[Paper Review] RT-DETRv2: Improved Baseline with Bag-of-Freebies for Real-Time Detection Transformer

본 리뷰는 원문을 최대한 직역한 내용입니다. 여기서 "우리는"은 저자를 지칭합니다. 참고 부탁드립니다.
초록
이 보고서에서는 개선된 실시간 Detection Transformer인 RT-DETRv2를 제시합니다. RT-DETRv2는 기존의 최신 실시간 detector인 RT-DETR을 기반으로 구축되었으며, 유연성과 실용성을 위한 bag-of-freebies를 도입하고 훈련 전략을 최적화하여 향상된 성능을 달성했습니다.
유연성 개선을 위해, deformable attention에서 서로 다른 스케일의 feature들에 대해 각기 다른 수의 sampling point를 설정하여 decoder가 선택적 multi-scale feature 추출을 수행할 수 있도록 제안합니다. 실용성 향상을 위해서는 YOLO들과 비교했을 때 RT-DETR 특유의 grid_sample operator를 대체할 수 있는 선택적 discrete sampling operator를 제안합니다. 이를 통해 일반적으로 DETR들과 연관된 배포 제약사항을 제거했습니다.
훈련 전략 측면에서는 속도 손실 없이 성능을 향상시키기 위해 dynamic data augmentation과 scale-adaptive hyperparameter 커스터마이징을 제안합니다. 소스 코드와 사전 훈련된 모델은 https://github.com/lyuwenyu/RT-DETR에서 제공될 예정입니다.
1. 서론
객체 탐지(Object detection)는 이미지에서 객체를 식별하고 위치를 파악하는 기본적인 컴퓨터 비전 작업입니다. 그 중에서도 실시간 객체 탐지는 자율주행과 같은 광범위한 응용 분야를 가진 중요한 영역입니다. 지난 몇 년간의 발전을 통해 YOLO detector들은 의심의 여지없이 이 분야에서 가장 권위 있는 프레임워크가 되었습니다. 그 이유는 YOLO detector들이 달성한 합리적인 균형(reasonable balance) 때문입니다.
RT-DETR v1의 등장은 실시간 객체 탐지를 위한 새로운 기술적 방향을 열어주었으며, 이 분야에서 YOLO에 대한 의존도를 깨뜨렸습니다.
- RT-DETR은 DETR의 vanilla Transformer encoder를 대체하는 효율적인
hybrid encoder를 제안했는데, 이는multi-scale feature들의intra-scale 상호작용과cross-scale 융합을 분리함으로써 추론 속도를 크게 향상시켰습니다.
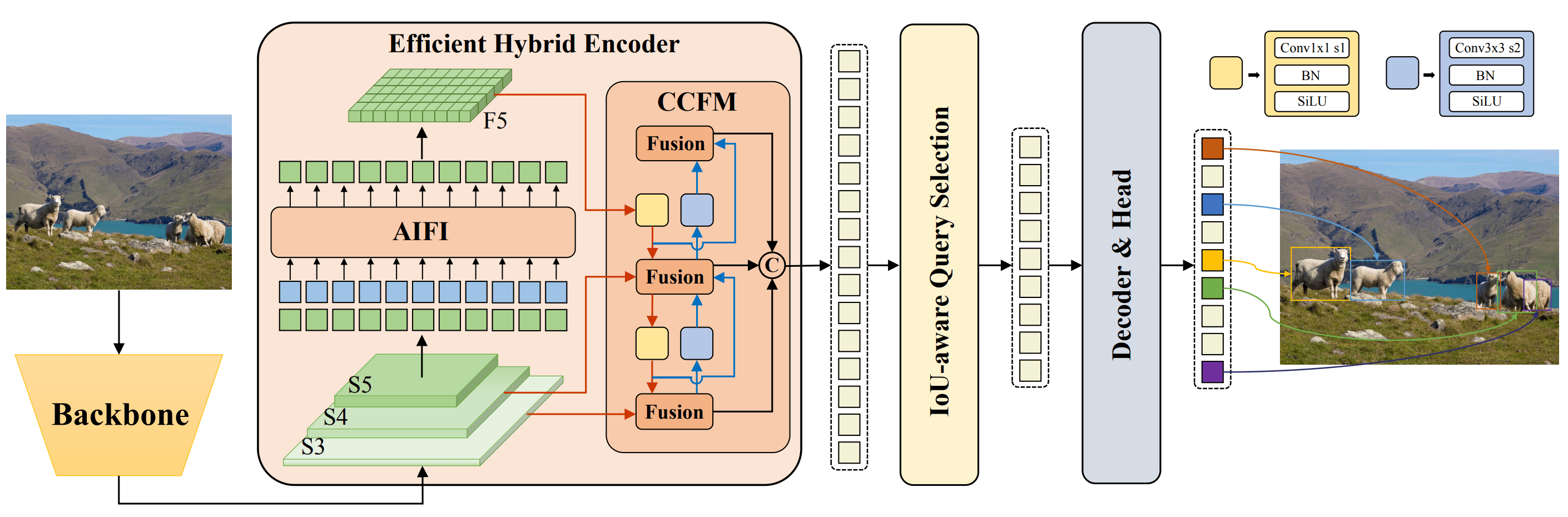
성능을 더욱 개선하기 위해 RT-DETR은 uncertainty-minimal query selection을 제안했습니다.
- 이는 uncertainty를 명시적으로 최적화하여 decoder에 고품질의 초기 query를 제공합니다.
- 또한 RT-DETR은 광범위한 detector 크기를 제공하며 재훈련 없이 다양한 실시간 시나리오에 맞춰 유연한 속도 조정을 지원합니다.
이 보고서에서는 개선된 실시간 detection Transformer인 RT-DETRv2를 제시합니다.
- 이 작업은 최근의 RT-DETR을 기반으로 구축되었으며, DETR family 내에서 유연성과 실용성을 위한
bag-of-freebies를 제공하고 향상된 성능을 달성하기 위해 훈련 전략을 최적화했습니다.
구체적으로, RT-DETRv2는 deformable attention module 내에서 서로 다른 스케일의 feature들에 대해 각기 다른 수의 sampling point를 설정하여 decoder가 선택적 multi-scale feature 추출을 달성할 것을 제안합니다.
- 실용성 향상 영역에서 RT-DETRv2는 DETR 특유의 기존 grid_sample operator를 대체하는 선택적 discrete sampling operator를 제공하여 detection Transformer들과 일반적으로 연관된 배포 제약사항을 제거합니다.
또한 RT-DETRv2는 속도 손실 없이 성능을 향상시키는 목표로 dynamic data augmentation과 scale-adaptive hyperparameter 커스터마이징을 포함한 훈련 전략을 최적화합니다.
- 결과는 RT-DETRv2가 RT-DETR을 위한 bag-of-freebies와 함께 개선된 baseline을 제공하고, 유연성과 실용성을 증가시키며, 제안된 훈련 전략이 성능과 훈련 비용을 최적화함을 보여줍니다.
2. 방법론
RT-DETRv2의 프레임워크는 RT-DETR과 동일하게 유지되며, decoder의 deformable attention module에만 수정사항이 있습니다.
2.1 프레임워크
서로 다른 스케일에 대한 구별된 sampling point 수
현재 DETR들은 multi-scale feature로 구성된 긴 입력 시퀀스로 인해 발생하는 높은 계산 오버헤드를 완화하기 위해 deformable attention module을 활용합니다.
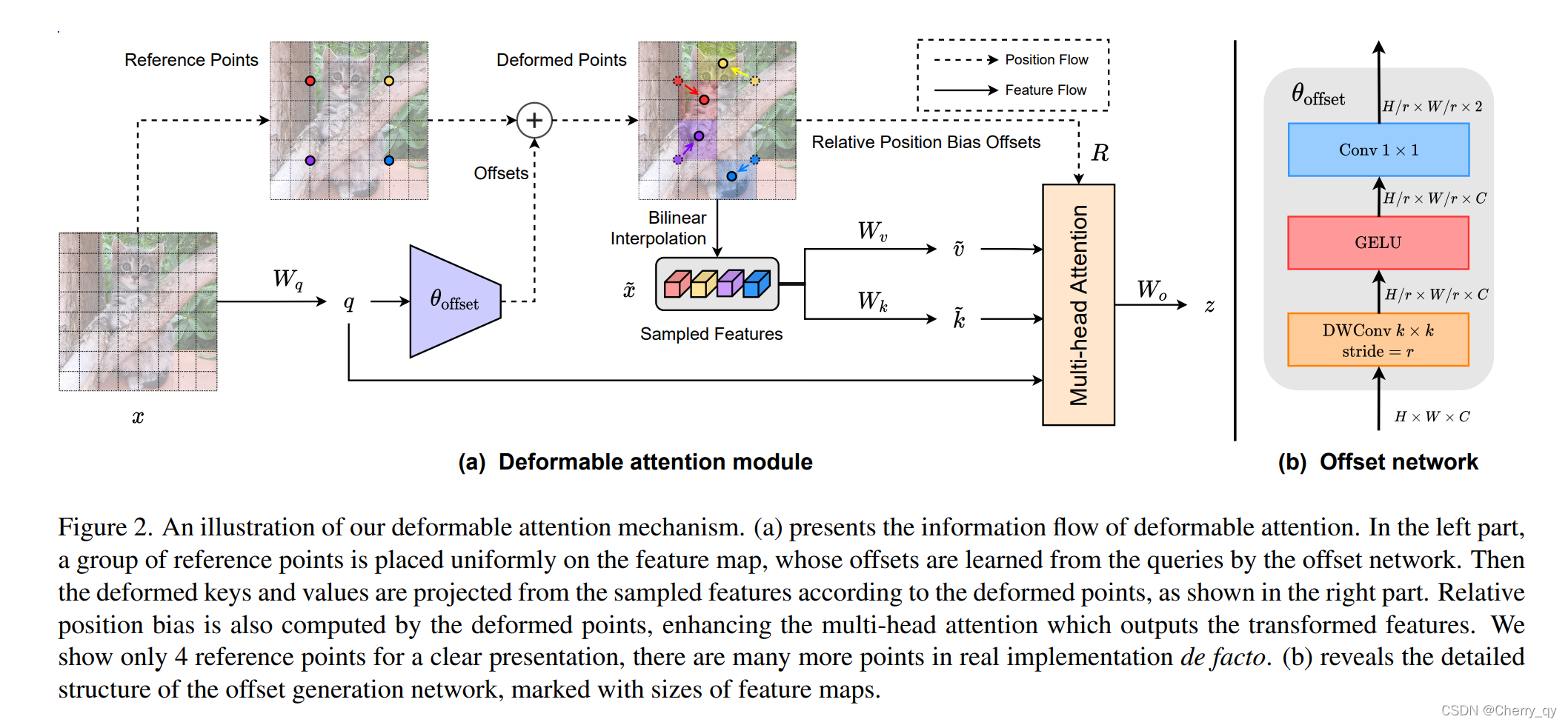
참고. DAT : Vision Transformer with Deformable Attention
RT-DETR의 decoder는 이 모듈을 유지하는데, 각 스케일에서 동일한 수의 sampling point를 정의합니다.
우리는 이러한 제약이 서로 다른 스케일의 feature들의 본질적 차이를 무시하고 deformable attention module의 feature 추출 능력을 제한한다고 주장합니다.
- 따라서 보다 유연하고 효율적인 feature 추출을 달성하기 위해 서로 다른 스케일에 대해 구별된 수의 sampling point를 설정할 것을 제안합니다.
Discrete Sampling
RT-DETR의 실용성을 개선하고 어디서든 사용 가능하게 만들기 위해, 우리는 YOLO들과 RT-DETR의 배포 요구사항을 비교하는 데 초점을 맞췄습니다.
- RT-DETR 특유의 grid_sample operator가 광범위한 적용 가능성을 제한합니다.
- 따라서
grid_sample을 대체하는 선택적discrete_sample operator를 제안하여 RT-DETR의 배포 제약사항을 제거합니다.
(참고)
grid_sampleoperator는 deformable attention에서 핵심적인 역할을 수행하는 PyTorch의 내장 함수입니다. 이 operator는 연속적인 좌표에서 feature를 샘플링할 때 bilinear interpolation을 사용하여 정확한 값을 계산합니다.
구체적으로, 예측된 sampling offset에 대해 반올림 연산을 수행하여 시간 소모적인 bilinear interpolation을 생략합니다. 그러나 반올림 연산은 미분 불가능하므로 sampling offset 예측에 사용되는 매개변수의 gradient를 차단합니다.
- (참고) 실제로는 훈련에서 먼저
grid_sampleoperator를 사용한 다음discrete_sampleoperator로 fine-tuning을 수행합니다. 추론과 배포에서는 모델이 discrete_sample operator를 사용합니다.
# RT-DETR과 동일한 프레임워크를 유지하되, 디코더의 deformable attention 모듈만 수정
Input Image (640×640)
↓
┌──────────────────────┐
│ CNN Backbone (ResNet) │ ← CNN으로 feature 추출
│ C3(80×80) → C4(40×40) → C5(20×20)│
└─────────────────────┘
↓
┌──────────────────────┐
│ Hybrid Encoder │ ← Transformer Encoder
│ Intra-scale + Cross-scale fusion │
└─────────────────────┘
↓
┌──────────────────────┐
│ Transformer Decoder │ ← Deformable Attention
│ - Deformable Attention 개선 │
│ - Distinct sampling points │
│ - Optional discrete sampling │
└─────────────────────┘
↓
Detection Heads
2.2 훈련 방식
Dynamic Data Augmentation
모델에 강건한 탐지 성능을 갖추기 위해 dynamic data augmentation 전략을 제안합니다.
- 초기 훈련 기간 동안 detector의 일반화 능력이 좋지 않다는 점을 고려하여, 더 강한 data augmentation을 적용하고 후기 훈련 기간에는 그 수준을 낮춰 detector가 목표 도메인의 탐지에 적응하도록 합니다.
구체적으로, 초기 기간에는 RT-DETR data augmentation을 유지하면서 마지막 두 epoch에서는 RandomPhotometricDistort, RandomZoomOut, RandomIoUCrop, MultiScaleInput을 비활성화합니다.
Scale-adaptive Hyperparameter 커스터마이징
우리는 또한 서로 다른 크기의 scaled RT-DETR들이 동일한 optimizer hyperparameter로 훈련되어 차선의 성능을 보인다는 것을 관찰했습니다. 따라서 scaled RT-DETR들을 위한 scale-adaptive hyperparameter 커스터마이징을 제안합니다.
- 가벼운 detector(예: ResNet18)의 사전 훈련된 backbone이 더 낮은 feature 품질을 가진다는 점을 고려하여 학습률을 증가시킵니다.
- 반대로, 큰 detector(예: ResNet101)의 사전 훈련된 backbone은 더 높은 feature 품질을 가지므로 학습률을 감소시킵니다.
3. 실험
3.1 구현 세부사항
RT-DETR과 마찬가지로 ImageNet에서 사전 훈련된 ResNet을 backbone으로 사용하고, batch size 16으로 AdamW optimizer를 사용하여 RT-DETRv2를 훈련시킵니다.
- ema_decay = 0.9999인 exponential moving average (EMA)를 적용합니다.
선택적 discrete sampling의 경우, 먼저 grid_sample operator로 6× 사전 훈련한 다음 discrete_sample operator로 1× fine-tuning을 수행합니다.
- Scale-adaptive hyperparameter 커스터마이징의 hyperparameter는 표 1에 나와 있으며, 여기서 lr은 학습률을 나타냅니다.
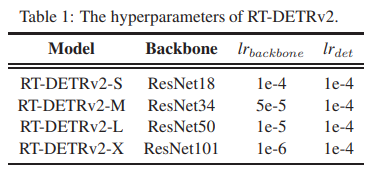
표 1: RT-DETRv2의 hyperparameter
3.2 평가
RT-DETRv2는 COCO train2017에서 훈련되고 COCO val2017 dataset에서 검증됩니다. 0.50에서 0.95까지 0.05 단계로 균등하게 샘플링된 IoU threshold에 대해 평균화된 표준 AP 메트릭과 실제 시나리오에서 일반적으로 사용되는 AP^val_50을 보고합니다.
3.3 결과
RT-DETR과의 비교는 표 2에 나와 있습니다. RT-DETRv2는 속도 손실 없이 서로 다른 스케일의 detector들에서 RT-DETR을 능가합니다.
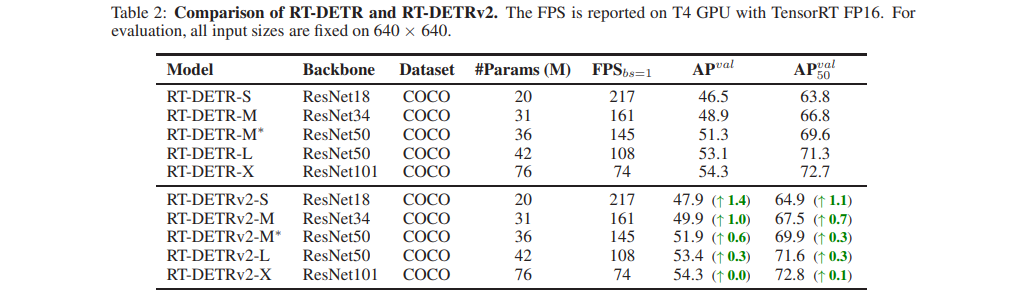
표 2: RT-DETR과 RT-DETRv2의 비교
FPS는 TensorRT FP16을 사용한 T4 GPU에서 보고됩니다. 평가를 위해 모든 입력 크기는 640×640으로 고정됩니다.
3.4 Ablation 연구
Sampling Point에 대한 Ablation
grid_sample operator의 총 sampling point 수에 대한 ablation 연구를 수행했습니다.
총 sampling point 수는 num_head × num_point × num_query × num_decoder로 계산되며, 여기서 num_point는 각 그리드에서 각 스케일 feature에 대한 sampling point의 합을 나타냅니다.
- 결과는 sampling point 수를 줄여도 성능에 큰 저하가 없음을 보여줍니다(표 3 참조). 이는 대부분의 산업 시나리오에서 실용적 적용이 영향받지 않을 것임을 의미합니다.
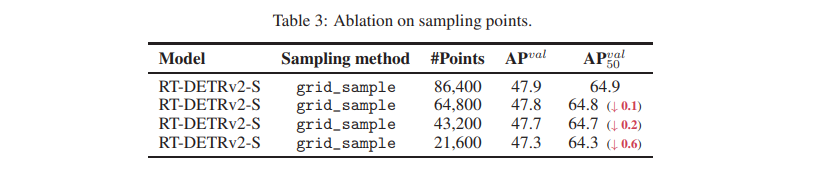
표 3: Sampling Point에 대한 Ablation
Discrete Sampling에 대한 Ablation
grid_sample을 제거하고 discrete_sample로 대체하는 ablation을 수행했습니다. 결과는 이 작업이 에서 눈에 띄는 감소를 일으키지 않으면서 DETR들의 배포 제약사항을 제거함을 보여줍니다(표 4 참조).
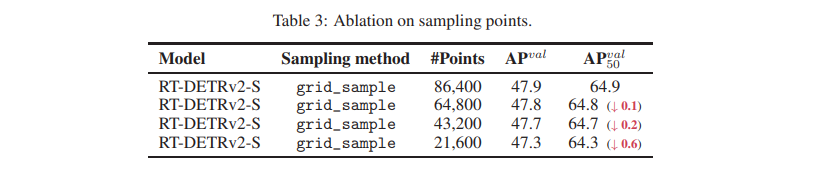
표 4: Discrete Sampling에 대한 Ablation
4. 결론
이 보고서에서는 개선된 실시간 detection Transformer인 RT-DETRv2를 제안했습니다. RT-DETRv2는 RT-DETR의 유연성과 실용성을 증가시키기 위한 bag-of-freebies를 제공하고, 속도 손실 없이 향상된 성능을 달성하기 위해 훈련 전략을 최적화합니다. 우리는 이 보고서가 DETR family에 대한 통찰을 제공하고 RT-DETR 응용의 범위를 넓히기를 희망합니다.
