안녕하세요! 12 Days of OpenAI의 마지막 날, Day 12에 오신 것을 환영합니다!

Greg Kamradt(ARC Prize Foundation), Mark Chen(OpenAI), Sam Altman(OpenAI)
오늘은 OpenAI가 발표한 최신 AI 모델인 o3와 o3-mini의 주요 성과와 혁신적인 기능을 심층적으로 소개합니다.
이 업데이트는 AI 기술의 한계를 확장하며, 더 복잡하고 다양한 작업을 수행할 수 있는 가능성을 열었습니다. 🎉
1. OpenAI o3와 o3-mini 소개
이번에 공개된 o3와 o3-mini는 AI 기술의 정점을 보여주는 모델로, 고도의 문제 해결 능력과 효율성을 겸비하고 있습니다. 이 모델들은 코딩, 수학, 과학 등 여러 분야에서 우수한 성능을 입증하며, AI의 실질적인 응용 가능성을 크게 확장했습니다.
-
o3: 복잡한 기술적 문제를 해결하는 데 중점을 둔 최첨단 AI 모델로, 수학적 사고와 프로그래밍 기술에서 독보적인 성과를 기록했습니다.
-
o3-mini: 비용 효율성과 성능을 모두 고려하여 설계된 모델로, 다양한 작업 환경에서 활용 가능한 적응형 사고 시간(Adaptive Thinking Time) 기능을 지원합니다.
성능 개요
-
새로운 벤치마크에서의 성과:
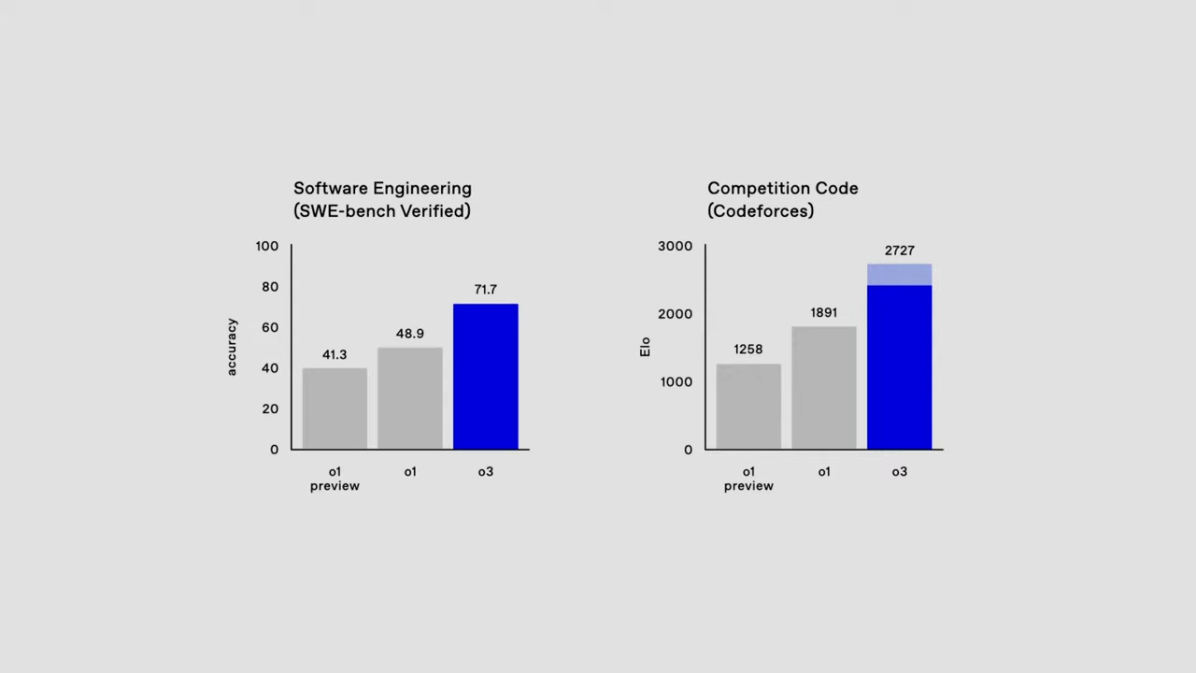
- Software Engineering(SWE) 벤치마크에서 71.7% 정확도 기록
- Codeforces 코딩 대회에서 ELO 2727 달성
-
수학과 과학 분야에서의 뛰어난 성과:
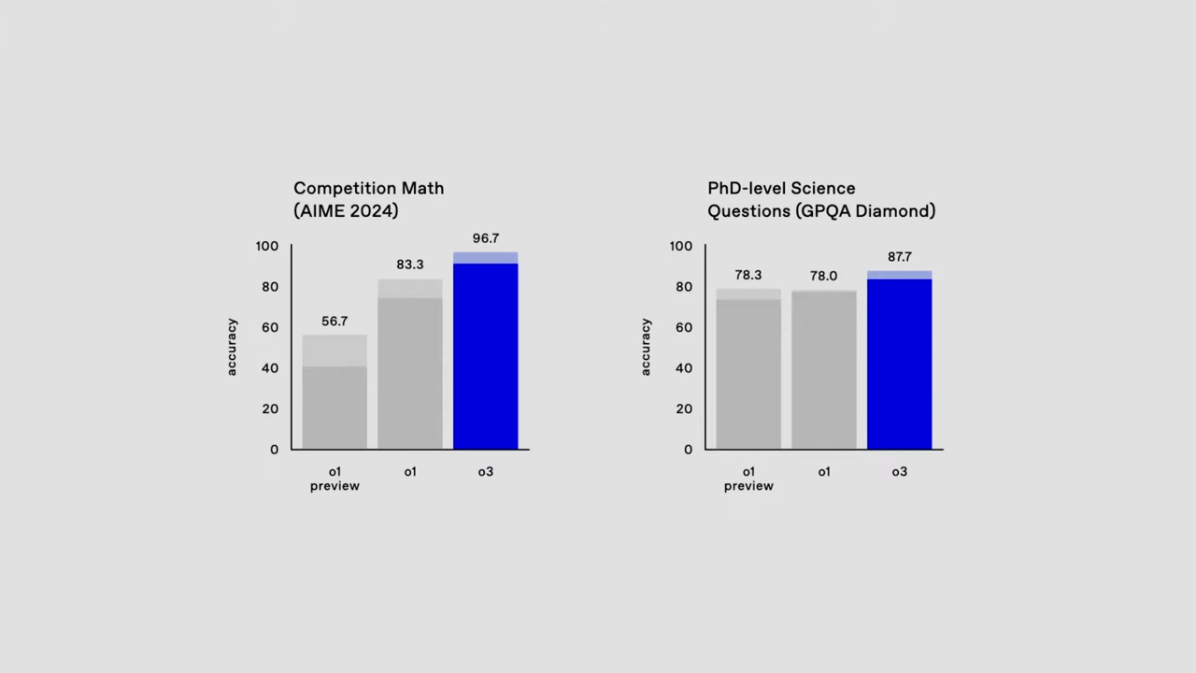
- AIME 2024(수학 대회): 96.7% 정확도
- PhD 수준 과학 질문(GPQA Diamond): 87.7% 정확도
-
ARC(Abstraction and Reasoning Corpus) 벤치마크의 새로운 기록:
- ARC AGI 평가에서 75.7% (일반 컴퓨팅), 87.5% (고성능 컴퓨팅) 기록

이 모델들의 성과는 AI의 기술적 발전이 실제 응용에서 얼마나 큰 가치를 창출할 수 있는지 보여줍니다.
일반 컴퓨팅과 고성능 컴퓨팅의 차이는 아래 X post에서 살펴보실 수 있습니다.

2. 벤치마크 결과 분석
1) 소프트웨어 코딩 벤치마크 (SWE-bench)
SWE 벤치마크는 실제 소프트웨어 개발 과제를 기반으로 하며, o3는 이전 모델(o1) 대비 20% 이상의 성능 향상을 기록했습니다. 이는 o3가 소프트웨어 환경에서의 AI 적용 가능성을 획기적으로 증명한 사례입니다. 이 성과는 AI가 실제 개발 환경에서 효율적으로 활용될 수 있는 가능성을 열어줍니다.

2) 수학 및 과학 벤치마크
- AIME 2024: 미국 수학 올림피아드 진출 시험에서 o3는 거의 완벽에 가까운 96.7% 정확도를 기록하며, 인간 전문가 수준을 뛰어넘는 성과를 보였습니다.
-
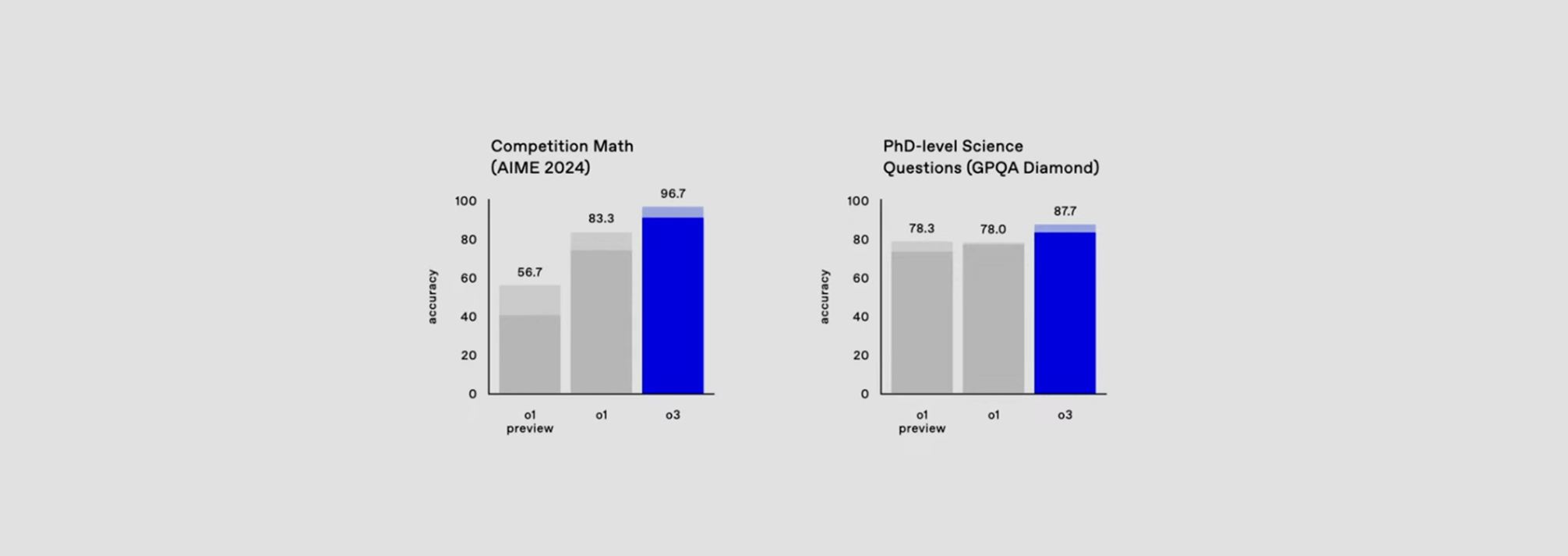
GPQA Diamond: 박사 수준 과학 질문에 대한 평가에서 o3는 **87.7%**의 정확도를 달성하며, 이전 모델 대비 10% 향상된 결과를 보여주었습니다.

이는 AI가 과학적 질문에 대한 정밀한 응답을 제공할 수 있는 능력을 입증합니다.
3) Research Math: EpochAI Frontier Math
가장 도전적인 수학 벤치마크 중 하나인 EpochAI Frontier Math에서 o3는 25.2% 정확도를 기록했습니다.

이 벤치마크는 전문가 수준의 수학 문제 해결 능력을 평가하며, AI 모델이 복잡한 문제를 해결하는 데 있어 탁월한 잠재력을 가지고 있음을 보여줍니다.
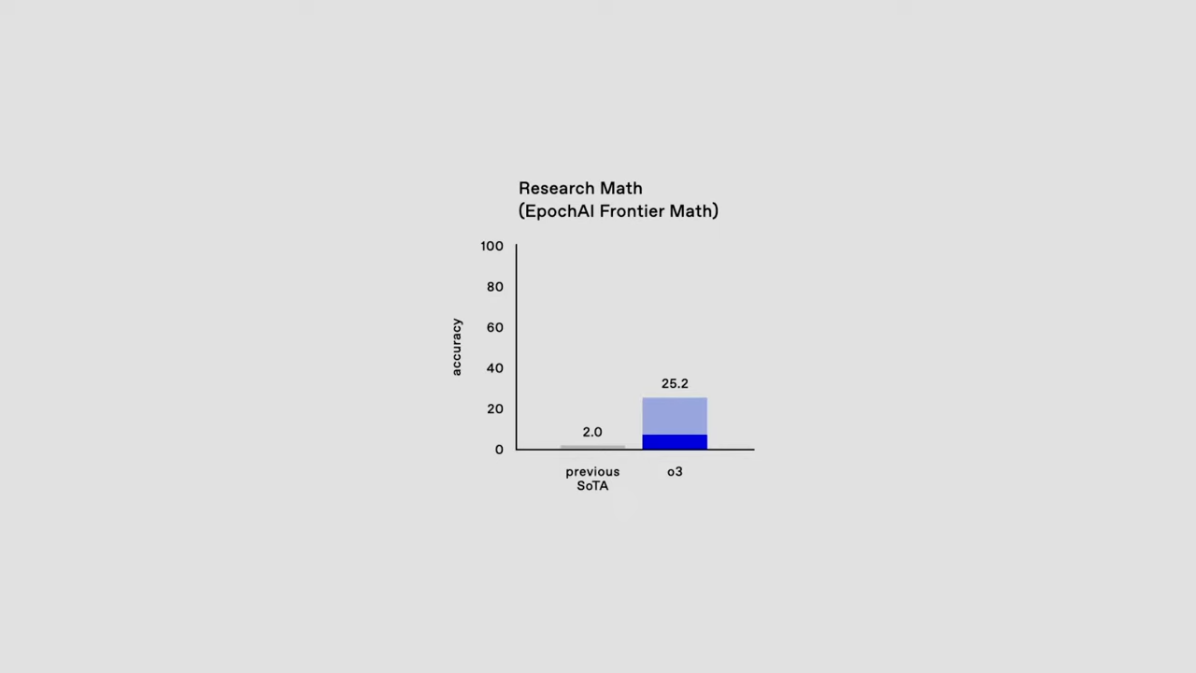
기존 AI 모델들이 2% 미만의 정확도를 보인 점과 비교하면, o3의 성과는 혁신적입니다.
4) ARC Prize Foundation: 새로운 AGI 벤치마크
ARC AGI(Abstraction and Reasoning Corpus) 벤치마크는 AI의 일반화 능력을 평가하기 위해 개발된 테스트입니다.

- o3는 ARC AGI 평가에서 인간 전문가 수준(85%)을 초과한 87.5%를 기록하며 새로운 표준을 세웠습니다. 이는 AI가 새로운 기술을 학습하고 일반화하여 적용할 수 있는 능력을 보여주는 중요한 성과입니다.
ARC 벤치마크는 AI의 학습 능력뿐만 아니라 창의적인 문제 해결 능력을 평가하기 위한 것으로, o3는 이를 통해 AI의 미래 가능성을 입증했습니다.
-
ARC 벤치마크는 아래와 같은 문항들로 구성되어 있습니다.
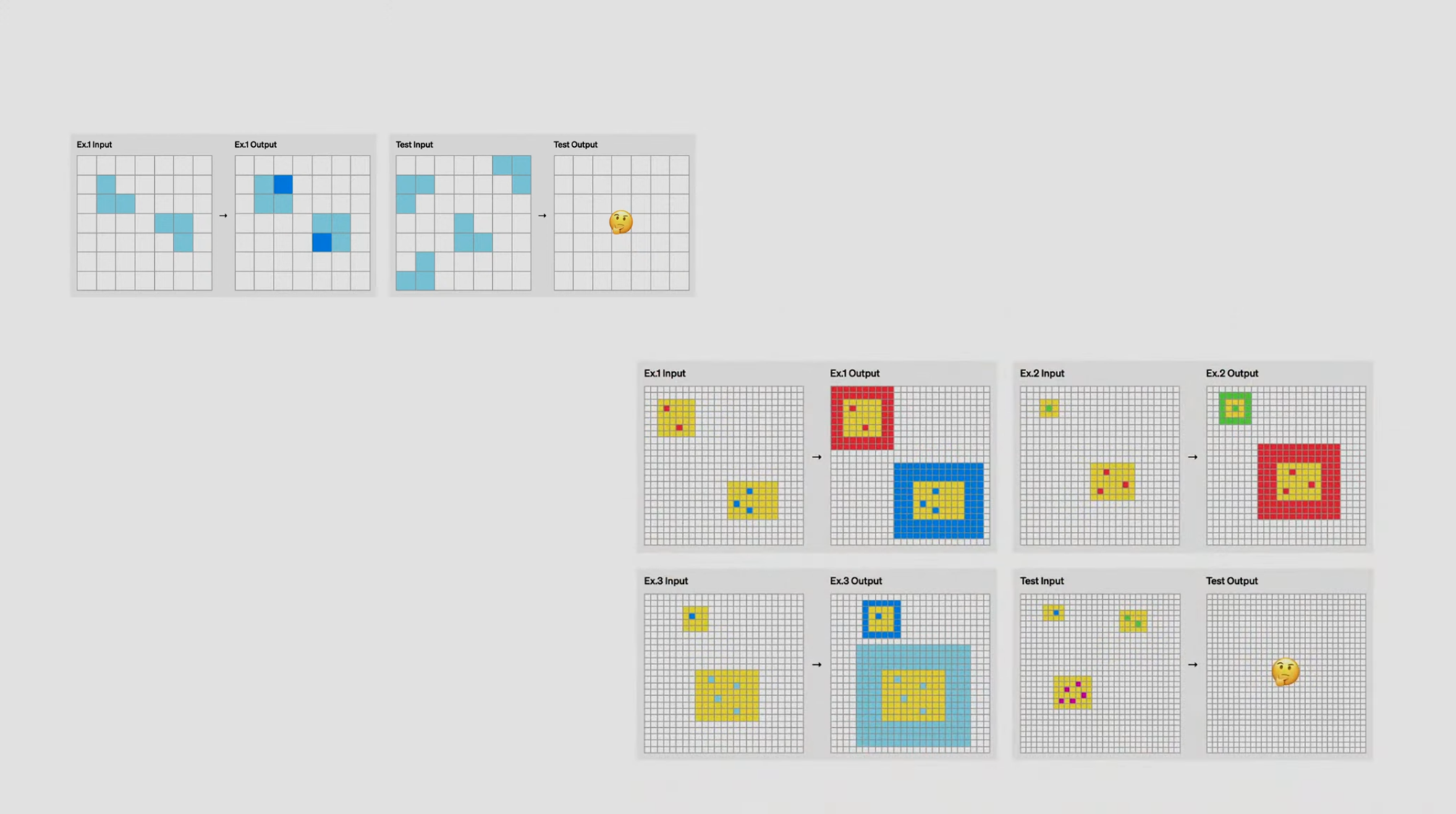
-
위에 예시가 쉬워서 "에이~ 쉽네" 했다가.. 다른 문제 보고 "오호라~🤔" 했던 1인 (Samples are from https://arcprize.org/)

3. o3-mini: 비용 효율성과 성능의 균형

Hongyu Ren(OpenAI), Mark Chen(OpenAI), Sam Altman(OpenAI)
o3-mini는 다양한 작업 환경에서 뛰어난 성능을 발휘하면서도 비용 효율성을 극대화한 모델입니다.
다음과 같은 특징이 있습니다:
- 적응형 사고 시간: 사용자는 문제의 난이도에 따라 사고 시간을 조정하여 최적의 결과를 얻을 수 있습니다.
- 낮은 비용, 높은 성능: 기존 모델(o1) 대비 실행 비용을 대폭 줄이면서도 성능은 개선되었습니다.
- 다양한 응용 가능성: 교육, 소프트웨어 개발, 연구 등 다양한 환경에서 활용할 수 있도록 설계되었습니다.
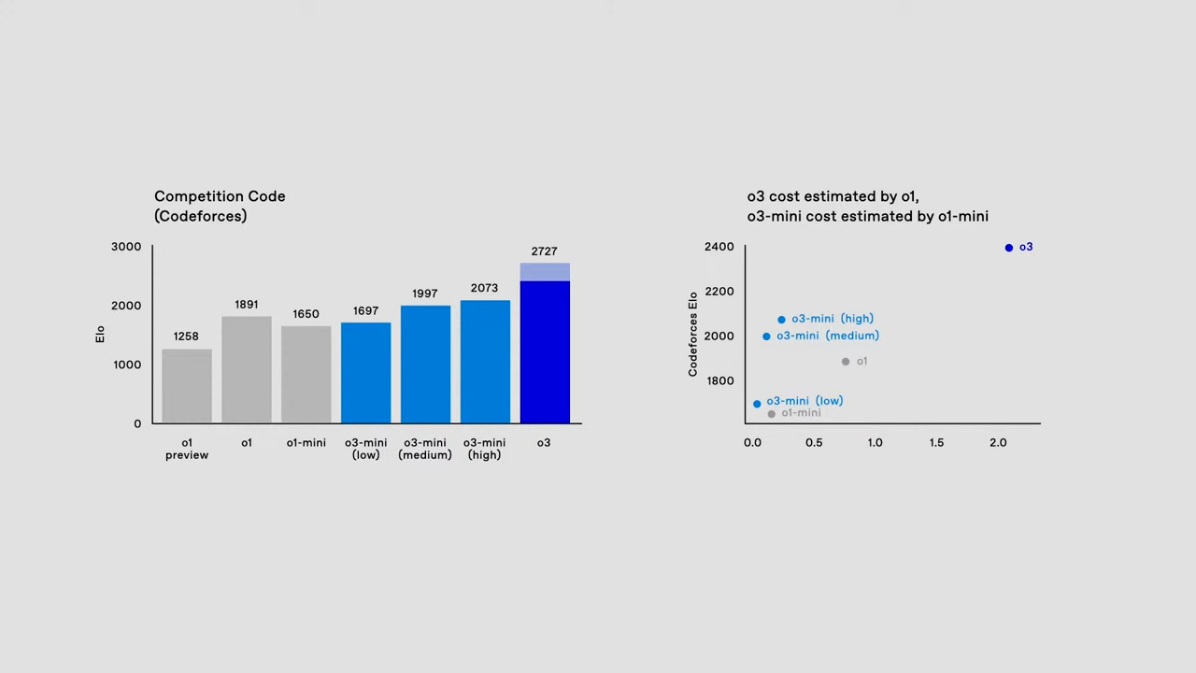
1) Codeforces 코딩 성능
o3-mini는 Codeforces 벤치마크에서 ELO 점수 1697 (low), 1997 (medium), 2073 (high)을 기록하며 기존 모델 대비 뛰어난 성능을 입증했습니다.
- 특히, 고성능 설정에서 o1-mini보다 뛰어난 성과를 보여주며, 최적의 비용 대비 성능 비율을 달성했습니다.
2) 비용 효율성 비교
오른쪽 그래프는 o3와 o3-mini가 다양한 설정에서 얼마나 효율적으로 작동하는지를 보여줍니다.
- 낮은 비용으로도 우수한 성능을 기록한 o3-mini는 사용자가 필요에 따라 성능과 비용의 균형을 맞출 수 있도록 설계되었습니다.
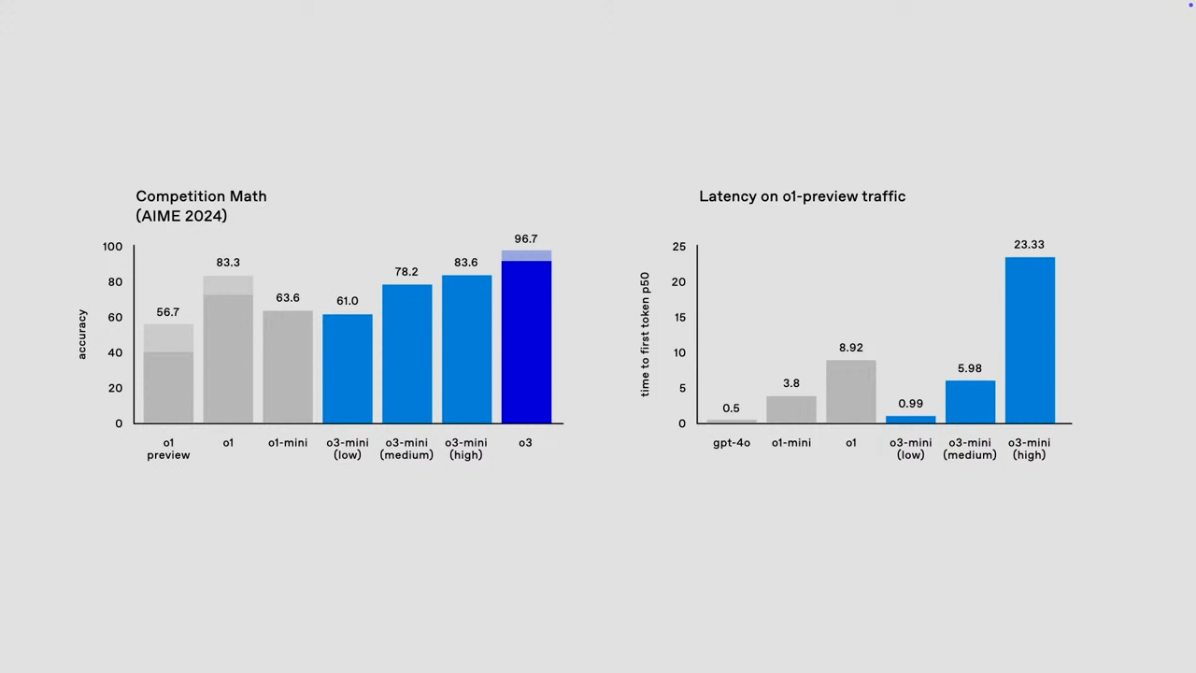
3) AIME 2024 성능과 레이턴시
-
AIME 2024에서 o3-mini는 low, medium, high 설정별로 각각 61.0%, 78.2%, 83.6%의 정확도를 기록하며 o1-mini보다 높은 성능을 보였습니다.
-
레이턴시 측면에서 o3-mini는 low 설정에서 가장 빠른 응답 시간을 제공하며, 고성능 설정(high)에서도 여전히 높은 정확도를 유지합니다.
4. API 호출 관련 기능 성능 분석
o3와 o3-mini는 다양한 API 호출 시 더 효율적이고 구조화된 출력을 제공합니다.
아래 그래프는 모델의 내부 함수 호출과 출력 구조화에서의 성능을 보여줍니다.
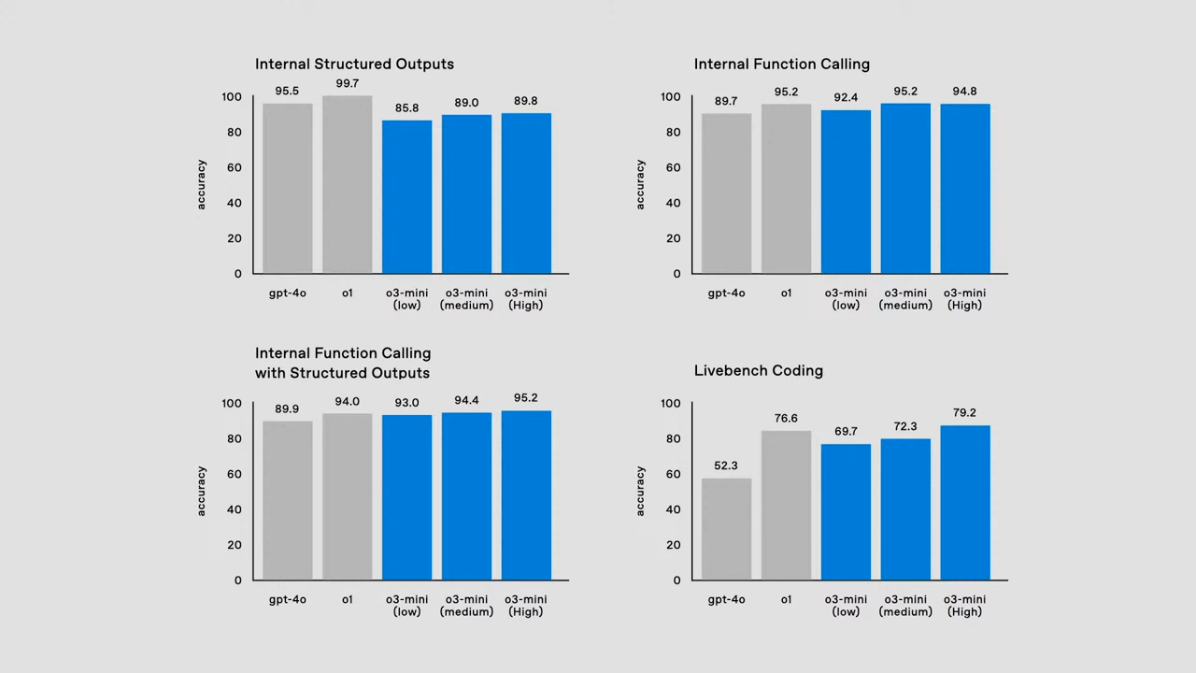
1) 내부 출력 구조화(Internal Structured Outputs)
- o3-mini는 low, medium, high 설정별로 각각 85.8%, 89.0%, 89.8%의 정확도를 기록하며, 높은 신뢰성을 보였습니다.
- 이는 GPT-4o 및 o1과 비교해도 경쟁력 있는 성과를 보여줍니다.
2) 내부 함수 호출(Internal Function Calling)
- o3-mini는 함수 호출에서 low, medium, high 설정별로 92.4%, 95.2%, 94.8%의 정확도를 달성했습니다.
- 특히, medium 설정에서 o1과 동등한 성능을 보이며, 높은 효율성을 입증했습니다.
3) 함수 호출 및 출력 구조화 결합(Internal Function Calling with Structured Outputs)
- o3-mini는 low, medium, high 설정별로 각각 93.0%, 94.4%, 95.2%의 정확도를 기록하며, o1 대비 안정적인 성능을 보였습니다.
4) 라이브벤치 코딩(Livebench Coding)
- 코딩 작업에서는 o3-mini의 high 설정이 79.2%로 가장 높은 성능을 보였으며, medium 설정도 72.3%로 안정적인 결과를 기록했습니다.
- 이는 GPT-4o 및 o1 대비 성능이 향상되었음을 보여줍니다.
5. 새로운 기능: Deliberative Alignment
Deliberative Alignment는 새로운 안전성 훈련 기법으로, AI의 신뢰성과 안전성을 크게 향상시킵니다.
주요 특징
- 안전한 경계 학습: 모델은 안전한 입력과 위험한 입력의 경계를 더 정밀하게 학습할 수 있습니다.
- 숨겨진 의도 파악: 모델이 사용자의 숨겨진 의도를 분석하여 잠재적 위험을 감지하고 대응할 수 있습니다.
- 추론 능력 활용: 입력 데이터를 단순히 처리하는 것을 넘어, 고급 추론 능력을 통해 안전성을 강화합니다.
성능 그래프
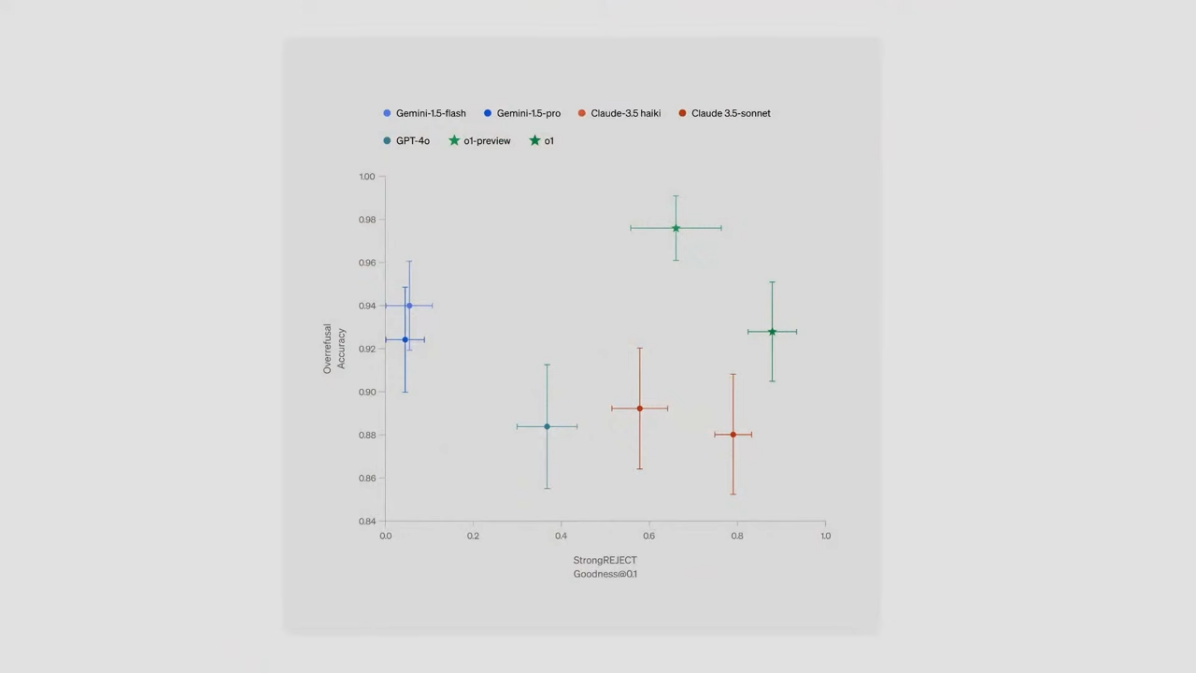
위 그래프는 다양한 모델이 Deliberative Alignment를 통해 강력한 거부(Strong Reject)와 우수한 출력(Goodness@Q1)을 얼마나 잘 달성했는지를 보여줍니다.
- 초록색 점(o1 모델)은 가장 높은 정확도와 안전성을 기록하며, 인간 전문가에 근접한 성능을 보였습니다.
- 다른 경쟁 모델들과 비교했을 때, OpenAI의 최신 기술이 안전성과 성능에서 모두 앞서 있음을 확인할 수 있습니다.
이 기술은 AI 모델이 점점 더 복잡해지는 사용자 요구와 환경에 적응하면서도 안전성을 유지할 수 있도록 돕습니다.
맺음말
이번 Day 12 발표는 AI 기술의 새로운 장을 열었습니다.
- o3와 o3-mini는 코딩, 수학, 과학, 일반화 문제 해결 등 다양한 분야에서 인간 전문가 수준의 성과를 보여줍니다.
- 비용 효율성과 안전성을 모두 고려한 혁신적인 기능은 AI의 실질적 응용 가능성을 크게 확장합니다.
- 특히, 새로운 기능과 벤치마크 성과는 AI가 더 복잡하고 창의적인 문제를 해결할 수 있는 기반을 마련했습니다.
이렇게 12일간의 길지만 짧은 가슴 벅찬 12 Days of OpenAI를 정리해봤는데요.
- Day 12: New frontier models o3 and o3-mini announcement
- Day 11: More App integrations for the Desktop App (Mac)
- Day 10: ChatGPT via phone and WhatsApp 1-800-CHATGPT
- Day 9: Dev Day Holiday Edition: o1 in the API, Realtime API improvements, a new fine-tuning method, better prices, WebRTC and more
- Day 8: Enhanced Search Feature, AVM Integration, Free Access
- Day 7: Projects and Folders for ChatGPT
- Day 6: Multimodal Advanced Voice Mode and Santa Mode
- Day 5: Apple Intelligence
- Day 4: Updates to ChatGPT’s Canvas
- Day 3: Release of Sora-Turbo
- Day 2: Reinforcement Fine-Tuning
- Day 1: Release of full o1 and ChatGPT Pro
내년에는 어떤 식으로 발전될지 더 궁금합니다. 앞으로도 AI 기술의 진보를 함께 기대해 주세요.
12일동안 함께 해주셔서 감사합니다! 💌
