
파이썬 판다스 심화
판다스(Pandas)에서 Group By는 데이터를 그룹화하고 그룹화된 데이터에 대한 연산을 수행하는데 매우 유용한 기능입니다.
이번 포스트에서는 Python에서 Group By의 개념과 활용 예제에 대해 다루어보겠습니다.
Group By란?
Group By는 데이터를 그룹화하고 그룹화된 데이터에 대한 연산을 수행하는 기능입니다.
Group By를 사용하면 데이터를 더 쉽게 분석할 수 있습니다. Pandas에서는 다음과 같은 형태로 Group By를 수행합니다.
df.groupby('그룹화할 열 이름')위 코드는 df 데이터프레임을 그룹화할 열 이름으로 그룹화합니다. 이제 그룹화된 데이터에 대해 원하는 연산을 수행할 수 있습니다.
Group By의 활용 예제
1. 그룹화된 데이터에 대한 기본 통계 정보 구하기
다음과 같은 데이터가 있다고 가정해봅시다.
import pandas as pd
import numpy as np
data = {'학년': ['1학년', '1학년', '2학년', '2학년', '3학년', '3학년', '3학년'],
'성별': ['남', '여', '남', '여', '남', '여', '여'],
'영어 성적': [80, 90, 70, 60, 85, 95, 75]}
df = pd.DataFrame(data)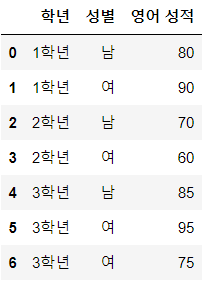
이제 학년을 기준으로 데이터를 그룹화하고, 그룹화된 데이터에 대해 영어 성적의 평균, 최소값, 최대값 등의 기본 통계 정보를 구해보겠습니다.
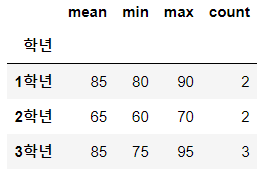
grouped = df.groupby('학년')
result = grouped['영어 성적'].agg(['mean', 'min', 'max', 'count'])
print(result)위 코드는 학년을 기준으로 데이터를 그룹화하고, 그룹화된 데이터에 대해 영어 성적의 평균, 최소값, 최대값, 개수 등의 기본 통계 정보를 구합니다. 출력 결과는 다음과 같습니다.
2. 그룹화된 데이터의 시각화
그룹화된 데이터를 시각화할 수도 있습니다. 예를 들어, 다음과 같은 데이터가 있다고 가정해봅시다.
data = {'Location': ['Seoul', 'Seoul', 'Seoul', 'Geongi', 'Geongi', 'Geongi', 'Incheon', 'Incheon', 'Incheon'],
'Year': [2018, 2019, 2020, 2018, 2019, 2020, 2018, 2019, 2020],
'Population': [9700000, 9800000, 9900000, 13000000, 13500000, 14000000, 2900000, 3000000, 3100000]}
df = pd.DataFrame(data)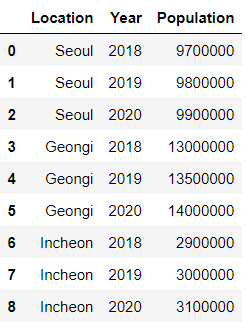
이제 지역을 기준으로 데이터를 그룹화하고, 그룹화된 데이터의 인구 정보를 막대그래프로 시각화해보겠습니다.
import matplotlib.pyplot as plt
import warnings
%matplotlib inline
grouped = df.groupby('Location')
result = grouped['Population'].sum()
result.plot(kind='bar')
plt.show()위 코드는 지역을 기준으로 데이터를 그룹화하고, 그룹화된 데이터의 인구 정보를 막대그래프로 시각화합니다. 출력 결과는 다음과 같습니다.
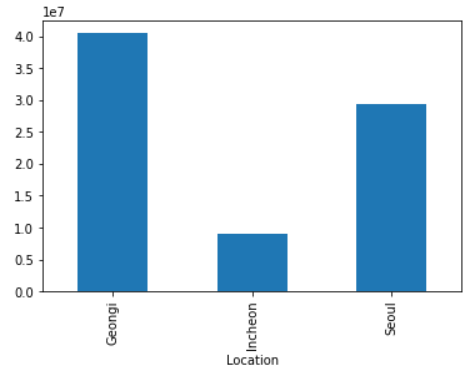
위 그래프에서 볼 수 있듯이, 서울과 경기 지역의 인구가 증가하고 있고, 인천 지역은 상대적으로 인구 증가율이 낮은 것을 알 수 있습니다.
3. 그룹화된 데이터에 대한 연산
groupby() 함수는 그룹화된 데이터에 대한 연산을 수행할 수 있습니다. 예를 들어, 다음과 같은 데이터가 있다고 가정해봅시다.
import pandas as pd
import numpy as np
data = {'학년': ['1학년', '1학년', '2학년', '2학년', '3학년', '3학년', '3학년'],
'성별': ['남', '여', '남', '여', '남', '여', '여'],
'영어 성적': [80, 90, 70, 60, 85, 95, 75]}
df = pd.DataFrame(data)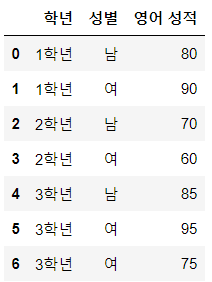
이제 학년을 기준으로 데이터를 그룹화하고, 그룹화된 데이터에 대해 영어 성적의 평균을 구해보겠습니다.
grouped = df.groupby('학년')
result = grouped['영어 성적'].mean()
print(result)위 코드는 학년을 기준으로 데이터를 그룹화하고, 그룹화된 데이터에 대해 영어 성적의 평균을 구합니다. 출력 결과는 다음과 같습니다.
학년
1학년 85.0
2학년 65.0
3학년 85.0
Name: 영어 성적, dtype: float644. 그룹화된 데이터의 피벗 테이블 생성
pivot_table() 함수를 사용하여 그룹화된 데이터의 피벗 테이블을 생성할 수도 있습니다. 예를 들어, 다음과 같은 데이터가 있다고 가정해봅시다.
data = {'국가': ['한국', '한국', '미국', '미국', '일본', '일본', '한국', '미국', '일본'],
'성별': ['남', '여', '남', '여', '남', '여', '남', '여', '남'],
'키': [170, 160, 180, 170, 165, 155, 175, 185, 175],
'몸무게': [70, 60, 80, 65, 70, 50, 75, 85, 70]}
df = pd.DataFrame(data)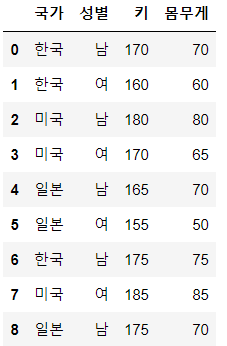
이제 국가와 성별을 기준으로 데이터를 그룹화하고, 키와 몸무게에 대한 피벗 테이블을 생성해보겠습니다.
table = pd.pivot_table(df, index=['국가', '성별'], values=['키', '몸무게'], aggfunc=np.mean)
print(table)위 코드는 국가와 성별을 기준으로 데이터를 그룹화하고, 키와 몸무게에 대한 평균값을 구한 뒤, 이를 피벗 테이블로 생성합니다. 출력 결과는 다음과 같습니다.
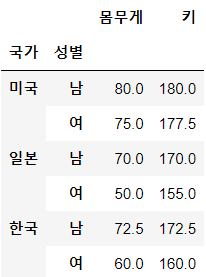
위 피벗 테이블을 보면, 국가와 성별 기준으로 그룹화된 데이터에 대해 키와 몸무게에 대한 평균값을 구한 것을 확인할 수 있습니다. 이처럼 Group By와 pivot_table을 조합하여 다양한 형태의 데이터 분석을 수행할 수 있습니다.
결론
위 예제를 통해 Python에서 Group By의 개념과 활용 예제에 대해 살펴보았습니다. Group By는 데이터를 그룹화하고 그룹화된 데이터에 대한 연산을 수행하는데 매우 유용한 기능입니다. Pandas와 함께 사용하면 데이터를 더 쉽게 분석할 수 있습니다.
