Spark는 쿼리를 돌리기 위해 두 가지 엔진을 사용한다.
| 그림 | 설명 |
|---|---|
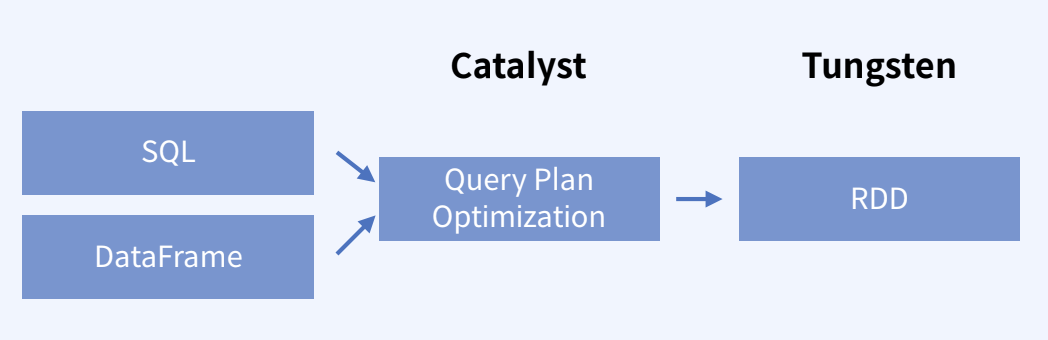 | - Catalyst의 경우 사용자의 코드를 엔진에서 구동하기 위해 실행 계획 최적화를 수행하고, Tungsten 의 경우 보다 row-level에서 하드웨어 성능 극대화를 수행한다. |
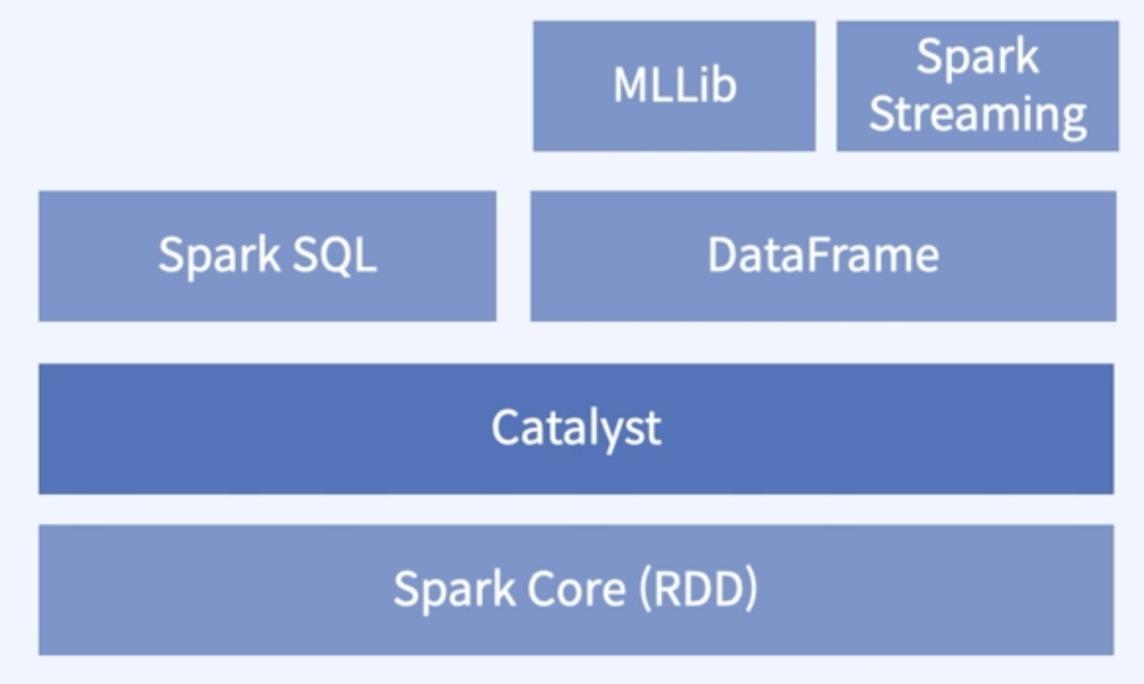 | - 기본적으로 Spark Core 위에 존재하는 모듈이며, Catalyst로 인해 Spark SQL과 Dataframe을 함께 사용할 수 있게 된다. |
Catalyst
- Logical Plan : 데이터가 어떻게 변해야 하는지 정의하지만, 실제 어디서 어떻게 동작하는지는 정의하지 않음 - 즉, 모든 transformation 단계에 대한 추상화
- Physical Plan : Logical Plan이 어떻게 클러스터 위에서 실행될지 정의. 실행 전략을 만들고 최적화하는 역할
사용자가 작성한 코드를 실행 가능한 엔진으로 최적화 시키는 역할 (데이터베이스 시스템의 실행계획법 ctrl+L 과 비슷한 역할) 핵심 기능 : Logical Plan을 Physical Plan으로 바꾸는 역할을 수행
| 기능 | 설명 |
|---|---|
| 분석 | Dtaframe 객체 relation 계산, 칼럼의 타입과 이름 확인 |
| Logical Plan 최적화 | - 상수 표현식 Compile Time 계산 - Predicate Pushdown (조인 먼저? 필터 먼저?) - Projection Pruning (연산에 필요한 칼럼만 선택) |
| Physical Plan 만들기 | Spark에서 실행 가능한 Plan으로 변환 |
| 코드 제너레이션 | 최적화 완료된 Physical Plan을 Java Bytecode로 |
코드 예시
SELECT zone_data.Zone, count(*) AS trips
FROM trip_data
INNER JOIN zone_data
ON trip_data.PULocationID = zone_data.LocationID
WHERE trip_data.hvfhs_license_num = 'HV003'
GROUP BY zone_data.Zone
ORDER BY trips| 최적화 전 | 최적화 후 |
|---|---|
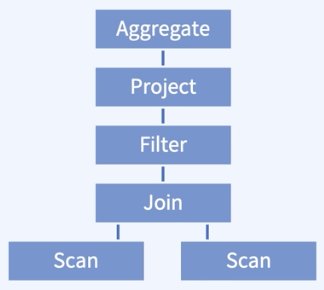 | 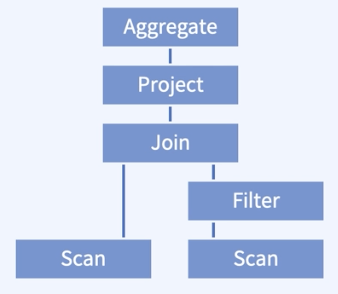 |
| - 두 테이블에 대한 Scan을 진행하고, - 두 테이블에 대한 조인을 수행한다. | - 두 테이블에 대한 Scan을 진행하고, - 조건문을 보았을 때 필터가 걸리는 테이블이 하나이므로, 하나의 테이블에서 먼저 필터 수행 |
Spark explain()
spark.sql(query).explain(True)- Spark의 실행계획에 대해 알려주는 함수
- 공식문서 Spark Explain()
Tungsten
row-level에서 하드웨어의 성능을 극대화하기 위한 엔진 Code generation
목표 : 스파크 엔진 성능 향상
- 메모리 관리 최적화
- 캐시 활용 연산
- 코드 생성
출처
실시간 빅데이터 처리를 위한 Spark & Flink (패스트캠퍼스 강의)

1차전직 DA 2차전직 DE