
오늘도 RAG에 대한 자료를 찾아보던 중, KT DS의 김성우 기술혁신단장님께서 공유하신 RAG 관련 자료를 발견했습니다.
KT 사내 직원 RAG 교안이라는 말에 어떤 내용일지 궁금하여, 이번 포스팅에서는 해당 자료를 자세하게 공부하며 내용을 정리해보았으니 함께 살펴보시죠.

본 블로그 포스팅은 "KT DS의 김성우 기술혁신단장님께서 공유해주신 RAG 관련 자료를 바탕으로 작성된 자료입니다.
- 별도의 Reference를 달지 않은 사진 자료는 해당 강의 자료 내용을 발췌한 자료임을 미리 밝힙니다.
Chapter 1: Overview of RAG
1. Discriminative vs. Generative AI
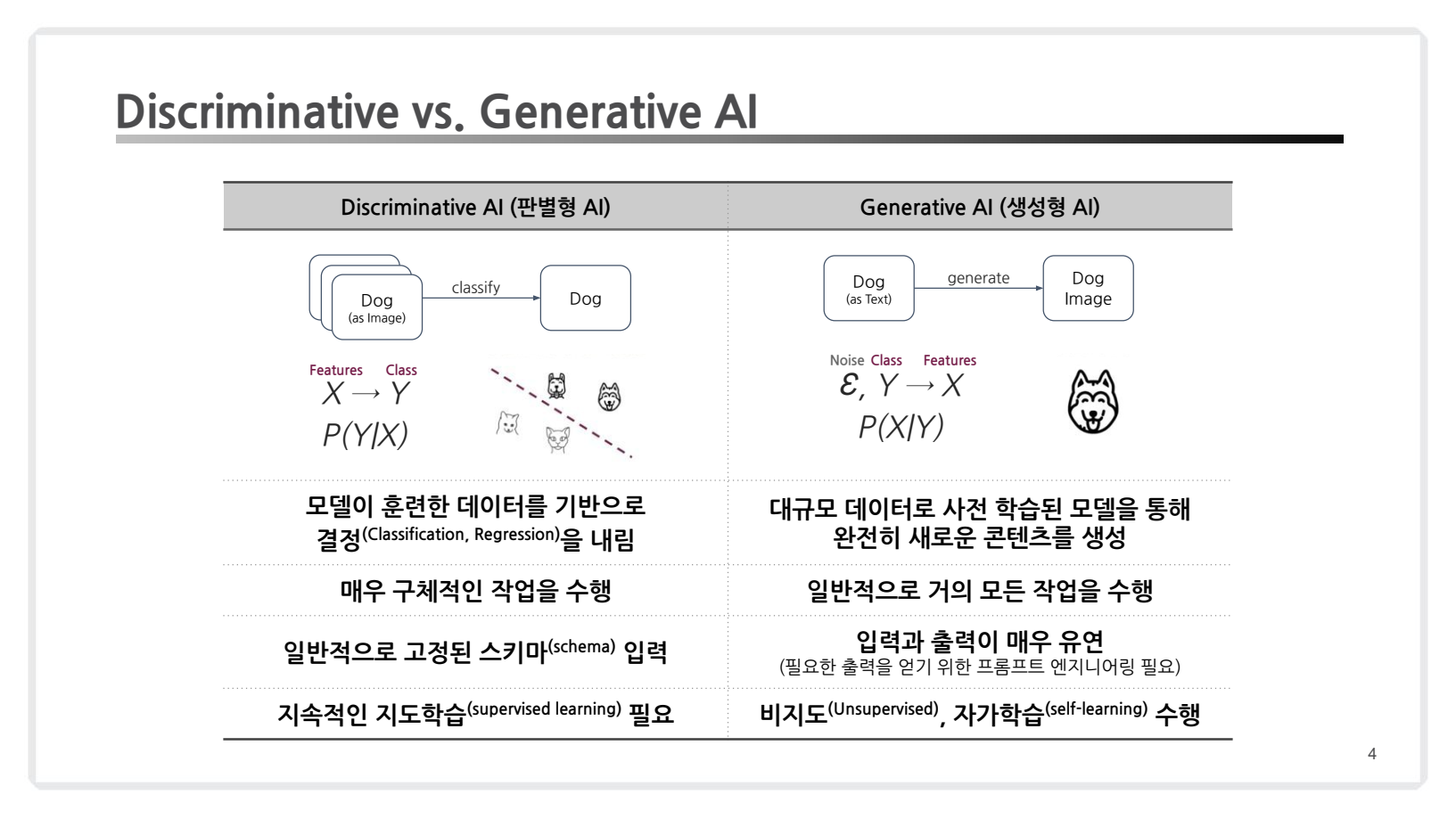
- Discriminative AI =>
판별형 AI- 분류(Classification) 및 회귀(Regression) 등 전통적인 머신러닝 작업에 초점을 맞춤.
- 일반적으로 고정된 스키마 입력. (입출력이 한정적임)
- 특징: 지도 학습(Supervised Learning)
- Generative AI =>
생성형 AI- 대규모 데이터로 사전 학습된 모델을 통해 완전히 새로운 데이터를 생성하는 데 중점을 둔 기술.
- 언어 생성, 이미지 생성 등 다양한 창의적 작업 가능. (입출력이 유연함)
- 특징: 비지도학습(unsupervised) , 자가학습(self-supervised)
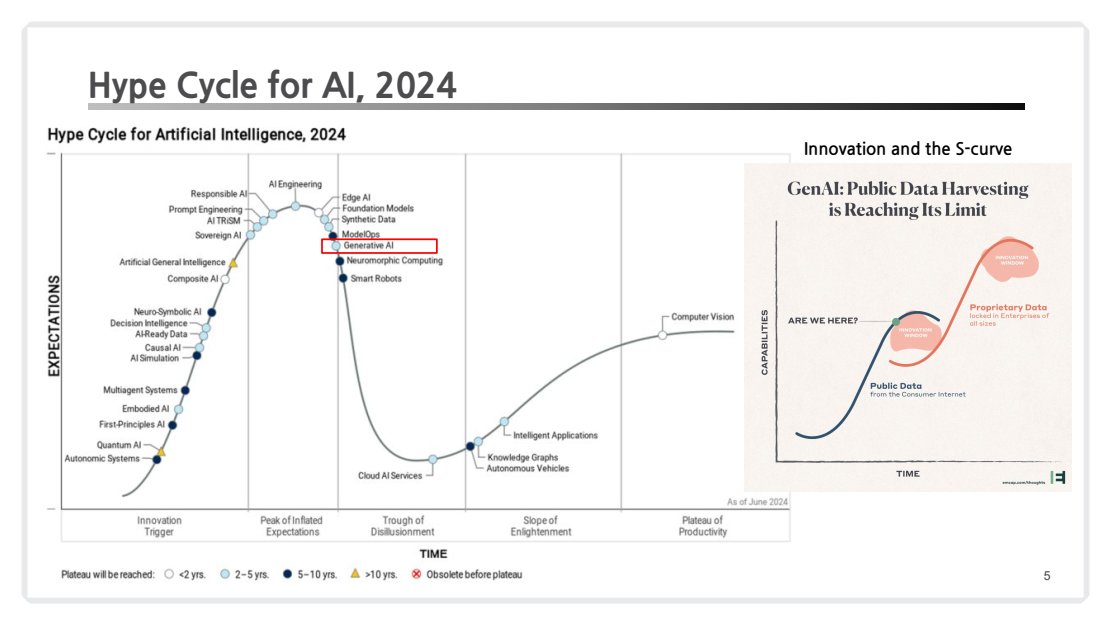
2. AI Hype Cycle
-
하이프 사이클(Hype Cycle)
-
신기술의 대중적 열광 및 채택 단계를 설명하는 가트너의 모델.
-
주요 단계:
- 기술 촉발 단계: 기술 소개.
- 과도한 기대의 정점: 과장된 기대감 형성.
- 환멸 단계: 실질적 한계에 대한 인식 증가.
- 계몽 단계: 실용적 사용 사례 등장.
- 생산성 단계: 성숙된 기술로 자리잡음.
-
현재 생성형 AI는 과도한 기대의 정점에서 환멸 단계로 진입 중임.
-
3. LLM & 한계
-
LLM(Large Language Models)이란?
- 대규모 데이터셋을 활용하여 훈련된 언어 모델로, 인간의 언어를 이해하고 생성하는 데 최적화된 모델.
- Generative AI 기술의 핵심으로, OpenAI의 GPT 시리즈, Google의 BERT, Hugging Face의 Transformers 등이 대표적.
- 언어 처리(자연어 처리, 음성 인식, 번역 등)와 관련된 다양한 작업에 적용 가능
-
LLM(Large Language Models)의 특징
- 대규모 학습 데이터:
- 수백억~수조 개의 토큰으로 이루어진 데이터로 학습.
- 웹 데이터, 논문, 소셜 미디어 등 광범위한 데이터 출처 활용.
- Generative AI의 핵심:
- 새로운 텍스트 생성, 질문 응답(QA), 요약, 번역 등 언어 생성 작업 수행.
- 창의적이고 유연한 응답 가능.
- 제로샷(Zero-shot) 추론 가능:
- 추가 학습 없이도, 사전 학습된 지식을 활용해 새로운 작업을 수행.
- 프롬프트만으로도 특정 도메인에서 문제 해결 가능.
- 다양한 작업에서의 적용성:
- 텍스트 분류, 감정 분석, 대화형 AI, 코드 생성, 의료 데이터 분석 등 다양한 도메인에서 활용.
- 기술 발전의 중심:
- 트랜스포머(Transformer) 구조를 활용한 학습.
- GPU/TPU 등의 하드웨어와 병렬처리 기술의 발전으로 훈련 효율 향상.
- 대규모 학습 데이터:

- LLM(Large Language Models)의 한계
- 도메인 특화 능력 부족:
- 학습 데이터가 일반적인 정보에 초점이 맞춰져 있음.
- 특정 산업(의료, 법률 등)이나 최신 데이터에 대한 이해 부족.
- 정보의 최신성 부족:
- 학습 시점 이후의 새로운 지식 반영 어려움.
- 정적 데이터 기반으로 훈련되므로 실시간 정보와는 격차 발생.
- 환각(Hallucination):
- 모델이 존재하지 않는 사실을 생성하거나 잘못된 정보를 신뢰도 있게 제공.
- 생성 결과가 신뢰성을 보장하지 않음.
- 추론 능력 부족:
- LLM은 추론의 깊이가 부족하여 논리적이거나 복잡한 문제 해결에 한계가 있음.
- 수학적 문제 풀이나 복잡한 논리 구조를 따르는 질문에 대해 정확히 답하지 못할 때가 많음.
- LLM은 논리적 체계보다는 패턴 인식에 의존하기 때문.
- 지식 매개변수화(parameterizing knowledge) 효율성이 낮음:
- LLM은 모든 지식을 모델의 가중치(parameter)에 압축 저장함.
- 이는 지식을 업데이트하거나 확장하는 데 비효율적임(어려움)
- 도메인 특화 능력 부족:
4. LLM 한계 극복
LLM 한계 극복 전략에서 다루는 주요 요소들은 각각 장단점이 있으며, 특정 상황에 적합하게 활용될 수 있습니다.
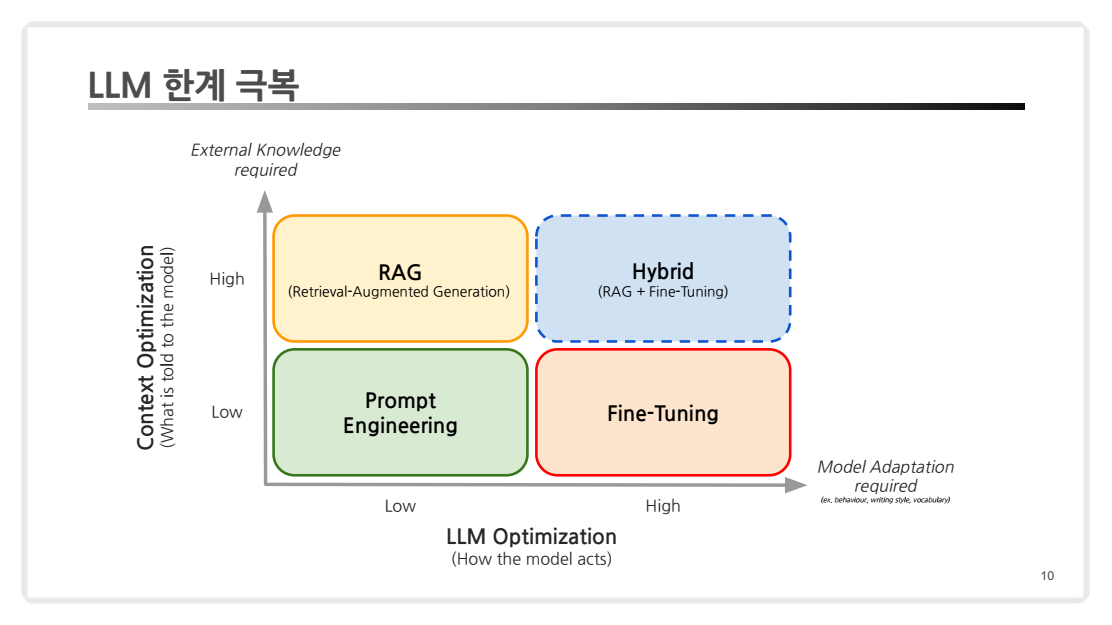
4.1 Prompt Engineering
-
프롬프트 엔지니어링
-
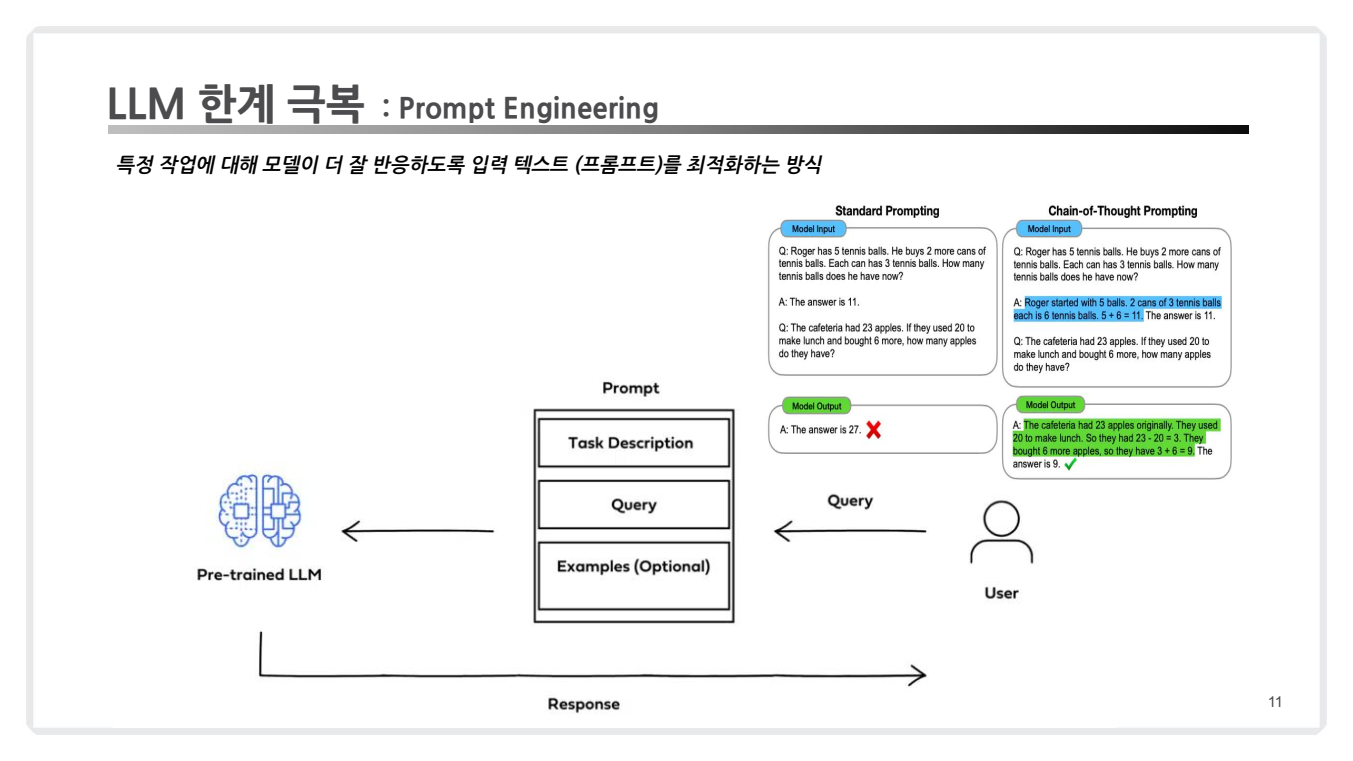
정의: 프롬프트 엔지니어링은 LLM의 성능을 개선하기 위해 입력 텍스트를 구조화하거나 재구성하는 과정을 말합니다. 이는 소프트웨어적 접근 방식으로, 모델의 가중치를 변경하지 않으면서도 성능을 크게 향상시킬 수 있는 방법입니다. -
예시: Standard Prompting(기본 질의)와 Chain-of-Thought Prompting(사고의 흐름)을 비교해보면, 후자는 복잡한 문제를 단계별로 해결하도록 유도하여 정확한 답변을 도출합니다. -
한계: 도메인 지식이나 복잡한 데이터를 처리하는 데 한계가 있으며, 잘 설계된 프롬프트 없이 결과가 일관적이지 않을 수 있습니다.
-
4.2 RAG (Retrieval-Augmented Generation)
-
RAG 개념
-
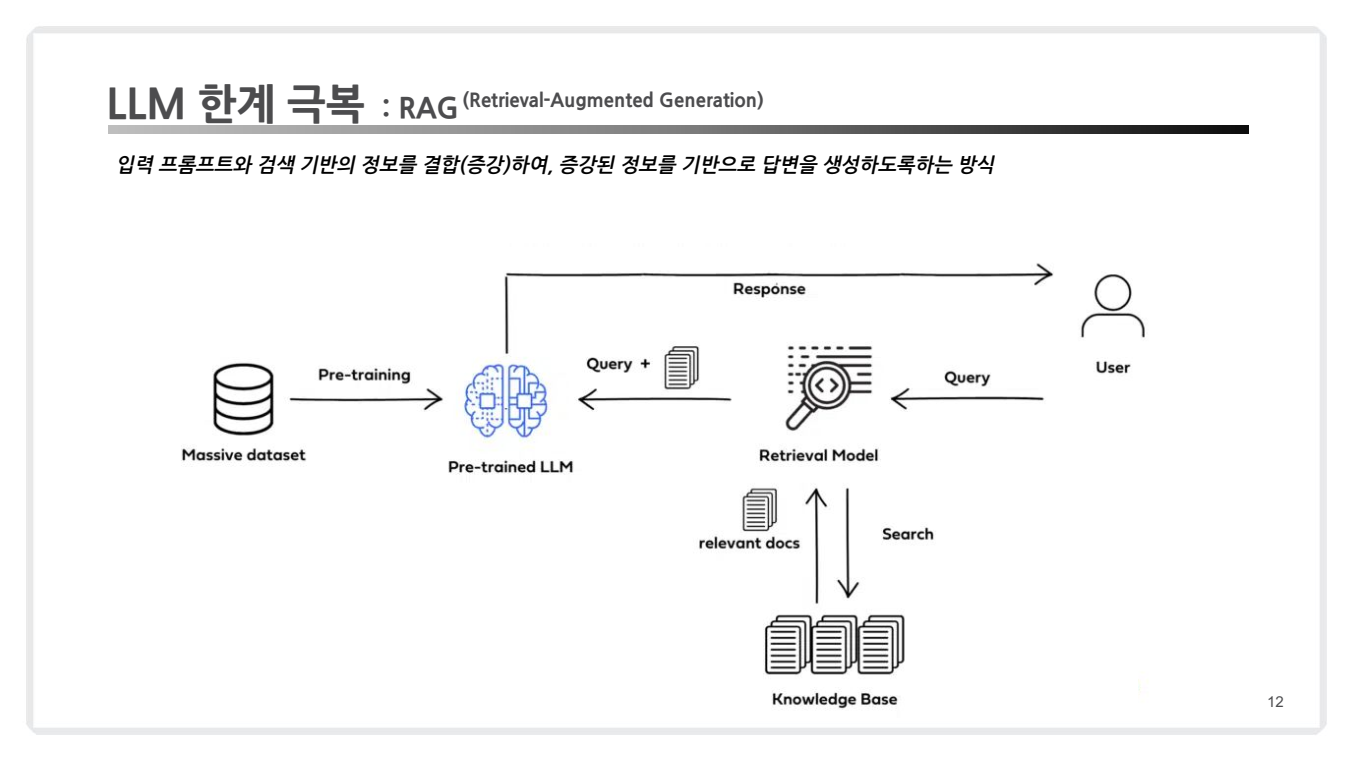
정의: RAG는 외부 지식베이스(Vector Database)와 LLM을 결합하여 더 강력한 답변을 제공합니다. 검색된 정보를 기반으로 응답을 생성함으로써 최신 데이터 반영이 가능하며, LLM이 자체적으로 처리할 수 없는 지식의 공백을 메웁니다. -
장점:- 정보 업데이트가 쉽습니다.
- 데이터베이스를 업데이트함으로써 즉각적인 지식 확장이 가능합니다.
- 다양한 외부 데이터(예: 문서, PDF, 데이터셋) 활용에 강점이 있습니다.
-
단점:- 검색 성능에 따라 최종 결과가 좌우됩니다.
- 검색 품질이 낮을 경우, 생성된 응답의 품질도 떨어질 수 있습니다.
- 검색과 생성 단계를 결합하다 보니 시간 지연(latency)이 발생할 가능성이 있습니다.
-
4.3 Fine-Tuning
-
Fine-Tuning
-
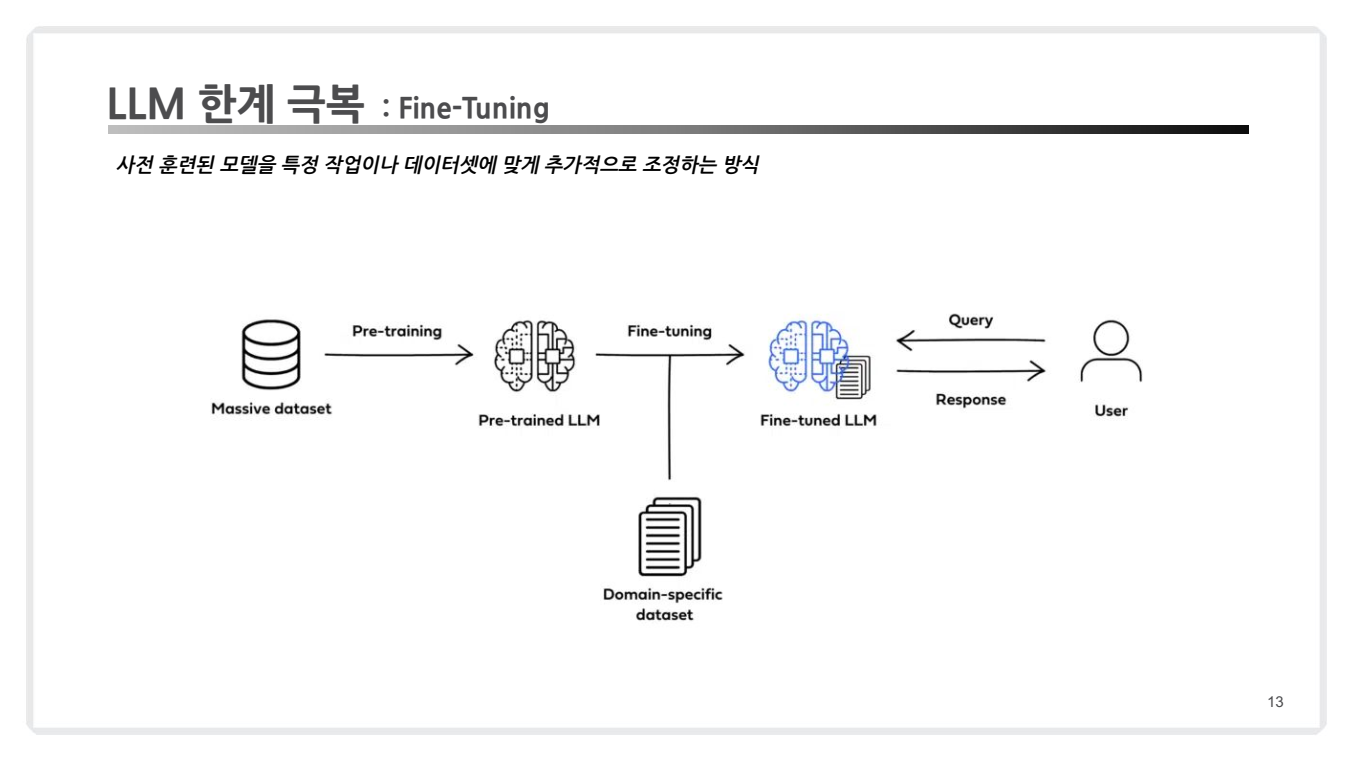
정의: Fine-Tuning(미세 조정)은 사전 학습된 대규모 언어 모델(LLM)을 특정 도메인이나 작업에 맞게 다시 학습시키는 과정입니다.- 이를 통해 모델의 가중치(Weights)를 조정하여, 사전 학습된 일반적인 언어 이해 능력을 특정한 용도에 맞게 최적화합니다.
-
예시: 의료 분야에서 특화된 진단 데이터를 사용하여 Fine-Tuning을 진행하면, 모델이 더 전문적이고 신뢰할 수 있는 의료 관련 답변을 생성할 수 있습니다. -
장점:- 도메인 전문성 극대화: Fine-Tuning을 통해 특정 도메인(예: 법률, 의료, 금융 등)에 맞는 응답을 생성할 수 있습니다.도메인 전문성을 극대화할 수 있습니다.
- 사용 사례 최적화: Fine-Tuning은 특정 작업(예: 감정 분석, 요약 생성, 고객 지원)에 필요한 데이터로 모델을 학습시켜 성능을 최적화합니다.
-
단점:-
높은 학습 비용: Fine-Tuning은 모델 전체의 가중치를 학습시키기 때문에, GPU/TPU와 같은 대규모 계산 자원이 필요하며, 학습 시간도 많이 소요됩니다.
-
유연성 부족: Fine-Tuning된 모델은 특정 데이터나 도메인에 지나치게 최적화되는 경향이 있어, 새로운 데이터나 빠르게 변하는 환경(예: 실시간 뉴스)에 적응하기 어렵습니다.
-
과적합 위험: 학습 데이터에 지나치게 의존할 경우, Fine-Tuning된 모델이 일반화 능력을 잃어 과적합 문제를 일으킬 수 있습니다.
-
-
💌 RAG vs Fine-Tuning
| 비교 항목 | RAG | Fine-Tuning |
|---|---|---|
| 특징 | 외부 데이터(예: 문서, 데이터베이스)를 검색하여 LLM이 활용하도록 설계. | 모델 자체를 특정 작업에 맞게 조정하여 도메인에 특화된 성능 제공. |
| 비용 | 비교적 낮음. 검색 인프라 구축에 따라 초기 비용은 발생하나, 모델 재학습 비용 없음. | 데이터 준비 및 모델 재학습에 상당한 비용과 시간이 소요됨. |
| 적용 가능성 | 자주 업데이트되는 동적 데이터나 실시간 정보에 적합. | 상대적으로 정적이고 구조화된 데이터 환경에서 적합. |
| 데이터 관리 | 데이터베이스 업데이트를 통해 쉽게 지식 확장 가능. | 데이터셋 생성 및 레이블링이 필요하며, 데이터 업데이트 시 재학습 필요. |
| 모델 수정 필요성 | 모델 가중치를 수정하지 않음. 외부 데이터베이스를 통한 지식 확장에 의존. | 모델 가중치를 직접 수정하여 특정 작업이나 도메인에 최적화된 모델 생성. |
| 성능 최적화 | 검색 단계의 품질에 따라 결과가 달라짐. 검색 시스템 개선으로 성능 향상 가능. | 모델 성능은 데이터 품질과 학습 설정에 따라 결정되며, 도메인 특화된 우수한 성능 제공. |
| 지연 시간 | 검색 및 생성 단계를 거쳐야 하므로 응답 시간이 길어질 수 있음. | 사전 학습된 모델로 바로 응답 가능하여 응답 속도가 빠름. |
| 유지 관리 | 데이터베이스 업데이트만으로 유지 보수 가능. | 데이터셋의 업데이트 및 모델 재학습이 필요하여 유지 관리 비용이 높음. |
| 윤리적 고려사항 | 외부 데이터 활용으로 인해 개인 정보 보호 및 데이터 소스 신뢰성이 중요. | 민감한 데이터 포함 시, 모델이 이를 학습하면서 개인정보 문제를 야기할 가능성 존재. |
| 환각(hallucination) | 검색된 정보에 의존하기 때문에 환각 가능성이 낮음. | 특정 도메인에서 학습되지 않은 경우, 부정확하거나 환각된 정보를 생성할 가능성 존재. |
| 도메인 적합성 | 다중 도메인 또는 새로운 데이터 환경에 적합. | 특정 도메인에 최적화된 데이터셋으로 높은 전문성 제공. |
| 구현 난이도 | 검색 시스템과의 통합이 요구되므로 초기 구축이 다소 복잡할 수 있음. | 모델 학습 및 데이터셋 준비 과정이 복잡하며, 계산 리소스 요구량이 높음. |
| 투명성(Explainability) | 검색된 데이터와 답변을 연결 가능하므로 결과의 추적 및 해석이 용이. | 모델이 내린 결론을 설명하기 어렵고, 블랙박스 특성을 가짐. |
| 활용 사례 | FAQ 시스템, 최신 뉴스 응답, 고객 지원 등 실시간 정보 제공 서비스에 적합. | 의료, 법률, 과학 연구 등 고도로 특화된 전문 분야에 적합. |
4.4 Fine-Tuning - PEFT (Parameter-Efficient Fine-Tuning)
효율적인 Fine-Tuning의 대안
-
PEFT 개념
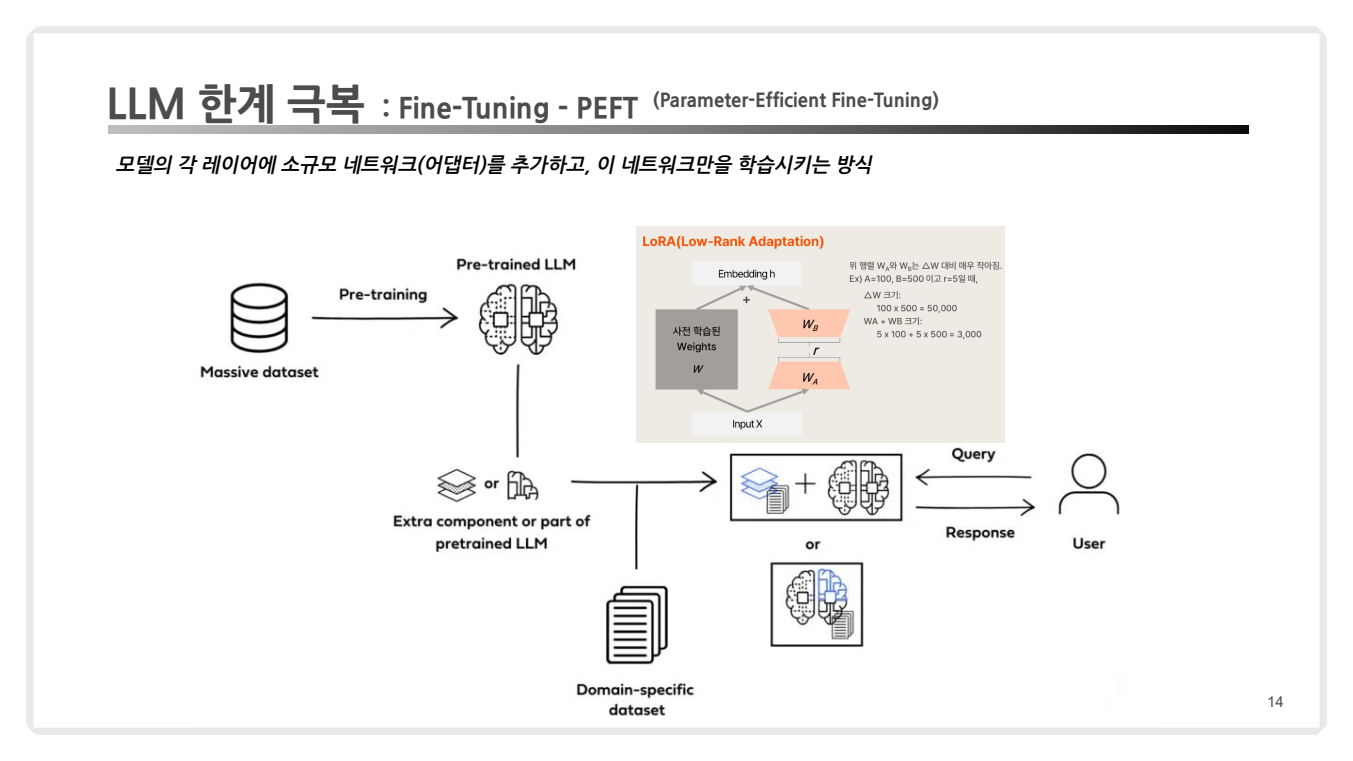
정의:PEFT(Parameter-Efficient Fine-Tuning)는 기존 Fine-Tuning의 한계를 극복하기 위해 제안된 방법으로, 모델 전체를 조정하지 않고 일부 파라미터만 업데이트하여 학습하는 기술입니다.- 기존 Fine-Tuning과는 달리, 모델의 기존 가중치를 대부분 고정한 상태에서 추가적인 학습 가능한 파라미터(모듈)를 삽입하여 학습하는 방식입니다. 이를 통해 필요한 연산량을 줄이고, 효율적인 학습이 가능하도록 설계된 기법입니다.
- 중요한 점은, 단순히 특정 레이어를 업데이트하거나 동결(Freeze)하는 것에 그치는 것이 아니라, 새로운 파라미터를 추가적으로 도입하여 학습을 진행한다는 것입니다. 이로 인해 Fine-Tuning의 고비용과 높은 자원 요구를 크게 줄일 수 있습니다.
-
PEFT 특징 : PEFT의 주요 특징은 다음과 같습니다:
-
기존 모델 유지: 사전 학습된 모델의 대부분의 파라미터는 고정된 상태로 유지됩니다. -
새로운 파라미터 추가: 모델에 적은 수의 새로운 학습 가능한 파라미터를 추가합니다. -
효율적인 학습: 추가된 파라미터만 학습하여 계산 비용과 저장 공간을 크게 줄입니다. -
성능 유지: 전체 미세 조정과 비슷한 성능을 달성하면서도 자원 사용을 최소화합니다. -
다양한 구현 방법: PEFT는 다음과 같은 방법으로 구현됩니다:
-
LoRA(Low-Rank Adaptation):- 기존 모델 가중치(예: 트랜스포머 레이어의 Query 및 Value 행렬)를
저랭크 행렬로 분해하여 학습 가능한 작은 매개변수를 추가. - 주요 가중치는 변경되지 않고, 저랭크 행렬만 학습됨.
- 메모리 사용량을 줄이면서 Fine-Tuning 성능에 근접한 결과를 도출.
- 기존의 가중치 를 그대로 둔 채, 형태로 표현합니다.
- 여기서:
- : 고정된 기존 모델의 가중치
- : 학습 가능한 작은 저랭크 행렬
- 여기서:
- 기존 모델 가중치(예: 트랜스포머 레이어의 Query 및 Value 행렬)를
-
Adapter:- 트랜스포머 아키텍처의 레이어 사이에 작은 어댑터 모듈을 추가.
- 어댑터는 주로 추가적인
Feedforward Layer또는Bottleneck Layer로 구성됩니다.- 예를 들어, 기존 레이어의 출력 에 대해:
- 과 은 학습 가능한 작은 가중치 행렬.
- 예를 들어, 기존 레이어의 출력 에 대해:
- 기존 모델의 구조를 크게 변경하지 않으면서 특정 작업에 필요한 새로운 기능을 추가 학습.
- 일반적으로 학습 가능한 파라미터 수가 매우 적음.
-
Prefix Tuning:- 입력 데이터 앞에 학습 가능한 프리픽스 텐서를 추가하여 모델이 새로운 정보를 학습하도록 유도.
- 프리픽스 텐서는 입력과 독립적으로 학습되며, 트랜스포머의 각 레이어의 어텐션 메커니즘에 영향을 줍니다.
- 예를 들어, 입력 에 대해, 새로운 입력 는:
- : 학습 가능한 프리픽스 텐서.
- 예를 들어, 입력 에 대해, 새로운 입력 는:
- 기존 가중치는 변경되지 않으며, 프리픽스 텐서만 학습.
-
-
장점:- Fine-Tuning 대비 적은 계산 자원을 사용하며, 더 적은 데이터로도 학습이 가능합니다.
- 대규모 모델에 적용할 때 효율적입니다.
-
단점:- 특정 파라미터만 학습하다 보니, 복잡한 도메인에 대한 학습 성능이 제한될 수 있습니다.
-
💌 Traditional Fine-Tuning vs. Parameter-Efficient Fine-Tuning
- PEFT(Parameter-Efficient Fine-Tuning)는 전통적인 Fine-Tuning과 비교해 효율성을 강조한 접근 방식으로, 대규모 모델을 학습시키는 데 있어 "
복잡성과 비용" 그리고 "성능" 측면에서 LLM 접근 방식을 비교하는 지표를 제공합니다.
| 항목 | Fine-Tuning | PEFT |
|---|---|---|
| 학습 파라미터 수 | 모델의 모든 파라미터 업데이트 | 일부 파라미터만 업데이트 |
| 계산 비용 | 높음 | 낮음 |
| 유연성 | 특정 도메인에 한정 | 다양한 작업에 빠르게 적용 가능 |
| 학습 시간 | 오래 걸림 | 비교적 빠름 |
| 적용 가능한 작업 | 복잡한 도메인 작업 | 적은 데이터로 빠르게 적용해야 하는 작업 |
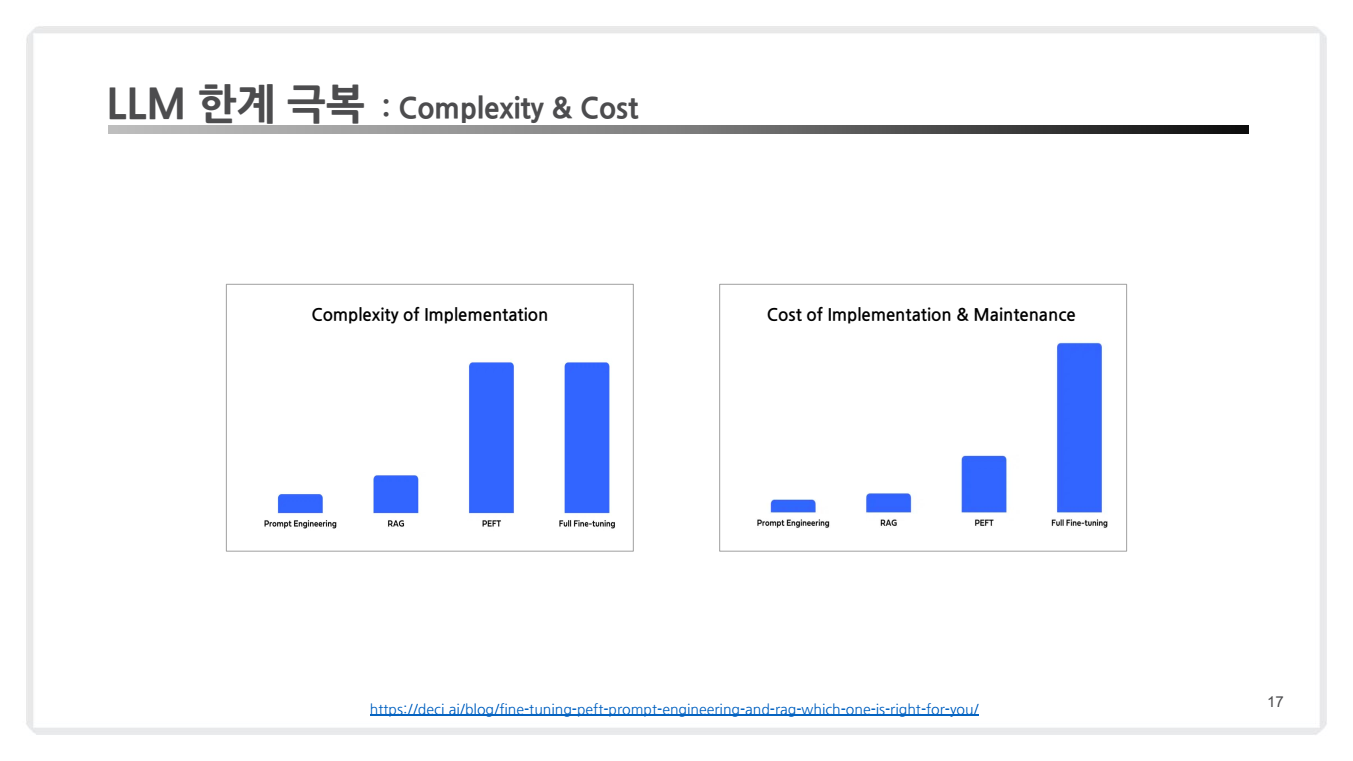
위 장표를 살펴보면 아래와 같이 해석해볼 수 있습니다.
Complexity of Implementation (구현 복잡성)
- Prompt Engineering: 가장 간단한 방식으로, LLM의 입력값인 프롬프트를 조정하여 원하는 결과를 얻는 방식입니다.
- 모델을 수정하지 않아 복잡성이 매우 낮습니다.
- RAG: RAG는 검색(Augmentation)과 생성(Generation)을 결합하기 때문에 프롬프트 엔지니어링보다는 복잡합니다.
- 하지만, 모델 자체를 미세 조정하지 않으므로 상대적으로 간단합니다.
- PEFT: 일부 파라미터만 학습시키는 PEFT는 RAG보다 복잡하지만, 완전한 Fine-Tuning에 비해서는 간단합니다.
- 그러나 추가 파라미터 삽입이나 LoRA와 같은 기술 설정이 필요해 구현 난이도가 높아질 수 있습니다.
- Full Fine-Tuning: 모든 모델 파라미터를 조정해야 하므로 가장 높은 복잡성을 가집니다.
- 특히 대규모 모델에서는 계산 리소스와 설정 복잡도가 매우 높습니다.
Cost of Implementation & Maintenance (구현 및 유지 비용)
- Prompt Engineering: 모델을 재학습할 필요가 없어 비용이 가장 낮습니다.
- 입력 프롬프트를 설계하는 데만 리소스가 소요됩니다.
- RAG: 검색 인프라 및 외부 데이터베이스 관리 비용이 있지만, Fine-Tuning에 비해 유지 비용이 낮습니다.
- PEFT: 계산 리소스를 적게 사용하고 일부 파라미터만 학습하므로 비용이 중간 수준입니다.
- 그러나 LoRA나 Adapter 추가로 인해 초기 설정 비용이 들 수 있습니다.
- Full Fine-Tuning: 모든 파라미터를 학습시키기 때문에 데이터 처리, 계산 리소스, 유지 보수 비용이 가장 높습니다.
- 특히, 도메인 데이터가 자주 변경되면 지속적인 업데이트가 필요하여 비용이 급증할 수 있습니다.

위 장표를 살펴보면 아래와 같이 해석해볼 수 있습니다.
Avoiding Hallucinations (할루시네이션(환각) 최소화)
- Prompt Engineering: 기본적인 프롬프트 조정으로는 환각 문제를 해결하기 어렵습니다.
- RAG: 외부 지식베이스를 사용하여 최신 정보 기반으로 응답하므로 환각 문제를 효과적으로 줄일 수 있습니다.
- PEFT: 학습된 데이터에 기반하여 작업을 수행하므로 RAG보다 환각 문제 해결에 약간 부족할 수 있습니다.
- Full Fine-Tuning: 특정 도메인 데이터로 학습하여 환각 문제를 최소화할 수 있습니다.
Domain-Specific Terminology (도메인 특화 용어)
- Prompt Engineering: 특화된 용어를 이해하거나 생성하는 데 한계가 있습니다.
- RAG: 외부 데이터베이스에서 검색된 정보를 활용해 도메인 용어를 이해하거나 사용할 수 있습니다.
- PEFT: 특정 도메인에 맞춰 일부 파라미터를 조정하므로 도메인 특화 성능이 좋습니다.
- Full Fine-Tuning: 전체 모델을 도메인 데이터로 학습하기 때문에 도메인 용어를 가장 잘 처리할 수 있습니다.
Up-to-date Response (최신 응답 제공)
- Prompt Engineering: 모델이 훈련된 데이터에 의존하므로 최신 정보를 반영하기 어렵습니다.
- RAG: 외부 지식베이스를 통해 최신 정보를 검색하여 즉각 반영할 수 있습니다.
- PEFT: 최신 데이터를 추가로 학습할 수 있지만, Fine-Tuning과 비슷한 한계를 가질 수 있습니다.
- Full Fine-Tuning: 사전 학습된 데이터 기반으로 응답하기 때문에 최신 정보를 반영하기 어렵습니다.
Transparency & Interpretability (투명성 및 해석 가능성)
- Prompt Engineering: 단순한 설정이므로 해석이 용이합니다.
- RAG: 검색된 정보 출처를 추적할 수 있어 투명성과 해석 가능성이 매우 높습니다.
- PEFT: 일부 파라미터만 학습하므로 해석 가능성이 낮을 수 있습니다.
- Full Fine-Tuning: 블랙박스 성격이 강하며, 학습 결과를 해석하거나 투명성을 확보하기 어렵습니다.
5. Emerging Tech: Agentic Workflow

-
Agentic Workflow
-
AI Agentic Workflow는 복잡한 작업을 여러 개의 특화된 에이전트로 분할하여 처리하는 AI 시스템 구조를 말합니다.
-
이는 단일 AI 모델이 모든 작업을 처리하는 기존 방식과 달리, 각 단계를 전문화된 에이전트가 담당함으로써 더욱 효율적이고 정확한 결과를 도출할 수 있는 접근 방식입니다.
-
Stanford 앤드류 응 교수는
AI Agentic Workflow를 다음과 같이 정의하고 있습니다:- 반복적인 프로세스: LLM이 문서를 여러 번 반복하여 작업할 수 있게 합니다.
- 자체 평가 및 개선: AI가 자신의 출력을 자체 평가하고 개선할 수 있는 능력을 갖습니다.
- 협업 시스템: 여러 AI 시스템이 서로 소통하고 균형을 맞추며 협력하여 복잡한 작업을 수행하고 문제를 해결합니다
-
6. LLM 에이전트 디자인 패턴
-
LLM 에이전트 패턴
-
LLM 기반 에이전트의 다양한 설계 방식은 특정 문제를 해결하기 위한 최적의 워크플로우를 제공합니다.

-
주요 디자인 패턴:
리플렉션(Reflection): AI가 자체적으로 작업을 검토하고 개선 방안을 마련합니다.도구 사용(Tool Use): AI가 웹 검색, 코드 실행 등의 도구를 활용하여 정보를 수집하고 데이터를 처리합니다.계획(Planning): AI가 목표 달성을 위한 다단계 계획을 수립하고 실행합니다.다중 에이전트 협업(Multi-Agent Collaboration): 여러 AI 에이전트가 협력하여 작업을 수행합니다.
-
주요 디자인 패턴 상세:
(1) Reflection Pattern
- 개념:
- LLM의 초기 응답을 기반으로 결과를 평가하고, 이를 수정하여 반복적으로 개선.
- LLM이 자체 검토와 피드백을 통해 품질을 높임.
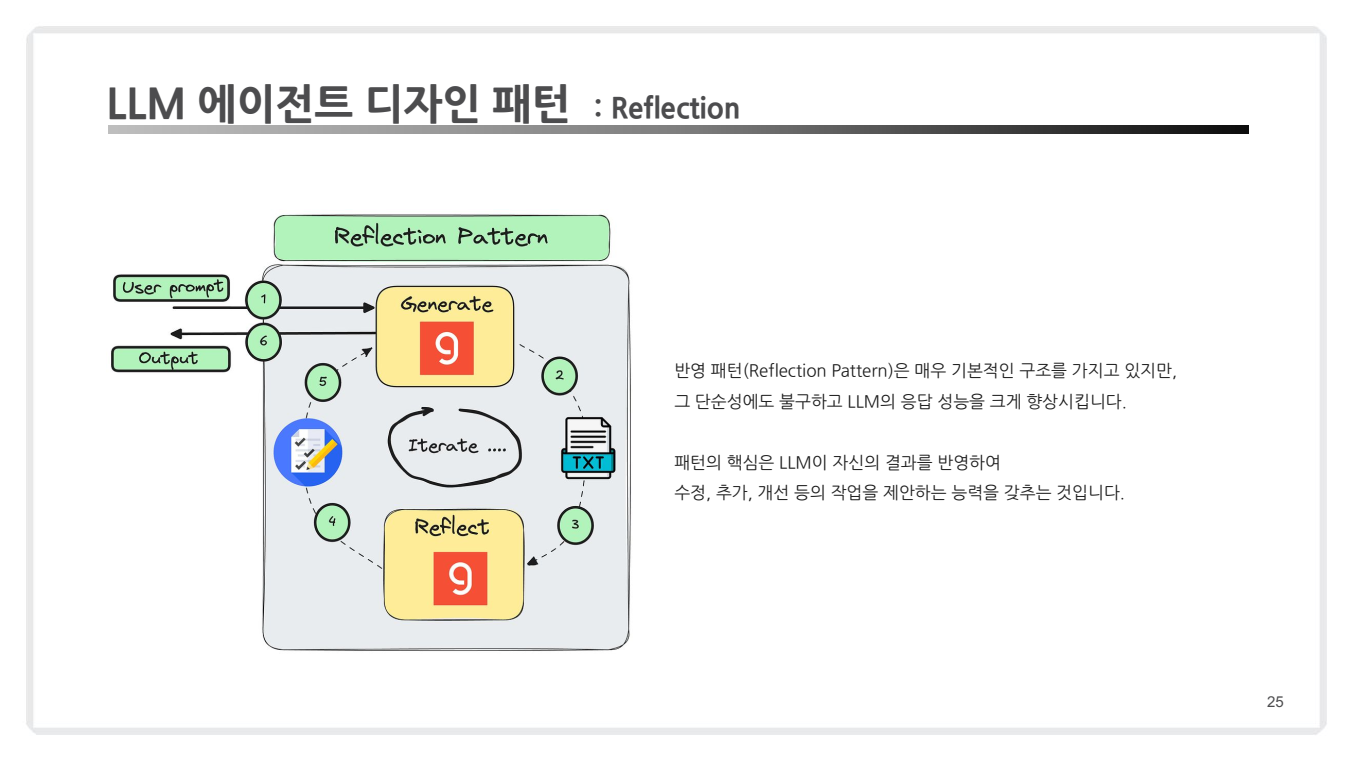
- 예시:
- 답변의 논리적 오류를 식별하고 스스로 수정.
- 텍스트 생성 후 문법, 논리 및 의미를 재검토.
- 적용 사례:
- Self-Refine: Madaan et al.(2023)의 연구에서 반복적인 자체 피드백을 통해 응답 품질 향상.
- Reflexion: 강화학습을 사용하여 언어 모델의 성능 개선.
(2) Tool Use Pattern
- 개념:
- LLM 자체 정보가 불충분할 경우 외부 도구(API, 데이터베이스 등)를 활용하여 정교한 응답 생성.
- 검색, 계산, 분석 도구 등 외부 리소스에 의존.
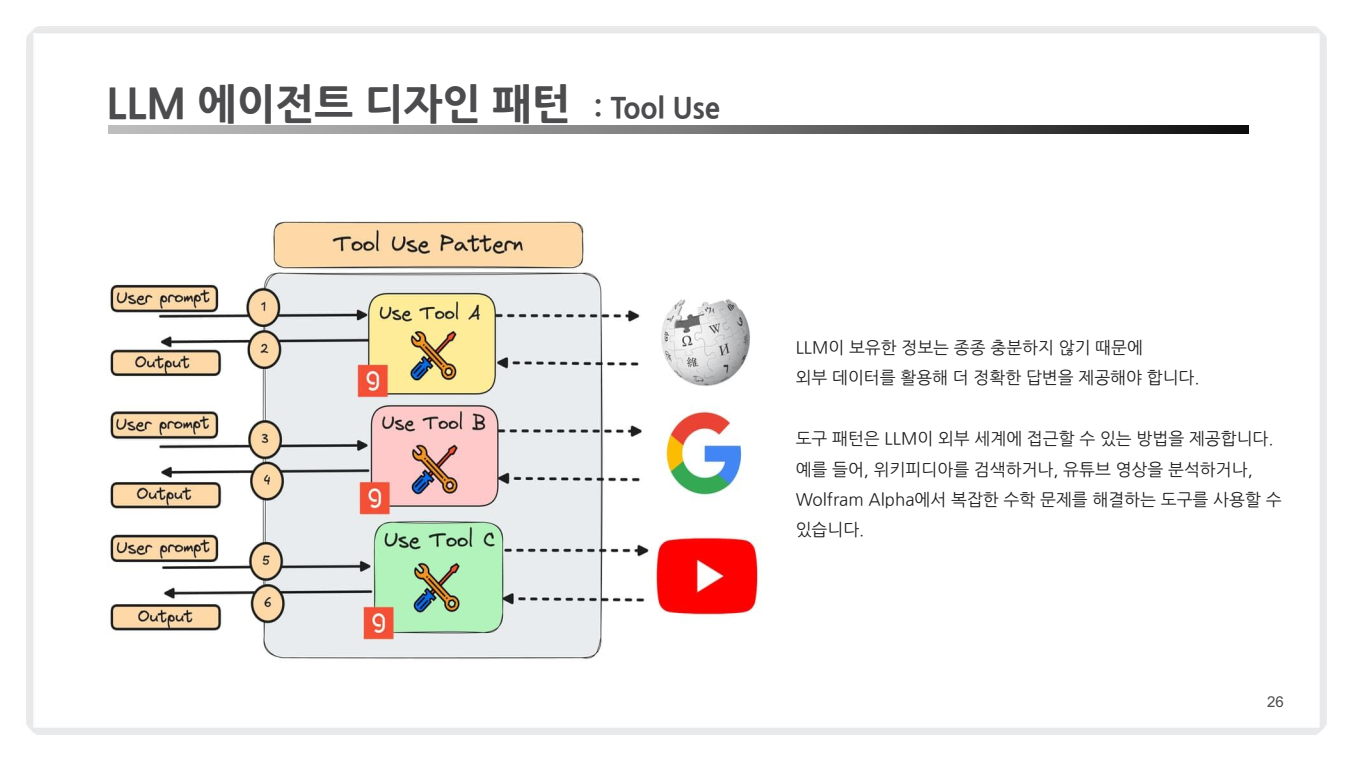
- 예시:
- Google 검색을 통해 최신 정보 확인.
- Wolfram Alpha를 사용해 수학 문제 해결.
- YouTube 분석 도구를 사용해 동영상 정보 추출.
- 적용 사례:
- Gorilla: API와 연계하여 정밀한 정보 검색 수행.
- MM-REACT: 멀티모달 데이터 처리 및 실행을 지원하는 시스템.
(3) Planning Pattern
- 개념:
- 작업을 세분화하여 단계적으로 수행하고 각 단계에서 피드백을 반영.
- 복잡한 작업도 체계적으로 분할해 해결.
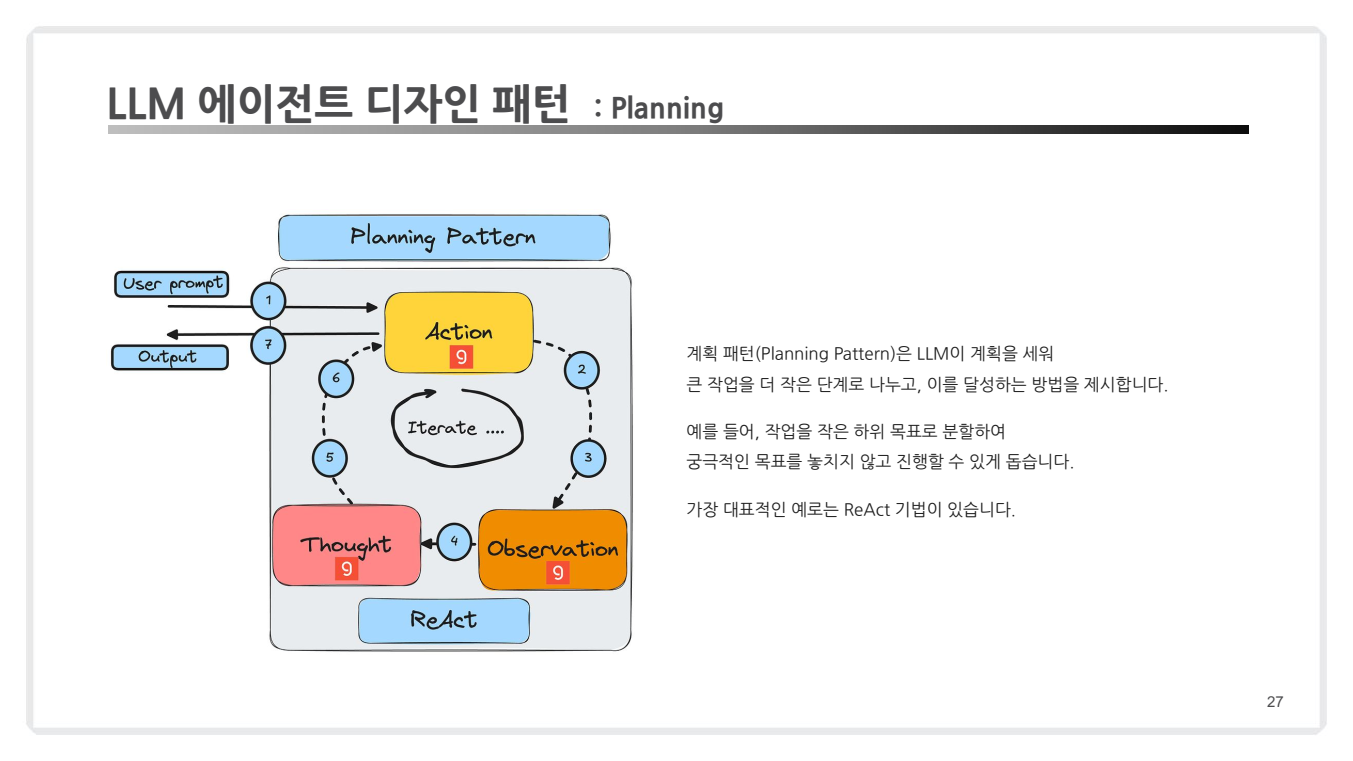
- 예시:
- ReAct(Reasoning + Acting) 기법을 통해 추론과 행동을 반복하며 목표 달성.
- 대규모 계획(예: 보고서 작성)을 세분화한 후 각 부분을 처리.
- 적용 사례:
- HuggingGPT: 다양한 AI 모델을 조율하여 복잡한 작업 처리.
(4) Multi-Agent Collaboration
- 개념:
- 여러 에이전트가 서로 협력하며 역할을 분담하여 작업을 효율적으로 수행.
- 각 에이전트는 고유의 기능(예: 데이터 수집, 분석, 실행)을 담당.
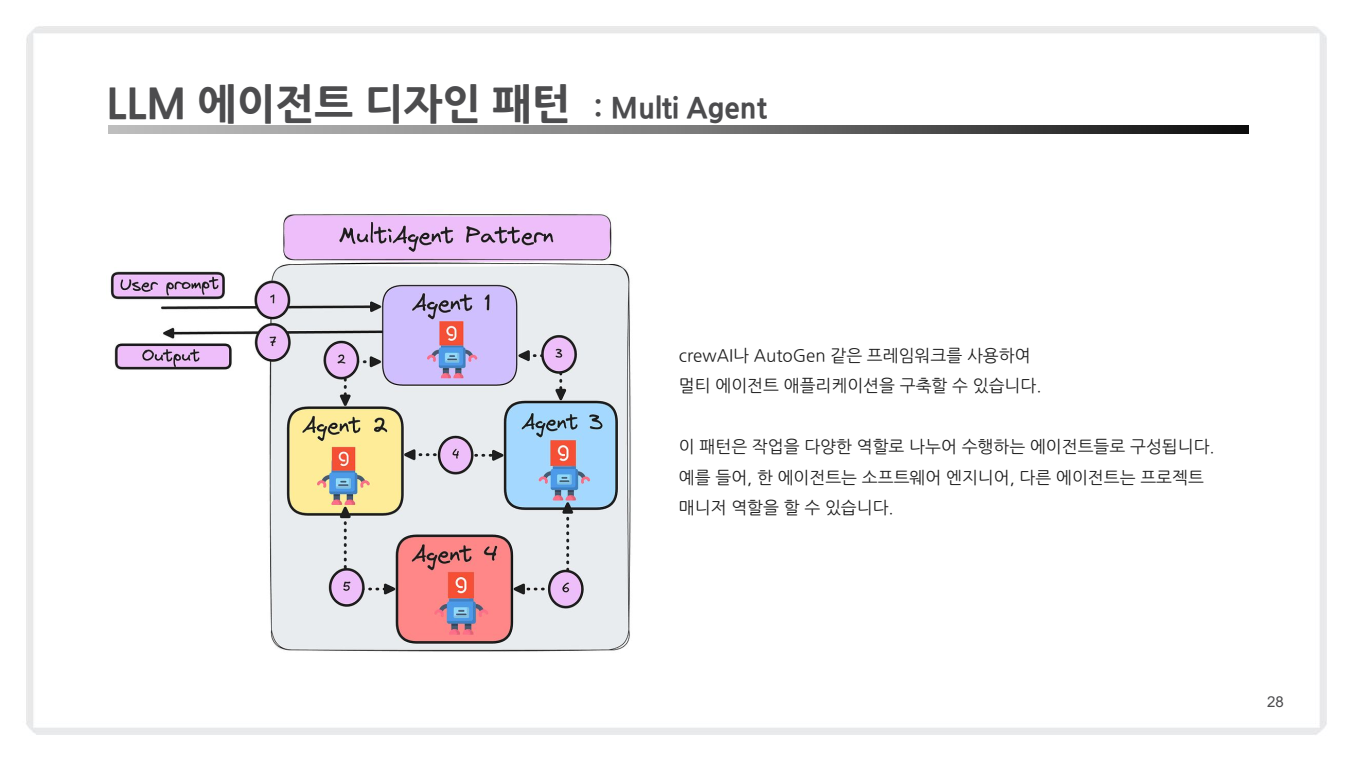
- 예시:
- 소프트웨어 엔지니어 역할의 에이전트와 프로젝트 매니저 역할의 에이전트가 협력.
- 한 에이전트는 데이터 크롤링, 다른 에이전트는 결과 분석.
- 적용 사례:
- AutoGen: 멀티 에이전트 협업을 지원하는 프레임워크.
- CrewAI: 작업 단위 분담을 통한 협력 수행.
Chapter 2: Naive RAG
Naive RAG란?
- Naive RAG는 RAG의 가장 기본적인 형태로, 외부 데이터를 검색하고 이를 LLM에 전달하여 답변을 생성하는 과정을 포함합니다.
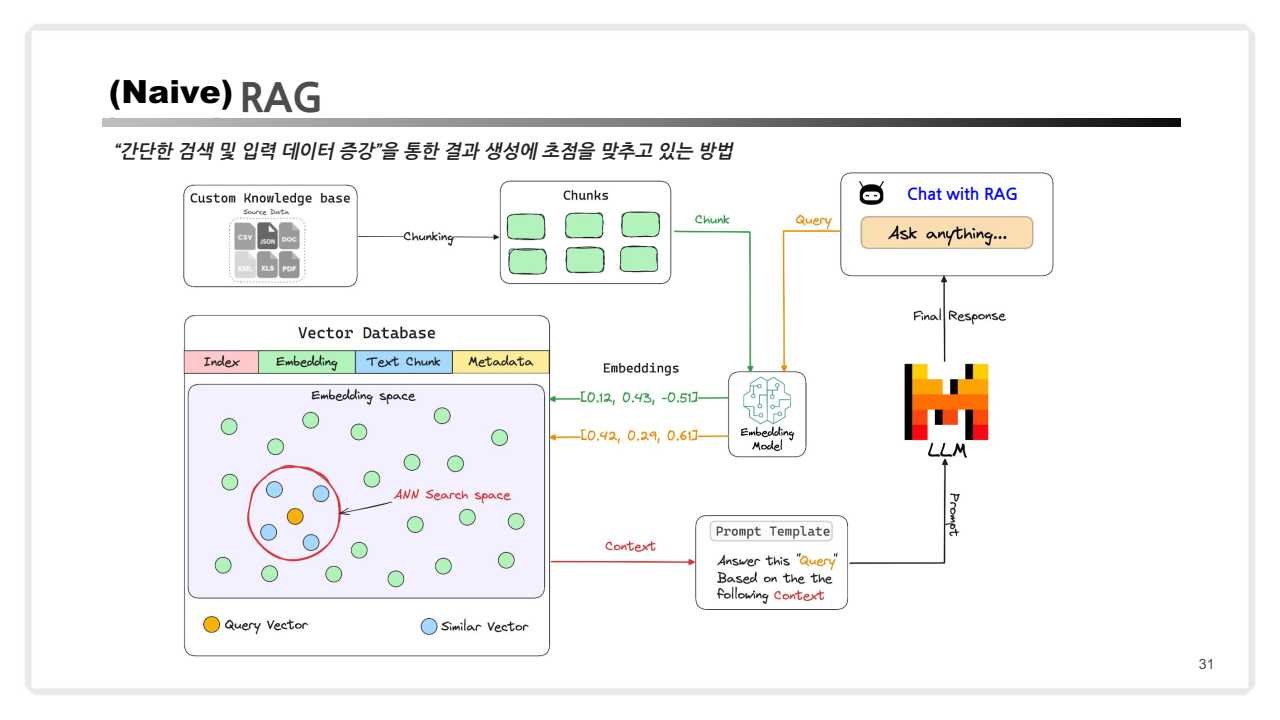
- 주로 벡터 데이터베이스(Vector DB)를 활용하며, 검색된 데이터를 컨텍스트로 사용해 LLM이 보다 정확한 답변을 생성하도록 돕습니다.
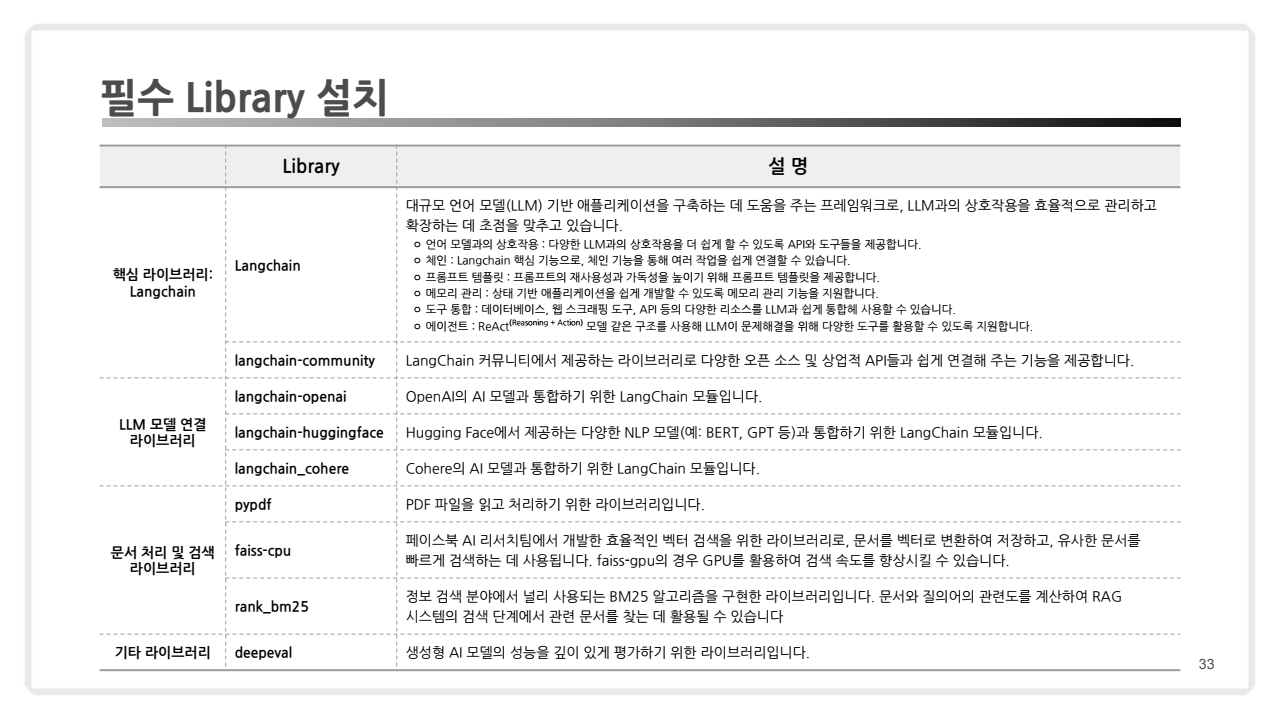
주요 라이브러리
설치 명령어
pip install langchain\
langchain-community\
langchain-openai\
langchain-huggingface\
langchain-cohere -qUpip install pypdf faiss-cpu rank-bm25 ragas deepeval -qULangChain 관련 패키지
langchain: LLM 애플리케이션 개발을 위한 프레임워크langchain-community: 서드파티 통합을 위한 LangChain 패키지langchain-openai: OpenAI와 LangChain 통합을 위한 패키지langchain-huggingface: Hugging Face와 LangChain 통합을 위한 패키지langchain-cohere: Cohere와 LangChain 통합을 위한 패키지
기타 패키지
pypdf: PDF 파일을 처리하기 위한 순수 Python 라이브러리faiss-cpu: 고밀도 벡터의 효율적인 유사성 검색 및 클러스터링을 위한 라이브러리rank-bm25: BM25 랭킹 함수를 구현한 패키지ragas: RAG(Retrieval-Augmented Generation) 시스템을 평가하기 위한 프레임워크deepeval: RAG(Retrieval-Augmented Generation) 파이프라인 평가를 위한 프레임워크
-qU 옵션 설명
pip 명령어의 -qU 옵션은 다음과 같은 의미를 가집니다:
-q: quiet 모드로, 설치 과정의 출력을 최소화합니다.-U: --upgrade의 축약형으로, 이미 설치된 패키지가 있다면 최신 버전으로 업그레이드합니다.
따라서 -qU 옵션을 사용하면 패키지를 조용히 설치하거나 업그레이드하게 됩니다.
2.1. Vector DB 구축하기
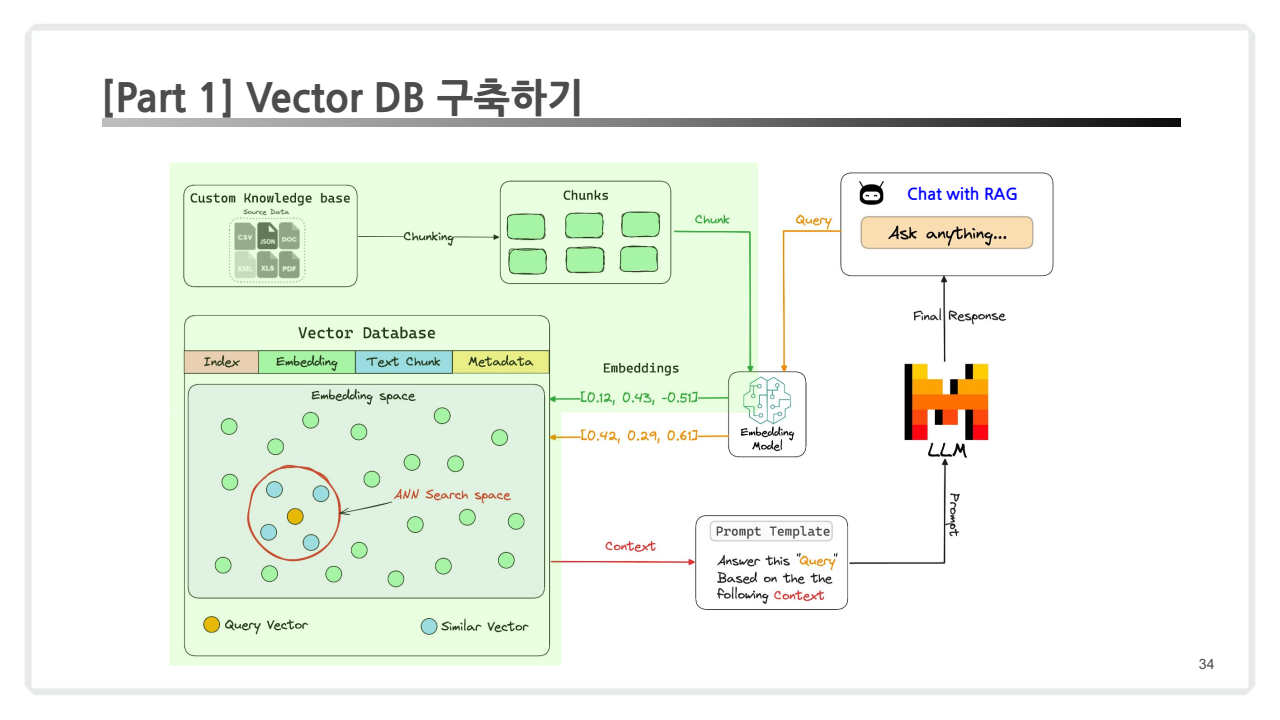
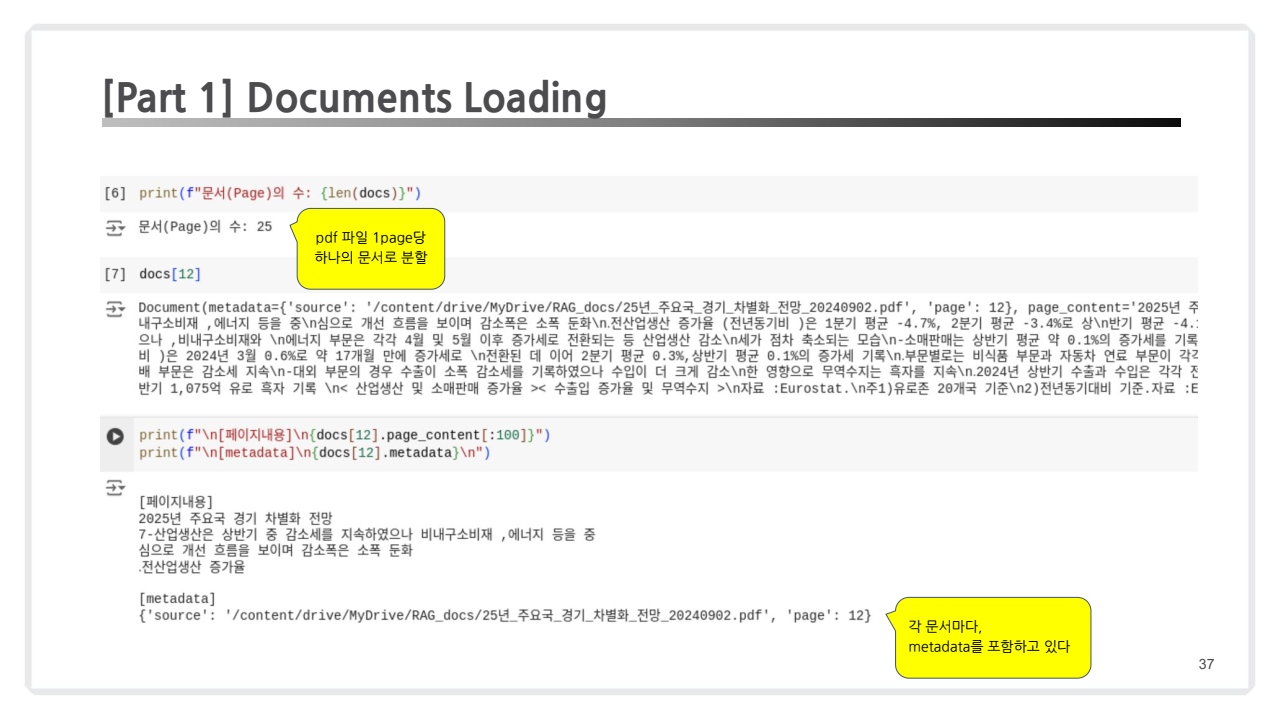
2.1.1. Documents Loading
-
작업 목적: 다양한 형태의 문서를 벡터 데이터베이스에 저장하기 위해 불러옵니다.
-
코드 예시
-
입력 예시 : 아래 코드는 PDF를 로딩하는 코드 snippet입니다.
from langchain.document_loaders import PyPDFLoader # PDF 파일 로딩 loader = PyPDFLoader("sample.pdf") docs = loader.load() -
출력 예시: 로드된 문서의 페이지 수와 메타데이터를 확인.
print(len(docs)) # 문서의 개수 print(docs[0].metadata) # 메타데이터 정보
-
2.1.2. Chunking
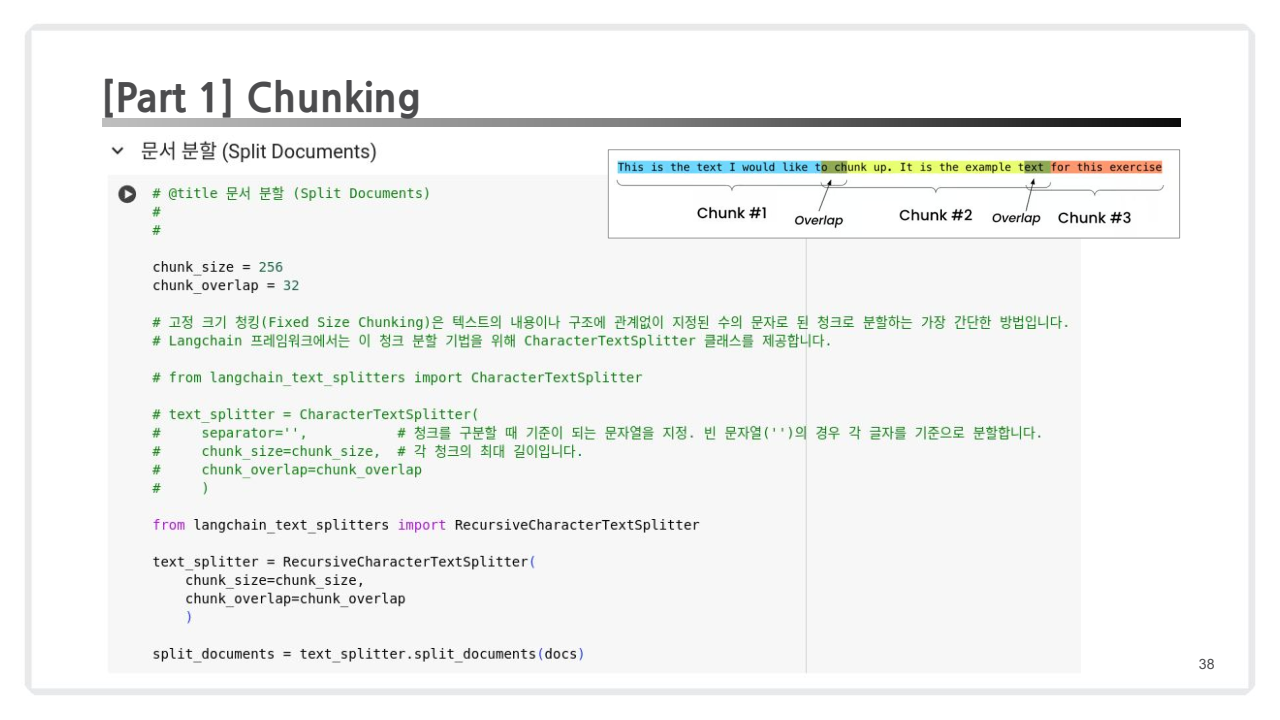
- 목적: 문서를 적절한 크기로 분리해 검색 효율성을 높임.
-
청킹(Chunking) 방식
- 텍스트를 일정 크기로 나눠주는 과정.
큰 Chunk=> 많은 정보, 많은 노이즈작은 Chunk=> 작은 정보, 작은 노이즈- 적당한 사이즈의 크기로 나누는 것이 시스템 결과의 충실도 및 관련성에 영향을 줌
- 텍스트를 일정 크기로 나눠주는 과정.
-
재귀적 청킹(Recursive Chunking) 방식
-
텍스트를 계층적으로 분할하여 정보의 맥락과 의미를 보존하는 과정.
-
단순 청킹 방식에서는 텍스트를 일정 크기로 나누지만, 재귀적 청킹은 텍스트 구조를 이해하여 상위-하위 관계를 유지하며 분할함.
-
RecursiveCharacterTextSplitter는 텍스트를 지정된 크기의 청크로 분할하는 LangChain의 유틸리티 클래스입니다. -
이를 활용하여 텍스트를 분할한 후 최종 chunk를 정의하는 과정은 다음과 같습니다:
-
분할 과정:
- 지정된 구분자(separators)를 사용하여 텍스트를 재귀적으로 분할합니다.
- 큰 단위의 구분자부터 시작하여 점차 작은 단위의 구분자로 이동합니다.
-
병합 과정:
- 분할된 텍스트 조각들을 지정된 chunk_size에 맞게 병합합니다.
- chunk_overlap을 고려하여 일부 내용이 겹치도록 합니다.
-
최종 chunk 정의:
- 병합된 텍스트 조각들이 최종 chunk가 됩니다.
- 각 chunk는 지정된 chunk_size를 초과하지 않습니다.
-
-
주요 매개변수
chunk_size: 각 청크의 최대 문자 수 (여기서는 100)chunk_overlap: 연속된 청크 간 겹치는 문자 수 (여기서는 20)separators: 텍스트를 분할할 때 사용할 구분자 목록
-
Separators의 작동 방식
separators 리스트 ["\n\n", "\n", ".", " "]는 우선순위 순서대로 적용됩니다:- "
\n\n": 먼저 빈 줄로 구분된 단락을 분리합니다. - "
\n": 그 다음 줄바꿈으로 구분된 줄을 분리합니다. - "
.": 그 다음 마침표로 구분된 문장을 분리합니다. - "
- "
-
-

-
코드 예시
-
입력
from langchain.text_splitter import RecursiveCharacterTextSplitter # 입력 텍스트 text = """ This is a sample document. It contains multiple paragraphs. Each paragraph contains multiple sentences. This is the second sentence in the second paragraph. Finally, this is the last paragraph. """ # RecursiveCharacterTextSplitter 설정 text_splitter = RecursiveCharacterTextSplitter( chunk_size=100, # 청크 크기 (최대 100자) chunk_overlap=20, # 청크 간 겹치는 부분 (20자) separators=["\n\n", "\n", ".", " "] # 분할 기준 ) # 텍스트 분할 chunks = text_splitter.split_text(text) # 분할된 청크 출력 for i, chunk in enumerate(chunks): print(f"Chunk {i + 1}:\n{chunk}\n") -
출력
Chunk 1: This is a sample document. It contains multiple paragraphs. Chunk 2: Each paragraph contains multiple sentences. This is the second sentence in the second paragraph. Chunk 3: Finally, this is the last paragraph. -
설명
-
첫 번째 청크:
- "\n\n"로 분리된 첫 번째 단락이 선택됩니다.
- 이 단락은 100자 미만이므로 그대로 첫 번째 청크가 됩니다.
-
두 번째 청크:
- 남은 텍스트에서 다음 "\n\n"로 구분된 단락이 선택됩니다.
- 이 단락도 100자 미만이므로 그대로 두 번째 청크가 됩니다.
-
세 번째 청크:
- 마지막 남은 텍스트가 세 번째 청크가 됩니다.
chunk_overlap이 20으로 설정되었지만, 이 예시에서는 각 청크가 100자 미만이어서 겹치는 부분이 생기지 않았습니다.
-
-
📋 참고 (Chunking 기법)
2.1.3. Embedding
- Embedding의 정의:
텍스트,이미지,음성등의 데이터를 고차원의 벡터 공간에 표현하는 기술입니다.- 이 단계는
벡터 데이터베이스(Vector DB)에서 유사도 기반 검색을 가능하게 하는 핵심 과정입니다.
- 이 단계는

-
Embedding의 역할:
의미적 유사성 포착: 유사한 의미를 가진 데이터는 벡터 공간에서 서로 가깝게 위치합니다.차원 축소: 고차원의 복잡한 데이터를 저차원으로 표현하여 효율적인 처리가 가능합니다.유사도 기반 검색: 벡터 간 거리나 각도를 계산하여 유사한 항목을 빠르게 찾을 수 있습니다.
-
Embedding 예시
-
이 예시에서는
HuggingFace와OpenAI의 임베딩모델을 사용하는 방법을 보여줍니다. -
OpenAI의 임베딩 모델은 강력한 성능을 제공하지만 API 키가 필요하고 사용량에 따른 비용이 발생합니다.
# OpenAI API 사용 from langchain.embeddings import OpenAIEmbeddings import os # OpenAI API 키 설정 os.environ["OPENAI_API_KEY"] = "your-api-key-here" # 임베딩 모델 설정 embedding_model = OpenAIEmbeddings() embeddings = [embedding_model.embed_query(chunk) for chunk in chunks] -
반면 HuggingFace 모델은 무료로 사용할 수 있고 로컬에서 실행 가능하지만, 일반적으로 OpenAI 모델에 비해 성능이 떨어질 수 있습니다.
# HuggingFace 모델 사용: from langchain_huggingface import HuggingFaceEmbeddings model_name = "BAAI/bge-m3" model_kwargs = {"device": "cuda"} encode_kwargs = {"normalize_embeddings": True} hf_embeddings = HuggingFaceEmbeddings( model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs )
-
-
Embedding 활용 예시
- 임베딩을 생성한 후에는 벡터 간 유사도를 계산하여 텍스트 간의 의미적 관계를 분석할 수 있습니다.
- 이는 정보 검색, 문서 분류, 추천 시스템 등 다양한 자연어 처리 작업에 활용됩니다.
import numpy as np # 임베딩 차원 확인 print(f"임베딩 차원: {len(embeddings[0])}") # 임베딩 벡터 간 유사도 계산 (코사인 유사도) def cosine_similarity(v1, v2): return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2)) similarity = cosine_similarity(embeddings[0], embeddings[1]) print(f"첫 번째와 두 번째 청크의 유사도: {similarity}")
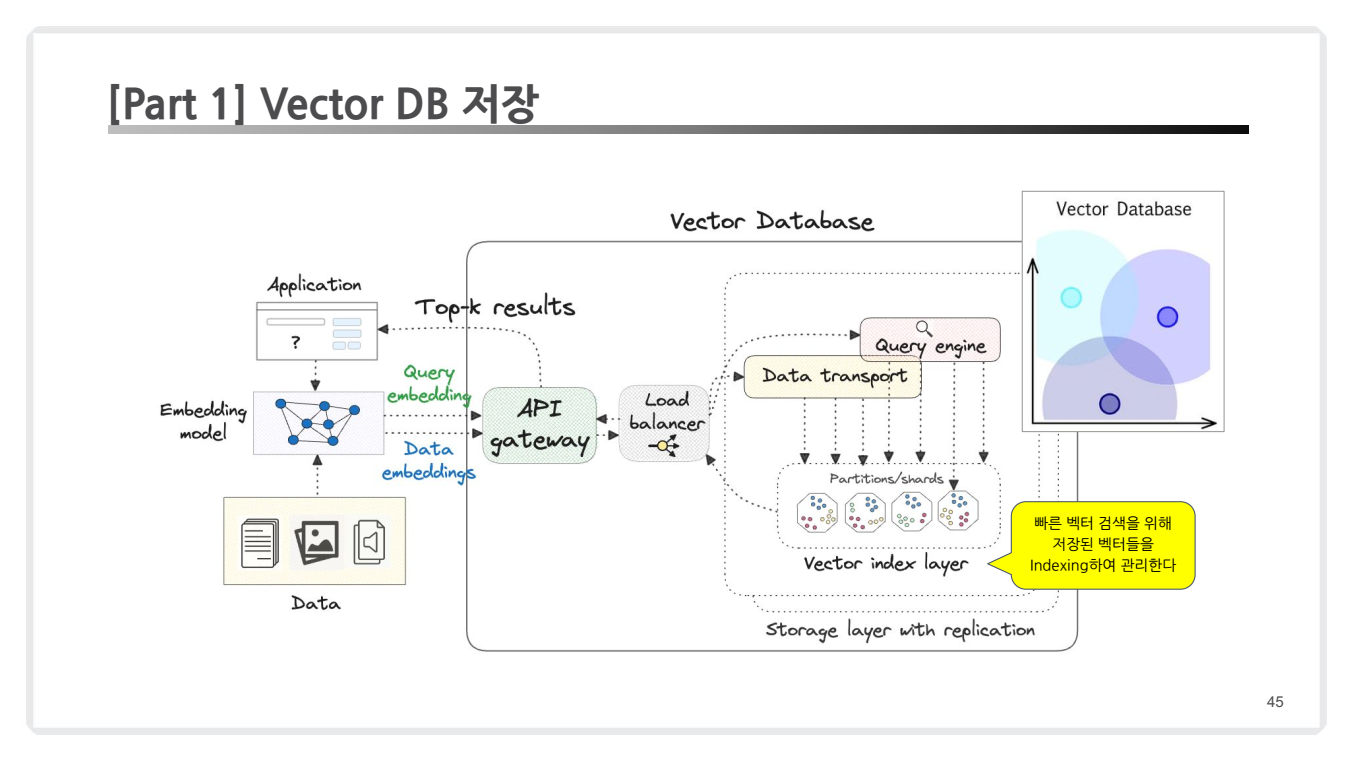
2.1.4. Vector DB 저장
임베딩 과정을 통해 생성된 벡터는 벡터 데이터베이스(Vector DB)에 저장됩니다.
-
Vector DB는 검색 속도를 높이고, 대규모 데이터셋에서도 빠르게 검색 결과를 반환할 수 있습니다.
-
벡터 DB 특징
인덱싱(Indexing): 효율적인 검색을 위해 벡터를 인덱싱하여 관리합니다.클라우드 네이티브: Milvus, Pinecone, Weaviate 등 벡터 DB 플랫폼이 클라우드 환경에서 빌리언 스케일 데이터를 다룰 수 있습니다.
-
코드 예시
from langchain.vectorstores import FAISS
# 1. 벡터 DB 생성
vector_db = FAISS.from_documents(documents = split_documents,
embedding = embedding_model)
# 2. 로컬에 저장
vectorstore.save_local('./db/faiss')
# 3. 로컬에서 로드
vectorstore = FAISS.load_local(
'./db/faiss',
embedding_model,
allow_dangerous_deserialization=True
)
📁 (참고) 다양한 유형의 Vector DB
- 아래 각 카테고리 별로 몇가지 사례들을 조사해서 설명을 추가해 두었습니다.

🗃️ 벡터 데이터베이스
- 주로 고차원 벡터 데이터의 저장과 검색에 특화된 데이터베이스로,
검색 효율성과확장성을 제공합니다.
- Milvus
- https://milvus.io/
- 다양한 인덱스 타입 지원과 확장 가능한 아키텍처가 특징
- 하드웨어 가속화된 연산 지원과 실시간 데이터 처리 기능 제공
- 10개 이상의 인덱스 타입을 지원하며 GPU 기반 인덱싱도 가능
🗃️ 벡터 라이브러리
- 벡터 데이터베이스에서 사용되는
벡터 임베딩 처리를 위한 라이브러리.
- Faiss
- https://github.com/facebookresearch/faiss
- Facebook AI(현 Meta)가 개발한 벡터 유사도 검색 라이브러리
- C++로 작성된 코어 라이브러리와 Python 래퍼 제공
- k-평균 클러스터링, 근접 그래프 기반 방식 등 다양한 인덱싱 방법 지원
🗃️ Vector-capable SQL 데이터베이스
- 기존 SQL DB에 벡터 처리 기능을 추가한 시스템.
- Timescale
- https://www.timescale.com/ai
- PostgreSQL 기반의 벡터 검색 기능 제공
- 시계열 데이터에 최적화된 벡터 검색 지원
- DiskANN 알고리즘 기반의 빠른 유사도 검색 제공
🗃️ Vector-capable NoSQL 데이터베이스
- 비정형 데이터를 위한 NoSQL 데이터베이스로 벡터 기능을 추가 제공.
- Cassandra
- LLamaIndex - Cassandra Index Demo
- 5.0 버전부터 벡터 검색 기능 추가
- Storage-Attached Indexing(SAI)를 통한 효율적인 벡터 인덱싱 제공
- 분산 아키텍처를 활용한 대규모 벡터 데이터 처리 가능

-
(참고)
SQL 데이터베이스vsNoSQL 데이터베이스-
SQL 데이터베이스는 전통적인 관계형 데이터베이스(Relational Database Management Systems, RDBMS)로, 데이터가 테이블 형태로 구조화되어 있습니다. -
NoSQL 데이터베이스는 비관계형 데이터베이스로, 정형 데이터뿐만 아니라 비정형(Unstructured) 데이터와 반정형(Semi-structured) 데이터 처리를 위해 설계되었습니다. -
SQL vs NoSQL: 주요 차이점 정리
특징 SQL NoSQL 데이터 구조 고정된 스키마 스키마가 유연하거나 없음 데이터 관계 관계형 데이터 지원 비관계형 데이터 처리 확장성 수직적 확장(더 강력한 서버) 수평적 확장(노드 추가) 쿼리 언어 표준 SQL 사용 다양한 API 및 자체 쿼리 언어 사용 트랜잭션 지원 ACID 속성 보장 BASE 속성(최종 일관성) 제공 처리 데이터 유형 정형 데이터 비정형 및 반정형 데이터 적합한 사용 사례 금융, ERP, CRM 등 관계형 데이터 소셜 미디어, IoT, 로그 분석
-
🗃️ Text Search Databases
- 텍스트 기반 데이터 검색을 처리하며, 벡터 처리 기능도 점진적으로 도입.
- Elasticsearch
- LLamaIndex - Elasticsearch Index Demo
- Apache Lucene 기반의 오픈소스 전문 검색 엔진
- 실시간 데이터 분석과 시각화 기능 제공
- 구조화/비구조화 데이터에 대한 강력한 전문 검색 기능 제공
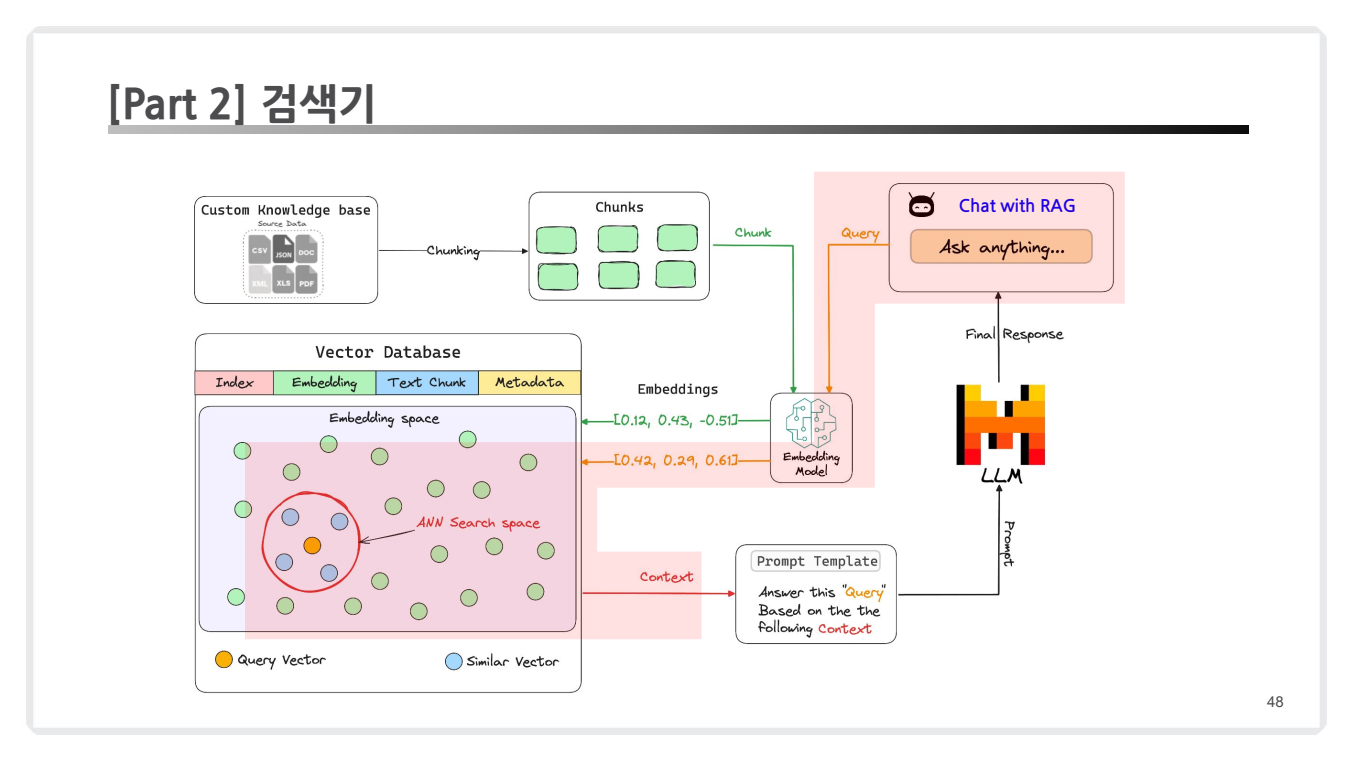
2.2. 검색기(Retriever)
검색기(Retriever)는 RAG 시스템에서 사용자의 질문에 대해 적절한 정보를 제공하기 위해 벡터 데이터베이스를 활용해 문서를 검색하는 핵심 모듈입니다.
- 아래는
검색기 생성과검색 방식에 대한 구체적인 설명입니다.
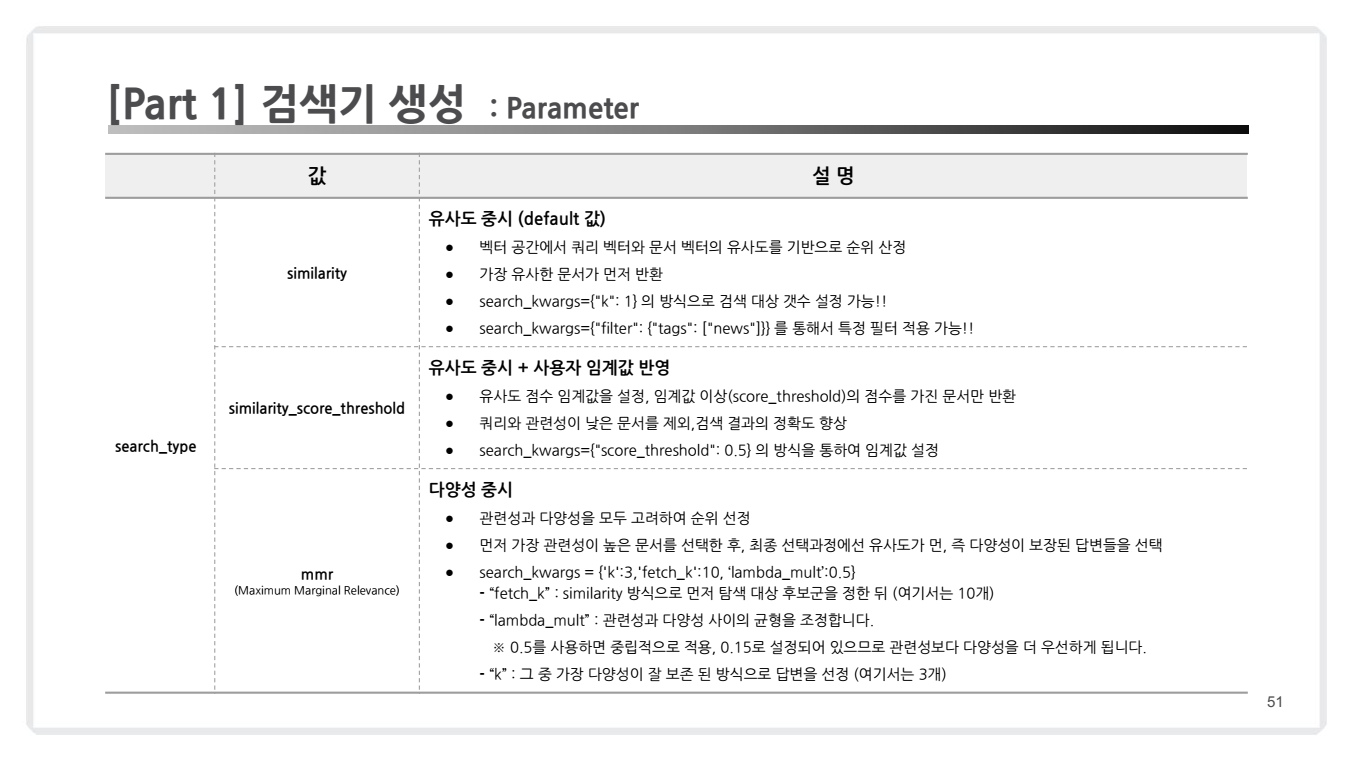
1. 검색기 생성
코드 예시
retriever = vector_db.as_retriever(search_type="similarity",
search_kwargs={"k": 5})주요 매개변수
-
search_type:- 검색 방식을 지정합니다.
"similarity": 유사도 기반 검색."mmr": MMR(Maximal Marginal Relevance) 방식."similarity_score_threshold": 유사도 점수 임계값을 설정하여 필터링.
- 검색 방식을 지정합니다.
-
search_kwargs:- 검색에 사용되는 추가 인자를 정의합니다.
k: 반환할 문서 수.fetch_k: MMR 검색에서 초기 탐색 문서 수.lambda_mult: MMR 결과에서 유사성과 다양성 간의 균형 조절.
- 검색에 사용되는 추가 인자를 정의합니다.
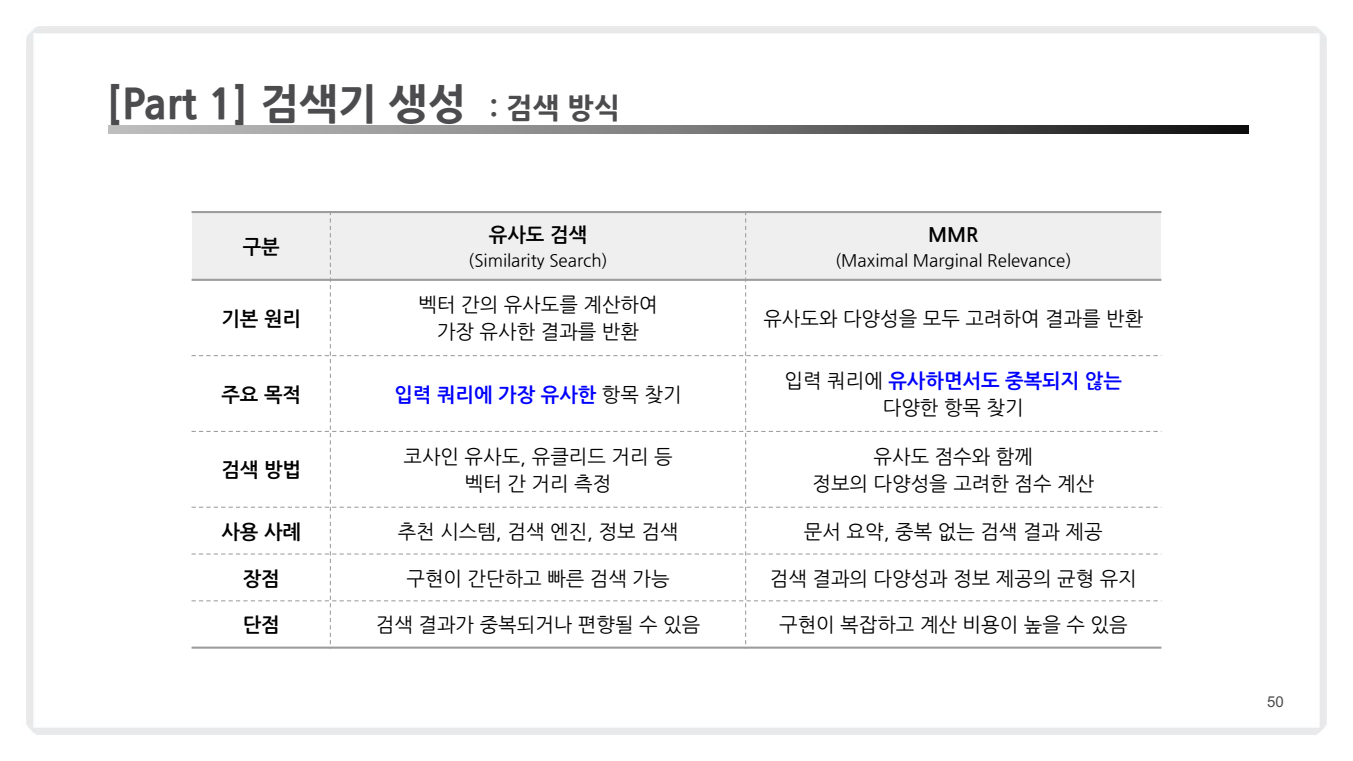
2. 검색 방법
검색기는 사용자의 질의(Query)를 벡터로 변환하고, 이를 데이터베이스 내 벡터들과 비교하여 가장 관련성 높은 문서를 반환합니다.
(1) 유사도 검색(Similarity Search)
- 원리:
- 벡터 간의 코사인 유사도를 계산하여 질의와 가장 유사한 문서를 찾습니다.
- 장점:
- 구현이 간단하고 빠른 검색이 가능.
- 단점:
- 반환된 문서가 중복되거나 다양성이 낮을 수 있음.
- 사용 사례:
- 추천 시스템, 단순 정보 검색.
- 코드 예시:
retriever = vector_db.as_retriever(search_type="similarity", search_kwargs={"k": 5})
(2) MMR (Maximal Marginal Relevance)
- 원리:
- 질의에 대한 유사도와 검색된 문서 간 다양성을 동시에 고려하여 결과를 반환합니다.
lambda_mult매개변수를 통해 유사성과 다양성의 가중치를 조정.
- 장점:
- 결과의 다양성을 확보.
- 중복 문서를 방지.
- 단점:
- 계산 비용이 더 높음.
- 사용 사례:
- 문서 요약, 중복 없는 정보 제공.
- 코드 예시:
retriever = vector_db.as_retriever(search_type="mmr", search_kwargs={"k": 5, "fetch_k": 10, "lambda_mult": 0.6} )
(3) 유사도 점수 임계값 검색(Similarity Score Threshold)
- 원리:
- 검색 결과 중, 유사도 점수가 특정 임계값 이상인 문서만 반환.
- 장점:
- 질의와 관련 없는 문서를 효과적으로 필터링.
- 단점:
- 임계값 설정이 어려움(너무 높으면 검색 결과 부족, 너무 낮으면 불필요한 결과 포함).
- 사용 사례:
- 검색 정확도가 중요한 상황.
- 코드 예시:
retriever = vector_db.as_retriever( search_type="similarity_score_threshold", search_kwargs={"score_threshold": 0.8} )
2.3. 생성기
앞 장 2.2 검색기에서 만든 검색기는 아래와 같이 동작을 하게 됩니다.
- 질의(Query) 처리: 사용자의 질문을 벡터로 변환.
- 벡터 비교: 질의 벡터와 데이터베이스 내 저장된 벡터 간의 유사도 계산.
- 문서 선택: 선택된 검색 방식에 따라 결과 문서 필터링(유사도, MMR, 임계값 기준).
- 결과 반환: 선택된 문서를 반환.
🤔 하지만 검색기만으로는 최종적인 답변을 생성할 수 없으며, 검색된 문서를 기반으로 질문에 대한 답변을 생성하는 과정이 추가적으로 필요합니다.
=> 이 역할을 수행하는 것이 바로 생성기(Generator)입니다.
- 검색기는 관련 문서를 잘 찾아내지만, 검색된 문서를 그대로 사용자에게 제공하기에는 다음과 같은
한계가 있습니다:
- 문서가 너무 길거나 질문과 관련 없는 세부 정보 포함 가능.
- 질문의 맥락에 맞는 요약이 필요.
- 사용자에게 최적화된 답변이 요구됨.
- 따라서 생성기는 검색된 문서를 사용해 사용자 질문에 맞는 간결하고 정확한 응답을 생성하는 역할을 합니다.
검색기와 생성기의 연결
검색기와 생성기는 다음과 같은 흐름으로 동작합니다:
-
질의(Query) → 검색기:- 사용자의 질문을 벡터로 변환하고, 데이터베이스에서 유사한 문서를 검색.
-
검색 결과 → 생성기:- 검색된 문서를 기반으로 LLM(Language Model)을 통해 사용자 질문에 대한 최적화된 답변 생성.
-
LLM → 응답 생성:- 검색된 문서와 질문을 결합한 프롬프트를 통해 LLM이 답변을 생성.
2.3.1. RAG 프롬프트
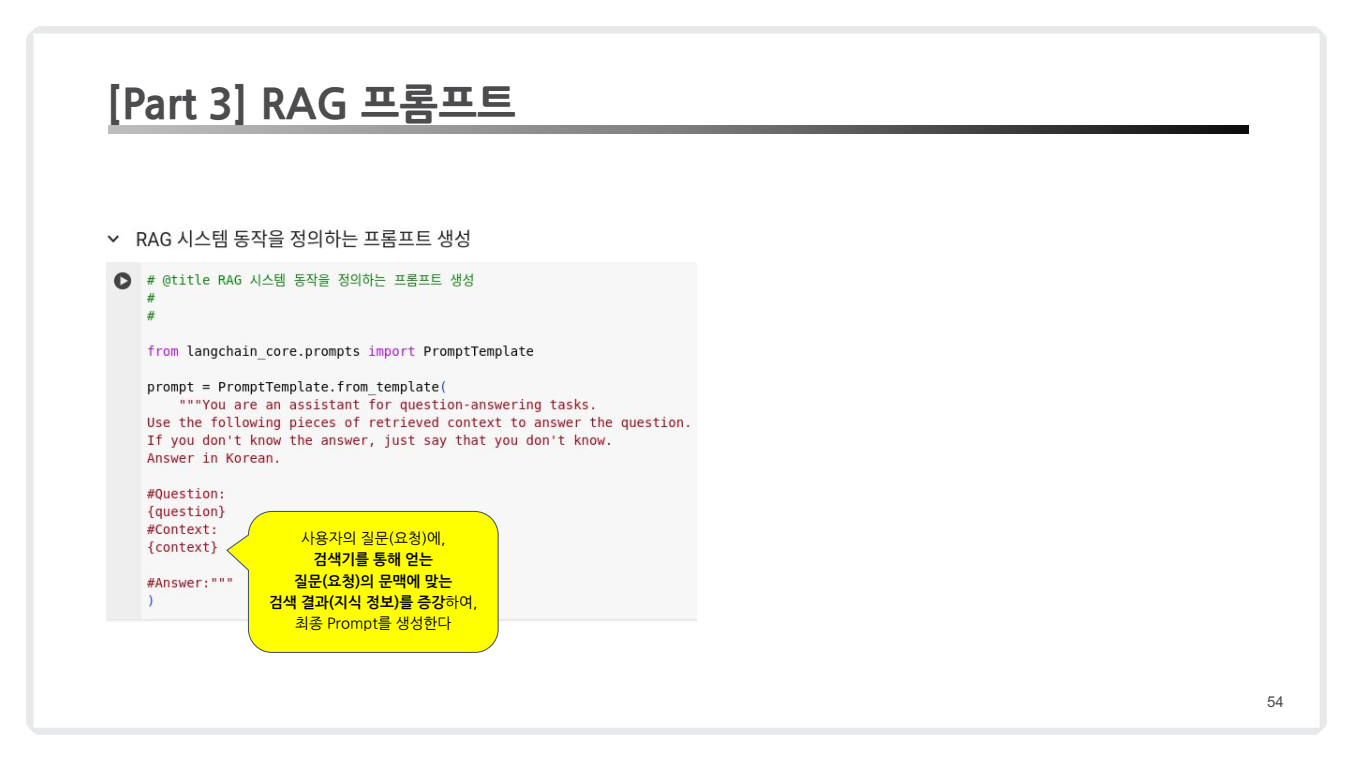
생성기의 핵심은 검색된 문서를 질문과 함께 언어 모델에 전달하는 방식입니다. 이를 위해 프롬프트를 설계하여 LLM이 환각(Hallucination)을 줄이고 명확한 답변을 생성하도록 유도합니다.
-
프롬프트 예시
prompt = PromptTemplate.from_template( """ 당신은 질문 답변 작업을 위한 어시스턴트입니다. 제공된 컨텍스트를 활용하여 질문에 답변해 주세요. 답을 모르는 경우에는 모른다고 말씀해 주세요. 한국어로 답변해 주세요. #질문: {question} #컨텍스트: {context} #답변: """ ) -
이 프롬프트는 RAG(Retrieval-Augmented Generation) 시스템에서 사용되는 기본 템플릿으로, 주어진 질문에 대해 검색된 컨텍스트를 바탕으로 한국어로 답변을 생성하도록 설계되어 있습니다.
-
사용자의 질문(
question)과 검색기를 통해 얻은 관련 문맥(context)이 각각 {question}과 {context} 위치에 삽입됩니다.question: 사용자의 질문.context: 검색기를 통해 반환된 관련 문서.- 결과 : LLM은 질문과 관련 문서를 기반으로 정확하고 요약된 답변을 생성.
2.3.2. 언어 모델 생성
생성기는 LLM을 활용하여 검색된 문서와 질문을 바탕으로 답변을 만듭니다. OpenAI의 GPT-4, Hugging Face 모델 등 다양한 언어 모델을 사용할 수 있습니다.
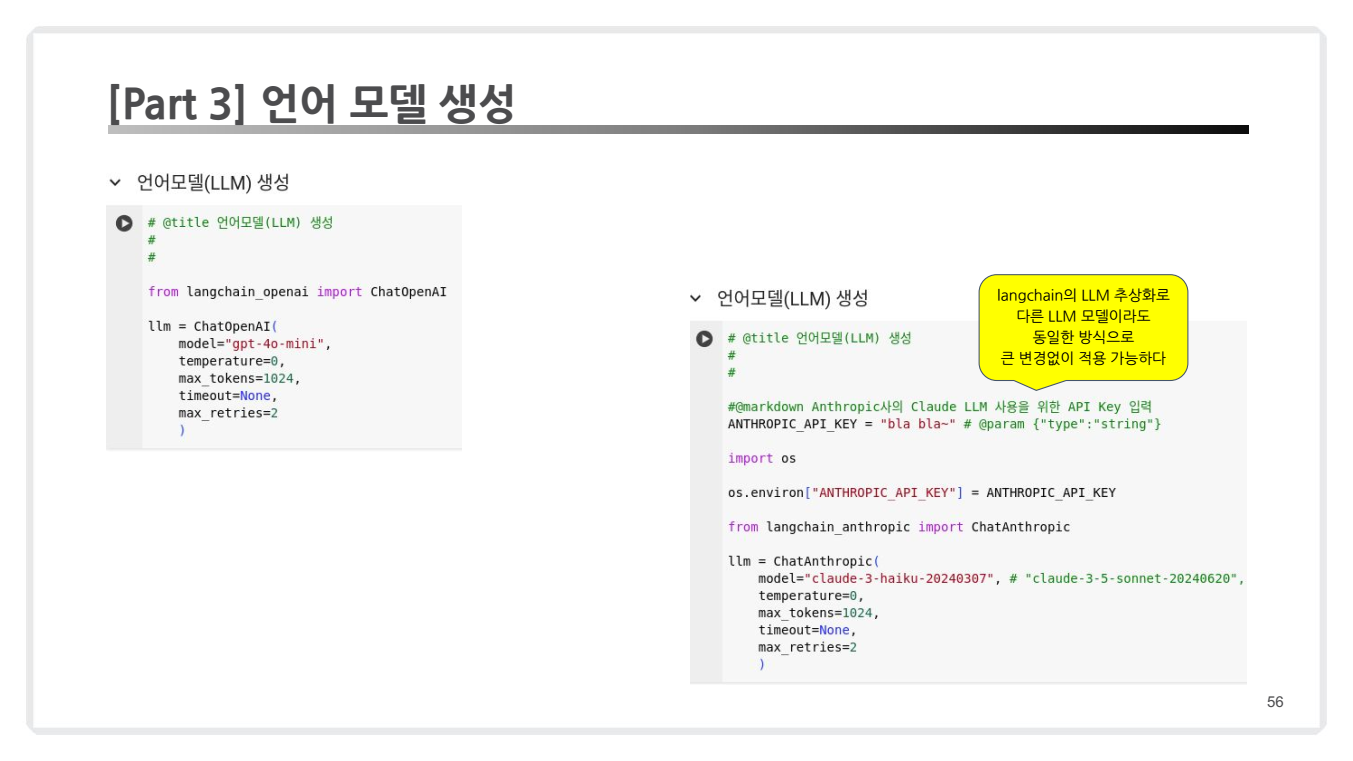
- 코드 예시
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-4", temperature=0.5, max_tokens=1000)
-
temperature: Temperature는 LLM의 출력 다양성과 창의성을 조절하는 핵심 파라미터입니다. 낮은 Temperature은 사실적이고 간결한 응답을, 높은 Temperature은 토큰의 무작위성이 증가하여 보다 다양하고 창조적인 결과를 촉진합니다.- Temperature 선택 Tips
- 0.0-0.5: 정확성이 중요한 작업(예: 고객 서비스, 기술 문서)
- 0.6-0.7: 일반적인 용도
- 0.8-1.0: 창의적 작업
- Temperature 선택 Tips
-
max_tokens: Max tokens는 모델이 생성할 수 있는 출력 텍스트의 최대 길이를 제한합니다. 이때, 프롬프트의 토큰 수와 max_tokens의 합이 모델의 컨텍스트 길이를 초과할 수 없습니다.- Max Tokens 설정 Tips
- 모델의 컨텍스트 길이 제한 고려
- 실제 필요한 출력 길이에 맞게 적절히 설정
- 짧은 응답이 필요한 경우 더 낮은 값 설정
- Max Tokens 설정 Tips

(추가)
Top-P(sampling)는 모델이 다음 토큰(단어)을 선택할 때 누적 확률을 기준으로 선택 범위를 제한하는 파라미터입니다.
- 확률이 높은 토큰부터 누적 확률을 계산하여 설정된 P값에 도달할 때까지의 토큰들만 선택 대상으로 고려합니다.
- 예를 들어 Top-P가 0.9라면, 확률이 높은 순서대로 토큰들을 더해가다가 합이 90%가 되는 지점까지의 토큰들만 고려합니다.
(Tips) Top-P & Temperature와의 관계
- Temperature와 Top-P는 모두 텍스트 생성의 다양성을 제어하는 파라미터이지만:
- Temperature는 전체 확률 분포를 조정하여 다양성을 제어합니다.
- Top-P는 선택 가능한 토큰의 범위를 제한하여 다양성을 제어합니다.
- 위 그림에서 파라미터 설정 시, 둘 중 하나만 변경하라고 권장하는 이유는:
- 두 파라미터가 비슷한 역할을 하기 때문에 동시에 조정하면 의도치 않은 결과가 나올 수 있습니다
- Temperature와 함께 사용할 경우 Top-P는 높은 Temperature에서 완전히 이상한 토큰이 선택되는 것을 방지하는 역할을 합니다.
(예시) Top-P 값에 따른 "강아지는 어떤 동물인가요?"에 대한 답변 예시를 살펴보겠습니다.
- 낮은 Top-P (0.3)
모델은 가장 확률이 높은 몇 가지 선택지만 고려하여 답변:
"강아지는 개과에 속하는 포유류입니다. 사람과 함께 사는 반려동물입니다."- 높은 Top-P (0.9)
더 많은 선택지를 고려하여 다양한 표현 가능:
"강아지는 개과에 속하는 포유류이면서, 충실한 반려동물입니다. 놀라운 후각과 청각을 가졌으며, 다양한 크기와 품종이 있고, 인간과 특별한 유대관계를 형성할 수 있는 감정이 풍부한 동물입니다."
(예시) Temperature 값에 따른 "강아지는 어떤 동물인가요?"에 대한 답변 예시를 살펴보겠습니다
- 낮은 Temperature (0.2)
더 사실적이고 일관된 답변:
"강아지는 개과에 속하는 반려동물입니다. 충실하고 사람과 잘 어울리며 보호자에게 충성심이 강합니다."- 높은 Temperature (0.8)
더 창의적이고 다양한 답변:
"강아지는 우리의 삶을 행복으로 물들이는 마법 같은 존재예요! 때로는 장난꾸러기 광대처럼, 때로는 든든한 수호천사처럼 우리 곁을 지켜주죠."
2.3.3. Chaining
LangChain을 활용하면 검색된 문서와 질문을 결합해 자연스러운 흐름으로 생성기와 연결할 수 있습니다. 이를 체이닝(Chaining)이라고 하며, 검색과 생성 단계를 하나의 파이프라인으로 구성합니다.
LCEL(LangChain Expression Language)을 사용하여 Chain을 연결하면 복잡한 워크플로우를 구현하거나 여러 단계의 논리적 흐름을 만들 수 있습니다.
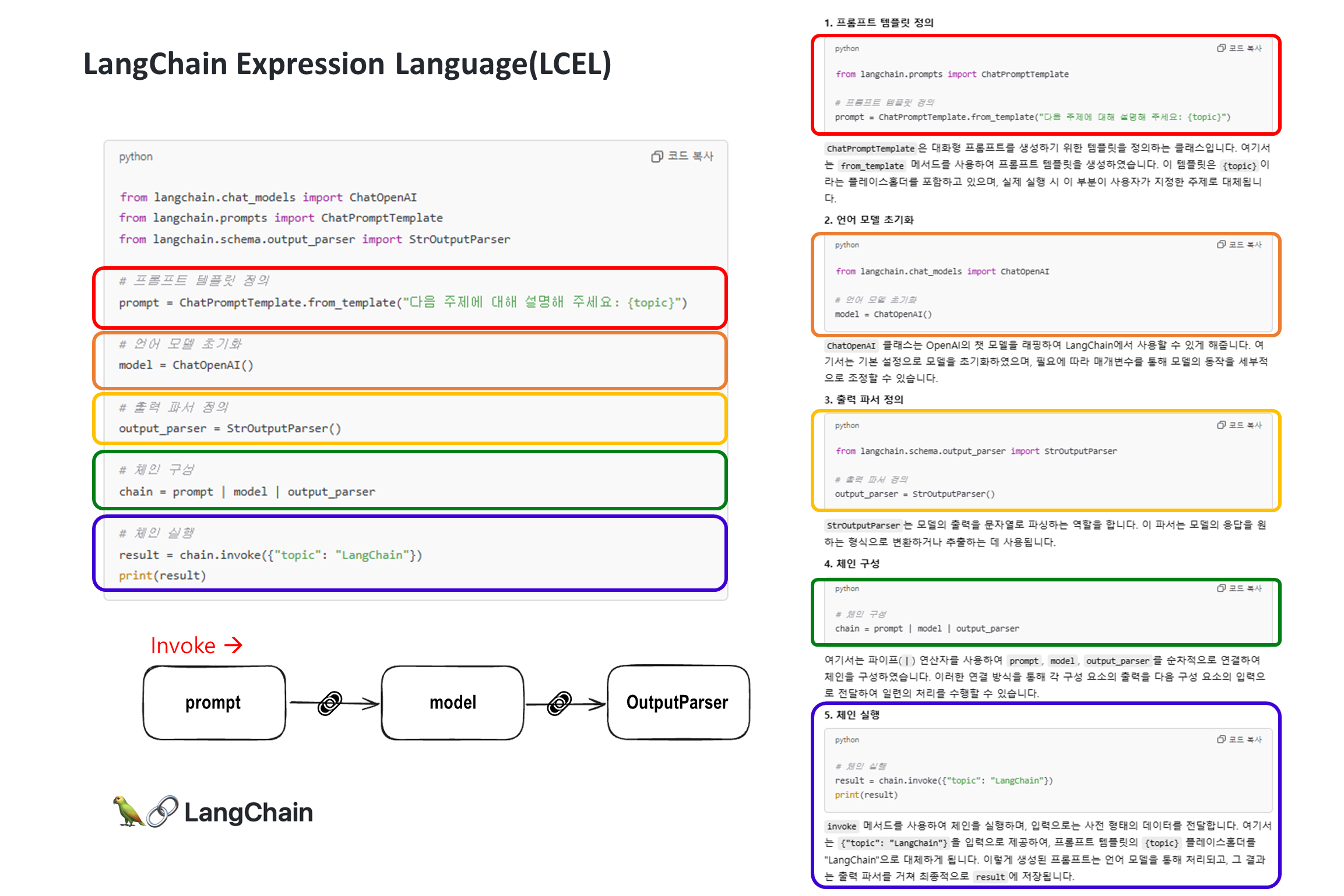
(참고) LCEL(LangChain Expression Language)
LangChain Expression Language(LCEL)은 LangChain 프레임워크 내에서 다양한 컴포넌트(Ex. 프롬프트 템플릿, 언어 모델, 출력 파서 등)를 선언적 방식으로 결합하여 체인을 구성할 수 있게 해주는 도구입니다.
- 이를 통해 복잡한 LLM(Large Language Model) 애플리케이션을 간결하고 효율적으로 구축할 수 있습니다.
- 주요 특징:
선언적 구문: 복잡한 로직을 간단하고 읽기 쉬운 방식으로 표현할 수 있습니다.모듈성: 다양한 컴포넌트를 쉽게 조합하고 재사용할 수 있습니다.유연성: 다양한 유형의 LLM 애플리케이션을 구축할 수 있습니다.확장성: 사용자 정의 컴포넌트를 쉽게 통합할 수 있습니다.최적화: 실행 시 자동으로 최적화를 수행합니다.- 주요 구성 요소:
Runnable: 모든 LCEL 컴포넌트의 기본 클래스입니다.Chain: 여러 Runnable을 순차적으로 실행합니다.RunnableMap: 여러 Runnable을 병렬로 실행합니다.RunnableSequence: Runnable의 시퀀스를 정의합니다.RunnableLambda: 사용자 정의 함수를 Runnable로 래핑합니다
코드 예시 1
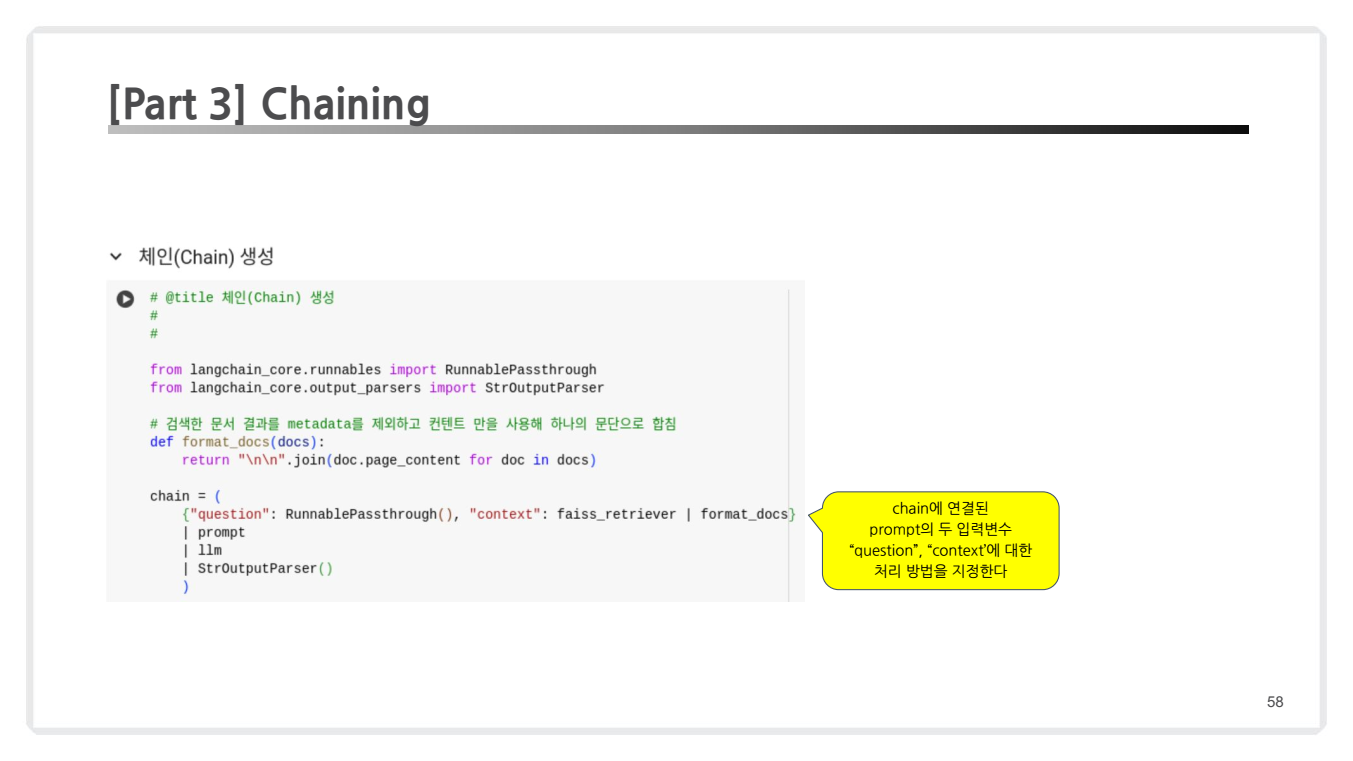
- 단일 체인 : 체이닝(Chaining)은 검색기에서 반환된 데이터를 자연어 모델(LLM)로 전달하여 사용자의 질문에 대한 응답을 생성하는 과정을 단일 파이프라인으로 처리합니다.
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
# 검색 문서 형식화 함수
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
chain = {
"question": RunnablePassthrough(),
"context": faiss_retriever | format_docs
} | prompt | llm | StrOutputParser()
주요 구성요소 설명:
-
RunnablePassThrough():- 입력된 질문을 그대로 다음 단계로 전달합니다.
- "question" 키를 통해 전달된 질문은 변환 없이 유지됩니다.
-
retriever | format_docs:- 검색기(retriever)를 통해 검색된 문서를 포맷팅하여 "context"로 전달합니다.
- format_docs는 검색된 문서의 내용을 하나의 문자열로 병합합니다.
-
prompt | llm | StrOutputParser():- 검색된 문서(context)와 질문(question)을 결합하여 LLM에 전달하고, 응답을 생성합니다.
- 생성된 응답은 문자열 형태(StrOutputParser)로 반환됩니다.
위에처럼 chain을 정의하고 아래 이미지처럼 실행할 수 있습니다.
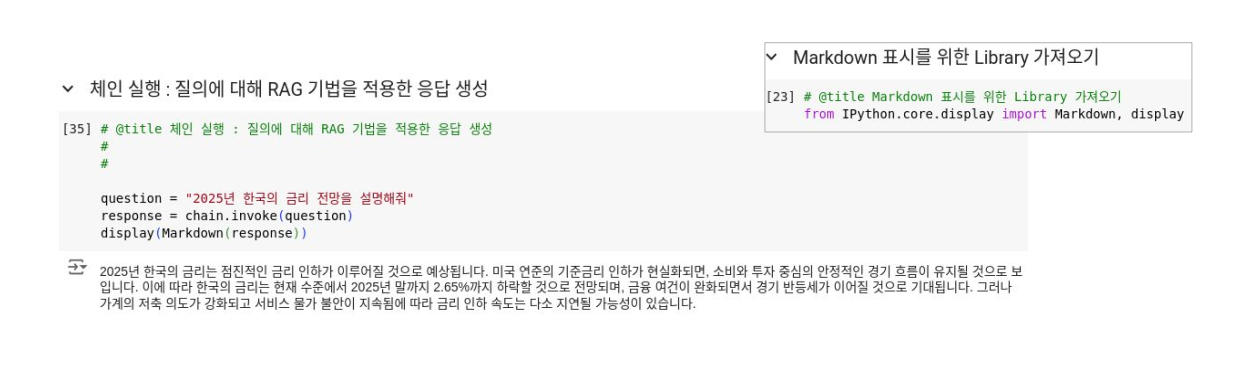
코드 예시 2
- 복수 체인: LCEL을 활용하면 여러 체인을 연결하거나 데이터를 순차적으로 처리할 수 있습니다. 다음은 체인을 연결하여 다단계 데이터 처리를 구현한 추가 예시입니다.
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
# 첫 번째 체인: 한국어 질문을 영어로 번역 (KOR2ENG)
prompt1 = ChatPromptTemplate.from_template(
"[{korean_input}] translate the question into English.
Don't say anything else, just translate it."
)
chain1 = (
prompt1
| llm
| StrOutputParser()
)
# 두 번째 체인: 번역된 질문에 대한 대답 생성
prompt2 = ChatPromptTemplate.from_messages([
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "{input}"}
])
chain2 = (
{"input": chain1} # chain1의 출력이 chain2의 input으로 전달됨
| prompt2
| llm
| StrOutputParser()
)
# 체인 실행
result = chain2.invoke({"korean_input": "대통령제에 대해 설명해줘"})
print(result)주요 구성요소 설명:
-
chain1: 한국어 -> 영어 번역 (KOR2ENG)- 사용자로부터 입력받은 한국어 질문(
korean_input)을 영어로 번역. - 프롬프트 템플릿과 LLM을 사용하여 번역 작업 수행.
- 사용자로부터 입력받은 한국어 질문(
-
chain2: 영어 질문 -> 답변 생성chain1의 출력(번역된 영어 질문)을 입력받아 답변 생성.- 번역된 질문을 기반으로 LLM을 통해 최적의 답변을 반환.
-
체인 연결:chain1의 출력은 자동으로chain2의 입력(input)으로 전달됩니다.- LCEL 문법을 통해 체인을 직관적이고 간결하게 연결.
체인 흐름
- 그렇다면
chain2.invoke({"korean_input": "대통령제에 대해 설명해줘"})을 실행했을 때 어떻게 호출이 될까요?chain2.invoke()호출입력:{"korean_input": "대통령제에 대해 설명해줘"}korean_input은chain1으로 전달됩니다.
chain1실행: 번역 작업prompt1에서 프롬프트 템플릿이 생성됩니다.[대통령제에 대해 설명해줘] translate the question into English. Don't say anything else, just translate it.- LLM이 이 프롬프트를 처리하여
번역된 영어 질문을 생성합니다."Explain about the presidential system."
번역 결과를chain2로 전달chain1의 출력인 번역된 질문 "Explain about the presidential system."이chain2의 입력으로 전달됩니다.
chain2실행: 대답 생성-
prompt2의 템플릿이 생성됩니다:
SYSTEM: You are a helpful assistant. USER: Explain about the presidential system. -
LLM이 이 프롬프트를 처리하여 대답을 생성합니다:
"A presidential system is a form of government where the president is the head of state and government, often elected by the people."
-
(정리) 입력 데이터 흐름:
korean_input→chain1→chain2.
코드 예시 3
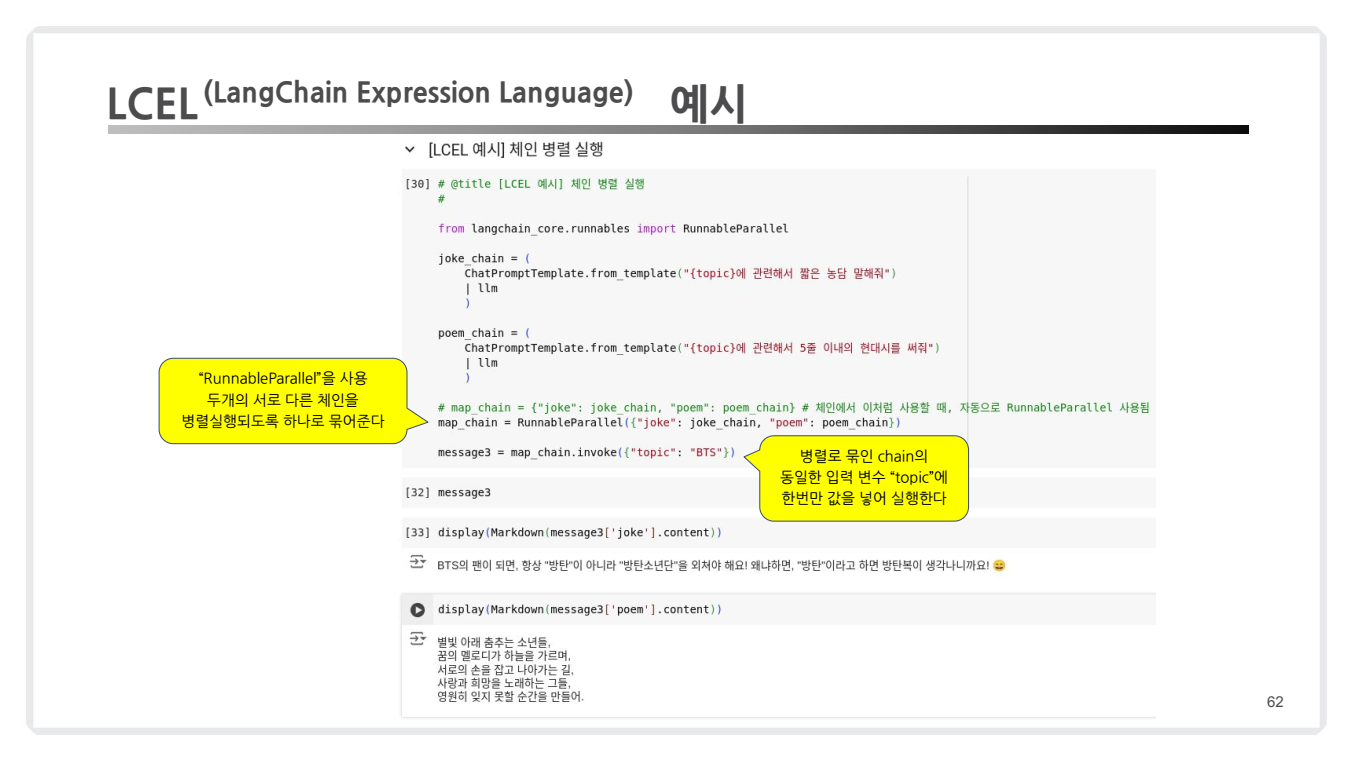
- 병렬 체인: LCEL은 체인을 유연하게 연결하거나 병렬 실행을 지원하여 더 복잡한 워크플로우를 설계할 수 있습니다.
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableParallel
# 두 개의 체인 생성
joke_chain = (
ChatPromptTemplate.from_template("{topic}에 관한 짧은 농담을 말해줘")
| llm
| StrOutputParser()
)
poem_chain = (
ChatPromptTemplate.from_template("{topic}에 관한 5줄 현대시를 써줘")
| llm
| StrOutputParser()
)
# 병렬 실행
parallel_chain = RunnableParallel({"joke": joke_chain, "poem": poem_chain})
# 실행
response = parallel_chain.invoke({"topic": "AI"})
print(response["joke"].content)
print(response["poem"].content)주요 구성요소 설명:
-
RunnableParallel:- 두 개의 체인을 병렬로 실행합니다.
joke_chain과poem_chain이 독립적으로 실행되며, 동일한 입력 변수(topic)를 공유합니다.
-
joke_chain:- 입력된 주제(topic)에 대해 짧은 농담을 생성합니다.
- 프롬프트와 언어 모델(LLM)을 연결하여 응답을 생성.
-
poem_chain:- 동일한 주제에 대해 짧은 시를 생성합니다.
joke_chain과 동일한 구조로 작동하지만, 응답의 내용은 시(poem)로 설정.
-
결과 병합:RunnableParallel은 두 체인의 결과를 병합하여 "joke"와 "poem" 키에 저장된 응답을 반환합니다.
Chapter 3: Advanced RAG
Advanced RAG란?
Advanced RAG는 Naive RAG의 기본 구조를 기반으로 하면서도, 검색 품질 향상과 답변 생성 최적화를 위해 추가적인 전략과 과정을 포함한 고도화된 RAG 구조입니다.
- 이 구조는 Naive RAG에서 발생할 수 있는 검색 결과의 정확도 저하와 중복된 응답 문제를 해결하고, 더욱 복잡한 질문에 대처할 수 있도록 설계되었습니다.
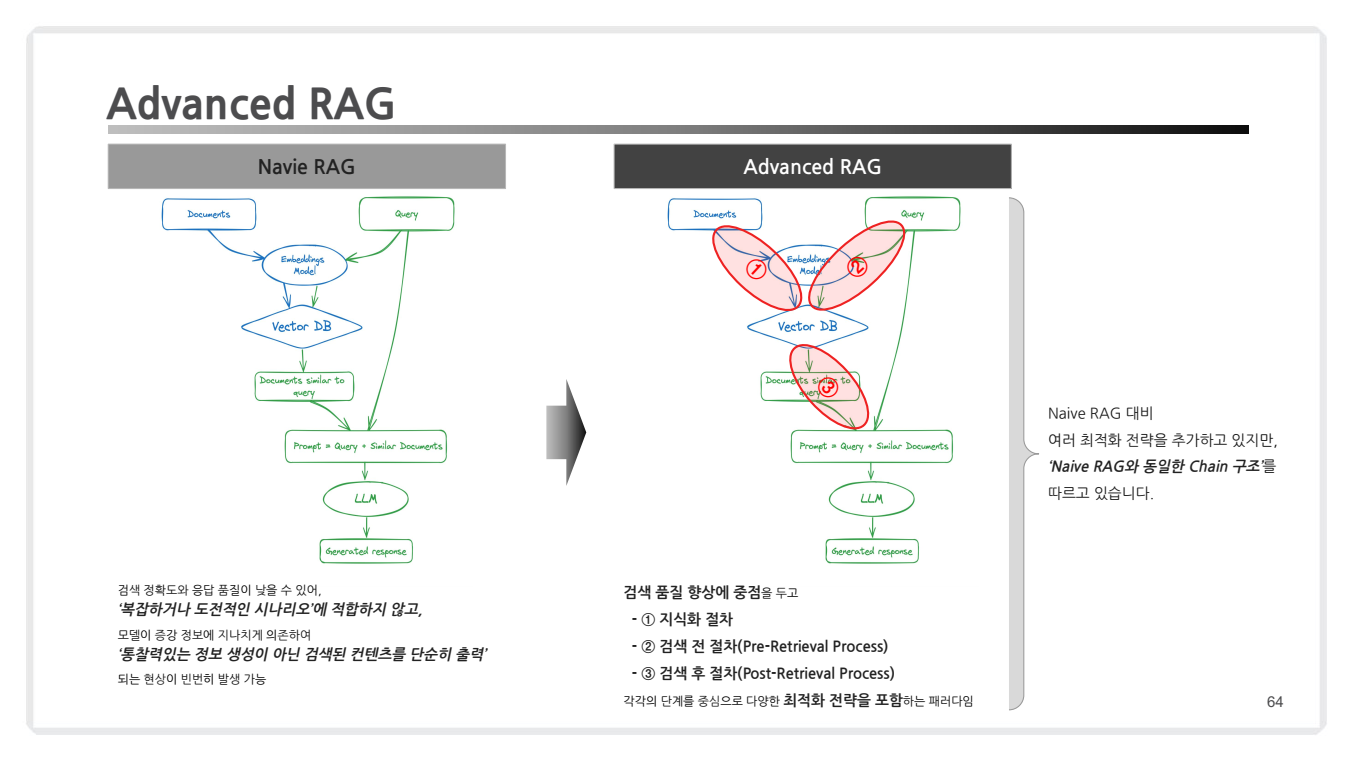
- 검색 품질 향상이라는 목표를 두고, 아래 사항들이 개선되었습니다.
- 지식화 증강(Knowledge Enrichment):
- 검색된 문서를 추가 가공하거나 기존 지식과 연결하여 정보의 깊이를 강화.
- 예: 요약, 통합, 도메인 지식 적용.
- 검색 전 최적화(Pre-Retrieval Process):
- 검색 전 쿼리를 최적화하거나 필터링.
- 예: 적합한 키워드 추출, 불필요한 쿼리 제거.
- 검색 후 최적화(Post-Retrieval Process):
- 검색 결과를 필터링하거나 중요도를 재조정하여 적합한 문서만 선택.
- 예: MMR(Maximal Marginal Relevance) 방식 적용, 관련성 점수 기반 재정렬.
- 지식화 증강(Knowledge Enrichment):
각각의 개선사항에 대해서 아래에서 살펴보도록 하겠습니다.
주요 기술 및 최적화
1. 지식화 증강(Knowledge Enrichment)이란?
지식화 증강은 기존의 검색 과정을 단순히 검색 결과를 반환하는 것에서 나아가, 검색된 정보를 더욱 구조적이고 풍부하게 만들어 검색 품질을 향상시키는 과정입니다.
이를 위해 주요 기술과 접근 방식을 다음과 같이 활용합니다:
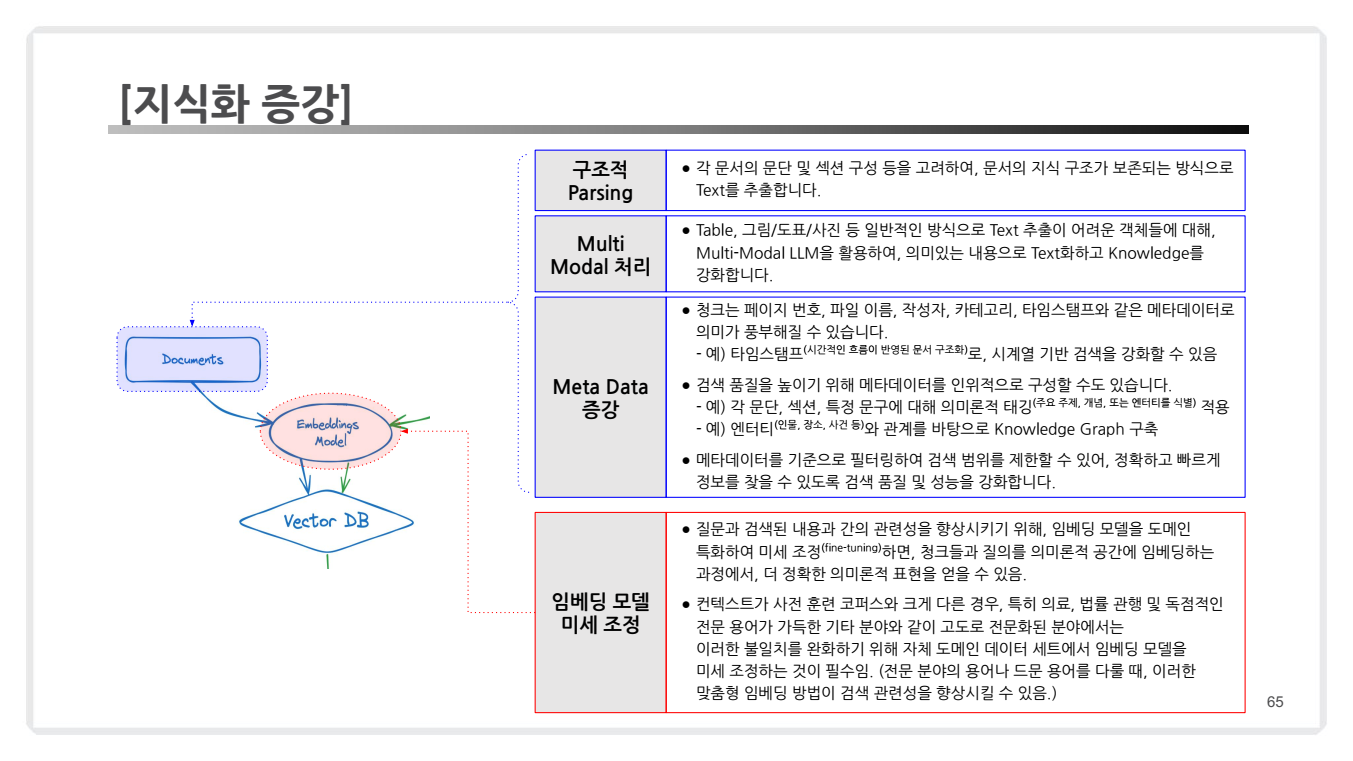
-
Document Level-
구조적 파싱 (Structural Parsing)
- 문서의 문단, 섹션, 표와 같은 구성 요소를 분석하여 정보의 구조를 보존합니다.
- 이렇게 생성된 구조적 데이터는 검색 쿼리의 맥락을 더욱 정교하게 반영할 수 있습니다.
-
멀티모달 처리 (Multi-Modal Processing)
- 텍스트뿐만 아니라 이미지, 표, 도표와 같은 비정형 데이터를 포함하여, 다양한 데이터 유형을 통합 처리합니다.
- 이를 통해 단순 텍스트 기반의 검색에서 벗어나, 보다 의미 있는 데이터로 검색 결과를 확장합니다.
-
메타데이터 증강 (Metadata Enrichment)
- 문서의 페이지 번호, 작성자, 카테고리, 시간 스탬프 등 메타정보를 활용하여 검색의 정확성과 속도를 높입니다.
- 예: 엔터티 추출(인물, 장소, 사건 등)을 통해 생성된 지식 그래프를 검색 결과에 반영.
-
-
Model Level- 임배딩 모델 파인튜닝(Finetune Embedding Models)
- 질문과 검색 쿼리 간의 의미적 관련성을 강화하기 위해, 사전 학습된 임베딩 모델을 특정 도메인에 맞게 조정하는 과정입니다.
- 특히 도메인 특화 검색이 필요한 경우, 일반적인 임베딩 모델로는 부족할 수 있어, 파인튜닝을 통해 정확도를 높입니다.
- 임배딩 모델 파인튜닝(Finetune Embedding Models)
2. 검색 전 최적화 (Pre-Retrieval Optimization)
2.1. HyDE (Hypothetical Document Embeddings)
- 개념: 사용자가 제시한 질문에 기반하여 "가상의 문서"를 생성하고, 이를 검색 과정에 활용하는 방법입니다.
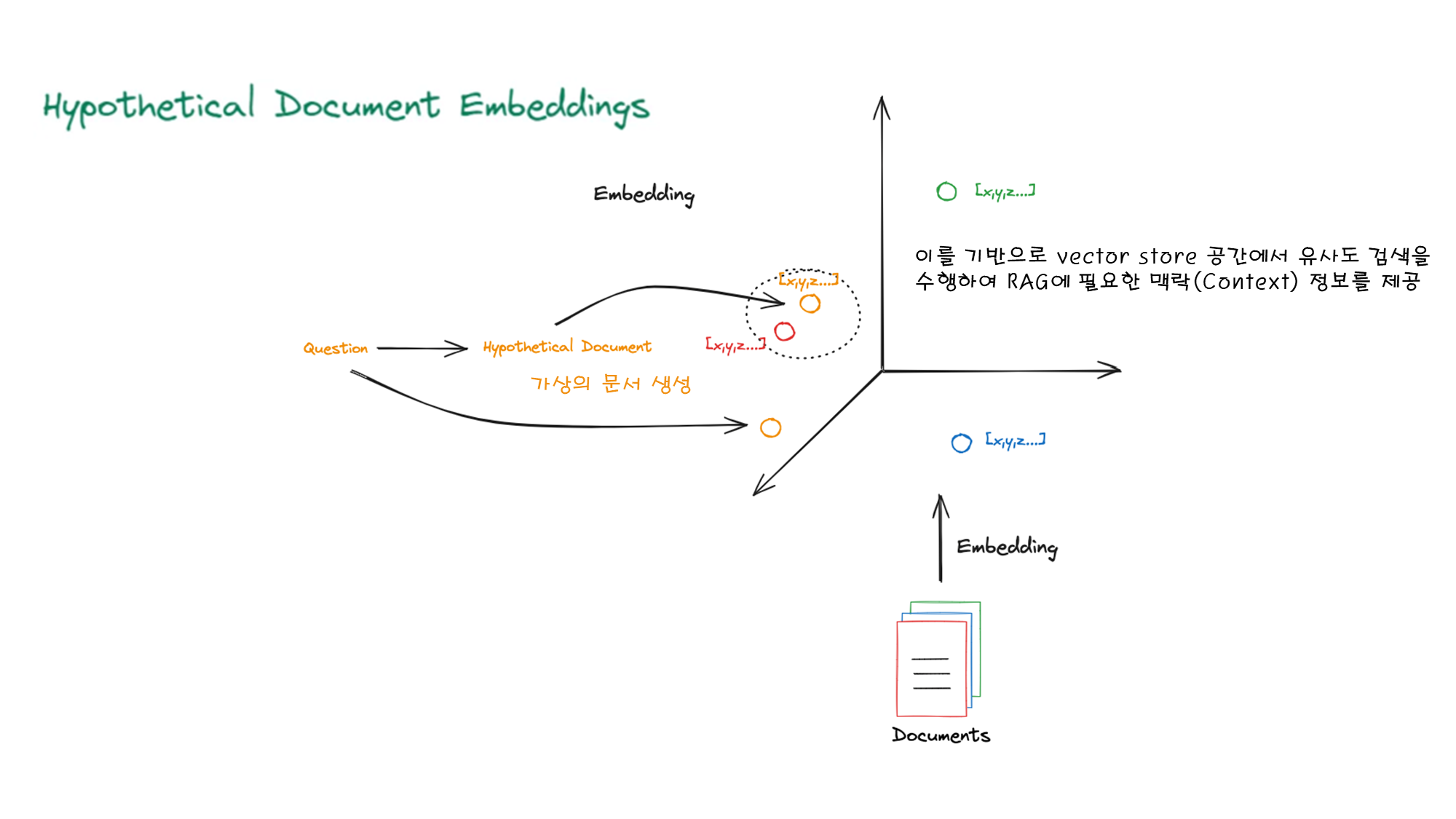
- 핵심 특징
- 가상 문서 생성: 대규모 언어 모델(LLM)을 사용하여, 사용자의 질문을 상세히 답변하는 문서를 생성합니다.
- 임베딩 활용: 생성된 가상 문서를 임베딩하여 검색 프로세스에 통합합니다.
- 장점:
- 사용자의 질문이 구체적이지 않을 때도 효과적인 검색이 가능합니다.
- 가상의 답변을 통해, 사용자가 찾고자 하는 문맥을 보완합니다.
- 활용 예시
from langchain.prompts.chat import SystemMessagePromptTemplate
def generate_hypothetical_document(query):
template =
"Imagine you are an expert writing a detailed explanation on the topic: '{query}'.
Your response should be comprehensive and include all key points from top search results."
system_message_prompt = SystemMessagePromptTemplate.from_template(template=template)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt])
messages = chat_prompt.format_prompt(query=query).to_messages()
response = llm(messages=messages)
return response.content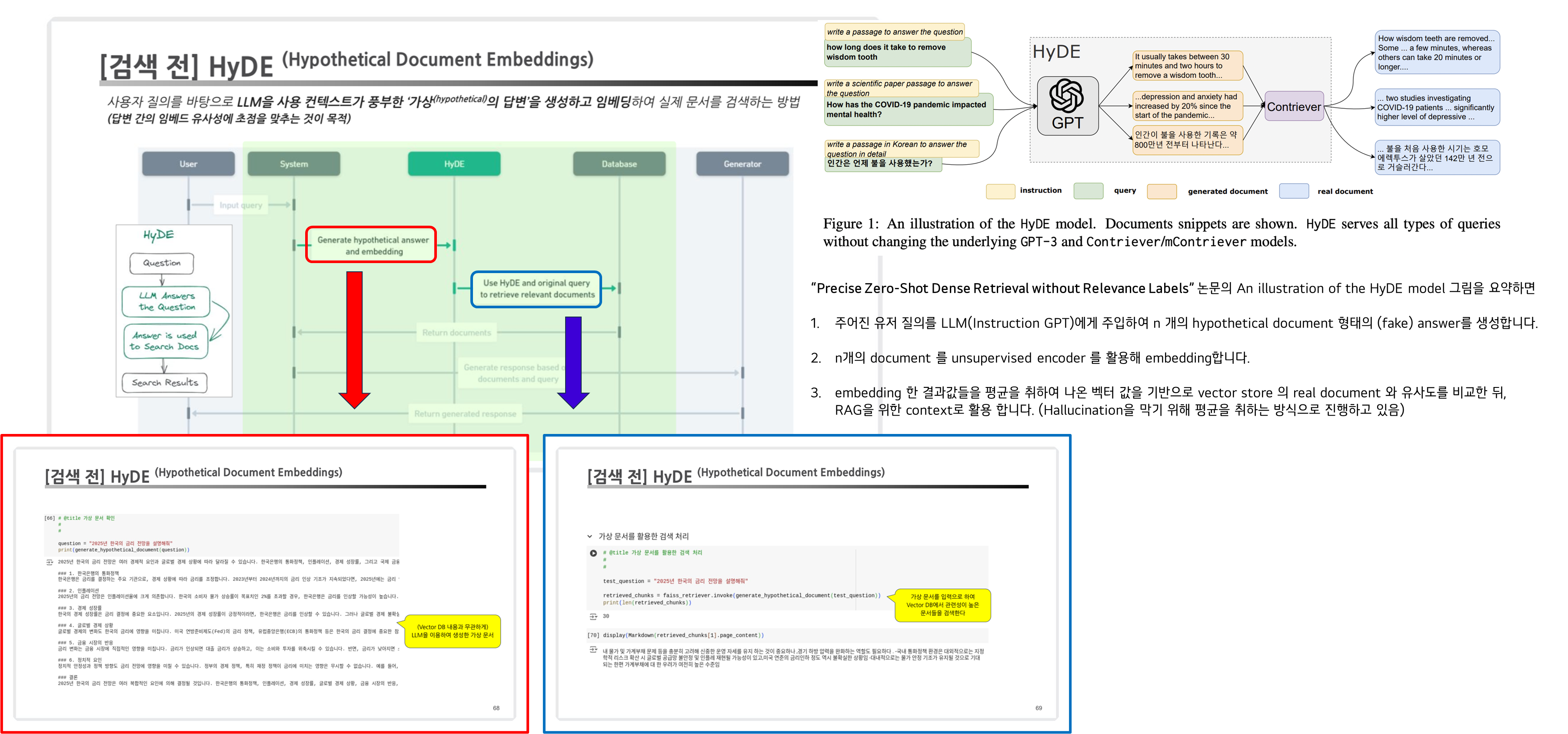
(참고) Langchain 함수를 이용한 Hyde 구현
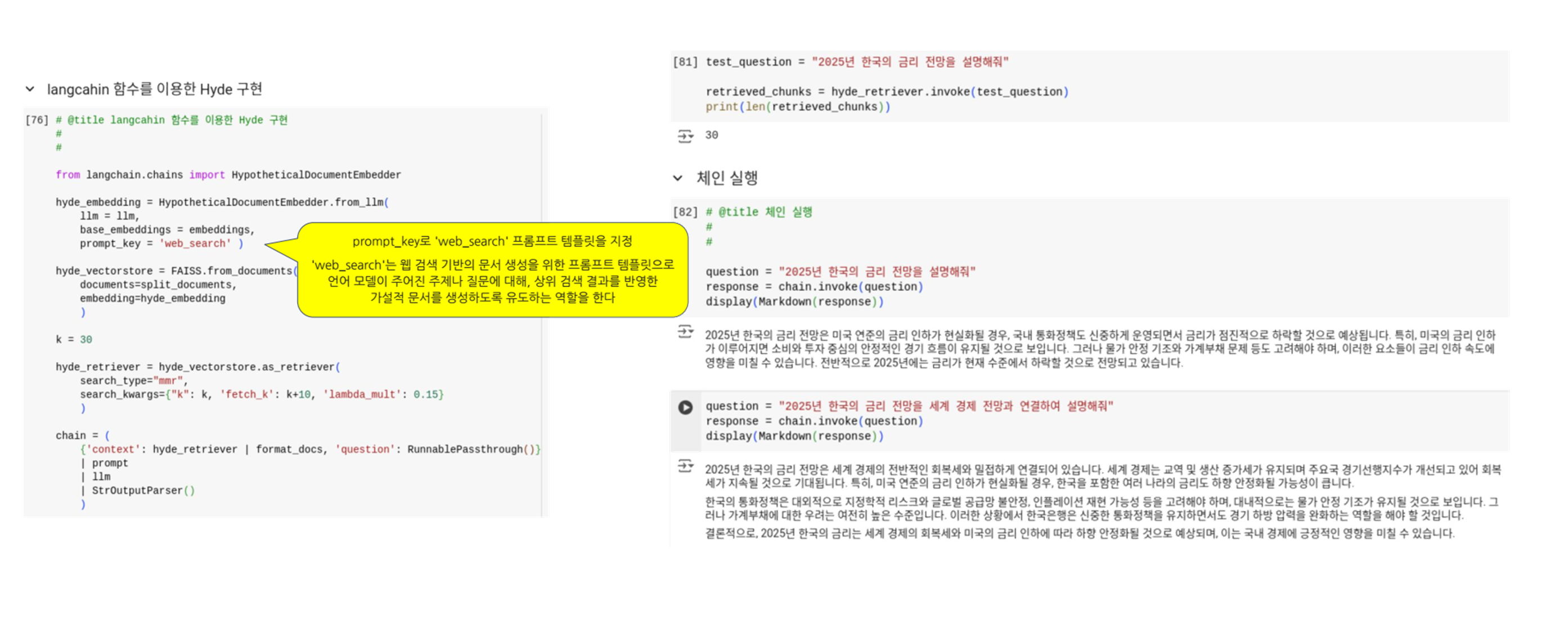
- HypotheticalDocumentEmbedder를 통한 가상 문서 생성:
HypotheticalDocumentEmbedder.from_llm메서드를 사용하여, LLM과 기본 임베딩(Base Embedding)을 결합한 HyDE 모델을 생성합니다.- HypotheticalDocumentEmbedder를 초기화할 때 다음과 같은 주요 매개변수를 사용합니다:
llm: 언어 모델 (예: OpenAI의 GPT 모델)Embeddings: 기본 임베딩 모델prompt_key: 프롬프트 템플릿을 선택하는 키
prompt_key='web_search'는 가상 문서를 생성할 때 활용되는 프롬프트 템플릿을 지정합니다. 이 프롬프트 템플릿은 생성된 가상 문서의 내용과 형식을 결정하는 데 중요한 역할을 합니다.prompt_key='web_search'프롬프트는 웹 검색과 관련된 정보를 효과적으로 생성하도록 설계되어, 사용자 질문에 대한 가상의 웹 검색 결과나 관련 정보를 생성하는 데 최적화되어 있습니다.web_search_template = """ Please write a passage to answer the question Question: {QUESTION} Passage:"""- 만약 특정 도메인이나 목적에 맞는 맞춤형 프롬프트를 사용하고자 한다면,
custom_prompt매개변수를 통해 직접 프롬프트 템플릿을 제공할 수 있습니다.custom_prompt = PromptTemplate( input_variables=["question"], template="최신 기술 동향에 대해 상세히 설명해주세요: {question}" )
- (예시) 벡터 스토어(Vector Store) 구성:
FAISS.from_documents는 Facebook AI가 개발한 FAISS(Facebook AI Similarity Search) 라이브러리를 사용하여 문서를 벡터 데이터베이스로 변환하는 메서드입니다.- 이는 아래와 같은 매개변수들을 사용합니다:
documents: split_documents를 통해 분할된 문서들embedding: hyde_embedding을 사용하여 문서를 벡터화
- (예시) 검색 실행:
hyde_retriever.as_retriever를 통해 MMR(Maximal Marginal Relevance) 방식으로 검색을 수행합니다.search_type="mmr":- MMR(Maximal Marginal Relevance) 검색 방식을 사용하여 검색 결과의 다양성과 관련성을 모두 고려합니다.
search_kwargs:- k : 검색할 문서의 수 (이미지에서는 30으로 설정)
- fetch_k : k+10으로 설정하여 추가 후보 문서를 검색
- lambda_mult : 0.15로 설정하여 다양성과 관련성 사이의 균형을 조절
2.2. Multi-Query
-
개념: Multi-Query는 사용자가 입력한
단일 질문(쿼리)을 여러 개의 하위 질문으로 변환하여 검색 과정의 품질을 극대화하는 접근 방식입니다.- 단일 질문이 가지고 있는 의도나 의미의 한계를 보완하며, 검색 결과의 다양성과 포괄성을 높이기 위해 설계되었습니다.
- 이 접근 방식은 특히 복잡하거나 뉘앙스가 필요한 질문을 처리할 때 강력한 효과를 발휘합니다.
- 예를 들어, "2025년 한국 금리 전망은?"이라는 질문에 대해
다양한 관점(정책,경제 상황,글로벌 동향등)에서 관련 문서를 검색하고, 이를 결합하여 종합적인 답변을 제공합니다.
- 예를 들어, "2025년 한국 금리 전망은?"이라는 질문에 대해
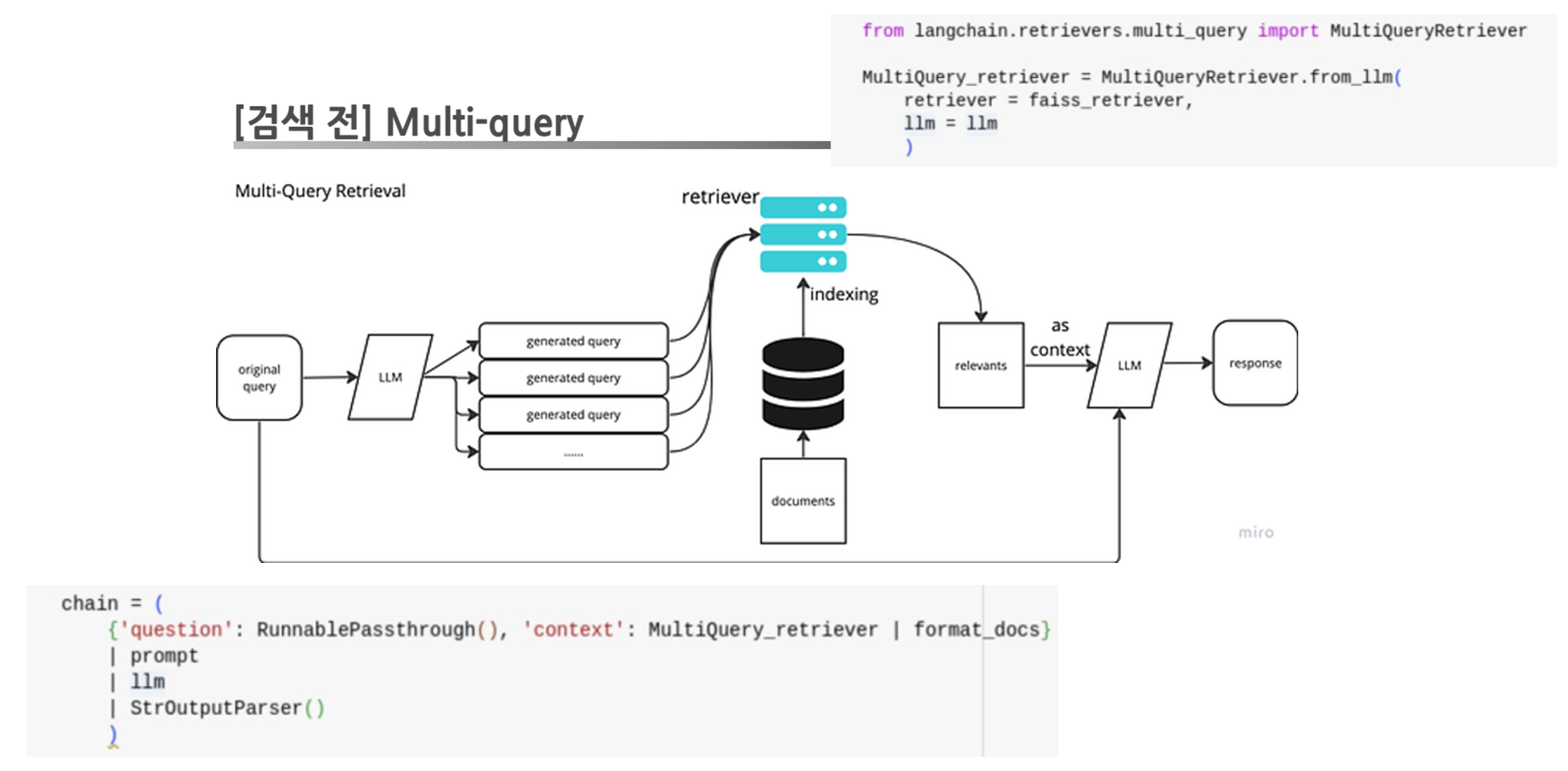
코드 예시
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain.llms import ChatOpenAI
from langchain.prompts.chat import ChatPromptTemplate
from langchain.schema import RunnablePassthrough
from langchain.chains import Chain
# 언어 모델 및 기본 검색기 설정
llm = ChatOpenAI(temperature=0.5) # 질문 확장을 위한 LLM 설정
retriever = faiss_retriever # 벡터 데이터베이스 기반 검색기
# Multi-Query Retriever 생성
multi_query_retriever = MultiQueryRetriever.from_llm(
retriever=retriever, # FAISS 기반 기본 검색기
llm=llm # 질문 확장을 위한 LLM
)
# LCEL 스타일 Chain 구성
prompt_template = """
You are an assistant answering user questions based on the following retrieved context.
Context:
{context}
Question:
{question}
Provide a concise and structured response in bullet points.
"""
prompt = ChatPromptTemplate.from_template(prompt_template)
# LCEL Chain 설정
chain = (
{
"question": RunnablePassthrough(), # 사용자 입력 질문
"context": multi_query_retriever | format_docs, # 검색 결과를 정리 및 형식화
}
| prompt # 프롬프트 생성
| llm # LLM을 사용한 응답 생성
| StrOutputParser() # 결과 형식화
)
# LCEL Chain 실행
query = "2025년 한국 금리 전망은?"
response = chain.invoke(query)
# 결과 출력
print("Generated Response:")
print(response)(참고)
format_docs?
format_docs는 검색된 문서를 특정 형식으로 정리하거나, LLM에 전달하기 적합한 텍스트로 변환하는 역할을 하는 함수 또는 프로세스를 나타냅니다. 이를 통해 검색된 문서가 LLM에서 더 쉽게 처리될 수 있도록 구성됩니다.
- 위 코드에서는
format_docs는MultiQueryRetriever와 LLM 간의 중간 단계를 담당하며, 검색 결과를 정리한 뒤 프롬프트에 삽입될 수 있도록 준비합니다.- 아래는 format_docs가 어떻게 구현될 수 있는지 보여주는 예시입니다.
def format_docs(docs): """ 검색된 문서를 정리하고 LLM에 적합한 포맷으로 변환하는 함수. """ formatted = [] for doc in docs: # 문서 내용을 요약하거나 정리 content = doc.page_content metadata = doc.metadata # 예: 제목과 주요 내용만 추출 formatted_content = f"Title: {metadata.get('title', 'Untitled')}\nContent: {content[:500]}..." formatted.append(formatted_content) return "\n\n".join(formatted)
-
핵심 특징
-
1)
질문 확장- 작동 방식:
- AI 언어 모델(LLM)을 활용하여, 사용자의 질문을 다양한 관점에서 재구성하고 관련 하위 질문들을 생성합니다.
- 목적:
- 단일 질문이 가지는 표현의 한계를 극복하고, 다양한 검색 결과를 얻습니다.
- 예시:
원 질문 (Original Question, 1개): "2025년 한국 금리 전망은?"생성된 하위 질문(Generated Question, 3개): "2025년 한국 금리에 영향을 미치는 주요 요인은 무엇인가?" "글로벌 경제 상황이 2025년 한국 금리에 미칠 영향은?" "한국은행의 정책이 2025년 금리 변화에 어떻게 작용할까?" - 작동 방식:
-
2)
결과 통합- 작동 방식:
- 생성된 하위 질문 각각에 대해 독립적으로 검색을 수행한 후, 검색된 문서들을 하나의 결과로 통합합니다.
- 주요 과정:
- 중복 제거: 동일한 정보가 중복되면 제거하여 효율성을 높입니다.
- 결과 정렬: 검색된 문서에 관련성 점수를 부여하고 우선순위를 정리합니다.
- 목적:
다양한 관점에서 데이터를 결합하여 더 풍부하고 신뢰성 높은 결과를 제공합니다. - 예시:
생성된 하위 질문들(Generated Question, 3개): "2025년 한국 금리에 영향을 미치는 주요 요인은?" "글로벌 경제 상황이 한국 금리에 미칠 영향은?" "한국은행의 정책이 2025년 금리 변화에 어떻게 작용할까?" 검색 결과(Retrieved Documents, 3개): 문서 1: 한국은행 발표 자료, 금리 정책 보고서. 문서 2: 글로벌 경제 보고서에서 발췌된 금리 관련 정보. 문서 3: 금리 변화와 시장 반응에 대한 전문가 인터뷰. - 작동 방식:
-
-
장점:
- 검색 결과의 다양성 증가
- 단일 쿼리로는 탐지하기 어려운 다양한 맥락과 관점을 포착할 수 있습니다.
- 예: 정책, 시장, 글로벌 상황 등 다양한 측면에서 결과를 제공.
- 사용자 의도 파악 강화
- 질문의 명시적 의미를 넘어, 암묵적 맥락과 의도를 해석합니다.
- 이를 통해 더 완벽한 정보를 검색합니다.
- 포괄적 결과 제공
- 단순히 관련 문서만 나열하는 것이 아니라, 다층적이고 종합적인 정보를 제공합니다.
- 복잡하거나 다면적인 주제에 적합.
- 자동화된 프롬프트 최적화
- 사용자가 직접 질문을 수정하거나 재작성하지 않아도, AI가 질문을 자동으로 확장합니다.
- 검색 결과의 다양성 증가
4. 검색 단계: Retrieval (Ensemble Retrieval)
Ensemble Retrieval은 여러 검색기(Retriever)를 결합하여 각각의 장점을 조합하고 검색 성능을 극대화하는 RAG(Retrieval-Augmented Generation) 기법입니다.
- 서로 다른 특성을 가진
Dense Retrieval(고밀도 검색)와Sparse Retrieval(희소 검색)를 적절히 결합하여 다양한 검색 시나리오에서 뛰어난 결과를 제공합니다.
1. 검색 알고리즘
-
1. Sparse Retrieval
Sparse Retrieval은 전통적인 키워드 기반 검색 방식으로, 단어의 존재 여부와 빈도를 기반으로 검색합니다. 문서를 희소 벡터(sparse vector) 형태로 표현하며, 각 단어는 독립적인 차원을 가집니다(TF-IDF, BM25 등). 주로 전통적인 정보 검색(Information Retriever) 모델에 사용됩니다.
장점
- 속도와 효율성: 단어의 빈도를 기반으로 한 간단한 계산이므로 연산 속도가 빠릅니다.
- 메모리 사용: 희소 행렬(sparse matrix)을 사용하여 메모리 요구량이 상대적으로 적습니다.
- 정확한 키워드 매칭: 특정 단어가 문서에 존재하는지에 대한 검색에서 높은 성능을 발휘합니다.
단점
- 문맥적 의미 부족: 동의어나 유사어를 처리하지 못하며, 단순한 단어 일치에 의존합니다.
- 추가 학습 불가능: 사전 구축된 모델에 의존하므로 새로운 데이터에 적응할 수 없습니다.
- 복잡한 질문 처리 어려움: 문맥적 의도 파악이나 복잡한 쿼리 응답이 제한적입니다.
활용 예시
- BM25와 TF-IDF는
Sparse Retrieval에서 가장 대표적인 알고리즘으로, 뉴스 기사나 검색 엔진과 같은 키워드 중심 검색에 자주 사용됩니다.
-
2. Dense Retrieval
Dense Retrieval은 신경망 기반 모델(BERT, RoBERTa 등)을 활용하여 문맥적 의미를 포함하는 밀집 벡터(dense vector)를 생성합니다. 문서와 질문을 고차원 공간에서 의미적으로 유사한 벡터로 변환하여 검색합니다. 각 차원이 단어 간 관계를 포함하므로 복잡한 문맥을 이해할 수 있습니다.
장점
- 문맥적 의미 이해: 동의어나 유사어를 처리할 수 있으며, 문맥적 의미에 기반한 검색이 가능합니다.
- 지속적인 학습: 새로운 데이터로 추가 학습이 가능하며, 검색 성능을 지속적으로 개선할 수 있습니다.
- 복잡한 질문 처리 가능: 단순한 키워드 매칭을 넘어 문맥과 의도를 파악하여 검색합니다.
단점
- 연산 비용: 벡터를 계산하고 비교하는 과정에서 높은 연산 비용이 요구됩니다.
- 메모리 요구량: 밀집 벡터를 저장하는 데 많은 메모리를 소모합니다.
- 학습 데이터 의존: 모델의 성능은 학습 데이터의 질과 양에 크게 의존합니다.
활용 예시
Dense Retrieval은 학술 논문 검색, 자연어 기반 질의응답 시스템, 그리고 의미론적 문서 검색과 같은 복잡한 검색 작업에 사용됩니다.
Sparse vs Dense Retrieval: 비교와 조합
| 특징 | Sparse Retrieval | Dense Retrieval |
|---|---|---|
| 알고리즘 | BM25, TF-IDF 등 전통적 IR 모델 | BERT, RoBERTa 등 신경망 기반 모델 |
| 연산 효율성 | 계산 복잡도 낮음 | 계산 복잡도 높음 |
| 메모리 사용 | 메모리 요구량 낮음 | 메모리 요구량 높음 |
| 검색 성능 | 단순 단어 매칭에서 높은 정확도 | 문맥적 의미 이해에서 높은 정확도 |
| 훈련 필요성 | 사전 구축된 모델 사용, 추가 훈련 불필요 | 대규모 데이터 기반 학습 필요 |
| 주요 장점 | 빠른 검색 속도, 적은 메모리 사용 | 문맥 이해 및 유사어 처리 가능 |
| 주요 단점 | 문맥적 의미 이해 부족 | 높은 계산 비용 및 메모리 요구 |
2. Ensemble Retrieval로의 확장
Sparse Retrieval과 Dense Retrieval은 각각의 장점과 단점을 보완하기 위해 자주 함께 사용됩니다.
- Sparse Retrieval: 키워드 기반 정확도를 보장하며 빠르고 효율적인 검색을 제공합니다.
- Dense Retrieval: 문맥적 의미를 이해하고 복잡한 쿼리를 처리할 수 있습니다.
- Ensemble Retrieval: 두 검색 방식을 조합하여 높은 검색 정확도와 속도를 동시에 달성합니다.
Ensemble Retrieval 구현 예시:
from langchain_community.retrievers import BM25Retriever, EnsembleRetriever
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
# Embeddings 초기화
embeddings = OpenAIEmbeddings()
# Sparse 검색기 (BM25) 초기화
bm25_retriever = BM25Retriever.from_documents(
split_documents,
k=20 # 검색할 문서 수
)
# Dense 검색기 (FAISS) 초기화
faiss_retriever = FAISS.load_local(
"dense_index",
embeddings,
allow_dangerous_deserialization=True
).as_retriever()
# Ensemble 검색기 생성
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, faiss_retriever],
weights=[0.4, 0.6]
)
chain = (
{
"question": RunnablePassthrough(), # 사용자 입력 질문
"context": ensemble_retriever | format_docs, # 검색 결과를 포맷팅
}
| prompt # 프롬프트 적용
| llm # LLM을 사용해 응답 생성
| StrOutputParser() # 출력 형식 정리
)
출력 예시

Ensemble Retrieval 검색 과정
-
입력된 질문:
"2025년 한국 금리 전망은?" -
사용자가 입력한 이 질문은
RunnablePassthrough를 통해 체인의 첫 단계로 전달되었습니다. -
두 검색기(Sparse와 Dense)를 결합하여 검색을 수행합니다.
Sparse Retrieval(BM25 등): 단어 빈도 기반으로 관련 문서를 빠르게 검색.Dense Retrieval(FAISS 등): 문맥적 의미를 고려하여 관련 문서를 검색.
-
이 두 검색기의 결과가 가중치를 기반으로 통합됩니다.
- 코드에서 설정된 weights에 따라 Dense와 Sparse 검색기의 결과가 결합되었습니다.
- 최종적으로 검색된 문서는 42개입니다.
-
해석
weights=[0.4, 0.6]의 의미, 각 검색기는 독립적으로 문서를 검색하고 순위를 매김.- BM25 결과에 0.4 가중치 적용
- FAISS 결과에 0.6 가중치 적용
- 두 검색기의 결과를 가중치를 기준으로 재정렬, 각 문서는 두 검색기의 점수를 조합한 최종 점수를 받음.
- 두 가지가 균형있게 반영된 최적의 문서 집합 총 42개가 선택됨.

5. 검색 후: Re-Ranking
Re-Ranking(리랭킹)은 초기 검색 단계에서 수집된 후보 문서(또는 청크)의 순위를 재조정하는 기술입니다.
(앞에서 Ensemble Retrieval 이후 일종의 재순위화(Re-Ranking) 작업을 수행했다고 봐도 됩니다.)
- LLM 기반 검색에서는 입력 토큰 수 제한이 있기 때문에, 질문과 가장 관련성이 높은 문서를 선택해 최종 순위로 정렬해야 합니다.
- 특히 긴 문서에서 다수의 검색 결과가 생성될 때, 관련성이 낮은 문맥 제거 및 최적화된 순위 결정에 매우 유용합니다.
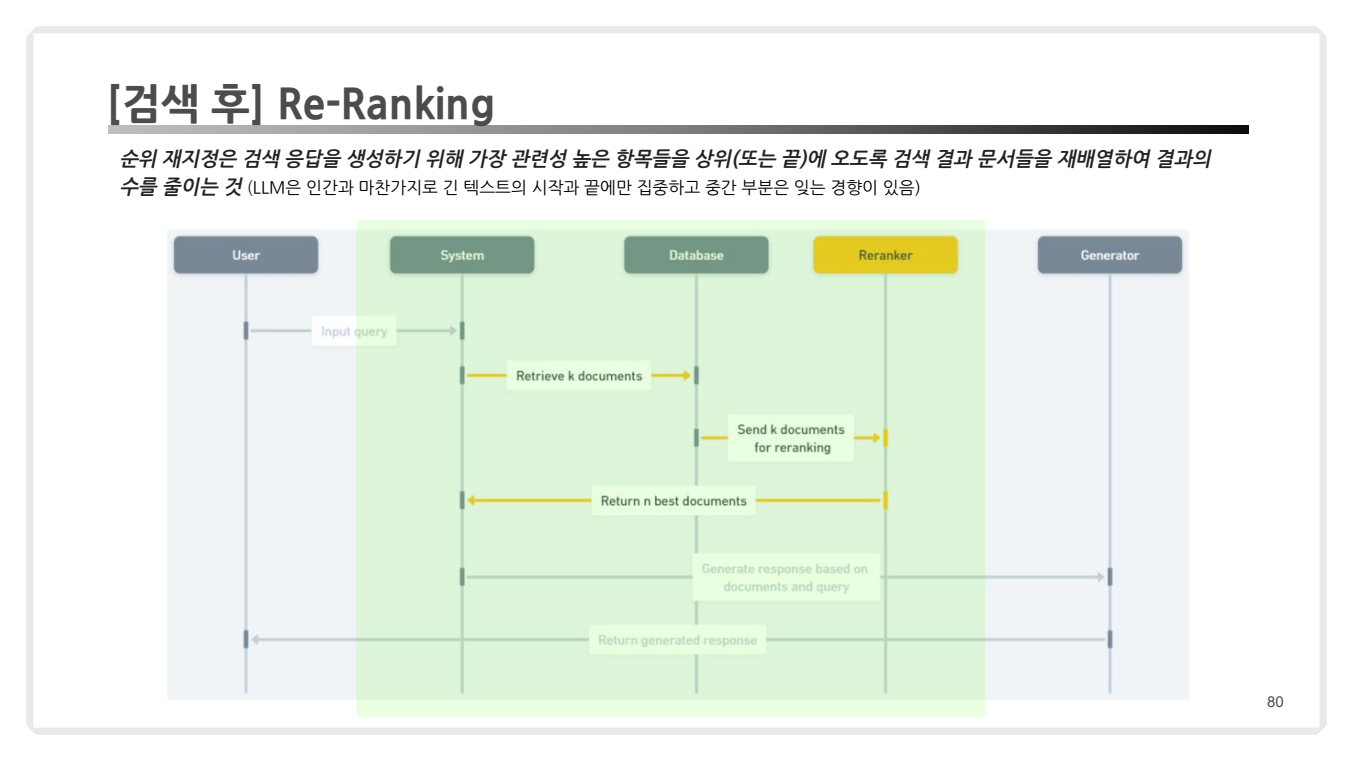
작동 원리
Re-Ranking의 작동 방식은 다음과 같습니다:
1. 초기 검색 결과 수집:
- Retriever(검색기)가 대규모 데이터셋에서 관련 후보 문서를 추출합니다.
- 이 단계에서 빠른 검색을 위해 Dense 혹은 Sparse 방식의 검색기가 주로 활용됩니다.
-
Re-Ranker로 순위 재조정:
- 초기 검색 결과와 질문을 입력으로 받아, 각 청크의 관련성 점수를 계산합니다.
- 계산된 점수를 기준으로 후보 문서의 순위를 재배치합니다.
-
상위 결과 반환:
- 설정된 상위 N개의 결과만 선택해 사용자가 확인할 수 있도록 제공합니다.
코드 예시
from langchain.retrievers import ContextualCompressionRetriever
from langchain_cohere import CohereRerank
# Cohere Reranker 설정
COHERE_API_KEY = "your_cohere_api_key"
reranker = CohereRerank(model="rerank-multilingual-v3.0", top_n=3)
# 리랭킹을 적용한 검색기 생성
reranking_retriever = ContextualCompressionRetriever(
base_compressor=reranker,
base_retriever=faiss_retriever # 초기 검색 단계에서 사용한 Retriever
)
# 질의에 따른 검색 실행
test_question = "2025년 한국 금리 전망은?"
retrieved_chunks = reranking_retriever.invoke(test_question)
# 최종 결과 확인
print(len(retrieved_chunks)) # 출력: 3
for chunk in retrieved_chunks:
print(chunk.page_content)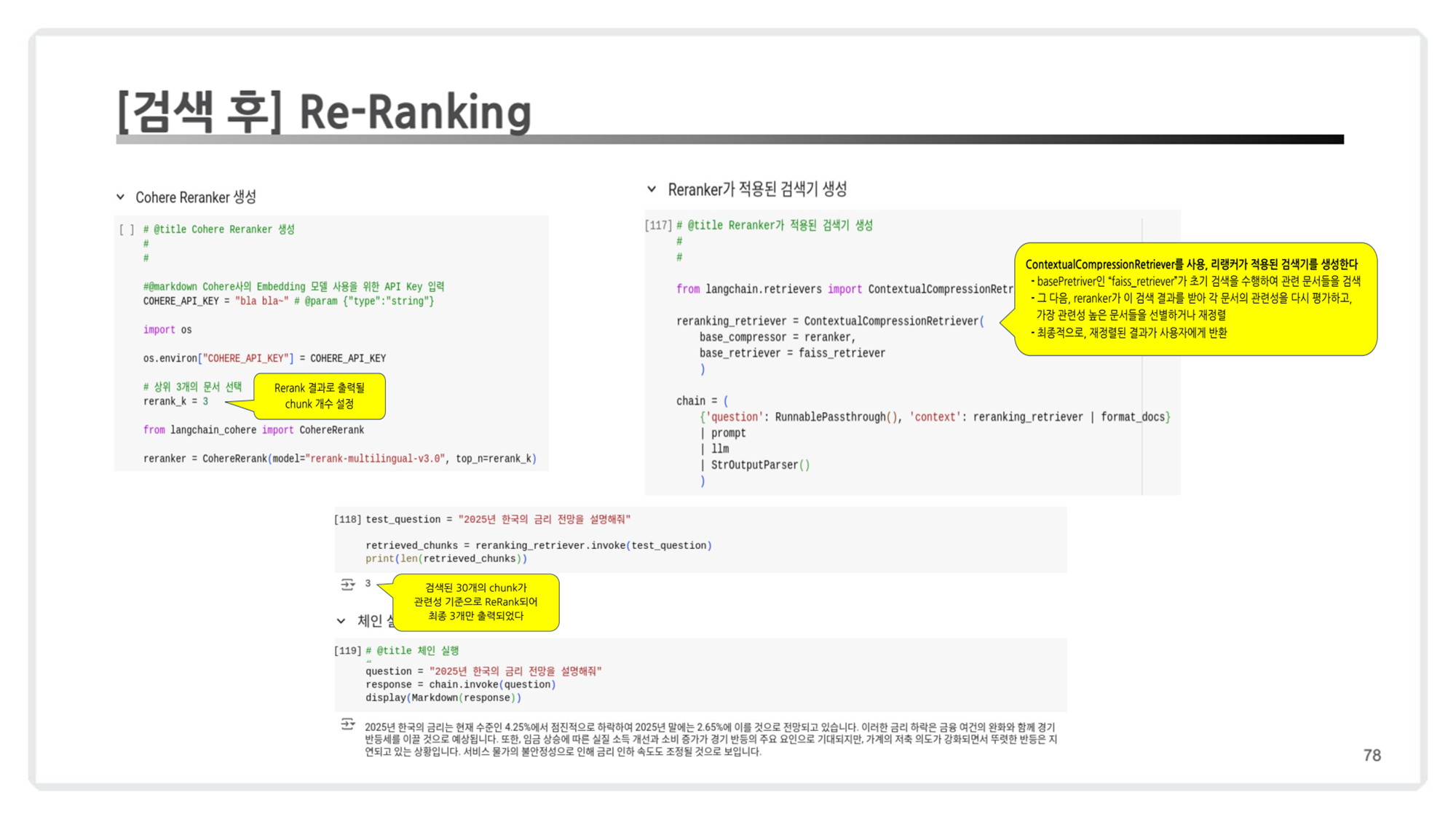
출력 결과 해석
retrieved_chunks의 길이는3으로, 초기 검색 결과30개중 가장 관련성이 높은3개의 문서만 최종적으로 반환되었습니다.- 최상위 문서들은 질문
"2025년 한국 금리 전망은?"과 관련성이 높은 내용을 포함하며, LLM이 활용 가능한 형태로 준비되었습니다.
이처럼 Re-Ranking은 초기 검색 결과를 최적화하여 사용자 질문에 가장 적합한 정보를 제공합니다.
6. 검색 후: Compression
Compression은 검색된 문서들의 길이를 줄이거나 요약(Summarization)하여 관련성이 높은 정보만 유지하는 과정입니다. 이는 LLM의 토큰 제한 문제를 극복하고 효율적인 문서 처리를 가능하게 합니다.
작동 원리
- 문서 압축 과정
- 초기 검색 결과는 여러 문서(chunk)로 구성됩니다.
ContextualCompressionRetriever는base_compressor와base_retriever를 결합하여 동작합니다.base_compressor로 LLM을 사용하여 문서를 압축하거나 필요한 정보를 요약합니다.
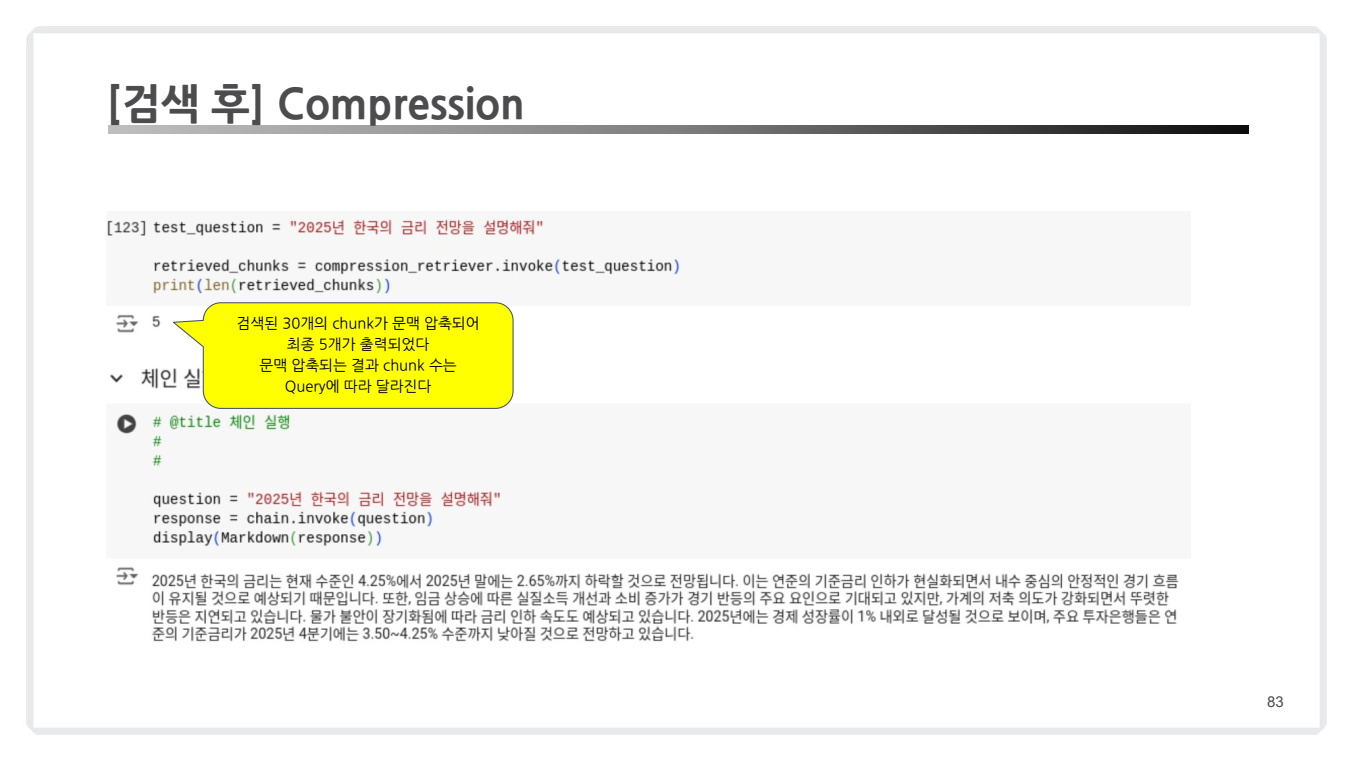
- 결과 비교
- 예시에서 초기 검색 결과는 30개의 chunk로 구성되었습니다.
- Compression 과정을 통해 5개의 chunk로 압축되었으며, 이는 Query의 맥락(Context)에 따라 달라질 수 있습니다.
코드 구현
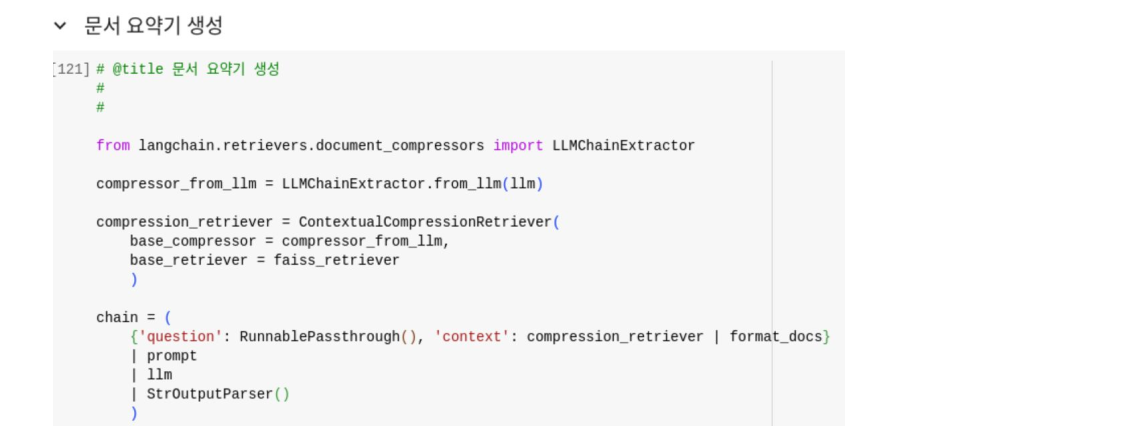
from langchain.retrievers.document_compressors import LLMChainExtractor
compressor_from_llm = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor_from_llm,
base_retriever=faiss_retriever
)위 코드를 통해 Compression 과정이 수행되며, 핵심적인 정보만 남기게 됩니다.
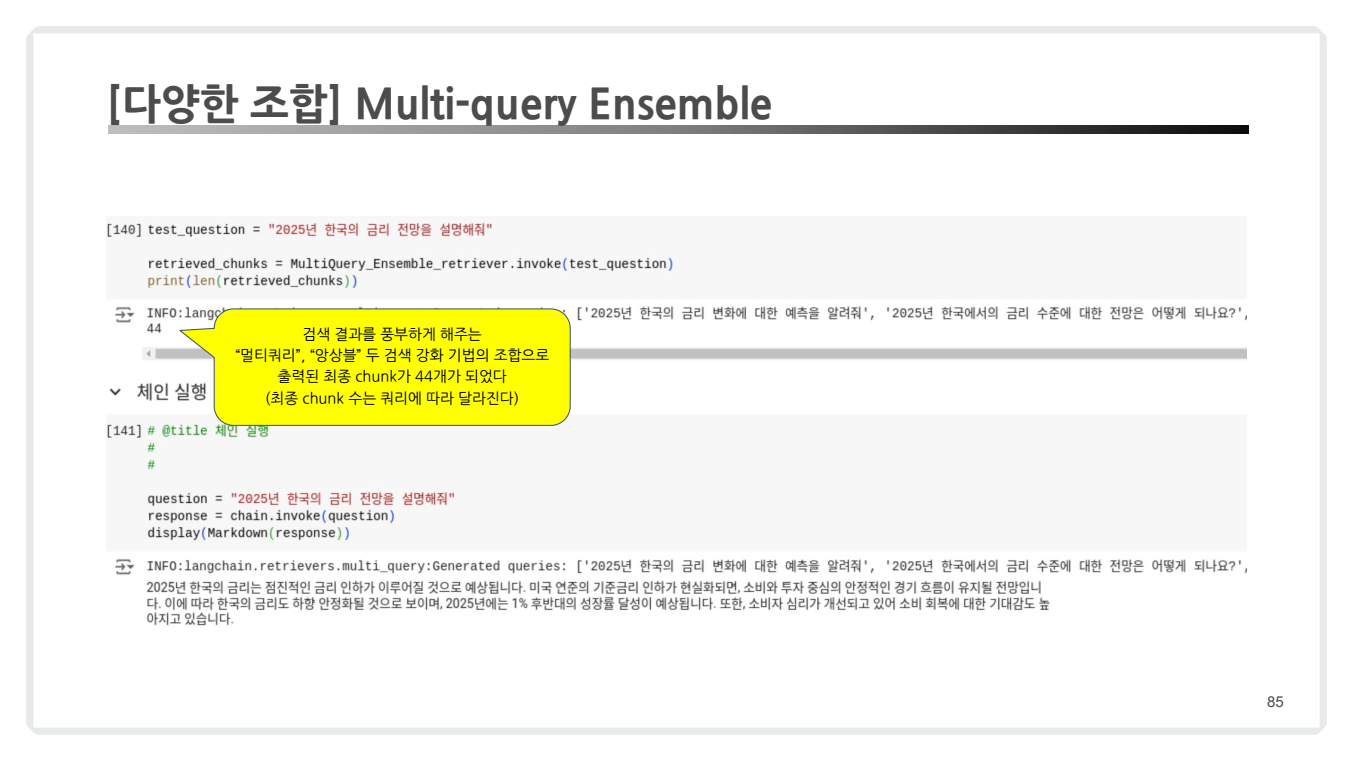
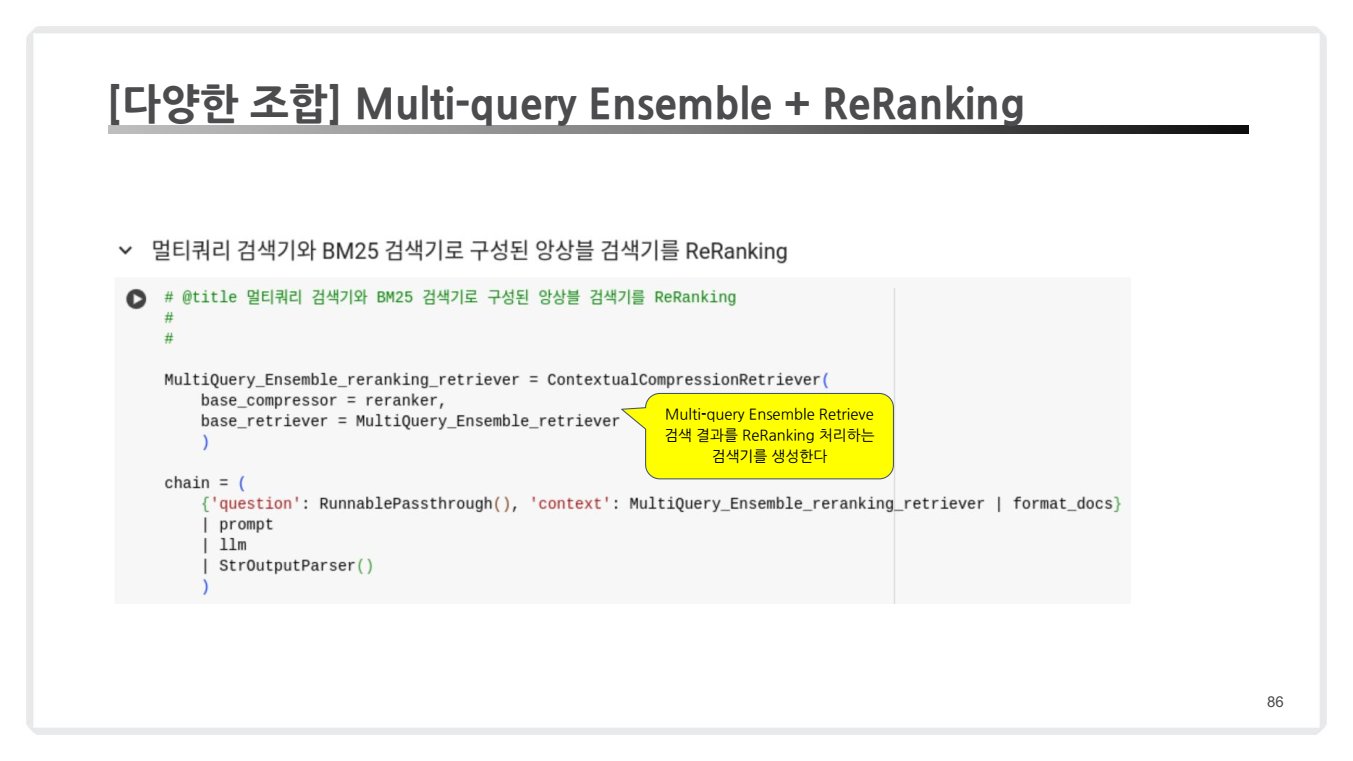
7. 다양한 조합: Multi-query Ensemble + Re-Ranking
이 접근 방식은 여러 검색 기법과 순위 조정(Re-Ranking)을 결합하여 검색 품질을 극대화하는 고급 RAG 기법입니다. 위 내용과 좀 유사한 부분들이 있긴 하지만 Multi-query Ensemble과 Re-Ranking을 같이 쓸 수 있다는 부분이 있다는 것을 강조하기 위해 별도로 챕터로 추가하신 것 같군요 🤔
구성 요소
-
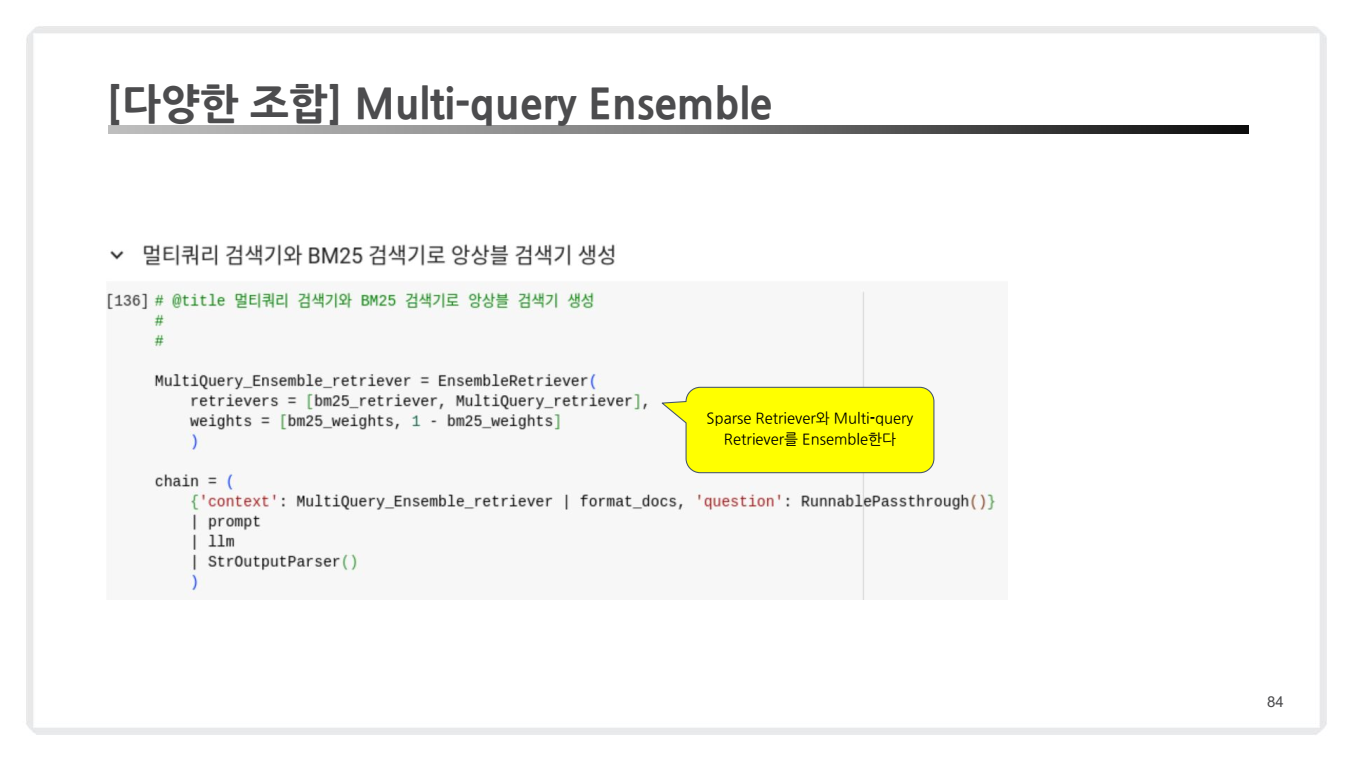
Multi-query Retrieval
Multi-query Retrieval은 하나의 질문을 다양한 관점으로 확장하여 검색 범위를 넓힙니다.
- 예: "2025년 한국 금리 전망" → "2025년 금리 변화 예측", "한국의 금리 수준 전망"
-
Ensemble Retrieval
Ensemble Retrieval은 Sparse Retriever(BM25)와 Dense Retriever를 조합합니다.
- 각 검색기의 결과에 가중치를 부여하여 검색 품질을 최적화합니다.
-
Re-Ranking
Re-Ranking은 Ensemble 검색 결과를 Re-Ranker로 다시 정렬합니다.
- LLM 기반 Re-Ranker를 사용하여 관련성이 높은 문서 순으로 재배치합니다.
작동 원리
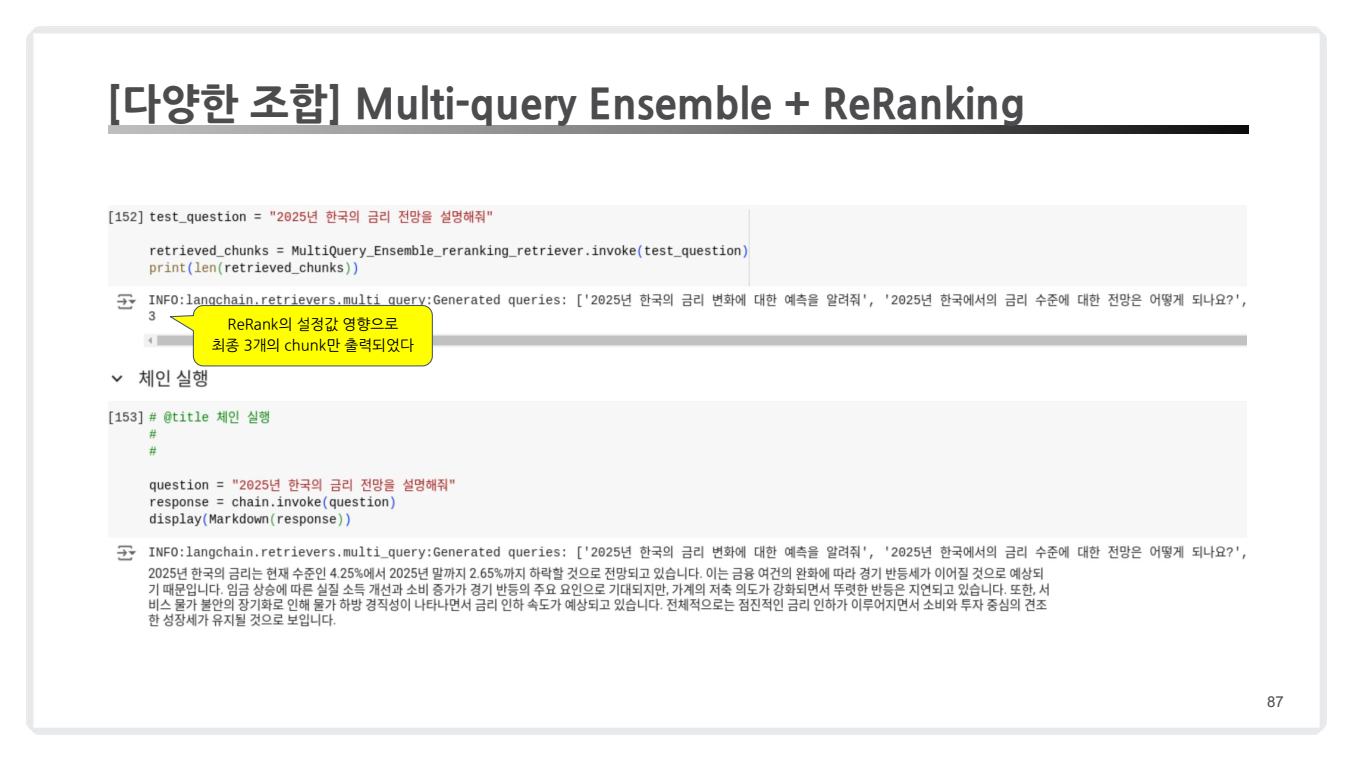
- Multi-query로 생성된 질문들은 Ensemble Retrieval로 처리됩니다.
- 검색된 결과(44개 chunk)는 ReRanking을 통해 3개의 chunk로 압축됩니다.
- 최종적으로 가장 관련성이 높은 문서들만 선택됩니다.
- Re-Ranking을 통해 검색 결과를 추가적으로 조정하여 최적의 답변을 생성합니다.
코드 구현
from langchain.retrievers.contextual_compression import ContextualCompressionRetriever
from langchain.retrievers import MultiQueryRetriever
from langchain.retrievers import EnsembleRetriever
from langchain.retrievers.document_compressors import CrossEncoderReranker
from langchain_community.cross_encoders import HuggingFaceCrossEncoder
# Define MultiQuery_Ensemble_reranking_retriever
MultiQuery_Ensemble_reranking_retriever = ContextualCompressionRetriever(
base_compressor=reranker,
base_retriever=MultiQuery_Ensemble_retriever
)8. 프로세스 증강(Process Augmentation)
프로세스 증강(Process Augmentation)은 단일 검색 및 생성 단계를 넘어 다단계 검색, 점진적 추론, 적응적 검색 방식을 도입하여 복잡한 문제를 해결하기 위한 접근법입니다. 이는 RAG(Retrieval-Augmented Generation)에서 정보를 보다 정교하고 효과적으로 사용할 수 있도록 설계되었습니다.
-
기존의 단일 검색과 응답 생성 프로세스는 제한된 정보만 제공하거나, 복잡한 문제를 충분히 해결하지 못할 수 있습니다.프로세스 증강은 다음과 같은 여러 단계를 통해 이를 보완합니다.Iterative Search(반복적 검색): 이전 결과를 기반으로 검색을 반복하여 더욱 풍부한 정보를 수집.Recursive Search(재귀적 검색): 문제를 세부적인 하위 문제로 분해하고 단계적으로 해결.Adaptive Search(적응적 검색): 검색과 생성 과정에서 상황에 따라 유연하게 처리.
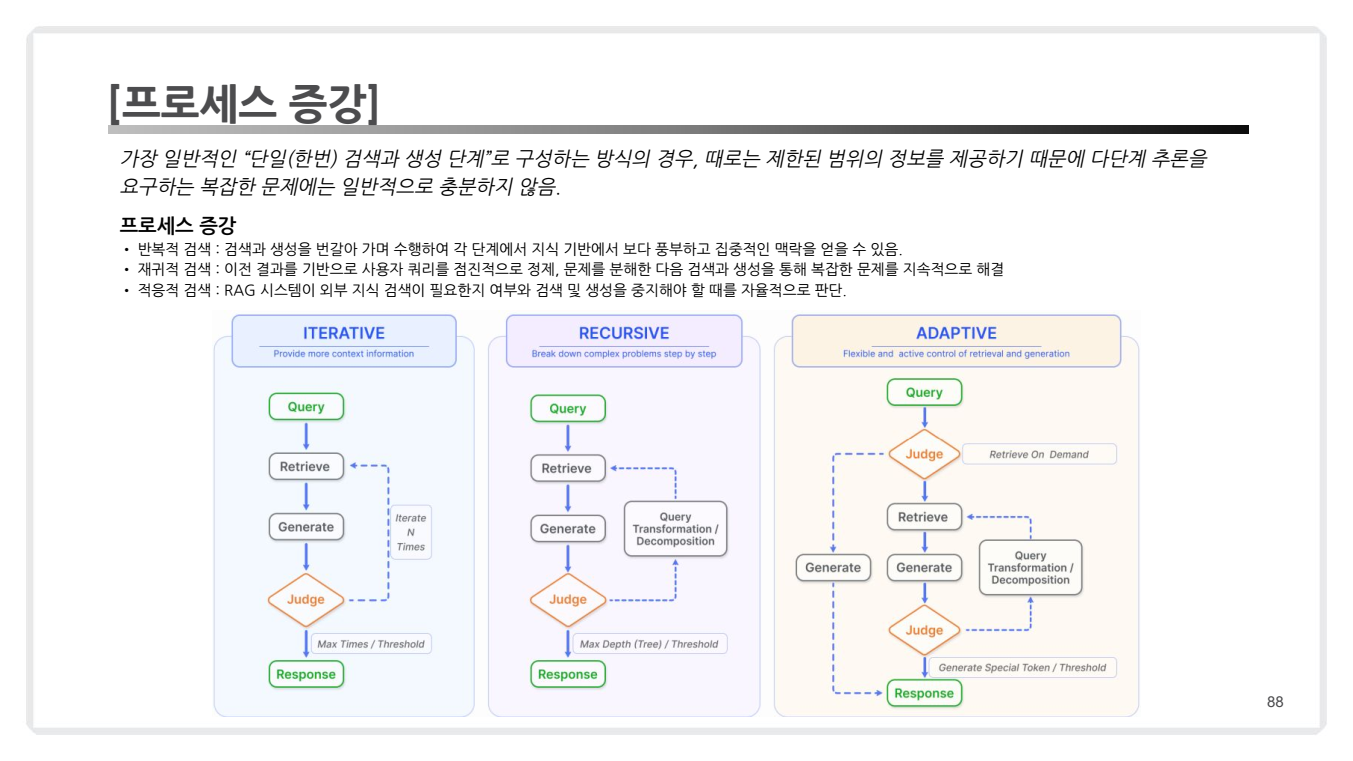
프로세스 증강 유형 (위 그림 참고)
1) Iterative Search (반복적 검색)
특징:- Query를 반복적으로 보강하여 관련 정보를 단계적으로 수집.
- Judge 단계를 통해 검색 및 생성의 정확도를 점검.
종료 조건:- 사전 설정된 최대 반복 횟수(Max Times) 또는 정확도 기준(Threshold)을 만족할 때 종료.
활용 사례:- 사용자의 추가적인 질문이 필요한 상황에서 점진적으로 답변을 완성.
2) Recursive Search (재귀적 검색)
특징:- 복잡한 문제를 하위 문제로 분해(Query Transformation).
- 문제를 점진적으로 해결하며 전체 답변을 생성.
종료 조건:- 설정된 최대 재귀 깊이(Max Depth) 또는 트리 구조 기반의 Threshold를 만족할 때 종료.
활용 사례:- 수학적 증명, 단계적 추론이 필요한 논리적 문제 해결.
3) Adaptive Search (적응적 검색)
특징:- 검색 필요성을 동적으로 판단하여 검색 또는 생성 프로세스를 선택.
- Generate 단계에서 특정 토큰(예: Special Token)을 생성하여 프로세스를 제어.
종료 조건:- 관련 정보가 충분히 수집되었거나 필요하지 않을 때 자동 종료.
활용 사례:- 실시간으로 변화하는 데이터나 외부 지식에 의존하는 응답 생성.
RAG 시스템 구현 예시
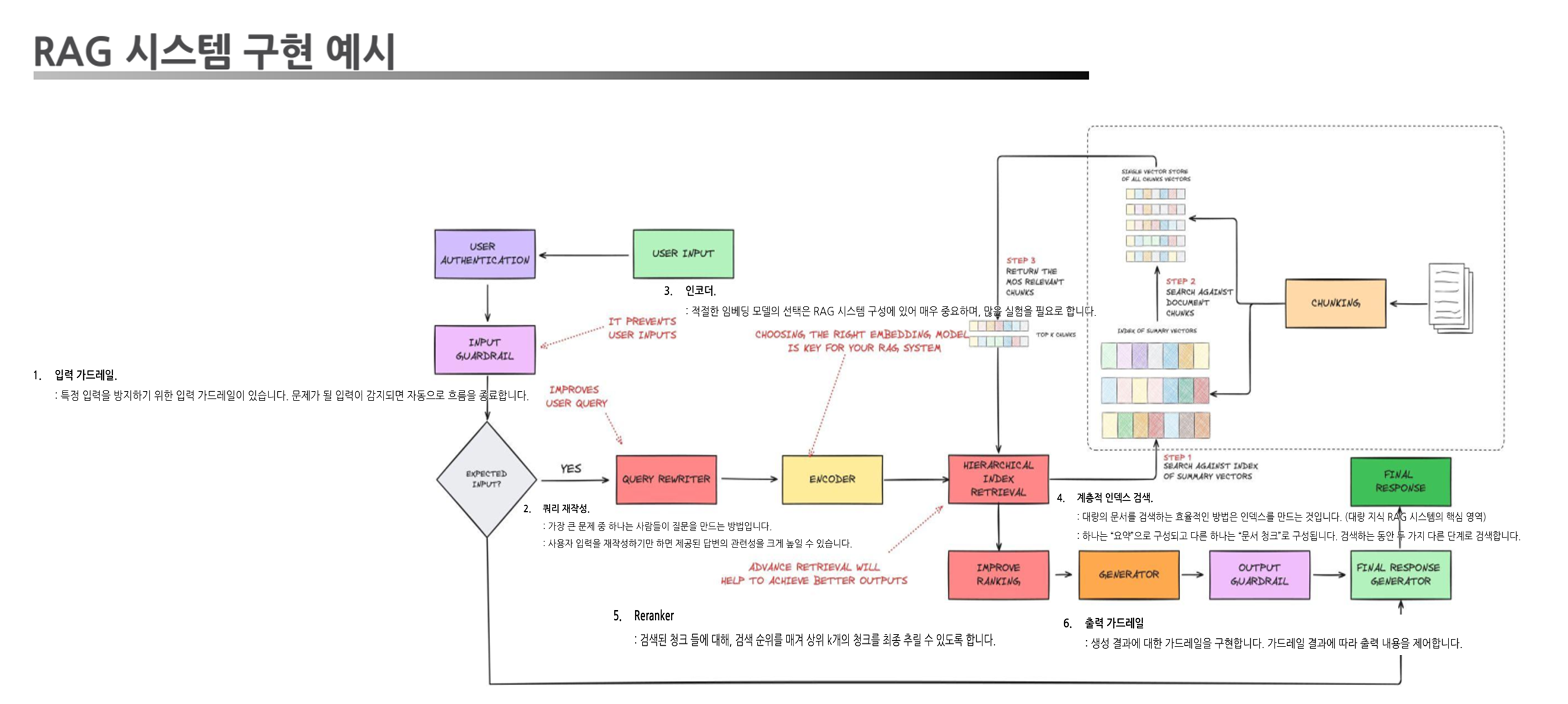
- 입력 처리: 사용자의 입력을 필터링 및 수정(가드레일 + 쿼리 재작성).
- 검색 단계: 쿼리를 임베딩하여 계층적 검색 수행.
- 결과 정제: 리랭커를 통해 검색 결과를 정제 및 순위 조정.
- 생성 단계: 선택된 청크를 바탕으로 답변 생성.
- 출력 처리: 생성된 답변이 적절한지 검증(출력 가드레일).
Chapter 4: RAG 평가하기
RAG 평가의 중요성
-
RAG 시스템의 품질을 평가하는 것은 모델 성능을 개선하고 신뢰도를 확보하기 위해 필수적입니다.
-
주요 평가 대상
검색 품질: 검색 결과의 정확성 및 관련성.생성 품질: LLM이 생성한 답변의 품질.사용자 경험: 실무에서의 응답 신뢰성과 일관성.
1. 유사도 및 관련성 평가
- 기본 평가 기준
- 검색된 문서의 벡터 유사도를 기반으로 검색 품질을 측정.
- 유사도 지표: Cosine Similarity 등.
- 평가 방식
- 벡터 데이터베이스에 저장된 벡터와 입력 벡터 간의 거리 계산.
- 유사도 점수를 기반으로 검색 결과의 품질을 평가.
측정 코드 예시
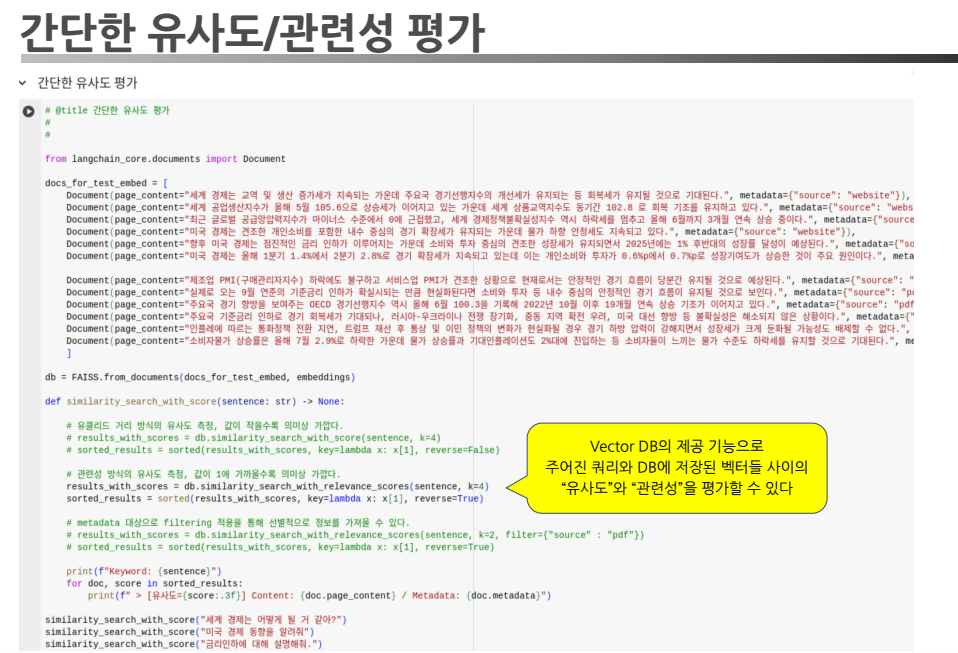
측정 출력 예시

2. LLM 평가 : Metric
2.1. 훌륭한 평가 지표의 조건

-
Quantitative (계량적):
- 점수 계산이 가능해야 하며, 품질 개선을 위해 시간에 따라 평가 점수의 변화를 모니터링할 수 있어야 합니다.
- 예: BLEU, ROUGE 같은 점수 기반 지표.
-
Reliable (신뢰성):
- 평가 결과에 일관성이 있어야 하며, 동일한 상황에서 평가를 반복했을 때 결과가 동일하게 나와야 합니다.
- 예: 통계적 평가 메트릭의 재현 가능성.
-
Accurate (정확성):
- 평가하려는 목표와 부합하며 부족함이 없어야 합니다.
- 예: Human Evaluation을 통한 정밀한 분석.
2.2. Types of Metric Scores
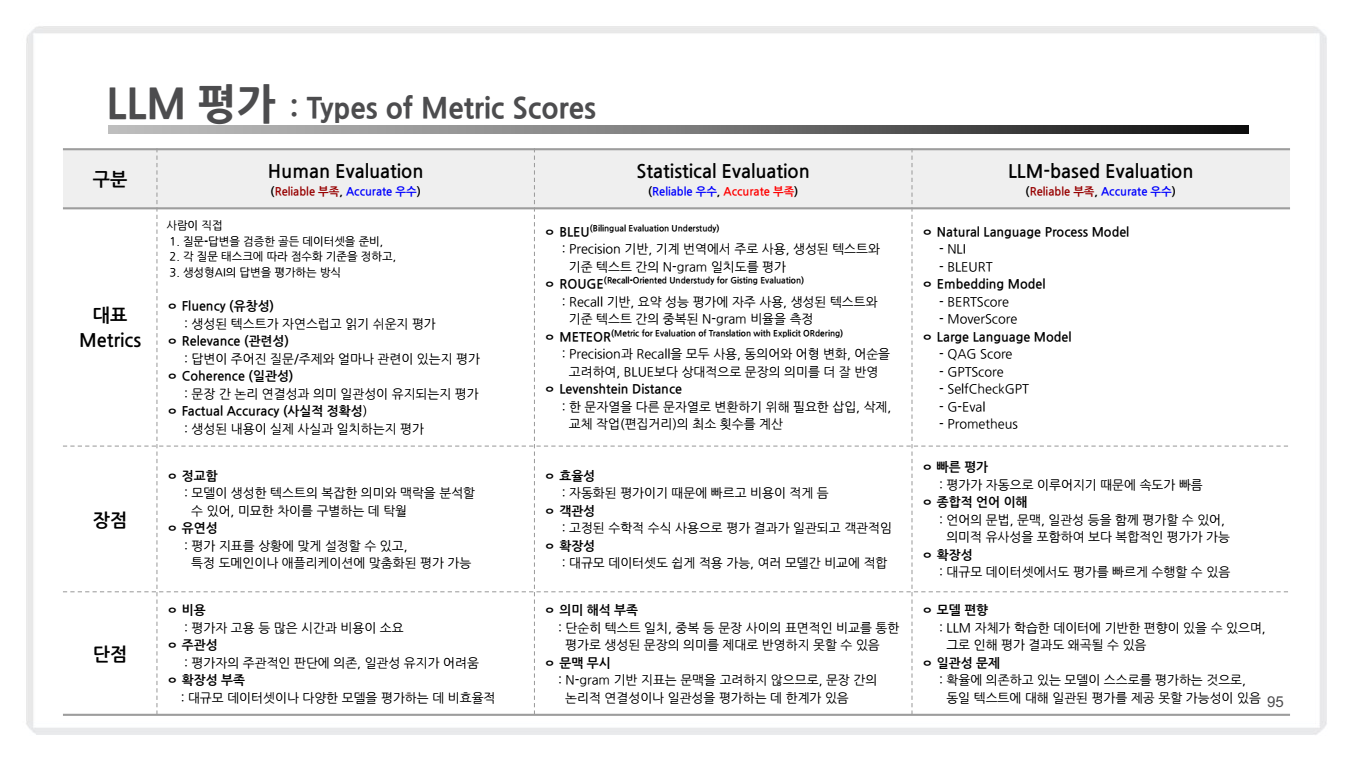
-
Human Evaluation
평가 방식: 사람이 직접 평가하여 생성된 텍스트의 유창성, 관련성, 논리적 일관성, 사실적 정확성을 판단합니다.장점: 실제 사용자 관점에서의 직관적인 평가 가능.단점: 비용과 시간이 많이 들며, 평가자의 주관이 결과에 영향을 줄 수 있습니다.
-
Statistical Evaluation
대표 메트릭: BLEU, ROUGE, METEOR, Levenshtein Distance.- BLEU (Bilingual Evaluation Understudy): N-gram 기반으로 문장의 정확도를 계산.
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation): 원문과 요약문 간의 N-gram 또는 단어의 중복 정도를 측정.
- METEOR (Metric for Evaluation of Translation with Explicit Ordering): 단어의 동의어와 어형 변화를 반영하여 BLEU보다 유연하게 평가.
- Levenshtein Distance: 텍스트 간의 편집 거리(삽입, 삭제, 교체)로 텍스트 간 차이를 계산.
장점: 자동화된 평가로 빠르고 비용 효율적.단점: N-gram 기반 평가로 문맥 및 의미를 충분히 반영하지 못할 가능성.
-
LLM-based Evaluation
-
평가 방식의 핵심 기술적 접근법과사용된 모델 또는 알고리즘의 종류에 따라 Natural Language Process Model, Embedding Model, Large Language Model로 메트릭을 구분할 수 있음.-
Natural Language Process Model: 논리적 관계와 문맥적 유사성 평가에 중점을 둡니다.- NLI (Natural Language Inference): 논리적 관계(포함, 모순, 중립)를 평가.
- BLEURT: 사전 훈련된 BERT 모델을 활용해 문맥적 유사성을 평가.
-
Embedding Model: 텍스트의 벡터 표현을 활용한 의미적 유사성 평가에 초점을 맞춥니다.- BERTScore: BERT 임베딩을 사용해 두 텍스트 간의 코사인 유사도를 계산.
- MoverScore: Earth Mover’s Distance(EMD)를 사용하여 텍스트 간 단어 이동 거리(Transport Cost)를 측정.
-
Large Language Model: 대규모 언어 모델을 활용한 다각적이고 고차원적인 평가가 가능합니다.- QAG Score: 질문 생성과 정답 비교를 통해 텍스트의 핵심 정보와 사실성을 평가.
- GPTScore: GPT 모델의 생성 확률 기반으로 텍스트의 자연스러움과 일관성을 평가.
- SelfCheckGPT: 모델이 생성한 텍스트의 품질을 스스로 평가하여 응답의 일관성과 정보의 사실성을 점검.
- G-Eval: Chain-of-Thought(CoT) 및 프롬프트 기반으로 작업별 평가 기준에 따라 생성 텍스트를 평가.
- Prometheus: 다중 지표 기반으로 특정 도메인이나 작업 목적에 맞춘 맞춤형 평가.
-
-
장점: LLM을 활용하여 고차원적인 평가 가능. -
단점: 평가 모델의 편향성에 따라 결과가 왜곡될 가능성.
-
(참고) 분류에 따라서는 아래와 같이도 정의될 수도 있음.
- Statistical Scorers는 통계적 평가 방식을 사용하는 메트릭들로, 주로 N-gram과 같은 언어 통계적 특징에 기반하여 텍스트 간의 유사도를 계산합니다.
- Model-Based Scorers는 사전 훈련된 모델을 활용하여 텍스트 간의 의미적 유사성을 평가하거나, 모델이 생성한 응답 자체를 평가합니다.
- 교집합(Statistical ∩ Model-Based)은 양쪽 특성을 모두 가지고 있다고 해석할 수 있습니다.
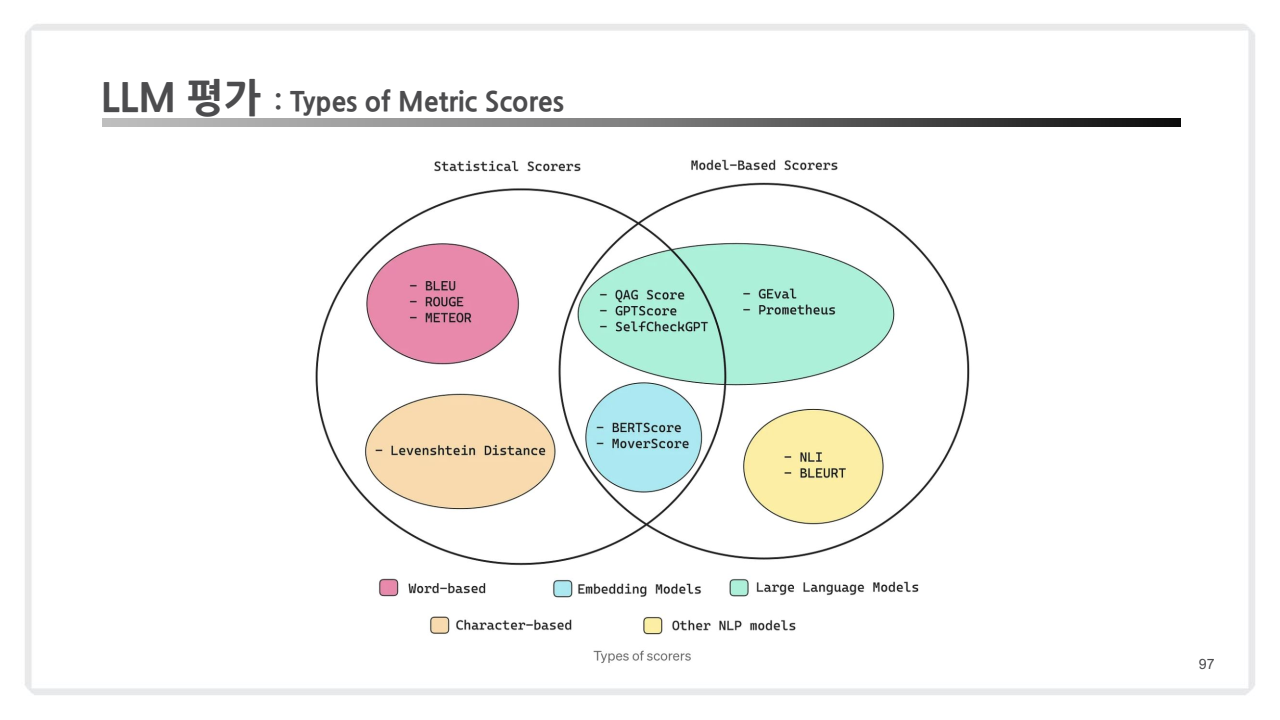
| 구분 | Statistical Scorers | Model-Based Scorers | 교집합 |
|---|---|---|---|
| 평가 방식 | 단순 N-gram 일치, 통계적 거리 계산 | 사전 훈련된 NLP 모델 활용 | 통계적 계산 + 임베딩 기반 의미 평가 |
| 장점 | 빠르고 비용 효율적, 자동화 가능 | 문맥적 의미와 구조적 평가 가능 | 효율성과 정확성을 균형 있게 결합 |
| 단점 | 문맥 반영 부족, 의미적 연결성 미흡 | 계산 비용 높음, 편향 가능성 | 계산 비용과 도메인 의존성 일부 존재 |
| 대표 메트릭 | BLEU, ROUGE, METEOR, Levenshtein Distance | BERTScore, GPTScore, SelfCheckGPT, Prometheus | BERTScore, MoverScore |
2.3. Strategies for LLM Evaluation
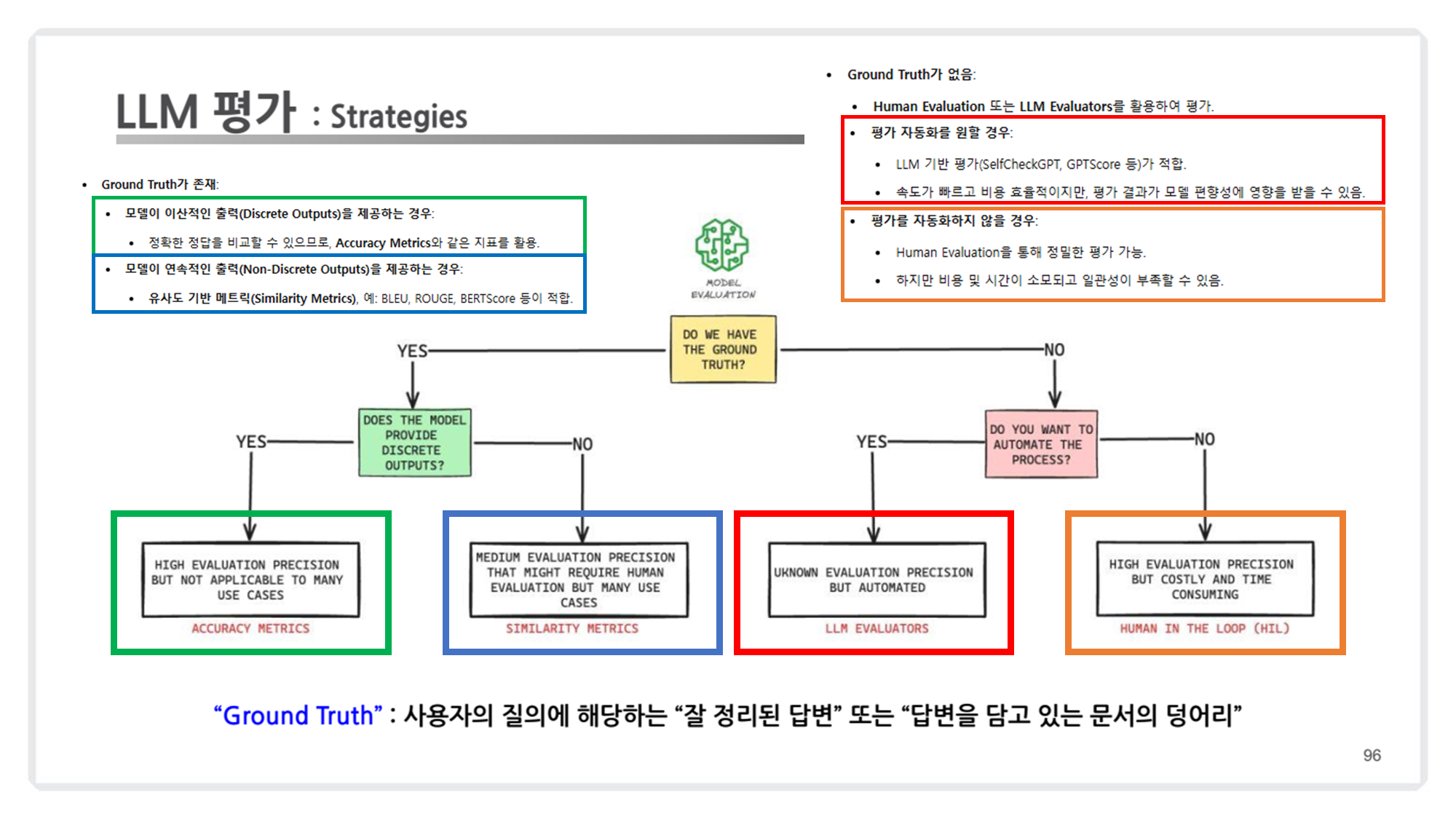
-
모델 출력의 형태와 평가 목표 정의: 정답이 명확한지, 아니면 유사성이나 품질 평가인지.
-
자동화의 가능성 및 비용 효율성 고려: Human Evaluation을 포함할지, LLM 기반으로 대체할지.
-
상황에 맞는 메트릭 선택: Accuracy, Similarity, Creativity 등.
2.4. LLM 평가 메트릭의 세부 내용
아래는 LLM(Large Language Model)을 평가하는 LLM 평가 메트릭에 대해서 강의 내용과 해당 내용을 보충할만한 자료를 추가적으로 첨부한 내용입니다.
1. NLI (Natural Language Inference)
- 설명:
- NLI는 자연어 추론을 통해 두 텍스트(
기준 텍스트와생성 텍스트)가 논리적으로 얼마나 관련이 있는지를 평가합니다.

- 기준 텍스트(Premise)를 전제로 삼고, 생성된 텍스트를 가설(Hypothesis)로 보아 둘 간의 관계를 분석합니다.
- 포함(Entailment): 가설이 전제를 지지합니다.
- 모순(Contradiction): 가설이 전제와 충돌합니다.
- 중립(Neutral): 두 문장이 논리적으로 연관은 있지만 직접적으로 지지하거나 모순되지 않습니다.
- NLI는 자연어 추론을 통해 두 텍스트(

-
특징:
- NLI는 생성된 텍스트와 기준 텍스트 간의 논리적 관계를 평가하며, 의미적 일관성을 분석합니다.
-
장점:
- NLI는 단순 단어 매칭이 아니라, 텍스트의 논리적 관계를 평가합니다.
- 번역, 요약, 정보 추출 등 다양한 작업에 적합합니다.
-
단점:
- 모델이 텍스트 간 관계를 충분히 이해하지 못하면 평가가 어려워질 수 있습니다.
- 텍스트 복잡성에 따라 민감하게 작동합니다.
2. BLEURT (Bilingual Evaluation Understudy with Representations from Transformers)
- 설명:
- BLEURT는 BERT를 기반으로 구축된 평가 모델입니다. 사전 학습된 BERT 모델이 문맥을 이해하며,
기준 텍스트와생성 텍스트간의 의미적 유사성을 평가합니다. - BLEURT는 단순한 단어 매칭 방식이 아닌, 문장의 깊은 의미와 문맥적 일치를 측정합니다.

- BLEURT는 BERT를 기반으로 구축된 평가 모델입니다. 사전 학습된 BERT 모델이 문맥을 이해하며,
-
특징:
- BLEURT는 문맥적 의미를 반영하여 두 텍스트가 얼마나 유사한지 평가합니다.
-
장점:
- 단순 통계적 평가보다 문장의 의미 차이를 세밀하게 반영합니다.
- BLEU와 ROUGE보다 정확한 평가를 제공합니다.
- 사전 훈련된 BERT를 사용해 빠르고 효과적으로 평가합니다.
-
단점:
- BERT 모델 사용으로 인해 자원이 소모될 수 있습니다.
- 특정 도메인에서는 적응력이 낮을 수 있습니다.
3. BERTScore
- 설명:
- BERTScore는 BERT 임베딩을 사용하여
생성된 텍스트와기준 텍스트의 의미적 유사성을 벡터 공간에서 측정합니다. - 단어 간의 코사인 유사도를 계산하여 두 텍스트가 얼마나 비슷한지를 점수로 산출합니다.

- BERTScore는 BERT 임베딩을 사용하여

-
특징:
- BERTScore는 BERT의 문맥 이해 능력을 활용하여 단순한 n-gram 기반 점수보다 정확하게 의미와 유사성을 평가합니다.
-
장점:
- 높은 의미적 정확도를 제공합니다.
- 번역, 요약, 생성 텍스트 평가 등 다양한 작업에 활용할 수 있습니다.
-
단점:
- 계산에 많은 자원이 소모될 수 있습니다.
- BERT 훈련 도메인과 다른 도메인에서는 정확도가 떨어질 수 있습니다.
4. MoverScore
- 설명:
- MoverScore는 Earth Mover’s Distance (EMD) 개념을 활용하여 생성된 텍스트와 기준 텍스트의 의미적 유사성을 계산합니다.
- 단어 임베딩 벡터 간의 이동 거리(이동 비용)를 최소화하여 두 텍스트가 얼마나 유사한지를 평가합니다.


-
특징:
- 단어 이동 거리 기반 평가로 의미적으로 비슷한 단어들 간의 유사성을 반영합니다.
-
장점:
- 단어 이동 거리 기반으로 정밀한 유사성을 측정할 수 있습니다.
- 번역, 요약 등 다양한 NLP 작업에 활용됩니다.
-
단점:
- 이동 거리 계산이 복잡하고 자원이 많이 소모됩니다.
- 긴 문장은 단어 수준에서 평가하기 어려울 수 있습니다.
5. GPTScore
- 설명:
- GPTScore는 GPT와 같은 대형 언어 모델(LLM)의 임베딩을 사용하여 문맥적 의미와 문장의 자연스러움을 평가합니다.
- 생성된 문장의 각 토큰(단어)이 주어진 조건에서 얼마나 높은 확률로 생성되었는지를 점수화합니다.


-
특징:
- GPTScore는 단어 수준을 넘어 문장 전체의 의미적 유사성과 문맥적 자연스러움을 측정합니다.
-
장점:
- 대형 언어 모델의 강력한 문맥 이해 능력을 활용합니다.
- 번역, 요약, 생성 텍스트 평가 등 다양한 작업에 적용 가능합니다.
-
단점:
- 사용된 모델에 따라 성능이 제한될 수 있습니다.
- 계산 비용이 많이 소모됩니다.
6. QAG Score (Question-Answer Generation)
- 설명:
- QAG는 질문-답변 생성 방식을 활용하여
생성된 텍스트와기준 텍스트간의 사실적 일관성을 평가합니다.
- 기존 Question Generation과의 차이점은 생성된 텍스트에서 질문을 만들고, 이에 대한 답변이 기준 텍스트와 일치하는지를 확인합니다.

- QAG는 질문-답변 생성 방식을 활용하여

(참고) 해당 논문은 Question-Answer Generation Task Pipeline을 다루긴 했지만, 정확하게 Scoring에 대해서 다루고 있지 않습니다.
-
특징:
- 질문-답변 형식으로 텍스트의 핵심 의미를 평가합니다.
-
장점:
- 텍스트의 사실적 품질을 정밀하게 평가합니다.
- 질문과 답변 방식으로 텍스트의 핵심 정보를 효과적으로 반영합니다.
-
단점:
- 추가적인 질문 생성 과정이 필요해 시간이 소요됩니다.
- QA 모델의 성능에 따라 평가 결과가 달라질 수 있습니다.
7. SelfCheckGPT
- 설명:
- SelfCheckGPT는 모델이 스스로 텍스트의 품질을 평가합니다.
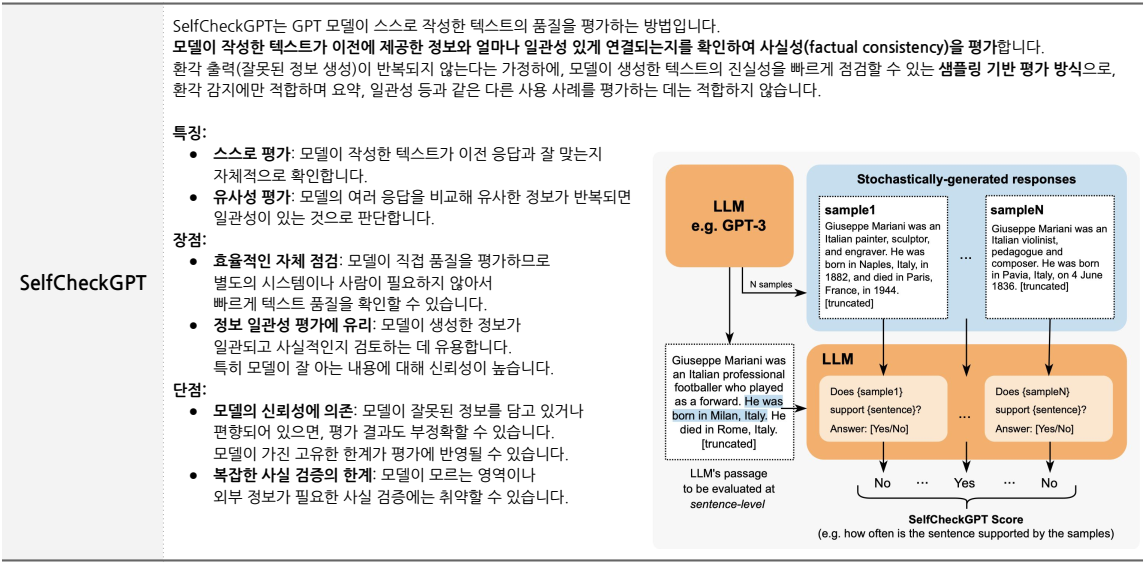
- 모델이 작성한 여러 응답을 비교해 유사성이 반복되면 일관성이 있는 것으로 간주합니다.
- SelfCheckGPT는 모델이 스스로 텍스트의 품질을 평가합니다.

-
특징:
- 생성된 텍스트가 이전 정보와 얼마나 잘 연결되는지를 점검합니다.
-
장점:
- 사람이 필요 없이 모델이 스스로 텍스트 품질을 점검할 수 있습니다.
- 정보 일관성과 사실성을 평가하는 데 유용합니다.
-
단점:
- 복잡한 사실 검증에는 약합니다.
- 모델의 신뢰성에 따라 결과가 영향을 받을 수 있습니다.
8. G-Eval
- 설명:
- G-Eval은 GPT-4를 기반으로 CoT (Chain-of-Thought)와 양식 채우기(Form-filling) 방식을 결합하여 평가 기준을 제시합니다.

- 평가 항목(예: 일관성, 정확성 등)을 정의하고 이에 따라 점수를 매깁니다.
- G-Eval은 GPT-4를 기반으로 CoT (Chain-of-Thought)와 양식 채우기(Form-filling) 방식을 결합하여 평가 기준을 제시합니다.

-
특징:
- 평가 기준을 세분화하여 정밀한 평가를 수행합니다.
-
장점:
- 다양한 작업에서 맞춤형 평가가 가능합니다.
- CoT 방식으로 평가의 정밀도가 높아집니다.
-
단점:
- 프롬프트 설계가 잘못되면 평가 결과에 부정적인 영향을 미칠 수 있습니다.
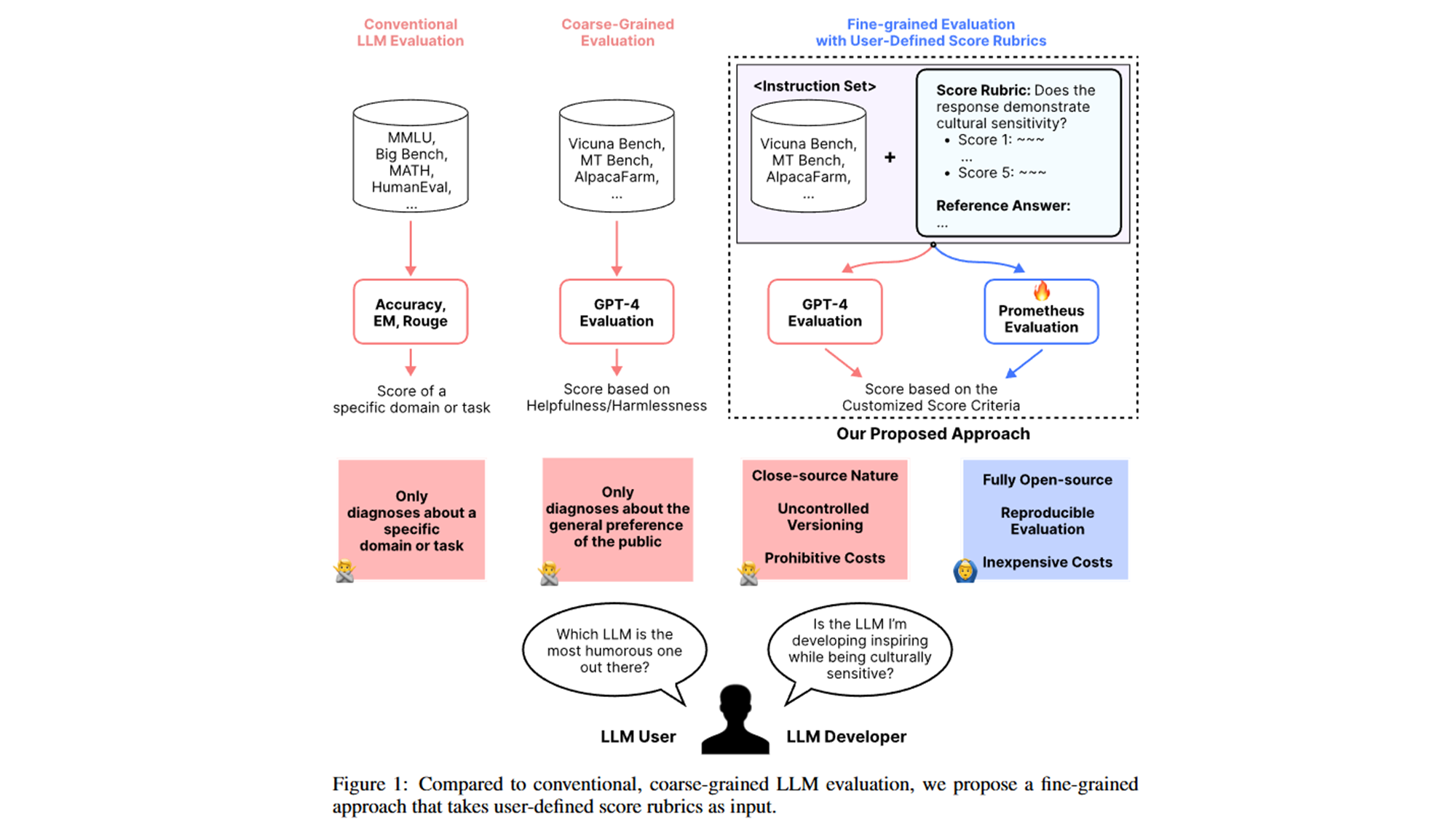
9. Prometheus
- 설명:
- Prometheus는 한국과학기술원(KAIST)과 LG AI연구원이 개발한 오픈 소스 평가 프레임워크로, 특정 도메인이나 애플리케이션에 맞춰 평가 기준을 설정할 수 있습니다.

- Prometheus는 한국과학기술원(KAIST)과 LG AI연구원이 개발한 오픈 소스 평가 프레임워크로, 특정 도메인이나 애플리케이션에 맞춰 평가 기준을 설정할 수 있습니다.

-
특징:
- 사전 정의된 평가 프로토콜을 사용하며, 다양한 평가 지표(정확성, 유창성, 일관성, 사실성 등)를 제공합니다.
-
장점:
- 다양한 지표와 사용자 맞춤형 평가를 제공합니다.
- 특정 도메인에 국한되지 않고 유연하게 적용할 수 있습니다.
-
단점:
- 프롬프트 설계가 평가 결과에 큰 영향을 미칠 수 있습니다.
3. RAG 평가
아래는 RAG(Retrieval-Augmented Generation)를 평가하는 RAG 평가 메트릭에 대해서 강의 내용과 해당 내용을 보충할만한 자료를 추가적으로 첨부한 내용입니다.
Background
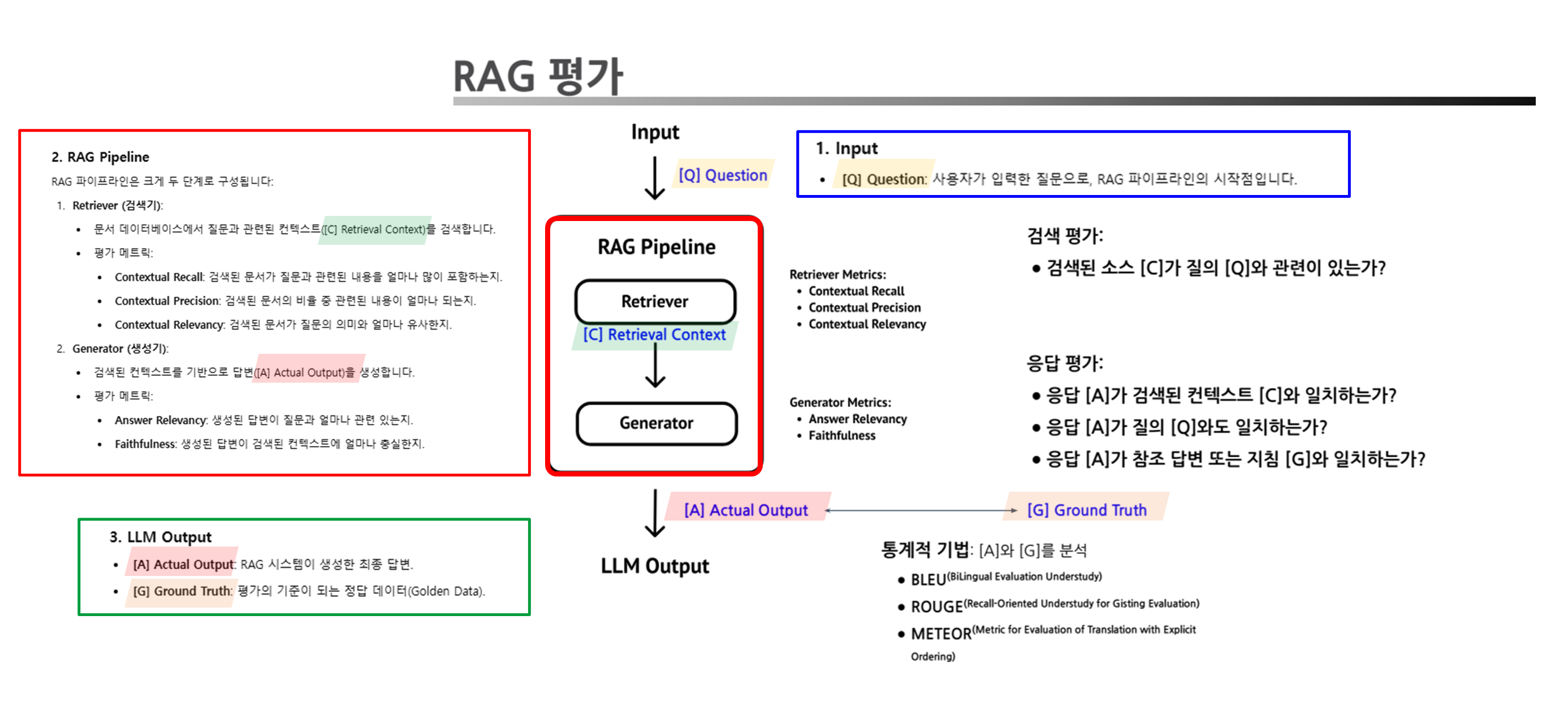
RAG 시스템은 검색 단계와 생성(답변) 단계의 평가가 모두 중요합니다.
- 각 단계의 세부 평가 요소와 방법은 다음과 같습니다.
1. Input
- [Q] Question: 사용자가 입력한 질문으로, RAG 파이프라인의 시작점입니다.
2. RAG Pipeline
RAG 파이프라인은 크게 두 단계로 구성됩니다:
Retriever (검색기):- 문서 데이터베이스에서 질문과 관련된 컨텍스트([C] Retrieval Context)를 검색합니다.
💬 검색 평가
목적: 검색된 컨텍스트가 사용자의 질문에 얼마나 관련성이 있는지를 평가합니다.
- 검색된 컨텍스트(
[C] Retrieval Context)가 질문([Q] Question)과 얼마나 관련이 있는지 확인합니다.평가 메트릭:
- Contextual Recall: 검색된 문서가 질문과 관련된 내용을 얼마나 많이 포함하는지.
- Contextual Precision: 검색된 문서의 비율 중 관련된 내용이 얼마나 되는지.
- Contextual Relevancy: 검색된 문서가 질문의 의미와 얼마나 유사한지.
Generator (생성기):- 검색된 컨텍스트를 기반으로 답변([A] Actual Output)을 생성합니다.
💬 생성 평가
목적: 생성된 답변이 검색된 문서 및 질문에 얼마나 잘 부합하는지를 평가합니다.
- 생성된 답변(
[A] Actual Output)이 검색된 컨텍스트([C] Retrieval Context), 질문([Q] Question), Ground Truth([G] Ground Truth)와 얼마나 일치하는지 평가합니다.평가 메트릭:
- Answer Relevancy: 생성된 답변이 질문과 얼마나 관련 있는지.
- Faithfulness: 생성된 답변이 검색된 컨텍스트에 얼마나 충실한지.
3. LLM Output
- [A] Actual Output: RAG 시스템이 생성한 최종 답변.
- [G] Ground Truth: 평가의 기준이 되는 정답 데이터.
3.1 Model-based Scorer
RAG 평가에서 LLM Evaluation Metric을 사용하여 질문, 검색된 컨텍스트, 생성된 답변, Ground Truth(Golden Data)를 기반으로 점수를 산출하는 과정을 보여줍니다.
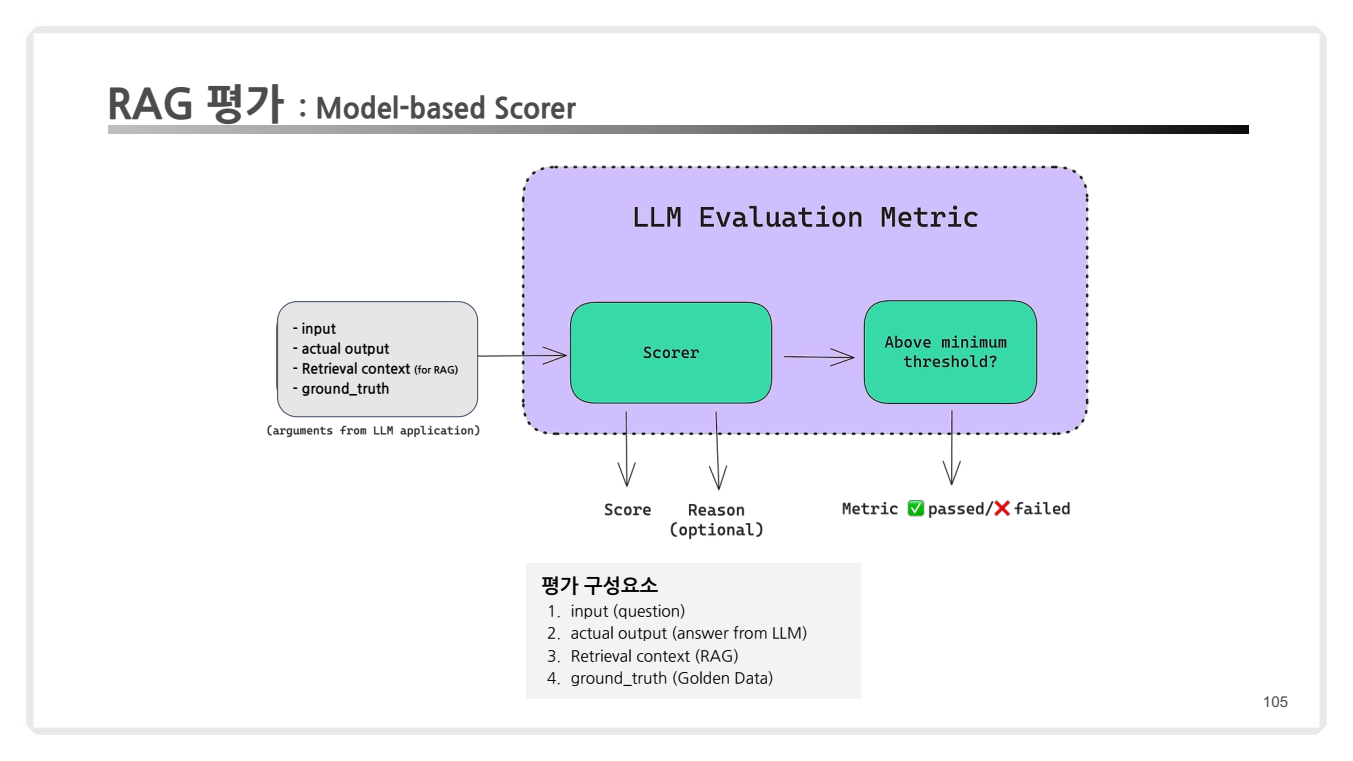
1. 입력/평가 요소
RAG 평가에 필요한 주요 입력 값(arguments from LLM application)들은 다음과 같습니다:
- Input (질문): 사용자가 입력한 질문.
- Actual Output (실제 출력): RAG 시스템이 생성한 답변.
- Retrieval Context (검색 컨텍스트): 질문에 대해 검색된 관련 문서나 텍스트.
- Ground Truth (정답 데이터): 이상적인 정답 데이터를 제공하는 기준 값.
2. LLM Evaluation Metric
-
Scorer (점수 산출기):
- 입력 요소들(Input, Actual Output, Retrieval Context, Ground Truth)을 비교하여 점수를 산출합니다.
- 예: Fine-tuned BERT, GPT 모델이 입력 값과 출력 값 간의 유사성을 계산.
-
Thresholding (임계값 평가):
- Scorer가 산출한 점수를 기준으로 최소 임계값(Threshold)을 설정합니다.
- 점수가 임계값을 초과하면 "Passed(✔️)"로 평가되고, 그렇지 않으면 "Failed(❌)"로 평가됩니다.
-
Score와 Reason(Optional):
- 점수와 함께 선택적으로 이유(Reason)를 제공하여 왜 해당 점수를 받았는지 설명할 수 있습니다.
3.2 Ground Truth
1. Ground Truth란?
-
정의: Ground Truth는 사용자의 질문에 적합한 이상적인 답변이나 문서의 청크를 말합니다.
- 이는 RAG 시스템에서 평가 기준 데이터로 사용됩니다.

- 이는 RAG 시스템에서 평가 기준 데이터로 사용됩니다.
-
특징:
- 정답 데이터: 학습 및 평가 과정에서 모델의 성능을 판단하는 기준점 역할.
- End-to-End 평가: RAG 시스템의 검색 및 생성 과정을 종합적으로 비교 평가할 수 있도록 함.
- 이상적 상태: 실제 현장에서 준비하기 어렵고, 많은 비용과 노력이 필요.
🏆 Golden Data ?
- Ground Truth는 학습 및 평가 기준이 되는 데이터라면, Golden Data는 그 데이터를 기반으로 구체적인 평가를 위한 샘플링된 데이터를 의미합니다.
- Golden Data는 Ground Truth 데이터를 특정 목적에 맞게 선별하여 구성합니다.

그렇다면 이러한 Ground_truth는 어떻게 말들 수 있을까요?
2. Ground Truth 생성 과정
아래 이미지에서 제시된 내용은 Ground Truth를 생성하는 일반적인 과정입니다.

각 단계는 다음과 같습니다:
(1) 문서 파싱 및 전처리
- PDF/원문 문서 처리:
- 원본 문서를 읽어서 텍스트로 변환(parsing).
- 긴 텍스트를 적절한 크기로 나누는 chunking 작업을 수행.
- 청크 단위 생성:
- 텍스트를 짧은 문장이나 단락으로 분리하여 평가 단위로 사용.
(2) 질문 생성
- Random Pick:
- 생성된 청크 중 일부를 무작위로 선택. (random ground truth)
- 질문 생성:
- 선택된 청크를 기반으로 관련된 질문을 자동 생성.
- 예를 들어:
- 텍스트 청크: "I like apple. I mean the fruit apple, not the smartphone."
- 생성된 질문: "What is your favorite fruit?"
(3) 답변 생성
- Retrieval GT(검색 기반 정답):
- 선택된 청크(retrieval ground truth)를 기반으로 답변 생성.
- Generation GT(생성 기반 정답):
- 질문과 관련된 문서를 기반으로 적절한 답변을 생성.
(4) 결과 검토
- 생성된 질문-답변 쌍의 품질을 수동으로 검토하거나 LLM 기반 자동화 도구를 활용하여 최종 Ground Truth 품질을 보장.
3.3 RAG 평가를 위한 Framework
강의 자료에서는 대표적인 평가 프레임워크(Evaluation Framework)로 Ragas와 DeepEval, 그리고 Pheonix를 예로 듭니다.

세 프레임워크 모두 대형 언어 모델(LLM) 애플리케이션의 성능을 평가하고 개선하는 데 사용되는 도구입니다.
Ragas
Ragas는 문서에서 청크를 생성하고 질문-답변 쌍을 자동으로 생성하는 도구입니다.
Ragas의 주요 특징은 다음과 같습니다:
자동화된 데이터 생성: 문서로부터 청크를 추출하고, 이를 바탕으로 질문-답변 쌍을 자동으로 생성합니다.비용 효율성: 데이터 생성 과정을 자동화함으로써 수동으로 데이터를 생성하는 것보다 비용을 크게 절감할 수 있습니다.정량적 평가: 생성된 데이터를 사용하여 LLM 애플리케이션의 성능을 정량적으로 평가할 수 있습니다.
DeepEval
DeepEval은 LLM을 위한 유닛 테스트 도구로, Ground Truth 생성 및 평가를 지원합니다.
DeepEval의 주요 특징은 다음과 같습니다:
LLM 기반 평가: LLM을 사용하여 Ground Truth를 생성하고 평가합니다.파이썬 친화적 접근: 파이썬으로 단위 테스트를 작성하는 것처럼 간단하게 LLM 애플리케이션용 테스트를 작성할 수 있습니다.다양한 메트릭 제공: 관련성, 사실의 일관성, 독성, 편향성 등 다양한 메트릭을 사용하여 LLM 응답을 평가합니다.CI/CD 통합: 테스트를 제품 개발 파이프라인에 쉽게 추가할 수 있어, 지속적인 통합과 배포가 가능합니다.Web UI 제공: 테스트, 구현, 비교를 위한 웹 인터페이스를 제공합니다.
Phoenix
Phoenix는 Arize AI에서 개발한 오픈소스 LLM 관찰성 및 평가 플랫폼으로, LLM 애플리케이션의 개발, 디버깅, 평가를 위한 종합적인 도구를 제공합니다.
Phoenix의 주요 특징은 다음과 같습니다:
트레이싱: LLM 작업의 실행 메트릭을 추적하고 모델 동작을 분석합니다. 지연 시간, 토큰 사용량 등의 성능 메트릭을 모니터링하며, 개발자가 특정 스팬을 자세히 살펴보고 관련 로그와 메타데이터에 접근할 수 있습니다.평가: 사전 테스트된 평가 템플릿을 제공하여 모델 품질을 평가합니다. 사용자 정의 메트릭 정의, 사용자 피드백 수집, 자동 평가를 위한 별도 LLM 활용 등을 지원합니다.실험 및 디버깅: 프로토타이핑 및 디버깅 단계에서 코드 계측을 통해 상세한 실행 흐름 정보를 제공하고, 프롬프트 및 모델 성능을 측정하기 위한 실험 기능을 제공합니다.검색 및 추출(RAG) 분석: 검색 프로세스를 시각화하고 청크 생성, 컨텍스트 추출, 프롬프트 템플릿 등을 최적화할 수 있습니다.프롬프트 템플릿 디버깅: LLM 호출에서 사용된 프롬프트 템플릿과 최종 생성된 프롬프트를 추적합니다.다양한 환경 지원: 주피터 노트북, 로컬 환경, 컨테이너, 클라우드 등 다양한 환경에서 실행 가능합니다.프레임워크 및 모델 통합: LlamaIndex, LangChain 등의 프레임워크와 OpenAI, Amazon Bedrock 등 다양한 LLM 모델을 지원합니다.
(참고) Retrieval-Augmented Generation for Large Language Models: A Survey
- 링크 : https://arxiv.org/pdf/2312.10997v1
- 본 논문에서는
RAGAS와ARES라는 두 가지 주요 평가 프레임워크가 소개합니다.- 아래 내용은 논문 내용을 기준으로 작성되었습니다.
- RAGAS:
- 이 프레임워크는 검색 시스템이 관련성과 중요성을 가진 문단을 식별하는 능력, LLM이 이러한 문단을 얼마나 충실히 사용하는지, 생성의 질을 평가합니다.
- RAGAS는 간단한 수동 프롬프트를 사용하여 세 가지 품질 측면(답변의 신뢰성, 답변의 관련성, 문맥의 관련성)을 평가합니다.
- 모든 프롬프트는 OpenAI API를 통해 gpt-3.5-turbo-16k 모델로 평가됩니다.
- ARES:
- ARES는 RAG 시스템의 성능을 자동으로 평가하기 위해 Context Relevance, Answer Faithfulness, Answer Relevance의 세 가지 측면을 목표로 합니다.
- RAGAS와 유사한 평가 지표를 사용하지만, 더 새로운 설정에 대한 적응성이 떨어지는 단점이 있습니다.
- ARES는 소량의 수동 주석 데이터와 합성 데이터를 사용하여 평가 비용을 줄이며, Predictive-Driven Reasoning (PDR)을 사용해 평가의 정확도를 높입니다.
3.4 RAGAs 기반 Ground Truth 생성
RAGAs를 활용하여 RAG 평가를 위한 Ground Truth를 생성하는 방법은 다음과 같은 프로세스를 따릅니다.
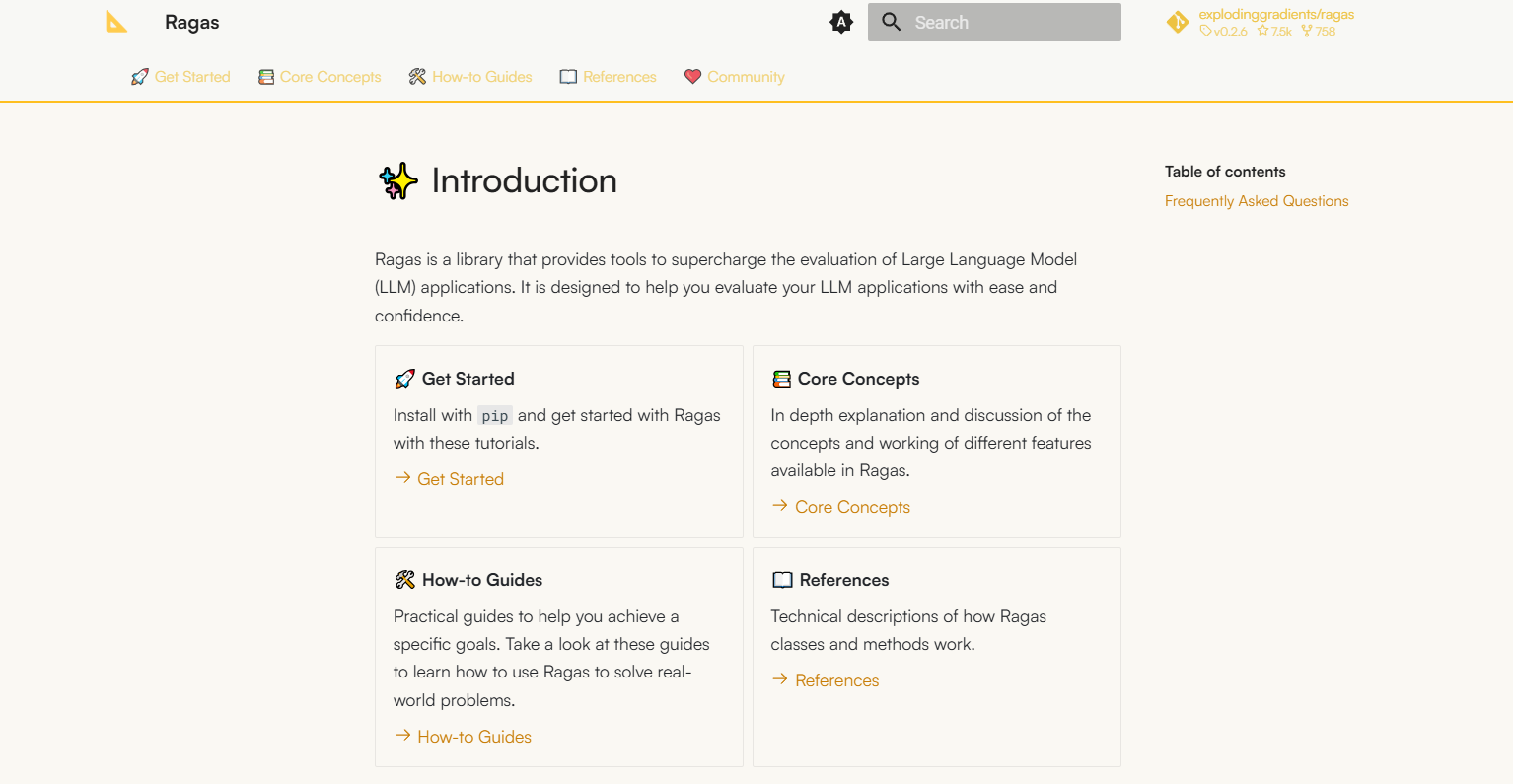
RAGAs 설정 및 활용
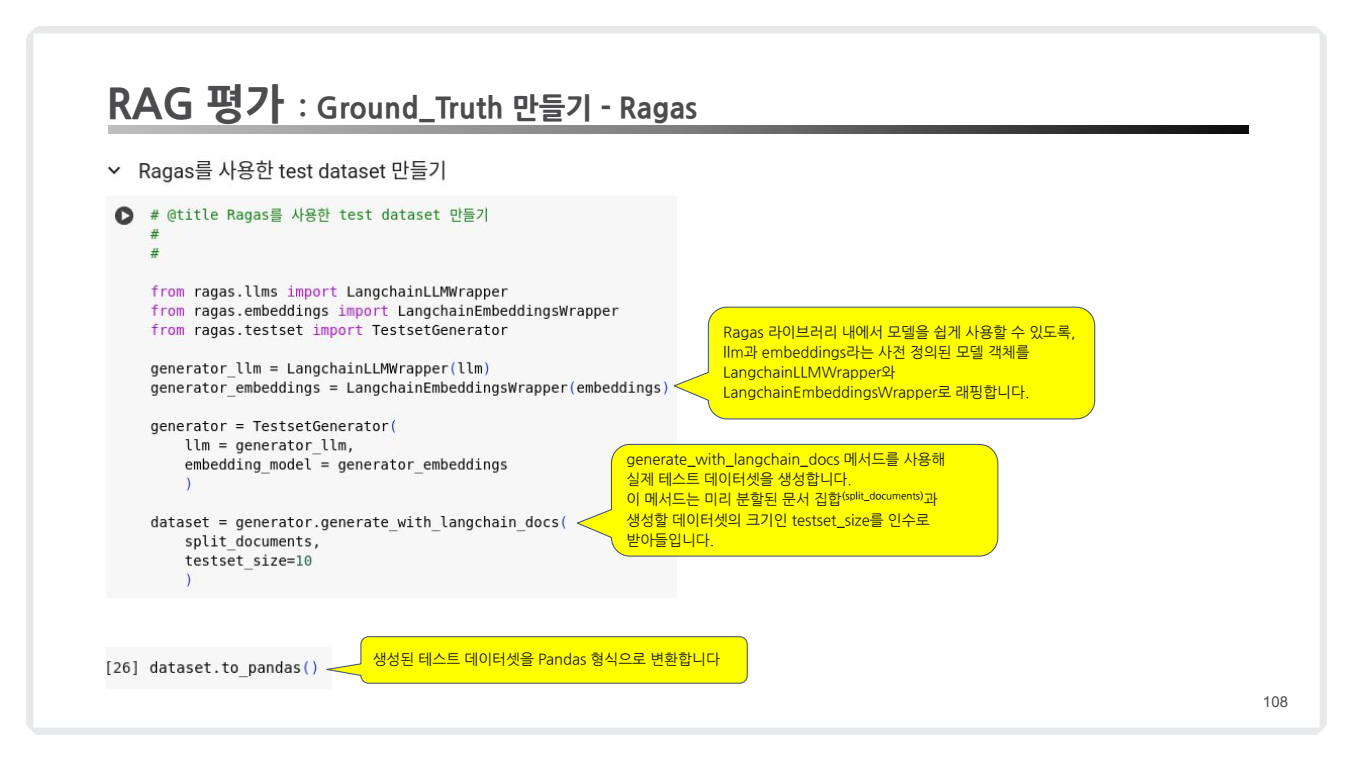
-
필요한 라이브러리 불러오기:
from ragas.llms import LangchainLLMWrapper from ragas.embeddings import LangchainEmbeddingsWrapper from ragas.testset import TestsetGenerator -
모델 및 임베딩 초기화:
llm = LangchainLLMWrapper("openai-gpt") # LLM 모델 초기화 embeddings = LangchainEmbeddingsWrapper("openai-embedding") # 임베딩 모델 초기화 -
테스트셋 생성기 정의:
generator = TestsetGenerator( llm=llm, embedding_model=embeddings ) -
Ground Truth 생성:
dataset = generator.generate_with_langchain_docs( split_documents=split_documents, # 사전 분리된 문서 testset_size=10 # 생성할 질문-답변 쌍 개수 ) -
데이터셋 확인:
print(dataset.to_pandas()) # Pandas 데이터프레임 형식으로 확인
위 코드를 수행하면, 아래와 같이 질문과, GT가 생성되는 것을 확인할 수 있습니다.

3.5 RAG 평가: RAG Triad
RAG Triad는 RAG(Retrieval-Augmented Generation) 시스템의 성능을 평가하기 위한 세 가지 핵심 평가 지표 프레임워크입니다.
-
이는 ‘질의 (Query)’, ‘컨텍스트 (Context)’, ‘응답 (Response)’의 세 요소가 ‘적절한 (Relevance)’ 내용을 담고 있는지 평가하고자 합니다.
-
이 프레임워크는 검색과 생성의 균형을 평가하고 잠재적인 실패 모드를 식별하는 데 도움을 줍니다.
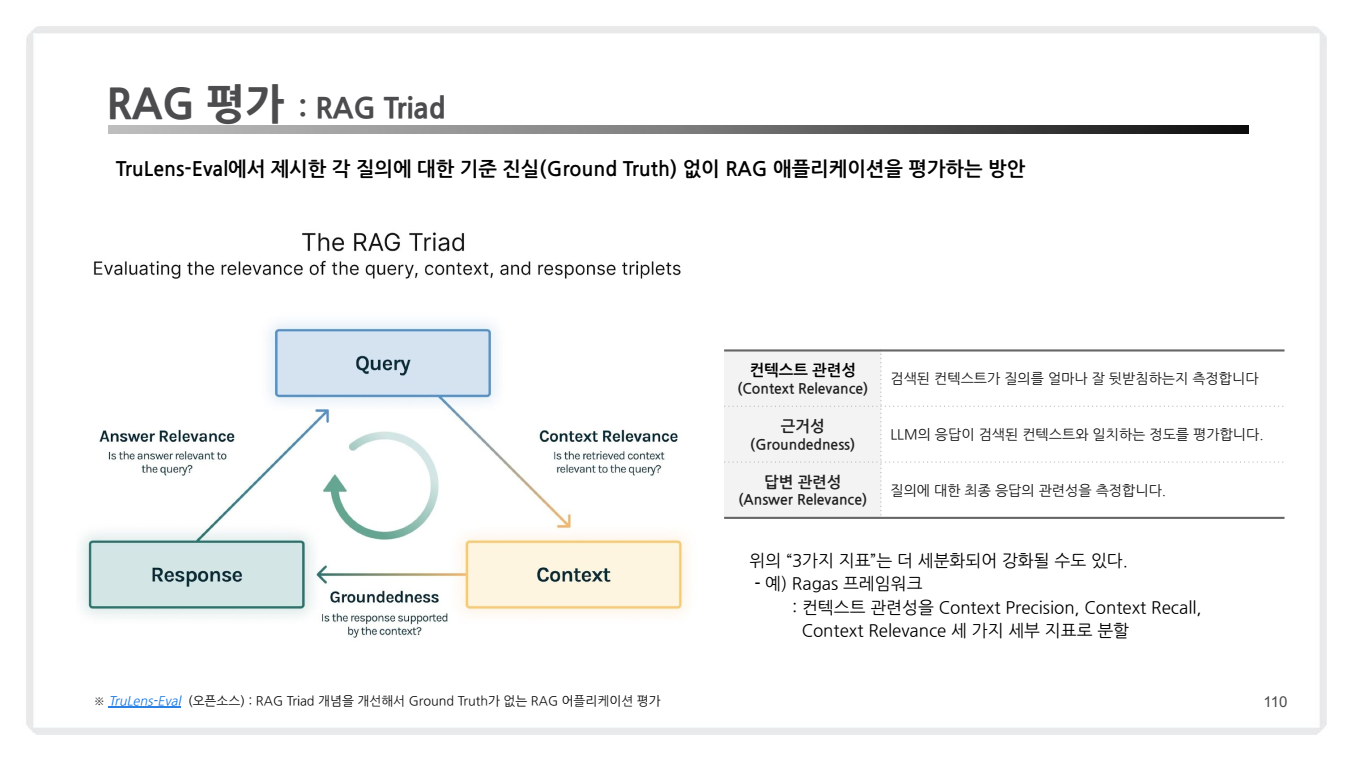
- RAG 평가의 세 가지 핵심
- 검색 품질(Search Quality): 검색 결과의 정확성.
- 생성 품질(Generation Quality): 생성된 답변의 정확성과 관련성.
- 사용자 경험(User Experience): 사용자 친화성, 응답 시간 등.
(참고) DeepEval 실습
유형 1: 기본 출력 품질 평가

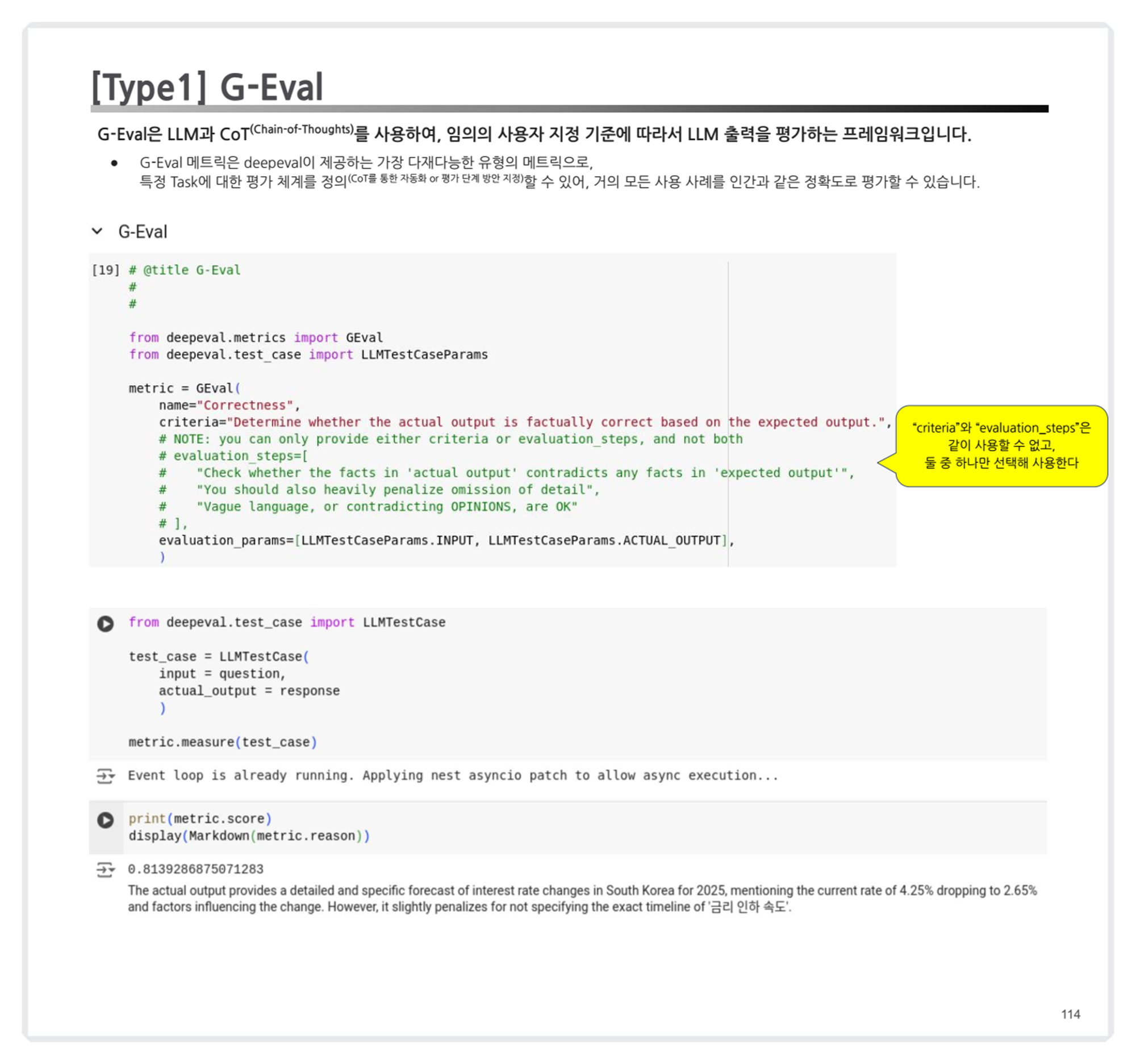
- G-Eval 메트릭
- "criteria"와 "evaluation_steps"는 동시에 사용할 수 없으며, 이들 중 하나를 선택해야 함.
- CoT(Chain-of-Thoughts)를 활용한 평가 체계의 중요성 및 실제 활용 사례(예: 단계별 reasoning).
-
답변 관련성 평가
- 제공된 입력과 비교하여, LLM의 출력이 얼마나 관련성이 있는지 평가.
- 특징:
- 자체 설명형 지표로, 점수에 대한 이유(reason)를 함께 출력.
- 임계값(Threshold): 0.7 이상이면 관련성이 있다고 간주.

-
편향성(bias) 및 독성(toxicity) 평가
Bias (편향성): 출력에 성별, 인종, 정치적 편향성이 포함되었는지 평가.- 특징: 임계값: 0.5 이상일 경우, 편향적이라고 판단.
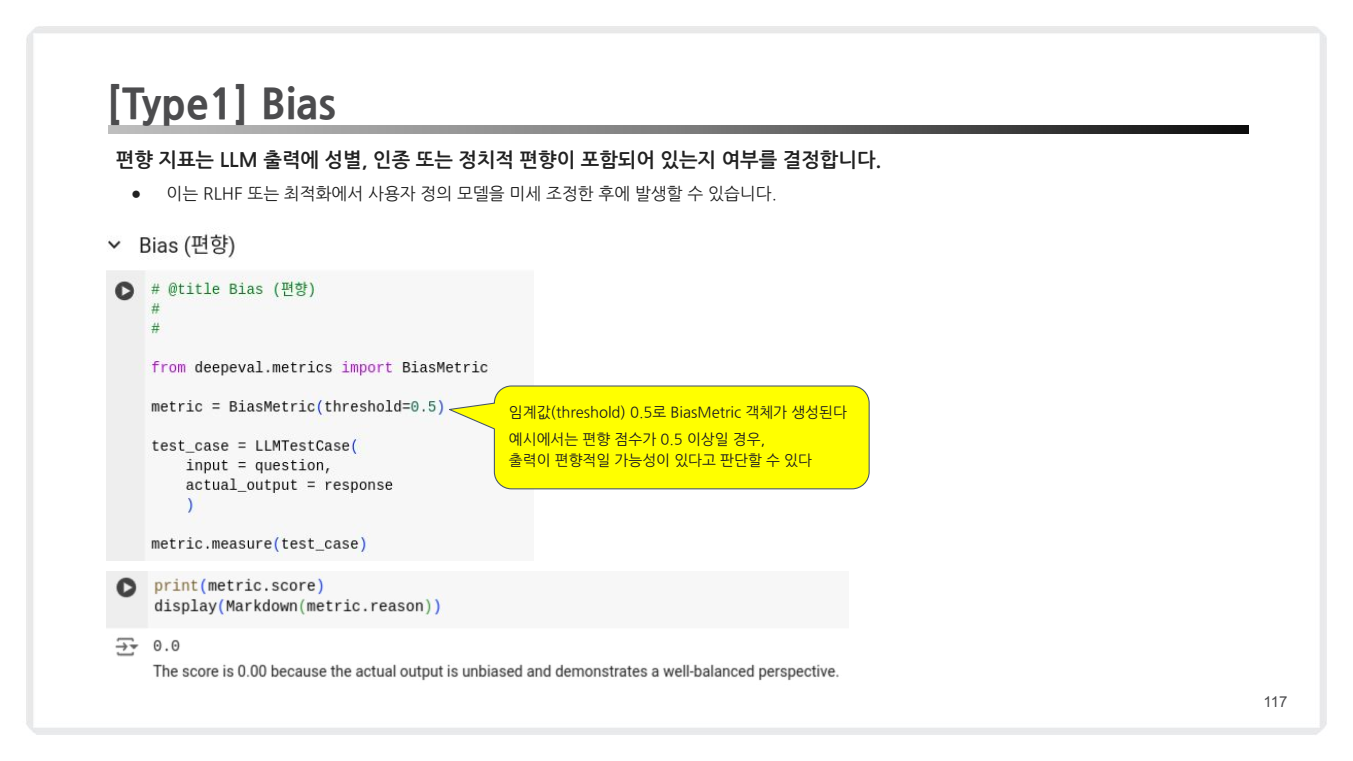
- 특징: 임계값: 0.5 이상일 경우, 편향적이라고 판단.
Toxicity (독성): 출력이 모욕적이거나 유해한 언어를 포함하는지 평가.- 특징: 임계값: 0.5 이상일 경우, 독성이 있다고 판단.
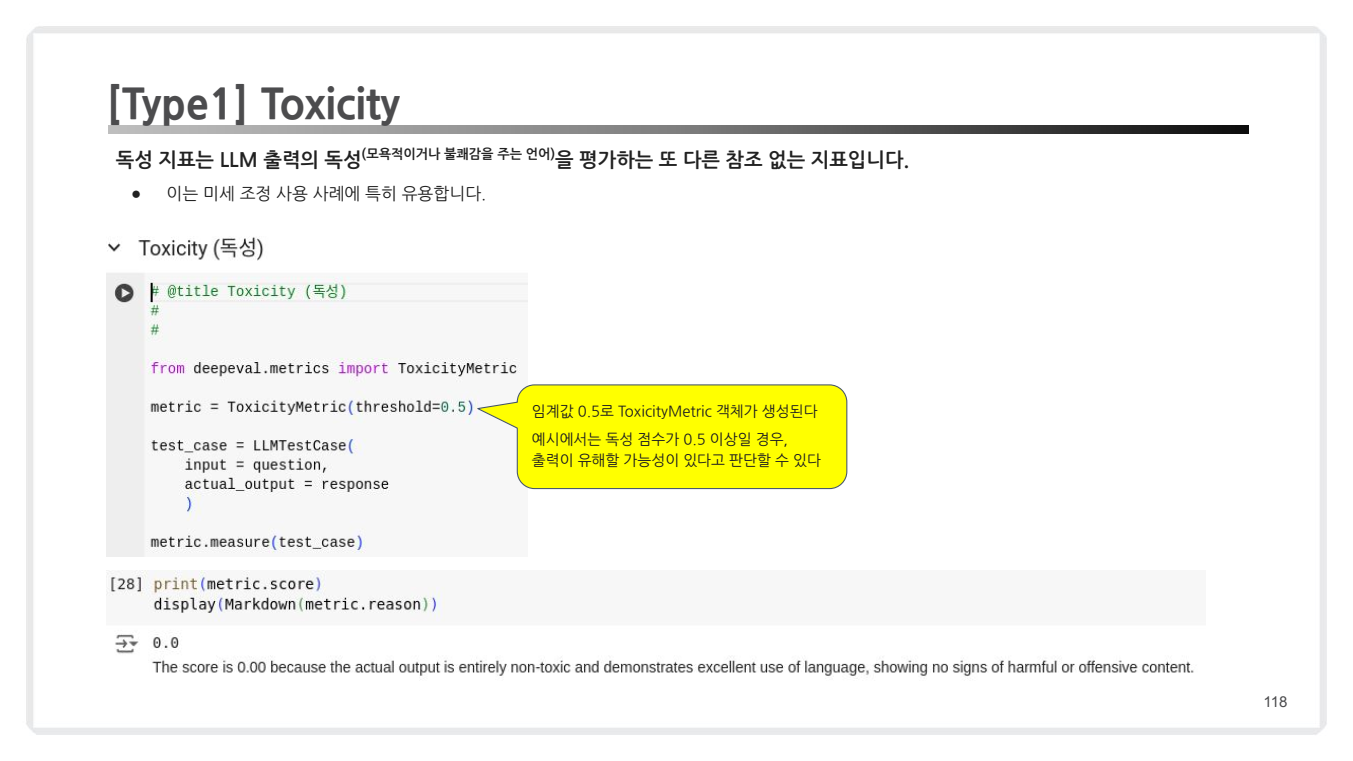
- 특징: 임계값: 0.5 이상일 경우, 독성이 있다고 판단.
-
대화 완전성 및 관련성 평가
Conversation Completeness (대화 완전성): 대화 전반에서 사용자의 요구를 충족하는지 평가.- 특징: 임계값: 0.5 이상이면 대화가 충분히 완전하다고 간주.
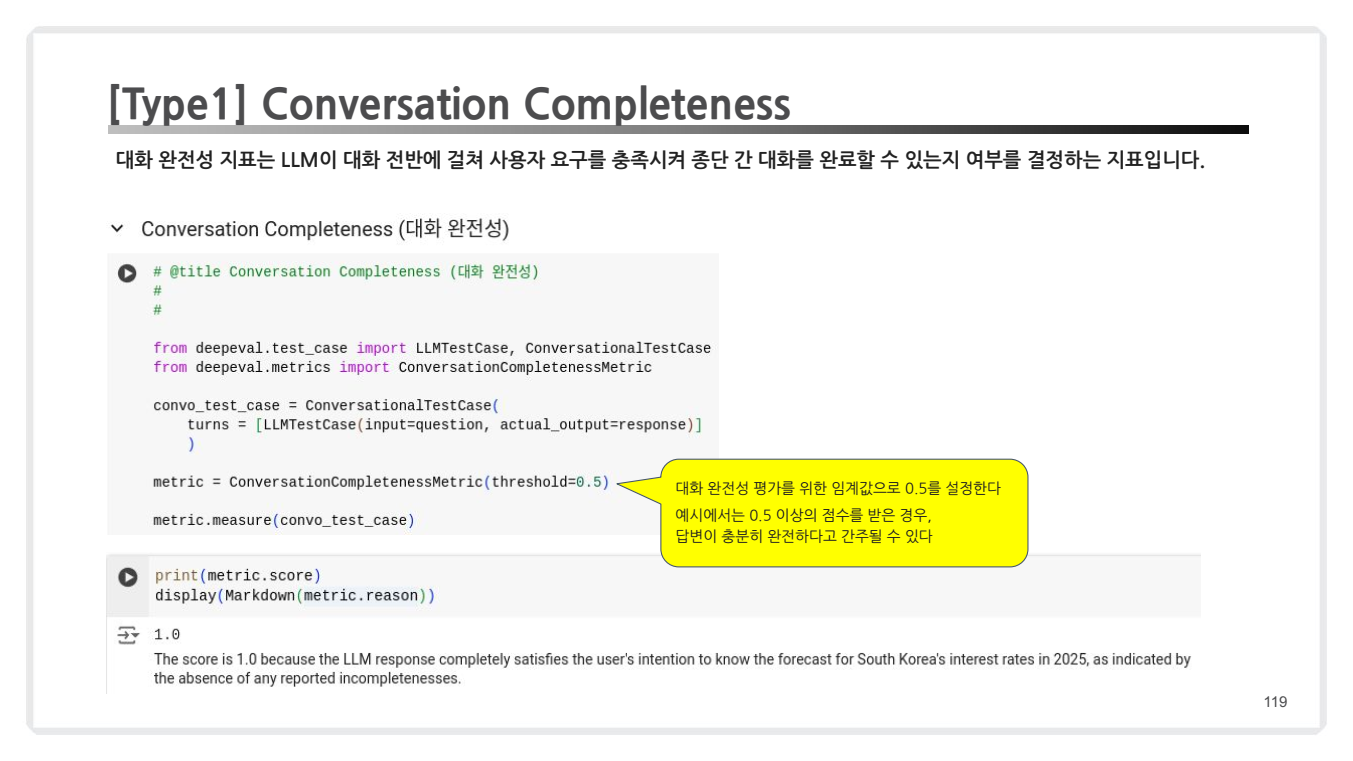
- 특징: 임계값: 0.5 이상이면 대화가 충분히 완전하다고 간주.
Conversation Relevancy (대화 관련성): 대화 맥락에서 지속적으로 관련성 있는 응답을 생성하는지 평가.- 특징: 임계값: 0.5 이상이면 관련성이 있다고 간주.
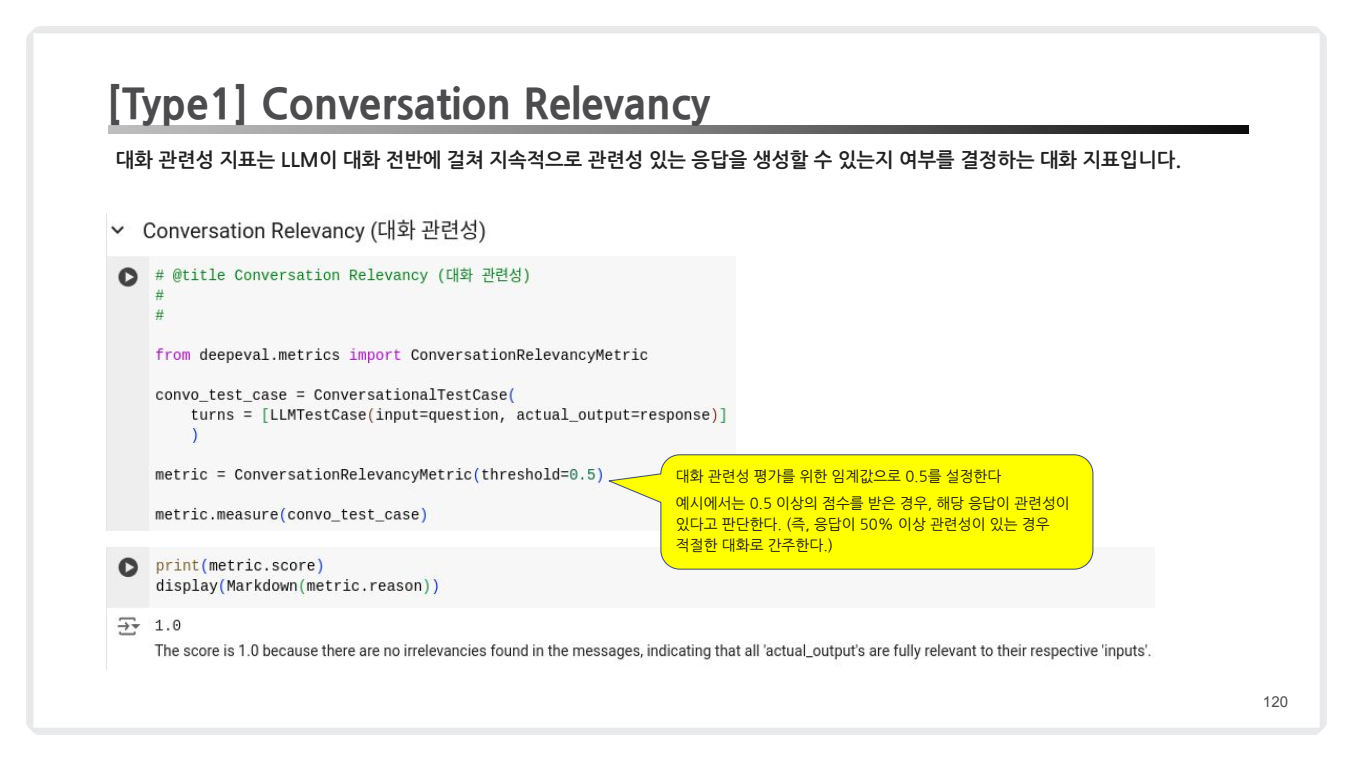
- 특징: 임계값: 0.5 이상이면 관련성이 있다고 간주.
DeepEval의 Test Dataset 생성
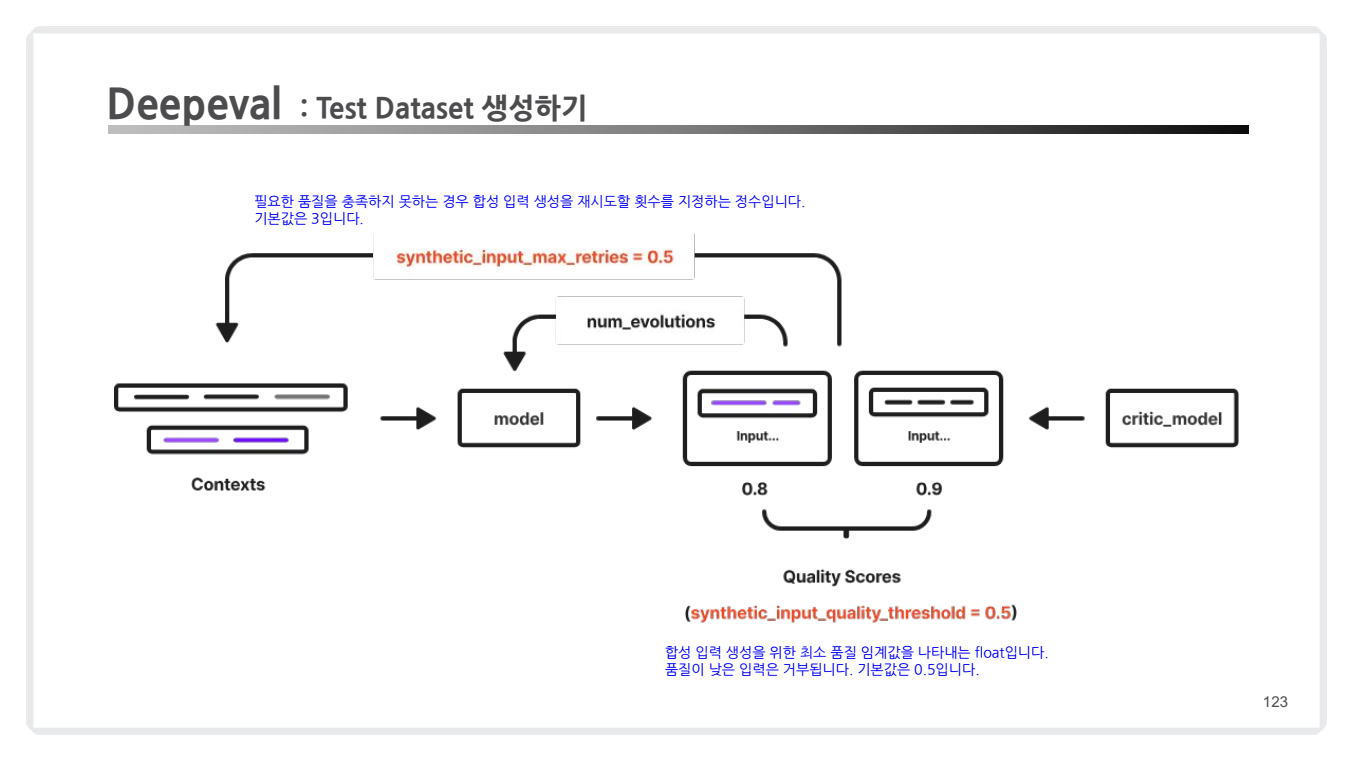
- 프로세스 개요
- 문서 청크화:
- 원본 문서를 청크로 분리하고, 각 청크를 임베딩하여 노드 컬렉션 생성.
- 유사 노드 검색 및 컨텍스트 생성:
- 각 청크에 대해 유사한 노드를 검색하여 그룹화.
- 합성 입력 및 출력 생성:
- 생성된 컨텍스트를 기반으로 질문-답변 쌍을 생성하여 Golden Dataset을 형성.
- 문서 청크화:
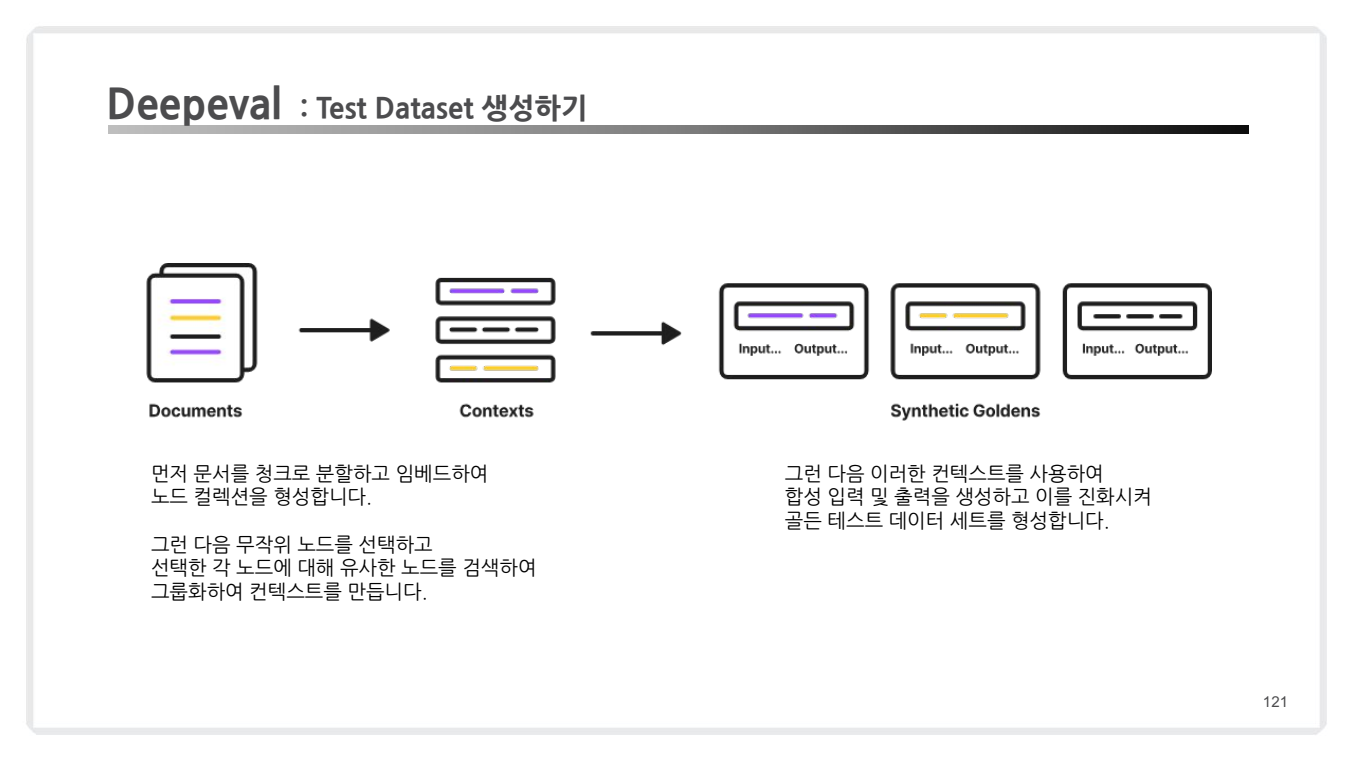
- 임계값 설정
- 품질이 낮은 입력 및 컨텍스트는 거부되며, 기본 임계값(0.5)이 설정됨.
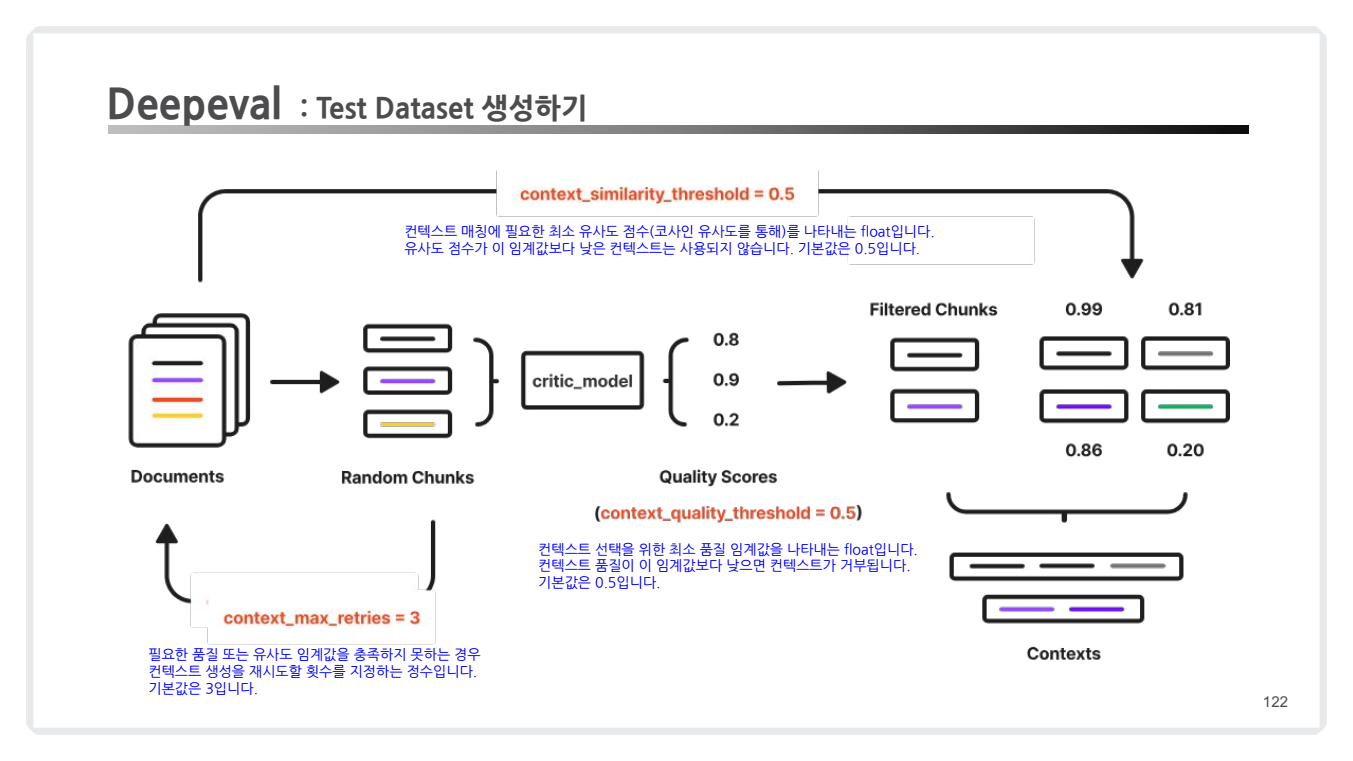
- 컨텍스트 품질이나 유사도가 기준 미달일 경우 재시도 가능.
- 품질이 낮은 입력 및 컨텍스트는 거부되며, 기본 임계값(0.5)이 설정됨.
코드 실습
from deepeval.dataset import EvaluationDataset
from deepeval.synthesizer import Synthesizer
# Synthesizer 초기화
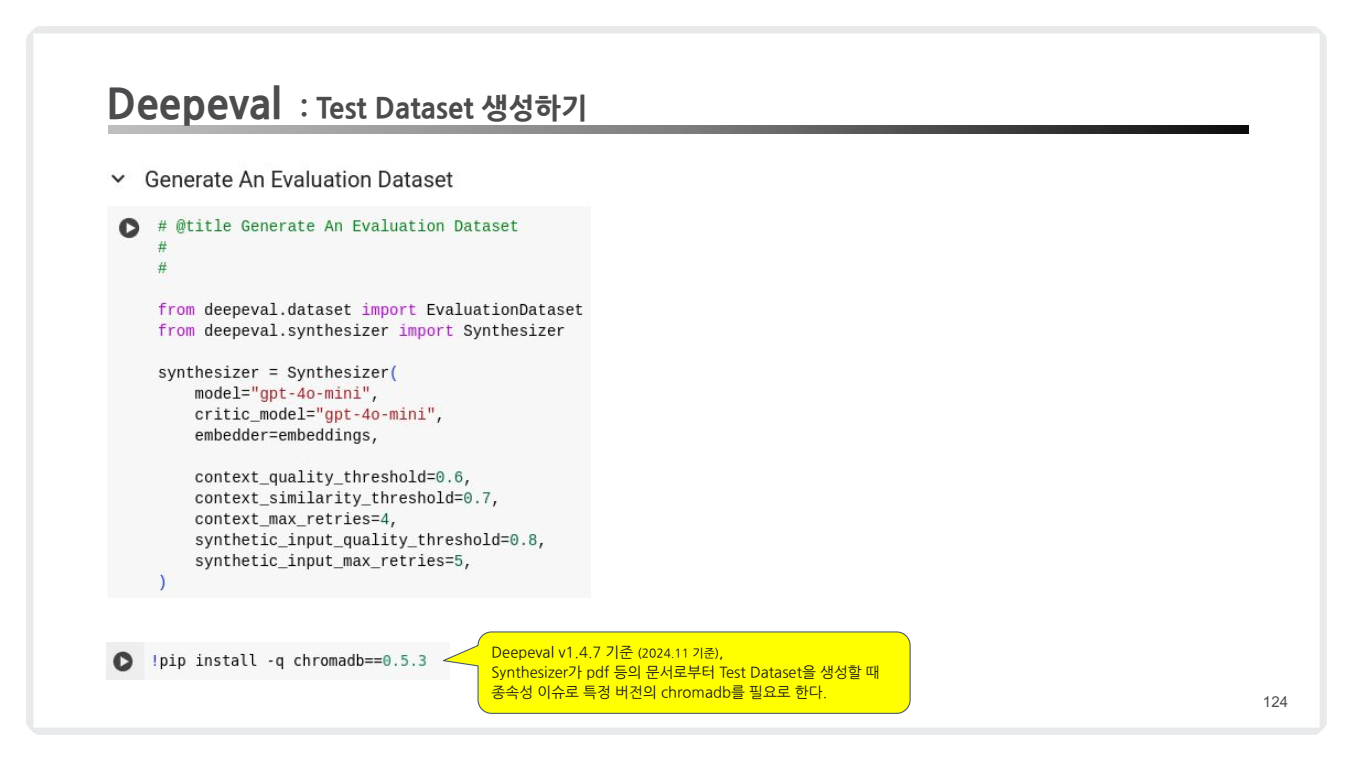
synthesizer = Synthesizer(
model="gpt-4o-mini", # 기본 GPT 모델 설정
critic_model="gpt-4o-mini", # 평가 기준(Critic) 모델 설정
embedder=embeddings, # 문서 임베딩 모델
context_quality_threshold=0.6, # 컨텍스트 품질 임계값 설정
context_similarity_threshold=0.7, # 컨텍스트 유사도 기준
context_max_retries=4, # 컨텍스트 생성 재시도 횟수
synthetic_input_quality_threshold=0.8, # 합성 입력 품질 기준
synthetic_input_max_retries=5 # 합성 입력 재시도 횟수
)
- Synthesizer 초기화
Synthesizer객체는 문서를 기반으로 합성 질문-답변 쌍을 생성하기 위한 핵심 역할을 수행합니다.- 매개변수:
model과critic_model: 생성과 평가에 사용할 GPT 모델.embedder: 문서를 임베딩하여 유사도 계산에 사용하는 모델.context_quality_threshold: 컨텍스트의 최소 품질 기준 (0.6).context_similarity_threshold: 코사인 유사도를 기반으로 컨텍스트의 유사도를 평가 (기본값: 0.7).context_max_retries: 기준 미달 시 컨텍스트 생성 재시도 횟수 (4회).synthetic_input_quality_threshold: 합성 입력의 품질 기준 (0.8).synthetic_input_max_retries: 합성 입력 생성 재시도 횟수 (5회).
# Test Dataset 생성
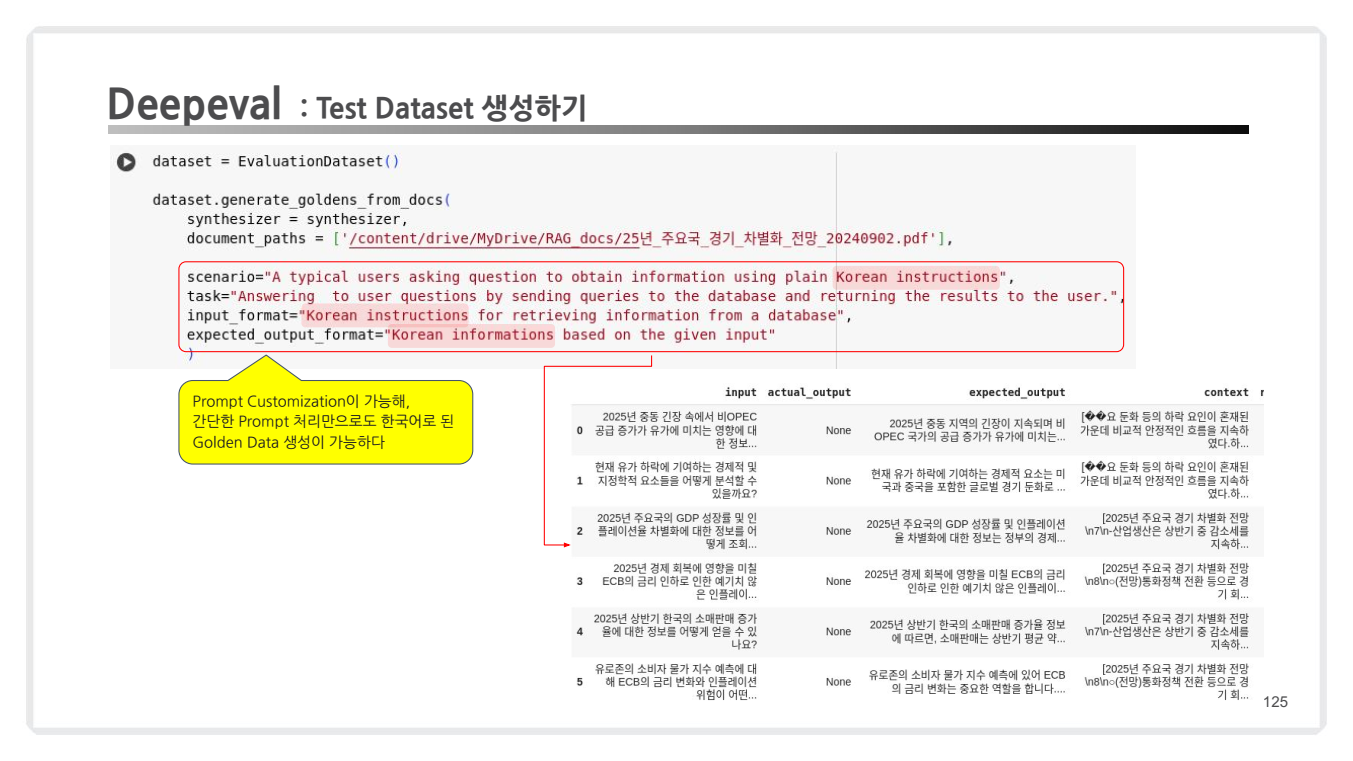
dataset = EvaluationDataset()
# Prompt Customization
dataset.generate_goldens_from_docs(
synthesizer=synthesizer,
document_paths=['/content/drive/MyDrive/RAG docs/경기_차별화_전망.pdf'], # 문서 경로 설정
scenario="A typical users asking question to obtain information using plain Korean instructions",
task="Answering to user questions by sending queries to the database and returning the results to the user.",
input_format="Korean instructions for retrieving information from a database",
expected_output_format="Korean informations based on the given input"
)
-
Test Dataset 생성
generate_goldens_from_docs메서드를 통해 Test Dataset 생성.- 매개변수:
document_paths: 문서 경로 리스트.scenario: 사용 사례 설명 (예: 사용자 요청 시 데이터베이스에서 정보를 반환하는 시나리오).task: 작업의 목표 설명 (예: 질의응답).input_format: 입력 데이터의 형식 (한국어 질의 형식).expected_output_format: 출력 데이터의 형식 (한국어 정보).
-
Prompt Customization
- 간단한 프롬프트 설정을 통해 한국어 기반의 Golden Dataset 생성 가능.
- 사용 사례에 맞는 다양한 언어 지원.
마지막 단계에서는 생성된 데이터를 Markdown 형식으로 출력하여 확인합니다:

display(Markdown(f"**Input**: {dataset.goldens[2].input}"))
display(Markdown(f"**Context**: {dataset.goldens[2].context}"))
display(Markdown(f"**Expected_output**: {dataset.goldens[2].expected_output}"))결과:
- Input: 2025년 주요국 GDP 성장률 및 인플레이션을 차별화에 대한 정보를 어떻게 조회할 수 있나요?
- Context: 2025년 경제 전망 보고서에 따르면 산업 생산이 감소 추세에 있으며, 국제 금융 기관의 분석 보고서를 통해 경제 상황 비교 가능.
- Expected Output: 주요국 GDP 성장률 정보를 비교하고, IMF 및 OECD 보고서를 활용하여 경제적 인사이트를 얻을 수 있습니다.
유형 2: 컨텍스트 기반 평가

-
문맥적 관련성 (Contextual Relevance)
- 검색된 컨텍스트가 질문의 맥락과 얼마나 의미적으로 관련이 있는지를 평가.
- 구체적 기준은 코사인 유사도와 같은 임베딩 비교 방식 사용.
from deepeval.metrics import ContextualRelevancyMetric # 문맥적 관련성 평가 메트릭 초기화 metric = ContextualRelevancyMetric( threshold=0.7, # 임계값: 0.7 이상이면 Pass model="gpt-4o-mini", # 평가에 사용할 모델 include_reason=True # 점수에 대한 이유를 출력 ) # 평가 구성요소 생성 question = dataset.goldens[2].input # 입력 질문 actual_output = chain.invoke(question) # 실제 출력 retrieval_context = dataset.goldens[2].context # 검색된 컨텍스트 # 테스트 케이스 생성 test_case = LLMTestCase( input=question, actual_output=actual_output, retrieval_context=retrieval_context ) # 문맥적 관련성 평가 수행 metric.measure(test_case)
-
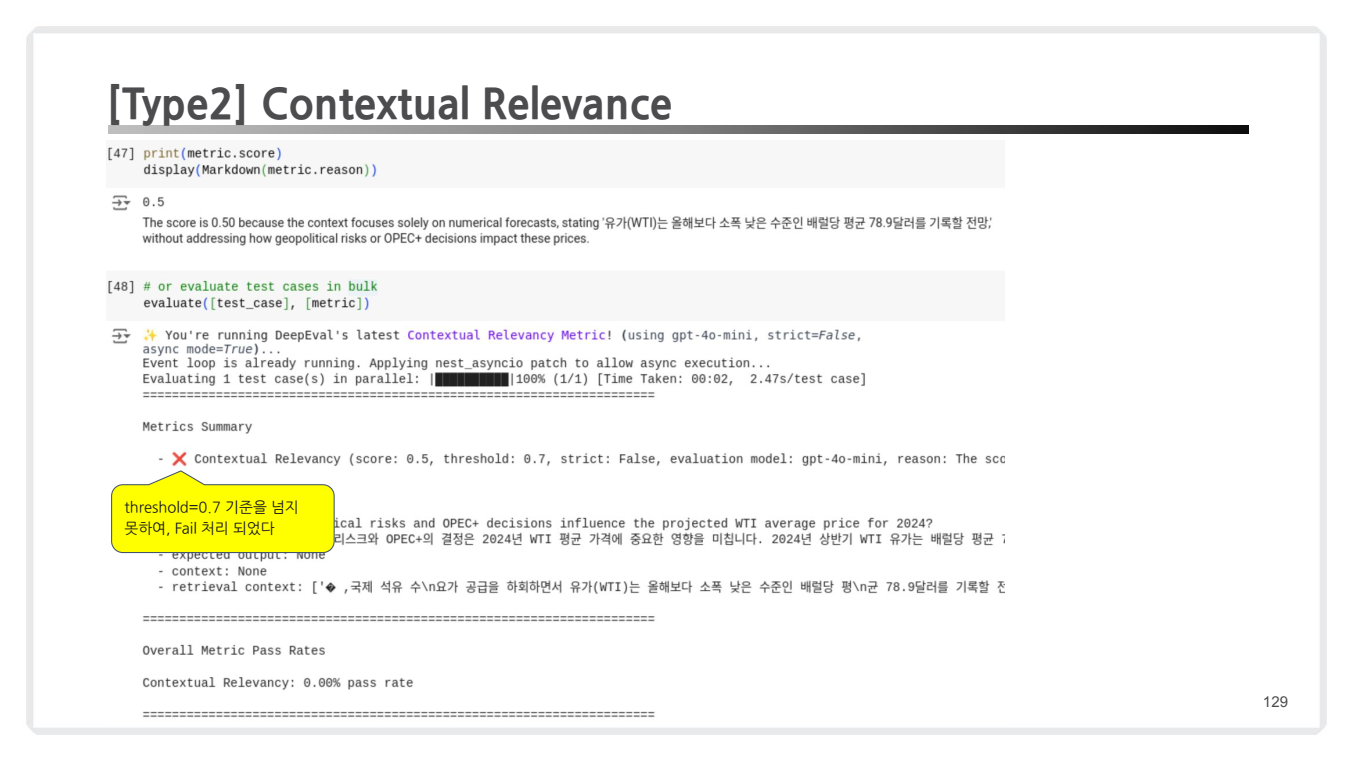
평가 결과 해석
- 출력 점수: 0.5 (기준 미달)
- 이유(Reason): 검색된 컨텍스트가 단순히 숫자 예측만 포함하고 있으며, 질문의 맥락적 요구(예: 지정학적 위험, OPEC 결정의 영향)를 반영하지 못함.
- 임계값 미달 (설정된 threshold=0.7를 넘지 못해 Fail로 처리.)
- Fail 이유:
- "WTI 평균 가격"에 대한 질문은 지정학적 위험과 같은 복잡한 요인을 고려해야 하지만, 컨텍스트가 단순 수치 정보만 제공.
- Fail 이유:
- 출력 점수: 0.5 (기준 미달)
-
충실도 (Faithfulness) 평가
- 출력이 검색된 컨텍스트 내에서 왜곡 없이 정보를 반영했는지 확인.
- 충실도가 낮은 출력은 RAG 파이프라인에서 "환각"으로 간주.
from deepeval.metrics import FaithfulnessMetric # 충실도 평가 메트릭 초기화 metric = FaithfulnessMetric( threshold=0.7, # 임계값: 0.7 이상이면 Pass model="gpt-4o-mini", # 평가에 사용할 모델 include_reason=True # 점수에 대한 이유를 출력 ) # 평가 구성요소 생성 question = dataset.goldens[2].input # 입력 질문 actual_output = chain.invoke(question) # 실제 출력 retrieval_context = dataset.goldens[2].context # 검색된 컨텍스트 # 테스트 케이스 생성 test_case = LLMTestCase( input=question, actual_output=actual_output, retrieval_context=retrieval_context ) # 충실도 평가 수행 metric.measure(test_case)
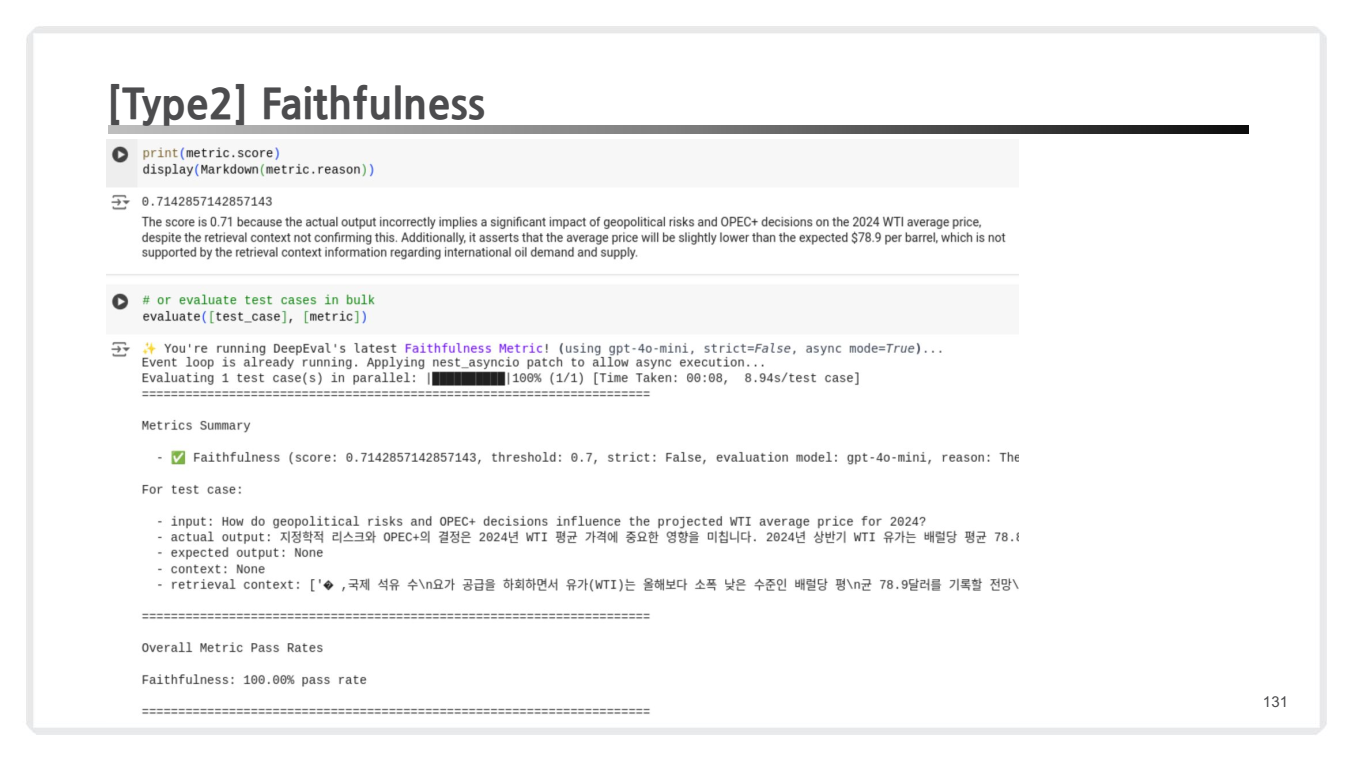
- 평가 결과 해석
- 출력 점수: 0.71 (임계값 초과, Pass)
- 이유(Reason): 출력이 지정학적 위험과 OPEC 결정의 WTI 평균 가격에 미치는 영향을 언급했으나, 검색된 컨텍스트와 일부 불일치 발생.
- 임계값 초과 (설정된 threshold=0.7를 초과하여 Pass로 처리.)
- Pass 이유:
- 출력이 전체적으로 컨텍스트의 정보를 반영하고 있음.
- 일부 추가적인 논리가 포함되었지만, 사실적 왜곡은 없음.
- Pass 이유:
- 출력 점수: 0.71 (임계값 초과, Pass)
유형 3: 심층 품질 평가

아래는 3가지 품질 평가 Metric을 한번에 코드로 묶어서 작성한 코드입니다:
from deepeval.metrics import ContextualPrecisionMetric, ContextualRecallMetric
from deepeval.metrics.ragas import RagasMetric
# 문맥적 정밀성 메트릭 정의
contextual_precision_metric = ContextualPrecisionMetric(
threshold=0.7, # 평가 통과 기준
model="gpt-4o-mini", # 사용 모델
include_reason=True # 점수 계산 이유 포함 여부
)
# 문맥적 재현성 메트릭 정의
contextual_recall_metric = ContextualRecallMetric(
threshold=0.7, # 평가 통과 기준
model="gpt-4o-mini", # 사용 모델
include_reason=True # 점수 계산 이유 포함 여부
)
# RAGAS 메트릭 정의
ragas_metric = RagasMetric(
threshold=0.5, # 평가 통과 기준
model="gpt-4o-mini" # 사용 모델
)
# 평가 구성 요소 생성
question = dataset.golden_data[2].input # 질문 데이터
actual_output = chain.invoke(question) # 모델 출력
retrieval_context = dataset.golden_data[2].context # 검색된 컨텍스트
expected_output = dataset.golden_data[2].expected_output # 기대 출력 (Ground Truth)
# 테스트 케이스 생성 (Type3는 expected_output 포함)
test_case_type3 = LLMTestCase(
input=question,
actual_output=actual_output,
retrieval_context=retrieval_context,
expected_output=expected_output
)
# 메트릭 평가
contextual_precision_metric.measure(test_case_type3)
contextual_recall_metric.measure(test_case_type3)
ragas_metric.measure(test_case_type3)각각의 결과 해석 및 설명은 아래에서 보실 수 있습니다.
-
문맥적 정밀성 (Contextual Precision)
- 관련 컨텍스트와 무관한 컨텍스트의 순위를 비교하여 정확도를 측정.
- RAG 시스템에서 검색기 성능을 개선하기 위해 필수적인 메트릭.
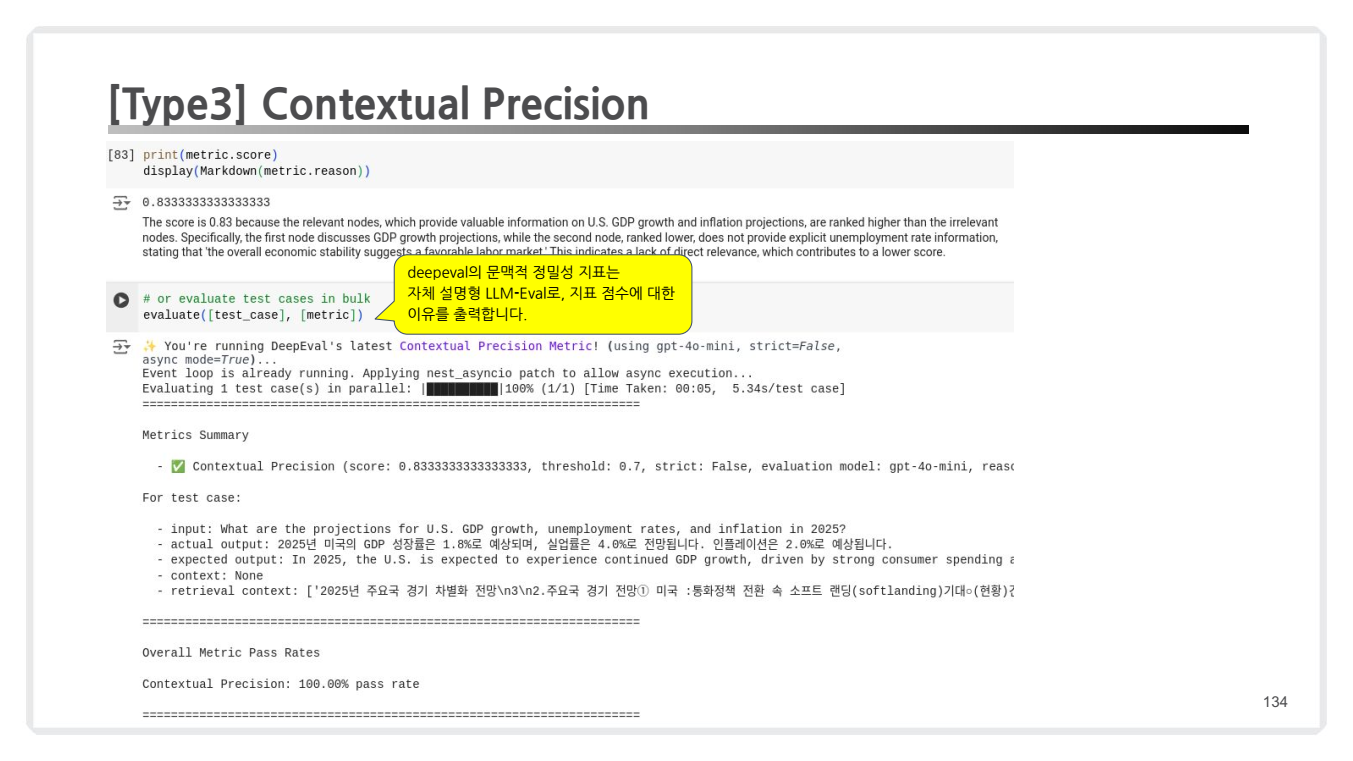
- 출력 예시:
- 종합 점수: 0.83
- 해설: 검색된 첫 번째 노드는 GDP 성장률과 관련된 정보를 제공하여 높은 순위를 받았지만, 두 번째 노드는 실업률 정보로 관련성이 낮아 점수가 감소함.
-
문맥적 재현성 (Contextual Recall)
- 검색된 컨텍스트가 Ground Truth와 얼마나 일치하는지를 측정.
- 재현성이 낮으면 RAG 파이프라인의 검색 과정이 부정확하다고 평가.

- 출력 예시:
- 종합 점수: 0.75
- 해설: 검색된 문장이 GDP 성장과 물가 안정화에 대한 정보를 잘 포함하고 있지만, 실업률에 대한 정보 부족으로 점수가 감소함.
-
RAGAS 메트릭 (RAGAS Metric)
- RAG 파이프라인의 생성기 및 검색기를 종합적으로 평가하는 핵심 지표.
- 각 메트릭(답변 관련성, 충실도, 정밀성, 재현성)의 평균 점수를 계산.
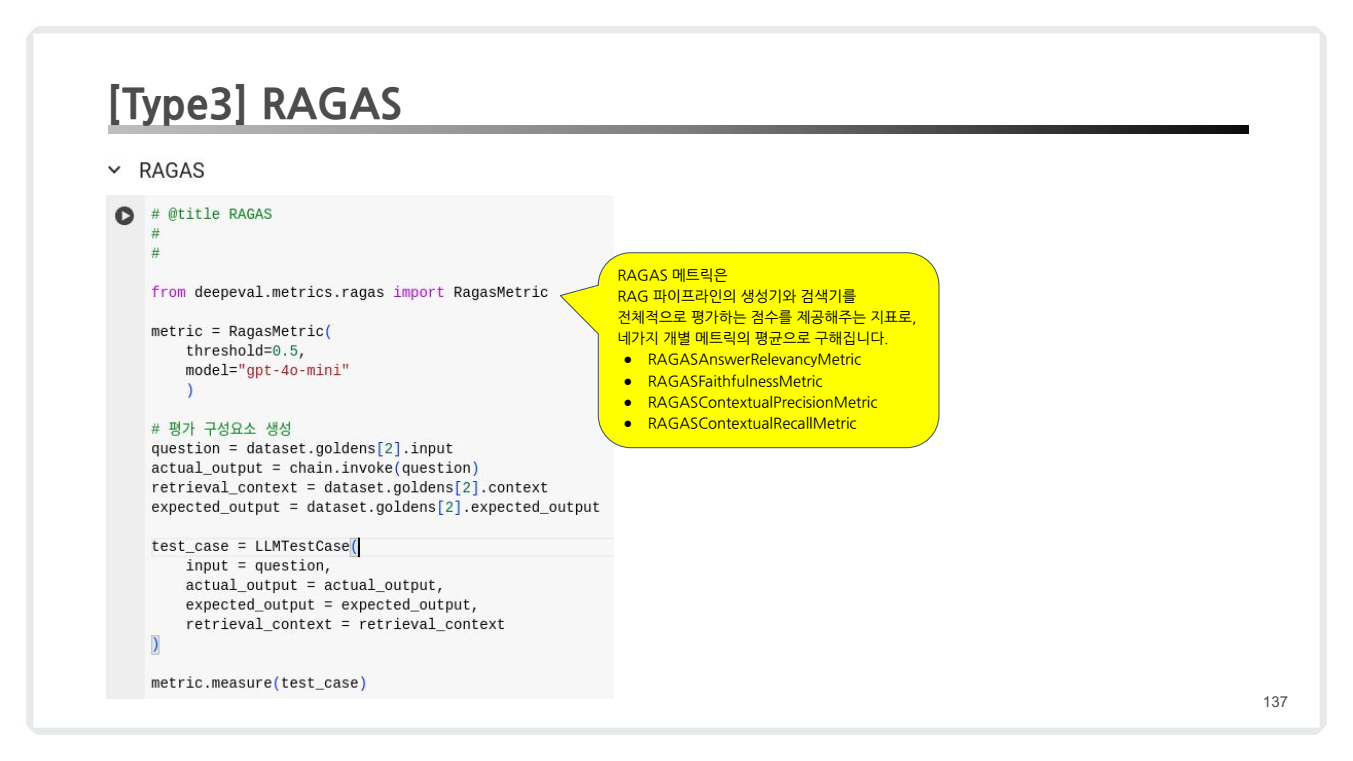
- 출력 예시:
- 종합 점수: 0.605
- 해설: 각 메트릭의 세부 점수를 기반으로 RAG 시스템의 전반적인 성능을 평가.
이상으로 강의 자료에 있는 모든 내용을 정리해보았는데요.
자료를 토대로 조사하면서 작성한 블로그이므로, 실제 강연 내용과는 상이할 수 있습니다 💌
읽어주셔서 감사합니다.
