RAG for long context LLMs
Introduction
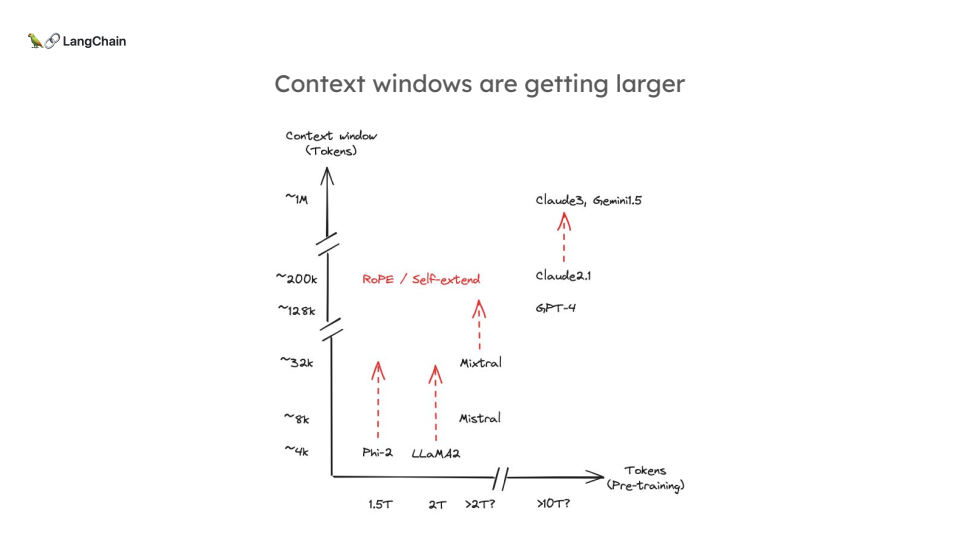
최근 LLM(Long Large Models)의 급격한 발전으로 인해 거대한 양의 데이터를 한 번에 처리할 수 있는 가능성이 열리고 있습니다. 특히, 100만 토큰 이상의 정보를 한 번에 처리할 수 있는 모델들이 등장하면서, 과연 RAG(Retrieval-Augmented Generation) 시스템이 여전히 필요한지에 대한 의문이 커지고 있습니다.
하지만, 단순히 데이터를 모델의 context window에 모두 넣는 것이 문제를 해결할 수 있을까요? 이 글에서는 LangChain의 Lance가 설명한 RAG의 현재 상태와 장문 LLM이 가져오는 새로운 도전과 기회에 대해 알아보겠습니다. (해당 글은 아래 Youtube 영상 자료를 공부 후에 정리하였습니다.)
영상 제목: RAG for long context LLMs영상 링크: https://youtu.be/SsHUNfhF32s
Background: RAG란 무엇인가?
RAG는 간단히 말해, 대형 언어 모델(LLM)이 외부 데이터베이스나 문서에서 필요한 정보를 검색(Retrieval)하고 이를 바탕으로 응답을 생성(Generation)하는 과정입니다.
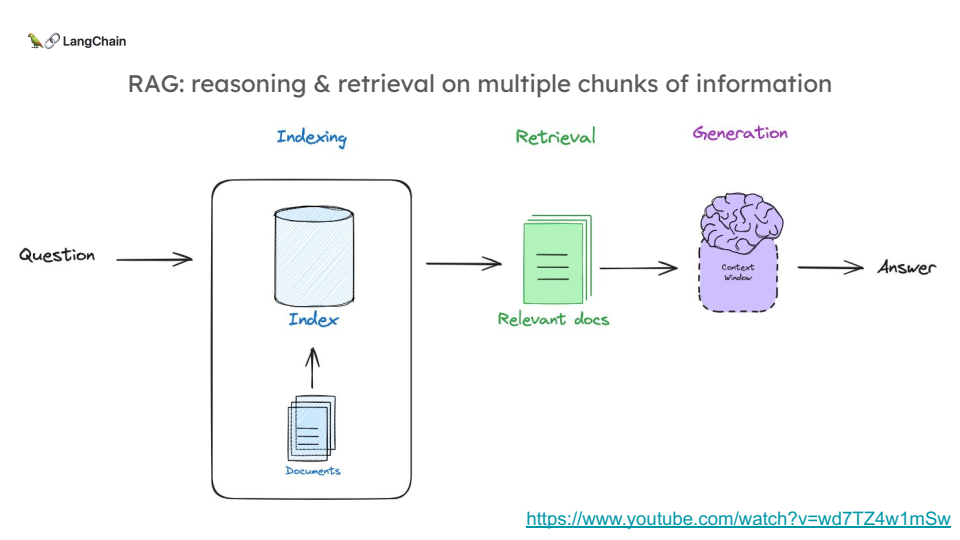
RAG는 다음과 같은 흐름을 따릅니다:
1. 문서 인덱싱: 정보를 가진 문서를 미리 인덱싱합니다.
2. 문서 검색: 질문에 맞는 문서를 검색합니다. 이때 보통 semantic similarity를 사용합니다.
3. LLM 활용: 검색된 문서를 기반으로 LLM이 응답을 생성합니다.
장문 LLM은 RAG를 대체할 수 있을까?
오늘날 Claude 3나 GPT-4 같은 최신 모델들은 최대 100만 토큰 이상의 데이터를 한 번에 처리할 수 있습니다. 이 말은 수백 페이지의 문서를 한꺼번에 모델에 넣을 수 있다는 뜻입니다. 그렇다면 이렇게 많은 데이터를 한 번에 처리할 수 있는 모델이 RAG 시스템을 대체할 수 있을까요?
Lance는 이 질문에 답하기 위해 몇 가지 실험을 설계했습니다.
실험: Needle in a Haystack 테스트
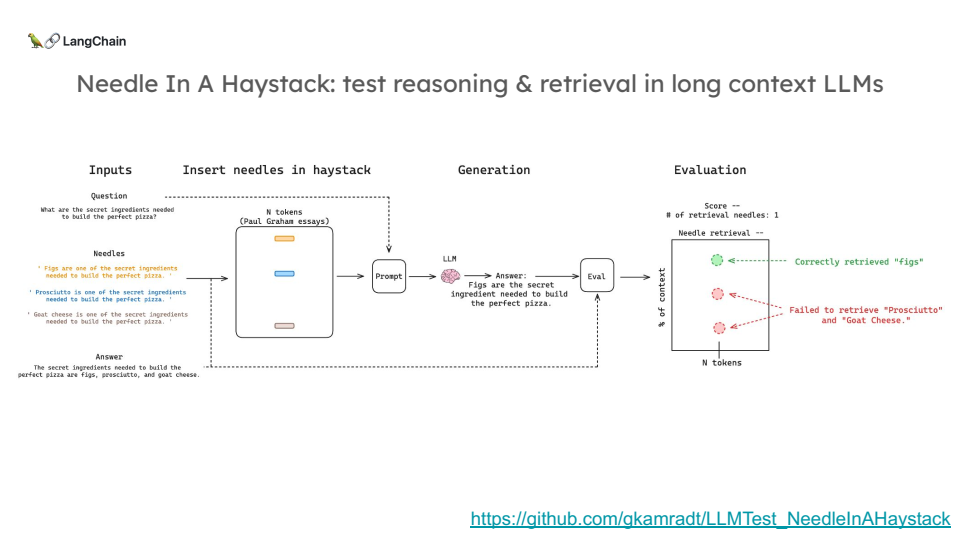
Needle in a Haystack(건초 더미에서 바늘 찾기) 테스트는 대규모 문맥에서 특정 정보를 얼마나 잘 찾아낼 수 있는지를 측정하는 실험입니다. 실험의 목표는 장문 LLM이 여러 정보 조각(Needles)을 얼마나 잘 검색하고 추론할 수 있는지를 알아보는 것이었습니다.
Lance는 이 테스트를 위해 "피자 재료"를 이용했습니다. 예를 들어, "무화과(figs), 프로슈토(prosciutto), 염소 치즈(goat cheese)" 같은 피자 재료를 문맥의 여러 위치에 숨겨 두고, 모델에게 "완벽한 피자의 비밀 재료는 무엇인가요?"라고 질문한 후, 모델이 그 재료를 모두 찾을 수 있는지 확인했습니다.
결과: 장문 LLM의 한계
-
정보가 많을수록 성능 저하: 문맥에 삽입된 정보의 수가 많아질수록, 모델이 모든 정보를 정확히 검색해 내는 비율이 떨어졌습니다.
-
추론의 어려움: 단순히 정보를 검색하는 것보다, 그 정보를 기반으로 추론을 해야 할 때 성능이 더 떨어졌습니다. 예를 들어, 재료의 첫 글자를 추론하는 작업에서 성능이 더 나빠졌습니다.
-
Recency Bias(최근성 편향): 문서의 앞부분에 위치한 정보는 나중에 위치한 정보보다 검색되기 어려웠습니다. 이는 모델이 최근의 정보를 더 중요하게 여기는 Recency Bias 때문일 가능성이 큽니다.
- 참고 논문 : https://arxiv.org/pdf/2310.01427
Recency Bias (최신성 편향 문제): 긴 문맥에서 언어 모델이 가장 최근의 정보에 더 많은 주의를 기울이고, 앞서 등장한 중요한 정보는 상대적으로 덜 주목하는 현상이 발생합니다. 이는 모델이 문맥 내의 정보를 충분히 활용하지 못하는 원인이 됩니다.Attention Sorting 기법: 이를 해결하기 위해 "attention sorting"이라는 방법을 도입합니다. 먼저 한 단계의 디코딩을 수행한 후, 문서들이 받은 주의(attention) 정도에 따라 문서를 재정렬합니다. 주의를 많이 받은 문서일수록 뒤쪽에 배치되고, 이를 반복하여 새로운 순서대로 답을 생성합니다.

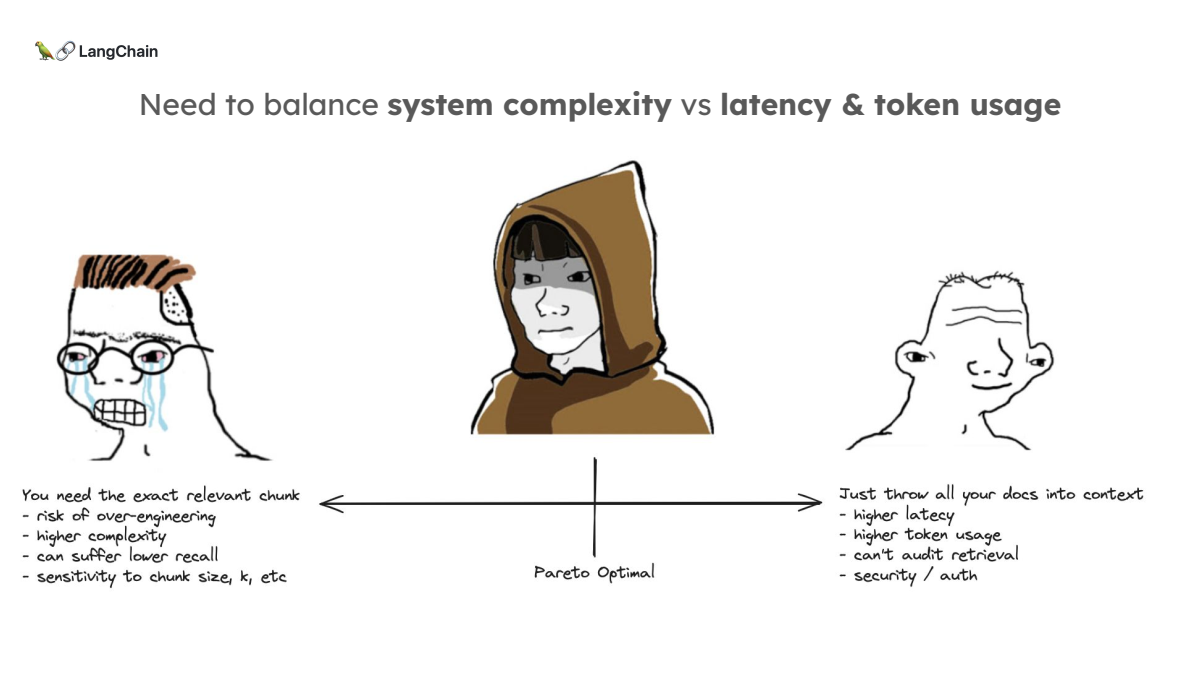
한계점: 단순한 Context Stuffing의 문제
실험 결과, 아무리 긴 문맥을 처리할 수 있는 LLM이라도 모든 정보를 완벽하게 검색해 내지는 못한다는 것이 드러났습니다.
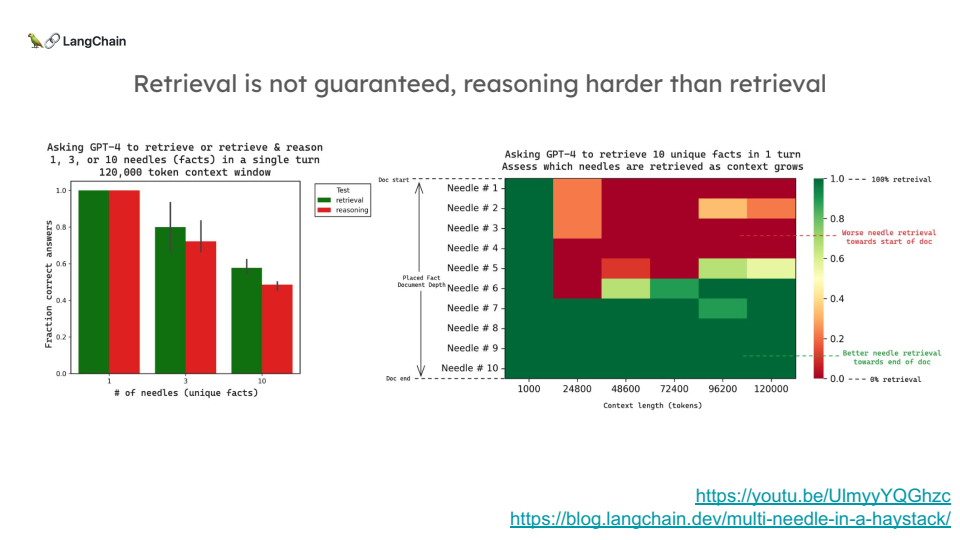
특히 문서의 앞부분에 있는 정보는 잊혀지는 경향이 있었습니다. 따라서 단순히 더 많은 정보를 LLM의 context window에 넣는 것이 능사가 아님이 명백해졌습니다. 또한, 이러한 방법은 토큰 비용이 매우 높아질 수 있으며, 보안과 인증 문제가 발생할 수 있습니다.
RAG의 미래: 변화하는 패러다임
앞으로 더욱 더 긴 컨텍스트를 넣어줄 수 있는 모델들이 나오게 될수도 있는데, 그렇다면 RAG는 이제 끝난 것일까요? 발표자 Lance는 그렇지 않다고 주장합니다. RAG는 단순히 변할 뿐, 사라지지 않을 것이라고 이야기합니다.
다음은 long context LLMs 시대에서 RAG가 어떻게 변화할 수 있을지에 대한 몇 가지 연구들을 소개합니다. (이전 챕터들과 조금 겹치는 내용들이 조금 있습니다.)
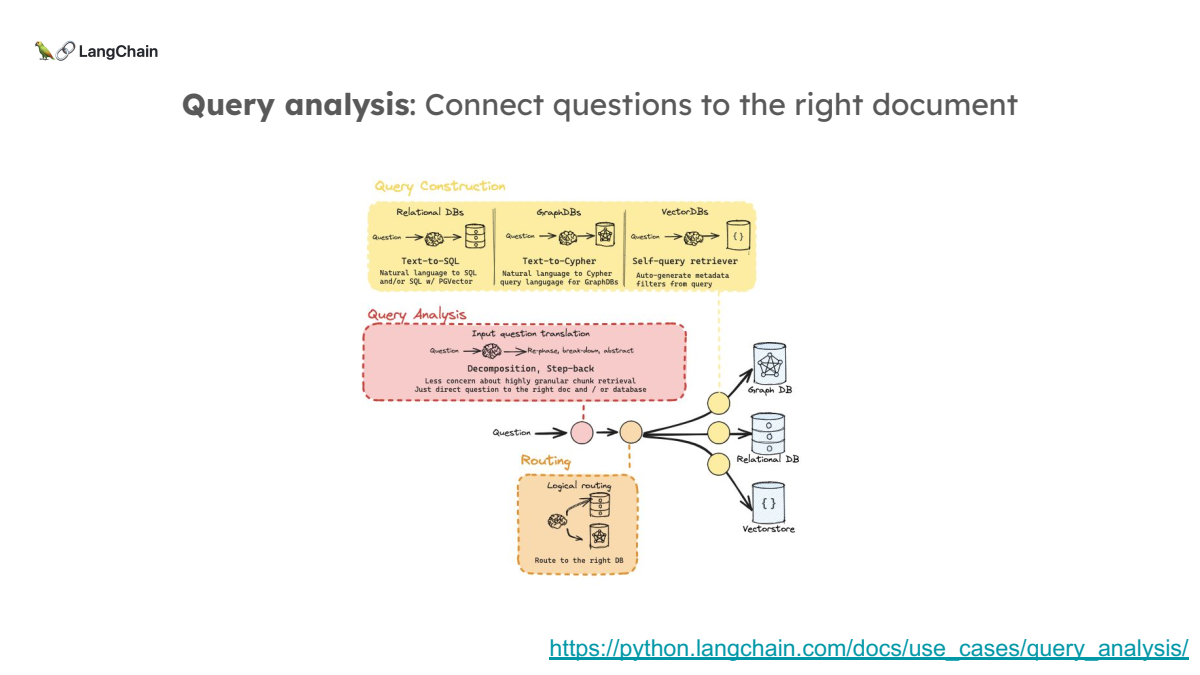
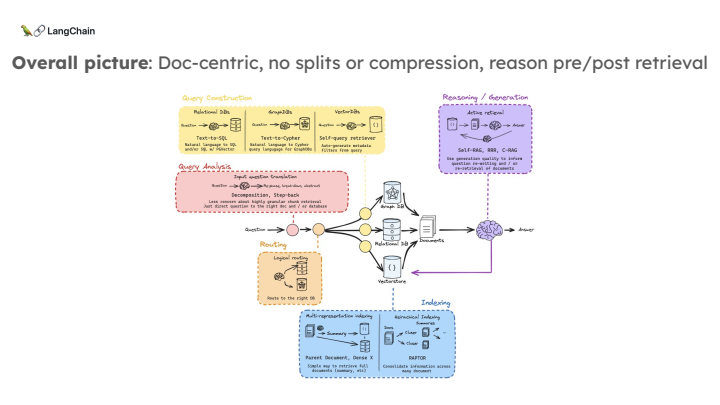
1. Document-Centric RAG
현재의 RAG 시스템은 문서를 작은 덩어리로 쪼개서 인덱싱하고, 그 덩어리 중 적합한 것을 검색하는 방식입니다. 하지만 장문 LLM 시대에서는 문서 자체를 전체로 검색하는 방법이 더 적합할 수 있습니다. 이는 쪼개는 방식에 대한 불필요한 복잡성을 줄이고, 더 자연스러운 문서 검색을 가능하게 합니다.
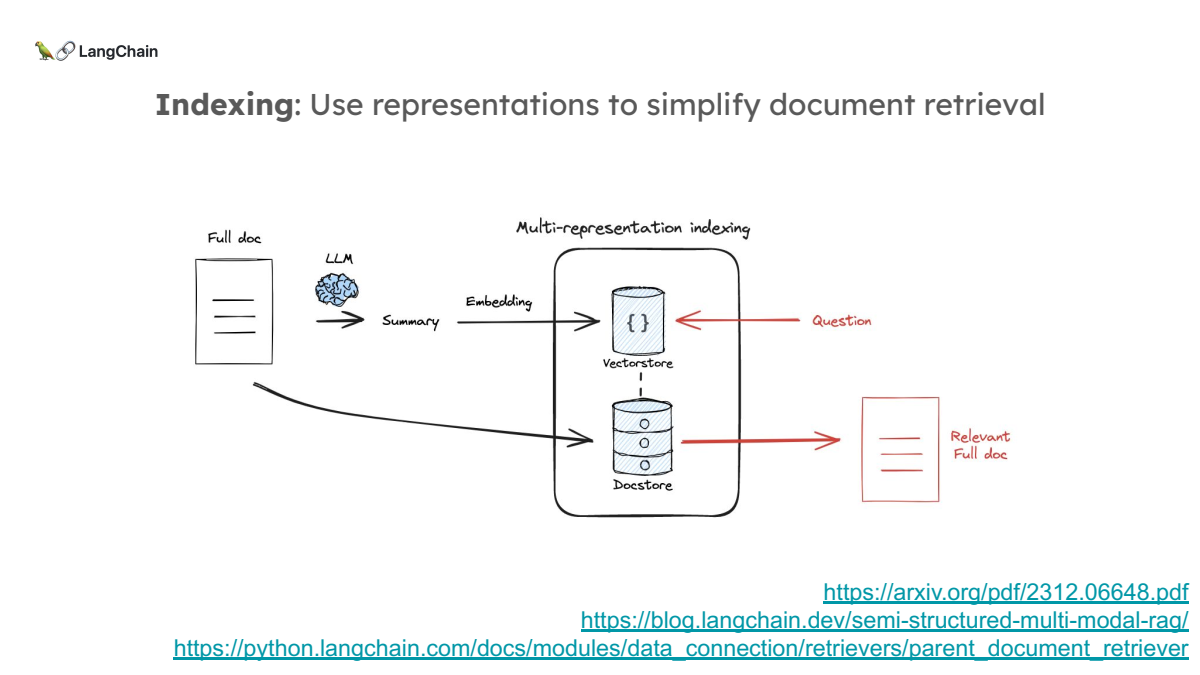
2. Multi-Representation Indexing
문서를 쪼개지 않고 요약을 통해 문서의 대표적인 표현을 인덱싱하는 방법입니다. 검색 시에는 이 요약을 활용해 적합한 문서를 찾고, 최종적으로는 전체 문서를 LLM에게 넘겨주는 방식입니다.

-
제목 : Dense X Retrieval: What Retrieval Granularity Should We Use?
-
연구 배경: Dense retrieval은 오픈 도메인 NLP 작업에서 관련 컨텍스트나 세계 지식을 얻기 위한 중요한 방법론으로 부상하고 있습니다. 이러한 dense retrieval 기법을 사용할 때 자주 간과되는 설계 결정 중 하나는 '어떤 단위를 기준으로 검색할 것인가'입니다.
- 기존의 접근 방식인 문서나 문단, 문장 단위 대신, 이 연구에서는 'proposition(제안)'이라는 새로운 검색 단위를 제안합니다. 이 proposition은 텍스트 내에서 자립할 수 있는 하나의 정보 단위로, 단순하고 자족적인 자연어 형식으로 표현됩니다.
-
Contributions:
-
Proposition 기반 검색 단위 제안: 기존의 문단 또는 문장 기반 검색과 비교하여, 텍스트를 더 세밀하게 나누어 각 proposition 단위로 나누어 검색하는 방식을 제안합니다. 이를 통해 검색된 텍스트가 질문과 더 밀접하게 관련된 정보를 제공하며, 불필요한 정보의 혼입을 줄여줍니다.
-
FACTOIDWIKI 소개: 이 연구에서는 FACTOIDWIKI라는 영어 위키피디아 덤프를 새로 가공하여, 각 페이지를 100단어 길이의 문단, 문장, proposition 단위로 나누는 작업을 진행했습니다.
-
검색 및 다운스트림 작업 성능 향상: proposition 기반 검색은 문장 및 문단 기반 검색보다 전반적인 성능이 우수했으며, 특히 질문에 관련된 정보를 더 밀집된 형태로 제공하여 QA(질문 답변) 작업에서 더욱 뛰어난 성능을 발휘했습니다.
-
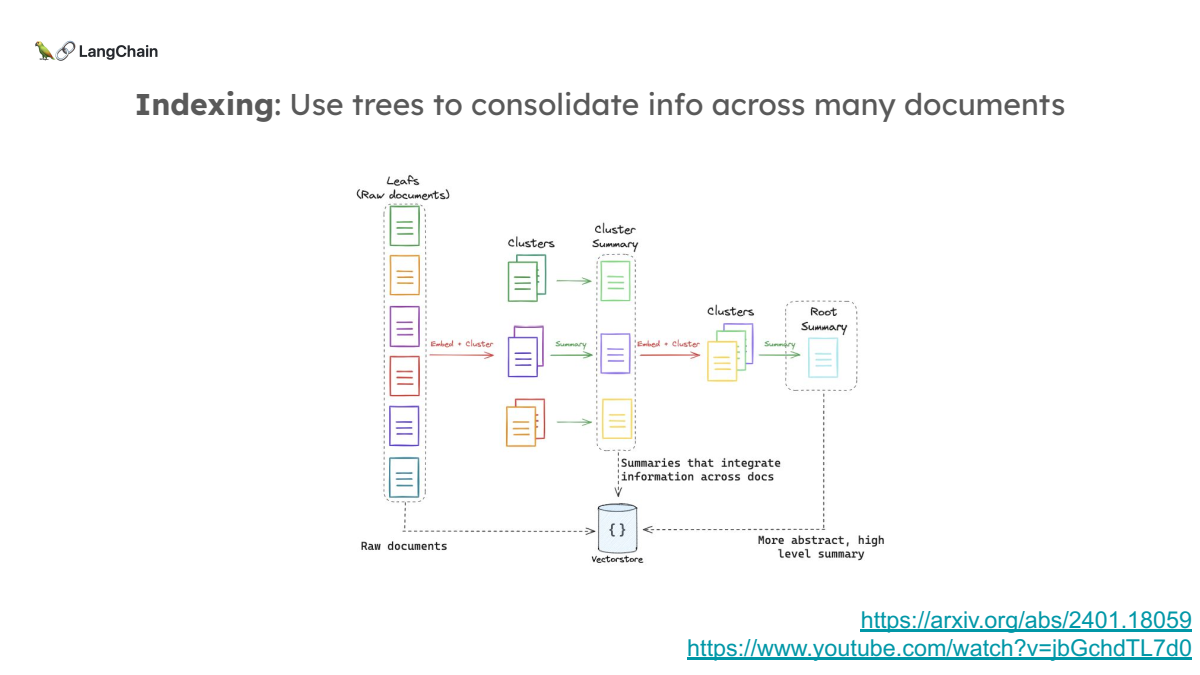
3. RAPTOR: 문서 요약 클러스터링
RAPTOR는 문서를 요약한 후, 이를 클러스터로 묶고, 클러스터 간의 요약을 반복하여 최종적으로 전체 문서 코퍼스에 대한 고차원 요약을 만드는 방식입니다. 이렇게 생성된 요약을 바탕으로 여러 문서에 걸친 정보를 통합하여 검색할 수 있습니다.

-
제목 : RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
-
연구 배경: 대형 언어 모델(LLM)은 많은 작업에서 뛰어난 성능을 보여주고 있지만, 이 모델들 역시 세계 상태의 변화나 긴 문서에서의 복잡한 정보 통합에 약점을 가지고 있습니다.
- 특히 대부분의 기존 모델들은 텍스트의 작은 연속적인 부분만을 가져와 이해하는 방식으로, 전체 문서의 맥락을 온전히 반영하지 못하는 한계가 있습니다.
- 이를 해결하기 위해, RAPTOR는 텍스트의 다양한 요약 수준을 바탕으로 한 정보를 효과적으로 검색하고 통합할 수 있는 모델입니다.
- Contributions:
- 재귀적 요약: 텍스트를 클러스터링하고 요약하여 트리 구조로 구성함으로써, 서로 다른 추상화 수준의 정보를 통합할 수 있도록 했습니다.
- 효율적인 검색 및 정보 통합: 이 트리 구조는 다양한 요약 수준에서 정보를 검색하여, 복잡한 질문에 대해 효과적으로 답할 수 있게 합니다. 이를 통해, 긴 문서를 처리하는 질문-응답 작업에서 기존 방식보다 성능이 크게 향상되었습니다.
- 최신 성과: RAPTOR와 GPT-4를 결합하여 QuALITY 데이터셋에서 20% 이상의 성능 개선을 달성했으며, 여러 QA 작업에서 최고 성능을 기록했습니다.
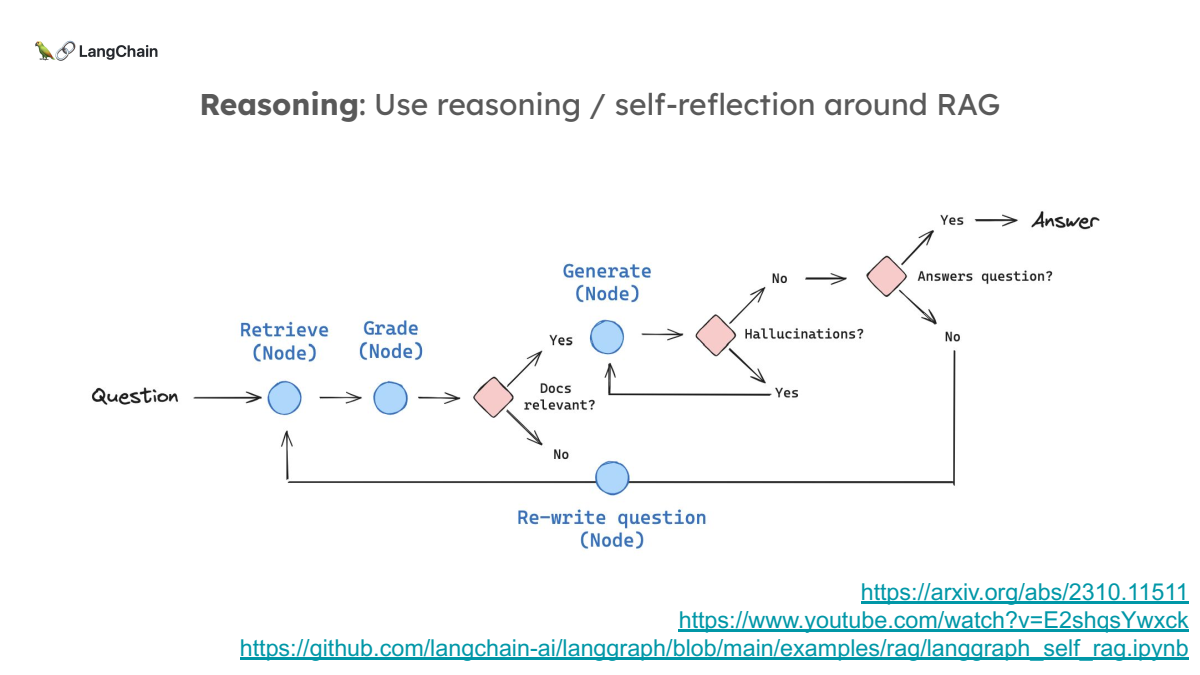
4. Self-RAG: 순환적 RAG
RAG 시스템이 한 번의 검색과 응답 생성으로 끝나는 것이 아니라, 반복적으로 질문을 수정하거나 검색 결과를 평가하는 방법입니다. 이를 통해 검색의 정확도를 높이고, hallucination을 방지할 수 있습니다.
-
제목 : SELF-RAG: LEARNING TO RETRIEVE, GENERATE, AND CRITIQUE THROUGH SELF-REFLECTION
-
연구 배경: 대형 언어 모델(LLM)은 뛰어난 능력을 가지고 있지만, 여전히 사실적인 오류를 자주 포함한 응답(hallucination)을 생성하는 문제가 있습니다.
- 기존의 정보 검색 기반 생성(RAG) 방식은 LLM이 외부에서 관련 정보를 검색하여 이 문제를 해결하려고 했으나, 무조건적으로 고정된 개수의 문서를 검색하고 이를 사용하면서, 모델의 유연성이 떨어지거나 부적절한 정보를 포함한 응답이 생성될 수 있다는 단점이 있었습니다.
-
Contributions:
- SELF-RAG 프레임워크 제안: 이 프레임워크는 언어 모델이 필요할 때만 정보를 검색하고, 검색된 정보를 반성(reflection)하여 스스로 평가함으로써, 응답의 사실성을 높이고 품질을 향상시키는 방법을 도입합니다.
- 자기 반성 토큰(reflection tokens): 특별한 토큰을 사용하여 모델이 스스로 생성한 출력에 대해 반성하고 평가합니다. 이는 검색이 필요한지 여부를 판단하거나, 생성된 응답이 얼마나 사실적인지 평가하는 데 사용됩니다.
- SELF-RAG 모델은 자기 반성 토큰을 통해 스스로 생성한 응답을 평가하고 비판하는 능력을 갖추고 있습니다. 이 평가 기준은
관련성,사실성,유용성으로 구분되며, 각각의 토큰을 사용해 평가를 수행한 뒤, 이를 바탕으로 가장 적합한 응답을 최종적으로 선택합니다.
- 적응형 검색: SELF-RAG는 기존의 RAG 방식과 달리, 문서 검색이 필요할 때만 검색을 수행하여 모델의 효율성을 높이고, 불필요한 정보의 사용을 줄입니다.
- 모델의 성능 향상: SELF-RAG는 사실 확인, 장문 생성, 오픈 도메인 질문 응답 등 다양한 과제에서 기존의 최첨단 모델들(예: ChatGPT, Llama2)을 능가하는 성능을 보였습니다.
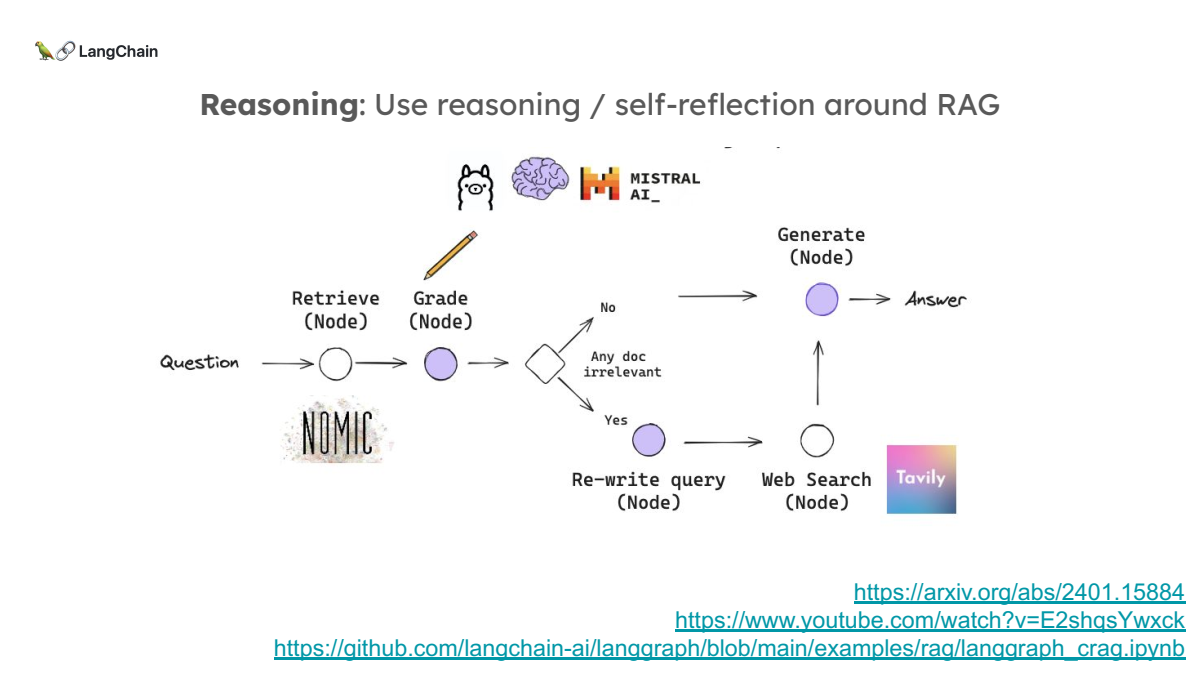
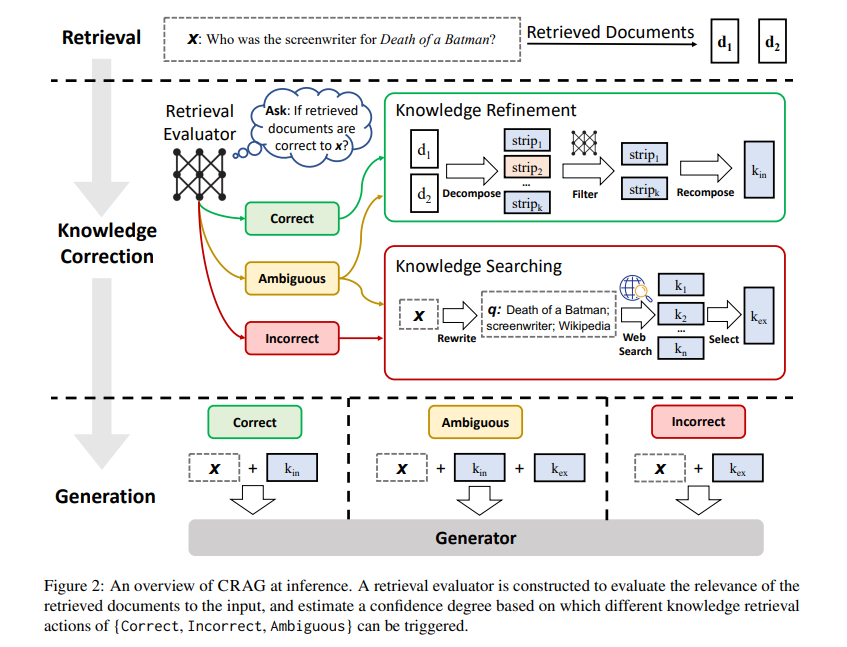
5. Corrective RAG: 외부 검색 연동
내부 인덱스에 없는 질문이 들어왔을 때, 외부 웹 검색을 통해 새로운 정보를 찾아내는 방법입니다. 이를 통해 out-of-domain 질문에도 대응할 수 있습니다.
-
제목 : Corrective Retrieval Augmented Generation
-
연구 배경: 대형 언어 모델(LLM)은 매우 자연스럽고 유창한 텍스트 생성 능력을 보이지만, 종종 정확하지 않은 정보를 생성하는 "환각" 현상을 보입니다. 이를 해결하기 위해 Retrieval-Augmented Generation (RAG) 기법이 사용되며, 외부 지식 문서에서 관련 정보를 검색해와 모델이 답을 생성할 때 이를 참고하게 됩니다. 그러나, 검색된 문서가 부정확하거나 관련이 없을 경우, 생성된 결과가 더 악화될 수 있습니다.
- 본 논문은 이러한 문제를 해결하기 위해 검색된 문서의 정확성을 평가하고 수정하는 CRAG (Corrective Retrieval Augmented Generation) 방법을 제안합니다.
-
Contributions:
- 오류 수정 기법 제안: 기존의 RAG 방식이 부정확한 검색 결과로 인해 환각 현상을 일으키는 문제를 해결하기 위해, 본 논문은 검색된 문서의 정확도를 평가하고 수정하는 전략을 설계했습니다. 이는 RAG 기반 모델의 견고성을 강화하는 첫 번째 시도입니다.
- 경량 평가자 설계: 검색된 문서의 품질을 평가하는 경량 평가자를 도입해 문서의 신뢰성을 판단하고, 필요한 경우 대규모 웹 검색을 통해 추가적인 지식을 보완할 수 있습니다.
- 경량 검색 평가자는 T5 기반 모델로, 문서의 관련성을 경량화된 방식으로 평가하며, 상/하한 임계값을 통해 정확성, 부정확성, 모호성을 구분합니다.
- 웹 검색은 쿼리 재작성을 통해 검색을 수행하며, 웹에서 검색된 정보를 정교하게 필터링하고 재구성하여 유용한 지식으로 변환합니다.
- 지식 통합을 통해 내부 문서와 웹에서 얻은 데이터를 결합하여, 오류를 최소화하고 LLM의 환각 현상을 줄이는 것을 목표로 합니다.
- 다양한 실험을 통한 성능 개선 증명: 본 논문의 실험 결과, CRAG는 다양한 데이터셋에서 기존 RAG 방식보다 우수한 성능을 보였으며, 특히 짧은 형식과 긴 형식의 텍스트 생성 작업 모두에서 일반화 가능함을 입증했습니다.
Conclusion: RAG의 새로운 방향
결론적으로, RAG는 끝나지 않았습니다. 다만, 장문 LLM 시대에 맞춰 변화하고 있을 뿐입니다. 앞으로는 문서를 쪼개는 복잡한 과정 대신 문서 전체를 검색하는 방식이 더 주목받을 것입니다. 또한, 문서 검색 이후 추론을 반복하고 평가하는 방법도 더 많이 사용될 것으로 보입니다.
장문 LLM이 계속해서 발전함에 따라, RAG 시스템은 더 효율적이고 유연한 방향으로 진화할 것입니다. 하지만 단순히 모든 정보를 한 번에 LLM에 넣는 방식이 항상 최선이 아님을 명심해야 합니다. RAG는 새로운 시대에 맞게 변화하고 있으며, 그 중요성은 여전히 유지될 것입니다.

좋은글 잘 읽고 갑니다.