ELECTRA
본 논문의 전체 제목은 ELECTRA : pre-training text encoders as discriminators rather than generator 로, google research 팀이 ICLR에 2020년 발표한 논문이다. 부제로 적혀있는 것과 같이, ELECTRA는 generator(생성자)보다 discriminator(판별자)를 주로 학습에 사용하는 pre-training text encoder라고 볼 수 있다. 지금부터 본격적인 ELECTRA 논문 리뷰를 시작해보도록 하겠다.
0. Abstract
우선 ELECTRA의 구조를 이해하기 위해서는 간단한 BERT의 pre-training 과정을 이해해야 한다. BERT는 MLM과 NSP 두가지의 pre-training 과정을 거치는데, 그 중 MLM (masked language modeling)은 몇개의 단어 토큰을 [MASK] 토큰으로 변경하여 모델을 학습하는 pre-training 과정이다. 해당 방법을 사용하면 downstream NLP task에서 좋은 성능을 보일 수 있지만, 해당 과정을 수행하기 위해서는 굉장히 많은 연산량을 필요로 한다.
그렇기 때문에 해당 논문에서는 replaced token detection을 제안한다. 이는 masking을 적용하는 MLM과는 달리, small generator network에서 sampling된 alternatives로 대체하자는 개념이다. 그러고나면 원래 토큰을 예측하는 학습을 진행하는 BERT의 방식과 달리, 해당 토큰이 generator에 의해 생성된 토큰인지를 예측하는 차별적 모델을 학습시킨다.
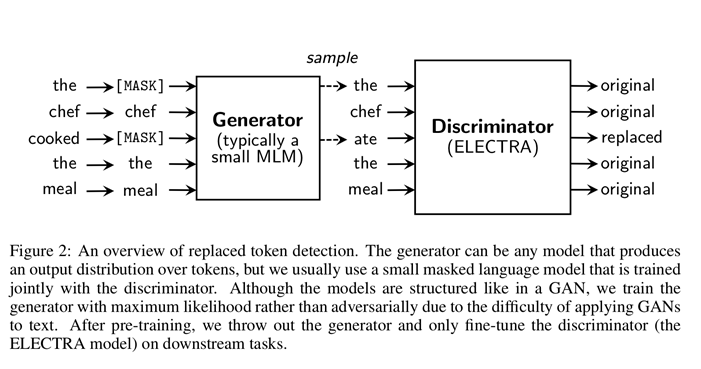
Figure 2를 보면 ELECTRA의 전체적 구조를 쉽게 확인할 수 있기 때문에 해당 자료를 미리 가져왔다. 우선 몇 개의 토큰을 [MASK] 토큰으로 바꾸고 이를 Generator에 의해 생성된 sample로 대체한다. 그리고 이 토큰들을 Discriminator에 의해 대체된 토큰인지, 원래 토큰인지 예측한다.
결과적으로, 해당 방법을 사용해 학습한 문맥은 동일한 size, data, compute에서 BERT보다 훨씬 더 잘 수행된다고 한다. 또한 이는 연산을 1/4보다 적게 사용할 때도 RoBERTa와 XLNet에 필적하게 수행하여, 같은 양의 컴퓨팅을 사용했을 경우는 더 높은 성능을 보인다고 한다.
1. Introduction
replaced token detection에 대해 더 자세히 살펴보도록 하자. 앞에서도 말했듯, replaced token detection은 plausible하지만 합성적으로 생성된 대체 토큰을 구별할 수 있도록 학습시키는 pre-training task이다. 마스킹을 하는 대신 일부 토큰을 제안 분포의 샘플로 대체하는 작업을 수행하는데, 이때의 제안 분포는 보통 small masked language model의 output이다.
BERT에서는 pre-training 과정에는 [MASK] 토큰이 존재함에 비해, fine-tuning 과정에는 [MASK] 토큰이 존재하지 않기 때문에 발생하는 mismatch가 존재하는데, 본 논문에서 제안하는 방법을 사용하면 이 문제를 해결할 수 있다. 그런 다음 네트워크를 모든 토큰에 대해 원래의 토큰인지 대체된 토큰인지 예측하는 discriminator로 pre-train하는 과정을 거친다. 이에 반해 MLM은 원래 토큰을 예측하는 generator로 네트워크를 훈련한다.
해당 논문에서 제시하는 방법의 가장 큰 장점은 다른 모델은 모델이 단순히 마스킹된 토큰들을 주로 학습하는 것과 달리, 모든 입력 토큰에서 학습해 계산의 효율성을 높인다는 점이다. 동일한 컴퓨팅 예산에서 다른 모델들보다 해당 방법이 우수하다는 것을 아래의 Figure 1 결과로부터 확인할 수 있다.
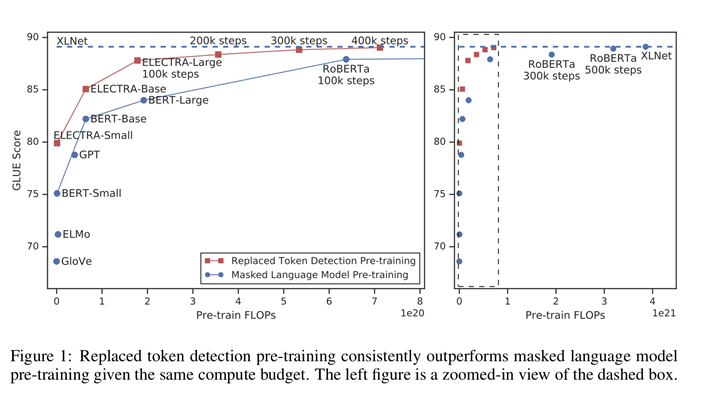
본 논문에서는 해당 과정을 ELECTRA라고 부르며, 이를 pre-train된 transformer text encoder에 적용해 downstream task에 fine-tuning한다. 일련의 ablation을 통해 모든 입력 위치에서 학습하면 ELECTRA가 BERT보다 훨씬 더 빠르게 훈련한다는 것을 알 수 있다. 또한 완전히 훈련되었을 때 ELECTRA가 downstream task에서 더 높은 정확도를 달성한다.
2. Method
위의 Figure 2는 Replaced Token Detection pre-training task를 나타내고 있다. 이 방법에서는 generator 와 discriminator 의 두 가지 neural network로 학습하며, 각각은 input token 를 문맥정보를 반영한 시퀀스 으로 매핑하는 transformer encoder로 구성된다.
Generator
generator는 주어진 position 에 대해 (이 때 [MASK]) softmax layer를 통해 특정 토큰 를 생성할 확률을 반환한다.
이 때 e는 token embedding이다.
간단히, generator는 MLM을 수행하기 위해 학습된다고 볼 수 있다. 수식은 복잡해 보이지만 단순히 [MASK]자리에 어떤 단어가 나타날지에 대한 확률이라고 생각하면 된다. 즉, BERT의 MLM과 그 과정이 거의 유사하다.
다음은 generator network의 세부 학습과정이다.
-
주어진 input 이 있을 때, 우선 마스킹을 하기 위한 position의 random set 을 선택한다.
for =1 to -
해당 position의 토큰은 [MASK]토큰으로 대체하는데, 이를 수식으로 [MASK]와 같이 나타낸다.
-
마스킹된 토큰을 예측하도록 학습한다.
generator의 loss function은 다음과 같다.
Discriminator
주어진 position 에서, discriminator는 토큰 가 진짜인지, 생성된 것인지 이진분류로 예측한다.
discriminator는 토큰이 generator sample에 의해 대체되었는지 판별하는 과정을 학습한다. 다음은 discriminator network의 세부 학습과정이다.
- masked-out token을 generator sample로 대체하여 corrupted example 를 생성한다.
for - 에 있는 token이 원래의 input 와 일치하는지 판별하는 학습을 거친다.
discriminator의 loss function은 다음과 같다.
combined loss
결론적으로 large corpus에 대해 combined loss를 최소화하는 방향으로 학습한다.
Generator에서 샘플링하기 때문에 discriminator loss는 generator로 역전파 되지 않으며, 위의 구조로 pre-training을 마친 뒤에 generator는 버리고 discriminator만 취해서 downstream task으로 fine-tuning을 진행한다.
3. Experiments
3.1 Experimental Setup
GLUE와 SQuAD를 사용해 ELECTRA의 성능을 평가한다. Large Model 실험에서는 XLNet에서 사용한 데이터로, 나머지 대부분 experiment에서는 BERT에서 사용한 데이터로 pre-train시킨다. 모델의 구조와 대부분의 하이퍼 파라미터 역시 BERT와 동일하게 세팅했다.
3.2 Model Extensions
해당 절에서는 ELECTRA를 개선시킬 수 있는 확장법을 몇가지 제안한다. 실험에서는 BERT-Base와 동일한 모형 size와 데이터로 학습한다.
Weight Sharing
weight sharing은 말 그대로 generator와 discriminator 사이의 weight를 공유하는 개선법이다. 두 네트워크가 같은 size를 가지면 모든 transformer weight가 공유될 수 있다. generator와 discriminator가 같은 size를 가질 때, weight tying strategy를 500k step으로 학습시킨 결과 GLUE Score는 다음과 같이 도출된다.
- no weight tying : 83.6
- tying token embeddings : 84.3
- tying all weights : 84.4
GLUE Score는 모든 weight를 공유할 때 가장 높은 값을 가진다는 것을 확인할 수 있다. Discriminator는 입력으로 들어온 토큰만 학습하는 반면, generator는 출력 레이어에서 softmax를 통해 사전에 있는 모든 토큰에 대해서 밀도 있게 학습할 수 있다. ELECTRA는 결국 discriminator만을 취해서 사용하는데, 이때 generator와 임베딩을 공유해서 학습한 경우의 discriminator는 훨씬 효과적으로 학습했을 것이고 결과적으로 좋은 성능을 기록한 것으로 보인다.
그러나, 아래의 절에서도 설명하듯이 더 작은 generator를 가지는 것이 효율적인데, 이 경우에는 임베딩만 공유하기 때문에 이후 실험은 임베딩만 공유하는 방법을 사용한다고 한다.
Smaller Generators
위에서도 잠깐 언급했듯이 generator와 discriminator의 size가 같으면 MLM만을 이용해서 학습시키는 것에 비해 ELECTRA를 학습시키는 데 약 2배정도 많은 computing을 소요하기 때문에 해당 절에서는 작은 generator size를 사용하는 것을 제안한다.
이 때 size를 줄이는 것은 hyperparameter를 모두 유지하고 layer size를 줄이는 것을 말한다. 또한 본 논문에서는 학습 코퍼스에 등장하는 unigram의 분포를 기반으로 샘플링하는 unigram generator도 실험에서 이용했다. Figure 3의 왼쪽 그림에서 generator와 discriminator size에 대한 GLUE Score를 확인할 수 있다.
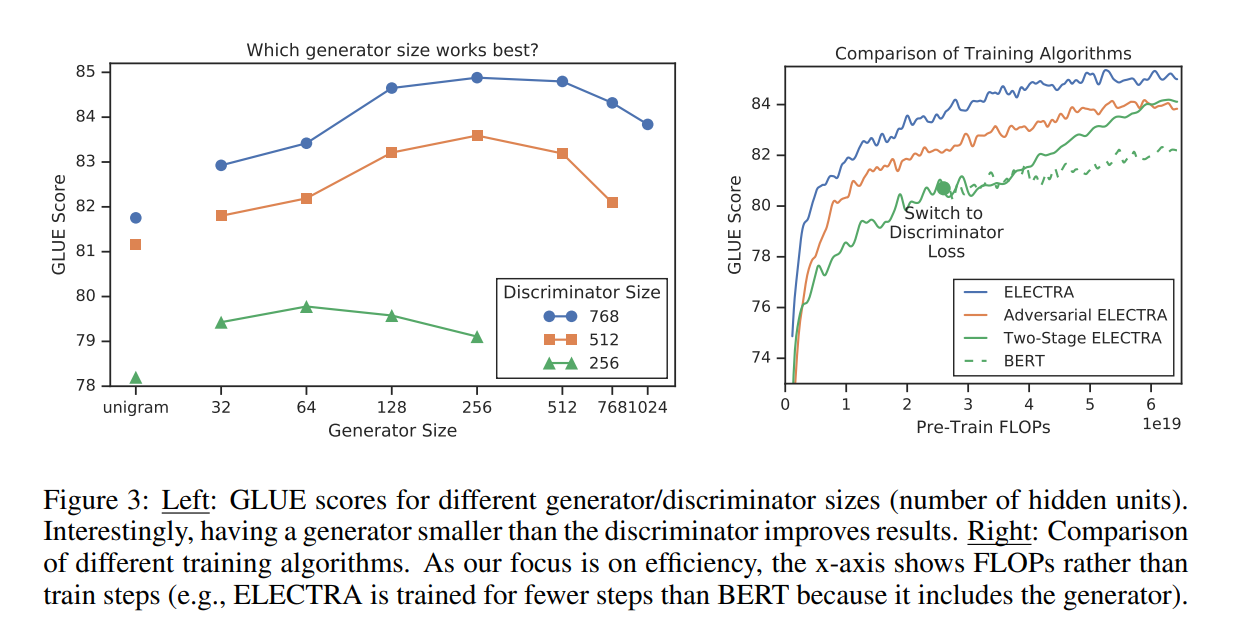
모두 동일한 스텝만큼을 학습했기 때문에 작은 모델은 똑같은 계산량, 시간만큼 학습하면 더 많은 스텝을 돌 것이고, 결과적으로 작은 모델 입장에서는 계산량 대비 성능을 손해본 셈이다. 그럼에도 불구하고 discriminator의 크기 대비 1/4 - 1/2 크기의 generator를 사용했을 때 가장 좋은 성능을 보인다.
Training Algorithms
이 파트에서는 ELECTRA를 더 개선시킬 수 있는 알고리즘을 소개한다. 기본적으로 ELECTRA는 generator와 discriminator를 jointly하게 학습하는데, 이 알고리즘에서는 대신 다음과 같은 두가지 절차를 이용해 실험했다.
- generator만 으로 n스텝동안 학습
- discriminagtor의 weights를 generator의 weights로 초기화하고, generator의 weights를 고정시킨 채 discriminator를 로 n스텝동안 학습
해당 실험의 결과는 Feature 3의 오른쪽 그림에 정리되어 있다. 위의 두 가지 절차를 이용한 ELECTRA는 generative에서 discriminative objective로 바꿨을 때 성능이 많이 향상되었음을 확인할 수 있으나, joint training보다 높은 성능을 보이지는 않는다. 또한 Adversarial 학습이 maximum likelihood 기반의 학습보다 성능이 낮다는 것도 알 수 있는데, 이런 현상의 원인은 다음과 같다.
- MLM 성능이 안 좋아서: MLM 성능은 58% 밖에 안됨. Maximum likelihood로 학습한 generator는 65%였음.
- 학습된 generator가 만드는 분포의 엔트로피가 낮아서: Softmax 분포는 하나의 토큰에 확률이 쏠려있고, 이러면 샘플링할 때 다양성이 많이 떨어짐.
3.3 Small Models
해당 작업의 목표는 pre-training의 효율을 향상시키는 것으로, 하나의 GPU로 빠르게 학습할 수 있는 소형 모델을 개발했다.

ELECTRA-Small은 크기를 고려했을 때, 더 많은 연산과 parameter를 사용하는 다른 방법들보다 높은 GLUE 점수를 가짐을 알 수 있다. BERT-Small 모델보다 5점 더 높으며, 훨씬 큰 GPT 모델보다도 좋은 성능을 낸다.
ELECTRA 모델은 general한 크기의 모델에서도 강점을 보이는데, ELECTRA-Base는 BERT-Base는 물론이고 BERT-Large(84.0 GLUE score)도 능가한다.
3.4 Large Models
다음은 Large 모델로 실험을 진행한 결과이다.
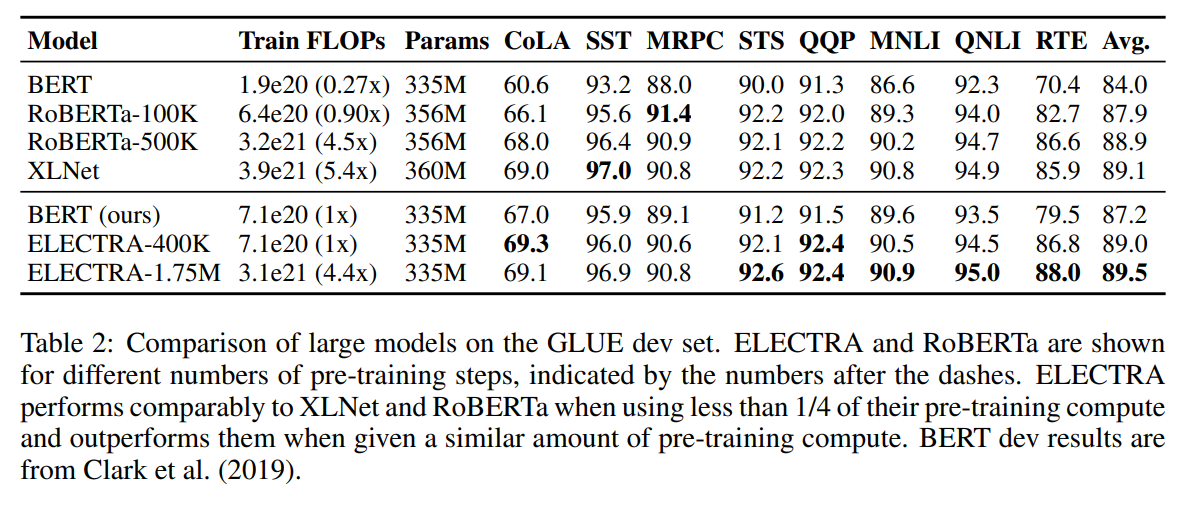
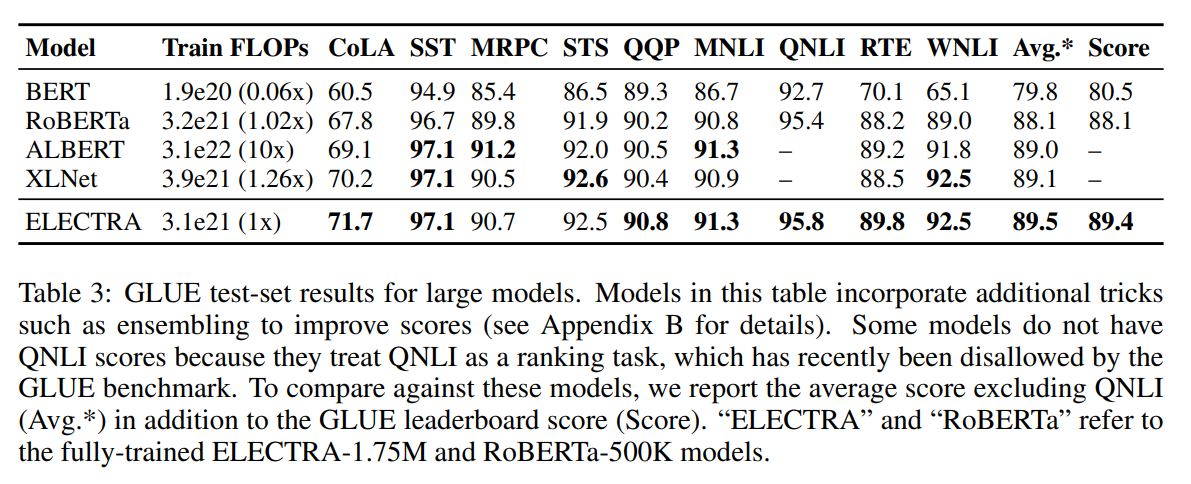
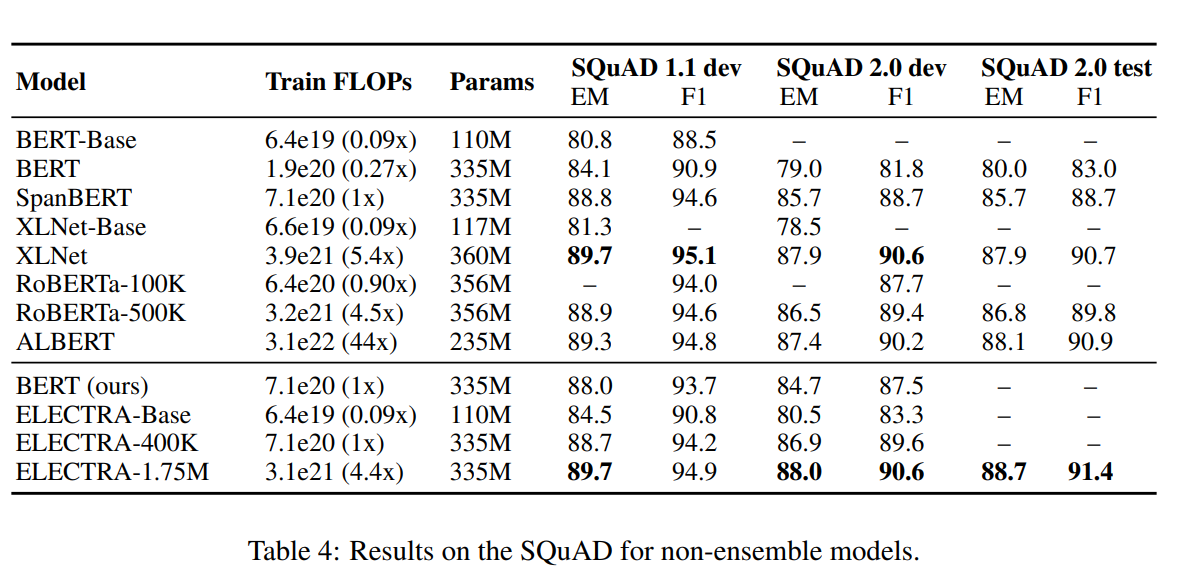
ELECTRA-400K는 RoBERTa(-500K)나 XLNet의 단 1/4의 계산량(FLOPs)만으로 이들과 필적할 만한 성능을 보인다. 그리고 더 많이 학습시킨 ELECTRA-1.75M은 이들을 뛰어넘는 성능을 보였고, 이 역시도 계산량은 두 모델보다 작다. GLUE뿐만 아니라, SQuAD에서도 마찬가지로 ELECTRA는 가장 좋은 성능을 보인다.
3.5 Efficiency Analysis
해당 절에서는 ELECTRA의 성능이 왜 좋은지 정확히 알기 위해 다음과 같은 세팅을 가지고 효율성 분석을 실시했다.
- ELECTRA 15% : ELECTRA의 구조를 유지하되, discriminator loss를 입력 토큰의 15%만으로 만들도록 세팅
- Replace MLM : Discriminator를 MLM 학습을 하되,
[MASK]로 치환하는 게 아니고 generator가 만든 토큰으로 치환 - All-Tokens MLM : Replace MLM처럼 하되, 일부(15%) 토큰만 치환하는 게 아니고 모든 토큰을 generator가 생성한 토큰으로 치환

해당 실험의 결과는 위의 Table 5와 같다. ELECTRA는 ELECTRA 15%와 Replace MLM 보다 훨씬 좋은 성능을 보였고 All-Tokens MLM은 그나마 ELECTRA에 가까운 성능을 보이며 BERT와 ELELCTRA의 성능 차이를 많이 줄였다. 전반적으로 결과를 봤을 때, ELECTRA가 학습 효율도 굉장히 좋고 [MASK] 토큰에 대한 pre-training과 fine-tuning 간의 불일치 문제도 상당히 완화시킨 것을 알 수 있다.
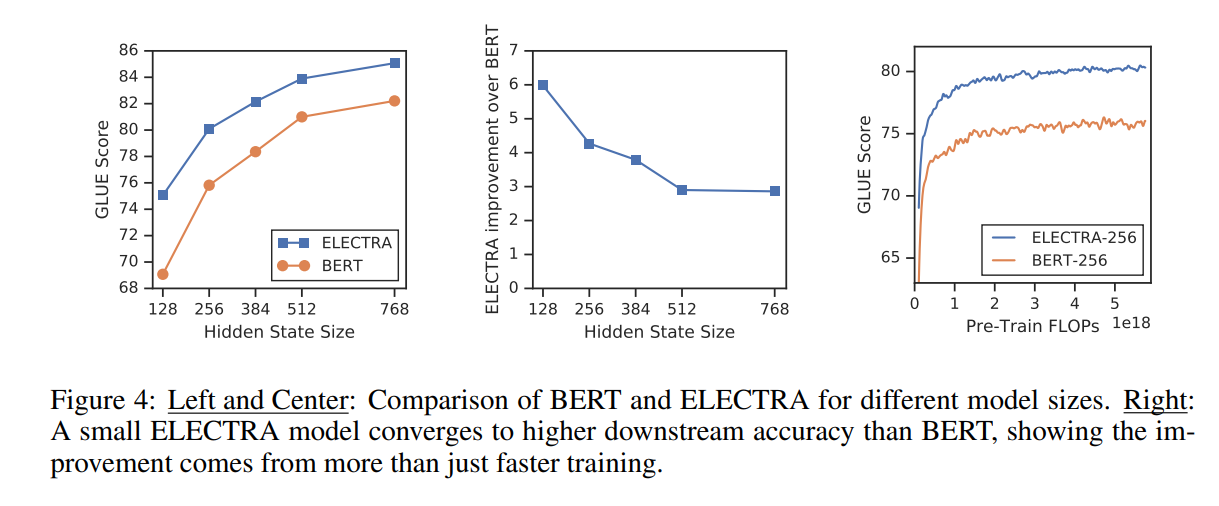
추가적으로 히든 레이어 크기에 따른 BERT와 ELECTRA의 성능 변화 실험도 있었는데, Figure 4에서 볼 수 있듯이 히든 레이어의 크기가 작아질수록 BERT와 ELECTRA의 성능 차이는 커진다는 사실을 알 수 있으며, BERT에 비해 ELECTRA는 모델이 작아도 매우 빠르게 수렴함을 알 수 있다.
앞서 소개한 많은 실험을 통해서 ELECTRA가 BERT보다 효율적으로(parameter-efficient) 학습한다고 결론지을 수 있다.
Conclusion
이 논문은 새로운 Self-supervised task로 Replaced Token Detection을 제안했으며, 핵심 아이디어는 작은 generator network가 만들어낸 고품질의 negative sample을 사용해 텍스트 인코더가 input 토큰을 구분할 수 있도록 학습시키는 것이었다. MLM과 비교했을 때, 본 논문에서 제안한 방법은 효율적으로 computing 하면서도 downstream task에서 성능도 좋았다.
