- 해당 블로그 포스트는 RAG From Scratch : Coursework
강의 파트 1 - 4 내용을 다루고 있습니다.
| 비디오 | 요약 | 강의 링크 | 슬라이드 |
|---|---|---|---|
| Part 1 (개요) | RAG를 소개하며, 시리즈가 기본 개념부터 고급 기술까지 다룰 것임을 설명합니다. | 📌 강의 | 📖 슬라이드 |
| Part 2 (인덱싱) | 검색의 정확성과 속도에 중요한 인덱싱 과정에 초점을 맞춥니다. | 📌 강의 | 📖 슬라이드 |
| Part 3 (검색) | 검색의 정밀성을 위해 인덱스를 사용한 문서 검색을 다룹니다. | 📌 강의 | 📖 슬라이드 |
| Part 4 (생성) | LLM을 통한 답변 생성을 위한 RAG 프롬프트 구성을 탐구합니다. | 📌 강의 | 📖 슬라이드 |
Part 1 (개요)
- RAG의 기본 개념 소개:
- 이 비디오 시리즈는 RAG(Retrieval-Augmented Generation)의 기본 원칙을 다루고, 고급 주제까지 확장해 나가는 과정을 설명합니다.
- RAG의 주요 동기는 대형 언어 모델(LLM)이 모든 데이터를 포함하지 않는다는 점에서 시작됩니다. 예를 들어, 개인 데이터나 최근 데이터는 LLM의 사전 학습에 포함되지 않을 수 있습니다.
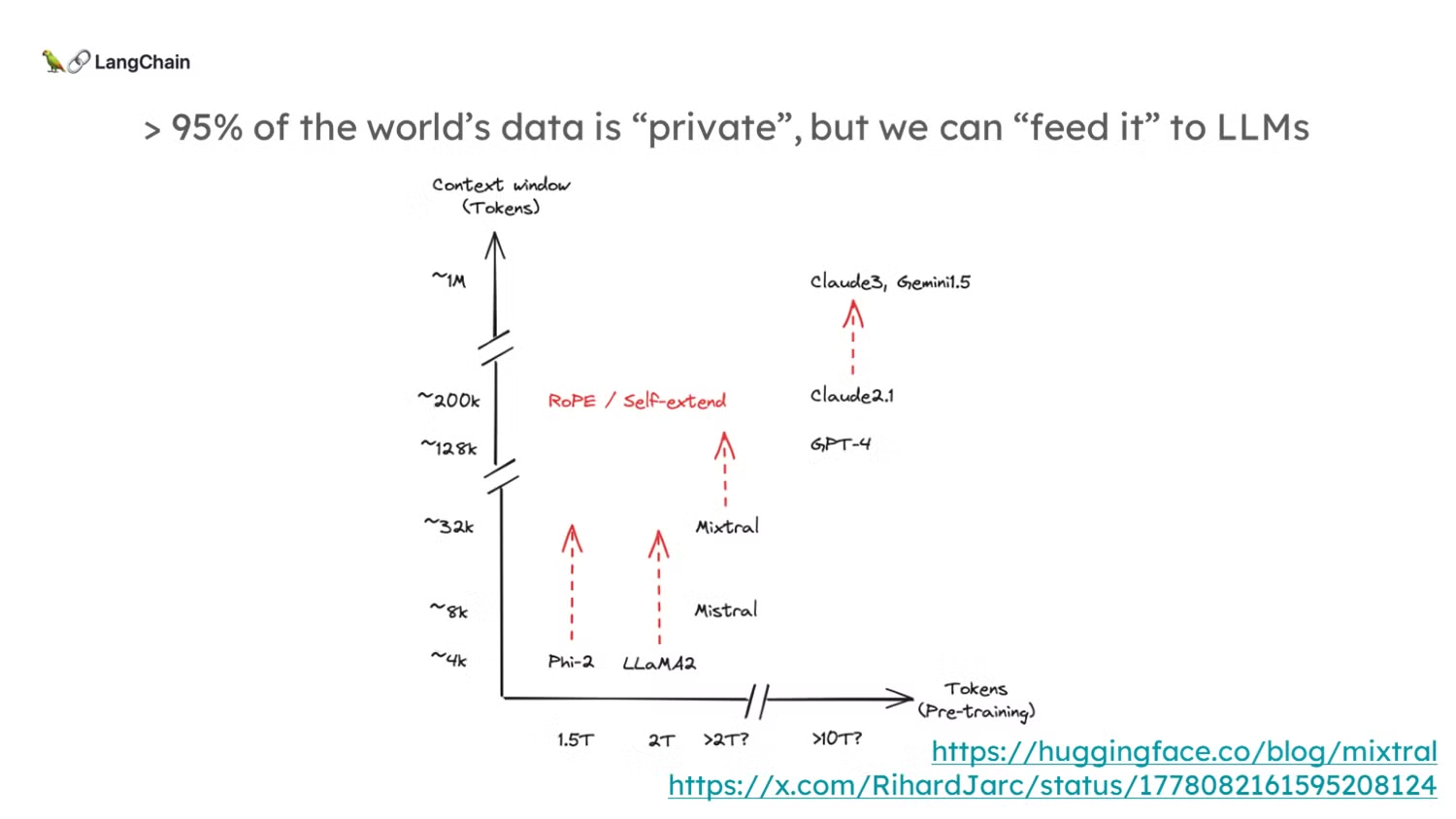
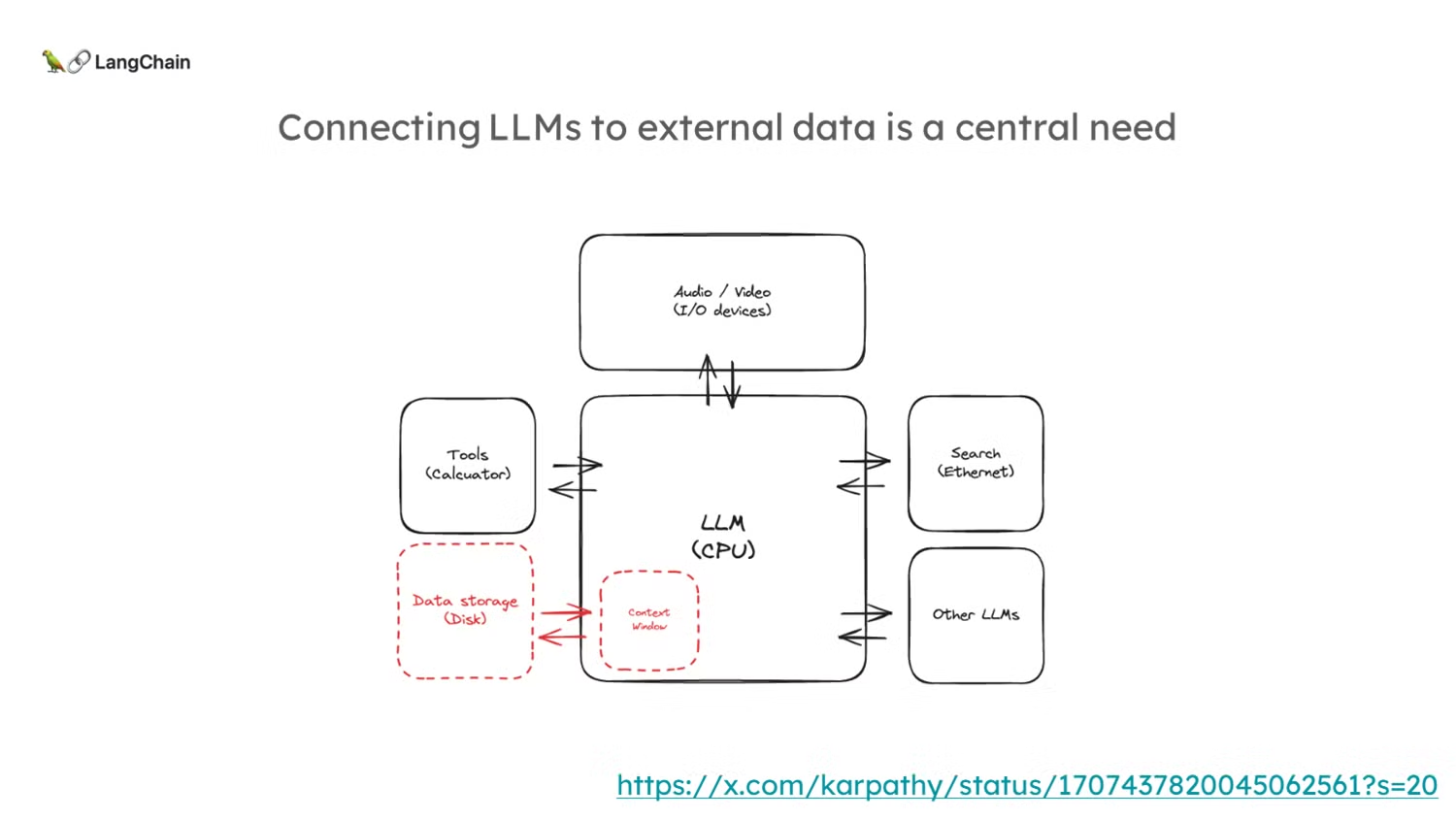
- 또한, LLM은 컨텍스트 윈도우(context windows)라는 제한이 있습니다. 최근에는 이 컨텍스트 윈도우가 점점 더 커지고 있지만, 여전히 외부 소스를 통해 데이터를 연결하는 것이 중요합니다.
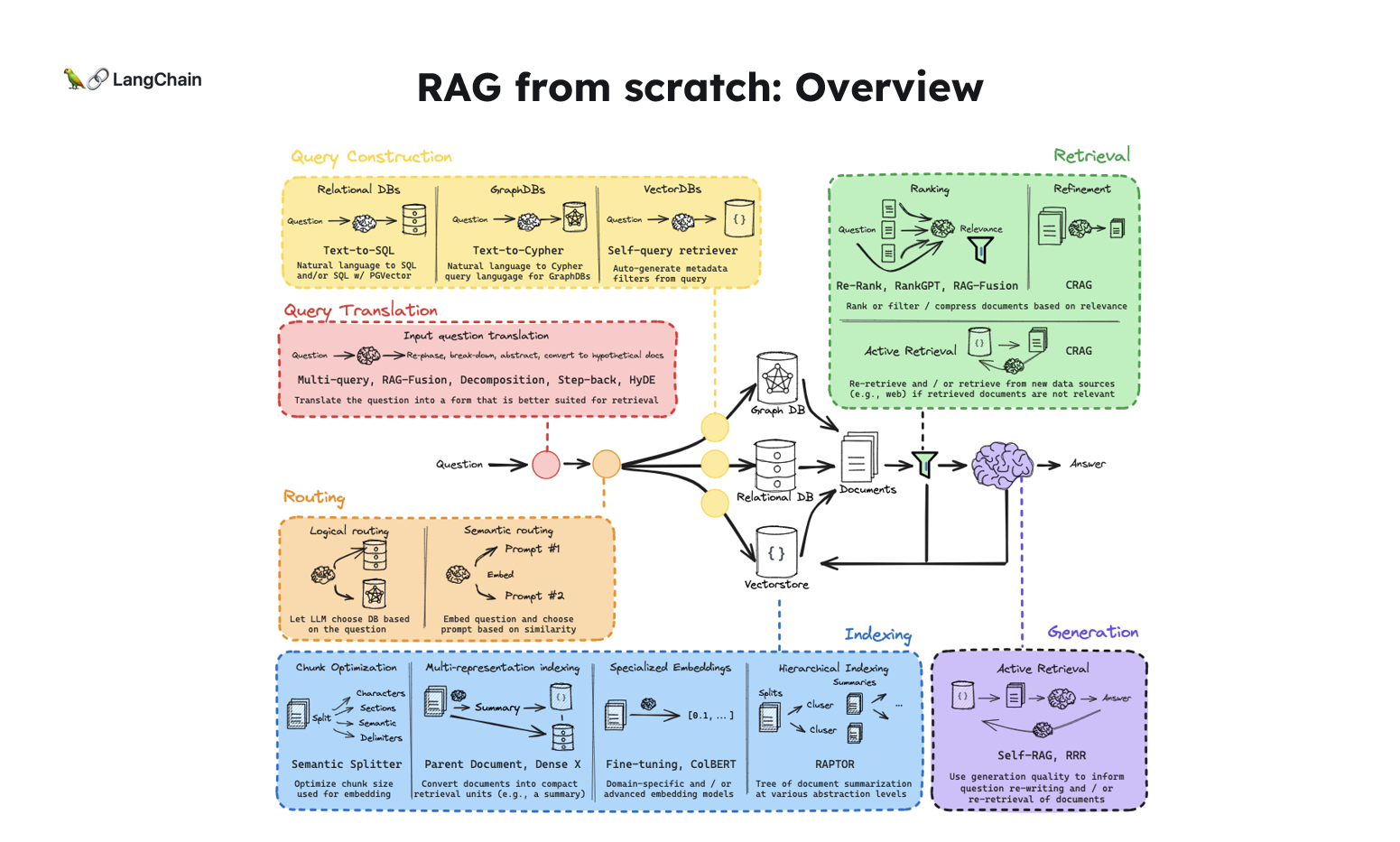
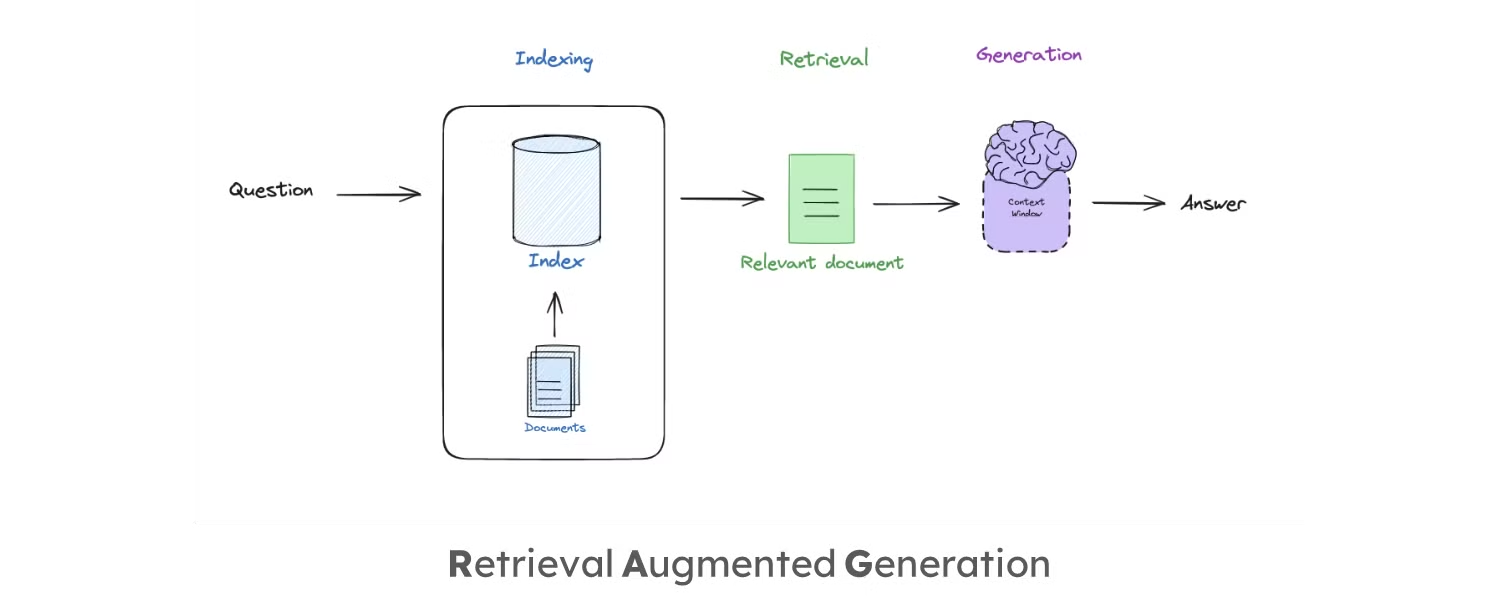
- RAG의 세 가지 주요 단계:
- 인덱싱(Indexing): 외부 문서를 인덱싱하여 입력 쿼리에 따라 쉽게 검색할 수 있도록 합니다.
- 검색(Retrieval): 질문에 대한 문서를 검색하고, 이 문서를 LLM에 입력합니다.
- 생성(Generation): 검색된 문서를 바탕으로 LLM이 답변을 생성합니다.
코드 시연
1. Install Packages
- 필수 패키지를 설치합니다.
pip install langchain_community tiktoken langchain-openai langchainhub chromadb langchain bs4- 주요 라이브러리를 임포트합니다:
import bs4
from langchain import hub
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings- API KEY 및 주요 환경 변수를 셋팅해줍니다:
# OPEN_AI CHATGPT KEY 설정
os.environ['OPENAI_API_KEY'] = <your-api-key># langsmith용 키 설정
# <https://docs.smith.langchain.com/>
import os
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_ENDPOINT'] = '<https://api.smith.langchain.com>'
os.environ['LANGCHAIN_API_KEY'] = <your-api-key>(참고) LangSmith API Key 발급 방법
- 링크 : https://smith.langchain.com/
- 위 링크에서 Personal > Setting > Creating API Key에서 발급 가능
💡 LangChain & LangSmith?
LangChain과LangSmith는 대규모 언어 모델(LLM) 애플리케이션의 개발을 지원하는 두 가지 강력한 도구로, 각각의 목적과 사용 사례가 다릅니다. - 이 두 도구를 잘 이해하는 것은 LLM 기반 애플리케이션을 효율적으로 개발하고 운영하는 데 중요한 역할을 합니다.
LangChain ⛓️
- LangChain은 주로 LLM을 활용하여 애플리케이션을 신속하게 개발하고 프로토타입을 구축하기 위한 프레임워크입니다. Python으로 제공되는 오픈 소스 패키지로, 다양한 LLM을 사용하여 복잡한 언어 처리 작업을 수행할 수 있습니다. LangChain은 다음과 같은 특징을 가지고 있습니다:
- 체인과 에이전트: LangChain은 여러 작업을 체인(Chain) 형태로 연결하거나, 복잡한 의사 결정 과정을 에이전트(Agent)로 구현하여 자동화할 수 있습니다.
- 프롬프트 템플릿: 특정 작업에 맞는 프롬프트 템플릿을 쉽게 정의하고 활용할 수 있습니다.
- 메모리 시스템: 작업의 상태를 유지하기 위해 다양한 메모리 시스템을 사용할 수 있습니다.
LangSmith ⚒️
- LangSmith는 LangChain 애플리케이션의 개발, 테스트, 모니터링, 그리고 배포를 위한 종합적인 DevOps 플랫폼입니다. 이는 대규모 LLM 애플리케이션을 관리하고 최적화하는 데 필요한 다양한 기능을 제공하며, 특히 다음과 같은 기능이 돋보입니다:
- 디버깅: 모델의 모든 단계에서 입력과 출력을 추적할 수 있어, 예상치 못한 결과나 오류를 쉽게 식별할 수 있습니다.
- 테스트: 새로운 체인과 프롬프트 템플릿을 실험할 수 있는 환경을 제공하여, 안정성과 성능을 확인할 수 있습니다.
- 모니터링: 애플리케이션의 지연 시간과 토큰 사용량을 추적하여 문제를 일으킬 수 있는 호출을 식별할 수 있습니다.
- 평가: 복잡한 프롬프트 체인을 평가하고, 성능을 최적화할 수 있는 도구를 제공합니다.
- 프로젝트 분석: 실행 카운트, 오류 발생률, 토큰 사용량 등을 프로젝트 단위로 분석할 수 있습니다.
(참고) Langfuse 🧬
- Langfuse는 LLM(대규모 언어 모델) 애플리케이션을 위한 오픈소스 관측성 및 분석 플랫폼으로, 다음과 같은 주요 기능을 제공합니다:
- 관측성: 복잡한 LLM 앱 실행을 시각적 UI를 통해 탐색하고 디버깅할 수 있습니다. 대기 시간, 비용, 성능 점수 등의 상세 정보를 포함한 중첩된 뷰를 제공합니다.
- 분석: 비용, 지연 시간, 응답 품질을 측정하고 개선할 수 있습니다. 모델별 토큰 사용량, 평가 점수 등을 리포트로 제공합니다.
- 프롬프트 관리: Langfuse 내에서 프롬프트를 관리, 버전 관리, 배포할 수 있어 효율적인 프롬프트 엔지니어링이 가능합니다.
- 평가: LLM 완성에 대한 점수를 수집하고 계산합니다. 모델 기반 평가, 사용자 피드백 수집, 수동 점수 매기기 등 다양한 평가 방법을 지원합니다.
- 실험 및 테스트: 새 버전을 배포하기 전에 앱 동작을 추적하고 테스트할 수 있습니다. 데이터셋을 사용하여 예상 입출력 쌍을 테스트하고 성능을 벤치마크할 수 있습니다.
- 통합: LlamaIndex, Langchain 등 주요 LLM 프레임워크와의 통합을 제공하여 다양한 LLM 애플리케이션에서 사용할 수 있습니다.
2. Indexing
- 이제 필요한 환경 설정은 다했으니, Indexing 코드를 살펴보겠습니다.
#### INDEXING ####
# Load Documents
loader = WebBaseLoader(
web_paths=("<https://velog.io/@euisuk-chung/꿀팁-Velog-글씨를-내-마음대로-색상-형광펜>",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# Embed
vectorstore = Chroma.from_documents(documents=splits,
embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
-
위 코드에서
Chroma는 vectorstore의 한 종류로, LangChain 라이브러리에서 자주 사용되는 구현체입니다. -
Vectorstore를 사용하면 대규모 데이터셋에서 효율적인 유사성 검색을 수행할 수 있어, 자연어 처리나 기계학습 애플리케이션에서 널리 활용됩니다.
- Chroma, Pinecone, Faiss 등 다양한 구현체가 있습니다.
-
주요 특징은 다음과 같습니다:
- 고차원 벡터 데이터를 저장하고 검색하는 데 특화되어 있습니다.
- 텍스트, 이미지, 오디오 등의 데이터를 벡터로 변환하여 저장합니다.
- 유사성 검색을 빠르게 수행할 수 있어 추천 시스템, 이미지 검색 등에 활용됩니다.
3. Retreive and Generate
- Indexing이 끝난 뒤, 검색기(retriever)를 정의하고, 검색된 문서와 함께 질문을 LLM에 전달하여 답변을 생성(generate)합니다.
#### RETRIEVAL and GENERATION ####
# Prompt
prompt = hub.pull("rlm/rag-prompt")
# LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# Post-processing
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Chain
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# Question
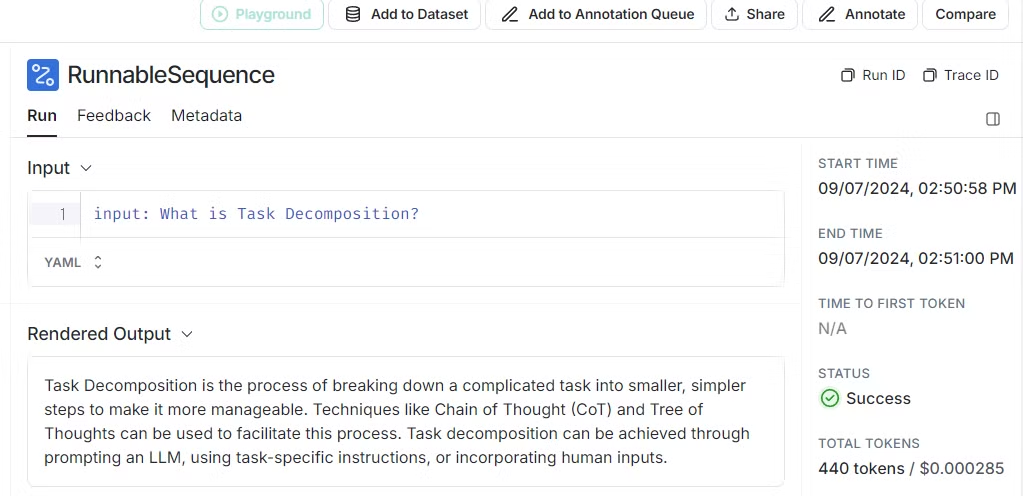
rag_chain.invoke("What is Task Decomposition?")
## Answer Returned
'Task Decomposition is a technique used to break down complex tasks into smaller, more manageable steps.
It involves methods like Chain of Thought (CoT) and Tree of Thoughts, which guide models to think step by step and explore multiple reasoning possibilities.
This approach enhances model performance by simplifying and structuring tasks systematically.'
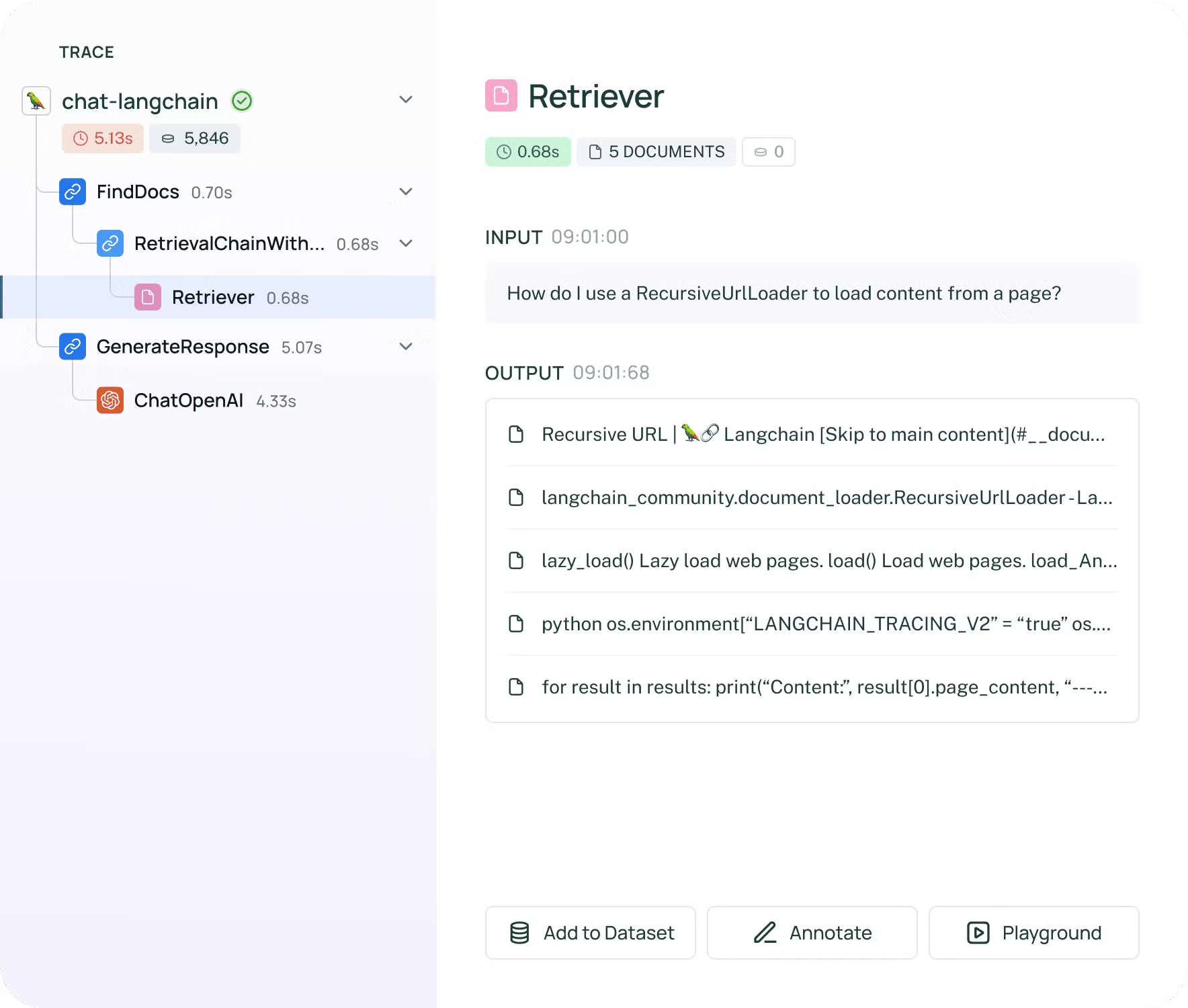
- langsmith 툴을 사용하면 사이트 > 프로젝트로 접속하여 아래와 같이 질문과 검색된 문서, 그리고 생성된 답변을 확인할 수 있습니다.
Part 2 (인덱싱)
-
이번 영상은 RAG(Retrieval-Augmented Generation) 파이프라인의 두 번째 파트로, '인덱싱(Indexing)'에 대해 다룹니다.
-
이전 영상에서는 RAG 파이프라인의 주요 구성 요소(인덱싱, 검색, 생성)에 대해 개괄적으로 설명했으며, 이번 영상에서는 그 중 인덱싱에 대해 심도 있게 설명합니다.
-
인덱싱의 역할: 인덱싱의 첫 번째 단계는 외부 문서를 로드하고 이를 '리트리버(Retriever)'에 넣는 것입니다.
-
리트리버(Retriever)의 목표는 입력된 질문에 대해 관련 문서를 찾아내는 것입니다.
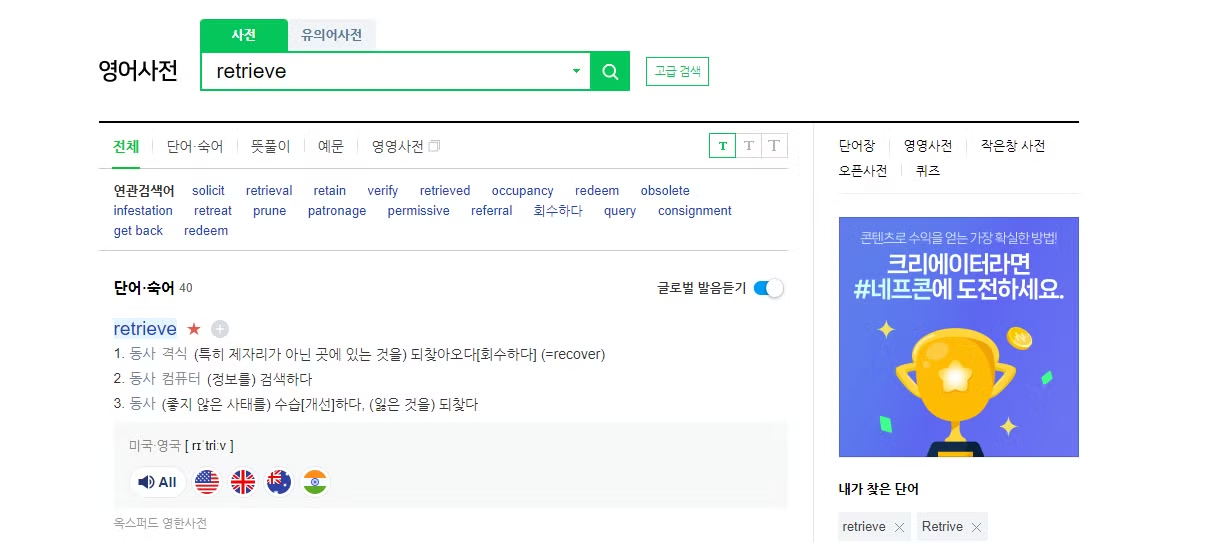
✍️ 사전적 의미로
retrieve란 "회수하다"라는 뜻으로, _"우리가 질문한 질의문과 유사한 내용의 문서를 저장해둔 VectorDB에서 회수해 온다"_라고 직역해볼 수도 있을 것 같습니다.
-
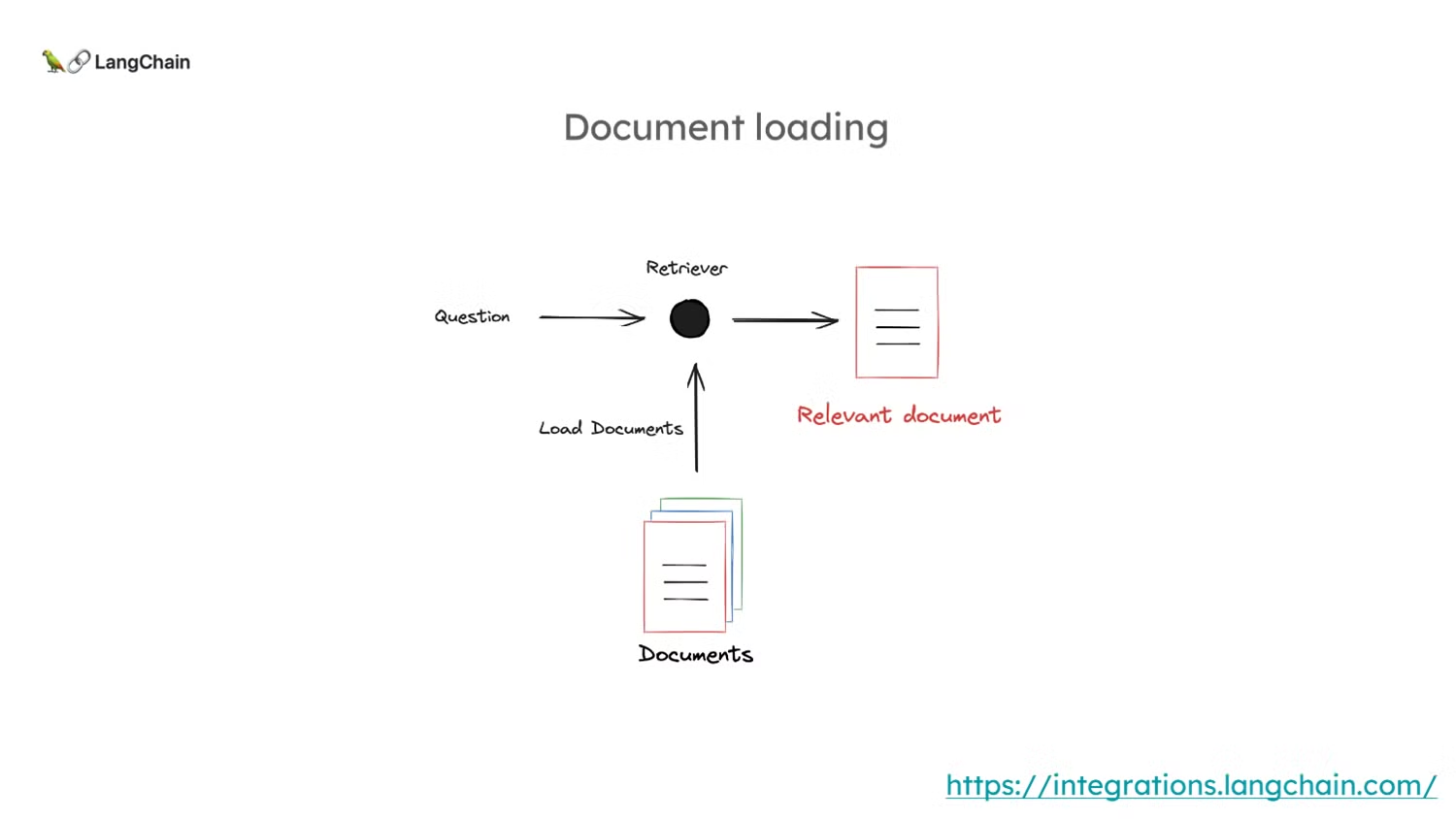
- 관계(유사성)을 확립하는 방법은 주로 문서의 수치적 표현(numerical representation)을 사용하는 것입니다. 이는 자유 형식의 텍스트보다는 벡터 비교가 훨씬 쉽기 때문입니다.
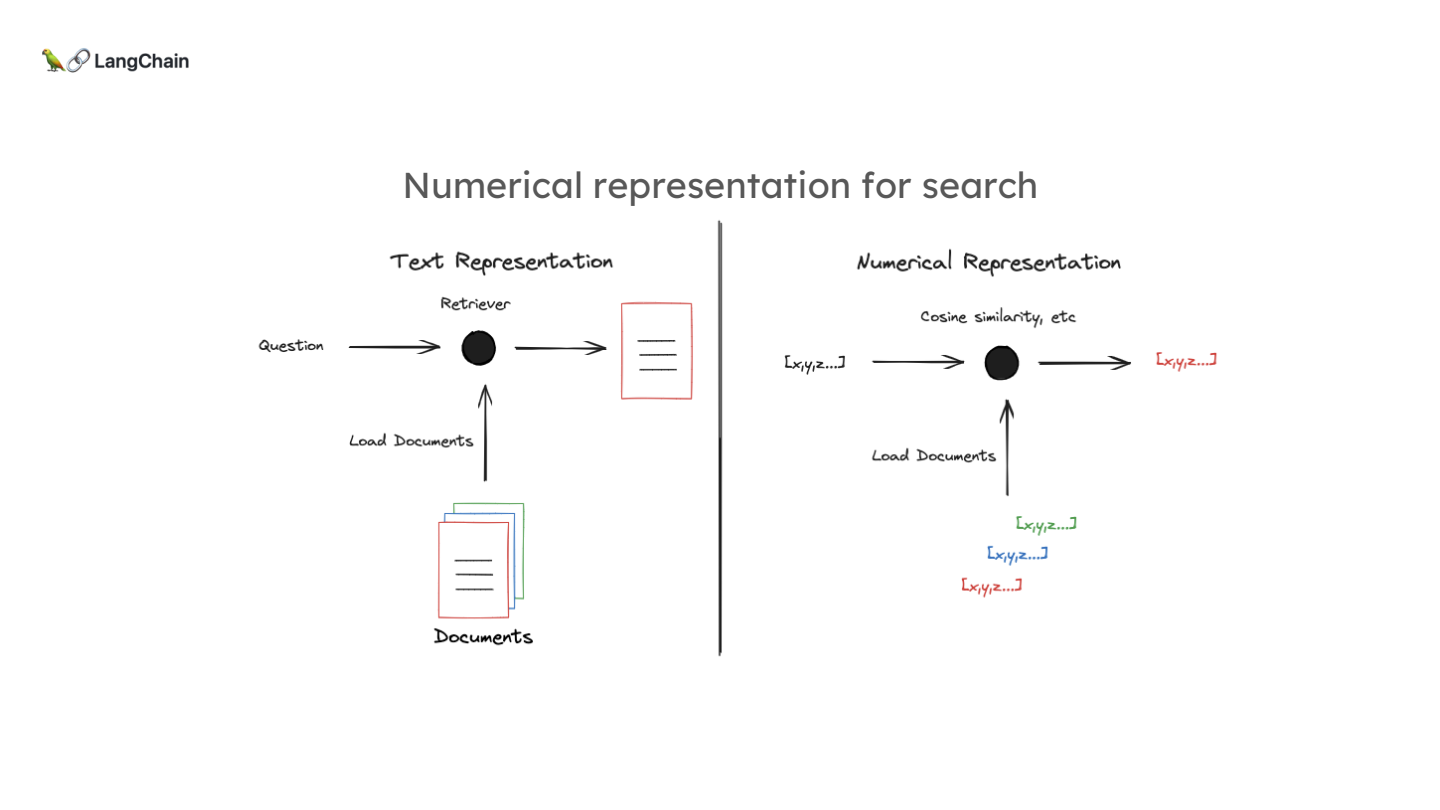
-
벡터 표현 방법:
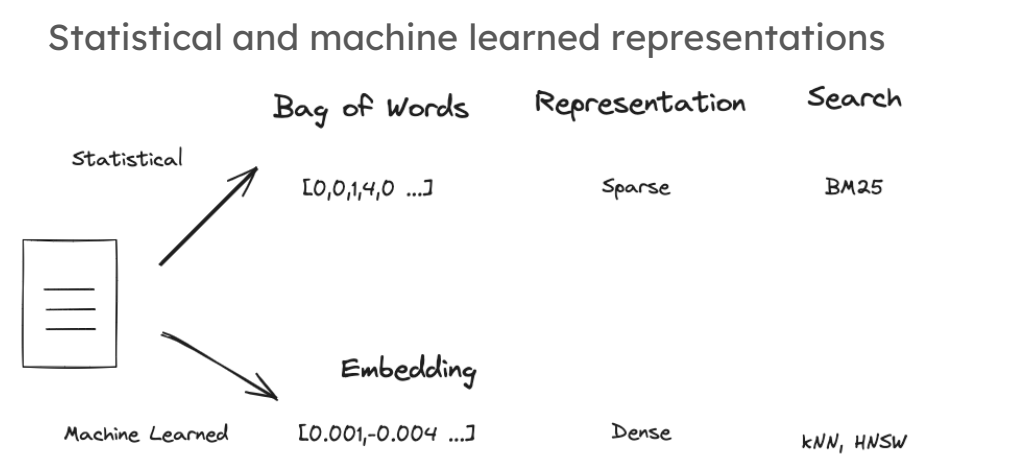
- Sparse Vectors: 과거에는 구글 등에서 문서의 단어 빈도수를 기반으로 하는 희소 벡터(sparse vectors)를 생성하는 통계적 방법이 많이 사용되었습니다. 이 벡터의 각 위치는 큰 어휘 집합 중 특정 단어의 발생 횟수를 나타내며, 문서에 포함되지 않은 단어의 경우 값이 0이 됩니다.
- Embedding Methods: 최근에는 문서를 고정된 길이의 벡터로 압축하는 머신러닝 기반 임베딩(embedding) 방법이 개발되었습니다. 이 방법은 문서의 의미적 내용을 벡터에 압축해 담아내며, 이러한 벡터는 검색에 매우 효과적입니다.
-
문서 분할 및 임베딩:
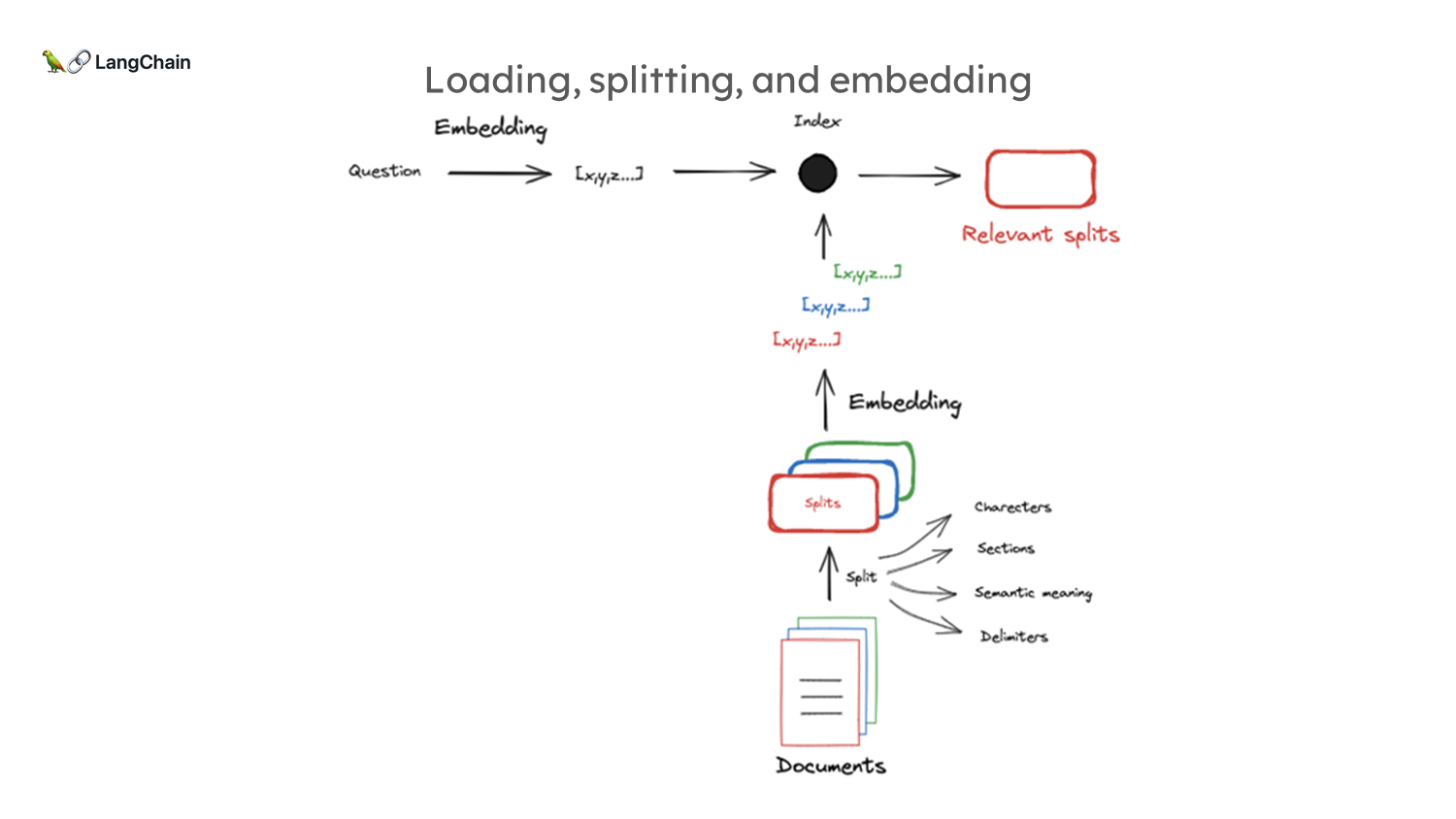
- 문서는 임베딩 모델의 제한된 컨텍스트 윈도우(512~8000 토큰) 때문에 분할됩니다. 각 문서 조각은 벡터로 압축되며, 이 벡터는 문서의 의미적 의미를 담고 있습니다.
- 질문도 동일한 방식으로 임베딩되며, 이렇게 생성된 벡터들을 비교하여 관련 문서를 검색하게 됩니다.
-
코드 시연
1. tiktoken 패키지와 토큰 개수 계산
import tiktoken
def num_tokens_from_string(string: str, encoding_name: str) -> int:
"""Returns the number of tokens in a text string."""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
num_tokens_from_string(question, "cl100k_base")
설명:
tiktoken패키지를 사용하여 문자열의 토큰 개수를 계산합니다. 여기서 "토큰"은 텍스트를 구성하는 작은 단위로, 일반적으로 단어 또는 단어의 일부를 의미합니다.num_tokens_from_string함수는 주어진 문자열과 인코딩 방식을 사용하여 해당 문자열의 토큰 개수를 반환합니다.tiktoken.get_encoding(encoding_name)은 지정된 인코딩 방식을 불러오고,encoding.encode(string)은 문자열을 토큰으로 인코딩합니다.- 마지막으로
len(encoding.encode(string))은 인코딩된 토큰 리스트의 길이(토큰 개수)를 반환합니다.
tiktoken 패키지 설명:
tiktoken은 주로 OpenAI의 모델들(예: GPT-3.5, GPT-4 등)에서 사용되는 토큰화(tokenization) 라이브러리입니다. 이 패키지는 텍스트를 토큰으로 변환하고, 이러한 토큰이 모델에 입력될 때의 토큰 수를 계산하는 데 사용됩니다. 각 토큰은 약 4자 정도로 구성된 단위이며, 이는 모델이 텍스트를 처리할 때의 기본적인 단위가 됩니다.
2. 텍스트 임베딩 모델
from langchain_openai import OpenAIEmbeddings
embd = OpenAIEmbeddings()
query_result = embd.embed_query(question)
document_result = embd.embed_query(document)
len(query_result)
설명:
- 이 코드 블록에서는
langchain_openai패키지의OpenAIEmbeddings를 사용하여 주어진 질문과 문서를 임베딩합니다. - 임베딩(embedding)이란 텍스트를 고차원 벡터로 변환하는 과정입니다. 이 벡터들은 의미적으로 유사한 텍스트들이 서로 가까이 위치하도록 하여, 텍스트의 의미를 수치적으로 표현할 수 있게 합니다.
embed_query메서드는 주어진 텍스트(질문이나 문서)를 임베딩하여 벡터 표현으로 변환합니다.- 결과적으로
query_result와document_result는 각각 질문과 문서의 임베딩 벡터가 됩니다.(print로 길이 출력 시 동일 길이의 임배딩 벡터가 생성되는 것을 확인할 수 있음)

3. 코사인 유사도 계산
import numpy as np
def cosine_similarity(vec1, vec2):
dot_product = np.dot(vec1, vec2)
norm_vec1 = np.linalg.norm(vec1)
norm_vec2 = np.linalg.norm(vec2)
return dot_product / (norm_vec1 * norm_vec2)
similarity = cosine_similarity(query_result, document_result)
print("Cosine Similarity:", similarity)
설명:
- 이 블록은 두 임베딩 벡터 간의 코사인 유사도를 계산합니다.
- 코사인 유사도는 두 벡터 사이의 각도를 기반으로 유사성을 측정하며, 1에 가까울수록 두 벡터가 유사하다는 것을 의미합니다.
np.dot(vec1, vec2)는 두 벡터의 내적을 계산하고,np.linalg.norm(vec1)와np.linalg.norm(vec2)는 각각의 벡터의 크기(노름)를 계산합니다.- 마지막으로
dot_product / (norm_vec1 * norm_vec2)는 코사인 유사도를 반환합니다.
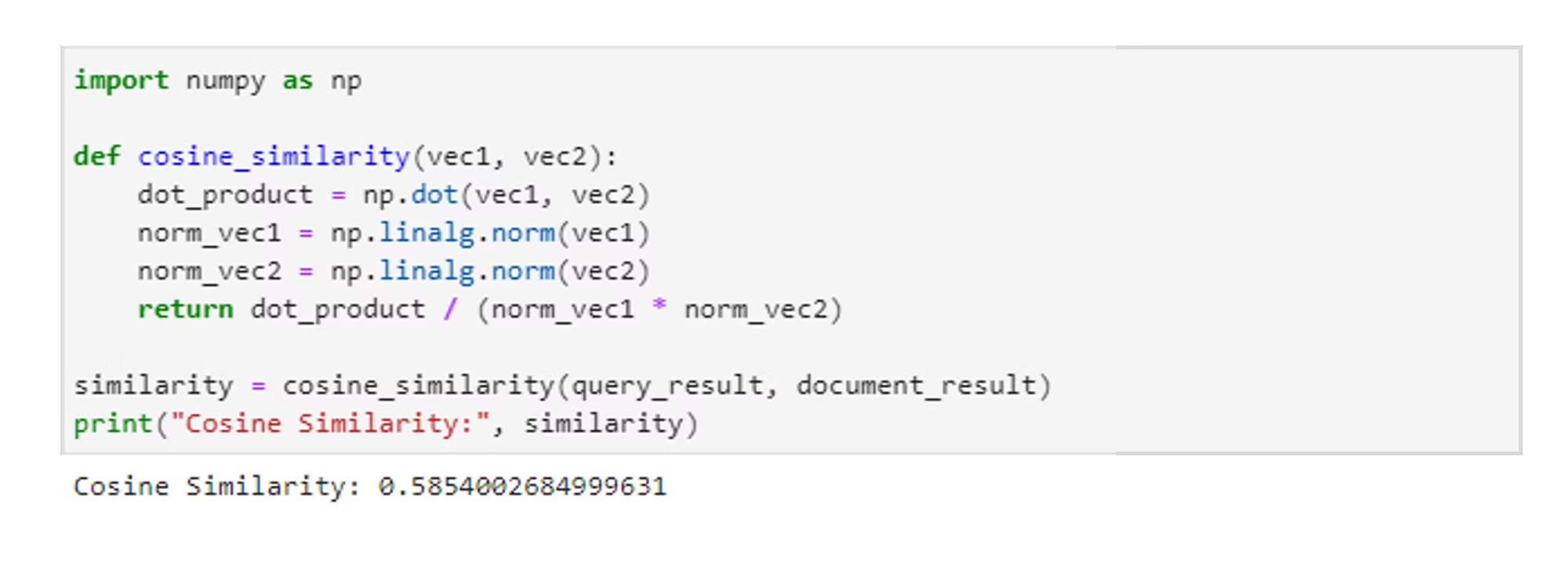
- 제가 사용한 GPT 모델의 임배딩 기반의 Query와, Document의 유사도는 그렇게 높진 않지만, 어느정도의 유사성을 띄고 있긴하네요!
4. 문서 로더
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(
web_paths=("<https://lilianweng.github.io/posts/2023-06-23-agent/>",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
blog_docs = loader.load()
설명:
- 이 블록에서는
langchain_community의WebBaseLoader를 사용하여 지정된 웹 페이지에서 문서를 로드합니다. WebBaseLoader는 웹 페이지의 특정 HTML 요소를 추출하여 텍스트로 변환하는 역할을 합니다. 여기서는bs4.SoupStrainer를 사용하여class_로 지정된 요소들만 추출합니다.loader.load()는 로드된 문서를 반환합니다.
5. 텍스트 분할기
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=300,
chunk_overlap=50
)
splits = text_splitter.split_documents(blog_docs)
설명:
- 이 부분은 긴 텍스트를 작은 덩어리로 분할하는 과정입니다.
RecursiveCharacterTextSplitter는 텍스트를 특정 크기로 나누되, 덩어리 간에 겹치는 부분도 포함되도록 합니다. chunk_size=300은 각 덩어리의 최대 크기를 설정하며,chunk_overlap=50은 덩어리 간의 겹치는 부분의 크기를 설정합니다.- 최종적으로
split_documents메서드를 통해 문서를 분할합니다.
6. 벡터 스토어
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=splits,
embedding=OpenAIEmbeddings())
# 검색기 생성
retriever = vectorstore.as_retriever()
설명:
- 이 코드에서는 분할된 문서 덩어리들을 벡터 스토어에 인덱싱합니다.
Chroma는 텍스트의 임베딩을 저장하고 검색할 수 있는 벡터 스토어를 생성하는 역할을 합니다. Chroma.from_documents는 문서의 임베딩을 생성하여 벡터 스토어에 저장합니다.- 마지막으로
vectorstore.as_retriever()를 통해 저장된 임베딩에서 텍스트 검색이 가능한 검색기를 생성합니다.
Part 3 (검색)
- 이 비디오는 LangChain의 Lance가 진행하는 "RAG From Scratch" 시리즈의 세 번째 영상으로, 이번 주제는 정보 검색(Retrieval)입니다.
- 색인화의 기본 개념
- 문서를 색인화하는 과정은 문서를 작은 조각(Chunks)으로 나누고, 이를 임베딩(Embedding)하여 벡터화하는 것입니다.
- 이 벡터화된 임베딩은 문서의 의미적 내용에 따라 고차원 공간의 한 점으로 표현됩니다. 이 점의 위치는 문서의 의미를 반영하며, 질문도 동일한 방식으로 임베딩되어 해당 공간에서 문서와의 유사성을 검색하게 됩니다.
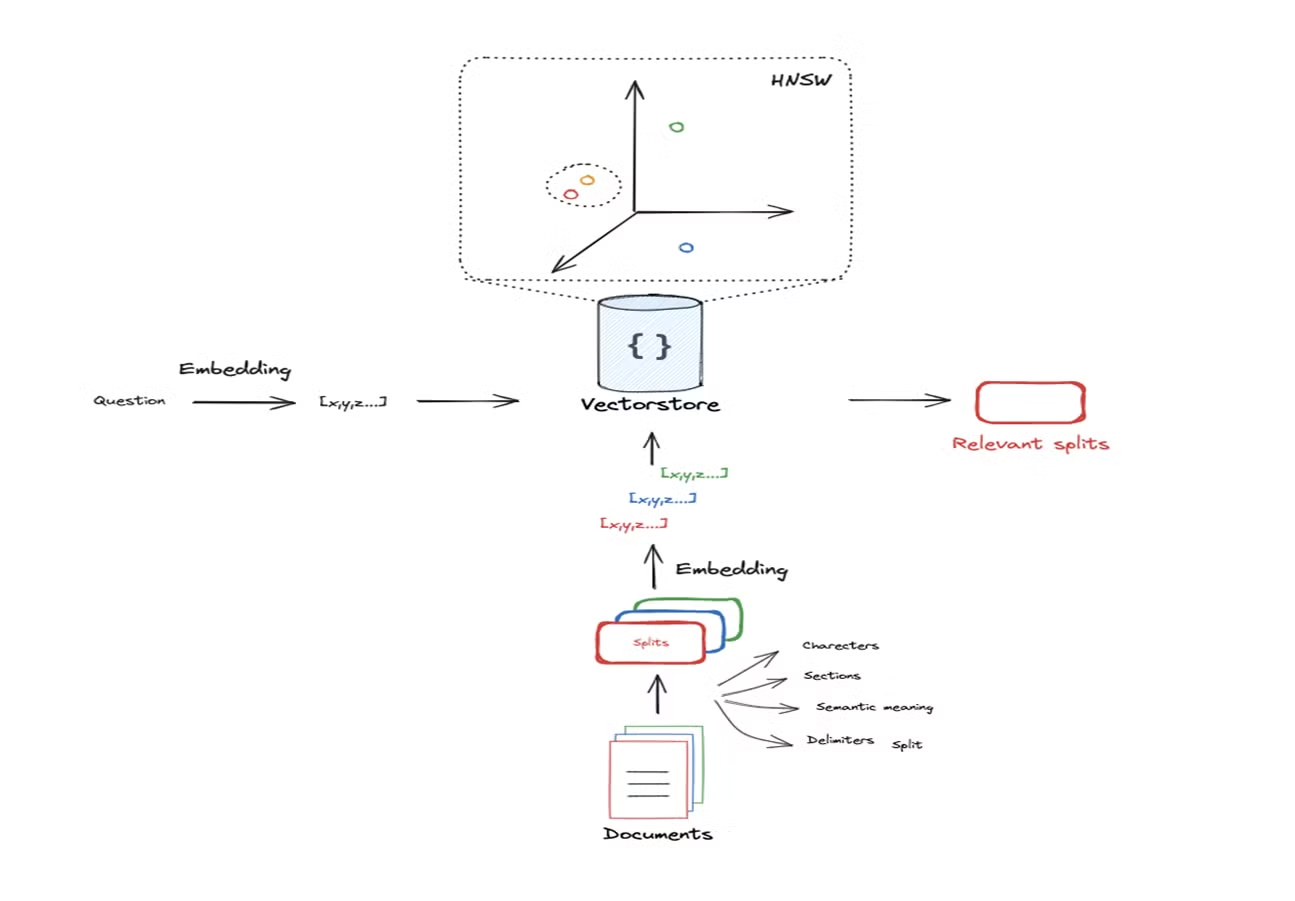
코드 시연
- 문서가 임베딩된 고차원 공간에서 질문과 유사한 문서를 검색하는 과정은 로컬 네이버후드 검색(Local Neighborhood Search)이라고 할 수 있습니다.
- 이 검색 과정에서 질문과 가까운 위치에 있는 문서들을 찾아내고, 이를 기반으로 관련 문서를 반환합니다.
- 문서 검색 시, 반환할 문서의 수를 결정하는 K-값을 설정할 수 있습니다. 예를 들어, K=1로 설정하면 질문과 가장 가까운 한 개의 문서만 반환합니다.
# Index from langchain_openai import OpenAIEmbeddings from langchain_community.vectorstores import Chroma # 앞에서 본 것처럼 vectorstore 선언 vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings()) retriever = vectorstore.as_retriever(search_kwargs={"k": 1}) docs = retriever.get_relevant_documents("What is Task Decomposition?") len(docs) # 1이 반환됨
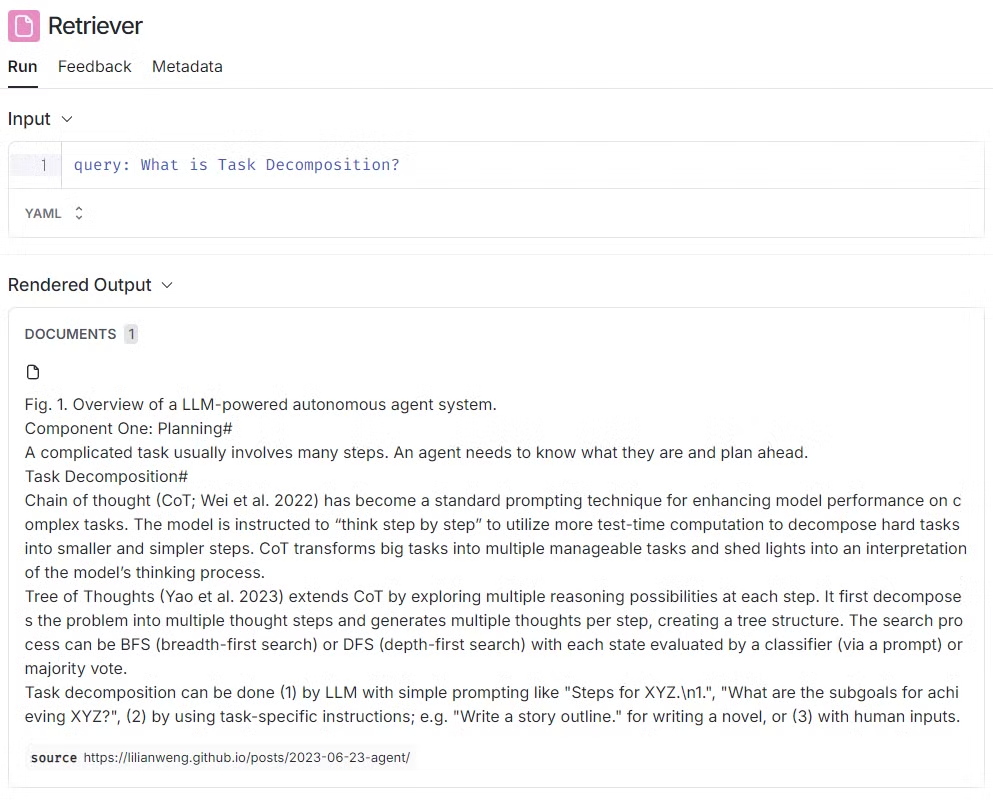
Part 4 (생성)
- 해당 영상에서는 문서 검색을 통해 얻은 데이터를 기반으로
LLM(Large Language Model)을 활용하여 답변을 생성하는 과정에 중점을 둡니다.
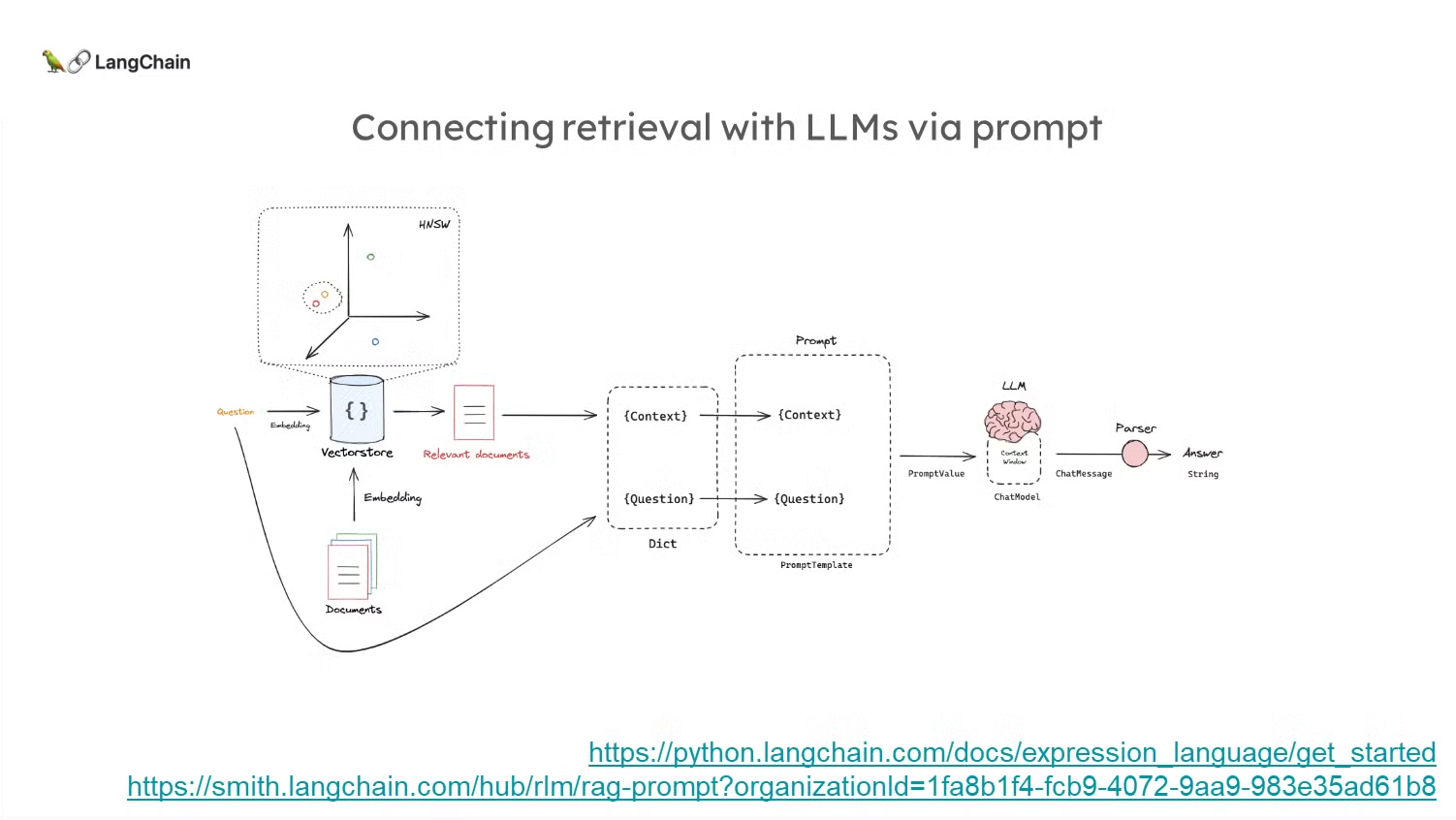
(복습) 문서 삽입과 LLM 컨텍스트 윈도우
- 문서 검색 후, 문서를 작은 단위로 나눈 뒤, 이를 벡터로 변환하여 벡터 스토어에 저장합니다.
- 질문도 마찬가지로 벡터로 변환하여 KNN(K-Nearest Neighbors)과 같은 기법으로 검색된 문서와 비교합니다.
- 검색된 문서는 LLM의 컨텍스트 윈도우에 삽입되어 답변 생성에 사용됩니다.
위에서 보여드린 그림을 좀 더 자세하게 살펴보도록 하겠습니다:
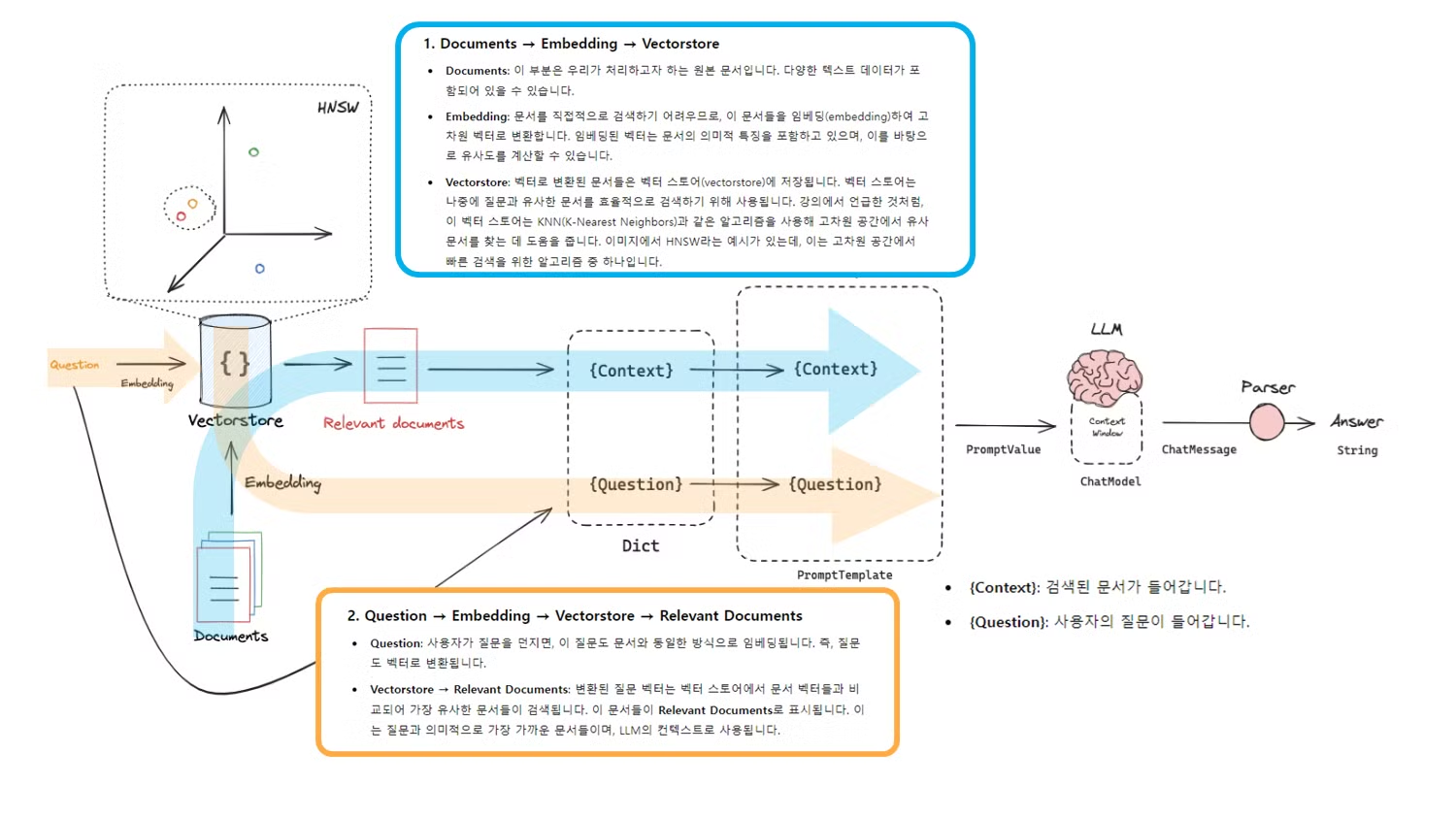
- Documents → Embedding → Vectorstore
- Documents: 이 부분은 우리가 처리하고자 하는 원본 문서입니다. 다양한 텍스트 데이터가 포함되어 있을 수 있습니다.
- Embedding: 문서를 직접적으로 검색하기 어려우므로, 이 문서들을 임베딩(embedding)하여 고차원 벡터로 변환합니다. 임베딩된 벡터는 문서의 의미적 특징을 포함하고 있으며, 이를 바탕으로 유사도를 계산할 수 있습니다.
- Vectorstore: 벡터로 변환된 문서들은 벡터 스토어(vectorstore)에 저장됩니다. 벡터 스토어는 나중에 질문과 유사한 문서를 효율적으로 검색하기 위해 사용됩니다. (Ex. KNN, HNSW 기법 등을 기반으로 검색을 수행합니다.)
HNSW(Hierarchical Navigable Small World): 고차원 벡터 데이터의 근사 최근접 이웃(Approximate Nearest Neighbor) 검색을 위한 효율적인 알고리즘입니다.
- Question → Embedding → Vectorstore → Relevant Documents
- Question: 사용자가 질문을 던지면, 이 질문도 문서와 동일한 방식으로 임베딩됩니다. 즉, 질문도 벡터로 변환됩니다.
- Vectorstore → Relevant Documents: 변환된 질문 벡터는 벡터 스토어에서 문서 벡터들과 비교되어 가장 유사한 문서들이 검색됩니다.
- 이 문서들이 Relevant Documents로 표시됩니다. 이는 질문과 의미적으로 가장 가까운 문서들이며, LLM의 컨텍스트로 사용됩니다.
- Dict 생성
- 검색된 문서와 질문은 Dict라는 자료 구조로 변환됩니다.
- 이 Dict는 두 가지 필드를 포함하고 있는데:
- {Context}: 검색된 문서가 들어갑니다.
- {Question}: 사용자의 질문이 들어갑니다.
- 이 Dict는 Prompt Template에 들어갈 데이터를 정의하는 중요한 역할을 합니다.
- Prompt Template
- 프롬프트 템플릿(Prompt Template)은 LLM(Large Language Model)을 이용하여 텍스트를 생성할 때 중요한 역할을 합니다.
- LLM은 텍스트 데이터를 받아들이는 방식이 매우 유연하지만, 사용자가 원하는 대로 결과를 도출하려면 일관되고 구조화된 방식으로 모델에게 정보를 제공할 필요가 있습니다. 프롬프트 템플릿은 바로 이 과정을 돕기 위한 도구입니다.
- 프롬프트 템플릿은 텍스트 생성 과정을 쉽게 반복 가능하게 하고, 각기 다른 입력에 따라 변형할 수 있는 일종의 템플릿을 제공합니다.
- 문서와 질문을 기반으로 답변을 생성하는 작업을 할 때, 모델에 동일한 구조로 정보(문서와 질문)를 전달하는 것이 중요합니다.
- 프롬프트 템플릿은 문서를 {context}에, 질문을 {question}에 삽입함으로써 이 구조를 유지해 줍니다.
# 예시 프롬프트 템플렛 Answer the question based only on the following context: {context} Question: {question} - 이제, 실제 데이터를 프롬프트 템플릿에 채워 넣는 순간, Prompt Value라는 최종 프롬프트가 만들어집니다. 이 프롬프트는 텍스트로 변환되어 LLM에 전달할 준비가 된 상태입니다.
- 예를 들어, 템플릿에 검색된 문서와 질문이 삽입되면 다음과 같은 형태로 변환됩니다.
Answer the question based only on the following context: "Document 1 content here. Document 2 content here..." Question: "What is Task Decomposition?"
- 프롬프트 템플릿(Prompt Template)은 LLM(Large Language Model)을 이용하여 텍스트를 생성할 때 중요한 역할을 합니다.
Q. 아니 그냥 dict로 주면 되지 않나? 왜 프롬프트 템플릿을 사용하지?
A. 이 방식은 다음과 같은 장점이 있습니다:
- 자동화: 여러 개의 질문과 컨텍스트에 대해 동일한 형식의 프롬프트를 자동으로 생성할 수 있습니다.
- 재사용성: 같은 프롬프트 템플릿을 다양한 입력 데이터에 사용할 수 있습니다.
- 일관성: 일정한 형식으로 LLM에 데이터를 전달하여, 더 일관된 결과를 얻을 수 있습니다.
- LLM (Large Language Model)
- Prompt Value가 LLM에 전달됩니다. LLM은 컨텍스트 윈도우(Context Window)를 사용해 전달된 문서와 질문을 바탕으로 답변을 생성합니다.
- Parser
- LLM에서 생성된 답변은 Parser를 통해 처리됩니다. Parser는 LLM에서 생성된 텍스트 데이터를 적절히 파싱하여 최종적으로 Answer로 반환합니다.
코드 시연
- 문서를 로드하고, 이를 분할한 후, 임베딩을 적용하여 벡터로 변환하고 벡터 스토어에 저장하는 작업을 보여줍니다.
- 생성 부분에서는 간단한 프롬프트 템플릿을 만들어, 문맥(context)과 질문(question)을 바탕으로 답변을 생성하는 방식을 설명합니다.
- LangChain에서 제공하는
LangChain Expression Language를 활용하여 프롬프트, LLM, 파서(parser), 그리고 리트리버(retriever)를 쉽게 연결할 수 있습니다.
(1) 프롬프트 템플릿이 LLM에 들어가는 과정
- 아래 코드를 통해 프롬프트 템플릿을 LLM에 전달되고, 그 결과로 답변이 생성할 수 있습니다.
from langchain_openai import ChatOpenAI from langchain.prompts import ChatPromptTemplate # 프롬프트 템플릿 정의 template = """Answer the question based only on the following context: {context} Question: {question} """ # 템플릿을 ChatPromptTemplate 객체로 변환 prompt = ChatPromptTemplate.from_template(template) # LLM 생성 llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0) # 체인(chain) 생성: 프롬프트와 LLM 연결 chain = prompt | llm # 실행: 컨텍스트와 질문을 템플릿에 삽입하여 답변 생성 # 앞에서 선언해둔 docs와 Question을 Invoke하는 형태 chain.invoke({"context": docs, "question": "What is Task Decomposition?"})- 프롬프트 템플릿 정의: 먼저 템플릿 문자열을 정의합니다. 여기서 {context}는 검색된 문서가 삽입되는 자리이고, {question}은 질문이 삽입되는 자리입니다. 이 템플릿은 답변을 생성하는 데 필요한 모든 정보를 제공합니다.
- 템플릿을 객체로 변환: ChatPromptTemplate.from_template() 메서드를 사용해 문자열 형태의 템플릿을 객체로 변환합니다. 이 객체는 나중에 데이터가 삽입될 수 있는 준비된 템플릿입니다.
- LLM 정의: ChatOpenAI 클래스에서 gpt-3.5-turbo라는 모델을 선택하여 LLM을 정의합니다. 여기서 temperature=0은 모델이 더욱 일관된(즉, 덜 랜덤한) 답변을 생성하도록 설정한 것입니다.
- 프롬프트와 LLM 연결(Chain): 프롬프트 템플릿과 LLM을 연결하여 체인을 만듭니다. 이 체인은 프롬프트에 데이터를 삽입하고, LLM을 호출해 답변을 생성하는 전체 프로세스를 하나의 흐름으로 묶습니다.
- 실행: chain.invoke() 메서드를 통해 {context}에는 문서(docs)가, {question}에는 질문이 삽입된 프롬프트가 LLM에 전달됩니다. 모델은 이 프롬프트를 기반으로 답변을 생성하고, 그 결과를 반환합니다.
(2) LangChain과 프롬프트 템플릿
- LangChain에서는 프롬프트 템플릿을 보다 쉽게 사용할 수 있는 다양한 도구를 제공합니다.
- 예를 들어, 템플릿과 LLM, 그리고 파서를 연결하여 하나의 파이프라인을 만들고, 이를 통해 검색 기반 답변 생성(RAG)을 수행할 수 있습니다.
from langchain import hub from langchain_core.output_parsers import StrOutputParser from langchain_core.runnables import RunnablePassthrough prompt_hub_rag = hub.pull("rlm/rag-prompt") # RAG 체인 생성 rag_chain = ( {"context": retriever, "question": RunnablePassthrough()} | prompt_hub_rag # 호출한 template 사용 | llm | StrOutputParser() ) # 질문에 대한 답변 생성 rag_chain.invoke("What is Task Decomposition?") - 제대로 결과가 출력되고, 실행된 것을 확인할 수 있습니다: