Tsai et al., ACL, 2019
modality: 데이터 양식
다양한 모달리티를 어떻게 fusion(융합)할 것인가
가장 쉬운 방법: 각 모달리티를 단순히 concat해서 입력
각 모달리티의 시퀀스 길이가 서로 다르기 때문에 문제 발생
1. missing modality: 비디오나 음성처럼 더 긴 데이터가 남게 됨
2. 길이를 강제로 맞추게 되면 모달리티 간의 temporal missmatch 발생
각 모달리티의 시퀀스 길이를 동일하게 하는 작업: alignment
alignment+lstm인 경우 local multimodality는 반영할 수 있어도
global 또는 long-term multimodality는 반영하기 어려움
또한, alignment를 하는 것에 많은 cost 소요
Human language는 multimodal이다.
-> natural language, facial gesture, acoustic behaviors (tone of voice)
+) rich information provides us the benefit of understanding human behaviors and intents
-) increase the difficulty of analyzing human language
multimodal language sequences often exhibit “unaligned” nature and require inferring long term dependencies across modalities, which raises a question on performing efficient multimodal fusion.
human language time-series data 멀티 모달 모델링 두 가지 main challenge
1) inherent data non-alignment due to variable sampling rates for the sequences from each modality
2) long-range dependencies between elements across modalities
In this paper,
Multimodal Transformer (MulT)
: to generically address the above issues in an end-to-end manner without explicitly aligning the data
모델의 핵심은 directional pairwise crossmodal attention
1) distinct time step에 걸쳐 mutimodal sequence 간의 interaction에 attend
2) 한 모달리티의 스트림을 다른 모달리티로 잠재적으로 조정
정렬된 다중 모달 시계열과 비 정렬된 다중 모달 시계열에 대한 포괄적인 실험은 우리 모델이 최첨단 방법을 크게 능가한다는 것을 보여준다.
또한, 경험적 분석은 상관된 교차 모달 신호가 MulT에서 제안된 교차 모달 주의 메커니즘에 의해 포착될 수 있음을 시사한다.
1.Introduction
Multimodal Transformer (MulT)
an end-to-end model
extends the standard Transformer network
to learn representations directly from unaligned multimodal streams
핵심 모듈
crossmodal attention module
which attends to the crossmodal interactions at the scale of the entire utterance.
latently adapts streams
from one modality to another (e.g., vision → language)
by repeated reinforcing one modality’s features with those from the other modalities, regardless of the need for alignment.
기존 방식은
tackling unaligned multimodal sequence is by forced word-aligning before training.
manually preprocess the visual and acoustic features by aligning them to
the resolution of words.
이 방식은 do not directly consider long-range crossmodal contingencies of
the original features 라는 단점이 있다.
requires feature engineering that involves domain knowledge
: entails extra meta-information about the datasets -> 현실적으로 불가능!
(e.g., the exact time ranges of words or speech utterances)
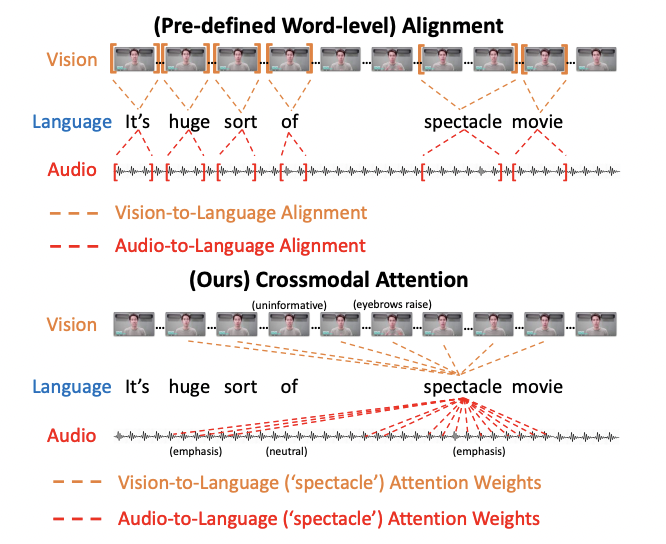
모델 평가 human multimodal language benchmarks
CMU-MOSI, CMU-MOSEI, IEMOCAP
SOTA 달성
not only the commonly evaluated word-aligned setting
but also the more challenging unaligned scenario
2. Related Works
Human Multimodal Language Analysis
Transformer Network
NMT transformer
focuses on unidirectional translation from source to target texts,
human multimodal language time-series are neither as well-represented nor discrete as word embeddings, with sequences of each modality having vastly different frequencies.
we propose not to explicitly translate from one modality to the others (which could be extremely challenging), but to latently adapt elements across modalities via the attention.
MulT has no encoder-decoder stucture
built up from multiple stacks of pairwise and bidirectional crossmodal attention blocks
-> directly attend to low-level features (while removing the self-attention)
3.Proposed Method
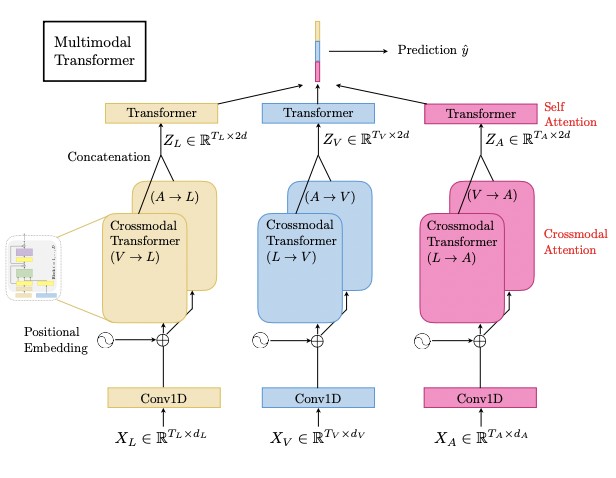
At the high level,
MulT merges multimodal timeseries via a feed-forward fusion process from multiple directional pairwise crossmodal transformers
each crossmodal transformer serves to repeatedly reinforce a target modality with the low-level features from another source modality by learning the attention across the two modalities’ features
((서로 교차해서 학습하고 Crossmodal attention으로 또 학습))
A MulT architecture hence models all pairs of modalities with such crossmodal transformers, followed by sequence models (e.g., self-attention transformer) that predicts using the fused features.
3.1 Crossmodal Attention
two modailies
two sequence (potentially non-aligned)
:sequence length, : feature dimension
하나의 언어에서 다른 언어로 translate하는 NMT의 decoder transformer에서 영감을 받아서
fuse crossmodal information을 latent adaptation across modalities에서 제공받는 방법을 가정했다.
facial attribute와 spoken word처럼 아주 다른 도메인을 고려할 수 있다.
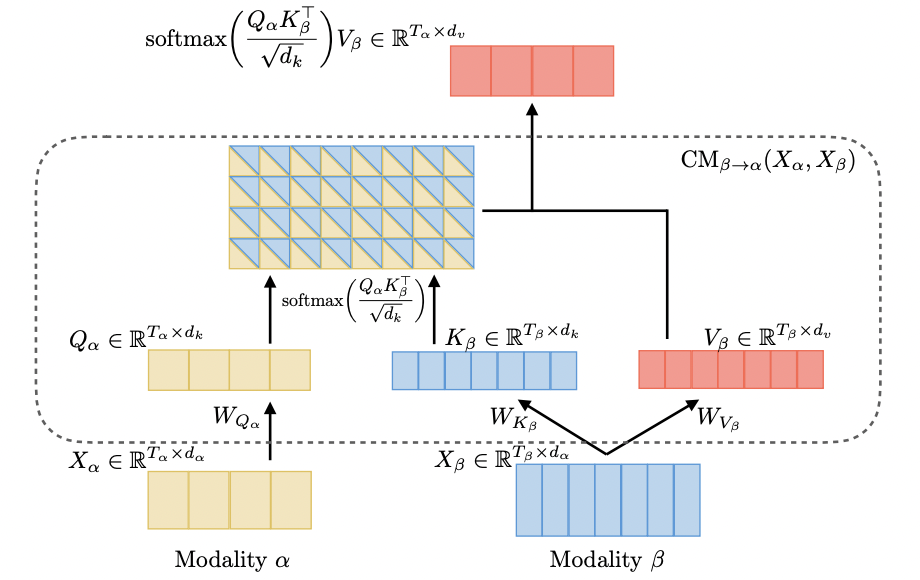
-> scaled dot product attention score matrix가 4x7이 되어야 하지 않을까요?
식 1: Single head crossmodal attention
Query, Key, Value, Weight를 정의했다.
latent adaptation from to 는 crossmodal attention으로 표기된다.
(식 1)
는 와 같은 길이 (즉, )
-> Crossmodal Attention의 output의 길이가 쿼리의 길이와 같은데 쿼리(타켓)에 value(source)의 정보를 입혀줬다고 생각하면 됌
add a residual connection to the crossmodal attention computation
another positionwise feed-forward sublayer is injected to complete a crossmodal attention block
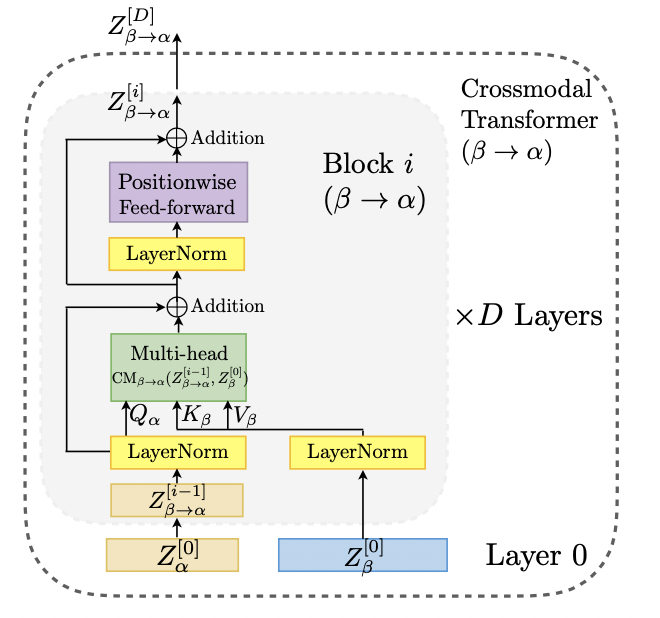
를 반영하면서 를 계속해서 업데이트
Each crossmodal attention block adapts directly from the low-level feature sequence
does not rely on self-attention,
which makes it different from the NMT encoderdecoder architecture
(i.e., taking intermediate-level features)
We argue that performing adaptation from low-level feature benefits our model to preserve the low-level information for each modality.
3.2 Overall Architecture
L: language
V: video
A: audio
input feature sequences from 3 modalities:
Temporal Convolutions
: sizes of the convolutional kernels for modalities
: common dimension
1D convolution의 효과
1) convolved sequences에 sequence의 local structure가 있을 것으로 기대
2) temporal convolutions project the features of different modalities to the same dimension
즉, 다른 시퀀스의 길이를 같은 차원으로 만들어 주기 위해 1D conv를 함
crossmodal attention module에서 dot product 연산이 쉬워짐
Positional Embedding
temporal information을 반영하기 위해 positional embedding(PE)
compute the fixed embeddings for each position index
는 low-level position aware features for different modalities
Crossmodal Transformers
하나의 모달리티에서 다른 모달리티로 정보를 보낼 수 있도록 모델을 설계했다.
fix all the dimensions
compute feed forwardly layers
를 query, 를 key, value로 하여 연산
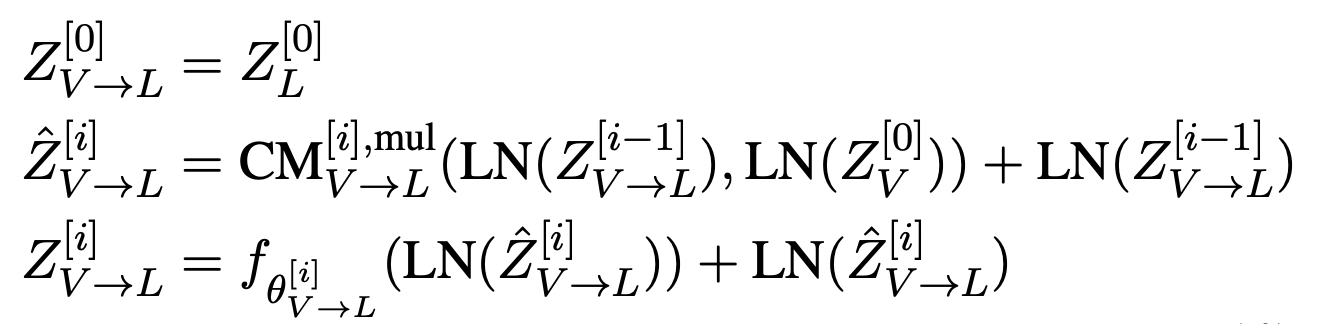
= language (L), = vision (V) 일 때 식
: positionwise feed-forward sublayer parametrized by
LN: layer normalization
이 과정에서 각 modality가 multi-head crossmodal attention module의 low-level external information을 통해 sequence를 계속 업데이트합니다.
low-level signal은 Key/Value 세트로 변환됩니다.
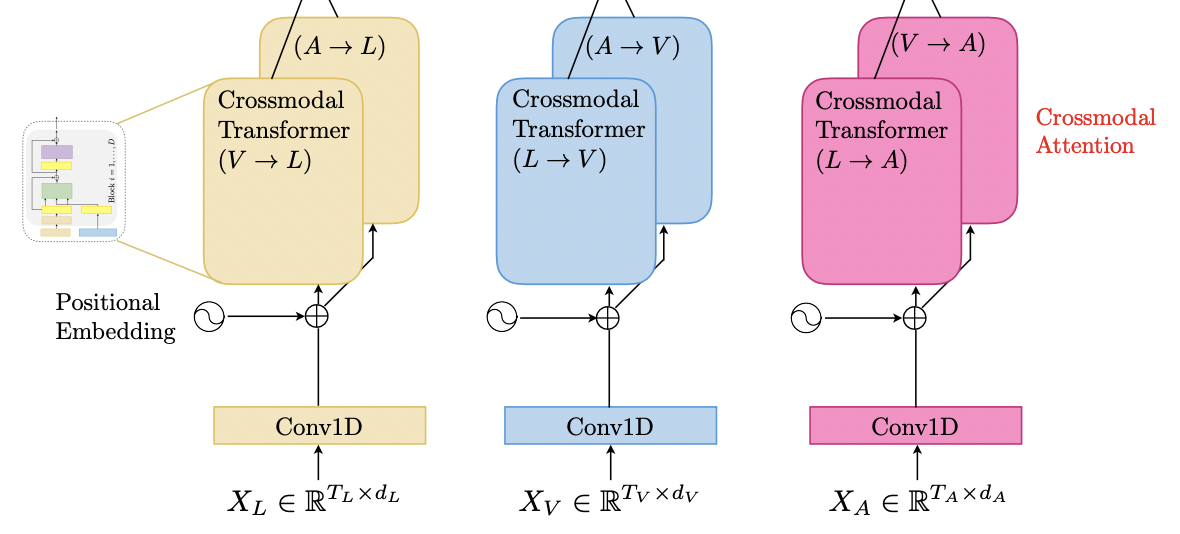
MulT는 모든 crossmodal interaction 쌍을 고려하기 때문에 3개의 모달리티의 경우
위 그림처럼 6 crossmodal trasformer이다.
**
original transformer에서의 encoder-decoder attention과 비슷한 역할을 함
-> encoder output과 decoder input의 연관성을 반영한 learned representation
crossmodal transformer
-> source modality와 target modality의 연관성을 반영한 fused representation 산출
Self-Attention Transformers and Prediction
crossmodal trasformer의 output을 각각 concat하여 self-attention transformer에 투입
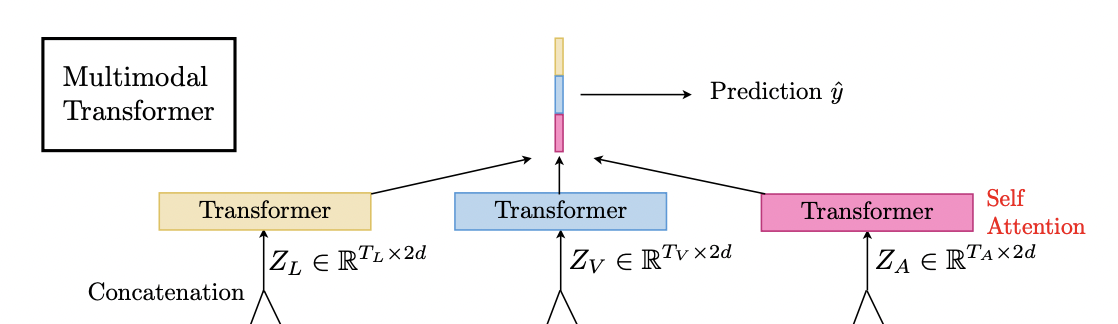
각각은 sequences model을 통과해서 temporal information을 만들고 sequences model의 마지막 elements를 fully-connnected layer에 통과시켜 prediction을 생성한다.
본 논문에서는 self-attention transformer를 sequence model로 사용하였다.
3.3 Discussion about Attention & Alignment
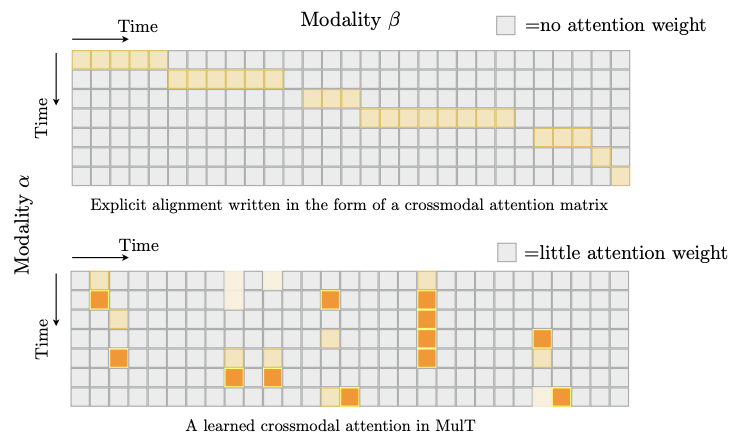
기존 연구에서는 학습 전에 multimodal sequences를 수동으로 같은 길이로 aligned한다.
MulT는 완전히 다른 관점에서 nonalignment issue에 접근한다.
즉, crossmodal attention을 사용함으로서 long-range crossmodal contingencies를 포착할 수 있다.
반면에 고전적인 교차 모달 정렬은 특별한 (단계 대각선) 교차 모달 주의 행렬(즉, 단조 주의)로 표현될 수 있다 -> 뭔 소리지?
그림 해석으로 이해한 것은 수동으로 정렬하는 것은 대각 요소들 말고는 나머지에 아예 attention이 들어가지 않는데, Mult에서는 다른 타임라인에서도 attention이 적용됨
4.Experiments
4.1 Datasets and Evaluation Metrics
& 4.3 Quantitative Analysis
Multimodal features extracted
textual (GloVe word embeddings (Pennington et al., 2014))
visual (Facet (iMotions, 2017))
-> Facet: Sentiment analysis를 위한 vision feature를 추출하는데 사용되는 라이브러리
각 action unit에 대한 score를 산출하여 vectorize 수행
face detection (SVM model) -> key point extraction -> action unit recognition
acoustic (COVAREP (Degottex et al., 2014))
-> COVAREP 라이브러리, MFCC를 산출하여 vextorize
http://multicomp.cs.cmu.edu/resources/cmu-mosi-dataset/
https://paperswithcode.com/sota/multimodal-sentiment-analysis-on-cmu-mosi
http://multicomp.cs.cmu.edu/resources/cmu-mosei-dataset/
https://paperswithcode.com/sota/multimodal-sentiment-analysis-on-cmu-mosei-1
CMU-MOSI와 CMU-MOSIE는 짧은 독백 비디오 클립으로 구성된 human multimodal sentiment analysis dataset
각 비디오 clip은 sentence동안 지속됨
CMU-MOSI는 textual data는 단어 당 segmented 되고 discrete 단어 임베딩으로 표현
CMU-MOSIE는 YouTube에서 가져온 23,454개의 영화 리뷰 비디오 clip으로 구성된 데이터 세트
CMU-MOSI의 약 10배 크기
human annotators with a sentiment score from -3 (strongly negative) to 3
(strongly positive)
10K videos for human emotion analysis
happy, sad, angry, neutral
multilabel task (슬픔과 분노를 동시에 느낄 수 있음)
https://paperswithcode.com/dataset/iemocap
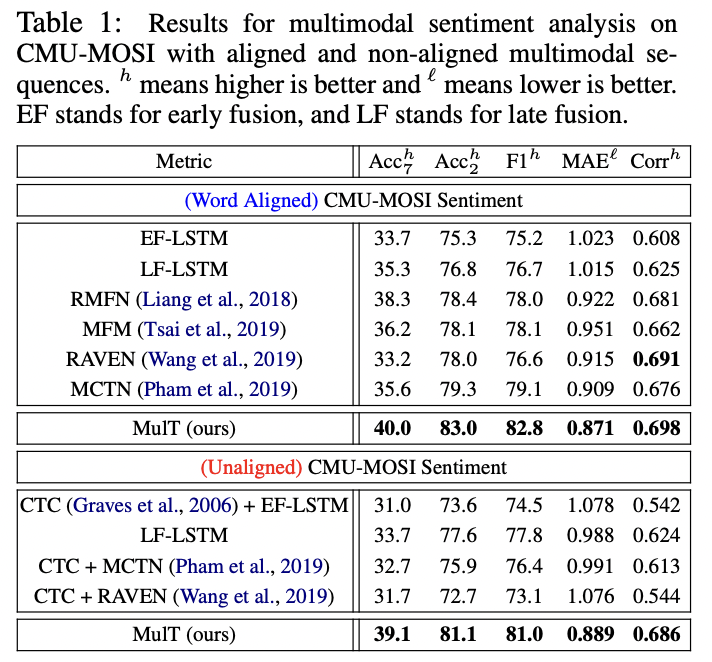
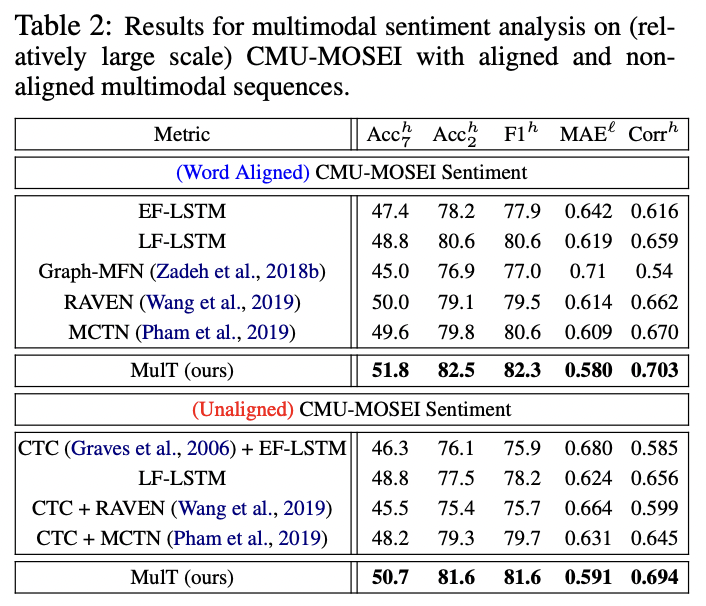
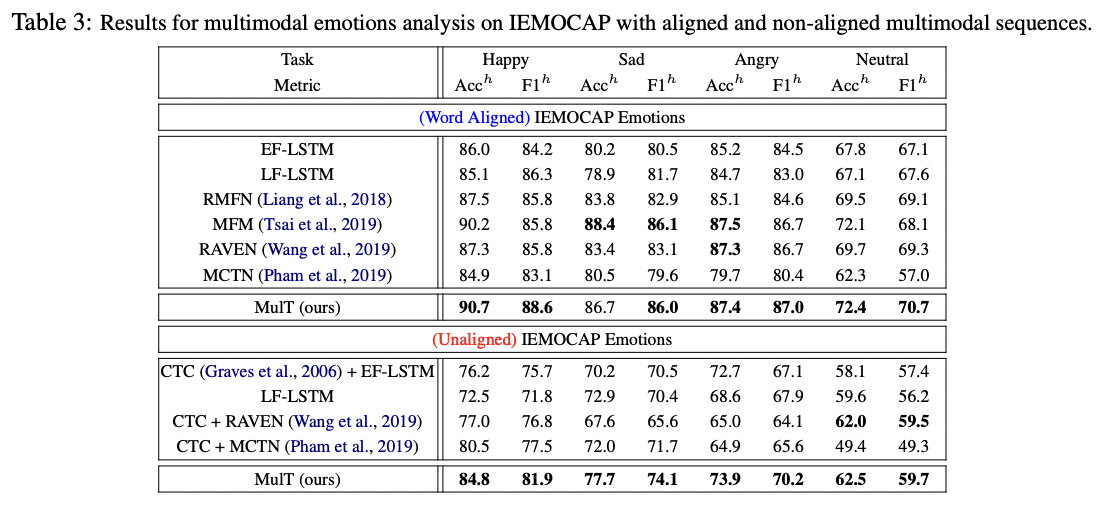
다른 모델들보다 모두 더 좋은 성능을 보임
word aligned의 성능이 더 좋지만 unaligned임에도 근소한 차이로 성능을 내는 것에 의의가 있음
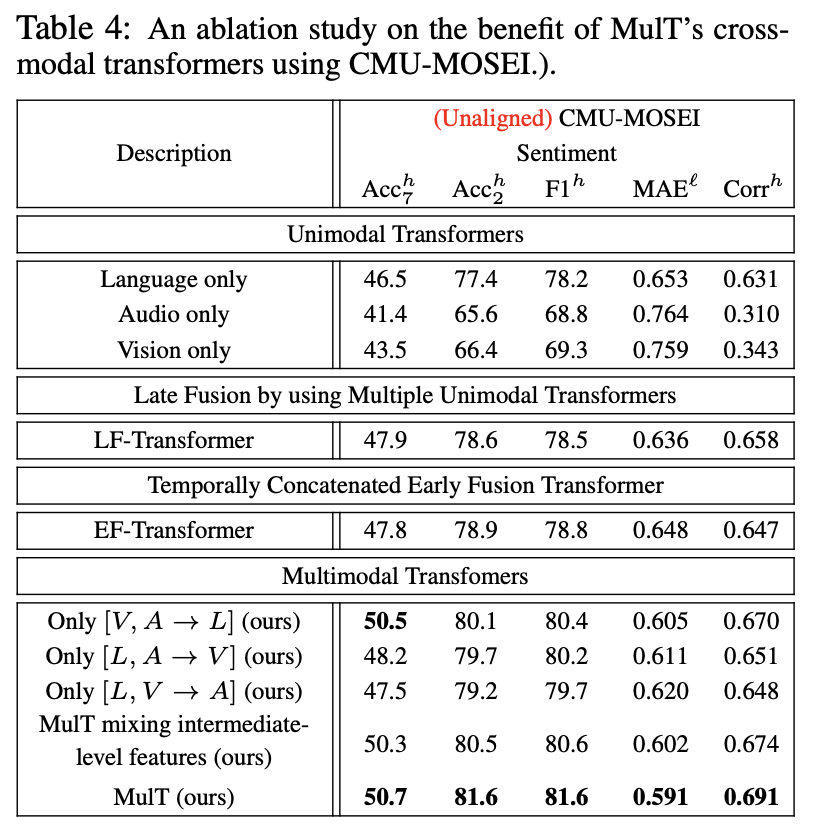
unimodality보다 multimodality에서 성능이 더 좋다
intermediate level: source modality에도 self attention을 적용한 경우를 의미
intermediate level보다 low level이 더 좋은 성능
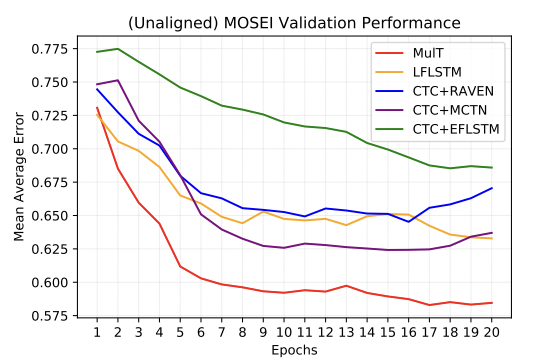
CMU-MOSEI task에서 가장 빠르게 수렴하는 것을 볼 수 있다
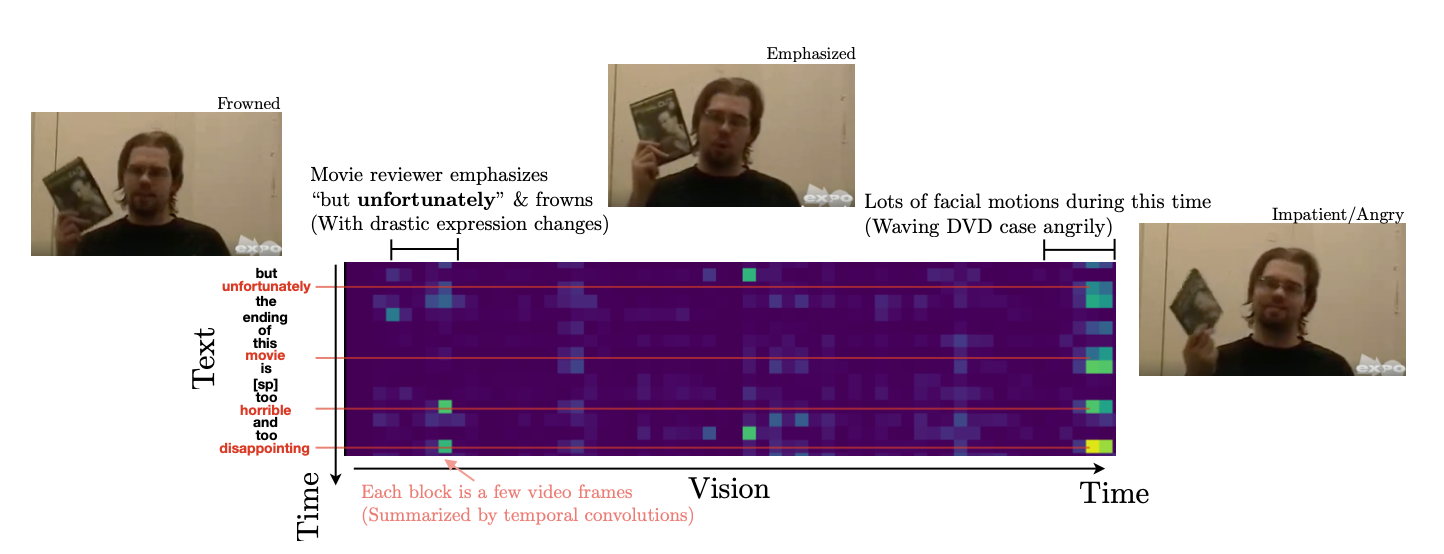
다른 시간대의 시퀀스 간에도 attention이 발생하는 것을 볼 수 있다
4.2 Baselines
word-aligned human multimodal language tasks SOTA model
1) Early Fusion LSTM (EF-LSTM)
LSTM의 입력 단계에서 각 modality vector를 더하거나 concat하여 fusion
각 modality vector는 align 되어 있음
2) Late Fusion LSTM (LF-LSTM)
각 modality 별로 LSTM을 적용하여 출력 단계에서 더하거나 concat하여 예측
Late fusion 방식이 보통 성능이 더 좋음
3) Recurrent Attended Variation Embedding Network (RAVEN)
text vector에 vision과 audio vector를 적용하는 방식의 fusion
vision과 audio vector 각각의 attended vector를 shift vector로 만들고
text vector와 더해서 fusion vector를 만들고 LSTM cell에 입력
4) Multimodal Cyclic Translation Network (MCTN)
connectionist temporal classification (CTC) 를 적용
논문의 장점
발상의 전환으로 아이디어를 제시해서 단순하게 문제를 해결한 것이 좋았다
figure와 수식 설명이 친절하다고 생각했다.
논문의 단점
친절한 설명이었지만 figure에 오류가 있어서 해석이 혼란스러웠다.

4개의 댓글

새로운 방식인데 쉽게쉽게 설명해주셔서 이해가 잘 되었습니당
- 기존 연구들의 limitation 부분 설명해준 것이 좋았는데요, 길이를 강제로 맞추면 mismathing이 된다는 부분이 이쪽 연구에서 어떤걸 challenge로 하는지 알 수 있어서 좋았습니다!
- 기존 방식보다 성능은 조금 떨어질지 모르지만, unalignment를 하니까 추가적인 전처리 방식이 필요없어서 효율적인 방식인 것 같습니다!! 이렇게 성능이 높지 않더라도 더 효율적인 방식을 제안하는 것도 큰 contribution이 되는 걸 알게되어서 뜻깊었습니다~

- transformer가 multimodal에서 어떻게 쓰일 수 있는지 좋은 예시가 된 것 같읍니다
- 기존 연구의 limitation을 언급하면서 간단하게나마 흐름을 짚어주어서 좋았습니당

안녕하세요 Eun2님 ! 새해 복 많이 받으세요 ㅎㅎㅎ 🌄
- Multimodal의 여러 세부 task 중에서도 alignment에 해당되는 논문이군요 ~
- 비디오, 오디오, 텍스트 모두 temporal한 정보가 중요한데, transformer가 적용됨으로 인해 각 모달리티 간에서도 시간적인 요소가 잘 반영된 논문이네요 !
재밌고 좋은 논문 리뷰 감사합니다 !
Multimodal Transformer (MulT)가 어떠한 구조로 작동하고 왜 6가지의 방법인지 깔끔하게 잘 설명해주셔서 좋았습니다 !!! 첫 발표를 함께 하게 되어 영광이었어여 !!! 앞으로 파이팅 ~~~