
정규표현식(Regular Expression, RegEx)은 문자열을 처리하고 패턴을 검색하거나 변형할 때 매우 유용한 도구입니다. 데이터 과학과 웹 스크래핑, 텍스트 처리 등 다양한 작업에서 문자열을 다룰 때 정규표현식은 필수적으로 사용됩니다.
이번 포스트에서는 파이썬에서 re 모듈을 사용해 정규표현식을 어떻게 활용할 수 있는지에 대해 자세히 알아보겠습니다.
1. 정규표현식이란?
정규표현식은 특정 패턴을 가진 문자열을 찾기 위한 검색 패턴입니다. 예를 들어, 이메일 주소를 찾거나 전화번호와 같은 특정 형식의 데이터를 추출할 때 사용될 수 있습니다.
정규표현식의 기본적인 개념은 패턴을 정의하고, 그 패턴을 기반으로 문자열을 검색하거나 변형하는 것입니다. 파이썬에서는 이를 위해 re 모듈을 사용합니다.
2. 정규표현식에서 주요 개념 및 패턴
정규표현식(Regular Expression, RegEx)은 문자들로 이루어진 패턴을 정의하고, 이 패턴을 사용해 특정 문자열을 찾거나 바꾸는 도구입니다. 쉽게 말해, 정규표현식은 문자열에서 원하는 부분을 자동으로 찾아내는 '매우 똑똑한' 방법이라고 할 수 있습니다.
아래에서 정규표현식에서 자주 쓰이는 주요 개념들을 하나씩 알아보겠습니다.
-
.(점): 임의의 한 문자와 일치합니다.- 예:
a.c는 "abc", "axc", "a7c"와 일치하지만 "ac", "abbc"와는 일치하지 않습니다.
- 예:
-
\d(숫자): 숫자(0~9)와 일치합니다.- 예:
\d\d는 "12", "89", "45"와 같은 두 자리 숫자와 일치합니다.
- 예:
-
\D(숫자가 아님): 숫자가 아닌 문자와 일치합니다.- 예:
\D는 "a", "Z", "!"와 일치하지만 "1"과는 일치하지 않습니다.
- 예:
-
\w(문자와 숫자): 알파벳 문자, 숫자, 밑줄(_)과 일치합니다.- 예:
\w\w\w는 "abc", "123", "A2_"와 같은 세 개의 문자 또는 숫자와 일치합니다.
- 예:
-
\W(문자와 숫자가 아님): 알파벳 문자, 숫자, 밑줄(_)이 아닌 문자와 일치합니다.- 예:
\W는 "!", "@", "#"와 같은 특수 문자와 일치하지만 "a", "1"과는 일치하지 않습니다.
- 예:
-
\s(공백 문자): 공백 문자(스페이스, 탭, 줄바꿈)와 일치합니다.- 예:
\s는 "Hello World"에서 단어 사이의 공백과 일치합니다.
- 예:
-
\S(공백 문자가 아님): 공백 문자가 아닌 모든 문자와 일치합니다.- 예:
\S는 "Hello"에서 "H", "e", "l", "l", "o"와 각각 일치하지만 공백과는 일치하지 않습니다.
- 예:
-
^(문자열의 시작): 문자열의 시작 부분을 의미합니다.- 예:
^Hello는 "Hello, World!"와 일치하지만 "He said Hello"와는 일치하지 않습니다.
- 예:
-
$(문자열의 끝): 문자열의 끝 부분을 의미합니다.- 예:
World$는 "Hello, World!"와 일치하지만 "World is big"과는 일치하지 않습니다.
- 예:
-
\b(단어 경계): 단어의 경계(단어와 공백 또는 비문자 사이)를 의미합니다.- 예:
\bcat\b는 "cat is here"에서 "cat"과 일치하지만, "concatenation"에서는 일치하지 않습니다.
- 예:
-
\B(비단어 경계): 단어 경계가 아닌 부분과 일치합니다.- 예:
\Bcat\B는 "concatenation"에서 "cat"과 일치하지만, "cat is here"에서는 일치하지 않습니다.
- 예:
-
[](문자 집합): 대괄호 안에 있는 문자 중 하나와 일치합니다.- 예:
[abc]는 "a", "b", "c" 중 하나와 일치합니다. 예를 들어, "apple"에서는 "a", "cat"에서는 "c"와 일치합니다.
- 예:
-
*(0회 이상 반복): 앞의 문자가 0번 이상 반복될 수 있음을 의미합니다.- 예:
a*는 "a", "aa", "aaa"처럼 "a"가 0번 이상 나오는 부분과 일치합니다.
- 예:
-
+(1회 이상 반복): 앞의 문자가 1번 이상 반복될 수 있음을 의미합니다.- 예:
a+는 "a", "aa", "aaa"와 일치하지만, "b"와는 일치하지 않습니다.
- 예:
-
?(0회 또는 1회): 앞의 문자가 0번 또는 1번 나오는 것과 일치합니다.- 예:
a?는 "a" 또는 아무 문자도 없는 부분과 일치합니다.
- 예:
-
{n}(정확히 n회 반복): 앞의 문자가 정확히 n번 나오는 것과 일치합니다.- 예:
a{3}는 "aaa"와 일치하지만, "aa", "aaaa"와는 일치하지 않습니다.
- 예:
3. 파이썬에서 re 모듈 사용하기
re 모듈은 파이썬에서 정규표현식을 지원하는 표준 라이브러리입니다. 이를 사용하면 문자열 검색, 일치 여부 확인, 치환 등의 작업을 할 수 있습니다.
re.search(): 문자열 내에서 정규표현식과 일치하는 첫 번째 위치를 반환합니다.re.match(): 문자열의 시작 부분에서 정규표현식과 일치하는지를 확인합니다.re.findall(): 정규표현식과 일치하는 모든 부분 문자열을 리스트로 반환합니다.re.sub(): 정규표현식에 일치하는 부분을 다른 문자열로 치환합니다.re.split(): 정규표현식에 따라 문자열을 나눕니다.
import re
# 간단한 예제
text = "The rain in Spain"
# 'rain'이라는 단어가 있는지 검색
result = re.search(r"rain", text)
print(result) # <re.Match object; span=(4, 8), match='rain'>3.1 re.search() 함수
re.search()는 주어진 문자열에서 정규표현식과 일치하는 첫 번째 부분을 반환합니다. 일치하는 패턴이 없으면 None을 반환합니다.
# 이메일 형식 찾기
email_text = "My email is example@mail.com"
email_pattern = r"\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b"
email_match = re.search(email_pattern, email_text)
if email_match:
print(f"이메일 주소: {email_match.group()}")
else:
print("이메일 주소를 찾을 수 없습니다.")3.2 re.findall() 함수
re.findall() 함수는 문자열 내에서 정규표현식과 일치하는 모든 부분 문자열을 리스트로 반환합니다.
text = "Call me at 123-456-7890 or 987-654-3210"
phone_pattern = r"\d{3}-\d{3}-\d{4}"
matches = re.findall(phone_pattern, text)
print(matches) # ['123-456-7890', '987-654-3210']3.3 re.sub() 함수
re.sub() 함수는 정규표현식과 일치하는 문자열을 다른 문자열로 치환하는 데 사용됩니다.
text = "My phone number is 123-456-7890."
masked_text = re.sub(r"\d{3}-\d{3}-\d{4}", "XXX-XXX-XXXX", text)
print(masked_text) # My phone number is XXX-XXX-XXXX.3.4 re.split() 함수
re.split() 함수는 정규표현식을 기준으로 문자열을 나눌 때 유용합니다.
text = "apple, banana; orange, pineapple"
split_text = re.split(r"[;,]", text)
print(split_text) # ['apple', ' banana', ' orange', ' pineapple']4. 정규 표현식 예시
🔎 (참고) Notations
- 정규표현식 패턴을 작성할 때, 파이썬에서는 슬래시(/)로 감싸는 대신 문자열 리터럴 r"" 안에 작성합니다. r은 "raw string"을 의미하며, 이 방식으로 작성하면 백슬래시() 같은 특수 문자가 그대로 전달되어 정규표현식에서 올바르게 해석됩니다.
- 파이썬 말고 단순 정규 표현식만을 표기할 때,
^과$는 문자열의 시작과 끝을 의미함.- 파이썬에서는 정규표현식을 슬래시(
/)로 감싸지 않고, 문자열 리터럴(r"")로 사용.
- 플래그 (예: /g): 파이썬에서는 /g 같은 플래그 대신, re 모듈에서 옵션으로 플래그를 전달합니다. 예를 들어, 여러 줄에서 패턴을 검색하고 싶으면 re.MULTILINE 플래그를 사용할 수 있습니다.
/g는 전역 검색을 의미하지만, 파이썬에서는 필요 없음.- 플래그는 파이썬의 re 모듈에서 별도로 처리됩니다.
4.1. 이메일 주소 검증
/^[a-zA-Z0-9._%-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,6}$/- 설명: 이 정규표현식은 이메일 주소 형식을 검증하는데 사용됩니다. 이메일은 반드시
@기호가 포함되어 있고, 뒤에 도메인과 최상위 도메인이 옵니다.^[a-zA-Z0-9._%-]+: 이메일 주소의 사용자 이름 부분을 매칭. 문자, 숫자, 밑줄, 점 등을 허용하며, 하나 이상이 나와야 함.@[a-zA-Z0-9.-]+:@뒤에 도메인 이름을 매칭. 문자, 숫자, 점, 대시를 허용.\.[a-zA-Z]{2,6}$: 마지막으로 최상위 도메인 부분을 매칭. 2~6자리의 문자로 끝나야 함.
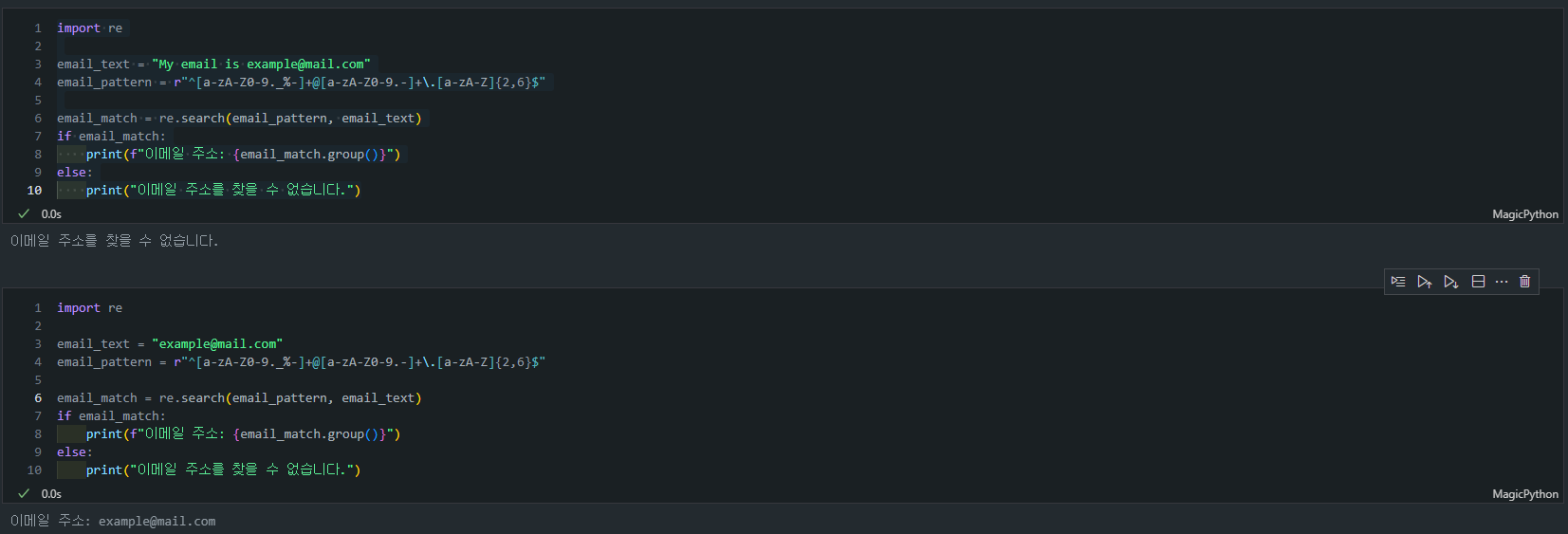
Python에서의 사용 예시는 다음과 같습니다.
import re
email_text = "My email is example@mail.com"
email_pattern = r"^[a-zA-Z0-9._%-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,6}$"
email_match = re.search(email_pattern, email_text)
if email_match:
print(f"이메일 주소: {email_match.group()}")
else:
print("이메일 주소를 찾을 수 없습니다.")- 사용 함수:
re.search()는 문자열 내에서 패턴이 처음으로 일치하는 부분을 찾습니다. 일치하는 부분이 있으면Match객체를 반환하고, 없으면None을 반환합니다.
-
출력 결과:
# 입력 1 email_text = "My email is example@mail.com" # 출력 1 이메일 주소를 찾을 수 없습니다.# 입력 2 email_text = "example@mail.com" # 출력 2 이메일 주소: example@mail.com
왜 다른가?
✍️ 이메일 주소 검증에서는 정규표현식에^(문자열의 시작)과$(문자열의 끝)가 포함되어 있습니다. 이 의미는 해당 정규표현식이 문자열 전체가 이메일 형식과 정확히 일치해야만 매칭된다는 것입니다. 즉, 이메일 이외에 다른 문자열이 포함되어 있으면 그 문자열 전체가 패턴에 맞지 않기 때문에 매칭되지 않습니다.
4.2. URL 매칭
/((([A-Za-z]{3,9}:(?:\/\/)?)(?:[\-;:&=\+\$,\w]+@)?[A-Za-z0-9\.\-]+|(?:www\.|[\-;:&=\+\$,\w]+@)[A-Za-z0-9\.\-]+)((?:\/[\+~%\/\.\w\-_]*)?\??(?:[\-\+=&;%@\.\w_]*)#?(?:[\.\!\/\\\w]*))?)/-
설명: 이 정규표현식은 웹 URL 형식을 매칭합니다. http, https, 또는 www로 시작하고, 도메인 이름과 선택적으로 쿼리 스트링, 프래그먼트가 포함될 수 있습니다. 예시로 가져와 봤는데 생각 이상으로 매운 맛이네요🌶️🌶️(스킵하셔도 됩니다ㅎㅎ) 각각 상세하게 해석해보겠습니다.
-
프로토콜 매칭:
([A-Za-z]{3,9}:(?:\/\/)?)[A-Za-z]{3,9}: 3~9개의 알파벳 문자가 포함된 문자열을 매칭합니다. 이는http,https,ftp,mailto와 같은 인터넷 프로토콜을 매칭하는 부분입니다.:: 프로토콜 뒤에는 반드시 콜론(:)이 따라옵니다.(?:\/\/)?: 선택적인//를 매칭합니다.(?:)는 non-capturing group으로, 이 그룹을 캡처하지는 않지만//자체는 있어야 하는 부분입니다. 그러나//는 필수가 아니기 때문에?를 붙여서 있을 수도 있고 없을 수도 있도록 합니다. (Ex.http://,https://,ftp://등을 처리)
-
도메인 사용자 정보 및 도메인 매칭:
(?:[\-;:&=\+\$,\w]+@)?[A-Za-z0-9\.\-]+-
(?:[\-;:&=\+\$,\w]+@)?: 선택적으로 사용자 정보를 포함할 수 있습니다.- 예를 들어
user:password@처럼 도메인 이전에 사용자 이름과 비밀번호를 포함하는 경우가 있습니다. [\-;:&=\+\$,\w]+: 이 부분에서 사용자 정보와 관련된 다양한 문자를 허용합니다.\w는 알파벳, 숫자, 밑줄을 의미합니다.\-;:&=\+\$는 허용된 특수문자들입니다.
@는 반드시 있어야 하며, 사용자 정보 뒤에 나오는@기호를 처리합니다. 이 부분은 선택적이기 때문에?가 뒤에 붙어 있습니다.
- 예를 들어
-
[A-Za-z0-9\.\-]+: 실제 도메인 이름을 매칭합니다.[A-Za-z0-9]: 도메인은 문자와 숫자로 이루어질 수 있습니다.\.: 도메인 이름 내에 점(.)이 포함될 수 있습니다.- 예를 들어,
example.com에서의 점을 처리하는 부분입니다.
- 예를 들어,
\-: 도메인 이름 내에 하이픈(-)이 포함될 수도 있습니다.- 예를 들어,
my-site.com같은 도메인을 처리합니다.
- 예를 들어,
-
-
www 매칭 또는 사용자 정보 포함 가능:
(?:www\.|[\-;:&=\+\$,\w]+@)[A-Za-z0-9\.\-]+(?:www\.):www.로 시작하는 도메인을 매칭합니다.- 여기서 non-capturing group을 사용한 것은
www.는 있지만 반드시 캡처할 필요가 없는 부분이기 때문입니다.
- 여기서 non-capturing group을 사용한 것은
|[\-;:&=\+\$,\w]+@: 또는 사용자 정보가 포함된 형태(앞서 설명한 부분처럼user:password@)를 처리합니다.
-
경로 매칭:
((?:\/[\+~%\/\.\w\-_]*)?\??(?:[\-\+=&;%@\.\w_]*)#?(?:[\.\!\/\\\w]*))?-
(?:\/[\+~%\/\.\w\-_]*)?: URL의 경로 처리\/: 슬래시(/)로 시작하는 경로를 나타냅니다.- 예를 들어,
/path/to/resource와 같은 경로입니다.
- 예를 들어,
[\+~%\/\.\w\-_]*: 경로 내에 허용되는 다양한 문자를 처리합니다.\w: 알파벳, 숫자, 밑줄(_)을 의미합니다.\-: 하이픈(-).\.,\/,\+,%: 경로에 자주 나타나는 특수 문자입니다.
?: 이 전체 그룹은 선택적이므로, 경로가 없을 수도 있습니다.
-
\??: 쿼리 스트링 처리?: 선택적으로 쿼리 스트링이 붙을 수 있습니다.- 예를 들어,
?key=value같은 형태입니다.
- 예를 들어,
\?는 실제 쿼리 스트링의 시작을 나타내는 물음표(?)를 매칭합니다.?는 물음표가 있을 수도 없을 수도 있음을 나타냅니다.
-
(?:[\-\+=&;%@\.\w_]*): 쿼리 스트링 처리- 쿼리 스트링의 키-값 쌍에서 허용되는 다양한 문자를 처리합니다.
[\-\+=&;%@\.\w_]*: 쿼리 스트링에 포함될 수 있는 문자입니다.- 예를 들어,
key=value&anotherKey=value2처럼 복잡한 형태의 쿼리 스트링을 처리합니다.
- 예를 들어,
-
#?(?:[\.\!\/\\\w]*): 해시 프래그먼트 처리#?: 해시 프래그먼트를 선택적으로 처리합니다. 해시 기호(#)는 있을 수도, 없을 수도 있습니다.(?:[\.\!\/\\\w]*): 해시 프래그먼트 내에 포함될 수 있는 문자입니다. 해시 뒤에는 일반적으로 알파벳, 숫자, 슬래시 등이 포함됩니다.- 예를 들어
#section1같은 형태를 처리합니다.
- 예를 들어
-
-
Python에서의 사용 예시는 다음과 같습니다.
import re
text = "Visit us at https://www.example.com or http://example.org"
url_pattern = r"((([A-Za-z]{3,9}:(?:\/\/)?)(?:[\-;:&=\+\$,\w]+@)?[A-Za-z0-9\.\-]+|(?:www\.|[\-;:&=\+\$,\w]+@)[A-Za-z0-9\.\-]+)((?:\/[\+~%\/\.\w\-_]*)?\??(?:[\-\+=&;%@\.\w_]*)#?(?:[\.\!\/\\\w]*))?)"
urls = re.findall(url_pattern, text)
for url in urls:
print(f"URL: {url[0]}")- 사용 함수:
re.findall()은 문자열 내에서 패턴과 일치하는 모든 부분을 리스트로 반환합니다.

- 출력 결과:
URL: https://www.example.com URL: http://example.org
4.3. 전화번호 (한국 휴대폰 번호 형식)
/010-\d{4}-\d{4}/- 설명: 이 정규표현식은 한국의 표준적인 휴대전화 번호 형식을 매칭합니다.
010-: 전화번호는 항상 "010-"으로 시작합니다.\d{4}-\d{4}: 각각 4자리의 숫자가 나오며, 하이픈(-)으로 구분됩니다.
Python에서의 사용 예시는 다음과 같습니다.
import re
text = "연락처는 010-1234-5678 또는 010-9876-5432입니다."
phone_pattern = r"010-\d{4}-\d{4}"
matches = re.findall(phone_pattern, text)
print(matches) # ['010-1234-5678', '010-9876-5432']- 사용 함수:
re.findall()은 문자열 내에서 패턴과 일치하는 모든 전화번호를 리스트로 반환합니다.

- 출력 결과:
['010-1234-5678', '010-9876-5432']
4.4. 날짜 형식 (MM/DD/YYYY)
/^[0-3]?[0-9](?:\/|\.|-)[0-3]?[0-9](?:\/|\.|-)[1-9]\d{3}$/- 설명: 이 정규표현식은 MM/DD/YYYY 형식의 날짜를 매칭합니다.
[0-3]?[0-9]: 첫 번째 두 자리는 날짜의 일(day)을 의미합니다.(?:\/|\.|-): 구분 기호를 캡처하지 않도록 non-capturing group을 사용합니다.- 이 부분에서 구분 기호(\/, ., -)는 여전히 매칭되지만 캡처되지 않으므로 결과에 포함되지 않습니다.
[0-3]?[0-9]: 두 번째 두 자리는 월(month)을 의미합니다.(?:\/|\.|-): 다시 non-capturing group을 사용하여 구분 기호를 매칭만 하고 캡처하지 않습니다.[1-9]\d{3}: 마지막으로 연도(year)를 의미합니다. 1000년 이후의 네 자리 숫자를 매칭합니다.
(용어) Capturing & Non-Capturing Group
Capturing Group: ( ) 안에 정의된 패턴을 캡처하고 결과로 반환합니다.Non-Capturing Group: ( ? : ) 안에 정의된 패턴을 캡처하지 않고, 패턴 매칭의 일부분으로만 사용합니다. 결과에 포함되지 않습니다.
(용어) 패턴을 캡쳐한다고?
- 정규표현식에서 캡처 그룹을 사용하면, 소괄호
()안에 들어있는 부분을 결과에 포함하거나, 그룹별로 따로 사용할 수 있는 형태로 처리합니다.
- 캡처 그룹은 매칭된 결과를 별도로 저장하거나, 나중에 다시 사용할 수 있는 특별한 기능을 제공합니다.
- 캡처 그룹은 정규표현식에서 매칭된 부분을 별도로 저장하거나, 나중에 참조할 수 있게 해줍니다.
- 예를 들어,
re.findall()은 캡처 그룹이 있다면 해당 그룹의 일치 항목만 결과로 반환합니다.import re text = "My email is example@mail.com" email_pattern = r"([a-zA-Z0-9._%-]+)@([a-zA-Z0-9.-]+\.[a-zA-Z]{2,6})" matches = re.findall(email_pattern, text) print(matches) # [('example', 'mail.com')]
- 여기서
([a-zA-Z0-9._%-]+): 이메일의 사용자 이름 부분을 캡처합니다.([a-zA-Z0-9.-]+\.[a-zA-Z]{2,6}): 도메인 부분을 캡처합니다.- 결과는 두 개의 그룹으로 분리되어 반환됩니다: ('example', 'mail.com').
- 반대로, non-capturing group(
(?: ...))은 해당 패턴을 매칭하되 결과로 반환하지 않고, 단지 패턴을 구성하는 요소로만 사용됩니다.import re text = "My email is example@mail.com" email_pattern = r"(?:[a-zA-Z0-9._%-]+)@(?:[a-zA-Z0-9.-]+\.[a-zA-Z]{2,6})" matches = re.findall(email_pattern, text) print(matches) # ['example@mail.com']
- 여기서 캡처하지 않는 그룹
(?: ...)를 사용하였기 때문에, 이메일의 부분을 캡처하지 않고, 전체 이메일만 매칭하고 결과로 반환합니다: 'example@mail.com'
Python에서의 사용 예시는 다음과 같습니다.
import re
text = "The event is on 12/25/2024 or 01-01-2025."
# 캡처 그룹을 non-capturing group으로 변경
date_pattern = r"[0-3]?[0-9](?:\/|\.|-)[0-3]?[0-9](?:\/|\.|-)[1-9]\d{3}"
dates = re.findall(date_pattern, text)
print(dates) # ['12/25/2024', '01-01-2025']- 사용 함수:
re.findall()은 문자열 내에서 패턴과 일치하는 모든 날짜를 리스트로 반환합니다.

- 출력 결과:
['12/25/2024', '01-01-2025']
4.5. 강력한 비밀번호 검증
/^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)(?=.*[@$!%*?&])[A-Za-z\d@$!%*?&]{10,}$/- 설명: 이 정규표현식은 대문자, 소문자, 숫자, 특수 문자를 모두 포함한 최소 10자리의 강력한 비밀번호를 매칭합니다.
(?=.*[a-z]): 소문자 최소 하나가 포함되어야 함.(?=.*[A-Z]): 대문자 최소 하나가 포함되어야 함.(?=.*\d): 숫자 최소 하나가 포함되어야 함.(?=.*[@$!%*?&]): 특수 문자 최소 하나가 포함되어야 함.[A-Za-z\d@$!%*?&]{10,}: 위 조건을 만족하며 10자리 이상이어야 함.
Python에서의 사용 예시는 다음과 같습니다.
import re
password = "StrongP@ssword1"
password_pattern = r"^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)(?=.*[@$!%*?&])[A-Za-z\d@$!%*?&]{10,}$"
if re.match(password_pattern, password):
print("비밀번호가 유효합니다.")
else:
print("비밀번호가 유효하지 않습니다.")- 사용 함수:
re.match()는 문자열의 시작부터 정규표현식과 일치하는지를 확인합니다.

- 출력 결과:
비밀번호가 유효합니다.
4.6. 사용자명 검증 (알파벳과 숫자, 특정 길이)
/^[a-zA-Z0-9_-]{3,16}$/- 설명: 이 정규표현식은 3~16자의 알파벳, 숫자, 밑줄 또는 대시로 구성된 사용자명을 매칭합니다.
[a-zA-Z0-9_-]: 알파벳, 숫자, 밑줄, 대시를 허용합니다.{3,16}: 최소 3자, 최대 16자까지 허용합니다.
Python에서의 사용 예시는 다음과 같습니다.
import re
username = "user_name123"
username_pattern = r"^[a-zA-Z0-9_-]{3,16}$"
if re.match(username_pattern, username):
print("사용자명이 유효합니다.")
else:
print("사용자명이 유효하지 않습니다.")- 사용 함수:
re.match()는 문자열의 시작부터 정규표현식과 일치하는지를 확인합니다.

- 출력 결과:
사용자명이 유효합니다.
4.7. IP 주소 검증 (IPv4 형식)
/^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/- 설명: 이 정규표현식은 IPv4 형식의 IP 주소를 매칭합니다.
25[0-5]: 250~255 범위의 숫자.2[0-4][0-9]: 200~249 범위의 숫자.[01]?[0-9][0-9]?: 0~199 범위의 숫자.\.: 각 숫자 구간은 점(.)으로 구분됩니다.
Python에서의 사용 예시는 다음과 같습니다.
import re
ip = "192.168.0.1"
ip_pattern = r"^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$"
if re.match(ip_pattern, ip):
print("IP 주소가 유효합니다.")
else:
print("IP 주소가 유효하지 않습니다.")- 사용 함수:
re.match()는 문자열의 시작부터 정규표현식과 일치하는지를 확인합니다.

- 출력 결과:
IP 주소가 유효합니다.
4.8. 숫자만 허용
/^\d+$/- 설명: 이 정규표현식은 숫자로만 구성된 문자열을 매칭합니다.
^\d+$: 숫자(\d)가 1회 이상 (+) 반복되며, 문자열의 시작(^)과 끝($)이 숫자여야 함.
Python에서의 사용 예시는 다음과 같습니다.
import re
text = "12345"
number_pattern = r"^\d+$"
if re.match(number_pattern, text):
print("숫자만 포함된 문자열입니다.")
else:
print("숫자만 포함되지 않은 문자열입니다.")- 사용 함수:
re.match()는 문자열의 시작부터 정규표현식과 일치하는지를 확인합니다.

- 출력 결과:
숫자만 포함된 문자열입니다.
4.9. 알파벳과 숫자만 허용 (공백 없이)
/^[a-zA-Z0-9]*$/- 설명: 이 정규표현식은 공백 없이 알파벳과 숫자로만 이루어진 문자열을 매칭합니다.
[a-zA-Z0-9]: 알파벳 대소문자와 숫자.*: 0회 이상 반복을 허용.
Python에서의 사용 예시는 다음과 같습니다.
import re
text = "Hello123"
alnum_pattern = r"^[a-zA-Z0-9]*$"
if re.match(alnum_pattern, text):
print("알파벳과 숫자로만 구성된 문자열입니다.")
else:
print("문자열에 다른 문자가 포함되어 있습니다.")- 사용 함수:
re.match()는 문자열의 시작부터 정규표현식과 일치하는지를 확인합니다.

- 출력 결과:
알파벳과 숫자로만 구성된 문자열입니다.
4.10. 신용카드 번호 검증
/^(?:4[0-9]{12}(?:[0-9]{3})?|5[1-5][0-9]{14}|6011[0-9]{12}|622((12[6-9]|1[3-9][0-9])|([2-8][0-9][0-9])|(9(([0-1][0-9])|(2[0-5]))))[0-9]{10}|64[4-9][0-9]{13}|65[0-9]{14}|3(?:0[0-5]|[68][0-9])[0-9]{11}|3[47][0-9]{13})*$/- 설명: 이 정규표현식은 다양한 신용카드 형식을 매칭합니다. 비자, 마스터카드, 디스커버 카드 등을 검증할 수 있습니다.
4[0-9]{12}(?:[0-9]{3})?: 비자 카드.5[1-5][0-9]{14}: 마스터카드.6011[0-9]{12}: 디스커버 카드.65[0-9]{14}: 또 다른 카드 형식.
Python에서의 사용 예시는 다음과 같습니다.
import re
text = "My card number is 4111-1111-1111-1111"
card_pattern = r"(?:4[0-9]{12}(?:[0-9]{3})?|5[1-5][0-9]{14}|6011[0-9]{12}|65[0-9]{14})"
card_match = re.search(card_pattern, text.replace("-", ""))
if card_match:
print("신용카드 번호가 유효합니다.")
else:
print("신용카드 번호가 유효하지 않습니다.")- 사용 함수:
re.search()는 문자열 내에서 패턴이 일치하는 부분을 찾습니다.
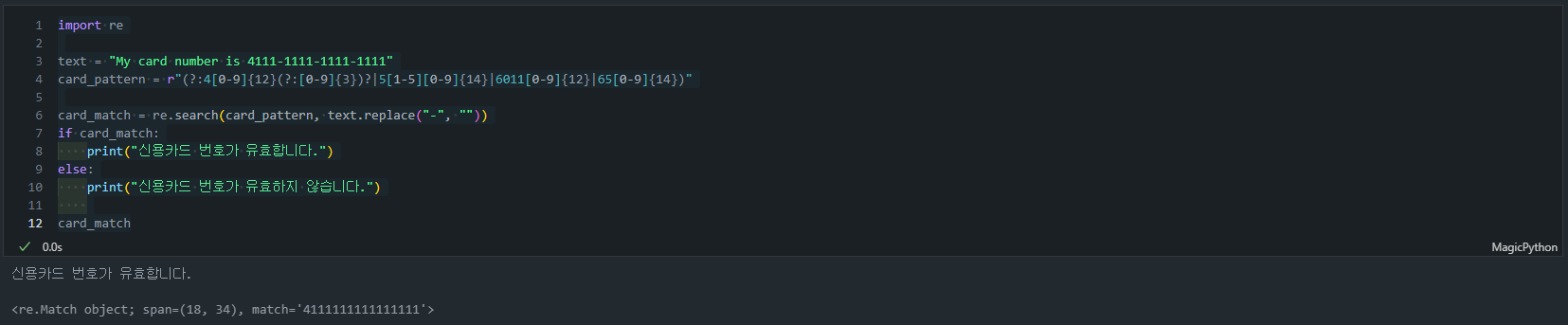
- 출력 결과:
신용카드 번호가 유효합니다.
4.11. 한글만 포함하는 문자열 검사
/^[가-힣]+$/- 설명: 이 정규표현식은 한글 문자만으로 이루어진 문자열을 매칭합니다.
[가-힣]: 한글 완성형 범위를 의미합니다.
Python에서의 사용 예시는 다음과 같습니다.
import re
text = "안녕하세요"
hangul_pattern = r"^[가-힣]+$"
if re.match(hangul_pattern, text):
print("한글로만 이루어진 문자열입니다.")
else:
print("한글 이외의 문자가 포함되어 있습니다.")- 사용 함수:
re.match()는 문자열의 시작부터 정규표현식과 일치하는지를 확인합니다.

- 출력 결과:
한글로만 이루어진 문자열입니다.
4.12. 한글 포함 여부 검사
/[가-힣]/- 설명: 이 정규표현식은 문자열에 한글이 포함되어 있는지 여부를 검사합니다.
[가-힣]: 한글 완성형 문자를 의미합니다.
Python에서의 사용 예시는 다음과 같습니다.
import re
text = "Hello, 안녕하세요!"
hangul_included_pattern = r"[가-힣]"
if re.search(hangul_included_pattern, text):
print("문자열에 한글이 포함되어 있습니다.")
else:
print("문자열에 한글이 포함되어 있지 않습니다.")- 사용 함수:
re.search()는 문자열 내에서 패턴이 처음으로 일치하는 부분을 찾습니다.

- 출력 결과:
문자열에 한글이 포함되어 있습니다.
4.13. 완성형 한글 검사 (자음, 모음 제외)
/^[가-힣]*$/- 설명: 이 정규표현식은 완성형 한글로만 구성된 문자열을 매칭합니다. 자음 또는 모음만으로 이루어진 문자열은 매칭되지 않습니다.
Python에서의 사용 예시는 다음과 같습니다.
import re
text = "가나다라마바사"
hangul_complete_pattern = r"^[가-힣]*$"
if re.match(hangul_complete_pattern, text):
print("완성형 한글로만 이루어진 문자열입니다.")
else:
print("완성형 한글 외의 문자가 포함되어 있습니다.")- 사용 함수:
re.match()는 문자열의 시작부터 정규표현식과 일치하는지를 확인합니다.

- 출력 결과:
완성형 한글로만 이루어진 문자열입니다.
4.14. 한글, 자음, 모음 모두 포함
/^[ㄱ-ㅎㅏ-ㅣ가-힣]*$/- 설명: 이 정규표현식은 한글, 자음, 모음이 모두 포함된 문자열을 매칭합니다.
[ㄱ-ㅎㅏ-ㅣ가-힣]: 한글 자음, 모음, 완성형 문자를 모두 포함.
Python에서의 사용 예시는 다음과 같습니다.
import re
text = "ㅏㄱ하"
hangul_full_pattern = r"^[ㄱ-ㅎㅏ-ㅣ가-힣]*$"
if re.match(hangul_full_pattern, text):
print("한글(자음, 모음 포함)로만 이루어진 문자열입니다.")
else:
print("한글 이외의 문자가 포함되어 있습니다.")- 사용 함수:
re.match()는 문자열의 시작부터 정규표현식과 일치하는지를 확인합니다.

- 출력 결과:
한글(자음, 모음 포함)로만 이루어진 문자열입니다.
4.15. 문자를 제외한 특수 기호 제거
/[^a-zA-Z0-9가-힣\s]/g- 설명: 이 정규표현식은 알파벳, 숫자, 한글, 공백을 제외한 모든 특수 문자를 제거합니다.
[^a-zA-Z0-9가-힣\s]: 알파벳, 숫자, 한글, 공백을 제외한 모든 문자를 의미.
Python에서의 사용 예시는 다음과 같습니다.
import re
text = "안녕하세요! Hello, World! 123 @#$%^&*"
cleaned_text = re.sub(r'[^a-zA-Z0-9가-힣\s]', '', text)
print(cleaned_text) # 출력: 안녕하세요 Hello World 123- 사용 함수:
re.sub()는 정규표현식에 일치하는 모든 부분을 지정한 문자열로 치환합니다.

- 출력 결과:
안녕하세요 Hello World 123
5. 마치며
파이썬의 re 모듈과 정규표현식을 활용하면 복잡한 문자열 처리를 손쉽게 할 수 있습니다. 이번 포스트에서 다룬 기본적인 정규표현식 패턴과 re 모듈의 함수들을 잘 활용하면 다양한 텍스트 데이터에서 패턴을 찾아내고, 변형하거나 필요한 정보를 추출하는 작업을 더 효율적으로 할 수 있습니다.
