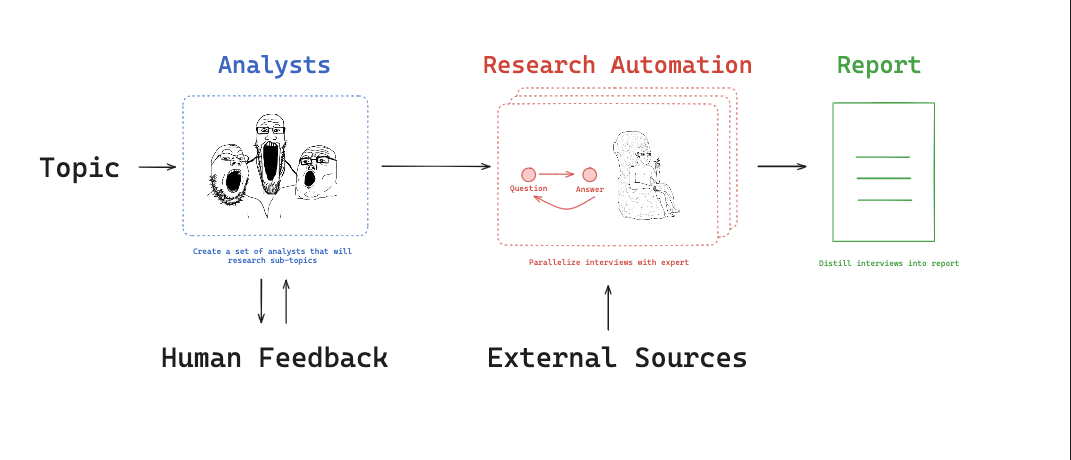
Research Assistant 시스템은 여러 AI 에이전트를 사용하여 연구 작업을 자동화하는 구조입니다. 주제에 따라 각 에이전트가 하위 주제를 담당하고, 외부 소스를 기반으로 연구를 수행한 후 결과를 병합하여 최종 보고서를 작성합니다.
주요 개념
이번 챕터의 목표는 채팅 모델을 중심으로 경량 멀티 에이전트 시스템을 구축하여 연구 프로세스를 최적화하는 것입니다.
해당 멀티 에이전트 시스템은 아래 모듈들로 구성되어 있습니다.
-
소스 선택- 사용자는 연구에 사용할 입력 소스 세트를 선택할 수 있습니다.
-
계획- 사용자가 주제를 제공하면 시스템은 AI 분석가 팀을 생성하고, 각 분석가는 하나의 하위 주제에 집중합니다.
- 연구 시작 전에 이러한 하위 주제를 개선하기 위해
Human-in-the-loop가 사용됩니다.
-
LLM 활용- 각 분석가는 선택된 소스를 사용하여 전문가 AI와 심층 인터뷰를 수행합니다.
- 인터뷰는 STORM 논문에서 보여진 것처럼 상세한 통찰을 추출하기 위한 다중 턴 대화가 될 것입니다.
- 이러한 인터뷰는 내부 상태를 가진
sub-graphs를 사용하여 캡처될 것입니다.
-
연구 프로세스- 전문가들은 분석가의 질문에 답하기 위해
parallel로 정보를 수집합니다. - 모든 인터뷰는
map-reduce를 통해 동시에 수행됩니다.
- 전문가들은 분석가의 질문에 답하기 위해
-
출력 형식- 각 인터뷰에서 수집된 통찰은 최종 보고서로 종합됩니다.
- 우리는 보고서에 대해 맞춤화 가능한 프롬프트를 사용하여 유연한 출력 형식을 허용합니다.
🌪️ "위키피디아와 유사한 글 작성을 위한 대형 언어 모델 지원 시스템, STORM"
- 논문 링크 : https://arxiv.org/pdf/2402.14207
- 해당 논문은 대형 언어 모델(LLM)을 활용하여 위키피디아 수준의 장문 글 작성을 지원하는
STORM 시스템을 소개합니다.
- STORM은 사용자가 제공한 주제를 바탕으로 위키피디아 스타일의 아티클을 생성하도록 설계되었습니다. 이 시스템은 보다 조직적이고 포괄적인 아티클을 만들기 위해 다음 두 가지 주요 인사이트를 활용합니다:
- 유사한 주제에 대한 쿼리를 통해 개요를 생성하는 것이 주제의 포괄성을 향상시킵니다.
- 다양한 관점을 반영하고 검색에 기반한 대화 시뮬레이션을 통해 참조 자료의 수와 정보 밀도를 높입니다.
- 위 그림은 논문에서 제시한 flow diagram이며, 아래 그림은 langchain 측에서 좀 더 디테일하게 그린 flow diagram입니다.
- 자료 링크 : https://github.com/langchain-ai/langgraph/blob/main/docs/docs/tutorials/storm/storm.ipynb
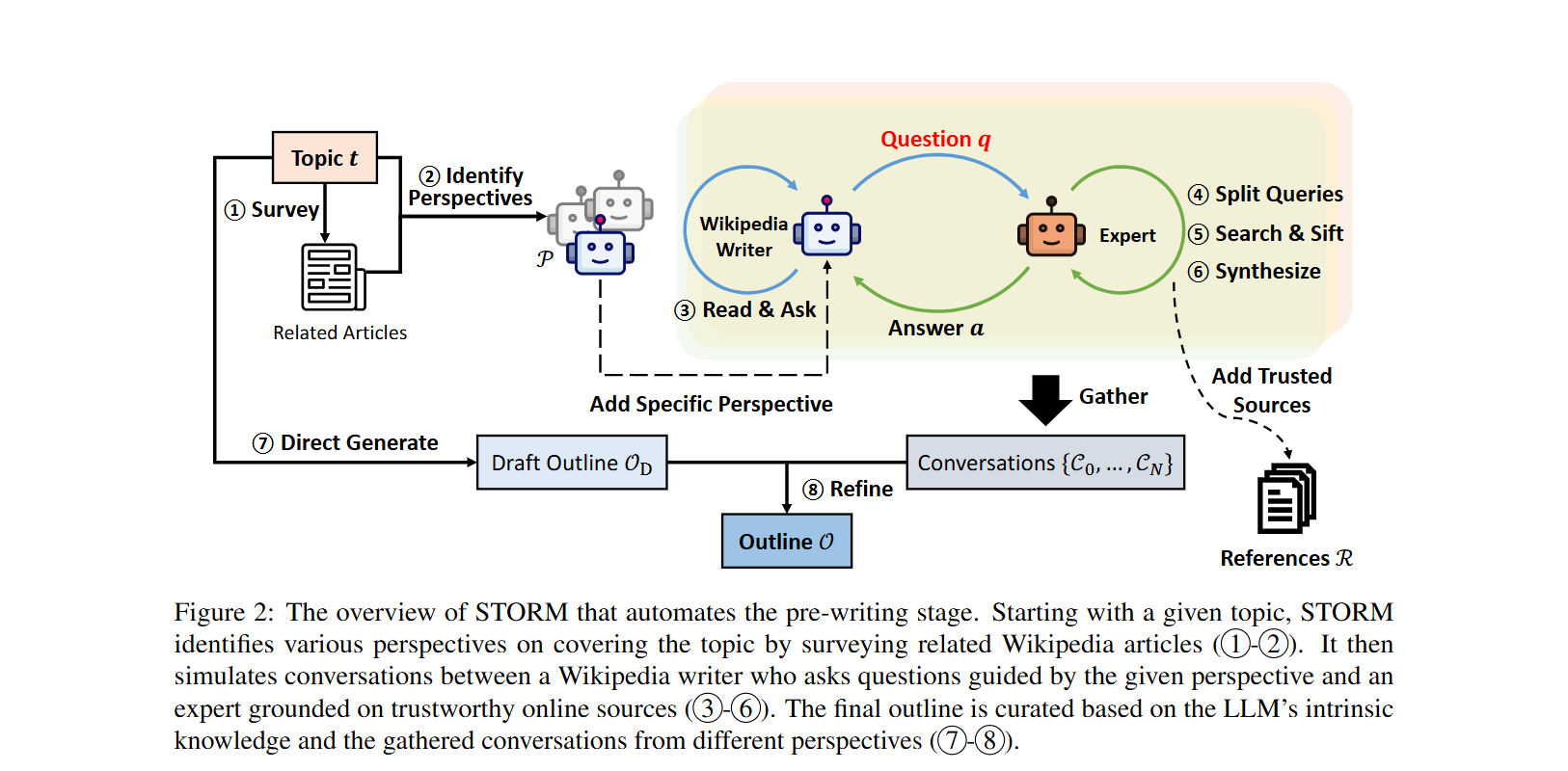
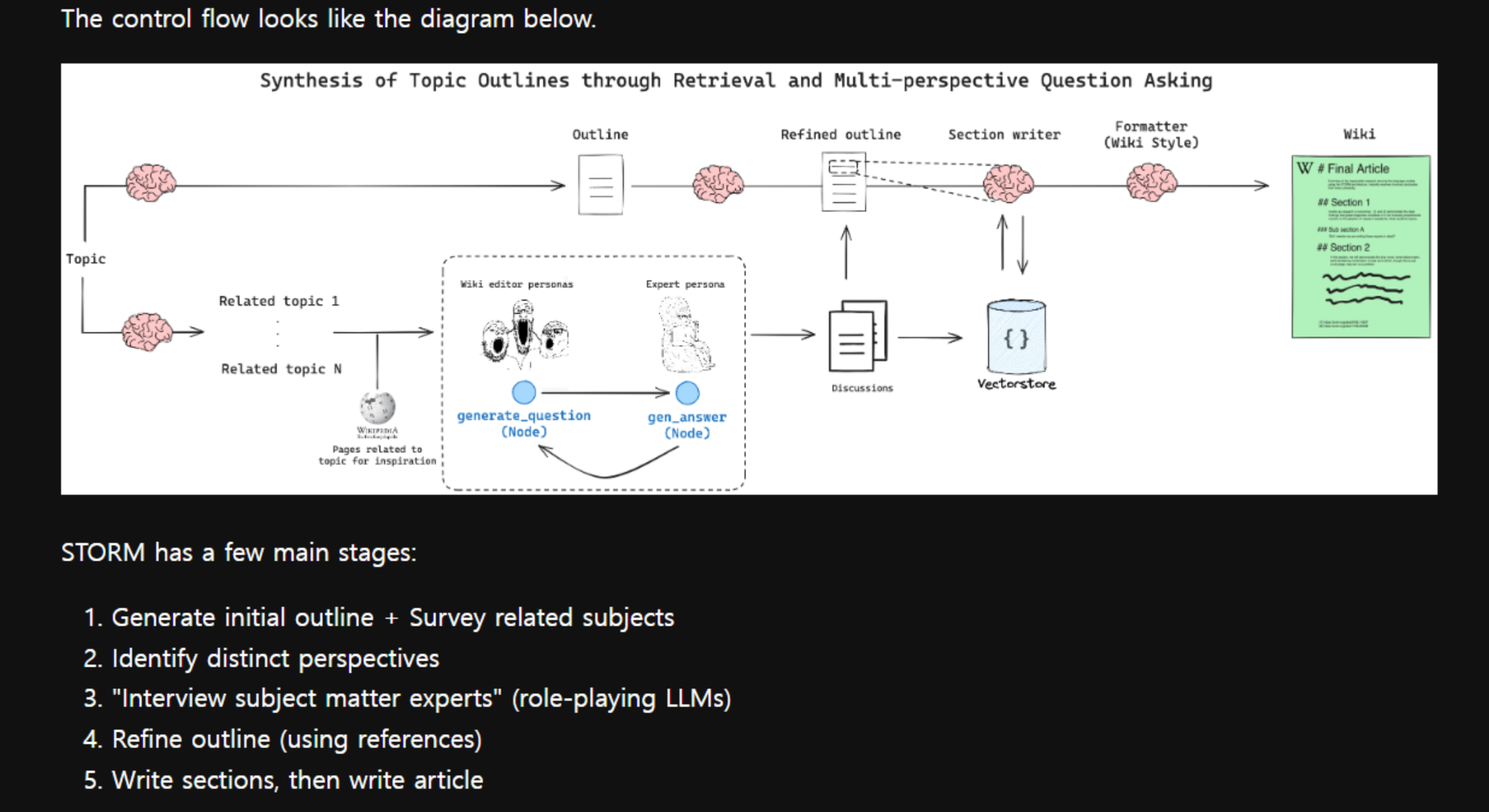
🌪️ STORM 논문에서 수행하는 다중 턴 대화(multi-turn conversation)는 위키피디아 작성자와 주제 전문가 간의 가상 대화를 시뮬레이션하여 정보를 얻는 과정입니다.
- 이 과정에서 STORM은 다음과 같은 단계를 거칩니다:
- 질문 생성: 특정 관점을 가진 위키피디아 작성자가 주제에 대해 질문을 던집니다. 예를 들어, “2022년 동계 올림픽 개막식의 교통 준비는 어떻게 되었는가?”와 같은 세부적인 질문이 생성될 수 있습니다. 이는 단순한 “무엇”이나 “언제”와 같은 표면적인 질문에서 벗어나, 주제에 대한 심층적인 탐구를 유도합니다.
- 질문 세분화 및 검색: 각 질문은 세부 검색 쿼리로 분할되고, 신뢰할 수 있는 인터넷 출처를 사용해 필요한 정보를 수집합니다. 이 단계에서는 위키피디아의 신뢰도 기준에 맞는 출처만 선택하여, 정확한 정보만이 답변에 반영되도록 합니다.
- 대답 생성 및 대화 반복: 수집된 정보를 바탕으로 가상의 전문가가 질문에 답변하고, 이 답변을 바탕으로 작성자가 새로운 후속 질문을 생성합니다. 예를 들어, 첫 번째 질문에 대한 답변에서 추가적인 교통 편의에 관한 언급이 있다면, 작성자는 이와 관련된 새로운 질문을 할 수 있습니다.
- 자료 축적 및 구조 형성: 여러 라운드에 걸친 대화가 진행되면서, STORM은 주제와 관련된 깊이 있는 정보를 수집하게 됩니다. 이렇게 얻어진 정보는 나중에 전체 문서의 개요를 정리하는 데 활용됩니다.
코드 예시
✔️ Generate Analysts: Human-In-The-Loop
Generate Analysts 섹션에서는 LangGraph의 Human-in-the-loop를 사용하여 연구 주제에 맞는 AI 분석가를 생성하고 인간의 피드백을 반영하여 분석가를 검토하는 방법을 다룹니다.
- 이를 통해 연구 주제를 다루기 위한 최적의 분석가 팀을 구성할 수 있습니다.
1. 기본 코드 구성
먼저 필요한 모듈과 기본 클래스 구조를 정의합니다. 분석가는 연구 주제와 역할에 따라 각기 다른 페르소나를 가지며, 이 페르소나는 주제에 맞는 질문과 분석을 수행하는 데 활용됩니다.
1) Analyst 클래스 스키마 정의
from typing import List
from pydantic import BaseModel, Field
class Analyst(BaseModel):
affiliation: str = Field(
description="분석가의 주요 소속.",
)
name: str = Field(
description="분석가의 이름."
)
role: str = Field(
description="주제와 관련된 분석가의 역할.",
)
description: str = Field(
description="분석가의 초점, 관심사, 동기에 대한 설명.",
)
# 페르소나 속성: 분석가의 배경 및 역할을 요약한 텍스트
@property
def persona(self) -> str:
return f"이름: {self.name}\n역할: {self.role}\n소속: {self.affiliation}\n설명: {self.description}\n"- Analyst 클래스: 분석가에 대한 주요 정보를 담고 있으며,
affiliation,name,role,description속성을 포함합니다.- affiliation: 분석가의 주요 소속을 나타내는 문자열입니다.
- name: 분석가의 이름을 나타내는 문자열입니다.
- role: 주제와 관련된 분석가의 역할을 나타내는 문자열입니다.
- description: 분석가의 초점, 관심사, 동기에 대한 설명을 나타내는 문자열입니다.
- persona 속성: 분석가의 배경을 요약하여 페르소나를 제공합니다.
- 이를 통해 분석가가 수행할 역할에 맞는 캐릭터를 갖출 수 있습니다.
- persona는
@property데코레이터를 사용한 메서드입니다. 이 메서드는 분석가의 정보를 요약된 문자열 형태로 반환합니다. 프로퍼티를 사용함으로써, 이 메서드를 속성처럼 접근할 수 있게 됩니다 (예:analyst.persona).
2) Perspectives 클래스 정의
class Perspectives(BaseModel):
analysts: List[Analyst] = Field(
description="분석가들의 역할과 소속을 포함한 종합적인 목록.",
)- Perspectives 클래스: 분석가 집합 리스트 (
List[Analyst])
3) GenerateAnalystsState 클래스 정의
class GenerateAnalystsState(TypedDict):
topic: str # 연구 주제
max_analysts: int # 생성할 분석가 수
human_analyst_feedback: str # 인간 피드백
analysts: List[Analyst] # 분석가 목록- GenerateAnalystsState 클래스: 주제와 분석가 수, 인간 피드백 등을 포함하여 연구 주제에 맞는 분석가 팀을 설정하는 데 사용됩니다.
GenerateAnalystsState클래스는 주제와 분석가 팀을 생성하고 인간의 피드백을 반영하여 주어진 상태를 관리합니다.
4) 분석가 생성 지침 (Analyst Instructions) 정의
analyst_instructions = """당신은 AI 분석가 페르소나 세트를 만드는 임무를 맡았습니다. 다음 지침을 주의 깊게 따르세요:
1. 먼저 연구 주제를 검토하세요:
{topic}
2. 분석가 생성을 안내하기 위해 선택적으로 제공된 편집 피드백을 검토하세요:
{human_analyst_feedback}
3. 위의 문서 및/또는 피드백을 바탕으로 가장 흥미로운 주제를 결정하세요.
4. 상위 {max_analysts}개의 주제를 선택하세요.
5. 각 주제에 한 명의 분석가를 할당하세요.
"""- analyst_instructions 지침: 연구 주제를 바탕으로 분석가의 페르소나를 생성하기 위한 일련의 단계들을 제공합니다.
- 분석가를 생성하기 위한 시스템 메시지인
analyst_instructions는 연구 주제와 피드백을 기반으로 특정한 분석가를 생성하는 지침을 포함합니다. - 피드백을 바탕으로 흥미로운 주제를 결정하고, 각각의 주제에 맞는 분석가를 생성합니다.
- 분석가를 생성하기 위한 시스템 메시지인
5) create_analysts 함수 정의
def create_analysts(state: GenerateAnalystsState):
topic = state['topic']
max_analysts = state['max_analysts']
human_analyst_feedback = state.get('human_analyst_feedback', '')
# 구조화된 출력 강제
structured_llm = llm.with_structured_output(Perspectives)
# 시스템 메시지
system_message = analyst_instructions.format(topic=topic,
human_analyst_feedback=human_analyst_feedback,
max_analysts=max_analysts)
# 질문 생성
analysts = structured_llm.invoke(
[SystemMessage(content=system_message)]
+
[HumanMessage(content="분석가 집단(set of analysts)을 만들어주세요.")]
)
# 분석 목록을 상태에 기록
return {"analysts": analysts.analysts}- create_analysts 함수: 주어진 상태를 기반으로 분석가를 생성하는 작업을 수행합니다.
llm.invoke메서드를 사용해 구조화된 출력으로 분석가 목록을 생성합니다.- structured_llm:
llm.with_structured_output(Perspectives)을 통해 분석가의 출력 형식을 구조화하여 반환합니다. (2 Perspective 클래스 참고) - system_message: 주제와 피드백을 기반으로 분석가의 페르소나를 생성하는 시스템 메시지입니다.
- invoke: 구조화된 출력으로 분석가 리스트를 생성하며, 이 리스트는 상태에 기록됩니다.
- structured_llm:
6-1) Human Feedback 함수 정의
def human_feedback(state: GenerateAnalystsState):
""" 중단되어야 하는 no-op 노드 """
pass- human_feedback: 사용자가 제공하는 피드백을 반영할 수 있도록 하는 함수입니다. 피드백을 주고받는 과정을 위해 임시 중단 상태를 제공합니다.
- 생성된 분석가에 대한 피드백을 반영하기 위해
human_feedback함수와should_continue함수를 사용합니다. - 피드백이 있을 경우,
create_analysts함수가 다시 호출되어 피드백에 맞는 새로운 분석가가 생성됩니다. should_continue함수는 아래를 참고해주세요.
- 생성된 분석가에 대한 피드백을 반영하기 위해
6-2) should_continue 함수 정의
def should_continue(state: GenerateAnalystsState):
# 인간 피드백 확인
human_analyst_feedback = state.get('human_analyst_feedback', None)
if human_analyst_feedback:
return "create_analysts"
return END- should_continue: 피드백이 있다면
create_analysts로 돌아가 분석가를 다시 생성하며, 없다면 종료합니다.
(추가) 작동방식 부연 설명
- LangGraph에서 분석가를 생성하는 과정 중, human_feedback 노드가 사용자의 피드백을 받을 수 있는 중단 지점을 제공합니다. 이 함수가 호출되는 동안 사용자는 생성된 분석가 목록을 보고, 필요한 경우 피드백을 제공할 수 있습니다.
- 이후, 사용자의 피드백이 should_continue 함수를 통해 확인되고, 피드백이 있는 경우 분석가 생성 단계(create_analysts)로 다시 돌아가 피드백을 반영한 새로운 분석가가 생성됩니다.
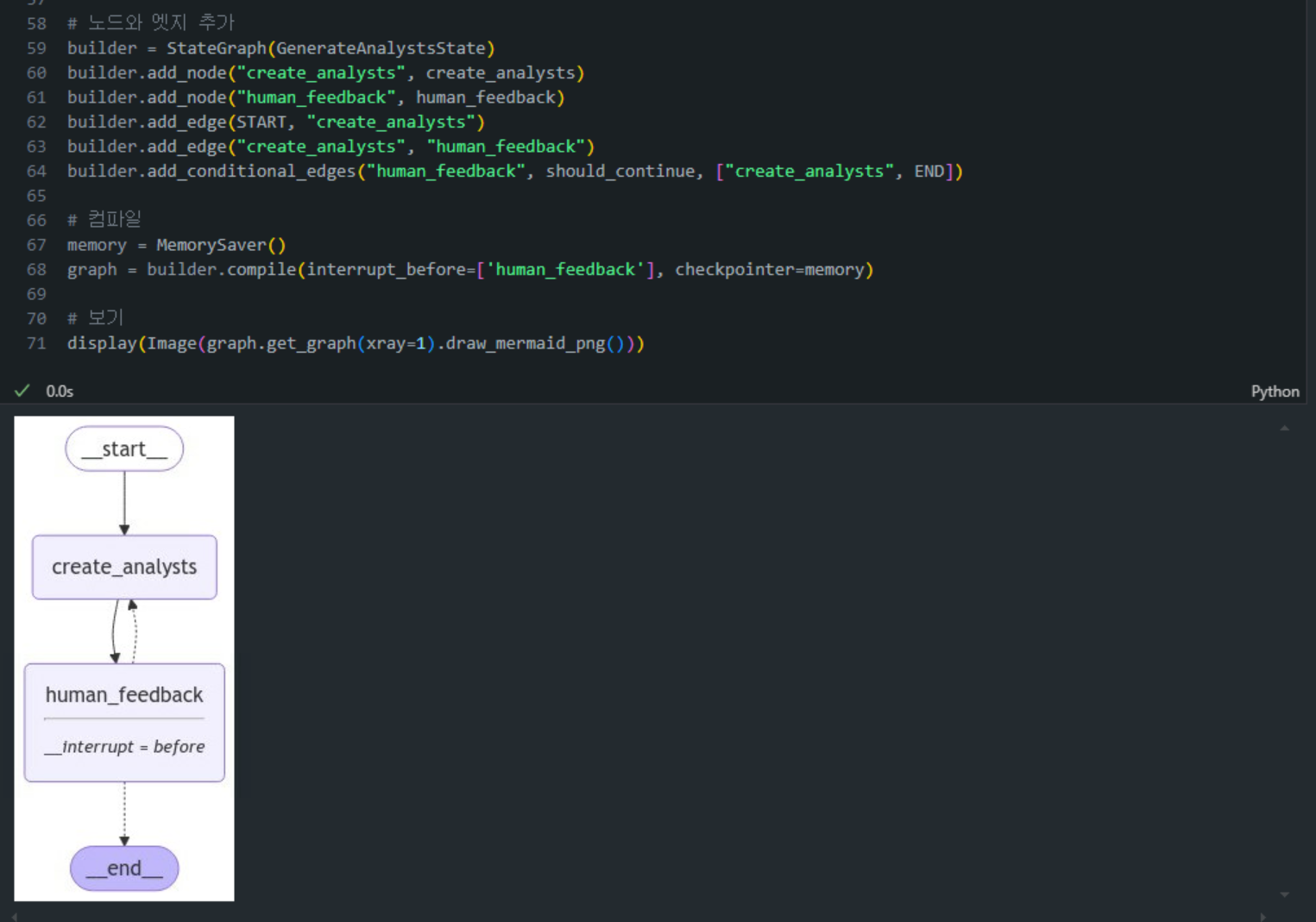
6-3) Graph 선언
from langgraph.graph import START, END, StateGraph
from langgraph.checkpoint.memory import MemorySaver
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
builder = StateGraph(GenerateAnalystsState)
builder.add_node("create_analysts", create_analysts)
builder.add_node("human_feedback", human_feedback)
builder.add_edge(START, "create_analysts")
builder.add_edge("create_analysts", "human_feedback")
builder.add_conditional_edges("human_feedback", should_continue, ["create_analysts", END])
# 컴파일
memory = MemorySaver()
graph = builder.compile(interrupt_before=['human_feedback'], checkpointer=memory)
# 보기
display(Image(graph.get_graph(xray=1).draw_mermaid_png()))- 이제
StateGraph클래스를 사용하여 노드와 엣지를 추가하고 전체적인 흐름을 설정합니다.- builder: 그래프 빌더를 설정하고 각 노드와 엣지를 추가합니다.
- add_node:
create_analysts및human_feedback노드를 추가하여 분석가 생성과 피드백을 처리합니다. - add_edge: 시작과 종료 노드를 연결하며, 피드백이 있을 경우 분석가를 생성하는 노드로 돌아가도록 합니다.
- MemorySaver: 실행 상태를 저장하여 필요할 때 복원할 수 있도록 합니다.
- display: 그래프를 시각화하여 구조를 확인합니다.
(중간 점검) 그럼 이제 잘 만들어졌나 확인해봐야겠죠?
- 아래와 같이
LLMOps 솔루션 제작이라는 주제로 전문가들을 3명 고용해보겠습니다.# 입력 max_analysts = 3 topic = "LLMOps 솔루션 제작" thread = {"configurable": {"thread_id": "1"}} # 첫 번째 중단까지 그래프 실행 for event in graph.stream({"topic":topic,"max_analysts":max_analysts,}, thread, stream_mode="values"): # 검토 analysts = event.get('analysts', '') if analysts: for analyst in analysts: print(f"이름: {analyst.name}") print(f"소속: {analyst.affiliation}") print(f"역할: {analyst.role}") print(f"설명: {analyst.description}") print("-" * 50)
(결과 확인) 실제로 전문가들이 제대로 생성되는 것을 확인할 수 있습니다
Lead Research Scientist,Data Engineer,AI Ethics Consultant직책으로 계신 분들을 만들어냈군요.이름: Dr. Emily Carter 소속: Tech Innovators Inc. 역할: Lead Research Scientist 설명: Dr. Carter focuses on the development and optimization of LLMOps solutions, with a particular interest in scalability and efficiency. -------------------------------------------------- 이름: Michael Thompson 소속: AI Solutions Ltd. 역할: Data Engineer 설명: Michael specializes in data pipeline architecture and is passionate about integrating LLMOps solutions to streamline data processing workflows. -------------------------------------------------- 이름: Sophia Martinez 소속: FutureTech Analytics 역할: AI Ethics Consultant 설명: Sophia is dedicated to ensuring that LLMOps solutions are developed and deployed ethically, with a focus on transparency and fairness. --------------------------------------------------

아래 코드를 실행해보면 현재 ('human_feedback',)이전에서 대기 중이라는 것을 알 수 있습니다.
# 상태 가져오고 다음 노드 확인
state = graph.get_state(thread)
state.next그리고 나서 아래와 같은 코드로 human_feedback을 줄 수 있습니다.
# 이제 human_feedback 노드인 것처럼 상태를 업데이트합니다
graph.update_state(thread, {"human_analyst_feedback":
"기업가적 관점을 추가하기 위해 gen ai 네이티브 스타트업의 CEO를 추가하세요"}, as_node="human_feedback")그럼 human_feedback 노드를 통해 이제 다시 create_analyst 노드로 넘어가서 추가적으로 analyst를 만드는 것을 확인할 수 있습니다.
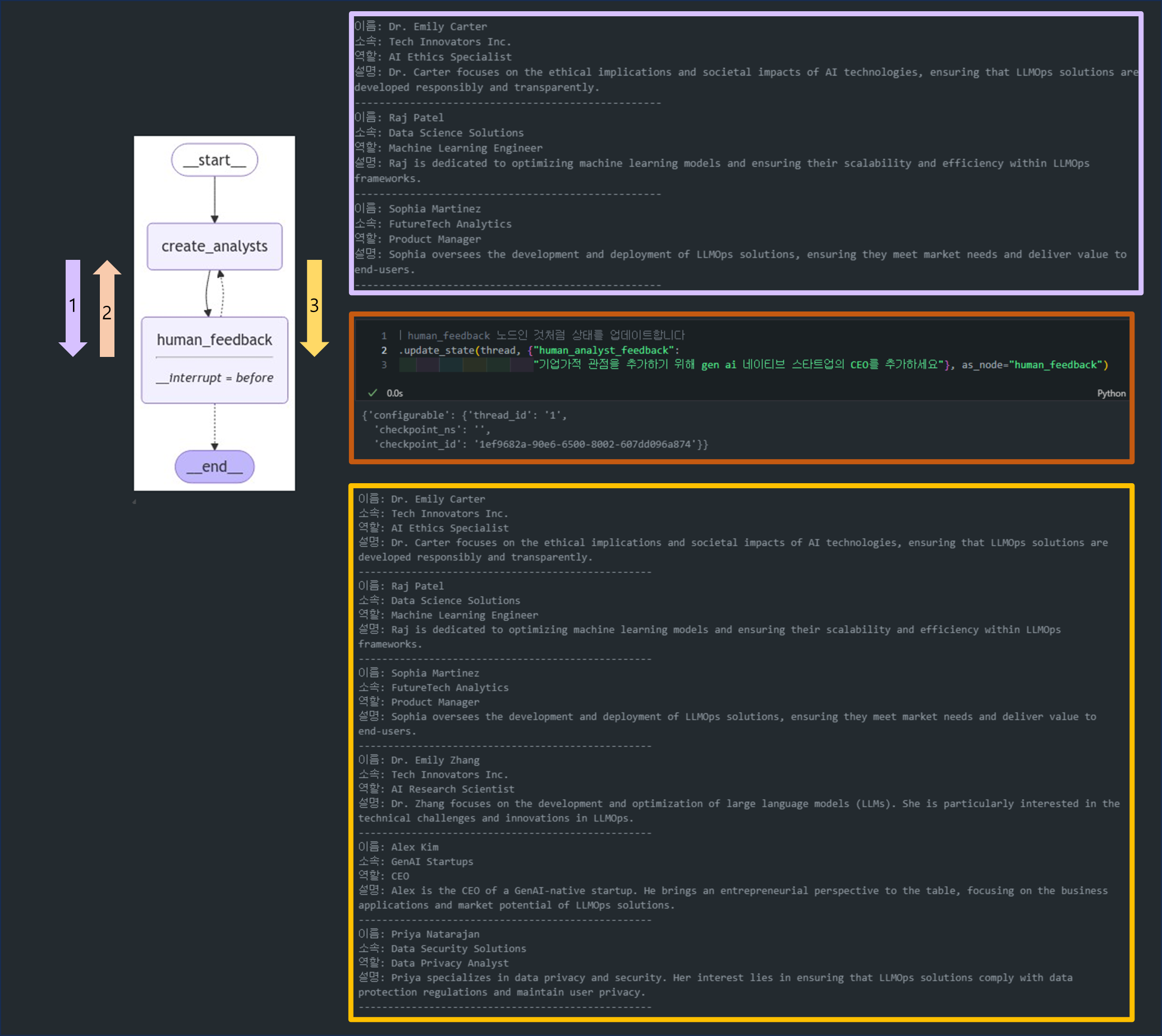
위 그림을 글로 정리하자면,
-
첫 번째
create_analysts호출:- 주제에 맞는 분석가 3명을 생성하여
analysts리스트에 추가합니다. - 이 리스트는 state에 저장됩니다.
- 주제에 맞는 분석가 3명을 생성하여
-
human_feedback를 통한 피드백 반영:human_feedback노드에서 피드백을 받고,create_analysts가 재호출됩니다.- 이때,
state['analysts']에 기존 3명의 분석가가 이미 포함되어 있습니다. - 새로운 3명이 추가되면서 최종적으로 6명의 분석가 리스트가 생성됩니다.
현재 출력에 지금 6명으로 뜬 이유는 MemorySaver()가 checkpointer로 사용되었기 때문에 이전 실행 상태가 메모리에 저장되었기 때문입니다.
- 이를 기반으로 create_analysts가 재호출되면서 기존 분석가 목록(이전에 호출된 3명의 분석가)에 새로운 분석가들(새롭게 이번에 추가된 3명의 추가 분석가)이 계속 추가된 것입니다(총 6명의 분석가).
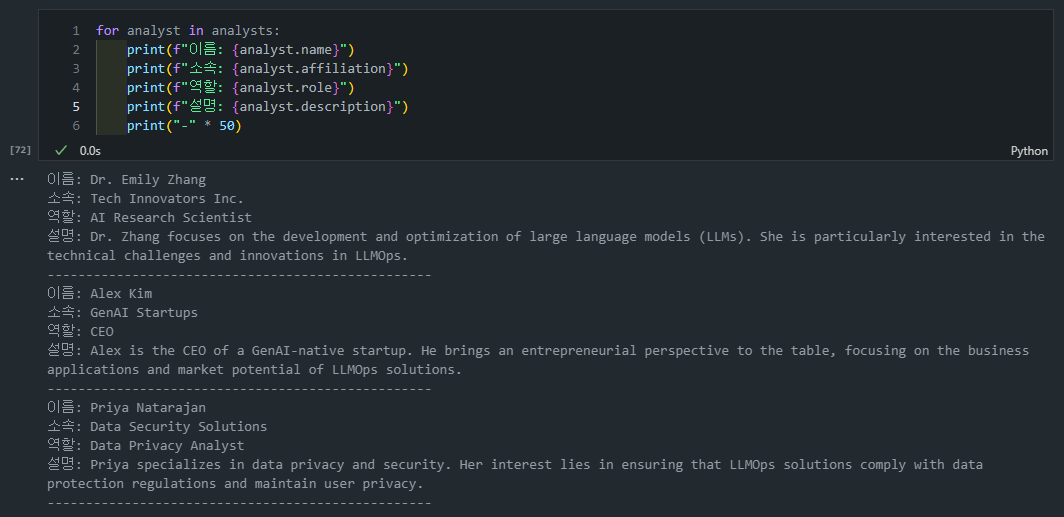
현재 state 정보만 보려면 아래와 같이 코드를 출력해볼 수 있습니다:
state = graph.get_state(thread)
# state.values
# 현재 상태 출력
print(f"주제: {state.values['topic']}")
print(f"최대 분석가 수: {state.values['max_analysts']}")
print(f"피드백: {state.values['human_analyst_feedback']}")
print('======================')
print(' PRINT INFO ')
print('======================')
# analysts 목록 출력
analysts = state.values['analysts']
if analysts:
for analyst in analysts:
print(f"\n이름: {analyst.name}")
print(f"소속: {analyst.affiliation}")
print(f"역할: {analyst.role}")
print(f"설명: {analyst.description}")
print("-" * 50)
주제: LLMOps 솔루션 제작
최대 분석가 수: 3
피드백: 기업가적 관점을 추가하기 위해 gen ai 네이티브 스타트업의 CEO를 추가하세요
======================
PRINT INFO
======================
이름: Dr. Emily Zhang
소속: Tech Innovators Inc.
역할: AI Research Scientist
설명: Dr. Zhang focuses on the development and optimization of large language models (LLMs). She is particularly interested in the technical challenges and innovations in LLMOps.
--------------------------------------------------
이름: Alex Kim
소속: GenAI Startups
역할: CEO
설명: Alex is the CEO of a GenAI-native startup. He brings an entrepreneurial perspective to the table, focusing on the business applications and market potential of LLMOps solutions.
--------------------------------------------------
이름: Priya Natarajan
소속: Data Security Solutions
역할: Data Privacy Analyst
설명: Priya specializes in data privacy and security. Her interest lies in ensuring that LLMOps solutions comply with data protection regulations and maintain user privacy.
--------------------------------------------------더이상 human-in-the-loop (휴먼-피드백)이 필요없다고 판단이 되면 아래와 같이 None을 피드백으로 제공하여 그래프가 종료될 수 있도록 합니다.
# 만족한다면 피드백 없음을 제공
further_feedack = None
graph.update_state(thread, {"human_analyst_feedback":
further_feedack}, as_node="human_feedback")이렇게 그래프를 끝까지 실행이 되는 것을 확인할 수 있습니다. (출력 결과: ())
# 그래프 실행을 끝까지 계속합니다
for event in graph.stream(None, thread, stream_mode="updates"):
print("--노드--")
node_name = next(iter(event.keys()))
print(node_name)
final_state = graph.get_state(thread)
analysts = final_state.values.get('analysts')
final_state.next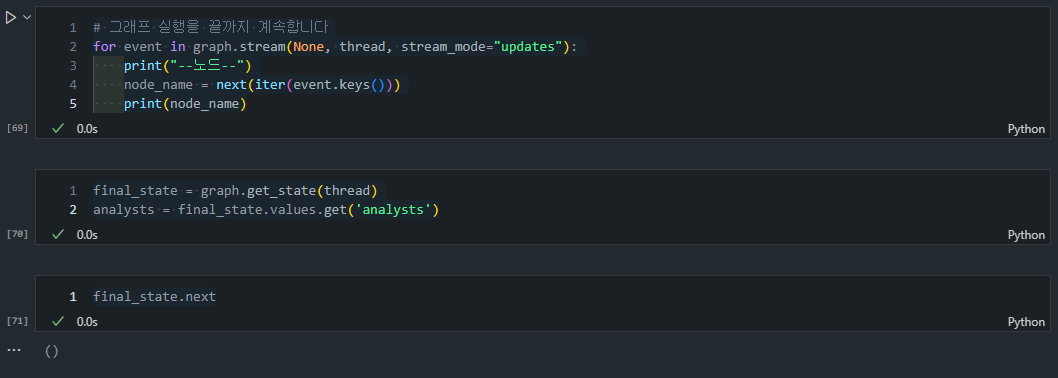
최종 선정 Analyst도 위에서 1번의 피드백을 거친 분석가들임을 확인할 수 있습니다:
✔️ Conduct Interview: 질문 생성 및 인터뷰 수행
Conduct Interview 단계에서는 생성된 분석가가 전문가 AI와 대화하며 주제에 대한 통찰을 얻기 위해 질문을 던지고 답변을 수집하는 과정을 진행합니다.
- 이 과정은 분석가의 역할에 따라 설계된 질문을 생성하고, 다양한 소스에서 정보를 병렬로 수집한 뒤 답변을 생성하는 방식으로 구성됩니다.
import operator
from typing import Annotated
from langgraph.graph import MessagesState-
InterviewState클래스:-
MessagesState를 상속받아 인터뷰 대화에서 필요한 상태를 관리합니다.class InterviewState(MessagesState): max_num_turns: int # 대화 턴 수 context: Annotated[list, operator.add] # 소스 문서 analyst: Analyst # 질문하는 분석가 interview: str # 인터뷰 기록 sections: list # Send() API를 위해 외부 상태에서 복제하는 최종 키 -
이 클래스는 분석가(Analyst)와 인터뷰 진행 과정에서 사용되는 여러 데이터를 저장합니다.
max_num_turns: 인터뷰의 최대 턴 수를 설정하여, 인터뷰가 몇 차례의 질문-응답 쌍 이후 종료될지 결정합니다.context: Annotated 타입을 사용하여 소스 문서의 목록을 설정하고,operator.add를 적용하여 각 인터뷰에서 수집된 소스 문서를 점진적으로 누적합니다.analyst: 현재 질문을 하는 분석가를 나타내며,Analyst객체로 관리됩니다.interview: 인터뷰 내용을 문자열로 저장하여, 대화 전체의 기록을 보존합니다.sections:Send()API에서 외부 상태와 데이터를 주고받기 위해 사용되는 키입니다.
-
-
SearchQuery클래스:-
search_query속성만을 가지는 간단한 데이터 모델로, 검색 쿼리를 문자열로 저장합니다.class SearchQuery(BaseModel): search_query: str = Field(None, description="검색을 위한 쿼리.") -
search_query는Field함수와 함께 설정되어, 검색어의 용도를 명시적으로 설명합니다.- Field 함수를 통해 검색 쿼리의 용도를 설명하여
search_query를 명확하게 지정합니다. - 검색 과정에서 분석가의 질문을 기반으로 검색어를 생성하여 저장하는 데 사용됩니다.
- Field 함수를 통해 검색 쿼리의 용도를 설명하여
-
-
question_instructions쿼리:
question_instructions는 인터뷰를 진행하는 분석가가 전문가에게 흥미롭고 구체적인 질문을 던지도록 돕는 가이드라인입니다.- 이 프롬프트는 분석가가 인터뷰의 초점과 목표에 맞춰 대화를 이끌어나가도록 유도하며, 전체 인터뷰 대화의 질과 방향성을 유지하는 데 중요한 역할을 합니다.
# 분석가가 전문가에게 흥미롭고 구체적인 질문을 던지도록 돕는 가이드라인
question_instructions = """
당신은 특정 주제에 대해 전문가를 인터뷰하는 분석가입니다.
당신의 목표는 주제와 관련된 흥미롭고 구체적인 통찰을 얻는 것입니다.
1. Interesting: 사람들이 놀랍거나 뜻밖이라고 생각할 통찰.
2. Specific: 일반론을 피하고 전문가의 구체적인 예시를 포함하는 통찰.
다음은 당신의 topic of focus와 set of goals입니다: {goals}
당신의 페르소나에 맞는 이름으로 자신을 소개하고 질문을 시작하세요.
주제에 대한 이해를 심화하고 구체화하기 위해 계속해서 질문하세요.
이해가 충분하다고 판단되면 "도움 주셔서 정말 감사합니다!"라고 말하며 인터뷰를 마무리하세요.
제공된 페르소나와 목표를 반영하며 응답 전체에 걸쳐 캐릭터를 유지하세요.
"""1) 질문 생성 (Generate Question)
이 단계는 분석가가 전문가에게 주제를 기반으로 구체적이고 흥미로운 질문을 던질 수 있도록 돕습니다.
- 질문 생성은
generate_question함수에서 이루어지며, 이 함수는 분석가의 페르소나와 목표를 기반으로 적절한 질문을 만듭니다.
def generate_question(state: InterviewState):
# 분석가와 이전 메시지 가져오기
analyst = state["analyst"]
messages = state["messages"]
# 분석가의 목표를 기반으로 질문 생성
system_message = question_instructions.format(goals=analyst.persona)
question = llm.invoke([SystemMessage(content=system_message)] + messages)
# 생성된 질문을 상태에 기록하여 다음 프로세스로 전달
return {"messages": [question]}-
analyst: 분석가의 페르소나 및 목표를 포함한 인스턴스로, 연구 주제와 관련된 구체적인 질문을 생성하는 데 필요한 정보가 담깁니다.
-
question_instructions: 분석가가 질문을 할 때 따라야 할 지침으로, 질문이 흥미롭고 구체적인 통찰을 유도하도록 설계되었습니다.
- (참고)
question_instructions은 바로 위3. question_instructions 쿼리에서 정의되어 있습니다.
- (참고)
- question =
llm.invoke메서드는 시스템 메시지와 이전 대화 메시지를 입력으로 받아 새로운 질문을 생성합니다.- llm.invoke에 들어가는 인자는
[SystemMessage(content=system_message)] + messages로, 위에서 정의한 question_instructions과 messages입니다. - 참고로, messages는 현재 진행 중인 인터뷰 대화의 전체 메시지 기록을 나타냅니다. 이는 분석가와 전문가 간의 이전 질문과 답변이 순서대로 포함된 상태입니다.
- llm.invoke에 들어가는 인자는
2) 병렬 답변 수집 (Parallelized Answer Collection)
LangGraph의 병렬화 기능을 활용해 전문가가 질문에 답변하기 위해 다양한 소스에서 정보를 수집하는 방식으로 진행됩니다.
- 본 예제에서는
tavily_search와search_wikipedia함수를 통해 각 소스를 검색하고 결과를 저장합니다.
# 웹 검색 도구
from langchain_community.tools.tavily_search import TavilySearchResults
tavily_search = TavilySearchResults(max_results=3)
# 위키피디아 검색 도구
from langchain_community.document_loaders import WikipediaLoadersearch_instructions
-
search_instructions는 대화 맥락을 바탕으로 최적의 검색 쿼리를 생성하는 데 필요한 지침을 제공합니다.- 이 프롬프트는 특정한 질문에 대한 정보를 검색할 때 구체적이고 유용한 쿼리를 구성할 수 있도록 유도합니다.
# 검색 쿼리 작성
search_instructions = SystemMessage(content=f"""
분석가와 전문가 사이의 대화가 주어질 것입니다.
당신의 목표는 대화와 관련된 검색 및/또는 웹 검색에 사용할 잘 구조화된 쿼리를 생성하는 것입니다.
먼저 전체 대화를 분석하세요.
분석가가 마지막으로 제기한 질문에 특히 주의를 기울이세요.
이 마지막 질문을 잘 구조화된 웹 검색 쿼리로 변환하세요
""")웹 검색 (search_web)
def search_web(state: InterviewState):
""" 웹 검색에서 문서 검색 """
# 검색 쿼리 생성
structured_llm = llm.with_structured_output(SearchQuery)
search_query = structured_llm.invoke([search_instructions] + state["messages"])
# Tavily 검색 API를 사용하여 결과를 가져옴
search_docs = tavily_search.invoke(search_query.search_query)
# 형식 지정된 결과 반환
formatted_search_docs = "\n\n---\n\n".join(
[f'<Document href="{doc["url"]}"/>\n{doc["content"]}\n</Document>' for doc in search_docs]
)
return {"context": [formatted_search_docs]} -
search_query: 분석가의 질문을 바탕으로 웹 검색에 적합한 쿼리를 생성합니다.
-
tavily_search: Tavily API를 사용하여 웹 검색 결과를 가져옵니다.
- 이 결과는 추후 답변을 생성하는 데 사용됩니다.
-
formatted_search_docs: 검색 결과를 HTML 형식으로 변환하여 보고서 작성 시 출처로 활용할 수 있도록 구성합니다.
위키피디아 검색 (search_wikipedia)
def search_wikipedia(state: InterviewState):
""" 위키피디아에서 문서 검색 """
# 검색 쿼리 생성
structured_llm = llm.with_structured_output(SearchQuery)
search_query = structured_llm.invoke([search_instructions] + state["messages"])
# WikipediaLoader로 검색 결과 가져오기
search_docs = WikipediaLoader(query=search_query.search_query, load_max_docs=2).load()
# 형식 지정된 결과 반환
formatted_search_docs = "\n\n---\n\n".join(
[f'<Document source="{doc.metadata["source"]}" page="{doc.metadata.get("page", "")}"/>\n{doc.page_content}\n</Document>' for doc in search_docs]
)
return {"context": [formatted_search_docs]} -
WikipediaLoader: 위키피디아에서 검색 결과를 가져오는 역할을 하며, 검색 쿼리를 사용해 관련 문서를 반환합니다.
-
formatted_search_docs: 검색 결과를 HTML 형식으로 변환하여 보고서 작성 시 출처로 활용할 수 있도록 구성합니다.
answer_instructions
-
answer_instructions는 분석가가 제시한 질문에 대해 전문가가 관련 정보만을 사용해 정확하고 구체적인 답변을 생성할 수 있도록 돕습니다.- 이 가이드라인은 답변의 일관성과 정확성을 보장하기 위해 설계되었습니다.
answer_instructions = """
당신은 분석가에 의해 인터뷰를 받고 있는 전문가입니다.
다음은 분석가의 관심 영역입니다:
{goals}.
당신의 목표는 인터뷰어가 제기한 질문에 답하는 것입니다.
질문에 답하기 위해 이 컨텍스트를 사용하세요:
{context}.
질문에 대답할 때 아래 지침을 따르세요:
1. 제공된 컨텍스트의 정보만 사용하세요.
2. 컨텍스트에 명시적으로 언급되지 않은 외부 정보를 도입하거나 가정하지 마세요.
3. 컨텍스트에는 각 개별 문서 상단에 소스가 포함되어 있습니다.
4. 관련 진술 옆에 이러한 소스를 답변에 포함하세요. 예를 들어, 소스 #1의 경우 [1]을 사용하세요.
5. 답변 하단에 소스를 순서대로 나열하세요. [1] 소스 1, [2] 소스 2 등
6. 소스가 '<Document source="assistant/docs/llama3_1.pdf" page="7"/>'인 경우 다음과 같이 나열하세요:
[1] assistant/docs/llama3_1.pdf, 7페이지
인용 시 괄호와 Document source 전문을 생략하세요.
"""3. 답변 생성 (Generate Answer)
분석가의 질문에 대한 답변은 웹 및 위키피디아 검색 결과를 사용해 생성됩니다.
generate_answer함수는 문맥(context)과 질문을 기반으로 전문가의 답변을 생성합니다.
def generate_answer(state: InterviewState):
# 분석가와 컨텍스트 가져오기
analyst = state["analyst"]
context = state["context"]
# 질문을 바탕으로 답변 생성
system_message = answer_instructions.format(goals=analyst.persona, context=context)
answer = llm.invoke([SystemMessage(content=system_message)] + state["messages"])
answer.name = "expert" # 전문가의 이름 지정
return {"messages": [answer]}-
context: 이전에 수집된 검색 결과들이 포함된 문맥 데이터로, 질문에 대한 답변을 작성하는 데 사용됩니다.
-
answer_instructions: 전문가가 컨텍스트와 분석가의 목표를 반영하여 정확하고 관련 있는 답변을 생성할 수 있도록 지침을 제공합니다.
- (참고)
answer_instructions은 위에서 정의되어 있습니다.
- (참고)
-
answer.name: 답변을 전문가로부터 온 메시지로 지정하여 인터뷰의 일관성을 유지합니다.
4. 인터뷰 저장 및 요약 (Save Interview)
인터뷰가 끝나면 모든 메시지를 하나의 텍스트로 변환하여 저장하는 save_interview 함수가 호출됩니다. 이 인터뷰 기록은 이후 최종 보고서 작성에 사용됩니다.
def save_interview(state: InterviewState):
# 메시지 가져오기
messages = state["messages"]
# 인터뷰 내용을 하나의 문자열로 변환
interview = get_buffer_string(messages)
# 인터뷰 내용을 상태에 저장
return {"interview": interview}- get_buffer_string: 인터뷰 대화를 하나의 텍스트 형식으로 변환하여 이후 단계에서 사용할 수 있도록 합니다.
🤔 get_buffer_string
get_buffer_string함수는 LangChain 라이브러리의 일부입니다. 구체적으로, 이 함수는 langchain_core.messages.utils 모듈에 정의되어 있습니다.- 목적: 일련의 메시지(Messages)를 문자열로 변환하고 하나의 문자열로 연결합니다
- 예제를 통해 어떻게 작동하는지 살펴보겠습니다.
from langchain_core import AIMessage, HumanMessage messages = [ HumanMessage(content="Hi, how are you?"), AIMessage(content="Good, how are you?"), ] result = get_buffer_string(messages) # 결과: "Human: Hi, how are you?\nAI: Good, how are you?"
- 위의 예제와 같이
get_buffer_string함수는 주어진 메시지 리스트를 하나의 문자열로 변환하며, 각 메시지에 대해prefix와content를 결합하여 출력합니다.
5. 라우팅 함수 (Route Messages)
질문과 답변을 주고받는 프로세스를 조율하기 위해 route_messages 함수를 사용합니다.
- 이 함수는 전문가가 특정한 응답 수에 도달했거나 분석가가 대화를 마치고자 하는 신호(“도움 주셔서 정말 감사합니다”)를 보냈을 때 인터뷰를 종료합니다.
def route_messages(state: InterviewState, name: str = "expert"):
# 메시지 가져오기
messages = state["messages"]
max_num_turns = state.get('max_num_turns', 2)
# 전문가 응답 수 확인
num_responses = len(
[m for m in messages if isinstance(m, AIMessage) and m.name == name]
)
# 응답이 최대 턴 수를 초과했거나 감사 메시지가 있을 경우 인터뷰 종료
if num_responses >= max_num_turns:
return 'save_interview'
last_question = messages[-2] # 마지막 질문 확인
if "도움 주셔서 정말 감사합니다" in last_question.content:
return 'save_interview'
return "ask_question"-
종료 조건:-
num_responses: 전문가의 응답 횟수를 확인하여 최대 응답 수에 도달하면 인터뷰를 종료하도록 설정합니다.
-
last_question: 분석가의 마지막 질문을 확인하여 대화 종료를 요청하는 메시지가 포함된 경우 인터뷰를 종료합니다.
-
6. write_section 함수
section_writer_instructions
-
section_writer_instructions는 전문 기술 작가가 보고서 섹션을 작성하는 데 필요한 세부 지침을 제공하여, 인터뷰에서 수집한 통찰을 명확하고 일관된 형식으로 정리할 수 있도록 돕습니다.- 이 과정은
Conduct Interview단계에서 수집된 정보를 바탕으로, 보고서의 각 섹션을 작성하는 데 중점을 둡니다. 주요 지침은 다음과 같습니다.
- 이 과정은
section_writer_instructions = """
당신은 전문 기술 작가입니다.
당신의 임무는 소스 문서 세트를 바탕으로 보고서의 짧고 이해하기 쉬운 섹션을 작성하는 것입니다.
1. 소스 문서의 내용 분석:
- 각 소스 문서의 이름은 <Document 태그와 함께 문서 시작 부분에 있습니다.
2. 마크다운 형식을 사용하여 보고서 구조 생성:
- 섹션 제목에는 ## 사용
- 하위 섹션 헤더에는 ### 사용
3. 다음 구조를 따라 보고서 작성:
a. 제목 (## 헤더)
b. 요약 (### 헤더)
c. 출처 (### 헤더)
4. 분석가의 관심 영역을 바탕으로 흥미로운 제목 만들기:
{focus}
5. 요약 섹션:
- 분석가의 관심 영역과 관련된 일반적인 배경/맥락으로 요약 시작
- 인터뷰에서 얻은 통찰 중 새롭거나 흥미롭거나 놀라운 점 강조
- 사용한 소스 문서의 번호 목록 생성
- 인터뷰어나 전문가의 이름 언급하지 않기
- 최대 400단어를 목표로 함
- 소스 문서의 정보를 바탕으로 보고서에 번호가 매겨진 출처 사용 (예: [1], [2])
6. 출처 섹션:
- 보고서에 사용된 모든 출처 포함
- 관련 웹사이트나 특정 문서 경로의 전체 링크 제공
- 각 출처를 줄바꿈으로 구분. 각 줄 끝에 두 개의 공백을 사용하여 마크다운에서 줄바꿈 생성.
- 다음과 같이 보일 것입니다:
### 출처
[1] 링크 또는 문서 이름
[2] 링크 또는 문서 이름
7. 출처를 반드시 결합하세요. 예를 들어 다음은 올바르지 않습니다:
[3] https://ai.meta.com/blog/meta-llama-3-1/
[4] https://ai.meta.com/blog/meta-llama-3-1/
중복된 출처가 없어야 합니다. 다음과 같이 간단히 표시해야 합니다:
[3] https://ai.meta.com/blog/meta-llama-3-1/
8. 최종 검토:
- 보고서가 필요한 구조를 따르는지 확인
- 보고서 제목 전에 서문을 포함하지 않음
- 모든 지침을 따랐는지 확인
"""write_section함수
def write_section(state: InterviewState):
""" 질문에 답변하는 노드 """
# 상태 가져오기
interview = state["interview"]
context = state["context"]
analyst = state["analyst"]
# 인터뷰에서 수집한 소스 문서(context) 또는 인터뷰 자체(interview)를 사용하여 섹션 작성
system_message = section_writer_instructions.format(focus=analyst.description)
section = llm.invoke(
[SystemMessage(content=system_message)]
+
[HumanMessage(content=f"이 소스를 사용하여 섹션을 작성하세요: {context}")])
# 상태에 추가
return {"sections": [section.content]}-
목적: 이 함수는
InterviewState에서 수집한 인터뷰 정보를 사용하여 최종 보고서의 각 섹션을 작성합니다. -
상태 요소 가져오기:
interview: 인터뷰 기록을 가져옵니다.context: 인터뷰에서 생성된 소스 문서나 참고 자료를 가져옵니다.analyst: 분석가의 정보를 가져와서 해당 분석가가 가진 특정 목표(analyst.description)를 섹션 작성에 반영합니다.
-
섹션 작성:
section_writer_instructions의focus를 분석가의 설명(analyst.description)으로 설정합니다.section_writer_instructions는 보고서가 일관성 있게 작성되도록 지침을 포함하고 있습니다.SystemMessage는 섹션 작성을 위한 지침을 전달하고,HumanMessage는 생성된context를 포함하여 AI 모델에 전달합니다.- 이를 통해 인터뷰 내용을 반영한 섹션이 생성됩니다.
-
섹션 추가:
sections라는 키에 해당 섹션을 추가하여 상태에 반환합니다.- 이 섹션은 보고서 작성의 최종 단계로 이어집니다.
StateGraph정의 및 노드 추가
interview_builder = StateGraph(InterviewState)
interview_builder.add_node("ask_question", generate_question)
interview_builder.add_node("search_web", search_web)
interview_builder.add_node("search_wikipedia", search_wikipedia)
interview_builder.add_node("answer_question", generate_answer)
interview_builder.add_node("save_interview", save_interview)
interview_builder.add_node("write_section", write_section)StateGraph정의:InterviewState를 사용하여 상태 그래프를 만듭니다. 이 그래프는write_section까지 이어지는 인터뷰 프로세스의 모든 단계별 노드를 포함합니다.- 노드 추가: 각 단계의 주요 기능을 담당하는 노드를 추가합니다.
ask_question: 인터뷰 질문을 생성하는 단계입니다.search_web및search_wikipedia: 필요한 자료를 검색하는 단계입니다.answer_question: 전문가의 답변을 생성합니다.save_interview: 인터뷰 내용을 저장합니다.write_section: 인터뷰의 요점을 섹션으로 작성합니다.
- 인터뷰 단계의 흐름 정의
# 흐름
interview_builder.add_edge(START, "ask_question")
interview_builder.add_edge("ask_question", "search_web")
interview_builder.add_edge("ask_question", "search_wikipedia")
interview_builder.add_edge("search_web", "answer_question")
interview_builder.add_edge("search_wikipedia", "answer_question")
interview_builder.add_conditional_edges("answer_question", route_messages, ['ask_question','save_interview'])
interview_builder.add_edge("save_interview", "write_section")
interview_builder.add_edge("write_section", END)- 흐름 정의:
START에서ask_question로 연결하여 인터뷰 질문을 시작합니다.- 질문 후
search_web또는search_wikipedia로 진행해 관련 정보를 검색합니다. - 각 검색 결과는
answer_question노드로 전달되어 인터뷰의 답변으로 이어집니다.
- 조건부 엣지:
answer_question에서route_messages를 통해 대화를 계속 진행할지(ask_question으로 돌아감) 아니면 인터뷰 저장 단계(save_interview)로 넘어갈지를 결정합니다.
- 마지막 단계:
- 인터뷰가 저장되면
write_section으로 넘어가 보고서의 섹션을 작성한 후 종료(END)됩니다.
- 인터뷰가 저장되면
- 그래프 컴파일 및 인터뷰 실행
# 인터뷰
memory = MemorySaver()
interview_graph = interview_builder.compile(checkpointer=memory).with_config(run_name="인터뷰 수행")MemorySaver: 인터뷰 중간 상태를 저장하여, 인터뷰 진행 중에 발생하는 상태 변화를 체크포인트로 기록합니다.- 그래프 컴파일: 인터뷰 수행을 위해 전체 그래프를 컴파일하며, 이를
interview_graph로 저장합니다.
- 그래프 시각화
# 보기
display(Image(interview_graph.get_graph().draw_mermaid_png()))- 그래프 시각화:
draw_mermaid_png()메서드를 사용하여 상태 그래프를 시각화하여 흐름을 확인할 수 있습니다.
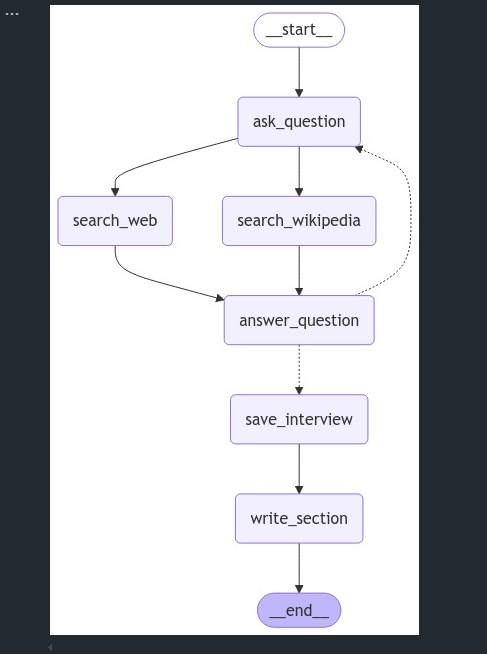
(중간점검) 분석가 한명을 선택해서 글 작성을 요청할 수 있습니다.
- 한 명을 선택해서 해당 주제에 대한 글을 요청해보도록 하겠습니다.
# 분석가 한 명 선택 analysts[0]Analyst( affiliation='Tech Innovators Inc.', name='Dr. Emily Zhang', role='AI Research Scientist', description='Dr. Zhang focuses on the development and optimization of large language models (LLMs). Her interest lies in improving model efficiency and scalability.' )
- 글 작성 요청 후 결과를 한번 살펴보겠습니다.
from IPython.display import Markdown messages = [HumanMessage(f"당신이 {topic}에 대한 글을 쓰고 있다고 했나요?")] thread = {"configurable": {"thread_id": "1"}} interview = interview_graph.invoke({"analyst": analysts[0], "messages": messages, "max_num_turns": 3}, thread) Markdown(interview['sections'][0])
- 엄청 그럴 듯하게 LLMOps에 대한 글을 작성하는 것을 볼 수 있습니다. 또한 앞에 세운 라우팅 규칙에 의해
max_num_turns3회까지 돌고, 답변을 생성하는 것을 확인할 수 있습니다.

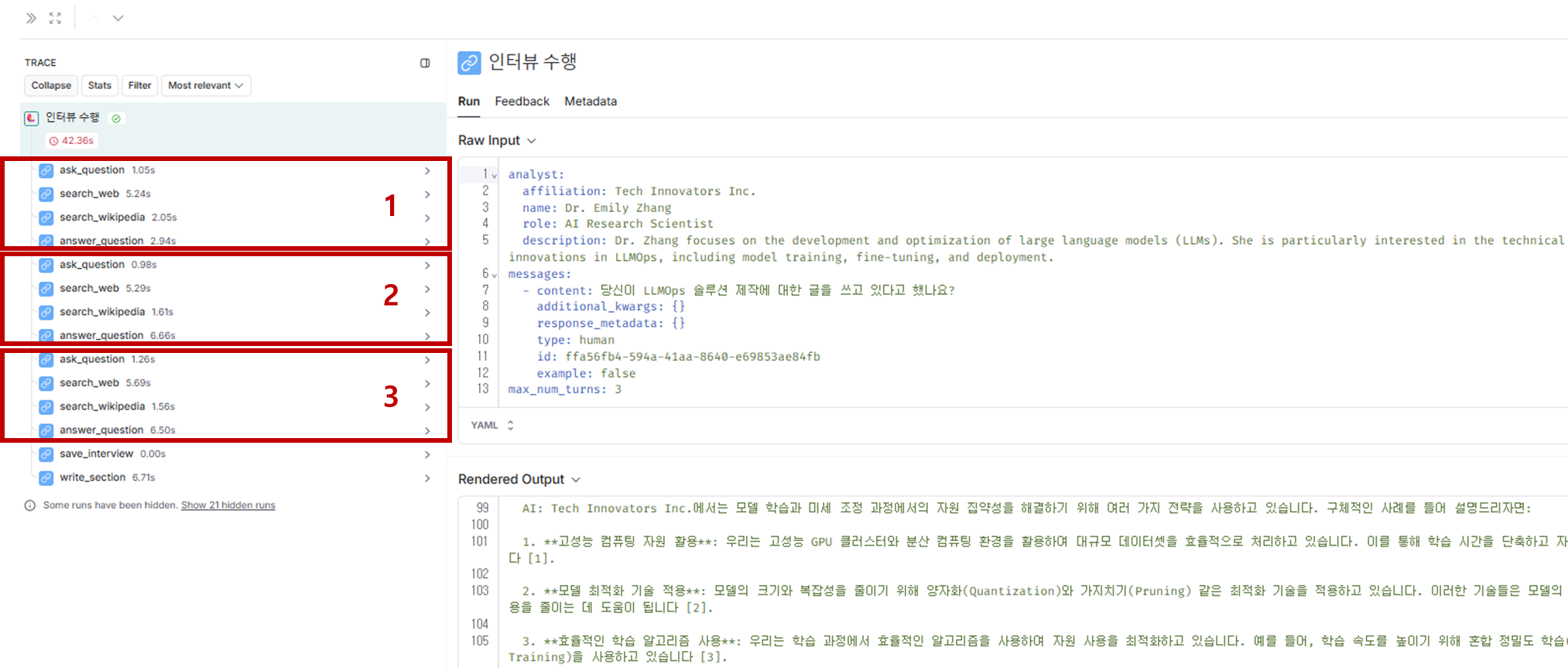
(결과해석) 출력 결과를 좀 더 세분화해서 해석해볼까요?
- 출력된 결과를 보면, 대화 시나리오와 문서 기반 섹션 작성이 정상적으로 작동한 것 같습니다.
- 구체적으로 확인해보면, 주요 절차가 다음과 같이 순차적으로 실행되었습니다.
- 대화 진행: 대화 흐름이
HumanMessage와AIMessage의 반복으로 자연스럽게 이어졌습니다. 각HumanMessage에 대해AIMessage가 논리적인 답변을 제공하고 있으며, LLMOps 관련 주요 개념과 구현 도전 과제들이 설명되었습니다.- 문서 컨텍스트 활용:
context로 지정된 문서들이section_writer_instructions에 따라 요약 및 문서 구성을 위해 사용되었습니다.write_section함수에서 문서 내용이 섹션에 적절히 반영되어,LLMOps의 주요 개념과 적용 사례 및 모범 사례가 포함된 요약이 생성되었습니다.- 섹션 작성:
sections필드에 저장된 보고서는##와###형식을 사용해 구조적으로 작성되었고, 출처 목록이 포함되어 있습니다. 여기서 각 출처가[1],[2]등으로 제대로 링크되었으며, 모범 사례와 LLMOps의 주요 구성 요소도 요약에 포함되어 있습니다.
이제 각각의 Analyst들을 평행하게 그래프 상에서 실행하기 위해 다음을 수행할 수 있습니다.
✔️ Parallelize 인터뷰: Map-Reduce 패턴 적용
이 구조에서는 인터뷰를 병렬로 수행하여 시간을 절약하고, 최종적으로 리포트를 작성하기 위해 결과를 결합하는 방식을 사용합니다.
-
맵(Map) 단계:
initiate_all_interviews함수가Send()API를 사용하여 병렬로 인터뷰를 실행하는 역할을 합니다.Send()는 각 분석가와 전문가 간 인터뷰 세션을 독립적으로 실행하며, 각 인터뷰가 별도로 진행되기 때문에 여러 인터뷰를 병렬로 실행하여 시간 효율성을 높입니다.- 이 단계에서는 각 인터뷰의 결과가
ResearchGraphState에sections리스트에 저장됩니다.
-
리듀스(Reduce) 단계:
write_report함수는sections리스트에 저장된 모든 인터뷰 세션을 결합하여 최종 보고서 내용을 생성합니다.- 이후
write_introduction과write_conclusion함수가 각각 서론과 결론을 작성하여 최종 보고서에 포함됩니다. - 최종 단계인
finalize_report에서는 서론, 본문, 결론을 하나의 완성된 보고서로 합쳐 리포트를 완성합니다.
1. ResearchGraphState 클래스 정의
- 역할: 연구 주제, 분석가 수, 피드백, 보고서 서론 및 결론 등 상태 정보를 추적하여, 전체 실행 흐름 중 데이터를 쉽게 관리하고 참조할 수 있게 합니다.
import operator
from typing import List, Annotated
from typing_extensions import TypedDict
class ResearchGraphState(TypedDict):
topic: str # 연구 주제
max_analysts: int # 분석가 수
human_analyst_feedback: str # 인간 피드백
analysts: List[Analyst] # 질문하는 분석가
sections: Annotated[list, operator.add] # Send() API 키
introduction: str # 최종 보고서의 서론
content: str # 최종 보고서의 내용
conclusion: str # 최종 보고서의 결론
final_report: str # 최종 보고서
- TypedDict로 지정하여 상태가 특정한 키와 값을 갖도록 강제합니다.
- Annotated로 여러 sections를 추가할 때 리스트 형태로 병합하여 저장하도록 합니다.
2. initiate_all_interviews 함수: 인터뷰 병렬화 실행
- 역할: 인터뷰를 병렬로 수행하는 “맵” 단계.
def initiate_all_interviews(state: ResearchGraphState):
""" 이는 Send API를 사용하여 각 인터뷰 서브그래프를 실행하는 "맵" 단계입니다 """
# 인간 피드백 확인
human_analyst_feedback=state.get('human_analyst_feedback')
if human_analyst_feedback:
# create_analysts로 돌아가기
return "create_analysts"
# 그렇지 않으면 Send() API를 통해 인터뷰를 병렬로 시작
else:
topic = state["topic"]
return [Send("conduct_interview", {"analyst": analyst,
"messages": [HumanMessage(
content=f"당신이 {topic}에 대한 글을 쓰고 있다고 했나요?"
)
]}) for analyst in state["analysts"]]human_analyst_feedback이 있을 경우, 피드백을 반영해create_analysts로 돌아가 분석가를 새로 생성합니다.- 피드백이 없으면
Send()API를 사용해 인터뷰를 각 분석가와 독립적으로 병렬로 시작합니다.
report_writer_instructions
- 해당 지침은 분석가 팀이 제공한 메모를 바탕으로 보고서 본문을 작성하는 데 필요한 세부사항을 안내합니다.
- 이 지침은 보고서 작성자가 일관성 있고 출처가 명확히 표시된 보고서를 작성할 수 있도록 하며, 제공된 자료를 기반으로 통찰력 있는 요약을 만들도록 합니다.
report_writer_instructions = """
당신은 다음 전체 주제에 대한 보고서를 작성하는 기술 작가입니다:
{topic}
당신에게는 분석가 팀이 있습니다. 각 분석가는 두 가지 일을 했습니다:
1. 특정 하위 주제에 대해 전문가와 인터뷰를 진행했습니다.
2. 그들의 발견을 메모로 작성했습니다.
당신의 임무:
1. 분석가들의 메모 모음이 주어질 것입니다.
2. 각 메모의 통찰을 신중히 생각해보세요.
3. 모든 메모의 중심 아이디어를 하나의 간결한 전체 요약으로 통합하세요.
4. 각 메모의 중심점을 하나의 일관된 내러티브로 요약하세요.
보고서 형식:
1. 마크다운 형식을 사용하세요.
2. 보고서에 서문을 포함하지 마세요.
3. 소제목을 사용하지 마세요.
4. 단일 제목 헤더로 보고서를 시작하세요: ## 통찰
5. 보고서에 분석가 이름을 언급하지 마세요.
6. 메모에 있는 인용을 보존하세요. 인용은 [1] 또는 [2]와 같이 대괄호 안에 표시됩니다.
7. 최종 통합 출처 목록을 만들고 '## 출처' 헤더가 있는 출처 섹션에 추가하세요.
8. 출처를 순서대로 나열하고 반복하지 마세요.
[1] 출처 1
[2] 출처 2
다음은 보고서 작성에 사용할 분석가들의 메모입니다:
{context}
"""3. write_report 함수: 보고서 작성
- 역할:
sections에 있는 인터뷰 내용을 결합하여 최종 보고서를 작성.
def write_report(state: ResearchGraphState):
# 전체 섹션 세트
sections = state["sections"]
topic = state["topic"]
# 모든 섹션을 하나로 연결
formatted_str_sections = "\n\n".join([f"{section}" for section in sections])
# 섹션을 최종 보고서로 요약
system_message = report_writer_instructions.format(topic=topic, context=formatted_str_sections)
report = llm.invoke([SystemMessage(content=system_message)]+[HumanMessage(content=f"이 메모를 바탕으로 보고서를 작성하세요.")])
return {"content": report.content}report_writer_instructions에서 주어진 양식에 따라llm.invoke()를 통해 보고서 본문을 생성.- 최종 보고서 본문은
"content"필드에 저장됩니다.
intro_conclusion_instructions
- 해당 지침은 보고서에 서론 또는 결론을 작성하는 데 필요한 세부 지침을 제공합니다. 보고서 전체를 요약하고 방향성을 제공하거나, 전체 보고서 내용을 정리하는 데 사용됩니다.
- 이 지침을 통해 작성자는 보고서 전체 내용을 간결하고 설득력 있게 정리하여, 독자들이 보고서의 주요 내용을 빠르게 파악하거나 결론을 통해 정리된 통찰을 얻게 합니다.
intro_conclusion_instructions = """
당신은 {topic}에 대한 보고서를 마무리하는 기술 작가입니다.
보고서의 모든 섹션이 주어질 것입니다.
당신의 임무는 간결하고 설득력 있는 서론 또는 결론 섹션을 작성하는 것입니다.
사용자가 서론 또는 결론 중 어느 것을 작성할지 지시할 것입니다.
두 섹션 모두 서문을 포함하지 마세요.
약 100단어를 목표로 하여 보고서의 모든 섹션을 간결하게 미리 보여주거나(서론의 경우) 요약하세요(결론의 경우).
마크다운 형식을 사용하세요.
서론의 경우, 매력적인 제목을 만들고 # 헤더를 제목에 사용하세요.
서론의 경우, ## 서론을 섹션 헤더로 사용하세요.
결론의 경우, ## 결론을 섹션 헤더로 사용하세요.
다음은 작성 시 참고할 섹션들입니다: {formatted_str_sections}
"""4. write_introduction 및 write_conclusion 함수: 서론 및 결론 작성
- 역할: 보고서에 서론 및 결론을 추가해 구조화.
def write_introduction(state: ResearchGraphState):
# 전체 섹션 세트
sections = state["sections"]
topic = state["topic"]
# 모든 섹션을 하나로 연결
formatted_str_sections = "\n\n".join([f"{section}" for section in sections])
# 섹션을 최종 보고서로 요약
instructions = intro_conclusion_instructions.format(topic=topic, formatted_str_sections=formatted_str_sections)
intro = llm.invoke([instructions]+[HumanMessage(content=f"보고서 서론을 작성하세요")])
return {"introduction": intro.content}def write_conclusion(state: ResearchGraphState):
# 전체 섹션 세트
sections = state["sections"]
topic = state["topic"]
# 모든 섹션을 하나로 연결
formatted_str_sections = "\n\n".join([f"{section}" for section in sections])
# 섹션을 최종 보고서로 요약
instructions = intro_conclusion_instructions.format(topic=topic, formatted_str_sections=formatted_str_sections)
conclusion = llm.invoke([instructions]+[HumanMessage(content=f"보고서 결론을 작성하세요")])
return {"conclusion": conclusion.content}intro_conclusion_instructions에 따라, 서론은 보고서의 간결한 요약을, 결론은 요약 및 마무리 내용을 담습니다.write_introduction및write_conclusion은 각각introduction,conclusion필드에 저장.
5. finalize_report 함수: 최종 보고서 결합 및 완료
- 역할: 서론, 본문, 결론을 하나의 완성된 보고서로 결합하는 “리듀스” 단계.
def finalize_report(state: ResearchGraphState):
""" 이는 모든 섹션을 수집하고 결합한 다음 서론/결론을 작성하기 위해 그들을 반영하는 "리듀스" 단계입니다 """
# 전체 최종 보고서 저장
content = state["content"]
if content.startswith("## 통찰"):
content = content.strip("## 통찰")
if "## 출처" in content:
try:
content, sources = content.split("\n## 출처\n")
except:
sources = None
else:
sources = None
final_report = state["introduction"] + "\n\n---\n\n" + content + "\n\n---\n\n" + state["conclusion"]
if sources is not None:
final_report += "\n\n## 출처\n" + sources
return {"final_report": final_report}content,introduction,conclusion,sources를 합쳐 최종 보고서(final_report)에 저장합니다.
6. StateGraph 노드 및 엣지 정의
- 역할: 인터뷰 생성, 피드백 처리, 인터뷰 진행, 보고서 작성, 서론 및 결론 작성, 최종 보고서 완성을 위한 노드와 엣지 정의.
# 노드와 엣지 추가
builder = StateGraph(ResearchGraphState)
builder.add_node("create_analysts", create_analysts)
builder.add_node("human_feedback", human_feedback)
builder.add_node("conduct_interview", interview_builder.compile())
builder.add_node("write_report",write_report)
builder.add_node("write_introduction",write_introduction)
builder.add_node("write_conclusion",write_conclusion)
builder.add_node("finalize_report",finalize_report)
# 로직
builder.add_edge(START, "create_analysts")
builder.add_edge("create_analysts", "human_feedback")
builder.add_conditional_edges("human_feedback", initiate_all_interviews, ["create_analysts", "conduct_interview"])
builder.add_edge("conduct_interview", "write_report")
builder.add_edge("conduct_interview", "write_introduction")
builder.add_edge("conduct_interview", "write_conclusion")
builder.add_edge(["write_conclusion", "write_report", "write_introduction"], "finalize_report")
builder.add_edge("finalize_report", END)add_conditional_edges로human_feedback조건을 충족할 경우 새로운 분석가를 생성하거나 인터뷰를 시작하도록 구성.- 여기서
interview_builder를 서브그래프로 처리한 방식은 인터뷰 수행 과정을 독립적인 그래프로 구성하여 모듈화하고, 이를 주 그래프인 StateGraph의 특정 노드로 컴파일하여 재사용한 것입니다.- 이 과정은 복잡한 워크플로우를 분리하여 관리할 수 있게 하고, StateGraph의 노드 간 단계별 흐름을 더 쉽게 설정할 수 있도록 도와줍니다.
interview_builder는 인터뷰 수행의 각 단계를 포함하는 작은 그래프로, 독립적인 StateGraph 인스턴스로 작성됩니다.interview_builder서브그래프는 이전 단계에서 만든ask_question,search_web,search_wikipedia,answer_question,save_interview,write_section노드와 이들을 잇는 엣지로 구성되어, 인터뷰와 관련된 모든 로직을 관리합니다.
7. 그래프 실행 및 확인
- 역할: 그래프를 컴파일하고 각 단계의 상태를 시각화하여 검사합니다.
# 컴파일
memory = MemorySaver()
graph = builder.compile(interrupt_before=['human_feedback'], checkpointer=memory)
display(Image(graph.get_graph(xray=1).draw_mermaid_png()))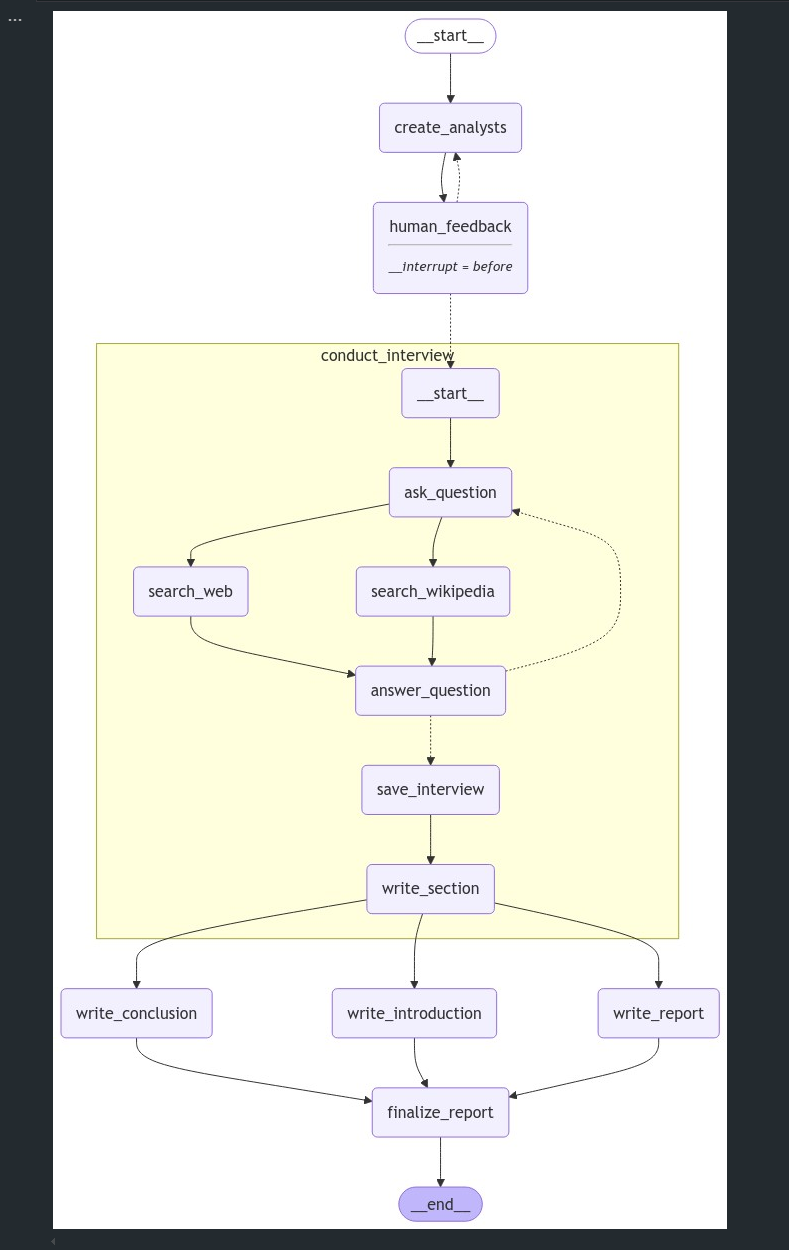
# 입력
max_analysts = 3
topic = "LLMOps 플랫폼 구축"
thread = {"configurable": {"thread_id": "1"}}
# 첫 번째 중단까지 그래프 실행
for event in graph.stream({"topic":topic,
"max_analysts":max_analysts},
thread,
stream_mode="values"):
analysts = event.get('analysts', '')
if analysts:
for analyst in analysts:
print(f"이름: {analyst.name}")
print(f"소속: {analyst.affiliation}")
print(f"역할: {analyst.role}")
print(f"설명: {analyst.description}")
print("-" * 50) graph.stream으로 그래프가 흐름에 따라 단계별로 진행되며, 상태에 저장된 분석가 정보도 출력됩니다.
# 나머지도 끝까지 실행해줍니다
graph.update_state(thread, {"human_analyst_feedback":
None}, as_node="human_feedback")
# 계속
for event in graph.stream(None, thread, stream_mode="updates"):
print("--노드--")
node_name = next(iter(event.keys()))
print(node_name)
- 의도한 것처럼
conduct_interview들이 병렬적으로 수행되고,write 작업들이 수행된 뒤에,finalize_report이 수행되는 것을 확인할 수 있습니다.
--노드--
conduct_interview
--노드--
conduct_interview
--노드--
conduct_interview
--노드--
write_introduction
--노드--
write_conclusion
--노드--
write_report
--노드--
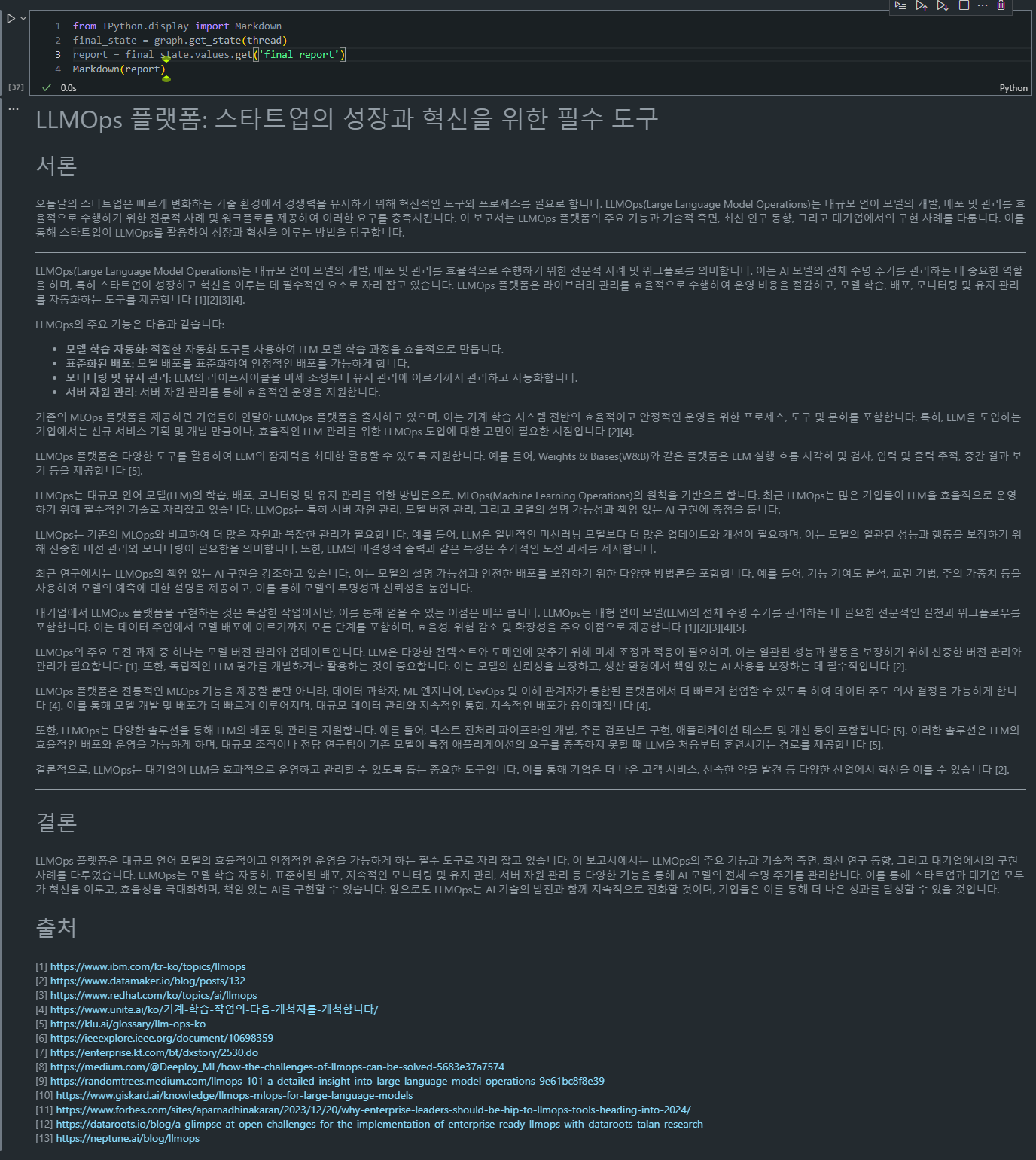
finalize_report8. 최종 보고서 결과 출력
- 역할: 최종 보고서를 Markdown 형식으로 출력.
from IPython.display import Markdown
final_state = graph.get_state(thread)
report = final_state.values.get('final_report')
Markdown(report)final_report에 저장된 최종 보고서를 시각화하여, 구조가 완성된 보고서를 확인할 수 있습니다.