
혹시나 잘못된 개념 전달이 있다면 댓글 부탁드립니다. 저의 성장의 도움이 됩니다
오늘의 Checkpoint
웹 애플리케이션 아키텍처
클라이언트 서버 아키텍처
-
2-tier architecture
리소스의 사용 / 존재 위치가 분리된 모델
-> 네트워크를 통해 실시간으로 데이터를 전달
-> 클라이언트(사용) + 서버(존재) -
3-tier architecture
클라이언트와 서버에 리소스를 제공하는 데이터베이스가 추가된 모델
-> 클라이언트(사용) + 서버(전달) + DB(제공)
클라이언트
: 리소스를 사용하는 곳
- 서버로 요청
- 유저와의 상호작용 담당
ex. 웹개발에서의 클라이언트는 브라우저, 결제기능, 상품 조회 기능 등
서버
: 리소스(데이터)가 전달하는 곳
- 클라이언트에 응답
- DB에 요청
ex. 상품 정보 노출, 사용자 인증 등
데이터베이스
: 리소스를 저장/제공하는 곳
요청과 응답
클라이언트는 서버로 요청을 보내면 서버는 응답하고 클라이언트로 데이터를 전송
만약, 리소스가 없다면 서버는 DB에 요청하여 받은 데이터를 클라이언트로 전달
- 요청 -> 응답
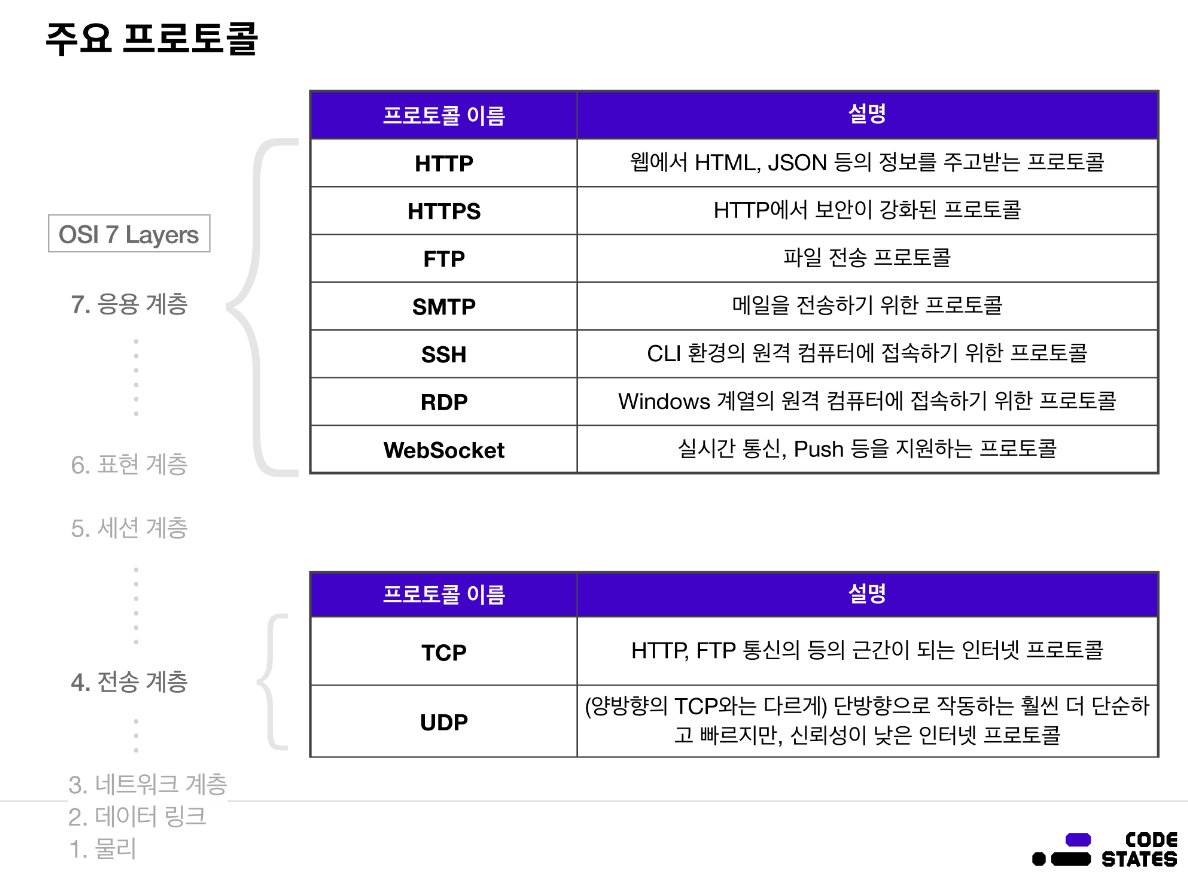
프로토콜 Protocal
통신 규약으로 요청/응답을 할 때 지켜야하는 약속들을 정의
- HTTP
: 웹 애플리케이션 프로토콜로 인터넷에서 데이터를 주고 받을때 사용
-> 주소(URL, URI)를 통해 접근- HTTP 메세지 : HTTP를 이용하여 주고받는 메세지
API
Application Programming Interface
사용자 메뉴얼처럼 리소스를 사용할 수 있도록 작성된 인터페이스
-> 클라이언트는 서버 측에서 제공한 API 방식대로 요청하여 서버와 소통
-> 소통을 위해 API를 알아보기 쉽게 디자인해아햠
cf. 좋은 API를 디자인 하기 위해 REST API 형식으로 작성
cf. 객체지향 프로그래밍에서 추상화와 관련됨
HTTP API 디자인
HTTP 요청시 메소드와 함께 사용하여 원하는 동작에 맞는 CRUD 지정하는 과정
-> URL 설정 + HTTP 메서드 지정
# 아메리카노 2잔 주문 예시
/coffee/americano?quantity=3
# 라떼 3잔 바닐라 시럽 넣어서 주문 예시
/coffee/latte?quantity=3&syrup=vanillacf. URL 디자인 레퍼런스
⭐️ HTTP 메서드
요청의 의도에 따라 다른 메소드 사용
ex. 게시글 조회할 때는 GET, 새로 작성한 글을 추가할 때는 POST를 적용
| method | CRUD |
|---|---|
| GET | Read |
| POST | Create |
| PUT | Update |
| PATCH | Update |
| DELETE | Delete |
| OPTIONS | - |
URL vs URI
브라우저의 주소창 url은 서버 속의 파일 위치를 의미
-> 실제로는 URI에 해당

URL
Uniform Resource Locator
네트워크에서 파일의 위치에 대한 정보를 의미
-
scheme
: 통신 방식, 즉 프로토콜
ex.file://,http://,https:// -
hosts
: 웹 페이지, 이미지, 동영상 등의 파일이 위치한 웹 서버, 도메인 또는 IP
ex. 로컬PC인127.0.0.1,www.google.com- port
: 웹 서버의 진입 통로
-> host에 이어서:port번호로 입력
cf. 보통은 0~1024번까지의 번호는 주요 통신 규약에 의해 정해져있음:22: SSH:80: HTTP -> URI에서 생략 가능:443: HTTPS -> URI에서 생략 가능
더 많은 포트 번호 확인하기
- port
-
url-path
: 지정된 root directory에서 파일의 위치까지의 경로와 파일명 표기
->/이후가 패스로/도 패스로 인식
->www.google.co.kr/(O)www.google.co.kr(X)
ex./search,/Users/username/Desktop
URI
Uniform Resource Identifier
통합 자원 식별자는 URL을 포함하는 상위 개념으로 URL의 기본 요소에 query, fragment 포함된 개념
-
query
: 서버에 보내는 추가 질문으로?부터 시작됨
?이후에 나오는 쿼리 부분은 파라미터의 조합으로&로 여러개를 나열할 수 있음
ex.?q=JavaScript,?titleId=748105&no=175&weekday=thu -
fragment
: 일종의 북마크 기능 수행하며#+HTML요소의id를 더하면 지정된 부분으로 스크롤됨
ex.#section1
IP 주소
Internet Protocol address
특정한 대상(PC)이 연결된 네트워크를 가리키는 주소 체계
-> 컴퓨터의 식별 번호 X
- IPv4
:.으로 구분된 4개의 숫자 묶음(0 ~ 255까지의 범위)으로 표현
-> 2^(32) 개수만큼의 주소127.0.0.1,localhost는 로컬PC를 의미0.0.0.0,255.255.255.255
: 로컬 네트워크에 접속된 모든 장치에서 접근가능한 주소(= broadcast address)
- IPv6
: IP 주소 부족으로 도입된 새로운 주소 체계
:으로 구분된 8개의 16진수 숫자 묶음으로 표현
-> 2^(128) 개수만큼의 주소

도메인과 DNS
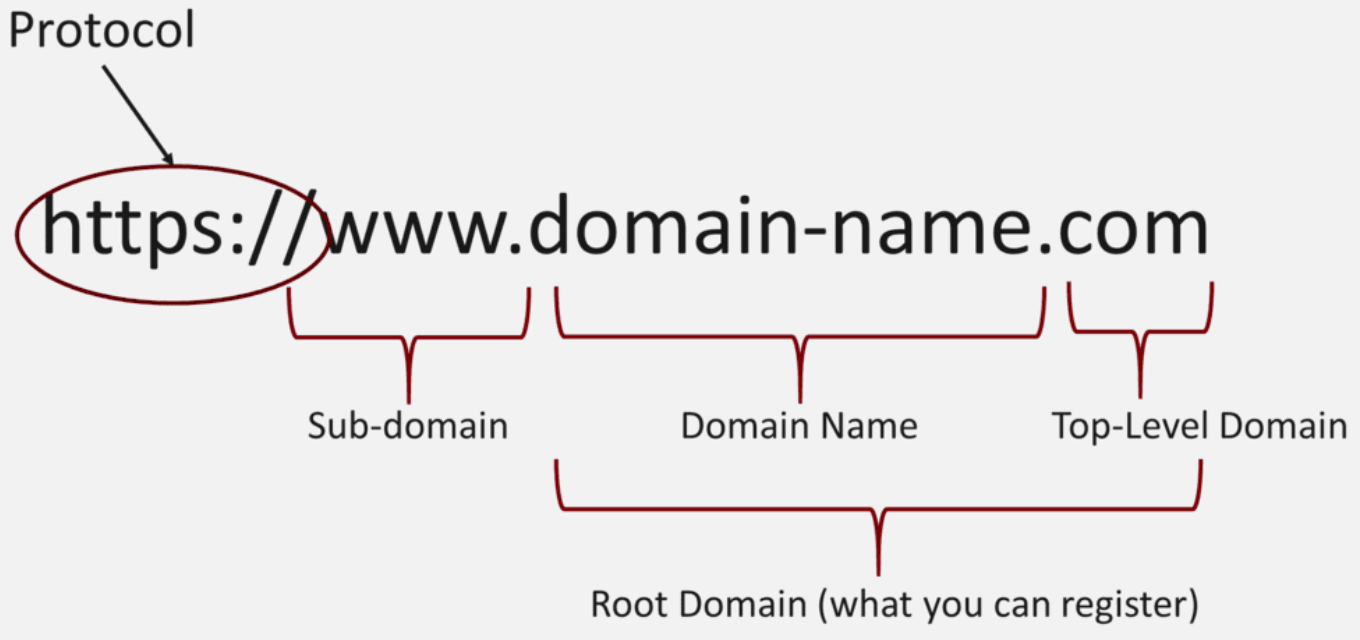
Domain name
IP주소를 대신하여 사람이 기억하기 쉬운 문자로 표현된 주소
-
TLD (Top Level Domain)
: 가장 오른쪽에 위치하는 도메인으로 최상위 도메인
ex..com,.kr,.net,.co.kr(국가 코드를 사용하는 도메인은.co,.ac와 같은 2단계 도메인과 함께 사용) -
SLD(Secondary Level Domain)
: TLD 바로 앞에 위치하며 우리가 흔히 도메인이라고 생각하는 부분
ex.starbucks,velog -
Sub Domain
: 가장 왼쪽에 위치한 부분으로 특정한 목적으로 웹페이지를 분리하거나 특별한 정보를 담을때 사용
ex.www(기본),m(모바일) ,store(스토어)
cf. 터미널 CLI에서 nslookup 과 함께 도메인을 입력하면 IPv4 조회 가능
DNS
Domain Name System
일정 기간 동안 대여하여 이용하는 도메인으로 접속시 매칭되는 IP 주소 찾아주는 데이터베이스 시스템(서버)
-> host의 도메인을 전달하면 IP주소로 변환
-> 안정성과 효율을 위해 여러개의 서버(DNS Zone)로 구성
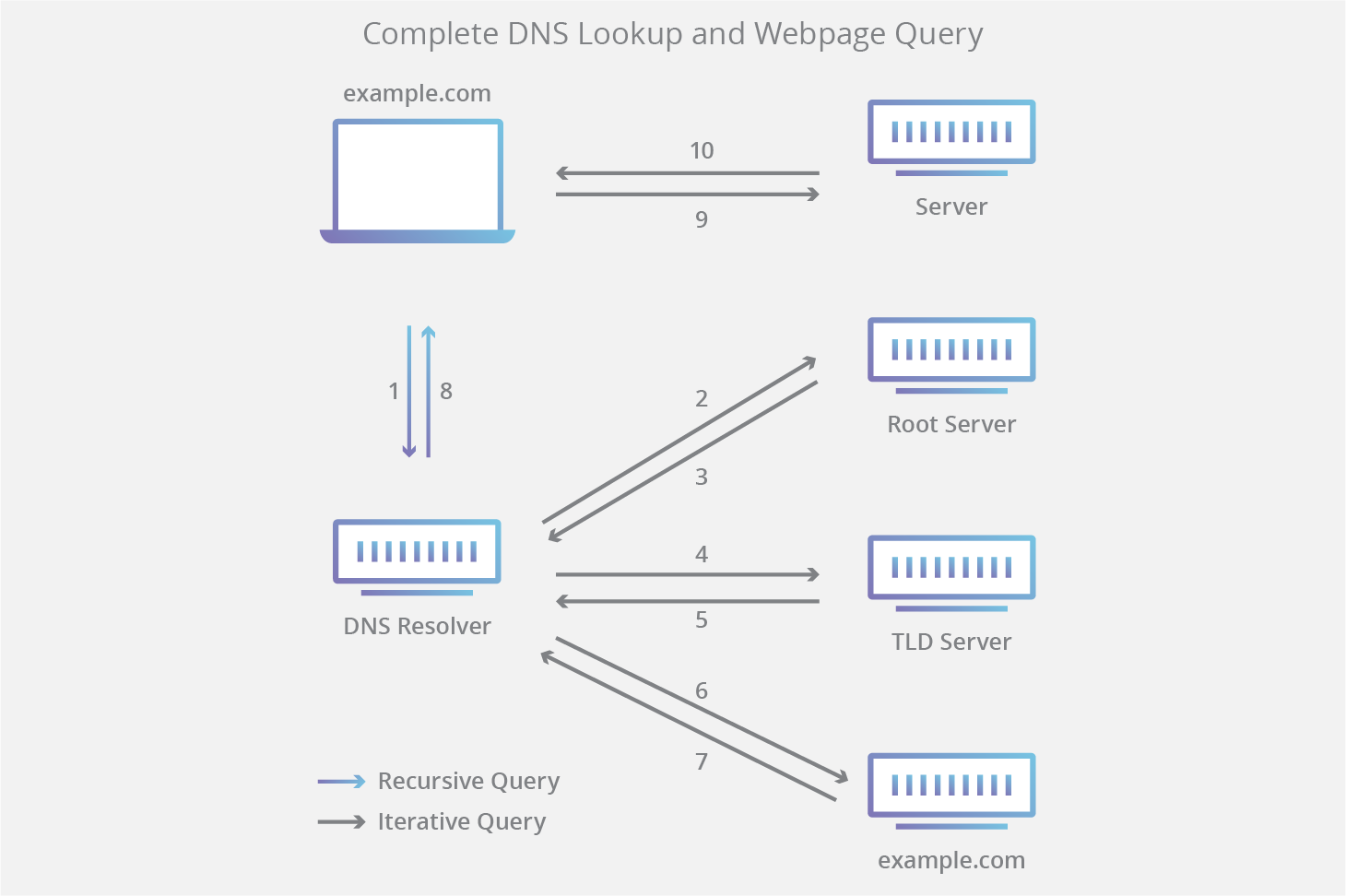
DNS Lookup
브라우저에 도메인을 입력하면 도메인이 해석되는 과정
-
Resolver
: 클라이언트와 연결되어 도메인 해석을 요청을 받는 서버
가장 먼저 이전에 조회한 내역이 담긴 캐시 파일을 살펴보고 해당하는 정보가 있다면 즉시 반환하고, 없는 경우 다른 DNS 서버와 연결되어 최종적으로 IP 주소를 응답받아 클라이언트로 전달 -
Root name server
: 해석 과정의 1단계로, TLD 서버의 주소를 반환 -
TLD name server
: 도메인 확장자 즉 최상위 도메인에 대한 정보를 가지고 있으며, 권한있는 서버의 주소를 반환 -
권한있는 서버
: 해석 과정의 마지막 단계로 찾으려는example.com등의 도메인 정보를 관리하는 권한을 가진 서버는 IP 주소를 반환하여 Resolver에 전달
Zone File
DNS 서버에 맵핑되어있는 파일로 이 파일들을 바탕으로 데이터(IP or 서버 주소)를 반환
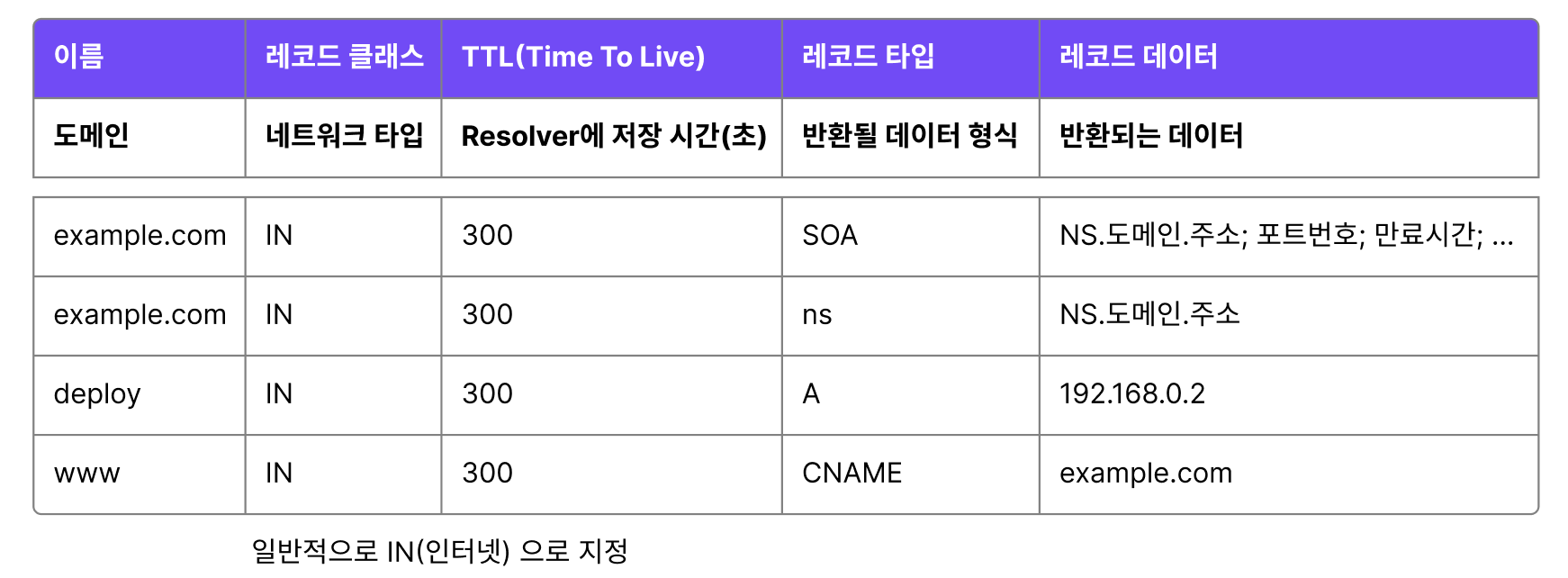
- 레코드 타입
- SOA : 주요 DNS 서버의 정보에 대한 데이터
- A : IPv4 주소로 연결
AAAA : IPv6 주소로 연결 - CNAME : IP가 유동적일 때 별칭(canonical name)으로 연결
- NS : 권한있는 DNS 서버의 주소로 연결 -> IP 주소를 찾을 수 있는 곳을 알려줌
위 예시는 192.168.0.2 는 deploy 서브 도메인의 주소이고, www 서브 도메인은 example.com 도메인으로 연결되어 있음
⭐️ HTTP
HyperText Transfer Protocol
웹에서 데이터를 주고받는 프로토콜
-
1 요청 -> 1 응답
-
무상태성 Stateless
: 통신 과정에서 HTTP 자체가 클라이언트나 서버의 상태를 기록하지 않음
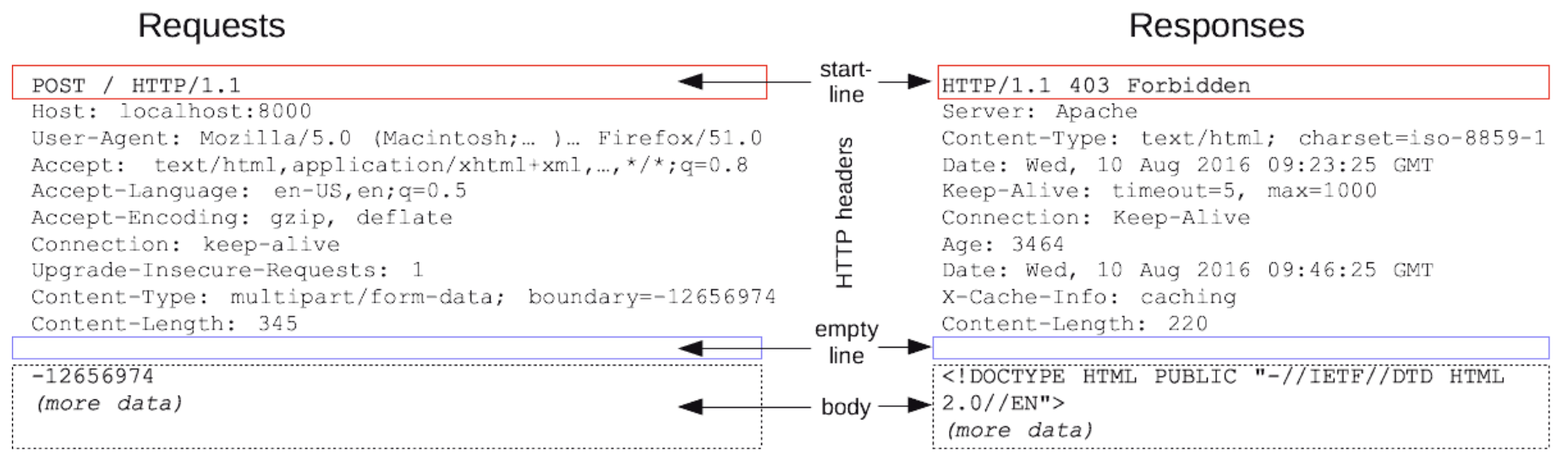
HTTP Messages
HTTP 프로토콜로 서버와 클라이언트가 데이터를 주고 받을때의 요청/응답 양식
cf. 구성 파일, API, 기타 인터페이스에서 HTTP Messages를 자동으로 완성
-
start line
: 요청/응답 상태 표시 -
HTTP headers
: Host 등을 포함하여 요청에 대한 설명이나 본문을 설명하는 부분
cf. 요청/응답 헤드 : start line 와 HTTP headers를 통으로 묶은 개념 -
empty line
: body와 구분짓는 빈 한줄 -
body
: 요청에 필요한 데이터나 응답에서는 회신하는 데이터 혹은 문서를 포함
cf. Payload : 헤더와 메타데이터를 제외한 보내고자 하는 데이터 자체를 의미
HTTP Resquests
- 클라이언트 -> 서버
Start line
- HTTP 메서드
- URI path(End point)
origin, absolute, autority, asterisk 형식 - HTTP 버전
POST / HTTP 1.1
GET /background.png HTTP/1.0
HEAD /test.html?query=alibaba HTTP/1.1
OPTIONS /anypage.html HTTP/1.0Headers
- 헤더이름 : 값
cf. 헤더이름은 대소문자 구분없는 문자열
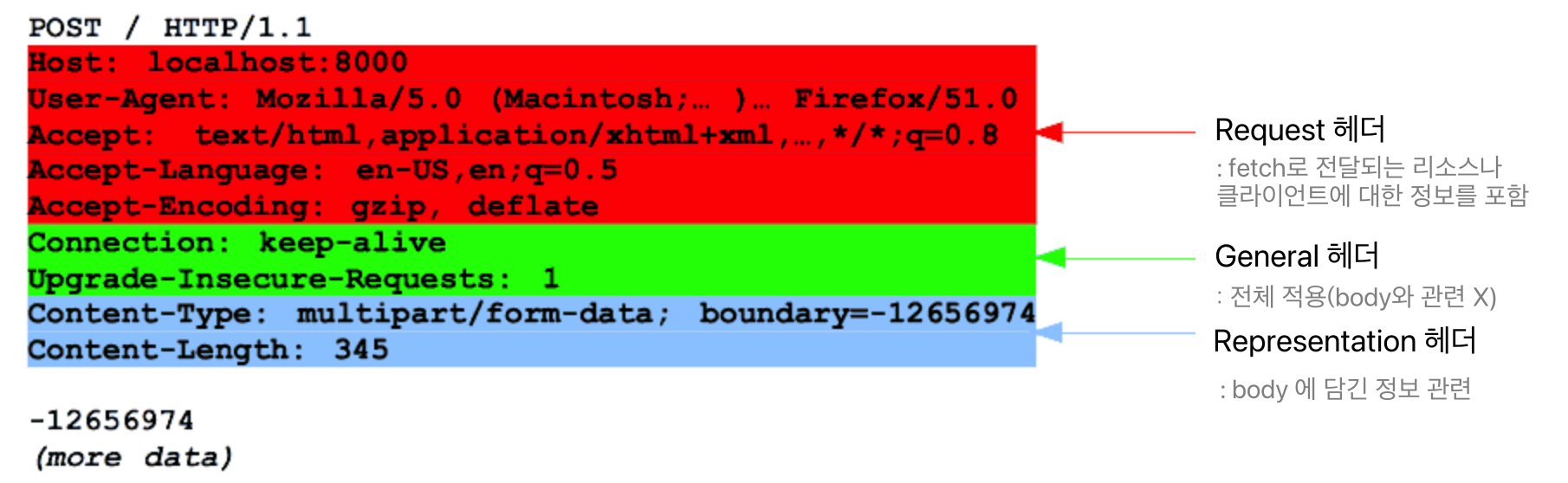
- Request headers
- General headers
- Representation headers(=Entitiy headers)
Body
: POST 혹은 PUT 같은 업데이트 요청시에 사용
- Single-resource bodies(단일-리소스 본문)
- Multiple-resource bodies(다중-리소스 본문)
HTTP Resquests
- 서버 -> 클라이언트
Start line
- HTTP 버전
- 상태 코드
- 상태 코드 설명
HTTP 1.1 200 OK
HTTP/1.1 404 Not FoundHeaders
: 응답에 들어가는 HTTP headers는 요청 헤더와 동일한 구조
- Request headers
- General headers
- Representation headers(=Entitiy headers)
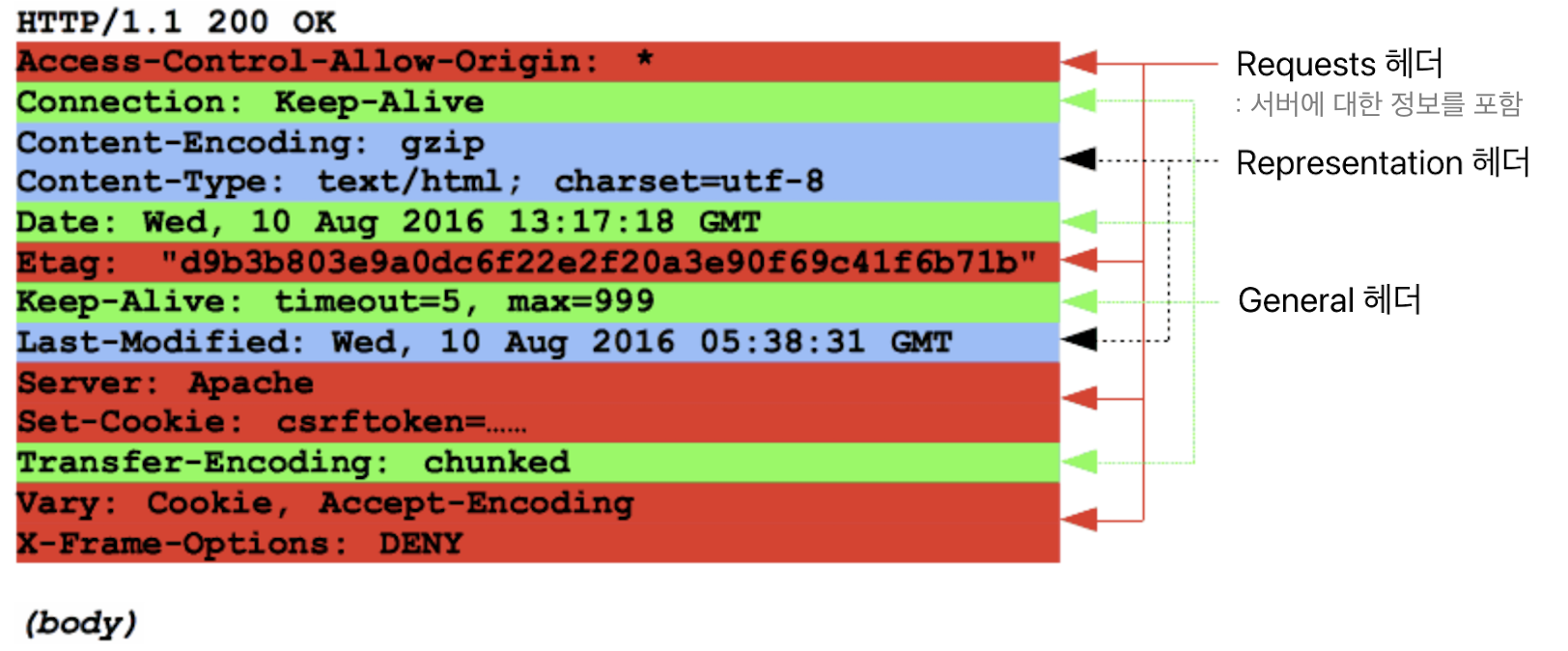
Body
- Single-resource bodies(단일-리소스 본문)
- Multiple-resource bodies(다중-리소스 본문)
AJAX
Asynchronous JavaScript And XMLHttpRequest
비동기적으로 서버에서 데이터를 받아오는 웹 개발 기법
-> JavaScript, DOM, Fetch, XMLHttpRequest, HTML 등의 다양한 기술을 사용
AJAX 핵심 기술
- fetch
-> 페이지 이동없이 비동기 방식으로 페이지 렌더링 가능 - Javascript & DOM
-> 필요한 데이터만 웹 페이지에 수정
AJAX의 장점
- 완성형태의 HTML 대신 필요한 부분만 전달 가능
-> 더 작은 데이터 크기로 대역폭에 제한 감소
cf. 대역폭 : 한번에 전송할 수 있는 데이터 크기 - 브라우저에 상관없이 사용
- 빠른 상호작용이 가능한 유저 중심의 애플리케이션 개발 가능
AJAX의 단점
- SEO(Search Engine Optimization)에 취약
: HTML파일에서 데이터를 수집하여 검색 결과로 보여주는 SEO에 불리한 방식 - 뒤로가기 버튼 문제
-> 별도의 History API 사용하여 해결
XHR
fetch 이전에 사용한 방식으로 XMLHttpRequest 객체를 사용하여 URL로 데이터를 받아와 렌더링
var xhr = new XMLHttpRequest();
xhr.open('get', 'http://52.78.213.9:3000/messages');
xhr.onreadystatechange = function(){
if(xhr.readyState !== 4) return;
// readyState 4: 완료
if(xhr.status === 200) {
// status 200: 성공
console.log(xhr.responseText); // 서버로부터 온 응답
} else {
console.log('에러: ' + xhr.status); // 요청 도중 에러 발생
}
}
xhr.send(); // 요청 전송
/*---- Fetch를 사용 ----*/
fetch('http://52.78.213.9:3000/messages')
.then (function(response) {
return response.json();
})
.then(function (json) {
...
});SSR vs CSR
Server Side Rendering vs Client Side Rendering
SSR
: 서버에서 렌더링이 끝난 상태로 클라이언트에 전달하는 방식
-> 경로가 변경되면 새로운 정적파일 요청
ex. 네이버 블로그, 뉴욕타임즈
- SEO(Search Engine Optimization)에 유리
- 첫 화면 로딩 속도가 빨라야 하는 경우 사용
- 사용자와 상호작용이 적을 경우 사용
CSR
: 서버에 요청한 데이터(Javascript파일 포함)를 받고 브라우저(클라이언트)에서 렌더링 하는 방식
-> 경로가 변경되더라도 서버가 웹 페이지를 다시 보내지 않고, 클라이언트에서 부분적으로 렌더링 진행
ex. 아고디(예약 사이트), SPA 기반 사이트
- 사용자와 상호작용이 많을 경우 사용
-> 빠른 라우팅, 동적 렌더링으로 강력한 User Experience 제공
참고
Chrome 브라우저 에러 읽기
| Error Message | Description |
|---|---|
| "Aw, Snap!" | Chrome 브라우저에서 페이지를 로드하는 데 문제가 발생했습니다. |
| ERR_NAME_NOT_RESOLVED | 호스트 이름(웹 주소)이 존재하지 않습니다. |
| ERR_INTERNET_DISCONNECTED | 사용 중인 기기가 인터넷에 연결되지 않았습니다. |
| ERR_CONNECTION_TIMED_OUT ERR_TIMED_OUT | 페이지에 연결하는 데 시간이 너무 오래 걸립니다. 인터넷 연결이 너무 느리거나, 웹페이지에 접속한 사용자가 많아서 발생할 수 있습니다. |
| ERR_CONNECTION_RESET | 웹페이지 연결을 방해하는 요소가 어딘가에 발생했습니다. |
| ERR_NETWORK_CHANGED | 웹페이지를 로드하는 중에 기기의 네트워크 연결이 해제되었거나, 새로운 네트워크에 연결되었습니다. |
| ERR_CONNECTION_REFUSED | 웹페이지에서 Chrome 브라우저의 연결을 허용하지 않았습니다. |
| ERR_CACHE_MISS | 웹페이지로부터 이전에 입력한 정보를 다시 한번 제출하도록 요청받았습니다. |
| ERR_EMPTY_RESPONSE | 웹페이지에서 데이터를 전혀 전송하지 않았으며, 데이터를 전송할 서버가 다운되었을 수 있습니다. |
| ERR_SSL_PROTOCOL_ERROR | 페이지에서 전송된 데이터를 Chrome 브라우저가 해석하지 못했습니다. |
| ERR_BAD_SSL_CLIENT_AUTH_CERT | 클라이언트 인증서(은행 또는 회사 내부 웹사이트 등)에 오류가 발생하여 웹페이지에 로그인할 수 없습니다. |
이해도 자가 점검 리스트
Chapter1. 웹 애플리케이션 아키텍쳐
- 클라이언트-서버 아키텍처를 이해할 수 있다.
- HTTP를 이용한 클라이언트-서버 통신을 이해할 수 있다.
- API의 개념을 이해할 수 있다.
Chapter2. 브라우저의 작동 원리 (보이지 않는 곳)
- 보이지 않는 곳의 통신을 이해할 수 있다.
- URL과 URI의 차이를 이해할 수 있다.
- IP 주소와 PORT에 대해 이해할 수 있다.
- DNS와 IP 주소의 관계를 설명할 수 있다.
- 크롬 브라우저의 에러 메시지를 통해 문제를 파악할 수 있다.
Chapter3. HTTP
- HTTP의 동작 방식을 이해할 수 있다.
- HTTP Messages의 구조를 설명할 수 있다.
- HTTP Requests와 Responses를 구분할 수 있다.
- HTTP의 응답 메시지를 찾아볼 수 있다.
Chapter4. 브라우저의 작동 원리 (보이는 곳)
- 보이는 곳의 통신을 이해할 수 있다.
- AJAX의 개념을 이해할 수 있다.
- SSR과 CSR의 차이를 이해할 수 있다.
자기주도적 학습 가이드
이해도 자가 점검 리스트의 결과를 토대로 자기주도적 학습 계획을 수립하고 실천해 보세요.
오늘 학습이 어려웠다면(0~12개)
- 개념학습 다시 보기
- 연습문제 다시 풀어보기
이해되지 않는 개념 아고라스테이츠에 질문하기
- 오늘 학습이 수월했다면(12~16개)
- 네트워크 기초에 대한 주요 개념 블로그에 정리하기
- 아고라스테이츠에 올라온 다른 수강생의 질문에 답변하기
추가적인 학습을 하고 싶다면(17~19개)
- SEO(Search Engine Optimization)에 대해 학습하기
- 아고라스테이츠에 올라온 다른 수강생의 질문에 답변하기
오늘의 나
느낀점
오늘 오랜만에 페어 없이 공부만 했는데 너무 힘들었다. 내용이 하나를 깊게 판다기보다 넓게 다루고 이걸 블로그에 써야되나 아니면 걍 가볍게 볼 내용인가 잘 구분이 안되서 더 오래걸렸다. 그리고 확실히 요새 체력도, 정신력도 많이 떨어진것 같다. 내일 하루만 하면 주말이니까 버티긴 하겠지만 이번주에 내용 정리 못한게 많아서 주말에도 새로운 것 알아가는 것 보다 복습 위주일 것 같다. 오늘은 너무 답답해서 점심에 10분정도 단지내부 돌아다니다 왔는데 이걸 쓰고있는 지금도 지치고 답답한 마음이 가득하다... 우선 내일은 나가서 밖에서 공부해야겠다. 배운내용에서 느낀 것보다 지쳤다는 말을 더 자주한다. 어떻게 하면 회복할 수 있을까. 온전히 쉬지도 못하는 상황이라 갑갑하다. 분명히 어려워도 코드는 재미있는데 지금 고비이다. 오래 앉는거는 자신 있었는데, 지금은 앉아있는게 힘들어졌다.
**
