Towards Inter-character Relationship-driven Story Generation
Introduction
대부분의 story는 캐릭터 간의 interpersonal relationship로부터 시작된다.
story에서의 relationship의 중요성에 반해, 현재 NLP 분야에서는 character relationship 측면을 고려하여 SG 연구를 하는 연구가 아주 적다.
이전 SG 연구들은 open-ended prompt를 기반으로 스토리를 생성하고 CR을 임베딩하거나 명시적으로 캐릭터나 CR을 컨트롤하지 못한다.
따라서 본 논문에서는 Relation-driven Stroy Generation을 제안한다.
prompt 문장과 inter-character relationship이 주어졌을 때, 캐릭터 간의 관계를 따르며 프롬포트 문장과 이어지는 문장을 생성하며 스토리를 만들어가는 것이다.
관계를 나타내는 방법은 다양하지만, 본 논문에서는 relationship polarity라는 방식을 사용한다.
캐릭터 간의 전반적인 상호작용을 positive, neutral, negative로 요약하여 표현한다.
- 이전 연구: Chaturvedi et al., 2016; Srivastava et al., 2016; Si et al., 2021
본 논문의 task에서는 두 가지 챌린지가 있다.
1) Relationship selection
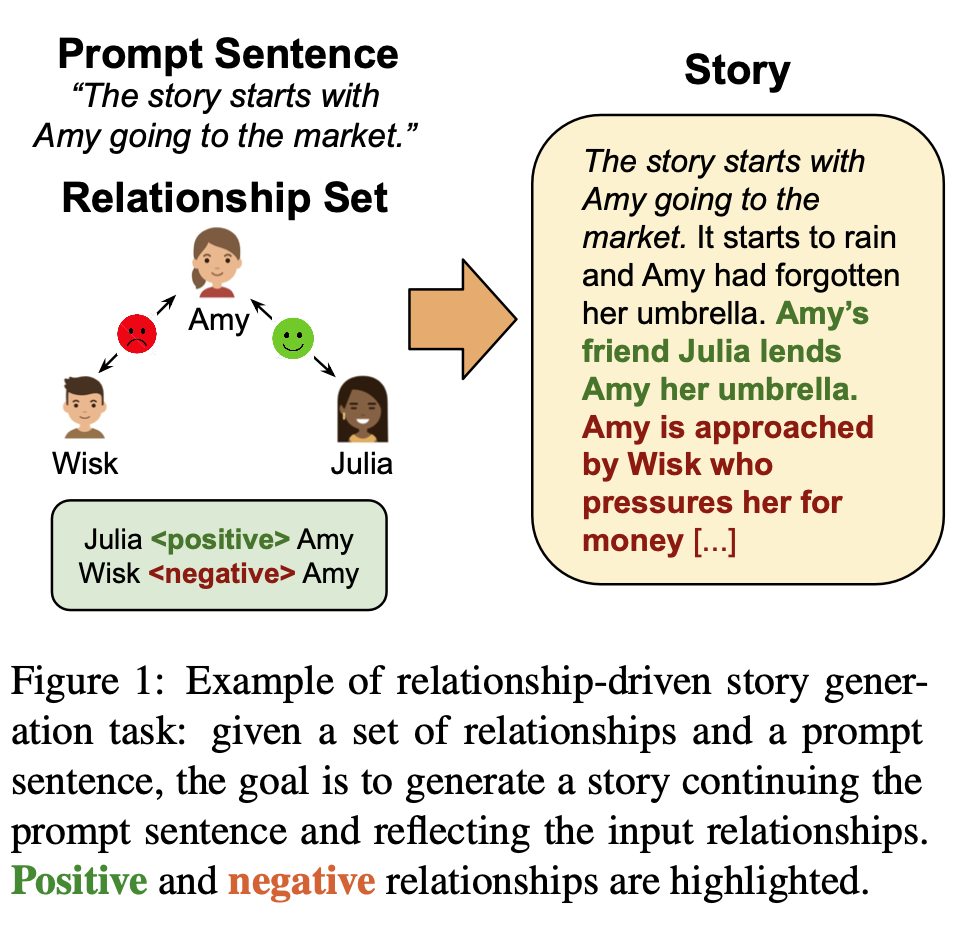
Figure 1의 첫번째 문장 "The story starts with Amy going to the market."처럼 인물 간의 관계성이 드러나지 않는 문장이 있는 경우가 있다.
따라서 SG 모델은 context를 기반으로 언제(when), 어떤(which) 관계를 선택할 것인지 결정해야 한다.
2) Story continuation
narrative의 전반적인 일관성을 유지하면서 원하는 관계를 자연스럽게 반영하는 이벤트를 생성해야한다.
두 챌린지 모두, 모델이 여러 문장과 캐릭터 사이의 long-range dependencies를 잘 포착해야함을 의미한다.
따라서 본 논문에서는 relationship을 latent variables로 취급하도록 모델링을 하였다.
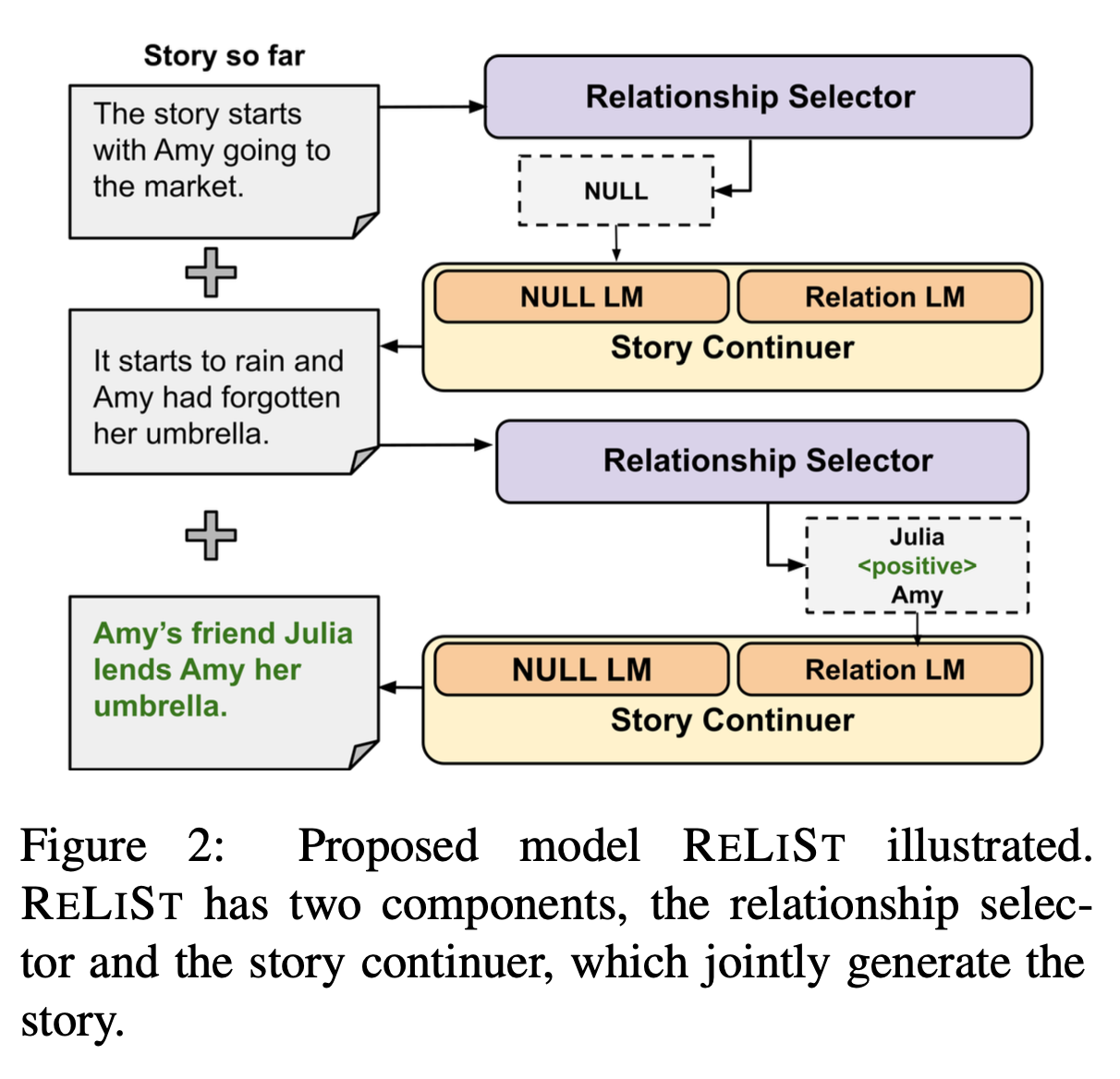
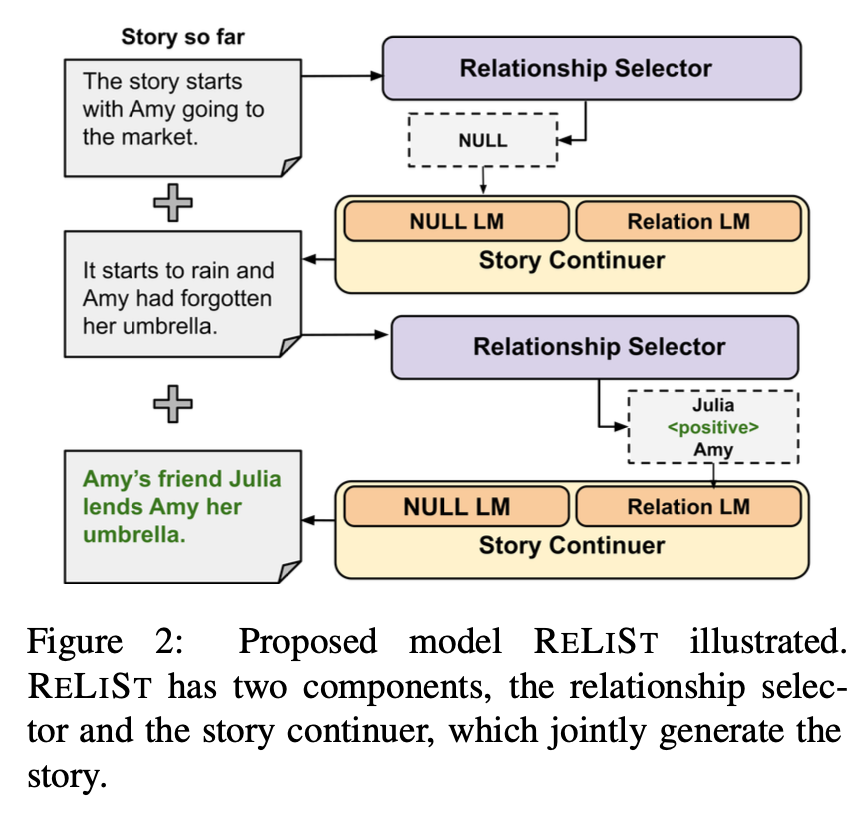
본 논문에서 제안하는 모델은 RELIST인데, 두 개의 컴포넌트로 구성되었다.
1) Relationship selector
첫번째 챌린지였던, 언제(when), 어떤(which) 관계를 처리할 것인지를 결정하는 컴포넌트이다.
문장을 생성하기 전에, 다음 문장을 생성하는데 조건화할 관계를 (또는 관계가 없을수도 있음) 선택한다.
2) Story continuer
narrative의 논리적인 지속성(logical continuation)을 보장하면서, 선택된 관계를 반영하여 자연스럽게 문장을 생성한다.
두 컴포넌트는 함께 작동하며 같이 훈련된다.
content quality와 relationship faithfulness 측면에서 automatic metric와 human evaluation을 진행했다.
실험 결과, RELIST가 생성된 이야기에서 fluency와 coherence를 유지하면서 원하는 관계를 표현할 수 있음을 보여준다.
본 논문의 네 가지 Contribution은 다음과 같다.
1) interpersonal relationship을 제어 가능한 파라미터로 사용하여, 관계 중심 스토리 생성에 대한 첫번째 연구이다.
2) Relationship selector와 Story continuer로 구성된 RELIST 모델을 제안했다.
3) 실험을 통해, 원하는 관계를 반영할 뿐만 아니라 유창한 스토리를 생성할 수 있음을 입증했다.
4) 분석을 통해 모델의 생성 프로세스에 대한 transparency(투명도)를 보여주었다.
Related Work
~.~
Relationship-driven Story Generation
Problem Statement
Task: relationship-driven story generation task
formulation은 다음과 같다.

와 ℜ이 input으로 들어왔을 때 를 생성하는 것이 목표이다.
Relationships as Latent Variables for Story Generation
본 논문에서 제안한 모델 Relationships as Latent Variables for Story Generation (RELIST)
- sentence by sentence로 이야기 생성
- 문장 내의 relationship을 latent variable의 관점으로 다룸
Relationship selector
각 문장 내의 relationship은 discrete latent variable인 로 표현된다.
하지만 이야기의 모든 문장에서 관계성이 드러나는 것은 아니니까, null을 의미하는 를 에 추가했다. 이다.
다음 문장을 생성하기 전에 relationship selector에서 가 샘플링 된다.
즉, Relationship selector는 다음과 같이 공식화 할 수 있다.
이전 시점까지의 context ()와 R이 주어졌을 때 에 대한 확률 분포를 구한다.
해당 컴포넌트는 가 있는 분류기를 사용하여 매개변수화된다.
Story continuer
Story continuer는 다음과 같이 공식화 할 수 있다.
가 주어졌을 때 를 샘플링한다.
Relationship selector의 결과가 Null인지 아닌지에 따라 다른 LM을 사용한다.
“Relationship LM”과 "NULL LM"이다.
해당 컴포넌트의 매개변수는 이다.
Training RELIST
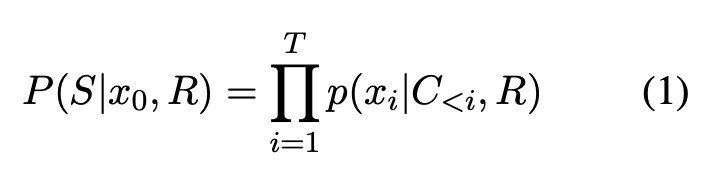
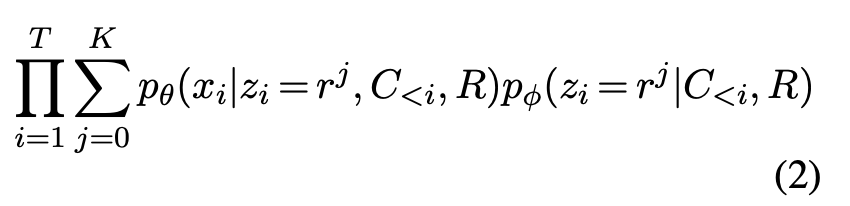
두 컴포넌트는 Expectation Maximization을 사용하여 jointly하게 훈련된다.
E step에서는 latent variable의 expected posterior를 추정한다. Bayes Rule에 따름.
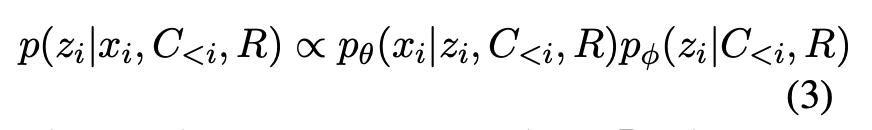
첫번째 텀을 통해 각 문장의 의 업데이트를 샘플링하여 할당한다.
M step에서는 새로운 latent variable의 할당이 주어지면, 파라미터 와 를 업데이트 하기 위해, log likelihood를 최대화한다.
relationship selector의 훈련 단계에서는 식(4)를, story continuer의 훈련 단계에서는 식(5)를 최적화한다.
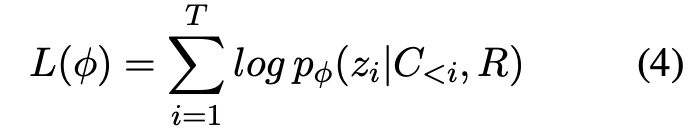
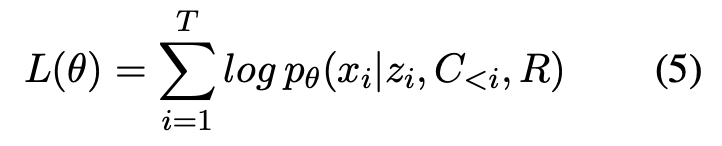
Implementation Details
Relationship selection task에서는 단순한 분류 모델을 사용할 수가 없었기 때문에 BERT 모델을 훈련했다.
Input:
Output: 의 토큰에서 다음 관계에 대한 시작 및 종료 토큰을 나타내는 시작 및 종료 포인터
따라서 모델은 relationship set 또는 null에서 pointing해서 선택할 수 있다.
이 세팅은 QA task를 위해 BERT를 훈련하는 것과 유사하다.
Story continuer에서는 GPT-2 medium으로 초기화된 decoder-only Transformers를 사용했다.
Relationship LM의 input: >Relationship LM의 output: $x_i
Relationship LM은 주석이 달린 문장에 대해서만 학습했다.
Null LM의 input: > C_{<i}Null LM의 output: $x_i
Null LM은 fluency와 coherence를 학습하기 위해, 모든 문장에 대해 학습했다.
노이즈를 막기 위해, warmup 단계까지는 업데이트를 지연했다.
Experimental Setup
Dataset and Annotation Pipeline
CMU Movie Summary Corpus 데이터셋을 사용했다.
Story: 42,306 movie summaries, 평균적으로 375개의 단어로 구성
Interpersonal relationship (IR)에 대한 라벨링이 필요하다.
자동으로 라벨링된 corpus를 silver labelled dataset이라고 부르기로 했다.
해당 데이터 셋을 구축하기 위한 automatically annotation process는 다음과 같다.
1. BookNLP를 사용하여 dependency parse labels과 character mentions를 식별한다.
2. 두 명의 캐릭터가 언급된 문장 중, 한 캐릭터는 object(주어)이고 다른 캐릭터는 subject(목적어)인 경우에 해당하는 문장을 식별한다.
- 이 제약은 문장의 전반적인 감정(sentiment)이 아니라 IR을 포착하는 데 도움이 된다. 예를 들어, "John과 Beth는 모든 돈을 잃었습니다." 전반적으로 부정적인 감정이 있지만 John과 Beth 사이의 부정적인 관계를 나타내지는 않는다.
- IR의 global representation으로 동일한 character pair에 대한 언급을 포함하는 모든 문장을 concat한다.
- 결합된 문장의 sentiment를 사용하여 character pair에 대한 전반적인 relationship polarity를 얻는다. Sentiment Intensity Analyzer toolkit을 사용하여 “positive”, “neutral”, “negative”에 대한 intensity score를 반환한다.
최종적으로 라벨링된 silver labelled dataset은 16,886 개의 story와 31,488개의 관계를 포함한다.
silver labelled dataset을 sentence-level에서의 관계 라벨링으로도 확장할 수 있다.
2번에서 선택된 문장에 4번의 score를 annotation한다. 2번에서 선택되지 않는 문장은 로 라벨링한다.
이 데이터는 story continuer와 relationship selector를 초기화할 때 사용한다.
Baselines
모든 베이스 라인 모델은 silver labelled datase을 사용했다.
앞서 말했듯 RELIST를 초기화할 때 sentence-level annotation 데이터를 사용했기 때문에, GPT-2 Planned에서도 이 정보를 포함한다.


Evaluation Measures
Automatic Evaluations
Relationship Faithfulness Metric
입력에서 원하는 관계를 표현하는 스토리를 모델이 얼마나 충실하게 생성하는지에 대한 평가 지표이다.
두 가지 metric을 제안한다.
1) Relationship Identification (RI)
모델이 생성한 스토리에 표시된 관계를 입력된 관계와 비교한다.
즉, 생성된 스토리에 위에서 설명한 annotation pipeline을 적용하여 도출된 관계와 실제 입력된 관계를 비교하여 아래 값들을 계산한다.
- %Exact: 정확히 일치하는 관계의 백분율
- %Unspec: 입력에서 지정되지 않은 pair가 등장하는 경우의 백분율
- %Incorrect: 올바른 pair지만 관계의 값(polarity)이 올바르지 않은 경우의 백분율
- Average Relationships (AvgRel): 생성된 스토리에서 식별된 관계의 평균 수
Polarity Classification (P-CLS)
모델에 의해 생성된 스토리가 원하는 관계를 정확하게 반영한다면, 스토리 텍스트에서 relationship polarities을 식별하는 'inverse' 작업에 사용할 수 있다.
생성된 스토리와 character pair를 입력으로 받아 relationship polarities를 예측하는 polarity classifier를 훈련할 수 있다.
훈련된 분류기로 수동 주석이 달린 스토리 105개를 분류함으로써 평가할 수 있다.
분류기 정확도는 학습 데이터의 우수성, 즉 생성된 스토리가 원하는 관계를 얼마나 잘 반영했는지를 나타낸다.
CLS를 이 분류기의 정확도로 정의한다.
finetune BERT-base로 분류기를 만들었다.
Content Quality Metrics
- BLEU score
- ROUGE score
n-gram, n = 1,2,3
Human Evaluations
입력과 한 쌍의 스토리가 주어졌을 때 아래 세 가지 측면을 고려하여 더 나은 스토리를 선택하거나 동일한 품질임을 선택한다.
(1) content quality
(2) relationship faithfulness
(3) overall
Experimental Results
Relationship Faithfulness
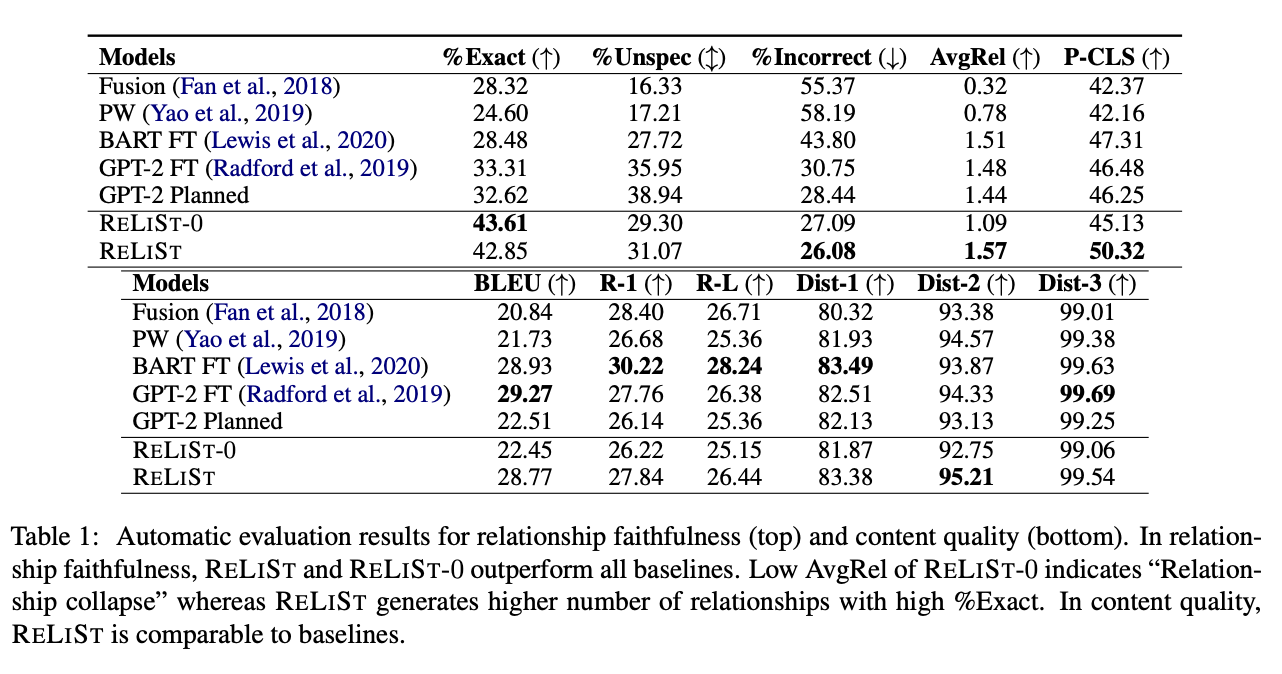
GPT-2 FT와 RELIST 비교 = latent variables의 유무
RELIST와 RELIST-0 비교 = silver labelled data로 초기화 유무
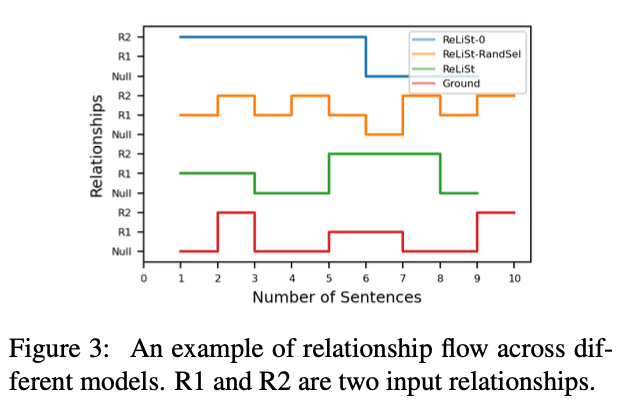
RELIST-0은 같은 관계를 반복해서 계속 선택하는 "Relationship collapse" 문제로 고통받는다. 따라서 스토리에서 더 적은 관계가 생성된다.
GPT-2 Planned는 이전에 생성한 문장을 고려하지 않고 relationship을 생성하기 때문에 낮은 성능이 나온다.
P-CLS score는 automatic하게 라벨링된 데이터로 학습해서 사람이 라벨링한 데이터를 예측하는 것이니까 원래 어려운 task이다.
그래서 다른 베이스 라인 모델들은 42.15라는 random performance에 근접하게 예측을 하는데 본 모델은 50.32에 도달한다.
Content Quality
RELIST-0은 앞서 말한 "Relationship collapse" 문제를 겪으면서 계속 같은 관계를 선택하고 그 관계에 대해 스토리를 생성하기 때문에 일관성이 크게 떨어진다.
Human Evaluation
Dist-2: relationship faithfulness에서는 더 좋은 점수를 받음
콘텐츠 품질 측면에서 두 모델 간의 차이는 통계적으로 유의하지 않지만 전반적으로 심사 위원들은 GPT-2 FT보다 RELIST를 선호했습니다. (표 해석 어케 함???????)
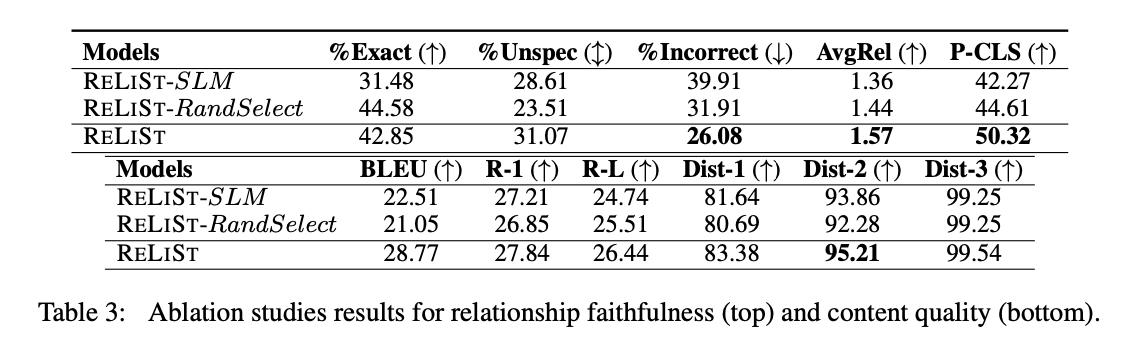
Ablation Study

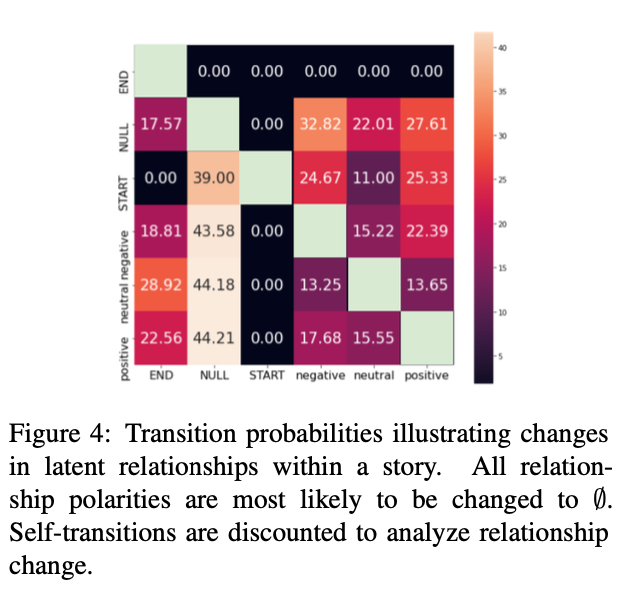
Appendix



공감하며 읽었습니다. 좋은 글 감사드립니다.