- 해당 블로그 포스트는 RAG From Scratch : Coursework
강의 파트 12 - 14 내용을 다루고 있습니다.
| 비디오 | 요약 | 강의 링크 | 슬라이드 |
|---|---|---|---|
| Part 12 (다중 표현 인덱싱) | 효율적인 검색을 위해 문서 요약을 인덱싱하면서도 전체 문서와 연결하여 포괄적인 이해를 제공하는 방법을 논의합니다. | 📌 강의 | 📖 참고자료 |
| Part 13 (RAPTOR) | 문서 요약과 클러스터링을 통해 고수준 개념을 포착하는 RAPTOR 기법을 소개합니다. | 📌 강의 | 📖 참고자료 |
| Part 14 (ColBERT) | RAG 프레임워크 내에서 강화된 토큰 기반 검색을 위한 ColBERT를 탐구합니다. | 📌 강의 | 📖 참고자료 |
필요 패키지 설치
# ! pip install langchain_community tiktoken langchain-openai langchainhub chromadb langchain youtube-transcript-api pytubePart 12 (인덱싱/다중표현인덱싱)
-
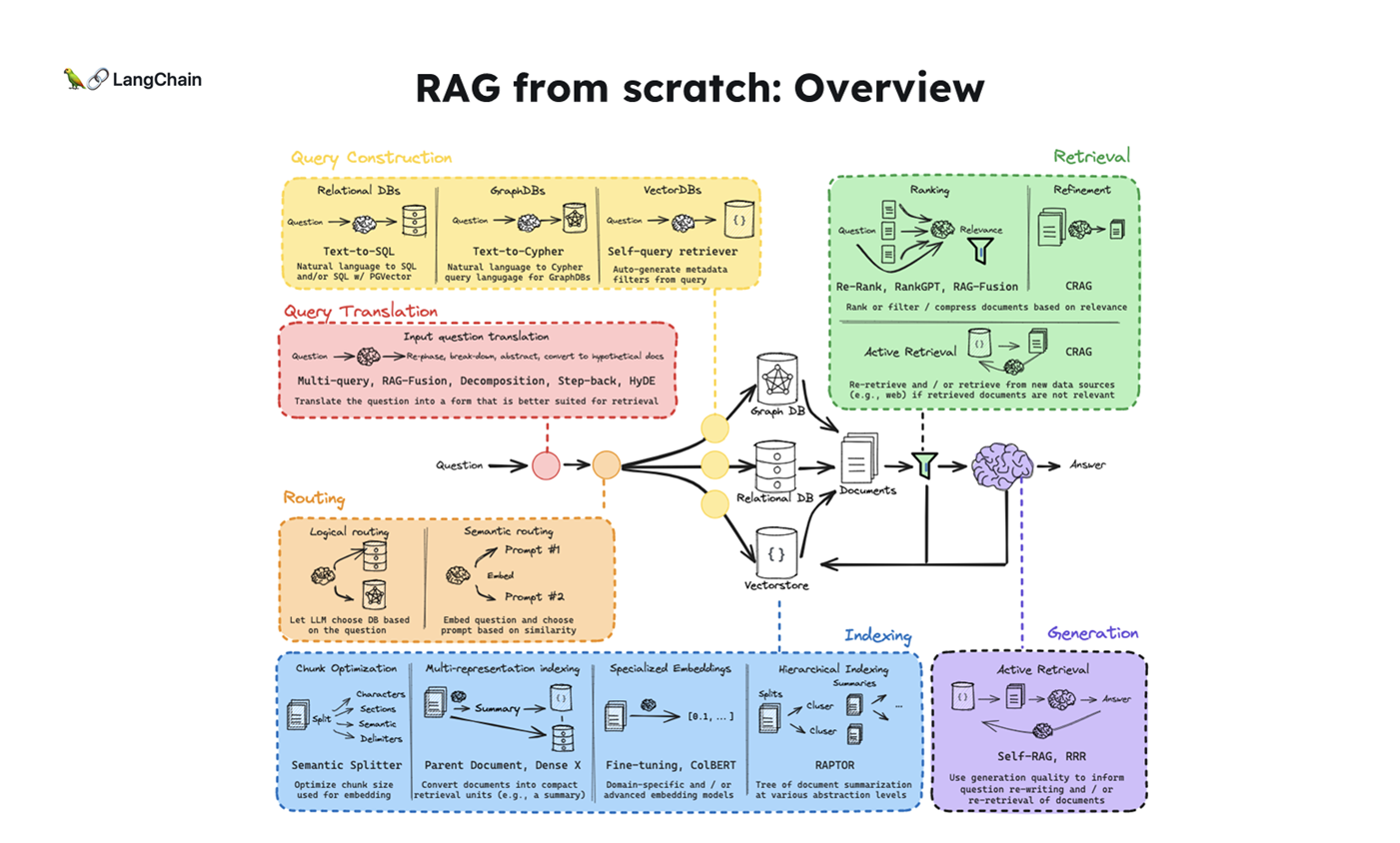
위 그림의 단계에 따라 각 과정의 역할과 개념을 간략하게 설명하겠습니다:
-
Question (질문) : 사용자가 시스템에 입력하는 자연어 형태의 질문입니다. 이는 전체 프로세스의 시작점이 됩니다.
-
Query Translation (쿼리 번역) : 사용자의 자연어 질문을 시스템이 이해할 수 있는 형식으로 변환하는 과정입니다. 이는 자연어 처리 기술을 활용하여 수행됩니다.
-
Routing (라우팅) : 변환된 쿼리를 적절한 처리 경로나 데이터 소스로 안내하는 과정입니다. 질문의 특성에 따라 최적의 처리 방법을 결정합니다.
-
Query Construction (쿼리 구성) : 라우팅된 정보를 바탕으로 실제 데이터베이스나 검색 엔진에서 사용할 수 있는 형태의 쿼리를 구성합니다.
-
Indexing (인덱싱, 이번 챕터📌) : 데이터베이스나 문서 컬렉션에서 효율적인 검색을 위해 데이터를 구조화하고 조직화하는 과정입니다. 이는 주로 시스템 구축 단계에서 수행됩니다.
-
Retrieval (검색) : 구성된 쿼리를 사용하여 인덱싱된 데이터에서 관련 정보를 추출하는 과정입니다. 이 단계에서 질문과 가장 관련성 높은 정보를 찾아냅니다.
-
Generation (생성) : 검색된 정보를 바탕으로 질문에 대한 답변을 생성하는 과정입니다. 이 단계에서는 주로 자연어 생성 기술이 사용됩니다.
-
Answer (답변) : 최종적으로 생성된 답변을 사용자에게 제공합니다. 이는 원래 질문에 대한 응답으로, 자연어 형태로 표현됩니다.
-
-
이번 강의는 Indexing(인덱싱), 그리고 그 중에서도 Multi-Representation Indexing(다중 표현 인덱싱)이라는 개념을 다루고 있습니다.
-
Multi-Representation Indexing(다중 표현 인덱싱)은 벡터 스토어에서 정보를 효율적으로 검색하는 데 중요한 기법입니다.
- 이 기법은 자연어 질문에 대한 최적의 문서 검색을 가능하게 하며, 특히 긴 문맥을 처리하는 LLM(Long Context Language Models)에서 매우 유용합니다.
1. Indexing이란?
- 인덱싱은 문서나 데이터를 저장하고 나중에 검색할 수 있도록 준비하는 과정입니다.
- 벡터 스토어(Vector Store)는 문서를 벡터로 변환하여 저장하는 방식으로, 문서의 주요 특징들을 벡터 형태로 인덱싱하고 나중에 유사도 검색을 통해 관련 문서를 찾아낼 수 있습니다.
- 예를 들어, 문서에서 중요한 키워드를 추출하여 벡터로 변환하고 이를 저장한 후, 질문과 유사한 키워드를 가진 문서를 검색하는 것입니다.
2. Multi-Representation Indexing이란?
- Multi-Representation Indexing은 문서의 여러 표현 방식을 사용하여 문서를 저장하고 검색하는 기법입니다.
- 이 기법은 한 문서를 단순히 나누어 저장하는 것이 아니라, LLM을 사용해 문서를 요약하고 그 요약을 벡터로 변환하여 저장합니다.
- 나중에 검색할 때 이 요약된 내용을 통해 문서를 검색한 후, 전체 문서를 반환하는 방식으로 동작합니다.
-
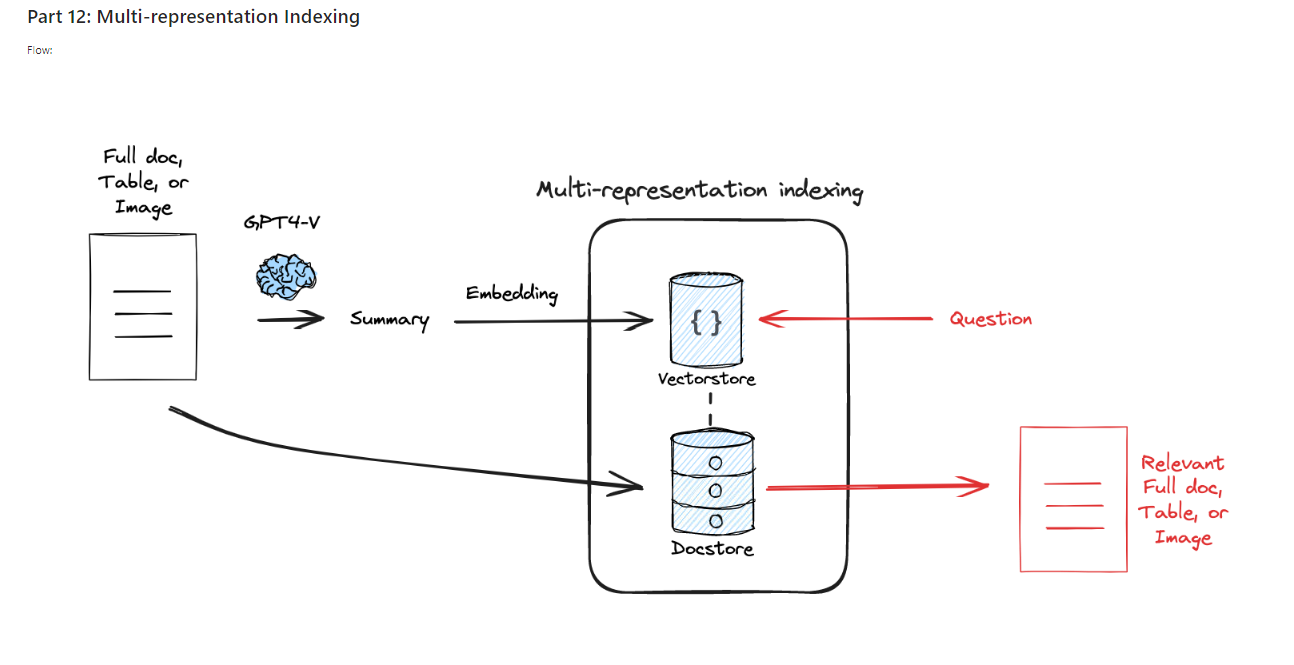
주요 절차:
- 문서 요약: 원본 문서를 요약하여 중요한 키워드를 포함한 요약본을 생성합니다.
- 요약본 인덱싱: 요약된 문서를 벡터로 변환하여 벡터 스토어에 저장합니다.
- 전체 문서 저장: 원본 문서는 별도의 문서 저장소(Doc Store)에 저장하여 검색 후에 원문을 반환할 수 있도록 준비합니다.
- 검색: 사용자가 질문을 하면, 질문과 유사한 요약본을 벡터 스토어에서 찾아내고, 해당 요약본에 연결된 원본 문서를 문서 저장소에서 반환합니다.
-
이 방식은 요약본을 통해 빠르게 검색한 후 전체 문서를 반환함으로써 검색 성능을 향상시키고, 긴 문서를 처리하는 데 유리합니다.
3. Multi-Representation Indexing의 장점
- 빠른 검색: 요약된 내용을 벡터로 인덱싱하기 때문에 검색 속도가 빠릅니다.
- 정확한 문서 반환: 검색 후에는 원본 문서 전체를 반환하여 질문에 대한 충분한 문맥을 제공합니다.
- LLM과의 통합: LLM이 문서를 요약하고 그 요약본을 검색에 사용함으로써, 문서의 핵심 내용을 기반으로 더 정확한 검색이 가능합니다.
4. 코드 설명
- 다음은 두 개의 블로그 포스트를 로드하고, 요약하여 Multi-Representation Indexing을 수행하는 예시입니다.
4.1 웹 문서 로드 및 요약 생성
- 위 코드는 웹에서 두 개의 문서를 로드합니다. 이후 이 문서를 요약하여 벡터 스토어에 저장합니다.
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
docs = loader.load()
loader = WebBaseLoader("https://lilianweng.github.io/posts/2024-02-05-human-data-quality/")
docs.extend(loader.load())
len(docs) # 2 4.2 LLM을 이용한 문서 요약
- 이 코드는 LLM을 사용하여 문서를 요약하는 과정을 보여줍니다. 각 문서는 요약본으로 변환되고, 이 요약본은 벡터 스토어에 저장됩니다.
import uuid
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
chain = (
{"doc": lambda x: x.page_content}
| ChatPromptTemplate.from_template("Summarize the following document:\n\n{doc}")
| Azure_Chat #ChatOpenAI(model="gpt-3.5-turbo",max_retries=0)
| StrOutputParser()
)
summaries = chain.batch(docs, {"max_concurrency": 5})
summaries-
chain.batch(docs, {"max_concurrency": 5})에서max_concurrency: 5는 다음과 같은 의미를 가집니다:-
동시 처리 문서 수: 한 번에 최대 5개의 문서를 병렬로 처리합니다.
-
처리 속도 최적화: 5개씩 문서를 묶어 처리함으로써 전체 처리 시간을 단축합니다.
-
리소스 관리: 시스템 리소스 사용을 제어하여 과부하를 방지합니다.
-
-
해당 예시의 경우, 문서가 2개이기 때문에
max_concurrency: 5로 설정되어 있더라도 실제 처리 과정은 다음과 같이 진행됩니다:- 동시 처리: 두 문서 모두 동시에 처리됩니다.
max_concurrency가 5로 설정되어 있지만, 실제 문서 수가 2개이므로 2개만 병렬로 처리됩니다.
- 동시 처리: 두 문서 모두 동시에 처리됩니다.
4.3 벡터 스토어 및 문서 저장소 설정
- 여기서는 요약된 문서를 벡터 스토어에 저장하고, 원본 문서는 별도의 문서 저장소에 저장하여 검색할 수 있도록 설정합니다.
from langchain.storage import InMemoryByteStore
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.retrievers.multi_vector import MultiVectorRetriever
# 요약본을 저장할 벡터 스토어
vectorstore = Chroma(collection_name="summaries",
embedding_function=OpenAIEmbeddings())
# 원본 문서를 저장할 문서 저장소
store = InMemoryByteStore()
# 요약본과 원본 문서를 연결하는 키
id_key = "doc_id"
# 요약본과 원본 문서를 통합하는 검색기
retriever = MultiVectorRetriever(vectorstore=vectorstore,
byte_store=store,
id_key=id_key,
)
4.4 문서 검색 및 반환
- 이 코드는 "Memory in agents"라는 질문에 대해 요약본을 검색하고, 해당 요약본에 연결된 원본 문서를 반환합니다.
# 요약본과 원본 문서 연결
doc_ids = [str(uuid.uuid4()) for _ in docs]
summary_docs = [Document(page_content=s, metadata={id_key: doc_ids[i]}) for i, s in enumerate(summaries)]
# 벡터 스토어에 요약본 추가
retriever.vectorstore.add_documents(summary_docs)
# 문서 저장소에 원본 문서 추가
retriever.docstore.mset(list(zip(doc_ids, docs)))
# 검색 쿼리
query = "Memory in agents"
# 요약본으로부터 문서 검색
sub_docs = vectorstore.similarity_search(query, k=1)
# 검색된 원본 문서 반환
retrieved_docs = retriever.get_relevant_documents(query, n_results=1)
retrieved_docs[0].page_content[0:500]

정리
- Multi-Representation Indexing은 요약본을 통해 빠르게 문서를 검색하고, 검색된 요약본에 연결된 원본 문서를 반환하는 방식입니다. 이는 검색 성능을 최적화하고, 긴 문맥을 가진 문서도 효율적으로 처리할 수 있는 기법입니다. 이 방식은 특히 벡터 스토어를 활용한 문서 검색에서 매우 유용하며, LLM을 사용해 문서를 요약하고 검색하는 데 큰 도움이 됩니다.
Part 13 (RAPTOR)
- RAPTOR는 계층적 인덱싱(hierarchical indexing) 기법으로, 대규모 문서나 텍스트 데이터에서 효율적으로 정보를 검색하는 데 사용됩니다.

1. RAPTOR 개념
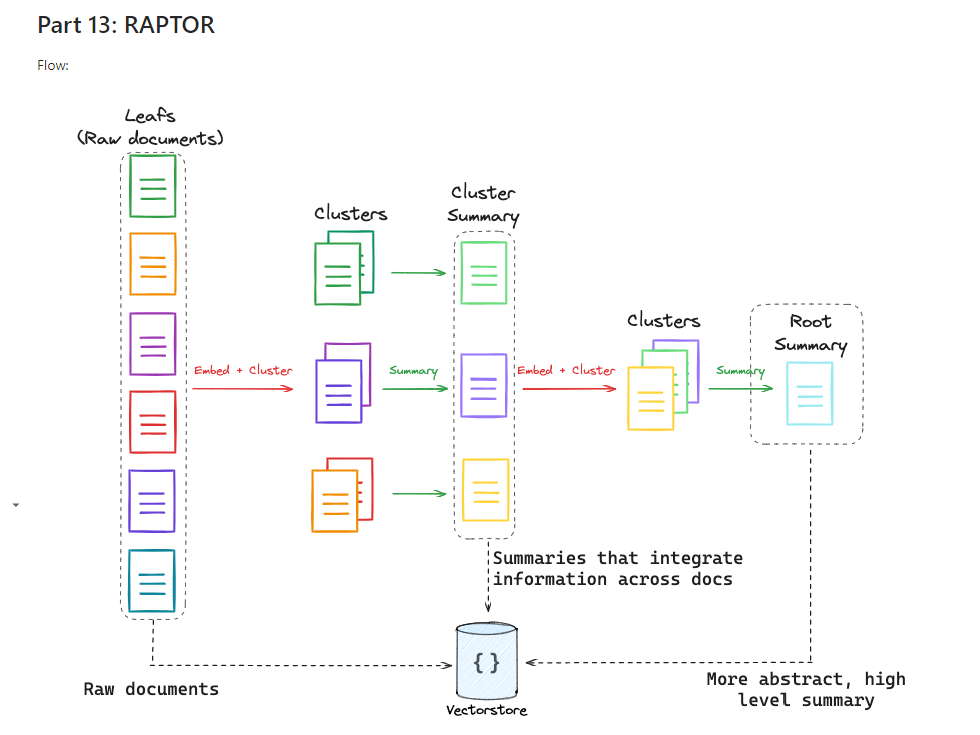
- RAPTOR (RECURSIVE ABSTRACTIVE PROCESSING FOR TREE-ORGANIZED RETRIEVAL)는 문서 집합을 여러 단계로 요약하여 트리 구조를 형성하는 기법입니다. 이는 다양한 질문 유형에 맞게 정보를 추출할 수 있도록 돕는 방식입니다.
- 즉, 특정 질문이 세부적인 정보를 요구하는 경우에는 하위 노드(세부 문서나 작은 정보 조각)를, 상위 개념을 다루는 질문에는 상위 노드(문서 요약)를 검색하여 답을 제공할 수 있습니다.
2. 계층적 추상화
RAPTOR의 핵심 개념은 바로 계층적 추상화(hierarchical abstraction)입니다.- 문서나 데이터가 여러 개의 작은 조각으로 나뉘며, 각 조각은 상위 레벨에서 요약되고, 이 과정을 반복하여 최종적으로 전체 문서를 요약한 최상위 요약을 생성합니다.
- 이렇게 생성된 요약 트리는 질문에 따라 적절한 수준의 정보를 추출할 수 있도록 합니다.
- 세부적인 질문에 대해서는 개별 문서나 작은 데이터 조각에서 정보를 가져오고, 더 큰 범위의 질문에 대해서는 상위 레벨에서 요약된 정보를 검색합니다.
3. RAPTOR의 동작 방식
RATOR의 동작을 더 깊이 있게 설명하기 위해 위 코드의 작동 원리와 구체적인 프로세스를 다음과 같이 설명할 수 있습니다.
-
3.1. 문서 로드 및 벡터화:
-
문서의 텍스트 데이터를 먼저 로드하고, 이를 벡터화합니다. 벡터화는 텍스트 데이터를 숫자로 변환하여 계산할 수 있는 형태로 만드는 중요한 과정입니다. 이 단계에서는 문서 내에서 단어나 문장 간의 의미적 유사도를 반영할 수 있도록 각 문서가 고차원의 벡터로 표현됩니다. 벡터화된 데이터는 이후 클러스터링이나 검색에서 활용됩니다.
docs = loader.load() # 문서 로드 docs_texts = [d.page_content for d in docs] # 텍스트 추출 text_embeddings = embd.embed_documents(docs_texts) # 문서 벡터화
-
-
3.2. 클러스터링 및 요약:
-
문서 간 유사성을 기준으로 클러스터링을 수행합니다. 클러스터링은 비슷한 문서들을 묶어주는 과정으로, Gaussian Mixture Model (GMM)을 활용하여 클러스터의 개수를 결정하고 각 문서가 어느 클러스터에 속하는지 결정합니다. 이후 클러스터 내 문서들을 요약하여 각 클러스터의 주요 내용을 간결하게 정리합니다.
df_clusters, df_summary = embed_cluster_summarize_texts(docs_texts, level=1) -
embed_cluster_summarize_texts함수def embed_cluster_summarize_texts( texts: List[str], level: int ) -> Tuple[pd.DataFrame, pd.DataFrame]:-
기능: 주어진 텍스트 목록을 임베딩하고, 클러스터링을 수행한 후 클러스터 내의 문서들을 요약합니다. 결과적으로 클러스터화된 문서 정보와 각 클러스터의 요약 정보를 반환합니다.
-
입력 인자:
texts: 문서의 리스트로, 각 문서가 문자열로 표현됩니다. 이 리스트는 클러스터링의 대상이 되는 텍스트 데이터를 담고 있습니다.level: 클러스터링 및 요약의 깊이를 나타내는 매개변수입니다. 주로 재귀적 요약 과정에서 이 값이 증가합니다.
-
출력:
df_clusters: 각 문서와 그 임베딩, 클러스터 정보가 담긴DataFrame.df_summary: 각 클러스터의 요약 정보가 담긴DataFrame.
-
-
-
3.3. 재귀적 요약:
-
클러스터별 요약을 한 번 수행한 후, 이를 다시 상위 레벨에서 클러스터링하고 요약하는 과정을 반복합니다. 이를 통해 문서의 계층적 구조를 분석하고, 고수준 요약을 점진적으로 생성할 수 있습니다. 재귀적 요약을 통해 문서 전체를 더 잘 이해할 수 있도록 돕습니다.
results = recursive_embed_cluster_summarize(docs_texts, level=1, n_levels=3) -
recursive_embed_cluster_summarize함수def recursive_embed_cluster_summarize( texts: List[str], level: int = 1, n_levels: int = 3 ) -> Dict[int, Tuple[pd.DataFrame, pd.DataFrame]]:-
기능: 주어진 텍스트 목록에 대해 재귀적으로 클러스터링과 요약을 수행하는 함수입니다. 기본적으로 3단계까지 재귀를 수행하며, 각 단계에서 생성된 클러스터와 요약 결과를 저장합니다.
-
입력 인자:
texts: 클러스터링 및 요약 대상이 되는 텍스트 데이터 리스트.level: 현재 재귀 수준을 나타냅니다. 기본값은 1이며, 재귀 호출 시 이 값이 증가합니다.n_levels: 재귀 호출의 최대 깊이로, 기본값은 3입니다. 최대 3단계까지 재귀적으로 클러스터링 및 요약을 수행합니다.
-
출력:
- 각 재귀 레벨별 클러스터 및 요약 정보를 담고 있는
Dict. - 각 레벨의 결과는 튜플 형태의
(df_clusters, df_summary).
- 각 재귀 레벨별 클러스터 및 요약 정보를 담고 있는
-
-
-
3.4. 검색 기능 구현:
-
벡터화된 문서들을 벡터 스토어에 인덱싱하여 사용자가 질문할 때 관련 문서를 검색할 수 있는 기능을 구현합니다. 이를 통해 사용자는 방대한 양의 문서 중에서 원하는 정보를 신속하게 검색할 수 있습니다.
vectorstore = Chroma.from_texts(texts=all_texts, embedding=embd) retriever = vectorstore.as_retriever() -
벡터 스토어는 문서의 벡터화를 저장하고 관리하며, 새로운 입력 질문에 대해 가장 관련성 높은 문서들을 반환합니다.
-
retriever는 검색 시에 유사한 문서를 찾는 역할을 하며, 벡터 간의 거리를 계산하여 가장 가까운 문서들을 반환합니다.
-
-
3.5. RAG 체인 구성:
-
검색된 문서들을 기반으로 답변을 생성하는 RAG (Retrieval-Augmented Generation) 체인을 구성합니다. RAG는 검색된 문서를 기반으로 더 구체적이고 맥락에 맞는 답변을 생성할 수 있는 모델로, 검색 결과를 문맥에 맞추어 잘 정리하여 제공하는 강력한 방법론입니다.
rag_chain = ( {"context": retriever | format_docs, "question": RunnablePassthrough()} | prompt | model | StrOutputParser() ) rag_chain.invoke("How to define a RAG chain?") -
질문을 입력받으면 검색된 문서의 내용과 질문을 결합하여 문서의 중요한 내용을 기반으로 답변을 생성합니다.
-
StrOutputParser는 생성된 텍스트를 후처리하여 구조화된 응답을 반환합니다.
-
Part 14 (ColBERT)
- 이번 강의는 ColBERT라는 새로운 검색 방법론을 다룹니다. ColBERT는 기존의 임베딩 방식에서 발생하는 한계를 보완하여, 더 나은 문서 검색 성능을 제공하는 방법입니다. 이번 설명에서는 ColBERT의 개념과 그 구현 방법을 자세히 살펴보겠습니다.
1. ColBERT의 개념
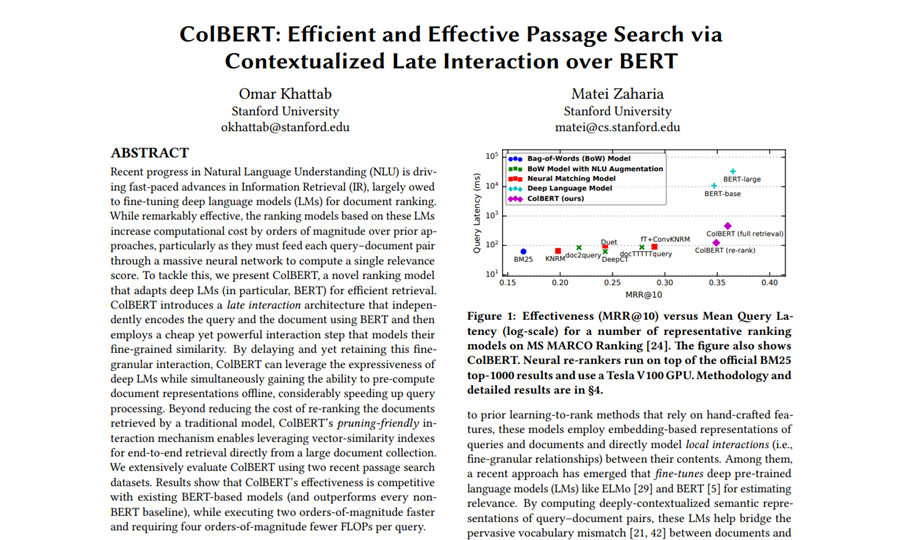
- 다음 패키지를 설치하셔야 사용이 가능합니다:
! pip install -U ragatouille1.1 전통적인 임베딩 방법의 한계
- 기존의 문서 검색은 문서 전체를 하나의 벡터로 임베딩(embedding) 하여 이를 이용한 K-최근접 이웃(K-Nearest Neighbors, KNN) 방식으로 검색을 진행합니다. 즉, 문서 전체를 하나의 벡터로 축약한 후, 질문을 같은 방식으로 벡터화하여 두 벡터 간의 유사도를 계산해 가장 유사한 문서를 찾는 방식입니다.
- 하지만 이 방식은 문서 전체를 하나의 벡터로 압축하는 과정에서 많은 세부 정보(nuance) 를 잃을 수 있다는 한계를 가지고 있습니다.
1.2 ColBERT의 해결책
- ColBERT (Contextualized Late Interaction over BERT)는 이러한 문제를 해결하기 위해 문서를 단순히 하나의 벡터로 축약하지 않고, 문서를 여러 토큰(token)으로 나누어 각 토큰에 대해 개별 임베딩을 생성합니다.
- 그리고 질문에 대해서도 동일한 방식으로 임베딩을 진행하여, 각 질문의 토큰과 문서의 모든 토큰 간의 유사도를 계산합니다. - 각 질문 토큰이 문서 내에서 가장 유사한 토큰을 찾고, 이 유사도 값들의 합을 최종적으로 문서와 질문 간의 유사도로 사용합니다.
2. ColBERT의 동작 방식
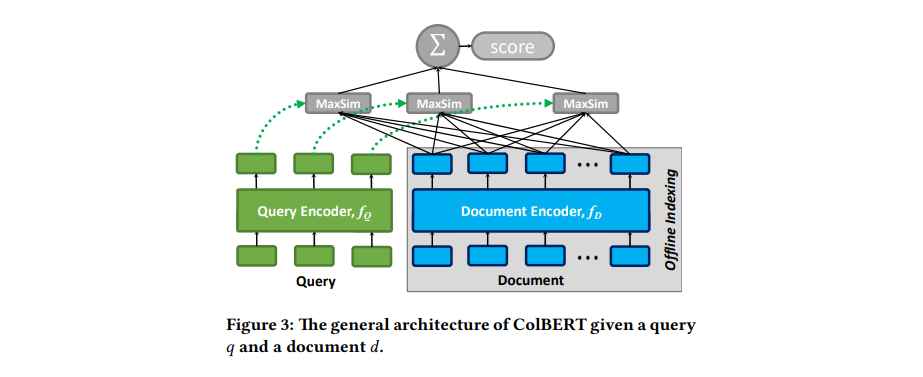
2.1 토큰화 및 임베딩
- 문서를 임베딩할 때, ColBERT는 문서 전체를 하나의 벡터로 압축하는 대신 토큰화(tokenization) 를 진행합니다. 토큰은 문서의 각 단어나 의미 있는 단위로 나뉩니다.
- 각 토큰에 대해 개별적인 벡터(임베딩) 를 생성합니다. 이 과정에서 각 토큰의 위치 정보(positional information) 가 반영됩니다.
2.2 질문에 대한 처리
- 질문도 문서와 동일한 방식으로 토큰화 및 임베딩이 이루어집니다. 질문의 각 토큰에 대해 임베딩 벡터가 생성되며, 문서와의 유사도를 계산할 준비를 합니다.
2.3 유사도 계산
- 질문의 각 토큰에 대해, 문서의 모든 토큰과 유사도를 계산합니다. 각 질문 토큰에 대해 문서에서 가장 유사한 토큰을 찾고, 이 유사도 값을 저장합니다.
- 질문의 모든 토큰에 대해 이 과정을 반복한 후, 유사도 값들의 합(sum of maximum similarities) 을 최종 유사도로 사용합니다.
- 이 방식은 문서 전체의 정보를 하나로 압축하는 대신, 각각의 세부 정보가 유지되도록 하여 더 정확한 검색 결과를 제공합니다.
3. ColBERT의 특징
- ColBERT는 문서의 세부적인 정보를 효과적으로 반영하기 때문에, 긴 문서나 복잡한 질문에 대한 검색 성능이 뛰어납니다.
- 하지만 이 방식은 모든 토큰 간의 유사도를 계산하기 때문에 처리 속도가 느릴 수 있으며, 실시간 응답이 필요한 환경에서는 성능 문제가 발생할 수 있습니다.
4. ColBERT 구현 예시
- 이제 ColBERT를 사용하는 코드 예시를 살펴보겠습니다.
- 여기서는 RAG 방식에 ColBERT를 적용하여 문서 검색을 수행합니다.
- 링크 : https://python.langchain.com/docs/integrations/retrievers/ragatouille/
4.1 Load Pretrained Model
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")4.2 Load Docs from Wikipedia
- 이 코드는 ColBERT 모델을 사용하여 Hayao Miyazaki의 Wikipedia 페이지를 가져와서 토큰화 및 인덱싱을 진행하는 과정입니다.
import requests
def get_wikipedia_page(title: str):
"""
Retrieve the full text content of a Wikipedia page.
:param title: str - Title of the Wikipedia page.
:return: str - Full text content of the page as raw string.
"""
# Wikipedia API endpoint
URL = "https://en.wikipedia.org/w/api.php"
# Parameters for the API request
params = {
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
"explaintext": True,
}
# Custom User-Agent header to comply with Wikipedia's best practices
headers = {"User-Agent": "RAGatouille_tutorial/0.0.1 (ben@clavie.eu)"}
response = requests.get(URL, params=params, headers=headers)
data = response.json()
# Extracting page content
page = next(iter(data["query"]["pages"].values()))
return page["extract"] if "extract" in page else None
# Get Document
full_document = get_wikipedia_page("Hayao_Miyazaki")
# Create Index
RAG.index(
collection=[full_document],
index_name="Miyazaki-123",
max_document_length=180,
split_documents=True,
)4.3 Search Query
- 이제 문서에 대해 질문을 던져 검색하는 과정을 진행할 수 있습니다.
results = RAG.search(query="What animation studio did Miyazaki found?", k=3)
results- 위 코드를 실행하면, "Miyazaki가 설립한 애니메이션 스튜디오는?"이라는 질문에 대해 관련된 답변이 검색됩니다.
4.4 Merge with LangChain
- LangChain 내에서 ColBERT를 retriever로 사용하여 더 복잡한 응답을 처리할 수 있습니다.
retriever = RAG.as_langchain_retriever(k=3)
retriever.invoke("What animation studio did Miyazaki found?")- 이 코드를 통해 LangChain에서 ColBERT를 사용하여 검색 기능을 강화할 수 있습니다.
