요즘 너무 바빠서 velog에는 정리를 못하고 notion이랑 ppt에다가만 정리해놨는데
밀리기 전에 후딱 써놓을려고 한다~!!
오늘은 Traffic data 간의 유사도를 파악해보는 걸 해봤다.
저번에는 시각화한 결과를 가지고 유사한 그룹을 정했는데
정량적인 방법으로 해야 더 신뢰성 있기 때문에 similarity measure를 찾아보았다.
찾다보니 time series data clustering 모델도 있길래 바로 적용~!!
내가 쓰는 데이터는 Abline 데이터 셋이다.
traffic prediction 논문들에서 자주 등장하는 데이터셋이구
학습 시키기에 데이터셋 크기도 충분한 것 같아서 이걸로 하고 있다.
미국 12개 주에서 주고 받은 traffic data set이다.
데이터 셋 규모가 넘 커서 각 target별로 12,000개씩만 불러왔다.
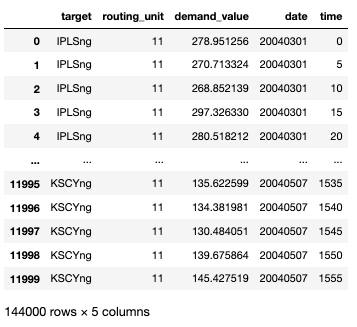
같은 target끼리 묶어줬다.
df_traffic = df_all.groupby('target')['demand_value'].apply(np.array).reset_index(name='traffic')
df_traffic['traffic']
re_traffic = df_traffic['traffic'].apply(lambda i: i.reshape(-1,1))
X = np.array(list(re_traffic), dtype=np.float)
Input 형태가 (12, 12000, 1)이 될 수 있도록 고쳐서 X를 만들어줬다.
from tslearn.clustering import TimeSeriesKMeans
km = TimeSeriesKMeans(n_clusters=3, random_state=42, metric = 'dtw')
y_pred = km.fit_predict(X)tslearn의 TimeSeriesKMeans를 사용해서 DTW 값을 가지고 클러스터링을 할거다.
늘 그렇듯 머신러닝 학습은 참 쉽다.
metric은 softdtw, dtw, ed가 있다.
y_pred
>>> array([0, 0, 1, 0, 1, 0, 0, 2, 0, 0, 0, 0])일일히 연산하니까 엄청 오래 걸린다.
print(f'Inertia: {km.inertia_}')
print(f'cluster_center {km.cluster_centers_}')클러스터 결과가 궁금하면 출력해볼 수 있다.
sz = X.shape[1]
plt.figure(figsize=(25,10))
for yi in range(3):
plt.subplot(3, 3, yi + 1)
for xx in X[y_pred == yi]:
plt.plot(xx.ravel(), "k-", alpha=.2)
plt.plot(km.cluster_centers_[yi].ravel(), "r-")
plt.xlim(0, sz)
plt.ylim(-10, 2500)
plt.text(0.55, 0.85,'Cluster %d' % (yi + 1),
transform=plt.gca().transAxes)
if yi == 1:
plt.title("Euclidean $k$-means")
예쁘게 시각화까지 해주면 끝!
k개수를 바꿔가면서 진행하고 최적의 k값을 찾으면 된다.
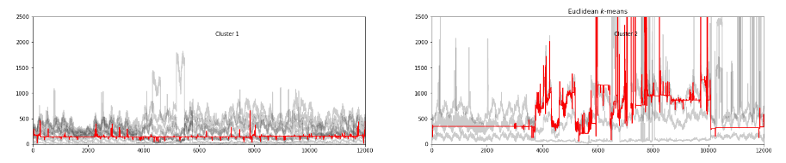

사실 시계열 데이터는 그동안 써본적이 거의 없어서 그동안 좀 어려웠는데 점차 익숙해져 가는 중이다.
끝!

A-I Can do anything
12개의 time series를 clustering하신건가요?