[Paper Review] OmDet_Turbo : Real-time Transformer-based Open-Vocabulary Detection with Efficient Fusion Head

초록
End-to-end transformer 기반 detector (DETRs)는 언어 modality 통합을 통해 closed-set과 open-vocabulary object detection (OVD) 작업 모두에서 뛰어난 성능을 보여주었습니다. 그러나 높은 연산 요구사항으로 인해 실시간 object detection (OD) 시나리오에서의 실용적인 적용이 제한되어 왔습니다.
본 논문에서는 OVDEval 벤치마크의 두 주요 모델인 OmDet과 Grounding-DINO의 한계를 면밀히 분석하고, OmDet-Turbo를 소개합니다.
- 이는 OmDet과 Grounding-DINO에서 관찰된 병목현상을 완화하도록 설계된 혁신적인 Efficient Fusion Head (EFH) 모듈을 특징으로 하는 새로운 transformer 기반 실시간 OVD 모델입니다.
주목할 점은 OmDet-Turbo-Base가 TensorRT와 language cache 기법을 적용하여 초당 100.2 frame (FPS)를 달성한다는 것입니다.
- TensorRT : https://developer.nvidia.com/tensorrt
- language cache : https://www.helicone.ai/blog/effective-llm-caching
COCO와 LVIS 데이터셋의 zero-shot 시나리오에서 OmDet-Turbo는 현재 state-of-the-art supervised 모델들과 거의 동등한 성능 수준을 달성합니다. 또한 ODinW와 OVDEval에서 각각 30.1 AP와 26.86 NMS-AP로 새로운 state-of-the-art 벤치마크를 수립합니다.
벤치마크 데이터셋에서의 뛰어난 성능과 우수한 추론 속도는 산업 애플리케이션에서의 OmDet-Turbo의 실용성을 강조하며, 실시간 object detection 작업을 위한 매력적인 선택으로 자리매김합니다.
Keywords:
Multi-Dataset Pre-Training, Zero/Few-Shot Detection, Task-Conditioned Detection, Deep Fusion Mechanism, language-aware object detection, Continual Learning
1. 서론
Object Detection (OD)은 다양한 deep neural network의 통합을 통해 상당한 진전을 이룬 컴퓨터 비전 분야의 기본 작업입니다. 전통적인 close-set OD 방법들은 광범위한 연구를 거쳐 점차 안정화되었으며, 주로 두 방향에 초점을 맞추고 있습니다: 더 높은 정확도를 달성하기 위한 detector 구조 개선과 더 빠른 추론 속도를 가진 실시간 detector 개발입니다.
stage 관점에서 보면, Faster R-CNN과 같은 two-stage 접근법과 YOLO 시리즈와 같은 one-stage 접근법이 잘 알려진 방법들입니다.
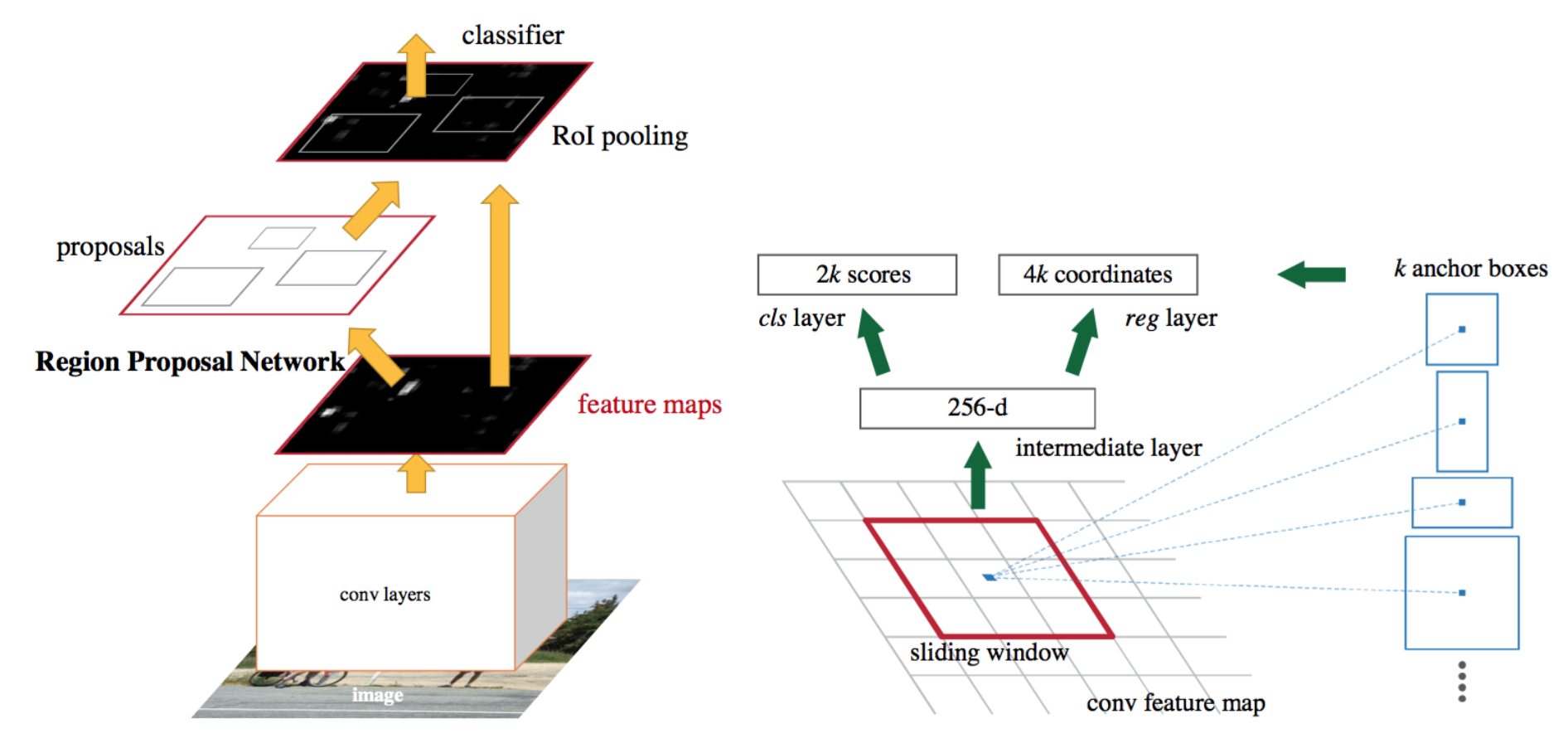
Faster R-CNN - 2 stage
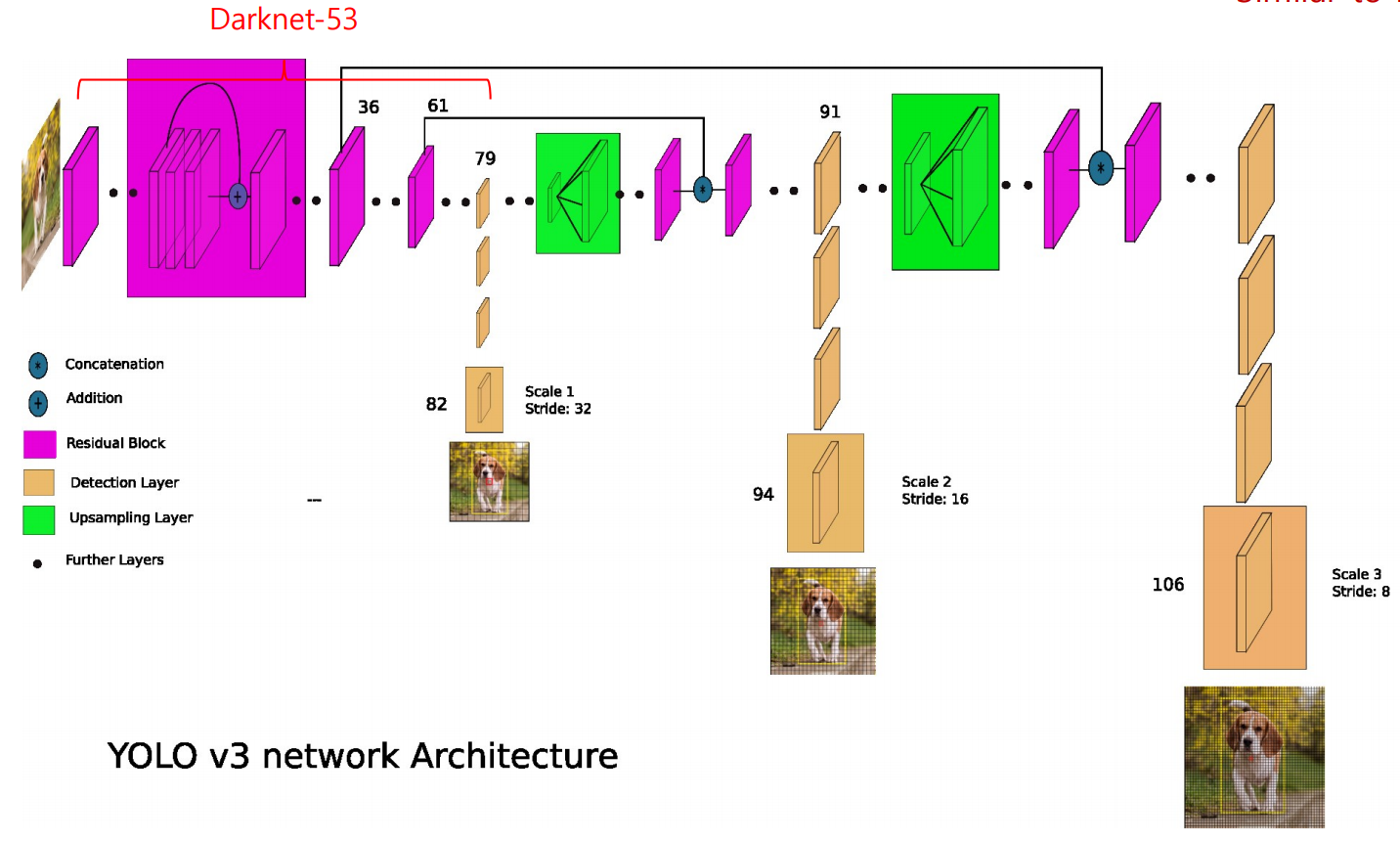
YOLO 시리즈 - 1 stage
Anchor 관점에서는 anchor 기반 방법에서 anchor-free 방법으로 연구가 발전했습니다. 모델 구조 측면에서는 CNN 기반 detector와 Transformer 기반 detector (DETRs)가 두 가지 주요 OD 아키텍처입니다.
(참고) Anchor 기반 vs Anchor-free 방법
- Anchor 기반 방법: 객체의 위치를 예측할 때, 미리 정의된 다양한 크기와 비율의 "anchor box"를 기준으로 예측합니다. 대표적인 모델:
- Faster R-CNN
- YOLOv2~YOLOv4
- Anchor-free 방법: anchor 없이 직접 객체의 중심점이나 경계 박스를 예측합니다. 최근 연구에서 성능과 효율성 측면에서 각광받고 있습니다. 대표적인 모델:
- CornerNet
- DETR
참고
| 구분 | Anchor 기반 | Anchor-free |
|---|---|---|
| CNN 기반 | Faster R-CNN, SSD, YOLOv3 | FCOS, CenterNet, CornerNet |
| Transformer 기반 | 일부 Deformable DETR (anchor-like 구조 사용) | DETR, DINO-DETR |
기존 방법들과 실시간 detector의 대부분이 CNN 기반 detector인 반면, 최근 DETRs에 대한 관심이 급증하고 있는 것은 간결한 pipeline과 end-to-end 접근법 때문입니다. DINO와 Co-DETR과 같은 몇 가지 새로운 DETR 방법들은 COCO 데이터셋에서 각각 63.2와 65.9 AP로 state-of-the-art 성능에 도달하며 인상적인 결과를 달성했습니다. 또한 RT-DETR은 hybrid encoder를 통해 CNN 기반 detector를 능가하는 실시간 object detection을 달성합니다.
그러나 전통적인 OD 모델들은 공통적인 한계를 가지고 있습니다—훈련 vocabulary를 벗어난 객체들로 일반화할 수 없다는 것입니다. 이러한 한계는 실제 애플리케이션과 산업 환경의 요구를 충족하는 데 어려움을 제기합니다.
Object detection의 새로운 연구 방향은 open-vocabulary object detection (OVD)으로, 이는 언어 정보를 통합하여 detector를 안내함으로써 훈련 데이터의 범위를 넘어선 객체들을 검출하는 것을 목표로 합니다.
현재 대부분의 OVD 모델은 언어 modality를 close-set detector에 통합하여 개발됩니다.
OVDEval 벤치마크에서 최고 성능을 보이는 OVD 모델들 중에서, OmDet은 Sparse-RCNN 구조를 채택하고 Multimodal Detection Network (MDN)를 사용하여 recursive head에서 latent query를 융합합니다.
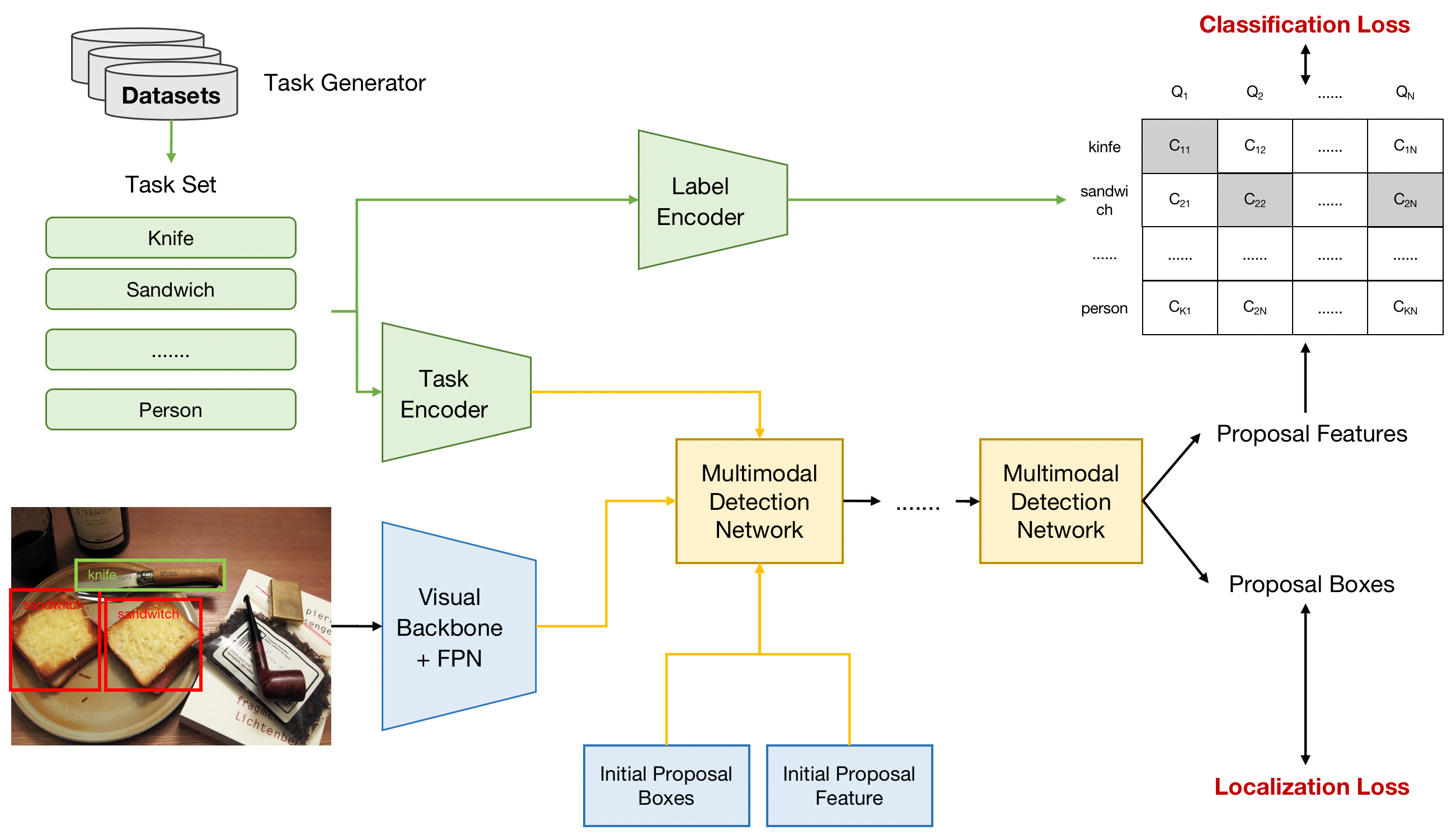
OmDet
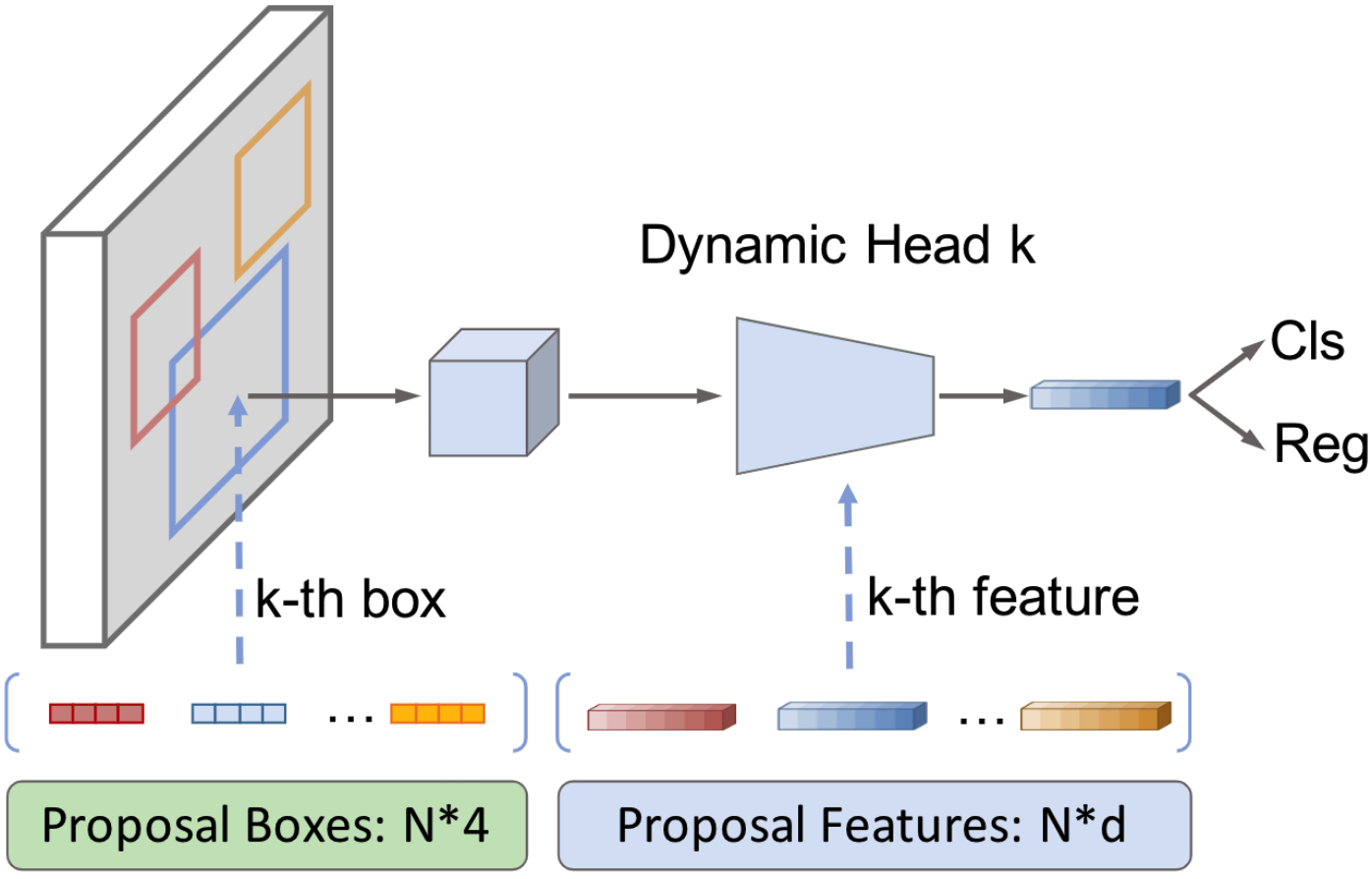
(참고) Sparse R-CNN은 고정된 수의 learnable object queries를 사용하여 객체를 탐지하는 end-to-end 방식의 detector입니다.
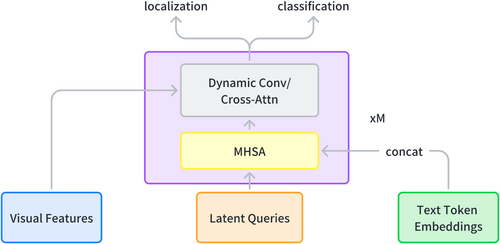
(참고) MDN(Multimodal Detection Network)은 텍스트와 이미지 정보를 융합하는 모듈입니다.
- 반면 Grounding-DINO는 DETR 구조를 채택하고 neck, head, query initialization stage에서 fusion mechanism을 통합하여 multimodal 능력을 향상시킵니다.
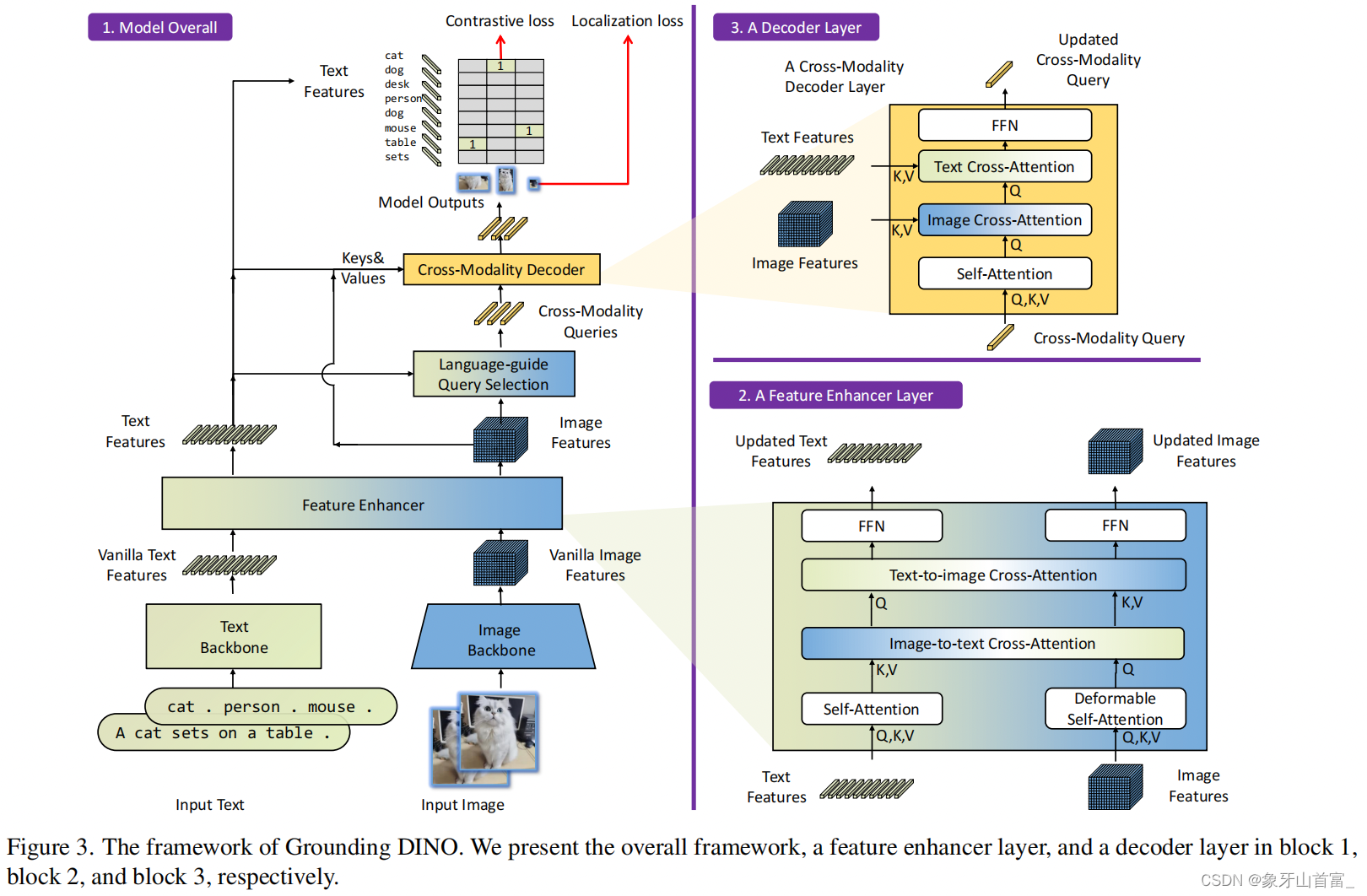
Grounding-DINO
이러한 발전에도 불구하고, 기존 OVD 모델들은 높은 계산 복잡성과 긴 추론 시간으로 인해 상업적 애플리케이션에서의 실제 배포가 방해받고 있습니다.
2. 관련 연구
2.1 Transformer 기반 Detection
Transformer 기반 object detection 방법들은 최근 몇 년간 상당한 주목을 받았습니다. 이러한 접근법들은 transformer의 힘을 활용하여 시각 데이터에서 long-range dependency와 contextual 정보를 캡처합니다. DETR은 이러한 유형의 모델에서 대표적인 방법 중 하나입니다.
DETR은 transformer encoder-decoder 아키텍처와 bipartite matching을 통한 unique prediction을 강제하는 set-based global loss를 사용합니다. DETR 모델의 출시 이후, 연구자들은 다양한 측면에서 DETR과 같은 모델 구조를 최적화하는 데 오랜 시간을 보냈습니다.
Sparse-RCNN, DN-DETR, DINO, RT-DETR과 같은 vision-and-language 모델의 최근 발전은 object detection을 향상시키고 downstream detection 작업으로의 transferability를 개선하는 데 유망함을 보여주었습니다. 그러나 이러한 DETR과 같은 모델들은 전통적인 closed-set object detection 알고리즘으로, 애플리케이션 시나리오와 Transformer가 가져야 할 잠재력을 크게 제한합니다.
2.2 Open-Vocabulary Object Detection
Open-vocabulary object detection (OVD)은 사용자가 미리 정의된 target category에 제한되지 않고 자연어로 정의된 target category를 사용하여 객체를 식별할 수 있다는 점에서 전통적인 object detection 알고리즘과 다릅니다.
전통적인 object detection 시스템은 고정된 객체 클래스 집합을 가진 데이터셋에서 훈련되어 일반화 능력이 제한적입니다. OVR-CNN과 같은 초기 OVD 알고리즘은 고정된 category의 bounding box annotation과 더 다양한 category를 다루는 image-caption pair로 구성된 데이터셋에서 훈련되었습니다.
이러한 문제를 해결하기 위해 최근 연구는 대규모 image-text pair에서 cross-modal contrastive learning을 수행하는 CLIP과 ALIGN과 같은 vision-and-language 접근법을 탐구했습니다. CLIP과 ALIGN에서 영감을 받은 ViLD는 뛰어난 zero-shot object recognition 능력을 보여주는 two-stage object detection 모델을 구축했습니다.
GLIP은 object detection을 phrase grounding 문제로 재공식화하여 grounding과 대규모 image-text paired data의 사용을 가능하게 함으로써 솔루션을 제공합니다. Sparse-RCNN에서 영감을 받은 OmDet은 자연어를 지식 표현의 통일된 방법으로 취급합니다.
Grounding DINO는 transformer 기반 detection 알고리즘인 DINO를 grounding task pre-training과 결합하여 속성을 가진 target expression의 사용자 입력을 지원함으로써 OVD 모델의 실용성을 크게 확장합니다.
CORA와 BARON과 같은 최근 연구들은 현재 OVD 방법들 내의 지속적인 도전과제들을 해결하려고 노력했습니다. 그러나 OVD 모델의 한계는 모델 규모와 복잡성에 있어 실시간 추론을 어렵게 만든다는 점으로, 이는 실제 애플리케이션에서의 광범위한 채택에 도전이 되며 시급한 해결이 필요한 문제입니다.
2.3 Real-time Object Detection
YOLO 시리즈, EfficientDet, RT-DETR과 같은 object detection 모델들은 one-stage 모델 아키텍처를 사용하여 추론 과정에서 계산 복잡성을 크게 줄임으로써 빠른 추론 속도를 가집니다.
YOLO-World는 실시간 open-vocabulary object detection의 시도입니다. YOLO 알고리즘의 대표적인 one-stage 모델 구조를 계승하고, CLIP text encoder를 사용하여 입력 텍스트를 임베딩한 후 특별히 설계된 re-parameterizable Vision-Language Path Aggregation Network를 사용하여 텍스트 특징을 이미지 특징과 융합합니다. YOLO-World는 실시간 인식의 목표를 달성했지만 CNN 기반 방법이며 일반화 정확도가 transformer 기반 모델들보다 뒤처집니다.
본 논문은 open-vocabulary object detection 작업에서 강력한 성능과 효율성을 달성하는 최초의 실시간 transformer 기반 end-to-end OVD 방법을 제시합니다.
3. 제안된 방법: OmDet-Turbo
3.1 모델 구조
OmDet-Turbo의 모델 구조는 text backbone(), image backbone(), 그리고 Efficient Fusion Head () 모듈로 구성됩니다.
모델의 입력은 작업을 설명하는 prompt, 객체 label 집합, 그리고 검출할 이미지로 구성됩니다.
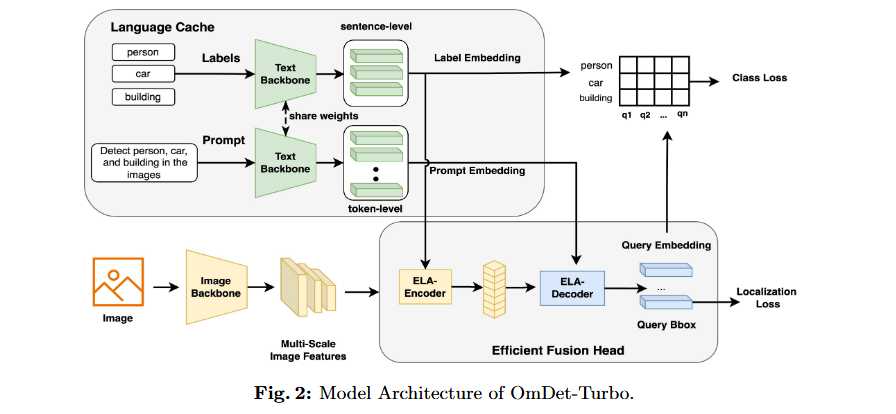
OmDet-Turbo는 유연성과 성능을 향상시키기 위해 과 달리 와 를 분리하여 동일한 텍스트 임베딩을 공유하지 않도록 했습니다.
- Label은 일반적으로 검출할 객체의 이름을 나타내는 반면, prompt는 객체 이름의 조합, Visual Question Answering (VQA) 작업의 질문, 또는 대규모 vocabulary 검출 시나리오에서 "모든 객체 검출"과 같은 일반적인 지시사항 등 다양할 수 있습니다.
(참고) GLIP은 텍스트 인코더(예: BERT 계열)를 사용해 prompt + label을 하나의 시퀀스로 합쳐서 인코딩합니다.
OmDet-Turbo는 Text backbone 는 prompt 와 K개의 label 의 텍스트 입력을 인코딩하여 label embedding과 prompt embedding을 생성하는 CLIP과 같은 transformer language model입니다.
-
구체적으로 각 label 의 sentence-level embedding을 생성하기 위해 text backbone 출력의 token을 label embedding으로 사용합니다.
-
Prompt embedding 의 경우, prompt에 대한 fine-grained 정보를 유지하기 위해 sentence-level embedding 대신 text backbone 의 token-level embedding 출력을 활용합니다.
Image backbone 는 입력 이미지의 픽셀 데이터를 받아 multi-scale image feature pyramid 를 추출합니다.
그 다음 두 가지 핵심 구성요소로 이루어진 를 소개합니다. 이는 Efficient Language-Aware Encoder (ELA-Encoder)와 Efficient Language-Aware Decoder (ELA-Decoder)로 구성됩니다.
ELA-Encoder
효율적인 언어 인식 인코더 (ELA-Encoder): 이 인코더는 시각적 백본에서 제공되는 다중 스케일 피처 맵을 활용하여 프롬프트와 관련된 쿼리 제안을 효율적으로 예측합니다.
RT-DETR에서 소개된 efficient hybrid encoder를 따라, multi-scale image backbone feature의 마지막 층인 는 multilayer Multi-head Self-Attention (MHSA) 모듈을 통해 인코딩되어 를 얻습니다.
그 다음 Cross-scale Feature-fusion Module (CCFM)은 PANet과 유사하게 convolutional layer를 활용하여 F5에서 P4, P3로 top feature를 융합합니다.
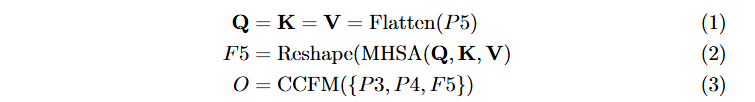
이 접근법은 정확도 수준을 유지하면서 속도를 35% 향상시킵니다. 위 encoder로부터 얻은 O가 주어지면, top-K encoder feature가 decoder의 초기 object position query로 선택됩니다. Language-aware selection 과정을 만들기 위해 label embedding을 도입합니다.
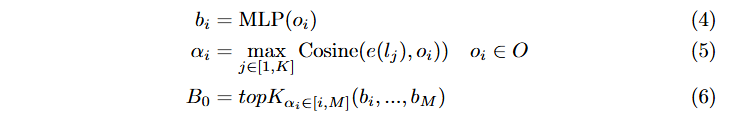
ELA-Decoder
효율적인 언어 인식 디코더 (ELA-Decoder): 이 모듈은 시각적 특징과 언어 특징의 융합 과정을 단순화하며, 멀티태스크 학습과 OVD(Open-Vocabulary Detection) 기능을 지원합니다.
Image cross-attention과 Text cross-attention을 순차적으로 활용하여 이미지와 텍스트 특징을 융합하는 Grounding DINO 접근법과 달리, vision-language fusion 과정을 단순화합니다.

각 decoder layer에서 먼저 query feature와 prompt feature를 concatenate한 후 상호작용을 위한 multi-head self-attention mechanism을 적용합니다. 그 다음 query feature는 deformable attention을 통해 시각적 특징에 attention을 수행합니다.
분리된 Prompt와 Label Encoder
이전 grounding 기반 OVD 방법들과 달리, 우리의 접근법은 모든 클래스를 object detection을 위한 prompt로 직접 concatenate하지 않습니다. 대신 detection 작업의 prompt와 클래스를 별도로 인코딩합니다. Prompt와 label을 분리함으로써 detection 작업의 prompt가 더욱 유연해집니다.
더 유연한 prompt는 language cache와 multi-task learning과 같은 기법을 쉽게 수행할 수 있게 해줍니다. 또한 이 접근법은 더 큰 vocabulary 크기를 가진 데이터셋에서의 훈련을 가능하게 합니다.
Language Cache
우리의 접근법에서는 시각적 및 텍스트 특징 추출 중에 multi-modal feature 상호작용을 수행하지 않으므로, image backbone과 text backbone이 완전히 독립적입니다. 이를 통해 테스트 및 배포 단계에서 target label과 target detection prompt의 텍스트 임베딩을 미리 추출하여 메모리나 GPU 메모리에 저장할 수 있습니다.
3.2 모델 훈련
Multi-task Learning
Open-vocabulary detection 작업에 대한 이전 연구들은 object detection의 고정된 사고방식에서 벗어나지 못했기 때문에 주로 detection 작업에 제한되었습니다.
클래스와 작업을 분리함으로써 grounding, object detection (OD), visual question answering (VQA), human-object interaction (HOI) 등과 같은 다른 작업을 수행하고 이러한 작업의 데이터셋을 pre-training에 활용하는 것이 편리해집니다.
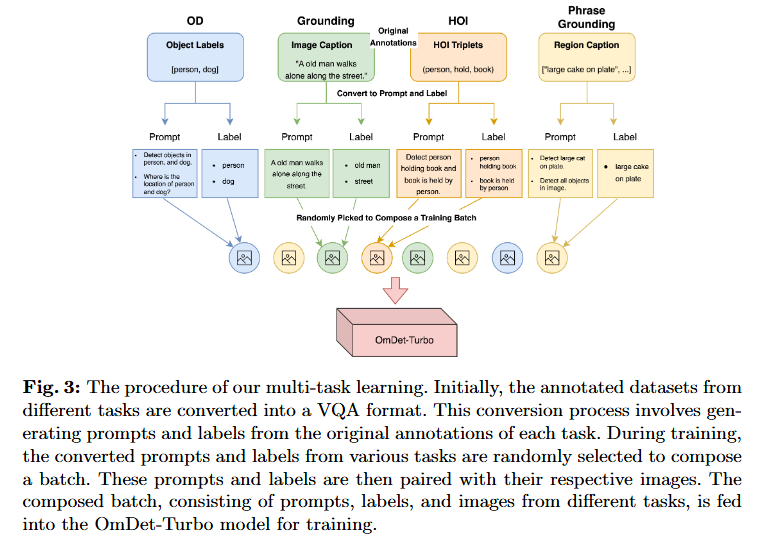
-
Grounding:
텍스트와 이미지의 특정 영역을 연결 (예: "the red car" → 이미지 내 위치) -
Object Detection (OD):
이미지에서 객체 위치와 클래스 예측 -
Visual Question Answering (VQA):
이미지 기반 질문에 답변 -
Human-Object Interaction (HOI):
사람과 객체 간의 관계 인식 (예: "사람이 컵을 들고 있다")
Large Vocabulary로의 확장
클래스와 독립적인 분리된 작업은 large-vocabulary 데이터셋에 적용될 수 있습니다. 검출할 target 클래스가 많을 때, 이들을 함께 concatenate하여 작업으로 만들면 매우 긴 작업이 됩니다. 이는 transformer 기반 언어 모델에서 작업을 인코딩할 때 이차적으로 증가된 시간 소비로 이어집니다.
분리된 작업 접근법을 통해 "이미지의 모든 객체 검출"과 같은 유연한 표현을 detection 모델에 대한 지시사항으로 사용합니다. 이를 통해 과도하게 긴 작업의 문제와 언어 모델에 대한 후속 지수적 인코딩 시간 증가를 피할 수 있습니다.
학습 방법
훈련 과정 전반에 걸쳐 DINO와 일치하게 모델 수렴을 가속화하고 모델 정밀도를 향상시키기 위해 여러 denoise group을 사용합니다. 다른 detr-base 모델과 일치하게, 재구성 및 예측 단계에서 detection 작업의 주요 loss function으로 L1 loss와 GIOU loss를 사용합니다.
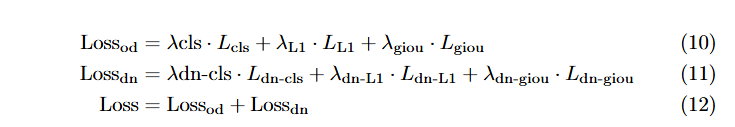
그러나 분류 작업에서는 각 query embedding과 텍스트 특징의 dot product를 취한 후 focalloss를 직접 사용하지 않습니다. 대신 positive sample의 분류와 localization 간의 일관성을 유지하기 위해 RT-DETR에서 효과적임이 입증된 IoU-aware Query Selection을 도입했습니다.
4. 실험
4.1 실험 설정
Pre-training 데이터
OmDet-Turbo-Base의 pre-training 과정은 multi-task learning 접근법을 통해 다양한 컴퓨터 비전 작업의 데이터셋을 활용합니다. Localization 능력을 향상시키기 위해 object detection용 O365 데이터셋을 통합합니다. Grounding 작업을 위해서는 이전 연구에서 일반화 개선에 효과적임이 입증된 GoldG 데이터셋을 선택합니다.
모델의 human-object interaction (HOI) 능력을 개선하기 위해 Hake 데이터셋과 정제된 버전의 HOIA를 활용합니다. 정제된 HOI-A 버전에서는 비합리적인 triplet 조합을 사용한 잘못된 annotation을 제거했습니다. 또한 phrase grounding에 전용된 PhraseCut 데이터셋을 통합하여 모델 내 지역과 텍스트 간의 alignment를 향상시킵니다.
구현 세부사항
OmDet-Turbo-Base 모델의 경우 image backbone으로 ConvNext Base를, text backbone으로 CLIP ViT-B/16의 text encoder를 사용합니다. 훈련 중 안정성을 보장하기 위해 text backbone의 첫 6개 layer를 동결하고 마지막 4개 layer만 fine-tune합니다.
훈련 중 base learning rate를 0.0001로 설정하고 전체 훈련 단계의 70%와 90%에서 0.1의 decay를 적용합니다. 모델은 16개의 NVIDIA A100 GPU를 사용하여 batch size 64로 훈련됩니다.
4.2 주요 결과
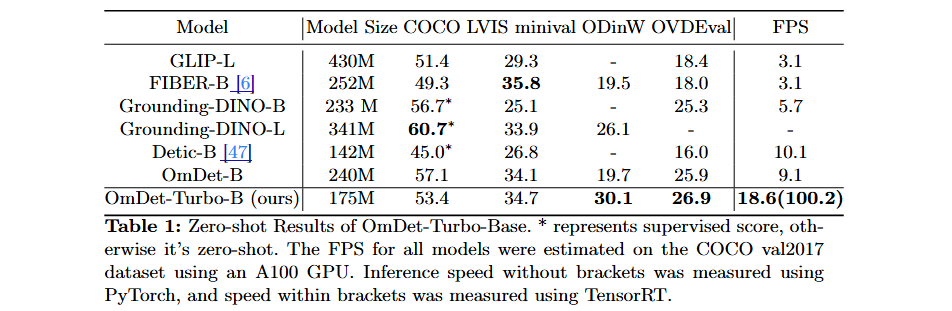
일반적인 OD 벤치마크 COCO와 LVIS에서의 Zero-shot 성능
COCO와 LVIS는 OD 모델 평가를 위해 널리 인정받는 벤치마크입니다. COCO에서 OmDet-Turbo-Base는 인상적인 53.4 AP를 달성하며 놀라운 성능을 보여줍니다. 더 작은 모델 크기에도 불구하고 GLIP-L을 능가합니다.
LVIS에서의 zero-shot 성능과 관련하여, OmDet-Turbo-Base는 두 개의 large-sized 모델인 GLIP-L과 Grounding-DINO-L을 능가합니다. 이 결과는 대규모 vocabulary에서 객체를 검출하는 우리 모델의 강점을 강조하며, 다양한 검출 시나리오를 처리하는 능력을 보여줍니다.
복잡한 OD 벤치마크에서의 Zero-shot 성능
ODinW 벤치마크에서 OmDet-Turbo-Base는 30.1의 zero-shot AP를 달성하여 Grounding-DINO-L과 OmDet-B의 성능을 능가했습니다. 이 결과는 다양한 실제 작업에 대한 우리 모델의 전이 능력과 적응성을 강조합니다.
OVD를 위해 세심하게 설계된 벤치마크인 OVDEval에서 OmDet-Turbo-Base는 26.86의 NMS-AP 점수로 새로운 State-of-the-Art (SOTA) 점수를 달성했습니다.
추론 속도
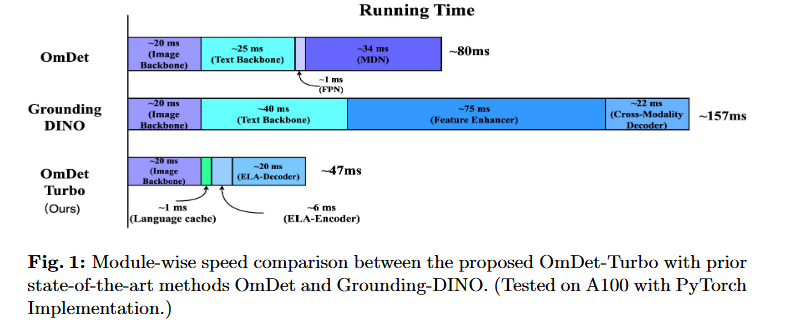
실용적 규모에서 모델의 추론 속도를 평가하기 위해 80개 category로 구성된 COCO val2017 데이터셋의 5000개 이미지에서 추론을 수행했습니다. 다른 모델들과의 비교에서 OmDet-Turbo-Base는 PyTorch에서 18.6 FPS, TensorRT에서 100.2 FPS의 인상적인 추론 속도를 달성합니다. 이 속도는 경쟁 모델들보다 약 20배 빠르며, object detection 작업 처리에서 우리 모델의 효율성과 속도를 강조합니다.
4.3 Ablation Study
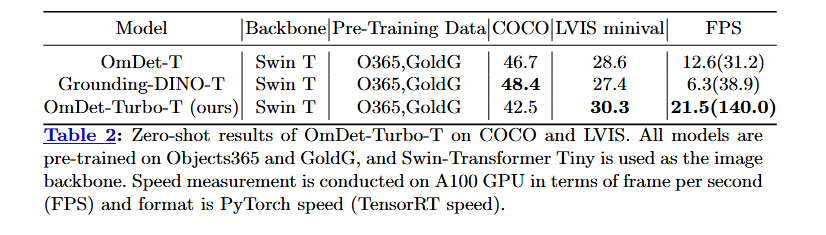
성능 분석
동일한 pre-training 데이터셋과 image backbone을 사용하는 zero-shot 시나리오에서 다른 모델들과 비교할 때 OmDet-Turbo-Tiny의 인상적인 성능을 보여줍니다.
- OmDet-Turbo-Tiny는 COCO에서 경쟁력 있는 zero-shot 점수를 달성하고 LVIS minival에서 30.3 AP의 최고 점수로 다른 모델들의 성능을 능가합니다.
상세한 추론 속도 분석
우리 모델에 대한 개선사항과 OmDet과 Grounding-DINO에 존재하는 병목현상의 제거를 설명하기 위해, 세 모델의 구조를 네 가지 주요 구성요소로 세분화했습니다: text backbone, image backbone, encoder/FPN, decoder/head. 그 다음 각 구성요소의 소요 시간을 세심하게 측정했습니다.

OmDet-Turbo는 모든 구성요소에서 다른 두 모델을 일관되게 능가하며, encoder/FPN과 decoder/head 섹션에서 특히 주목할 만한 개선을 보입니다. Encoder/FPN 구성요소에서 Grounding-DINO는 feature enhancer layer의 heavy multi-modality computation으로 인해 상당한 속도 저하를 겪습니다.
OmDet-Turbo는 hybrid encoder를 구현하여 이 병목현상을 해결하고, Grounding-DINO와 비교하여 encoder/FPN 과정에서 약 10배 속도 향상을 달성합니다. Decoder/head 구성요소와 관련하여, OmDet의 원래 MDN은 feature 추출을 위해 시간이 많이 소요되는 ROIAlign에 의존합니다. OmDet-Turbo는 ELA-Decoder를 도입하여 ROI operation의 필요성을 제거하고 decoder/head 구성요소를 상당히 가속화합니다.
5. 결론
결론적으로, 본 논문은 효율성과 성능 모두에서 뛰어난 실시간 transformer 기반 open-vocabulary object detection 모델인 OmDet-Turbo를 소개합니다. 높은 detection 정확도를 유지하면서 open-vocabulary 시나리오의 도전과제를 해결함으로써, OmDet-Turbo는 실제 object detection 작업을 위한 매력적인 솔루션으로 돋보입니다.
Efficient Fusion Head 모듈은 encoder와 head 구성요소의 계산 복잡성을 줄여 detection 성능을 해치지 않으면서도 더 빠른 추론 속도를 달성하는 데 중요한 역할을 합니다. 대규모 데이터셋에서 훈련된 OmDet-Turbo-Base는 ODinW와 OVDEval과 같은 어려운 데이터셋에서 state-of-the-art 성능을 달성하며 뛰어난 zero-shot detection 능력을 보여줍니다.
실제 배포와 실시간 애플리케이션에 중점을 둔 OmDet-Turbo는 견고한 detection 능력과 효율적인 추론 속도 간의 균형을 제공합니다. Open-vocabulary 시나리오에서 높은 정확도를 달성하는 모델의 능력과 인상적인 성능 지표가 결합되어, 산업 object detection 작업을 위한 유망한 선택으로 자리매김합니다.
혁신적인 설계 선택과 세심한 최적화의 조합을 통해 OmDet-Turbo는 실시간 transformer 기반 object detection 분야에서 상당한 발전을 나타냅니다.
