파이썬의 Pandas 라이브러리는 데이터 분석 및 조작을 위한 필수 도구입니다. 특히, 데이터를 효과적으로 정렬하고 분석하는 것은 데이터 과학자의 중요한 과제 중 하나입니다. 이전 포스트들에서도 몇 번 개념 및 주요 함수들을 소개해드렸는데요.
이 글에서는 주로 사용하는 Pandas의 정렬 및 분석에 유용한 테크닉과 함께, 실무에서 바로 활용할 수 있는 스니펫을 소개합니다. 각 스니펫은 바로 복사하여 사용할 수 있도록 구성되어 있으니, 필요할 때마다 빠르게 참조해보세요! (실은 제가 쓰려고 만들어둔 것은 안 비밀)
1. 정렬 옵션
📌 sort_values()로 컬럼 값 기준 정렬
-
sort_values()메서드를 사용하면 특정 컬럼을 기준으로 데이터프레임을 정렬할 수 있습니다.## 특정 컬럼을 기준으로 오름차순 정렬 (default: 오름차순) df_sorted = df.sort_values(by='column_name') ## 여러 컬럼을 기준으로 정렬, 첫 번째는 오름차순, 두 번째는 내림차순 df_sorted = df.sort_values(by=['column1', 'column2'], ascending=[True, False])
📌 sort_index()로 인덱스 기준 정렬
-
데이터 프레임의 인덱스를 기준으로 정렬할 때
sort_index()를 사용합니다. 주로 시간순 데이터를 다룰 때 유용합니다.## 인덱스를 오름차순으로 정렬 df_sorted = df.sort_index() ## 인덱스를 내림차순으로 정렬 df_sorted = df.sort_index(ascending=False)
📌 내림차순 정렬과 원본 수정
-
정렬 시
ascending=False옵션을 사용하여 내림차순으로 정렬할 수 있습니다.inplace=True옵션을 추가하면 원본 데이터프레임이 수정됩니다.## 내림차순 정렬 및 원본 수정 df.sort_values(by='column_name', ascending=False, inplace=True)
📌 정렬 알고리즘 선택
-
sort_values()는 기본적으로 'quicksort' 알고리즘을 사용합니다. 안정적인 정렬이 필요할 때는 'mergesort'를 선택할 수 있습니다.## 안정적인 정렬을 위해 mergesort 사용 df_sorted = df.sort_values(by='column_name', kind='mergesort')
2. 컬럼 변경
데이터 분석 시 컬럼의 이름을 변경하거나 순서를 재배치하는 것은 매우 자주 발생하는 작업입니다. Pandas에서는 간단한 명령어로 컬럼 이름을 수정하고, 순서를 변경할 수 있습니다.
📌 컬럼 이름 변경
-
컬럼의 이름을 쉽게 변경할 수 있습니다. dict를 사용하여 여러 컬럼의 이름을 동시에 바꾸거나, 특정 컬럼만 선택적으로 수정 가능합니다.
# 원본 데이터프레임 수정 (inplace=True) df.rename(columns={'old_name': 'new_name'}, inplace=True)
📌 정렬 기반 컬럼 순서 변경
-
컬럼 이름을 알파벳 순 또는 사전 순으로 정렬할 수 있습니다.
df.columns = df.columns.sort_values() # 방법1 df.columns = sorted(df.columns) # 방법2
📌 일부 컬럼 순서 변경하기
-
필요한 일부 컬럼만을 맨 앞에 배치하고 나머지 컬럼은 기존 순서를 유지할 수 있습니다.
# 'Date'와 'Time' 컬럼을 맨 앞에 배치 desired_order = ['Date', 'Time'] df = df[desired_order + [col for col in df.columns if col not in desired_order]]
3. 데이터 필터링
데이터를 분석할 때 특정 조건에 맞는 데이터만 추출하는 것이 매우 중요합니다.
📌 단일 조건 필터링
# 특정 컬럼 값이 100보다 큰 행만 필터링
filtered_df = df[df['column_name'] > 100]📌 여러 조건을 조합한 필터링
# 여러 조건을 조합한 필터링
filtered_df = df[(df['column1'] > 100) & (df['column2'] == 'specific_value')]4. 데이터 탐색
데이터 탐색은 분석 작업의 첫 단계로, 데이터의 구조와 주요 특징을 파악하는 데 중요합니다.
- Pandas에서는 간단한 명령어로 데이터의 요약 정보, 기술 통계, 결측치 등을 빠르게 확인할 수 있습니다.
# 처음 5행 보기
df.head()
# 기본 정보 보기
df.info()
# 기술 통계량 보기
df.describe()
# 결측치 확인
df.isnull().sum()5. 결측치 처리
실제 데이터에서 결측치는 매우 흔하게 발생하는 문제입니다. Pandas는 결측치를 처리할 수 있는 다양한 방법을 제공합니다. 결측치를 제거하거나, 특정 값으로 대체할 수 있습니다.
- 해당 섹션에서는
dropna,fillna,bfill,ffill등 결측치 처리 방법을 다루겠습니다.
📌 dropna()로 결측치 제거
-
dropna()는 결측치가 포함된 행 또는 열을 제거합니다. 결측치가 있는 데이터를 제외하고 분석을 진행할 때 유용합니다.# 결측치가 포함된 행을 제거 df_cleaned = df.dropna() # 특정 컬럼에서 결측치가 포함된 행만 제거 df_cleaned = df.dropna(subset=['column_name'])
📌 fillna()로 결측치 채우기
-
fillna()를 사용하여 결측치를 특정 값으로 대체할 수 있습니다. 평균값, 중간값 또는 고정된 값을 사용하여 결측치를 채울 수 있습니다.# 결측치를 0으로 대체 df_filled = df.fillna(0) # 특정 컬럼의 결측치를 평균값으로 대체 df['column_name'] = df['column_name'].fillna(df['column_name'].mean())
📌 bfill()로 결측치 뒤에서 채우기
-
bfill()은 결측치가 있는 셀을 뒤에 있는 값으로 채웁니다. 시간 순서 데이터에서 결측치를 뒤의 값으로 채워 연속성을 유지할 때 유용합니다.# 결측치를 뒤의 값으로 채우기 df_bfill = df.fillna(method='bfill')
📌 ffill()로 결측치 앞에서 채우기
-
ffill()은 결측치가 있는 셀을 앞에 있는 값으로 채웁니다. 이는 연속적인 값이 필요한 데이터에서 결측치를 채울 때 유용합니다.# 결측치를 앞의 값으로 채우기 df_ffill = df.fillna(method='ffill')
6. Lambda 함수로 데이터 변환
Lambda 함수와apply()메서드를 사용하면 데이터를 변환할 때 매우 유용합니다.
📌 조건부 수치 변환
-
특정 값 이상이거나 이하인 경우 값을 특정 상수로 변환하거나, 특정 범위에 속할 때 다른 값을 대입할 수 있습니다.
# 값이 0보다 작으면 0으로 변환, 그렇지 않으면 그대로 유지 df['non_negative'] = df['value'].apply(lambda x: 0 if x < 0 else x)
📌 여러 조건을 처리하기
-
여러 조건을 처리해야 하는 경우,
elif대신else를 중첩시켜 사용할 수 있습니다.# 100 이상은 'A', 50 이상은 'B', 그 외는 'C'로 분류 df['grade'] = df['score'].apply(lambda x: 'A' if x >= 100 else ('B' if x >= 50 else 'C'))
📌 대소문자 변환
-
문자열을 대문자나 소문자로 변환하는 람다 함수 예시입니다.
# 컬럼의 모든 값을 대문자로 변환 df['upper_case'] = df['text_column'].apply(lambda x: x.upper())
📌 리스트 데이터를 변환하기
-
람다 함수는 리스트나 배열 형태의 데이터를 처리할 때도 유용합니다.
# 리스트 내 요소의 개수에 따라 값 변환 df['list_length'] = df['list_column'].apply(lambda x: len(x))
📌 문자열 길이에 따라 필터링
-
문자열의 길이에 따라 조건을 걸어 처리할 수 있습니다.
# 문자열 길이가 5 이상인 경우에만 유지하고, 그렇지 않으면 'Short'로 변환 df['processed_text'] = df['text_column'].apply(lambda x: x if len(x) >= 5 else 'Short')
7. 그룹화 및 집계
- 데이터를 그룹화하여 집계할 때는
groupby()를 사용합니다. 이를 통해 다양한 통계를 낼 수 있습니다.
# 카테고리별 평균값 계산
grouped_df = df.groupby('category_column')['numeric_column'].mean()
# 다중 컬럼 그룹화 후 집계
grouped_df = df.groupby(['category1', 'category2'])['numeric_column'].agg(['mean', 'sum'])8. 데이터 타입 변환
데이터 분석을 위해 컬럼의 데이터 타입을 변환해야 하는 경우가 많습니다.
📌 문자열을 날짜로 변환
# 문자열을 날짜 타입으로 변환
df['date_column'] = pd.to_datetime(df['date_column'])📌 수치형 데이터를 카테고리형으로 변환
# 수치형 데이터를 카테고리형으로 변환
df['category_column'] = df['category_column'].astype('category')마무리
Pandas의 다양한 기능을 활용하면 데이터를 보다 쉽게 정렬하고 분석할 수 있습니다. 이 글에서 소개한 스니펫들은 실무에서 자주 사용되는 테크닉들로, 필요할 때마다 빠르게 복사하여 사용할 수 있도록 준비되었습니다. Pandas의 풍부한 기능들을 익히면 데이터 조작과 분석 작업에서 큰 효율성을 얻을 수 있을 것입니다.
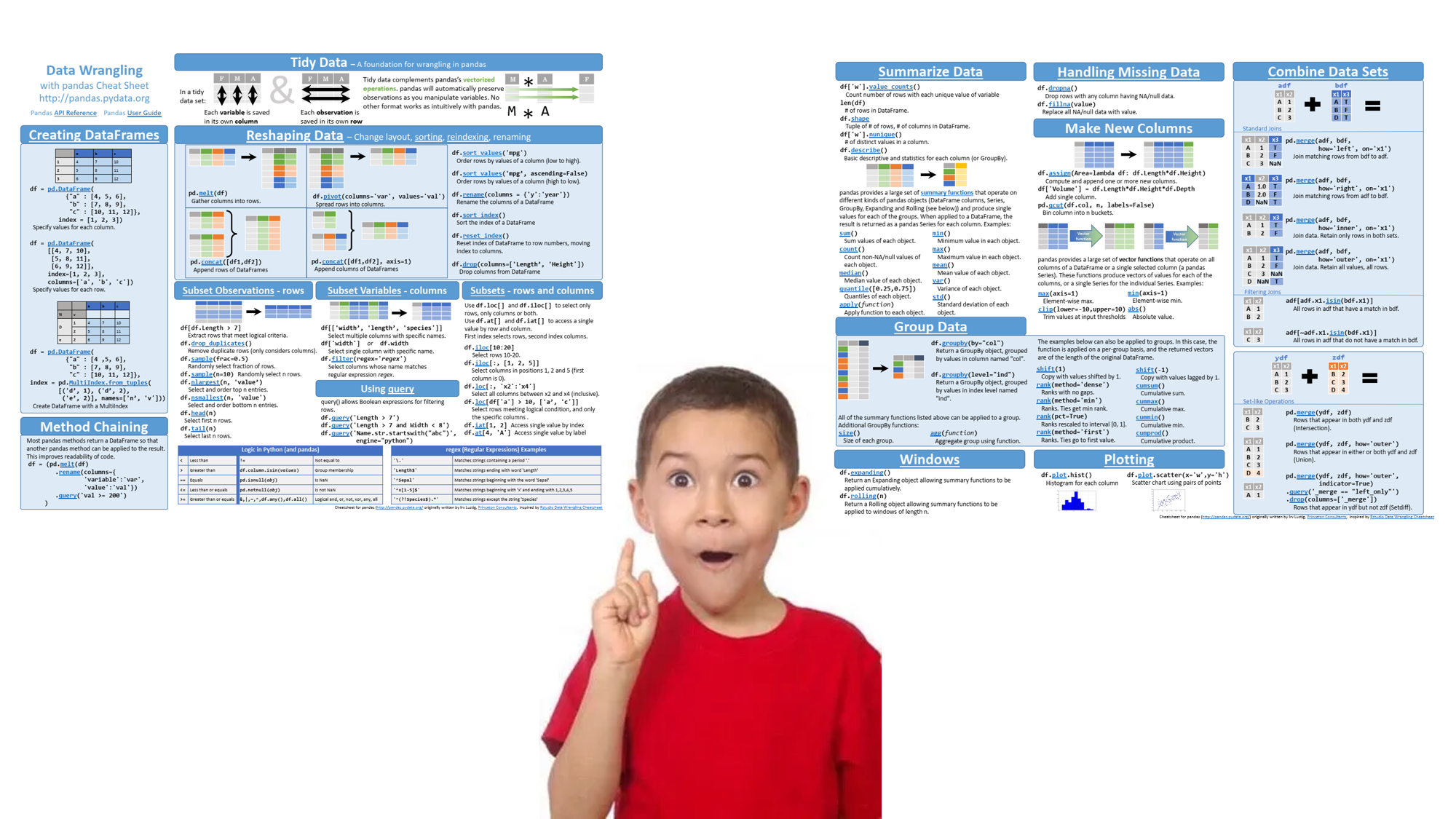
마지막으로 Pandas에서 공식으로 작성한 Cheating Sheet 공유드리면서 이번 포스트 마쳐보도록 하겠습니다! (링크: https://pandas.pydata.org/Pandas_Cheat_Sheet.pdf)


또 추가할 코드 블록이 있다면 댓글로 달아주세요 🤗🔎
