1. 행렬(Matrix)의 정의
인공지능 및 기계 학습에서 행렬(matrix) 은 데이터를 처리하고 표현하는 중요한 도구입니다. 행렬은 수를 직사각형 형태로 배열한 것으로, 데이터를 수학적으로 다루기 위해 필수적입니다. 행렬을 사용하면 대규모 데이터를 효율적으로 관리하고 계산할 수 있습니다.
예시:
우리가 이미 익숙한 데이터 테이블을 생각해봅시다.
A = [ 90 85 78 92 88 76 ] A = \begin{bmatrix} 90 & 85 \\ 78 & 92 \\ 88 & 76 \end{bmatrix} A = ⎣ ⎢ ⎡ 9 0 7 8 8 8 8 5 9 2 7 6 ⎦ ⎥ ⎤ 여기서 행은 학생, 열은 과목(수학과 영어)을 나타냅니다. 이처럼 행렬은 2차원 데이터를 매우 간단하게 표현할 수 있습니다.
행렬을 다룰 때 중요한 개념으로 행렬의 곱셈 , 역행렬 , 전치 행렬 등이 있으며, 이는 인공지능 모델을 구현할 때 필수적인 기초 연산입니다.
1.1. 행렬의 곱셈(Matrix Multiplication)
행렬의 곱셈 은 두 행렬을 곱하는 연산입니다. 두 행렬을 곱하려면 첫 번째 행렬의 열의 개수가 두 번째 행렬의 행의 개수와 같아야 합니다. 곱셈 결과로 나온 행렬의 i i i j j j i i i j j j
예시:
A = [ 1 2 3 4 ] , B = [ 5 6 7 8 ] A = \begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix}, \quad B = \begin{bmatrix} 5 & 6 \\ 7 & 8 \end{bmatrix} A = [ 1 3 2 4 ] , B = [ 5 7 6 8 ] 두 행렬을 곱하면,
A B = [ ( 1 × 5 ) + ( 2 × 7 ) ( 1 × 6 ) + ( 2 × 8 ) ( 3 × 5 ) + ( 4 × 7 ) ( 3 × 6 ) + ( 4 × 8 ) ] = [ 19 22 43 50 ] AB = \begin{bmatrix} (1 \times 5) + (2 \times 7) & (1 \times 6) + (2 \times 8) \\ (3 \times 5) + (4 \times 7) & (3 \times 6) + (4 \times 8) \end{bmatrix} = \begin{bmatrix} 19 & 22 \\ 43 & 50 \end{bmatrix} A B = [ ( 1 × 5 ) + ( 2 × 7 ) ( 3 × 5 ) + ( 4 × 7 ) ( 1 × 6 ) + ( 2 × 8 ) ( 3 × 6 ) + ( 4 × 8 ) ] = [ 1 9 4 3 2 2 5 0 ] 1.2. 역행렬(Inverse Matrix)
역행렬 은 어떤 행렬을 곱했을 때 결과가 단위행렬(identity matrix) 이 되는 행렬을 의미합니다. 행렬 A A A A − 1 A^{-1} A − 1
A A − 1 = A − 1 A = I A A^{-1} = A^{-1} A = I A A − 1 = A − 1 A = I 단, 모든 행렬에 역행렬이 존재하는 것은 아니며, 행렬식(determinant) 이 0이 아닌 경우에만 역행렬이 존재합니다.
예시:A = [ 1 2 3 4 ] A = \begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix} A = [ 1 3 2 4 ]
A − 1 = 1 ( 1 × 4 − 2 × 3 ) [ 4 − 2 − 3 1 ] = [ − 2 1 1.5 − 0.5 ] A^{-1} = \frac{1}{(1 \times 4 - 2 \times 3)} \begin{bmatrix} 4 & -2 \\ -3 & 1 \end{bmatrix} = \begin{bmatrix} -2 & 1 \\ 1.5 & -0.5 \end{bmatrix} A − 1 = ( 1 × 4 − 2 × 3 ) 1 [ 4 − 3 − 2 1 ] = [ − 2 1 . 5 1 − 0 . 5 ] 1.3. 전치 행렬(Transpose Matrix)
전치 행렬 은 원래 행렬의 행과 열을 서로 바꾼 행렬입니다. 행렬 A A A A T A^T A T A A A A T A^T A T
예시:A = [ 1 2 3 4 ] A = \begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix} A = [ 1 3 2 4 ]
A T = [ 1 3 2 4 ] A^T = \begin{bmatrix} 1 & 3 \\ 2 & 4 \end{bmatrix} A T = [ 1 2 3 4 ] 2. 고윳값(Eigenvalue)과 고유벡터(Eigenvector)란?
https://rfriend.tistory.com/181
고유벡터(Eigenvector)의 정의
고유벡터는 행렬이 특정 벡터에 작용할 때, 그 벡터의 방향은 변하지 않고 크기만 변화 하는 특별한 벡터입니다. 이는 데이터를 분석하고, 차원을 축소하거나, 이미지 처리를 할 때 매우 유용하게 사용됩니다.
고유벡터(Eigenvector) 의 크기(length, size) 는 정해져 있지 않습니다. 즉, 고유벡터는 방향만을 나타내며, 크기는 그 값에 영향을 미치지 않습니다. 실제로 고유벡터의 크기는 자유롭게 스칼라 배 를 해도 여전히 같은 고유벡터로 간주됩니다.
예를 들어, 고유벡터가 v = [ 1 2 ] \mathbf{v} = \begin{bmatrix} 1 \\ 2 \end{bmatrix} v = [ 1 2 ] 2 v = [ 2 4 ] 2\mathbf{v} = \begin{bmatrix} 2 \\ 4 \end{bmatrix} 2 v = [ 2 4 ]
실제로 고유벡터를 다룰 때는 주로 단위 벡터(normalized vector) 로 변환하여, 벡터의 크기를 1로 맞춰 사용하는 경우가 많습니다. 이를 통해 계산의 일관성을 유지하고 해석을 용이하게 합니다.
고윳값(Eigenvalue)의 정의
고윳값은 행렬이 고유벡터에 작용할 때 벡터의 크기를 얼마나 변화시키는지를 나타냅니다. 이 값은 벡터의 방향을 유지한 상태에서 크기만 변화시키는 비율을 의미합니다.
예시로 이해해봅시다:
행렬 A = [ 2 0 0 3 ] A = \begin{bmatrix} 2 & 0 \\ 0 & 3 \end{bmatrix} A = [ 2 0 0 3 ] v = [ 1 0 ] \mathbf{v} = \begin{bmatrix} 1 \\ 0 \end{bmatrix} v = [ 1 0 ]
A v = [ 2 0 0 3 ] [ 1 0 ] = [ 2 0 ] A \mathbf{v} = \begin{bmatrix} 2 & 0 \\ 0 & 3 \end{bmatrix} \begin{bmatrix} 1 \\ 0 \end{bmatrix} = \begin{bmatrix} 2 \\ 0 \end{bmatrix} A v = [ 2 0 0 3 ] [ 1 0 ] = [ 2 0 ] 고윳값을 구하는 방법
행렬의 고윳값은 다음과 같은 특성 방정식 을 통해 구할 수 있습니다:
A v = λ v A \mathbf{v} = \lambda \mathbf{v} A v = λ v 이를 변형하면,
( A − λ I ) v = 0 (A - \lambda I) \mathbf{v} = 0 ( A − λ I ) v = 0 이 방정식에서 행렬 ( A − λ I ) (A - \lambda I) ( A − λ I ) 행렬식(determinant) 을 0으로 두고 고윳값을 구할 수 있습니다.
예시로 고윳값을 구해봅시다:
행렬 A = [ 4 1 2 3 ] A = \begin{bmatrix} 4 & 1 \\ 2 & 3 \end{bmatrix} A = [ 4 2 1 3 ]
특성 방정식을 세우면:
det ( A − λ I ) = det [ 4 − λ 1 2 3 − λ ] = ( 4 − λ ) ( 3 − λ ) − 2 = 0 \det(A - \lambda I) = \det\begin{bmatrix} 4-\lambda & 1 \\ 2 & 3-\lambda \end{bmatrix} = (4-\lambda)(3-\lambda) - 2 = 0 det ( A − λ I ) = det [ 4 − λ 2 1 3 − λ ] = ( 4 − λ ) ( 3 − λ ) − 2 = 0 이를 풀면, 두 개의 고윳값 λ 1 = 5 \lambda_1 = 5 λ 1 = 5 λ 2 = 2 \lambda_2 = 2 λ 2 = 2
고윳값을 구했다면, 이제 고유벡터(eigenvector) 를 구할 차례입니다. 고유벡터는 주어진 고윳값에 대응하는 벡터로, 아래의 과정을 통해 구할 수 있습니다.
고유벡터를 구하는 방법
고유벡터는 행렬 방정식 을 통해서 구할 수 있습니다.
먼저, 고윳값 λ \lambda λ 행렬 방정식 ( A − λ I ) v = 0 (A - \lambda I) \mathbf{v} = 0 ( A − λ I ) v = 0
A A A λ \lambda λ I I I v \mathbf{v} v
방정식 ( A − λ I ) v = 0 (A - \lambda I) \mathbf{v} = 0 ( A − λ I ) v = 0 v \mathbf{v} v
예시
우리가 구한 고윳값을 사용하는 행렬 A A A
A = [ 4 1 2 3 ] A = \begin{bmatrix} 4 & 1 \\ 2 & 3 \end{bmatrix} A = [ 4 2 1 3 ]
참고로 도출한 고윳값은 λ 1 = 5 \lambda_1 = 5 λ 1 = 5 λ 2 = 2 \lambda_2 = 2 λ 2 = 2
1. 첫 번째 고윳값 λ 1 = 5 \lambda_1 = 5 λ 1 = 5
행렬 A A A λ 1 = 5 \lambda_1 = 5 λ 1 = 5 A − 5 I A - 5I A − 5 I
A − 5 I = [ 4 1 2 3 ] − 5 [ 1 0 0 1 ] = [ 4 − 5 1 2 3 − 5 ] = [ − 1 1 2 − 2 ] A - 5I = \begin{bmatrix} 4 & 1 \\ 2 & 3 \end{bmatrix} - 5 \begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix} = \begin{bmatrix} 4-5 & 1 \\ 2 & 3-5 \end{bmatrix} = \begin{bmatrix} -1 & 1 \\ 2 & -2 \end{bmatrix} A − 5 I = [ 4 2 1 3 ] − 5 [ 1 0 0 1 ] = [ 4 − 5 2 1 3 − 5 ] = [ − 1 2 1 − 2 ]
이제 행렬 방정식 ( A − 5 I ) v = 0 (A - 5I) \mathbf{v} = 0 ( A − 5 I ) v = 0
[ − 1 1 2 − 2 ] [ v 1 v 2 ] = [ 0 0 ] \begin{bmatrix} -1 & 1 \\ 2 & -2 \end{bmatrix} \begin{bmatrix} v_1 \\ v_2 \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \end{bmatrix} [ − 1 2 1 − 2 ] [ v 1 v 2 ] = [ 0 0 ]
이 행렬 방정식을 풀면, 다음과 같은 연립 방정식을 얻습니다:
− 1 ⋅ v 1 + 1 ⋅ v 2 = 0 ⇒ v 1 = v 2 -1 \cdot v_1 + 1 \cdot v_2 = 0 \quad \Rightarrow \quad v_1 = v_2 − 1 ⋅ v 1 + 1 ⋅ v 2 = 0 ⇒ v 1 = v 2
즉, 첫 번째 고유벡터는 v 1 = v 2 v_1 = v_2 v 1 = v 2
v 1 = [ 1 1 ] \mathbf{v}_1 = \begin{bmatrix} 1 \\ 1 \end{bmatrix} v 1 = [ 1 1 ] 2. 두 번째 고윳값 λ 2 = 2 \lambda_2 = 2 λ 2 = 2
두 번째 고윳값 λ 2 = 2 \lambda_2 = 2 λ 2 = 2 A − 2 I A - 2I A − 2 I
A − 2 I = [ 4 1 2 3 ] − 2 [ 1 0 0 1 ] = [ 4 − 2 1 2 3 − 2 ] = [ 2 1 2 1 ] A - 2I = \begin{bmatrix} 4 & 1 \\ 2 & 3 \end{bmatrix} - 2 \begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix} = \begin{bmatrix} 4-2 & 1 \\ 2 & 3-2 \end{bmatrix} = \begin{bmatrix} 2 & 1 \\ 2 & 1 \end{bmatrix} A − 2 I = [ 4 2 1 3 ] − 2 [ 1 0 0 1 ] = [ 4 − 2 2 1 3 − 2 ] = [ 2 2 1 1 ]
이제 행렬 방정식 ( A − 2 I ) v = 0 (A - 2I) \mathbf{v} = 0 ( A − 2 I ) v = 0
[ 2 1 2 1 ] [ v 1 v 2 ] = [ 0 0 ] \begin{bmatrix} 2 & 1 \\ 2 & 1 \end{bmatrix} \begin{bmatrix} v_1 \\ v_2 \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \end{bmatrix} [ 2 2 1 1 ] [ v 1 v 2 ] = [ 0 0 ]
이 행렬 방정식을 풀면, 다음과 같은 연립 방정식을 얻습니다:
2 v 1 + v 2 = 0 ⇒ v 2 = − 2 v 1 2v_1 + v_2 = 0 \quad \Rightarrow \quad v_2 = -2v_1 2 v 1 + v 2 = 0 ⇒ v 2 = − 2 v 1
따라서 두 번째 고유벡터는 v 2 = − 2 v 1 v_2 = -2v_1 v 2 = − 2 v 1
v 2 = [ 1 − 2 ] \mathbf{v}_2 = \begin{bmatrix} 1 \\ -2 \end{bmatrix} v 2 = [ 1 − 2 ]
(참고) 아래 사이트에서도 쉽게 행렬 연산 및 고유값 계산하실 수 있습니다!
3. 기저(Basis)란?
기저(Basis) 는 벡터 공간을 구성하는 기본적인 벡터들의 집합 을 의미합니다. 벡터 공간에 있는 모든 벡터는 이 기저 벡터들의 선형 결합(즉, 적절한 배수로 더한 것)으로 표현될 수 있습니다. 기저는 공간의 구조를 결정하는 중요한 개념이며, 기저 벡터들은 선형 독립(linearly independent) 이어야 합니다.
기저의 조건:
선형 독립성 : 기저를 구성하는 벡터들은 서로 선형 결합으로 표현될 수 없어야 합니다. 즉, 하나의 기저 벡터는 다른 기저 벡터들의 조합으로 만들어지지 않습니다.벡터 공간의 생성(Span) : 기저 벡터들을 선형 결합하여 해당 벡터 공간의 모든 벡터를 표현할 수 있어야 합니다.
예시로 이해해봅시다:
2차원 평면에서 가장 기본적인 기저는 e 1 = [ 1 0 ] \mathbf{e}_1 = \begin{bmatrix} 1 \\ 0 \end{bmatrix} e 1 = [ 1 0 ] e 2 = [ 0 1 ] \mathbf{e}_2 = \begin{bmatrix} 0 \\ 1 \end{bmatrix} e 2 = [ 0 1 ]
이 두 벡터는 2차원 공간에서 선형 독립적이고, 이 두 벡터를 적절히 조합하면 2차원 공간의 모든 벡터를 만들 수 있습니다.
v = a e 1 + b e 2 = a [ 1 0 ] + b [ 0 1 ] = [ a b ] \mathbf{v} = a\mathbf{e}_1 + b\mathbf{e}_2 = a\begin{bmatrix} 1 \\ 0 \end{bmatrix} + b\begin{bmatrix} 0 \\ 1 \end{bmatrix} = \begin{bmatrix} a \\ b \end{bmatrix} v = a e 1 + b e 2 = a [ 1 0 ] + b [ 0 1 ] = [ a b ] 즉, e 1 \mathbf{e}_1 e 1 e 2 \mathbf{e}_2 e 2 표준 기저 (Standard Basis)입니다.
기저의 중요성:
기저는 차원 축소, 고유값 분해, 데이터 변환 등의 다양한 분야에서 중요한 역할을 합니다.
예를 들어, 고유벡터(Eigenvector) 는 특정 행렬에서의 고유한 변환 성질을 반영하는 새로운 기저 로 사용할 수 있습니다. 이처럼 기저는 우리가 공간을 이해하고 변환하는 데 기본적인 틀을 제공해줍니다.
4. 대각화(Diagonalization)
대각화는 행렬을 그 행렬의 고유벡터(eigenvector) 로 구성된 새로운 기저(basis) 에서 표현하여, 대각행렬(diagonal matrix) 로 변환하는 과정입니다.
대각행렬은 매우 간단한 형태로, 대각선 상에 고윳값들이 배치되고 나머지 원소는 모두 0인 행렬입니다.
이 변환은 행렬의 특성을 더 명확하게 드러내고, 계산을 효율적으로 할 수 있게 해주는 중요한 기법입니다.
대각화를 수학적으로 표현하면 다음과 같습니다:
A = P D P − 1 A = PDP^{-1} A = P D P − 1 여기서,
A A A P P P A A A 고유벡터 들로 구성된 행렬입니다. P P P D D D A A A 고윳값 들이 대각선에 배열된 대각행렬 입니다.P − 1 P^{-1} P − 1 P P P
이 관계식은 행렬 A A A 나타냅니다. 즉, 고유벡터들을 기준으로 원래의 행렬을 변환하면, 단순한 대각행렬로 바뀌어 더 직관적으로 해석할 수 있습니다.
대각화를 직관적으로 설명하면, 복잡한 변환을 단순한 형태로 바꾸는 과정입니다.
예를 들어, 행렬 A A A 고유벡터들의 기저로 변환 하면, 행렬 A A A 대각행렬 로 바뀌어 고유벡터 방향으로만 크기를 조정 하게 됩니다.
예시로 대각화를 해봅시다. 행렬 A = [ 4 1 2 3 ] A = \begin{bmatrix} 4 & 1 \\ 2 & 3 \end{bmatrix} A = [ 4 2 1 3 ]
이 행렬의 고윳값과 고유벡터를 구하면:
고윳값: λ 1 = 5 , λ 2 = 2 \lambda_1 = 5, \lambda_2 = 2 λ 1 = 5 , λ 2 = 2
고유벡터: v 1 = [ 1 2 ] , v 2 = [ − 1 1 ] \mathbf{v}_1 = \begin{bmatrix} 1 \\ 2 \end{bmatrix}, \mathbf{v}_2 = \begin{bmatrix} -1 \\ 1 \end{bmatrix} v 1 = [ 1 2 ] , v 2 = [ − 1 1 ]
이 고유벡터들로 구성된 행렬 P P P
P = [ 1 − 1 2 1 ] P = \begin{bmatrix} 1 & -1 \\ 2 & 1 \end{bmatrix} P = [ 1 2 − 1 1 ] P − 1 = [ 1 / 3 1 / 3 − 2 / 3 1 / 3 ] P^{-1} = \begin{bmatrix} 1/3 & 1/3 \\ -2/3 & 1/3 \end{bmatrix} P − 1 = [ 1 / 3 − 2 / 3 1 / 3 1 / 3 ]
그리고 고윳값을 대각선에 배치한 대각행렬 D D D
D = [ 5 0 0 2 ] D = \begin{bmatrix} 5 & 0 \\ 0 & 2 \end{bmatrix} D = [ 5 0 0 2 ]
이제 대각화된 형태로 표현하면, 다음과 같은 관계식을 얻습니다.
A = P D P − 1 A = PDP^{-1} A = P D P − 1 A = [ 1 − 1 2 1 ] [ 5 0 0 2 ] [ 1 / 3 1 / 3 − 2 / 3 1 / 3 ] A = \begin{bmatrix} 1 & -1 \\ 2 & 1 \end{bmatrix} \begin{bmatrix} 5 & 0 \\ 0 & 2 \end{bmatrix}\begin{bmatrix} 1/3 & 1/3 \\ -2/3 & 1/3 \end{bmatrix} A = [ 1 2 − 1 1 ] [ 5 0 0 2 ] [ 1 / 3 − 2 / 3 1 / 3 1 / 3 ]
✔️ 대각행렬을 포함한 계산은 아래 특징들 덕분에 일반적인 행렬 곱셈보다 훨씬 간단하고 빠르게 수행할 수 있습니다.
⭐ (추가) 대각행렬 간의 곱셈
대각 성분만의 곱셈 : 두 대각행렬을 곱할 때는 각 대각 성분끼리만 곱하면 됩니다.
예시:
( 2 0 0 0 3 0 0 0 4 ) × ( 1 0 0 0 5 0 0 0 2 ) = ( 2 0 0 0 15 0 0 0 8 ) \begin{pmatrix} 2 & 0 & 0 \\ 0 & 3 & 0 \\ 0 & 0 & 4 \end{pmatrix} \times \begin{pmatrix} 1 & 0 & 0 \\ 0 & 5 & 0 \\ 0 & 0 & 2 \end{pmatrix} = \begin{pmatrix} 2 & 0 & 0 \\ 0 & 15 & 0 \\ 0 & 0 & 8 \end{pmatrix} ⎝ ⎜ ⎛ 2 0 0 0 3 0 0 0 4 ⎠ ⎟ ⎞ × ⎝ ⎜ ⎛ 1 0 0 0 5 0 0 0 2 ⎠ ⎟ ⎞ = ⎝ ⎜ ⎛ 2 0 0 0 1 5 0 0 0 8 ⎠ ⎟ ⎞
교환법칙 성립 : 대각행렬 간의 곱셈은 교환법칙이 성립합니다.
예시:
A = ( 2 0 0 3 ) , B = ( 4 0 0 5 ) A = \begin{pmatrix} 2 & 0 \\ 0 & 3 \end{pmatrix}, B = \begin{pmatrix} 4 & 0 \\ 0 & 5 \end{pmatrix} A = ( 2 0 0 3 ) , B = ( 4 0 0 5 )
A B = ( 8 0 0 15 ) = B A AB = \begin{pmatrix} 8 & 0 \\ 0 & 15 \end{pmatrix} = BA A B = ( 8 0 0 1 5 ) = B A
결과도 대각행렬 : 두 대각행렬의 곱은 항상 대각행렬이 됩니다.
⭐ (추가) 대각행렬과 일반 행렬의 곱셈
행 또는 열 단위 곱셈:
대각행렬이 앞에 올 경우: 일반 행렬의 각 행에 대각행렬의 해당 대각 성분이 곱해집니다.
대각행렬이 뒤에 올 경우: 일반 행렬의 각 열에 대각행렬의 해당 대각 성분이 곱해집니다.
예시:
D = ( 2 0 0 0 3 0 0 0 4 ) , A = ( 1 2 3 4 5 6 7 8 9 ) D = \begin{pmatrix} 2 & 0 & 0 \\ 0 & 3 & 0 \\ 0 & 0 & 4 \end{pmatrix}, A = \begin{pmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \end{pmatrix} D = ⎝ ⎜ ⎛ 2 0 0 0 3 0 0 0 4 ⎠ ⎟ ⎞ , A = ⎝ ⎜ ⎛ 1 4 7 2 5 8 3 6 9 ⎠ ⎟ ⎞
D A = ( 2 4 6 12 15 18 28 32 36 ) DA = \begin{pmatrix} 2 & 4 & 6 \\ 12 & 15 & 18 \\ 28 & 32 & 36 \end{pmatrix} D A = ⎝ ⎜ ⎛ 2 1 2 2 8 4 1 5 3 2 6 1 8 3 6 ⎠ ⎟ ⎞
A D = ( 2 6 12 8 15 24 14 24 36 ) AD = \begin{pmatrix} 2 & 6 & 12 \\ 8 & 15 & 24 \\ 14 & 24 & 36 \end{pmatrix} A D = ⎝ ⎜ ⎛ 2 8 1 4 6 1 5 2 4 1 2 2 4 3 6 ⎠ ⎟ ⎞
⭐ (추가) 대각행렬의 거듭제곱
대각행렬의 k제곱 : 대각행렬의 k제곱은 각 대각 성분을 k제곱하는 것과 같습니다.
예시:
( 2 0 0 0 3 0 0 0 4 ) 3 = ( 8 0 0 0 27 0 0 0 64 ) \begin{pmatrix} 2 & 0 & 0 \\ 0 & 3 & 0 \\ 0 & 0 & 4 \end{pmatrix}^3 = \begin{pmatrix} 8 & 0 & 0 \\ 0 & 27 & 0 \\ 0 & 0 & 64 \end{pmatrix} ⎝ ⎜ ⎛ 2 0 0 0 3 0 0 0 4 ⎠ ⎟ ⎞ 3 = ⎝ ⎜ ⎛ 8 0 0 0 2 7 0 0 0 6 4 ⎠ ⎟ ⎞
5. 닮은 행렬(Similar Matrices)
행렬 A A A B B B
A = P B P − 1 A = PBP^{-1} A = P B P − 1 닮은 행렬은 동일한 고유 성질을 가지며, 같은 고윳값 을 공유합니다.
따라서 닮은 행렬은 행렬식과 대각합이 동일합니다.
💡 행렬식(Determinant) : 행렬의 고윳값들의 곱과 동일합니다. 즉, 행렬의 모든 고윳값을 곱한 값이 그 행렬의 행렬식이 됩니다.
💡 대각합(Trace) : 행렬의 고윳값들의 합과 동일합니다. 즉, 행렬의 모든 고윳값을 더한 값이 그 행렬의 대각합입니다.
예시:
행렬 A = [ 4 1 2 3 ] A = \begin{bmatrix} 4 & 1 \\ 2 & 3 \end{bmatrix} A = [ 4 2 1 3 ] B = [ 5 0 0 2 ] B = \begin{bmatrix} 5 & 0 \\ 0 & 2 \end{bmatrix} B = [ 5 0 0 2 ]
6. 직교 대각화(Orthogonal Diagonalization)
직교 대각화(Orthogonal Diagonalization) 는 대칭 행렬(symmetric matrix) 을 직교 행렬(orthogonal matrix) 을 사용하여 대각행렬(diagonal matrix) 로 변환하는 과정입니다.
이 과정에서 사용되는 직교 행렬은 대칭 행렬의 고유벡터들로 이루어지며, 대각행렬의 대각선에는 그 행렬의 고윳값들이 위치하게 됩니다.
직교 대각화의 수학적 정의는 다음과 같습니다:
여기서,
A A A Q Q Q 직교 행렬 로, 행렬 A A A 고유벡터(eigenvector) 들로 구성됩니다.D D D 대각행렬 로, 행렬 A A A 고윳값(eigenvalue) 들이 대각선에 위치합니다.Q T Q^T Q T Q Q Q 전치 행렬 , 직교 행렬의 특성상 Q − 1 = Q T Q^{-1} = Q^T Q − 1 = Q T
💡 대칭 행렬 은 A T = A A^T = A A T = A
예를 들어, A = [ 2 1 1 3 ] A = \begin{bmatrix} 2 & 1 \\ 1 & 3 \end{bmatrix} A = [ 2 1 1 3 ]
(예시 1) 2x2 대각 행렬: A = [ 2 1 1 3 ] , A T = [ 2 1 1 3 ] A = \begin{bmatrix} 2 & 1 \\ 1 & 3 \end{bmatrix}, A^T = \begin{bmatrix} 2 & 1 \\ 1 & 3 \end{bmatrix} A = [ 2 1 1 3 ] , A T = [ 2 1 1 3 ]
(예시 2) 3x3 대각 행렬: B = [ 4 2 3 2 5 1 3 1 6 ] , B T = [ 4 2 3 2 5 1 3 1 6 ] B = \begin{bmatrix} 4 & 2 & 3 \\ 2 & 5 & 1 \\ 3 & 1 & 6 \end{bmatrix}, B^{T} = \begin{bmatrix} 4 & 2 & 3 \\ 2 & 5 & 1 \\ 3 & 1 & 6 \end{bmatrix} B = ⎣ ⎢ ⎡ 4 2 3 2 5 1 3 1 6 ⎦ ⎥ ⎤ , B T = ⎣ ⎢ ⎡ 4 2 3 2 5 1 3 1 6 ⎦ ⎥ ⎤
💡 직교 행렬 은 전치 행렬이 역행렬과 같은 행렬로, Q Q T = Q T Q = I QQ^T=Q^T Q = I Q Q T = Q T Q = I
예를 들어, Q = [ 1 2 1 2 − 1 2 1 2 ] Q = \begin{bmatrix} \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \\ -\frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \end{bmatrix} Q = [ 2 1 − 2 1 2 1 2 1 ]
(예시 1)Q = [ 1 2 1 2 − 1 2 1 2 ] Q = \begin{bmatrix} \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \\ -\frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \end{bmatrix} Q = [ 2 1 − 2 1 2 1 2 1 ] Q T = [ 1 2 − 1 2 1 2 1 2 ] Q^T = \begin{bmatrix} \frac{1}{\sqrt{2}} & -\frac{1}{\sqrt{2}} \\ \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \end{bmatrix} Q T = [ 2 1 2 1 − 2 1 2 1 ]
Q T Q Q^T Q Q T Q I I I
직교 대각화의 특징
대칭 행렬만 직교 대각화 가능 :
대칭 행렬 은 항상 직교 대각화가 가능합니다. 즉, 모든 실수 대칭 행렬은 직교 행렬을 사용하여 대각화할 수 있습니다.
직교 행렬 사용 :
직교 대각화에서는 고유벡터들로 이루어진 직교 행렬 Q Q Q 직교 하고, 각각의 길이가 1인 단위 벡터 로 이루어져 있습니다.
대각행렬의 고윳값 :
대각화된 행렬 D D D A A A 고윳값 들이 배치됩니다.
고유벡터들의 직교성 :
대칭 행렬의 고유벡터들은 서로 직교(orthogonal) 합니다. 이는 직교 대각화가 가능하게 하는 중요한 성질입니다.
7. 특이값 분해 (SVD)
Singular Value Decomposition(SVD, 특이값 분해)는 행행렬을 세 개의 행렬(좌측 특이벡터, 특이값, 우측 특이벡터)의 곱으로 분해하는 강력한 방법입니다. 모든 행렬에 대해 SVD가 가능하다는 점에서 고유값 분해보다 더 일반적인 기법으로, 차원 축소, 추천 시스템, 이미지 압축 등 다양한 분야에 활용됩니다.
SVD는 다음과 같이 표현됩니다:
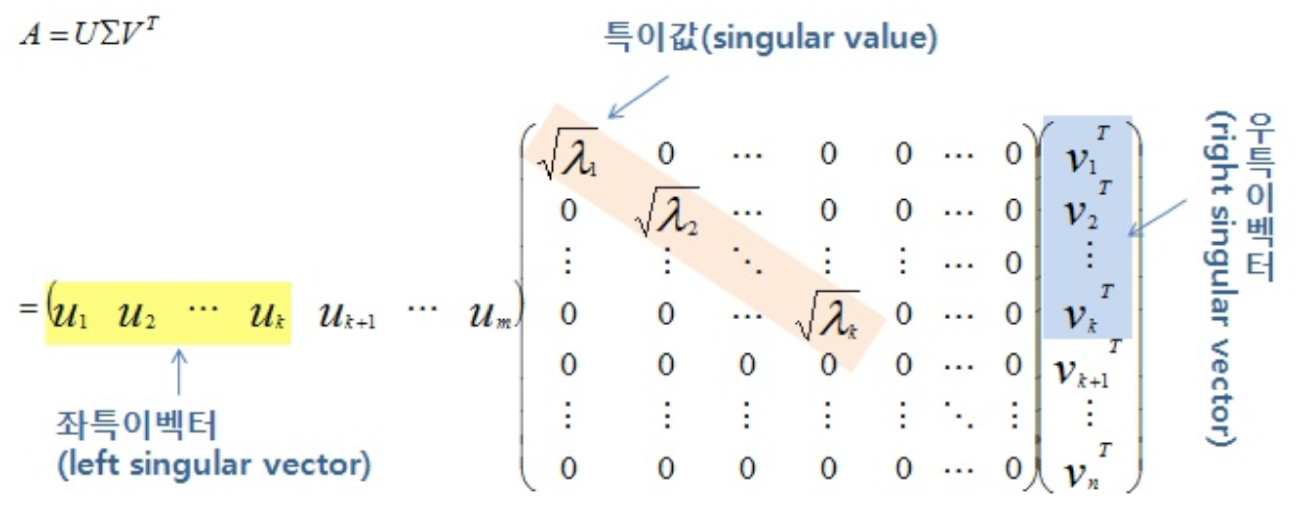
A = U Σ V T A = U \Sigma V^T A = U Σ V T
U U U A A A 직교 행렬 로, 좌측 특이벡터(left singular vector)를 포함합니다.Σ \Sigma Σ 대각행렬 로, 대각선 요소가 행렬 A A A 특이값(singular values) 입니다.V T V^T V T A A A 우측 특이벡터(right singular vector) 로 이루어진 행렬입니다.
SVD 분해의 과정
행렬 A T A A^T A A T A A A T A A^T A A T
SVD 분해를 하기 위해, 먼저 행렬 A A A 전치 행렬(transpose) 를 사용하여 A T A A^T A A T A A A T A A^T A A T 우측 특이벡터 와 좌측 특이벡터 를 구하는 데 사용됩니다.
A T A A^T A A T A n × n n \times n n × n 우측 특이벡터 를 구할 때 사용됩니다.
A A T A A^T A A T m × m m \times m m × m 좌측 특이벡터 를 구할 때 사용됩니다.
A T A A^T A A T A A A T A A^T A A T
A T A A^T A A T A A A T A A^T A A T 고유값(eigenvalue) 과 고유벡터(eigenvector) 를 구합니다.이 고유값들은 SVD에서 특이값 으로 사용되며, 고유벡터는 특이벡터 로 사용됩니다.
특이값(Singular Value) 구하기
A T A A^T A A T A A A T A A^T A A T 제곱근 을 구하면 특이값(singular value) 이 됩니다. 이 특이값은 대각 행렬 Σ \Sigma Σ 의 대각선에 위치하게 됩니다.특이값은 비음수가 항상 보장 되며, 행렬 A A A
우측 특이벡터(Right Singular Vectors) 구하기
A T A A^T A A T A 우측 특이벡터 가 됩니다. 이 고유벡터들을 모아서 직교 행렬 V V V 를 만듭니다.우측 특이벡터는 행렬 A A A 출력 공간 을 정의하는 벡터들입니다.
좌측 특이벡터(Left Singular Vectors) 구하기
A A T A A^T A A T 좌측 특이벡터 가 됩니다. 이 고유벡터들을 모아서 직교 행렬 U U U 를 만듭니다.좌측 특이벡터는 행렬 A A A 입력 공간 을 정의하는 벡터들입니다.
A = U Σ V T A = U \Sigma V^T A = U Σ V T
최종적으로 A A A
A = U Σ V T A = U \Sigma V^T A = U Σ V T
U U U m × m m \times m m × m 좌측 특이벡터 들로 구성됩니다.Σ \Sigma Σ m × n m \times n m × n 특이값 들이 대각선에 위치합니다.V T V^T V T n × n n \times n n × n 우측 특이벡터 들로 구성됩니다.
SVD의 응용
차원 축소 : PCA(Principal Component Analysis)와 밀접하게 연관된 SVD는 데이터의 주요 특징을 유지하면서 차원을 축소하는 데 사용됩니다.추천 시스템 : 넷플릭스 같은 서비스에서 SVD는 사용자 취향을 예측하는 데 중요한 역할을 합니다.이미지 압축 : 이미지를 표현하는 행렬을 SVD로 분해한 후, 일부 정보만 남겨두고 나머지를 버려 효율적인 압축이 가능합니다.
예시: 2x2 행렬의 SVD
행렬 A = [ 3 2 2 3 ] A = \begin{bmatrix} 3 & 2 \\ 2 & 3 \end{bmatrix} A = [ 3 2 2 3 ]
A T A A^T A A T A
A T A = [ 3 2 2 3 ] T [ 3 2 2 3 ] = [ 13 12 12 13 ] A^T A = \begin{bmatrix} 3 & 2 \\ 2 & 3 \end{bmatrix}^T \begin{bmatrix} 3 & 2 \\ 2 & 3 \end{bmatrix} = \begin{bmatrix} 13 & 12 \\ 12 & 13 \end{bmatrix} A T A = [ 3 2 2 3 ] T [ 3 2 2 3 ] = [ 1 3 1 2 1 2 1 3 ]
A A T A A^T A A T
A A T = [ 3 2 2 3 ] [ 3 2 2 3 ] = [ 13 12 12 13 ] A A^T = \begin{bmatrix} 3 & 2 \\ 2 & 3 \end{bmatrix} \begin{bmatrix} 3 & 2 \\ 2 & 3 \end{bmatrix} = \begin{bmatrix} 13 & 12 \\ 12 & 13 \end{bmatrix} A A T = [ 3 2 2 3 ] [ 3 2 2 3 ] = [ 1 3 1 2 1 2 1 3 ]
고유값 및 고유벡터 계산 :
고유값 λ 1 = 25 \lambda_1 = 25 λ 1 = 2 5 λ 2 = 1 \lambda_2 = 1 λ 2 = 1
고유벡터는 v 1 = [ 1 1 ] v_1 = \begin{bmatrix} 1 \\ 1 \end{bmatrix} v 1 = [ 1 1 ] v 2 = [ − 1 1 ] v_2 = \begin{bmatrix} -1 \\ 1 \end{bmatrix} v 2 = [ − 1 1 ]
특이값으로 대각행렬 Σ \Sigma Σ :Σ \Sigma Σ
Σ = [ 5 0 0 1 ] \Sigma = \begin{bmatrix} 5 & 0 \\ 0 & 1 \end{bmatrix} Σ = [ 5 0 0 1 ]
좌측 특이벡터 U U U :U U U A A T A A^T A A T
U = [ 1 2 − 1 2 1 2 1 2 ] U = \begin{bmatrix} \frac{1}{\sqrt{2}} & -\frac{1}{\sqrt{2}} \\ \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \end{bmatrix} U = [ 2 1 2 1 − 2 1 2 1 ]
우측 특이벡터 V V V :V V V A T A A^T A A T A
V = [ 1 2 − 1 2 1 2 1 2 ] V = \begin{bmatrix} \frac{1}{\sqrt{2}} & -\frac{1}{\sqrt{2}} \\ \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \end{bmatrix} V = [ 2 1 2 1 − 2 1 2 1 ]
최종 분해 :A A A
A = U Σ V T = [ 1 2 − 1 2 1 2 1 2 ] [ 5 0 0 1 ] [ 1 2 1 2 − 1 2 1 2 ] A = U \Sigma V^T = \begin{bmatrix} \frac{1}{\sqrt{2}} & -\frac{1}{\sqrt{2}} \\ \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \end{bmatrix} \begin{bmatrix} 5 & 0 \\ 0 & 1 \end{bmatrix} \begin{bmatrix} \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \\ -\frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \end{bmatrix} A = U Σ V T = [ 2 1 2 1 − 2 1 2 1 ] [ 5 0 0 1 ] [ 2 1 − 2 1 2 1 2 1 ]
결론
고윳값과 고유벡터는 행렬의 중요한 특성을 나타내며, 이를 활용해 대각화 와 닮은 행렬 등을 이해할 수 있습니다. 더 나아가 SVD 는 모든 행렬에 대해 적용 가능한 분해 방법으로, 데이터 분석, 차원 축소, 이미지 처리 등 인공지능과 데이터 과학 분야에서 널리 사용됩니다. 이 모든 개념들은 복잡한 행렬 연산을 단순화하고, 데이터를 효율적으로 처리하는 데 매우 중요한 역할을 합니다.
이번 시간에는 딥러닝에서 가장 많이 사용되는 선형대수 개념들을 정리해보았습니다. 오랜만에 수식이 많이 들어간 논문들을 읽으려니까 저도 좀 정리가 필요할거 같더라고요...🤗
도움이 되셨길 바라며 글을 마쳐보겠습니다!


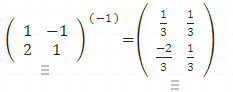
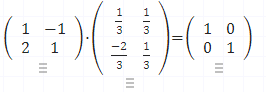


선형대수학 기초부터 다시 공부하고 좋은 글 잘읽었습니다..!! 도움이 많이 되었어요:)