Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
Multi-task learning
각 task가 최적의 parameter 를 공유한다.
하나의 커다란 모델이 다양한 task를 지원할 수 있는 형태로 이루어지고
새로운 task의 dataset이 들어오면 다수의 task에 동시에 최적화된 를 찾기 위해 학습한다.
즉, 서로 연관 있는 task들을 동시에 학습함으로써 모든 task 수행의 성능을 전반적으로 향상시키려는 학습을 하는 것이다.
참고) https://mapadubak.tistory.com/40, https://velog.io/@riverdeer/Multi-task-Learning
Transfer learning
Source task의 많은 dataset으로 모델을 학습(pretrained model)하고 traget task의 dataset으로 fine-tuning하는 방식이다.
일반적으로 모델의 앞부분은 freeze하고 뒷부분의 fully-connected layer만 학습시킨다.
중요 feature 추출 능력이 source task를 통해 잘 학습되어 있기 때문에 이를 잘 전이시켜 target task를 학습을 향상시킨다는 아이디어이다.
Few shot learning을 위해 제안된 알고리즘
참고) https://dacon.io/en/forum/405988
Meta-learning
Learn-to-Learn, 학습하는 방법을 학습하는 것
다른 task를 위해 학습된 모델을 이용해서 적은 dataset을 가지는 다른 task도 잘 수행할 수 있도록 학습시키는 방식이다.
다양한 task에 대한 경험을 통해 새로운 task에 대해 조금의 경험만으로 적응할 수 있는 인간의 지능을 모방하였다.
각 task마다 최적의 parameter 가 다르다는 assumption부터 시작한다.
기존에 학습된 모델의 parameter 와 새로운 dataset의 특성 사이의 correlation에 대한 새로운 parameter 를 찾는 과정을 통해, 새로 들어온 task의 를 찾는다.
Transfer learning과 마찬가지로 Few shot learning을 위해 제안된 알고리즘이다.
차이점은 meta learning은 빠르게 adaptation할 수 있는 최적의 알고리즘을 찾기 위해 제안되었다.
즉, 더 적은 dataset을 targeting하여 빠르게 최적화를 할 수 있도록 generalization에 focusing 되어 있는 방식이다.
장점
- 적은 양의 data를 가진 task에서도 잘 수행됨
- High computational hardware가 필요하지 않음
Meta Learning의 분류
-
Model-based model
-
Metric-based Approach
저차원의 공간에 새로 들어온 데이터를 mapping하고
데이터 간의 거리가 가까운 방향으로 새로운 task의 dataset을 분류하는 알고리즘 -
Optimization-based Approach
여러 task의 generalized 버전 model의 parameter 를 구하고
이를 new task model의 parameter 의 초기값으로 정의
최적의 task parameter 를 빠르게 찾을 수 있다
대표적인 모델로 MAML이 있다.
Model-Agnostic Meta Learning (MAML)
모델에 상관없이 대부분의 AI 모델에 적용 가능한 meta learing
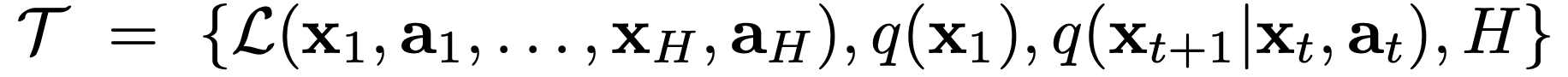
each task
observation
output
loss function
- ex) supervised learning
- Regression task: MSE, Classification task: Cross Entropy Loss
distribution over initial observation
transition distribution
episode length
-> supervised learning problem,
각 time t에서 output 를 선택 함으로써 모델은 길이가 H인 sample을 생성 (뭔솔?)
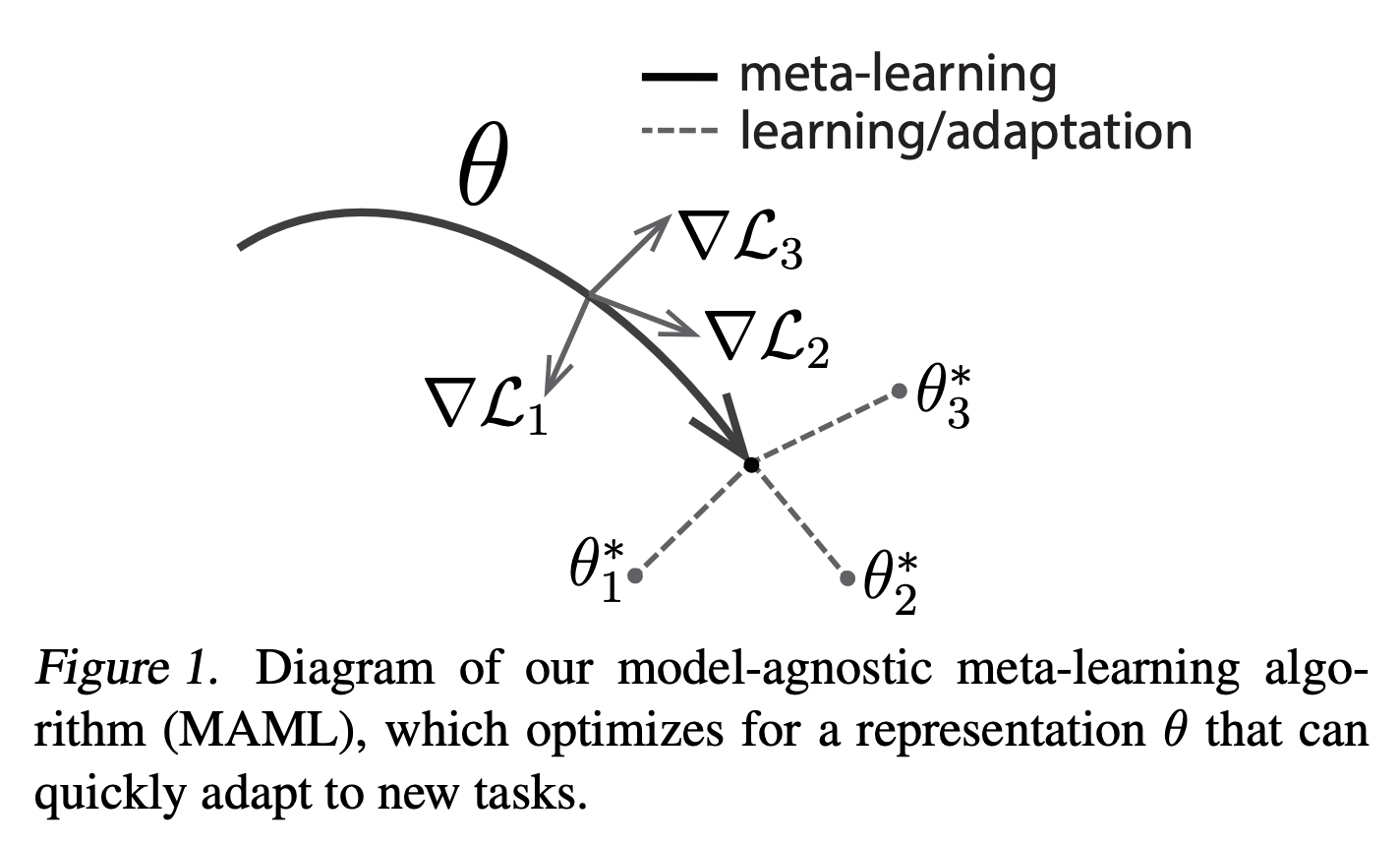
가 가르키는 point가 에 대한 최적점은 아니지만 가장 빠르게 adaptation 할 수 있는 point이다.
이후 새로운 task 에 맞는 최적의 model parameter 를 찾아가는 방식으로 gradient descent를 진행한다.

한 두번의 gradient descent로 update
Meta-optimization across Tasks를 진행 (-> 뭐지?)

MAML for Reinforcement Learning도 있는데 이건 다음에 알아보도록 하자 (띠~용~)
간단하게만 보자면 task가 변하는 환경에서 적은 exprience로 policy를 updat하는 방식이라고 한다.
Related Work가 Method 다음에 나와서 신기하다.
Experimental Evaluation
1) MAML이 새로운 task를 빠르게 학습할 수 있는가?
2) MAML이 여러 도메인에 적용될 수 있는가? (회귀, 분류, 강화학습)
3) MAML로 학습한 모델이 gradient update를 계속할 때 더 개선되는가?
Regression Task
Sine wave 예측
Neural Network model with 2 hidden layers of size 40 with ReLU nonlinearities
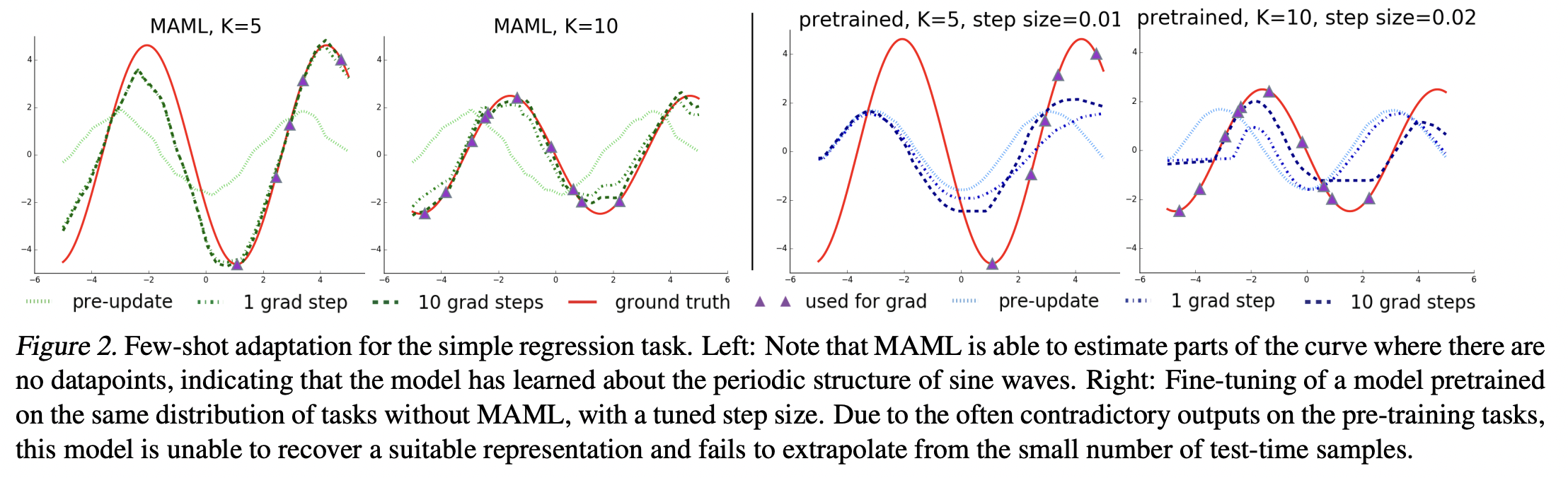
연두색: MAML update 이전
초록색: MAML update 이후
하늘색: pretrained model
파란색: pretrained model step 증가
빨간색: ground truth
초록색이 빨간색에 가장 잘 근사
보라색 데이터가 일부 구간에 몰려 있음에도 MAML은 데이터가 없는 구간도 잘 예측
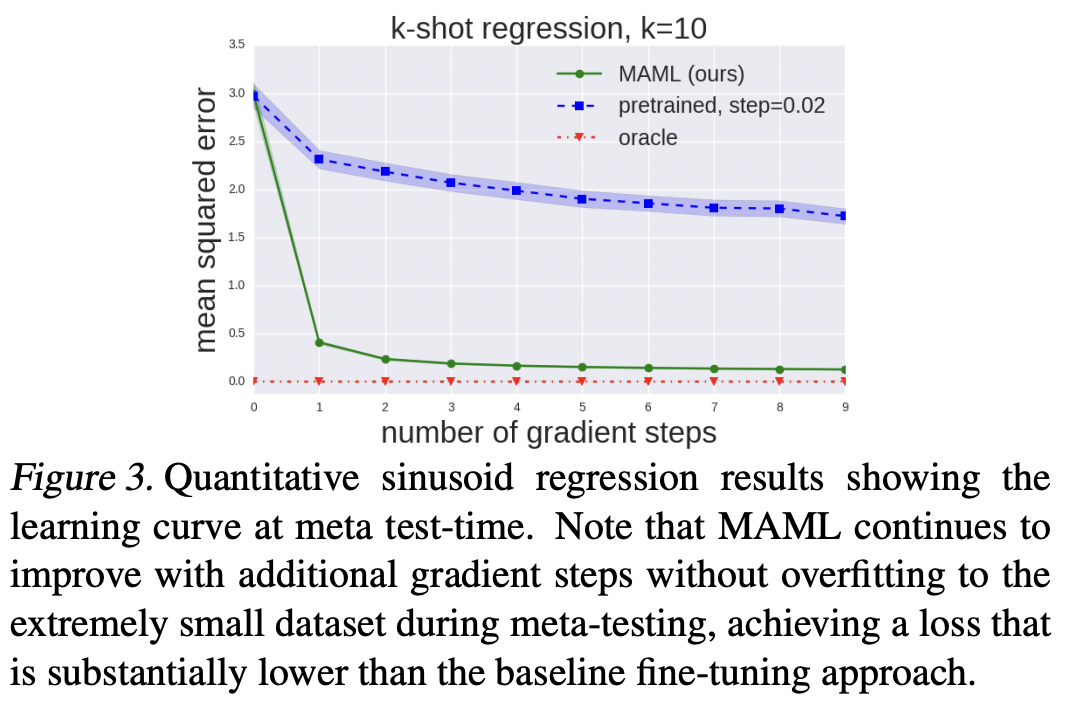
과적합 되지 않고 잘 수렴하고 있음
Classification Task
few-shot image recognition
Omniglot dataset
다양한 국가의 다양한 문자에 대한 손글씨 dataset
consists of 20 instances of 1623 characters from 50 different alphabets

MiniImagenet dataset
ImageNet dataset의 축소 버전
100개의 class당 600개의 이미지로 구성
64 training classes, 12 validation classes, and 24 test classes

다른 메타러닝 방법인 Siamese Networks, Matching Networks와 비교
MAML no conv 모델은 단순 4-layer NN 구조를 사용
타 모델들보다 훨씬 적은 파라미터를 사용하는데도 더 좋은 성능을 보임
Reinforcement Learning
2D Navigation
a point agent must move to different goal positions in 2D, randomly chosen for each task within a unit square
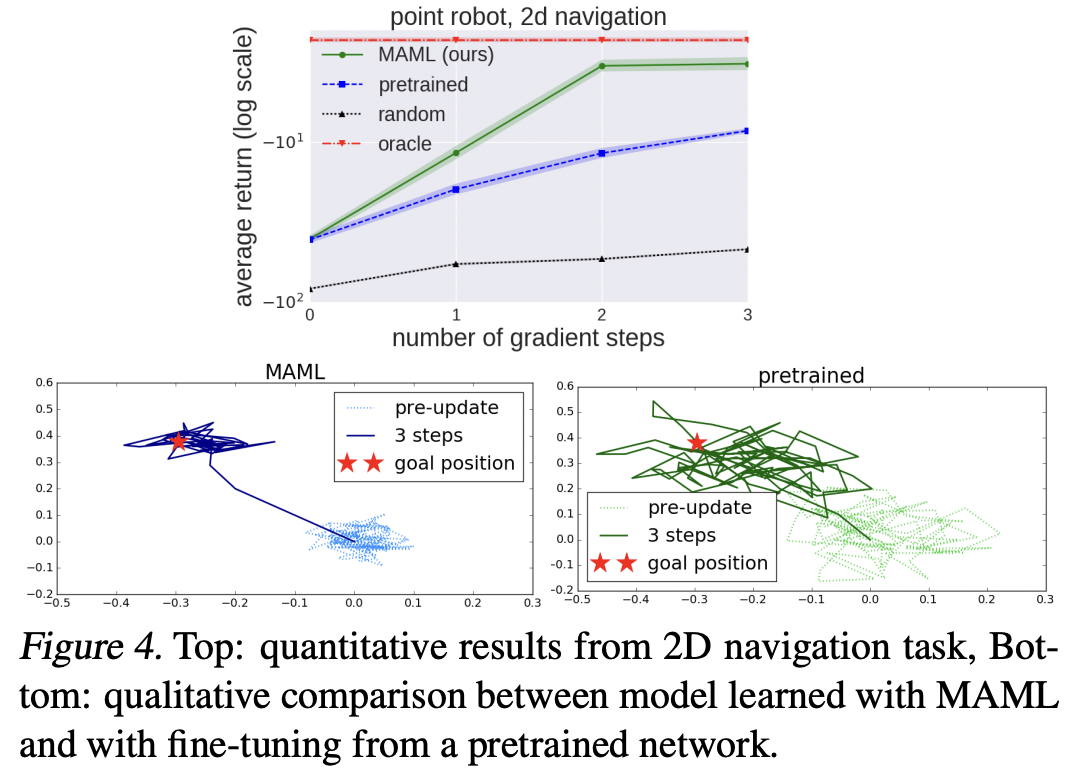
Locomotion
high-dimensional locomotion tasks
MuJoCo simulator : 물리적 현상을 자연스럽게 나타내는 시뮬레이터
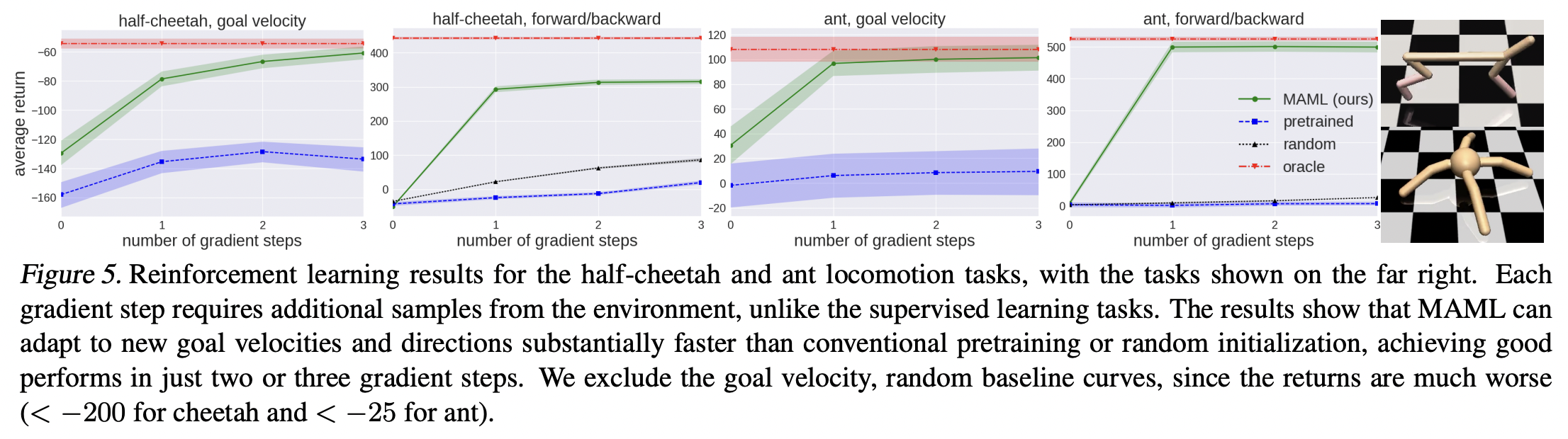
참고) https://engineering-ladder.tistory.com/95, https://velog.io/@tobigs_xai/10%EC%A3%BC%EC%B0%A8-MAML-Model-agnostic-Meta-Learning-for-Fast-Adaptation-of-Deep-Networks-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
