
llama3 fine-tuning - "나만의 부동산 중개업 서포터"
🏠 ㄱㅎ이가 부동산 일을 시작한지 얼마 안됐는데,
부동산 매물들이 너무 많고 자신이 조사한 매물을 파일로 정리해도
추후에 고객이 원하는 조건을 가진 매물들로만 추리기가 번거롭고 어렵다고 했다.
이런거도 AI로 개인화해서 필요한 조건의 매물을 추천해주면 너무 좋을 것 같다고 해서
새로운 모델도 써볼 겸 주제를 "부동산 중개업 서포터" 로 잡았다.
부동산 중개업자가 자신이 가진 매물을 조건에 맞게 찾을 때 쓰는 개인화 모델이다.
모델을 학습 시키는 것보다는 데이터셋 구축하는 과정이 꽤 걸렸다..
ㄱㅎ이가 정리한 csv 파일을 받긴 받았는데 매물 정보만 적혀있는 파일이라 이대로 자연어 처리는 어려웠다.
그래서 다시 내가 질문-답변 쌍의 데이터셋을 구축해야 했다.
대화형 데이터셋 구축 과정은 따로 게시글로 작성 할 예정이다.
일단 테스트까지 마쳤지만, (테스트 결과만 보려면 11번 과정으로..)
좀 더 완성도 높게 트레이닝 시키고 UI도 만들어서 선물(?) 해야겠다.👩🏼💻
좋은 아이디어를 준 ㄱㅎ이에게 응원과 고마움을 전한다! 🙇🏻♀️
이번 작업은 파인튜닝 절차와 각 모듈의 역할들을 하나하나 정리하면서 공부했기 때문에 게시글이 꽤 길어졌다.
표기 : ✅ 개념 / 🔥 개인 정리 및 생각
1. 라이브러리 설치
라이브러리를 설치한다.
pip install -U accelerate==0.29.3 peft==0.10.0 bitsandbytes==0.43.1 transformers==4.40.1 trl==0.8.6 datasets==2.19.0-
accelerate : GPU와 분산된 환경에서 딥러닝 모델을 효율적으로 학습할 수 있게 해주는 툴.
메모리 최적화와 모델 가속화 기능을 제공. -
peft : 대규모 언어 모델 효율적으로 미세 조정.
적은 파라미터로 파인튜닝을 수행하도록 도와줌 큰 모델의 학습 비용을 줄여줌. (예: LoRa)
🔥 8번 Peft 파라미터 설정 과정에서 더 자세히 알아보기로 하자. -
bitsandbytes : 모델의 양자화 지원을 통해 메모리와 계산 성능을 최적화.
🔥 4번 과정에서 양자화에 대해 더 자세히 알아보기로 하자. -
transformers : 트랜스포머 구조를 기반으로 한 모델들 사용할 수 있게 해줌.
BERT, GPT 같은 다양한 언어 모델을 사용하고 파인튜닝할 수 있게 API 제공. -
trl : 트랜스포머 모델에 강화 학습 사용할 수 있게 하는 라이브러리.
🔥 사용자 정의 목표에 달성하도록 조정가능하고, 주로 대화형 AI 튜닝이나 모델 품질 향상에 사용한다. -
datasets : 공개 데이터셋을 쉽게 불러와서 사용할 수 있게 해주는 라이브러리.
2. 라이브러리 로드
요기선 자연어 처리 모델의 학습 환경을 설정하고 모델을 불러와서 파인튜닝할 준비를 하는 과정이다.
3번째 과정에서 base model 을 불러올텐데, 그 모델에 대한 추가작업을 위해서 미리 라이브러리들을 불러오는 과정임.
✅ transformers : 다양한 사전 학습된 NLP 모델과 도구를 제공하여 모델 불러오기, 파인튜닝, 추론 등 지원
✅ peft : 효율적인 파라미터 조정을 통해 대규모 모델을 더 적은 자원으로 파인튜닝 지원
✅ trl : 강화 학습을 통한 모델 파인튜닝 및 학습을 지원
import os
import torch
from datasets import load_dataset
from transformers import ( // 라이브러리에서 가져오고 싶은 도구 꺼내오기.
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
logging,
)
from peft import LoraConfig
from trl import SFTTrainer
import huggingface_hub
huggingface_hub.login('Hunggingface API 키 발급받아 넣기')-
transformers : Hugging Face 의 라이브러리. 사전 학습된 트랜스포머 모델을 로드 가능.
🔥 이 라이브러리에서 아래와 같이 필요한 도구들을 가져오기-
AutoModelForCausalLM : 사전 학습된 언어 모델 로드.
-
AutoTokenizer : 모델에 맞는 토크나이저 로드.
-
BitsAndBytesConfig : 모델의 *양자화 설정을 관리하는 도구. 메모리 사용량과 계산 효율성을 극대화.
✅ 양자화 : 16비트나 32비트 부동소수점 연산을 8비트 또는 4비트로 축소하여 처리하는 것.
모델의 크기가 작아지고, GPU 메모리 사용량을 줄이며 속도를 높일 수 있음.
🔥 아키텍처 공부할 때나 봤던 floating point가 이렇게 쓰인다.. -
TrainingArguments : 모델 학습 매개변수를 정의 (예: 배치 크기, 학습률)
-
pipeline : 모델 추론 위한 파이프라인 생성. NLP 파이프라인을 생성해 텍스트 생성 등 작업을 수행.
-
logging : 학습 중 발생하는 로그를 관리
-
-
peft : 대규모 언어 모델 효율적으로 미세 조정.
적은 파라미터로 파인튜닝을 수행하도록 도와줌 큰 모델의 학습 비용을 줄여줌. (예: LoRa)- LoraConfig : LoRA 파인튜닝 설정을 정의해 적은 파라미터로도 효과적인 학습이 가능.
-
trl : 트랜스포머 모델에 강화 학습 적용 가능. 강화학습 기반 모델 조정(RLHF)을 지원하며, 응답 품질 향상을 위해 활용.
- SFTTrainer : 강화학습 기반으로 미세 조정(SFT)(=수퍼바이즈드 파인튜닝)을 수행하는 트레이너 라이브러리.
3. Model/dataset 설정
llama3 기본 모델은 영어에 특화되어 있음. (당연함...)
그래서 한국어로 파인튜닝 할 필요가 있는데, 이미 많은 사람들이 한국어 파인튜닝 모델을 만들어 공유하고 있다.
(god bless you guys...🙏🏻)
Huggingface 에 좋은 모델들이 많이 있으니 찾아서 넣어주면 됨.
# Hugging Face Basic Model 한국어 모델
base_model = "beomi/Llama-3-Open-Ko-8B" //다른 걸로 선택해도 된다.
# Custom Dataset -> 본인이 hugging face 내 저장한 모델경로를 설정해야함
custom_dataset = "huggingfaceID/저장된 모델경로"
new_model = "저장할 새로운 모델명"
나는 초기 csv에 따른 질문-답변 쌍을 코드로 몇개 만들어서 저장 후 그걸 데이터셋으로 썼다.
(데이터셋 구축 단계도 따로 게시글로 적어볼 예정)
4. GPU 환경 확인 및 attention 메커니즘 설정
GPU 환경에 따라서 적절한 메커니즘 설정 해주기
if torch.cuda.get_device_capability()[0] >= 8:
!pip install -qqq flash-attn
attn_implementation = "flash_attention_2"
torch_dtype = torch.bfloat16
else:
attn_implementation = "eager"
torch_dtype = torch.float16
-
torch.cuda.get_device_capability() : GPU의 CUDA 연산 기능을 확인
- torch.cuda.get_device_capability()[0] >= 8:
이렇게 조건문을 통해 현재 사용중인 GPU의 CUDA 연산 능력을 확인. 8이상이면 고성능 GPU 로 판단함.
- torch.cuda.get_device_capability()[0] >= 8:
-
flash-attn : GPU 메모리와 계산 속도를 개선하는 어텐션 방식
-
attn_implementation : 어텐션 방식 설정을 위해 사용되는 변수. 뭐 쓸지 고를 수 있는거임.
-
flash_attention_2 : flash-attn을 사용하여 빠른 연산을 지원
-
eager : 일반적인 기본 연산 방식
-
🔥 즉, GPU가 8 이상이면 빠른 flash_attention_2를 쓰기에 적당, 8 미만이면 안전하게 eager 로 돌려야 적당히 잘 돌아가기 때문에 적절한 매커니즘 설정을 해주는 것!
5. 4비트 양자화, 그런데 QLoRA 를 곁들인 ...
4비트 양자화 설정을 통해 대규모 모델의 메모리와 계산 효율성을 극대화하는 과정
✅ QLoRA (Quantized Low-Rank Adaptation) 란 ?
QLoRA = 양자화 + 저차수 조정
대규모 언어 모델을 4비트로 양자화하여 메모리와 계산 성능을 크게 줄이면서도 고품질 학습이 가능하게 하는 방법
- 양자화(Quantization): 모델의 파라미터를 4비트로 줄여 메모리를 절약 (위에서 말한 그 부동소수점 어쩌고)
- 저차수 조정(Low-Rank Adaptation): 필요한 소수의 파라미터만 효율적으로 조정해 적은 데이터로도 성능 향상
- 결론 : QLoRA 는 적은 자원으로 대형 모델의 파인튜닝을 가능하게 한다.
🔥 원래 LLM 은 일반적으로 32비트 형식으로 훈련되고, 일부 최적화된 경우 16비트 형식으로 훈련되어 있다. 양자화를 하게 되면 이거보다 훨씬 줄여서 메모리 효율성을 극대화 하고, 저차수 조정으로 성능 손실을 최소화 할 수 있는거지.
# QLoRA config
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch_dtype,
bnb_4bit_use_double_quant=False,
)-
BitsAndBytesConfig() : Hugging Face의 bitsandbytes 라이브러리를 통해, 모델의 메모리 사용량을 줄이고 계산 효율성을 높이는 방법을 제공. 아래는 옵션들 설명.
-
load_in_4bit=True : 모델 가중치를 4비트로 로드해서 메모리 사용 절감.
-
bnb_4bit_quant_type="nf4" : 양자화 유형은 NF4(Nearest Neighbor 4-bit) 타입을 사용해 정밀도와 효율성을 균형 있게 유지
✅ 다시한번 양자화 : 모델의 파라미터를 더 작은 비트 수로 표현해 메모리와 계산 효율성을 높이는 기술.
이 과정에서 파라미터 값을 더 작은 비트 단위로 압축하지만, 성능 저하를 최소화하는 방식으로 진행.
✅ 양자화 유형 : 정적 양자화, 동적 양자화, QAT ...
(여러가지가 많은데 .. 추후 따로 양자화에 대해 정리해야겠다.)
✅ 일단 여기서는 NF4 사용 : 고정밀도 유지와 메모리 효율성을 동시에 달성하기 위해.
4비트로 압축하면서도 파라미터 값을 근사화하여, 저비트 양자화에서도 상대적으로 성능 저하가 적은 것이 특징
특히, 대규모 언어 모델에서 자원을 절약하면서도 높은 성능을 유지할 수 있어 QLoRA와 같은 방식에 적합하다고 한다. -
bnb_4bit_compute_dtype=torch_dtype: GPU에 맞춰 설정된 데이터 타입(torch.bfloat16)을 사용하여 메모리 효율을 개선. *직전에 정의했던 타입으로 지정해주면 된다.
-
bnb_4bit_use_double_quant=False: 이중 양자화를 비활성화해서 메모리 사용을 줄이는 것.
✅ 이중 양자화 : 양자화 과정을 두 번 적용하여 정확도를 더 높일 수 있지만, 메모리를 더 많이 소모.
이중 양자화를 비활성화하면 성능 손실이 거의 없이 메모리 사용을 줄일 수 있어서 큰 모델에서도 효율적으로 학습과 추론을 수행가능.
🔥 이중 양자화 하면 좋긴한데, 기본 양자화만으로도 충분한 성능이 확보되면 굳이~ 메모리 쓰면서 할 필요는 없다. 근데 기본적으로 이중 양자화는 비활성화 되어있고, True 로 설정하지 않는 이상 자동 적용되진 않는당! 그래도 명시적으로 써두도록 하자.
-
6. 데이터 로드 및 모델 설정
사용할 데이터와 모델을 입맛에 맞게 세팅해서 불러오기
# 모델 불러오는 부분
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=quant_config,
device_map={"": 0}
# device_map="auto"
)
# 모델 설정하는 부분
model.config.use_cache = False
model.config.pretraining_tp = 1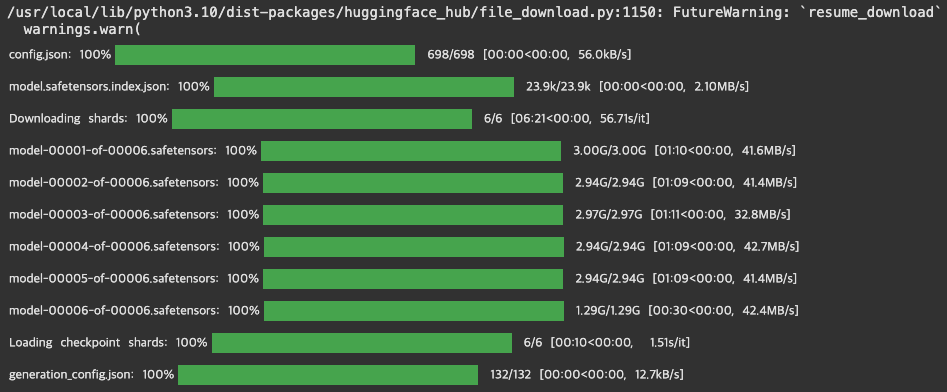
[모델 불러오는 부분]
-
AutoModelForCausalLM.from_pretrained() : 사전학습 된 모델 불러옴
-
base_model : 아까 기재해뒀던 base_model 경로에 있는 모델을 불러옴 (“beomi/Llama-3-Open-Ko-8B”)
-
quantization_config=quant_config : 아까 정의한 양자화 설정 불러옴 (4비트 양자화 설정을 적용)
-
device_map={"": 0} : 모델을 특정 GPU(여기서는 첫 번째 GPU)에 할당
만약에 device_map="auto"로 설정하면 사용 가능한 장치에 자동으로 할당됨!
-
[모델 설정하는 부분]
-
model.config.use_cache = False : 추론 시 캐시 기능을 비활성화해 메모리 사용량을 줄임.
-
model.config.pretraining_tp = 1 : 모델의 병렬화 파라미터임.
텐서 병렬화(training parallelism)를 1로 설정하여 모델의 메모리 사용을 최적화
설정값 1은 단일 GPU에서 실행되도록 설정 해주는 의미
✅ 텐서 병렬화 : 대규모 모델의 파라미터를 여러 GPU에 나누어 분산 처리하는 방법.
모델의 계산 부하를 여러 장치에 분산시켜 메모리 사용량을 줄이고 계산 속도를 높일 수 있다.
✅ 텐서 파라미터 : 이 분할이 이루어지는 방식을 조절하는 설정
pretraining_tp = 1은 파라미터를 특정 방식으로 나누어 한 번에 처리하도록 설정
병렬화의 정도에 따라 연산의 효율성과 메모리 사용량이 달라진다.
모델 학습과 추론 시 더 큰 모델을 더 작은 GPU 메모리에서도 다룰 수 있게 한다.
🔥 그럼 pretraining_tp 값은 1 외에도 다른 값으로 설정할 수 있을까?
이 값은 텐서 병렬화의 분할 수를 결정하니까, 아래와 같은 경우로 설정할 수 있다고 한다.
1️⃣: 병렬화를 사용하지 않고, 전체 모델을 하나의 장치에서 처리
2️⃣ , 3️⃣ ... : 모델의 각 파라미터를 지정된 수만큼 분할하여 여러 GPU에 분산 처리
예시) pretraining_tp = 2이면 모델이 두 개의 파트로 나뉘어 각기 다른 GPU에서 처리
✅ 결론 : 높은 pretraining_tp 값을 설정하면 더 많은 GPU에 연산이 분산되므로,
모델 학습 속도가 빨라지고 메모리 효율성이 개선 (하지만 GPU 많이 필요함 ^^;;)
7. 토크나이저 불러오기
모델을 다 불러왔으면 , 이제 토크나이저 초기화 및 설정을 수행해야 한다.
AutoTokenizer를 통해 사전 학습된 모델에 맞는 토크나이저를 불러오고, 추가 설정을 통해 데이터 입력 형식을 조정한다.
✅ 토크나이저 : 텍스트를 모델이 이해할 수 있는 토큰 단위로 변환하는 과정
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
-
AutoTokenizer.from_pretrained() :
Hugging Face에서 제공하는 기능으로, 특정 사전 학습 모델에 적합한 토크나이저를 자동으로 불러오는 역할 -
AutoTokenizer.from_pretrained(base_model, trust_remote_code=True) :
- base_model에 맞는 토크나이저를 불러온다.
✅ Hugging Face에서 base_model 경로에 저장된 모델에 적합한 토크나이저를 자동으로 불러온다.
예를 들어, 특정 사전 학습 모델이 있으면 그 모델에 맞는 맞춤형 토크나이저도 함께 불러올 수 있다.
🔥 이 과정은 모델 이름(경로)만 지정하면 Hugging Face가 해당 모델에 적합한 토크나이저를 자동으로 찾아 불러오는 방식! - trust_remote_code=True는 외부 코드 사용을 허용하여 사용자 정의 토크나이저를 지원한다.
✅ 외부 코드 사용 허용은 Hugging Face 허브에서 사용자 정의 코드를 포함하는 모델이나 토크나이저를 불러올 때 필요하다. 기본적으로는 보안상의 이유로 사용자 정의 코드 실행이 차단될 수 있다.
이 옵션을 True로 설정하면 해당 모델이 제공하는 커스텀 코드를 신뢰한다는 뜻이고, 코드를 실행할 수 있다.
🔥 이 기능은 사용자 정의된 토크나이저나 특수 기능을 가진 모델을 불러올 때 유용하고, 일반적인 토크나이저가 아닌 특별히 설계된 구조나 추가 기능을 지원할 수도 있다고 한다!
8. Peft 파라미터 설정
사전 모델을 최적화 시키는 과정이라고 말하면 쉬울 듯
✅ 파라미터 조정 이유 ?
파라미터 조정은 파인튜닝 과정의 일부임.
기본적으로 사전 학습된 모델을 특정 작업이나 도메인에 맞게 최적화 하기 위해 하는 작업.
🔥 대규모 언어 모델은 일반적 언어 이해와 생성 능력을 갖추고 있지만, 특정 작업에 필요한 세부 사항이나 맥락을 모두 포함하지 않기 때문에 입맛대로 맞춰주는 것.
✅ 다시한번 Peft 란 ?
(=Parameter-Efficient-Fine-Tuning)
파라미터 효율적 파인튜닝 기술. 파라미터 조정 기법 중 하나다.
일반적으로 파인튜닝을 할 때 모델의 모든 파라미터를 업데이트 하는데,
Peft를 쓰면 모델의 일부 파라미터만 조정해서 효율적으로 학습하게 한다.
메모리 사용량과 계산 복잡도를 줄이고, 더 적은 리소스로도 모델을 미세조정 할 수 있다.
✅ LoRA 란 ?
(=Low-Rank Adaptation)
Peft 종류 중 하나인데, 현재 가장 많이 사용되고 장점이 큰 기법이라고 한다.
대규모 모델의 특정 부분에 저차원 행렬을 삽입해 학습함으로써, 메모리 효율성과 학습 속도를 크게 향상시킨다.
🔥 즉, 대규모 모델을 미세 조정할 때 모델 전체 가중치를 변경하는게 아니고, 작은 크기의 행렬을 추가해서 학습하면, 학습해야할 파라미터 수를 줄여서 학습 속도를 높이고 메모리 사용량을 줄일 수 있다.
peft_params = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)-
LoraConfig : LoRA 설정을 정의하는 클래스.
-
lora_alpha : LoRA의 스케일링 계수 조정.
업데이트의 강도를 조절함에 따라 학습 성능도 달라진다.
🔥 값이 크면 학습 속도 빨라지지만, 너무 크면 또 불안정해질 수 있다. -
lora_dropout : 드롭아웃 비율 조정. 과적합을 방지한다.
10%(0.1)의 드롭아웃 확률을 사용해서 모델의 일반화 성능을 향상시킨다.
✅ 과적합 (overfitting) : 모델이 훈련 데이터에 지나치게 적응해서 훈련 데이터에서는 높은 정확도를 보이지만, 새로운 데이터(테스트 데이터) 에서는 성능이 저하되는 현상.
✅ 드롭아웃 (Dropout) : 인공신경망에서 과적합을 방지하기 위해 사용되는 정규화 기법.
훈련 시 훈련 단계마다 일부 뉴런(노드)를 랜덤하게 비활성화시킨다.
(🔥 과적합과 드롭아웃은 따로 정리해서 게시글에 올려두었다.) -
r=64 : 추가될 저차원 행렬의 차원 수. 더 작은 차원을 사용해서 메모리 사용량 줄이고, 학습 속도 높여서 학습 효율 조절.
-
bias="none" : 모델에 바이어스를 사용하지 않도록 설정.
✅ bias : 각 뉴런의 활성화를 조정하는 역할
🔥 여기서는 그 기능을 제거해서 모델을 단순화하고 메모리 사용 줄임. -
task_type="CAUSAL_LM" : 인과적 모델 작업에 사용할 설정.
✅ 인과적 언어 모델 : 주어진 입력의 이전 단어들을 기반으로 다음 단어를 예측하는 방식
9. 모델 학습 설정 정의
학습 시 매개변수 지정해서 모델이 어떻게 훈련될지 결정한다.
이 과정은 학습의 효율성과 성능을 최적화하기 위해 중요하다.
training_params = TrainingArguments(
output_dir="./results",
num_train_epochs=10,
per_device_train_batch_size=4,
gradient_accumulation_steps=1,
optim="paged_adamw_32bit",
save_steps=25,
logging_steps=25,
learning_rate=2e-4,
weight_decay=0.001,
fp16=False,
bf16=False,
max_grad_norm=0.3,
max_steps=-1,
warmup_ratio=0.03,
group_by_length=True,
lr_scheduler_type="constant",
report_to="tensorboard"
)-
output_dir : 학습 결과와 체크포인트를 저장할 디렉토리
-
num_train_epochs : 전체 학습 반복 횟수 (=에포크 수) (기본값=3)
-
per_device_train_batch_size : 각 장치마다 사용할 배치 크기.
4로 설정했으니 각 장치에서 한 번에 4개의 샘플 처리한다. (기본값=8) -
gradient_accumulation_steps : 여러 미니배치의 그레디언트 누적해서 업데이트를 한 번에 수행한다. GPU 메모리가 부족할 때 유용. (기본값=1)
-
optim : 사용할 옵티마이저 지정
✅ 옵티마이저 : 모델 학습 과정에서 손실함수를 최소화하기 위해 가중치와 바이어스 등 모델의 파라미터 업데이트하는 알고리즘. -
save_steps : 학습 중 체크포인트 저장할 단계 수.
25로 설정했으니 25스텝마다 모델을 기록하고 저장함. (기본값=500) -
logging_steps : 학습 중 로그를 출력할 단계 수.
25로 설정했으니 25스텝마다 로그 기록함. (기본값=500) -
learning_rate : 학습률.
✅ 학습률 :모델이 가중치를 업데이트 하는 속도를 결정함. -
weight_decay : 가중치 감소 계수 값 (=정규화 값). 과적합 방지하는 방법임.
-
fp16 / bf16 : 16비트 부동소수점 연산 여부. false 로 설정하면 32비트 연산 수행.
-
max_grad_norm : 그래디언트의 최대 크기를 제한해서 그래디언트 폭발 방지 및 학습의 안정성 보장.
✅ 그래디언트 : 신경망 학습 중 손실 함수의 변화율.
손실 함수의 기울기를 계산해서 가중치 업데이트 방향을 알려준다.
✅ 그래디언트 폭발 : 그래디언트의 값이 매우 커져서 불안정해지거나 수렴하지 않는 문제.
✅ 그래디언트 클리핑 : 이런 문제를 방지하기 위해 그래디언트의 최대 크기를 제한하는 방법. -
max_steps : 최대 학습 단계 수.
-1로 설정하면 num_train_epochs 기준으로 학습한다.
1000으로 설정하면 모델은 1000단계 학습 후 종료된다. -
warmup_ratio : 학습 초기 단계에서 학습률을 점진적으로 높이는 비율. 초기 단계에서 학습률을 쪼금씩 증가시켜서 모델이 안정적으로 학습 시작할 수 있게 함.
-
group_by_retio : 입력 시퀀스의 길이에 따라 배치를 그룹화해서 학습 효율을 높인다. 길이가 비슷한 샘플을 같이 배치하면 패딩의 양을 줄이니까 메모리 사용을 최적화 할 수 있다.
-
lr_scheduler_type : 학습률 스케줄러 유형을 설정.
constant 로 설정하면 일정하게 유지.
✅ 학습률 스케줄링
각 유형은 특정한 학습 상황에서 성능에 영향을 주기 때문에
모델의 성능 테스트나 경험적 설정을 통해 적합한 스케줄러를 선택하는 것이 중요하다.
✅ 학습률 스케줄링 선택 기준- 복잡도/안정성 : 큰 모델이나 복잡한 문제에서는 linear 나 cosine 스케줄러가 더 부드러운 학습률 감소를 제공해서 안정적인 학습을 유도함.
linear 설정 ) 학습률 점전적으로 줄여서 최종적으로는 0에 도달.
cosine 설정 ) 학습률을 코사인 곡선을 따라 감소시킴. - 학습 초기 단계 : constant_with_warmup 은 학습 초기 단계에서 급격한 학습률 증가로 빠른 수렴을 도와줄 수 있다.
- 일반적인 훈련 : constant 는 간단한 문제나 작은 모델에서 일정한 학습률로 고정해서 일관된 학습을 제공한다.
- 복잡도/안정성 : 큰 모델이나 복잡한 문제에서는 linear 나 cosine 스케줄러가 더 부드러운 학습률 감소를 제공해서 안정적인 학습을 유도함.
-
report_to : 학습 기록을 보낼 툴. 여기선 tensorboard 에 보고함.
10. 모델 학습
trl 라이브러리의 SRTTrainer 클래스를 사용해서 모델 학습을 진행하는 과정.
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_params,
dataset_text_field="text",
max_seq_length=None,
tokenizer=tokenizer,
args=training_params,
packing=False,
)
- model=model : 학습할 모델 객체 지정
- train_dataset=dataset : 학습에 사용할 데이터셋 설정
- peft_config:peft_params : PEFT(LoRA) 설정을 통해 효율적인 파라미터 조정 적용
- dataset_text_field : 데이터셋에서 학습할 텍스트 필드명을 지정
- max_seq_length : 시퀀스의 최대 길이 설정. None=기본값 사용
- tokenizer=tokenizer : 입력을 처리할 토크나이저 지정.
- args=training_params : 학습 매개변수(학습률, 배치 크기 등) 설정
- packing=False : 데이터 패킹을 비활성화해서 각 데이터 샘플을 독립적으로 처리
trainer.train()모델 학습 과정. 이 과정이 가장 시간이 많이 걸린다.
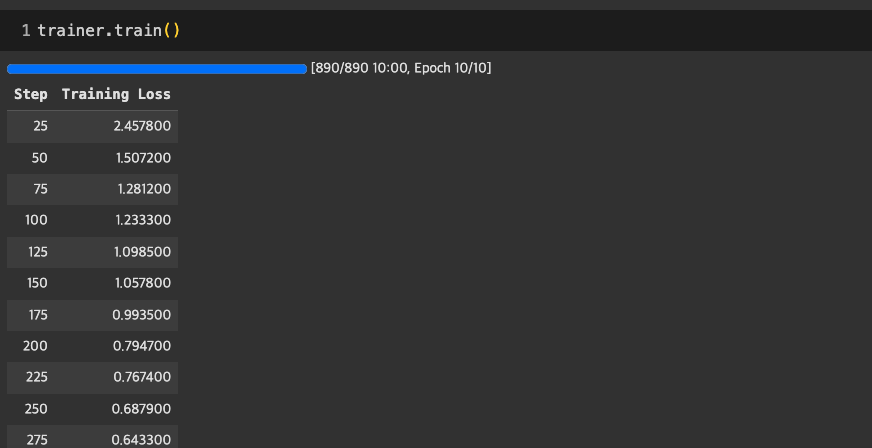
11. 대망의 테스트 해보기
나름 성공적인 첫 테스트 !

테스트 결과는 잘 나온다!! 🙆🏻♀️
🏠 실입금 3000만원 이하의 매물을 추천해달라고 하니, 개인 매물 리스트에서 잘 추천해주고 있고,
주변 인프라까지 알려준다. 우하하 ! 테스트 첫트인데, 나름 성공적이다 ~
하지만 좋지 않은 결과를 낼 때도 있다. 이건 질문-답변 쌍 데이터를 좀 더 쌓아야 되는 것으로 파악된다.
12. 모델 저장
절대 이대로 런타임 연결을 끄지 말고, 모델을 로컬 디렉토리에 저장한다 !
model.save_pretrained("./trained_model")
tokenizer.save_pretrained("./trained_model")

13. Huggingface에 모델 업로드
저번 모델처럼 Huggingface 에 업로드 해주었다.
model_name = "새 모델 이름 지정"
model.push_to_hub(model_name)
tokenizer.push_to_hub(model_name)
나만 쓰고 싶은 모델은 꼭 private 으로 올린다.(업로드 후 설정 가능)
학습에 사용된 데이터셋에 주소나 연락처 등의 정보들이 포함되어 있기 때문에 private 으로 올렸다.
이렇게 해서 업로드 까지 완성!
이제 더 데이터를 쌓고 계속 트레이닝 시켜볼 일만 남았다.
그리고 추후 범용성을 위해 개인화 csv 를 데이터셋으로 않아도 프롬프트 입력을 통해 학습시킬 방법을 공부해볼 것.
아자잣 💪🏻 🍀
