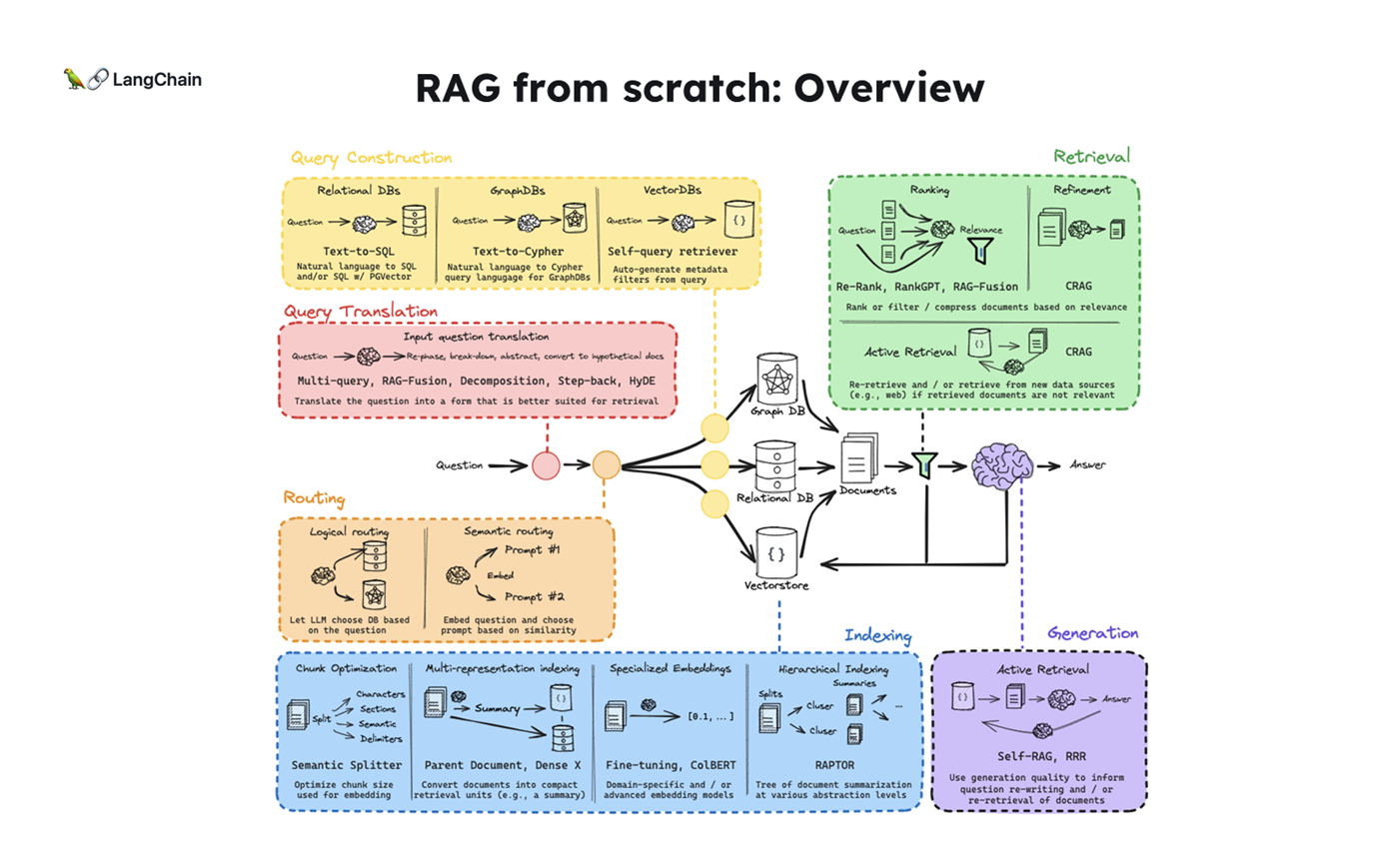
-
해당 블로그 포스트는 RAG From Scratch : Coursework
강의 파트 15 - 18 내용을 다루고 있습니다. -
별도의 강좌 내용이 보이지 않아서 실습 코드를 바탕으로
Reverse Enginneering해서 자료를 정리한 내용입니다. 참고 부탁드립니다!
1. Re-ranking (재정렬)
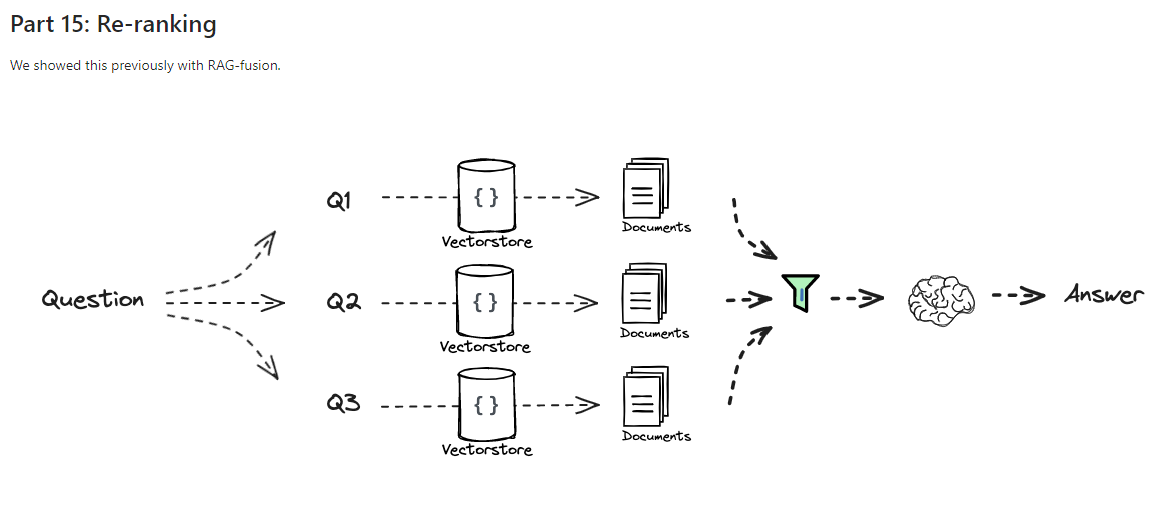
-
Re-ranking은 검색 시스템에서 초기 검색 결과의 순위를 다시 매기는 과정입니다. 검색된 결과가 사용자의 기대에 부합하지 않거나, 관련성이 충분하지 않을 때 주로 사용됩니다. 기본적으로 검색 알고리즘이 먼저 수행되고, 그 결과를 재정렬하여 사용자에게 더 적합한 항목을 상위에 노출합니다. Re-ranking 과정에서는 사용자의 과거 행동 데이터나 문맥적 요소, 최신성 등 여러 가지 요인을 반영하여 순위를 조정하게 됩니다.
-
Reciprocal Rank Fusion (RRF) 알고리즘은 여러 검색 결과를 종합하여 재정렬하는 방법 중 하나로, 여러 검색 시스템에서 나온 결과의 순위를 고려하여 검색 결과를 결합합니다. RRF는 검색 결과의 상호 순위에 기반하여 가중치를 부여하는 방식입니다. 각 결과에 대해 순위 역수를 가산하며, 이를 통해 상위에 노출된 결과가 우선시됩니다.
주요 특징:
- 초기 검색 결과 개선: 첫 번째 검색에서 놓친 관련 항목들을 상위로 끌어올립니다.
- 다양한 요소 고려: 사용자 선호도, 문맥, 최신성 등 다양한 요소를 고려하여 순위를 조정합니다.
- 머신러닝 활용: 많은 re-ranking 시스템은 머신러닝 알고리즘을 사용하여 더 정확한 순위를 매깁니다.
Re-ranking 코드 예시 (RRF)
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_core.output_parsers import StrOutputParser
from langchain.prompts import ChatPromptTemplate
# 벡터 스토어 생성 및 문서 로드
documents = ["This is document 1 about LLM.", "This is document 2 about AI agents."]
vectorstore = Chroma.from_documents(
documents=documents,
embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()
# 쿼리 생성 및 검색
query = "What is LLM?"
results = retriever.get_relevant_documents(query)
# RRF 재정렬 함수
def reciprocal_rank_fusion(results, k=60):
fused_scores = {}
for rank, doc in enumerate(results):
if doc not in fused_scores:
fused_scores[doc] = 0
fused_scores[doc] += 1 / (rank + k)
reranked_results = sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
return reranked_results
# RRF를 적용한 재정렬
reranked_results = reciprocal_rank_fusion(results)
print("Reranked results:", reranked_results)
코드 부연 설명:
reciprocal_rank_fusion함수는 각 검색 결과의 순위를 받아 해당 순위에 따라 점수를 계산합니다. 순위가 높은 결과는 역수 방식으로 높은 점수를 받습니다.k=60은 역수 계산에서 추가적인 가중치를 부여하는 역할을 하며, 이를 통해 순위가 너무 낮은 결과에 대한 가중치가 지나치게 작아지지 않도록 조정합니다.
2. Retrieval (CRAG)
-
CRAG는 Retrieval-Augmented Generation(RAG) 기반 시스템의 개선된 형태로, 검색된 문서의 관련성을 평가하고 필요시 질문을 다시 작성하여 검색 과정을 반복하는 방식입니다. 이 시스템은 초기 검색이 충분하지 않거나 부정확할 때 자체적으로 질문을 수정하고 추가 검색을 수행해 최종적으로 더 정확한 답변을 생성합니다.
-
CRAG의 핵심은 자기 수정 메커니즘으로, 검색된 문서가 부적절하다고 판단되면 시스템이 이를 평가하고 검색 전략을 조정합니다. 이를 통해, 사용자는 더 신뢰할 수 있는 결과를 얻을 수 있습니다.
주요특징
- 검색 평가기(Retrieval Evaluator) 도입:
- 경량 T5-large 모델을 사용하여 검색된 문서와 쿼리 간의 관련성을 평가합니다.
- 검색 결과를 "정확", "부정확", "모호"로 분류합니다.
- 자기 수정 메커니즘:
- 검색된 문서가 부적절하다고 판단되면, 시스템이 자동으로 수정 작업을 수행합니다.
- 웹 검색을 통해 추가 정보를 획득하여 검색 결과를 개선합니다.
- 분해-재구성(Decompose-then-Recompose) 알고리즘:
- 검색된 문서에서 가장 중요한 지식을 추출하고 재구성합니다.
- 불필요하거나 관련 없는 정보를 필터링하여 핵심 정보만 활용합니다.
- 유연한 통합:
- 기존 RAG 기반 시스템에 플러그 앤 플레이 방식으로 쉽게 통합될 수 있습니다.
- 성능 향상:
- 검색 결과의 품질을 개선함으로써 최종 생성 결과의 정확성과 관련성을 높입니다.
CRAG 코드 예시
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# 검색기 및 검색 도구
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
web_search_tool = TavilySearchResults(k=3)
# 질문 재작성 LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
rewrite_prompt = ChatPromptTemplate.from_template(
"Here is the initial question: {question}. Rephrase this question for better search."
)
def corrective_rag(question):
# 1단계: 벡터 스토어 검색
results = retriever.get_relevant_documents(question)
# 2단계: 문서 평가
if not results or len(results) < 1:
# 3단계: 질문 재작성 및 웹 검색
rewritten_question = rewrite_prompt.invoke({"question": question})
web_results = web_search_tool.invoke({"query": rewritten_question})
results.extend(web_results)
return results
question = "What are AI agents?"
corrected_docs = corrective_rag(question)
print(corrected_docs)
코드 부연 설명:
corrective_rag함수는 검색된 결과를 평가하고, 그 결과가 충분하지 않을 경우 질문을 재작성하여 웹 검색을 수행하는 구조입니다.- 여기서
rewrite_prompt는 초기 질문을 다시 작성하는 LLM 호출을 통해 이루어지며, 이는 질문을 명확하게 하거나 세분화하여 더 나은 검색 결과를 유도합니다.
3. Retrieval (Self-RAG)
-
Self-RAG는 언어 모델이 자체적으로 정보를 검색하고, 생성한 결과를 비평하며 필요시 추가 검색을 수행하는 방식입니다. 이는 기존 RAG 시스템에서 발생할 수 있는 제한 사항을 보완하고, 모델이 스스로 생성 결과를 평가하여 더 나은 답변을 만들 수 있는 유연성을 제공합니다. 즉, 모델은 생성된 답변이 충분히 관련성이 없다고 판단되면, 추가 정보를 검색해 이를 보완합니다.
-
이러한 자가 반영 메커니즘은 특히 정확성이 중요한 분야에서 유용하게 사용될 수 있으며, 모델이 한 번의 검색으로 충분한 정보를 얻지 못할 때 이를 인지하고 추가적으로 검색할 수 있도록 해줍니다.
주요 특징:
- 자가 반영: 모델이 자신의 출력을 평가하고 개선합니다.
- 동적 검색: 필요에 따라 추가 정보를 검색합니다.
- 비평 능력: 생성된 내용의 정확성과 관련성을 평가합니다.
Self-RAG 코드 예시
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
# 문서 및 벡터 스토어 설정
documents = ["Document 1 about LLM", "Document 2 about AI agents"]
vectorstore = Chroma.from_documents(
documents=documents,
embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()
# LLM 및 문서 평가
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
def self_rag(question):
# 1단계: 검색
results = retriever.get_relevant_documents(question)
# 2단계: 답변 생성
generated_answer = llm.invoke({
"context": results,
"question": question
})
# 3단계: 생성된 답변 평가
if "insufficient" in generated_answer:
# 문서가 충분하지 않다면 추가 검색
additional_results = retriever.get_relevant_documents(f"{question} more details")
results.extend(additional_results)
generated_answer = llm.invoke({
"context": results,
"question": question
})
return generated_answer
question = "What are the types of AI agents?"
answer = self_rag(question)
print(answer)
코드 부연 설명:
self_rag함수에서는 먼저 검색을 통해 문서를 가져온 후, 그 문서를 기반으로 LLM이 답변을 생성합니다.- 만약 모델이 답변을 생성한 후에 답변이 충분하지 않다고 판단하면, 추가 검색을 수행하여 답변을 개선합니다.
4. Active RAG
- Active RAG는 LLM이 언제, 어디서 정보를 추가로 검색할지 스스로 판단하는 방식입니다. 이는 초기 질문에 대해 기본 응답을 생성한 후, 시스템이 자율적으로 후속 질문을 생성하거나 추가 검색을 통해 더 나은 답변을 생성하는 능력을 갖추고 있습니다. Active RAG의 주된 목표는 첫 번째 생성된 답변에 만족하지 않고, 더 나은 답변을 위해 적극적으로 추가 작업을 수행하는 데 있습니다.
주요 특징:
- 반복적 검색: 초기 응답 후 추가 정보를 검색합니다.
- 질문 생성: 모델이 스스로 후속 질문을 생성합니다.
- 응답 개선: 새로운 정보를 바탕으로 초기 응답을 개선합니다.
Active RAG 코드 예시
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.prompts import ChatPromptTemplate
# 질문 분석 및 웹 검색 도구
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
web_search_tool = TavilySearchResults(k=3)
# 질문 라우팅 및 Active RAG
def active_rag(question):
# 질문 분석
initial_results = retriever.get_relevant_documents(question)
if len(initial_results) < 2: # 문서가 부족하면 웹 검색 수행
additional_results = web_search_tool.invoke({"query": question})
initial_results.extend(additional_results)
# 최종 답변 생성
answer = llm.invoke({
"context": initial_results,
"question": question
})
return answer
question = "What is LLM task decomposition?"
final_answer = active_rag(question)
print(final_answer)
코드 부연 설명:
active_rag함수는 초기 검색을 수행한 후, 검색된 문서가 부족하거나 관련성이 낮으면 웹 검색 도구를 이용해 추가 검색을 실행하는 구조입니다.- 이를 통해 더 풍부한 검색 결과를 얻어 최종적으로 더 나은 답변을 생성합니다.
5. Adaptive RAG
-
Adaptive RAG는 질문의 성격에 따라 적절한 검색 방법을 동적으로 선택하는 시스템입니다. 즉, 질문이 단순하면 간단한 벡터 스토어 검색을 사용하고, 질문이 복잡하면 웹 검색이나 데이터베이스 조회를 선택하는 방식으로 질문의 복잡성과 필요에 따라 최적의 검색 전략을 적용합니다. 이를 통해 리소스를 효율적으로 사용하고, 복잡한 질문에 대해 더 정확하고 신속한 답변을 생성할 수 있습니다.
-
Adaptive RAG는 다양한 검색 방법을 적절히 조합하여 다양한 질문 유형에 대해 높은 성능을 발휘할 수 있도록 설계되었습니다.
주요 특징:
- 동적 전략 선택: 질문에 따라 다른 검색 방법을 선택합니다.
- 복잡성 평가: 질문의 복잡성을 분석하여 적절한 접근 방식을 결정합니다.
- 리소스 최적화: 간단한 질문에는 간단한 검색, 복잡한 질문에는 더 심층적인 검색을 수행합니다.
Adaptive RAG 코드 예시
from langchain_openai import OpenAIEmbeddings
from langchain_core.prompts import ChatPromptTemplate
# 벡터 스토어 검색기
vector_retriever = vectorstore.as_retriever()
# LLM 설정
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# 질문 라우팅 함수
def adaptive_rag(question):
# 질문 분석 및 라우팅
if "LLM" in question:
results = vector_retriever.get_relevant_documents(question)
else:
results = web_search_tool.invoke({"query": question})
# 답변 생성
answer = llm.invoke({
"context": results,
"question": question
})
return answer
question = "What are the types of LLM agents?"
adaptive_answer = adaptive_rag(question)
print(adaptive_answer)
코드 부연 설명:
adaptive_rag함수는 질문에 따라 벡터 스토어 검색 또는 웹 검색을 선택하며, 그 결과를 기반으로 LLM이 최종 답변을 생성합니다.- 이를 통해 질문의 복잡도나 성격에 따라 검색 전략을 동적으로 조정할 수 있습니다.
