EfficientNet
EfficientNet은 Image classification 분야에서 월등한 성능으로 큰 이목을 받은 논문이라고 한다. 어떤 task를 통해 EfficientNet이 좋은 성능을 가질 수 있었는지 논문을 리뷰해보며 알아가보도록 하자.
Abstract
이 논문에서는 모델의 스케일링을 체계적으로 연구한다. 모델을 키워서 더 좋은 성능을 이끌어내는 방법은 크게 3가지가 존재한다.
- network의 depth를 깊게 만듦.
- channel의 width를 늘림.
- input image의 resolution(해상도)를 높임.
이 논문에서는 이러한 관찰사실에 근거하여 depth, width, resolution의 모든 차원을 균일하게 스케일링하는 새로운 스케일링 방법을 제안한다
더 나아가, neural architecture search를 이용해 새로운 베이스라인 네트워크를 설계하고 이를 확장해 EfficientNet이라는 모델을 소개한다. 이는 ConvNets보다 더 높은 정확성과 효율성을 달성하며, 특히 EfficientNet-B7은 ImageNet에서 84.3%로 SOTA 최고점을 달성함과 동시에 기존 ConvNet보다 8.4배 작고 6.1배 빠르다고 한다.
Introduction
ConvNets은 scaling을 통해 더 높은 정확도를 이끌어낼 수 있다. 예를 들어, ResNet-18에서 더 많은 layer를 사용해 ResNet-200으로 확장될 수 있으며, 최근에는 GPipe가 baseline 모델을 4배 더 크게 확장하여 84.3%로 ImageNet top-1 accuracy를 달성하기도 했다.
그러나, ConvNets를 어떻게 확장해야 하는지 그 과정이 잘 알려지지 않았다. 이전의 연구에서는 depth나 width, resolution 중 하나만 scaling하는 것이 일반적이었다. 2~3개의 차원을 임의로 확장할 수도 있지만, 수동으로 조정해야 해서 여전히 최적의 정확성과 효율성을 달성하기는 어려웠다.
따라서 본 논문에서는 ConvNet의 scaling up 과정을 연구해 더 나은 정확성과 효율성을 달성할 수 있는 ConvNet 확장방법을 탐색한다. 본 논문에서는 네트워크의 width,depth, resolution의 모든 차원을 균형있게 조정하는 것이 중요하다는 사실을 알려주며, 이는 놀랍게도 각각의 차원을 일정한 비율로 스케일링함으로써 달성할 수 있다고 말한다. 본 논문에서는 이러한 관찰을 바탕으로 단순하지만 효과적인 compound scaling method를 제안한다. 해당 방법에서는 고정적인 scaling coefficients를 이용해 width, depth, resolution을 균일하게 scaling한다. 예를 들어, 배의 computational resourses를 사용하고 싶다면 depth를 , width를 , image size를 배 증가시켜 small grid search를 통해 를 찾으면 된다고 한다.
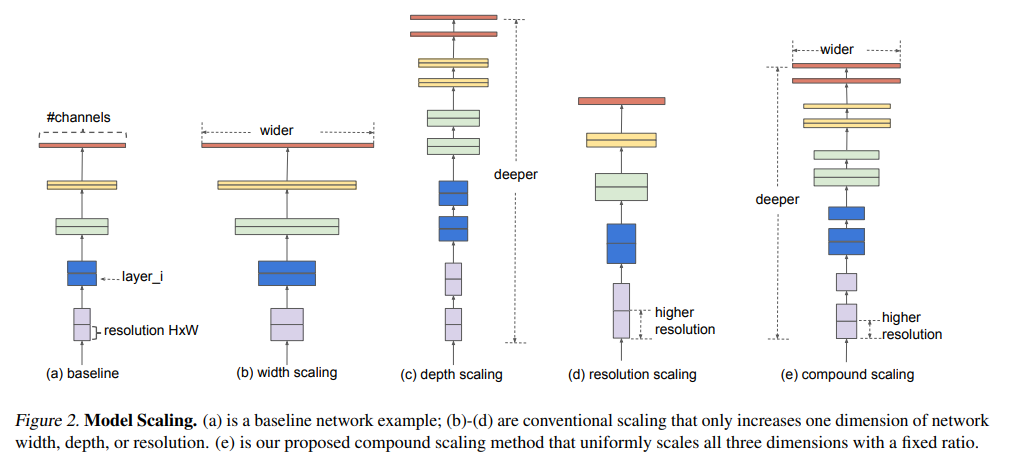
Figure 2에서 (e)가 compounding scaling method를 시각화한 것으로, depth와 width, resolution을 동시에 scaling하고 있음을 확인할 수 있다. 더 자세한 내용은 이후의 section에서 다시 다루도록 하겠다.
본 논문에서는 실험을 통해 스케일링 방법이 기존 MobileNets 및 ResNet에서 잘 작동함을 입증한다. 특히 모델 스케일링의 효과는 baseline network에 따라 크게 달라지기 때문에, 더 나아가 새로운 baseline network를 개발하기 위해 neural architecture search를 사용하고, 이를 확장해 EfficientNets라는 모델을 제시한다.
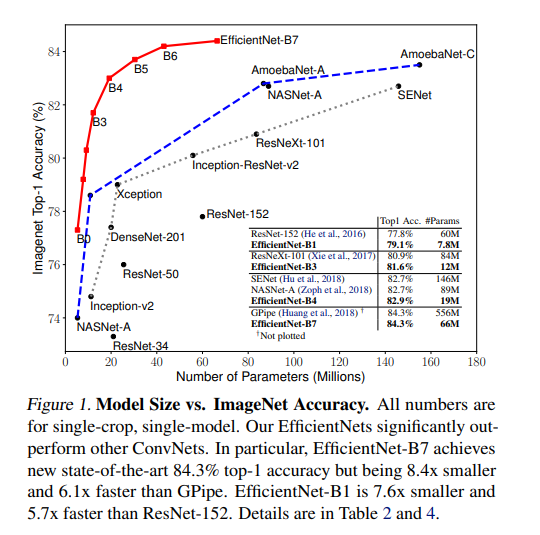
Figure 1을 통해 ImageNet의 성능에서 EfficientNet이 다른 ConvNets보다 크게 능가함을 알 수 있다. 특히, NAT의 EfficientNEt-B7은 기존 GPipe 정확도를 능가하지만, 8.4배 적은 parameter와 6.1배 빠른 속도로 작동한다. EfficientNet-B4는 ResNet-50과 비교하면 top-1 accuracy를 76.3%에서 83%까지 높인다. ImageNet 외에도 EfficientNet은 8개 중 5개 SOTA를 달성하며 기존 ConvNet보다 parameter를 최대 21배까지 줄인다고 한다.
Compound Model Scaling
해당 section에서는 scaling 문제를 formulate하고, 다양한 접근방식을 연구하며 새로운 scaling 방법을 제안한다.
Problem Formulation
baseline에서 입력값은 각 레이어 함수(f)를 거쳐서 최종 출력값을 생성하기 때문에 를 입력 tensor의 크기, 를 Conv layer라 하면 ConvNet은 다음과 같은 수식으로 정의할 수 있다.
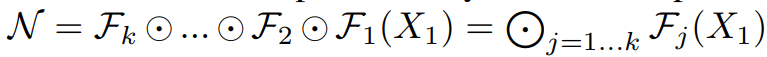
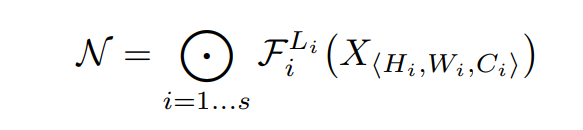
모델의 목적은 자원이 제한된 상태에서 모델의 정확도를 최대화하는 것이므로, 이 문제는 다음과 같이 정리할 수 있다.
이 때 은 width, depth, resolution의 스케일링 계수이다.
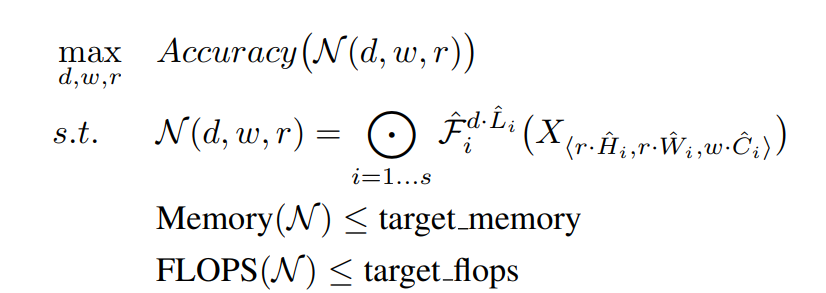
Compounding Scaling
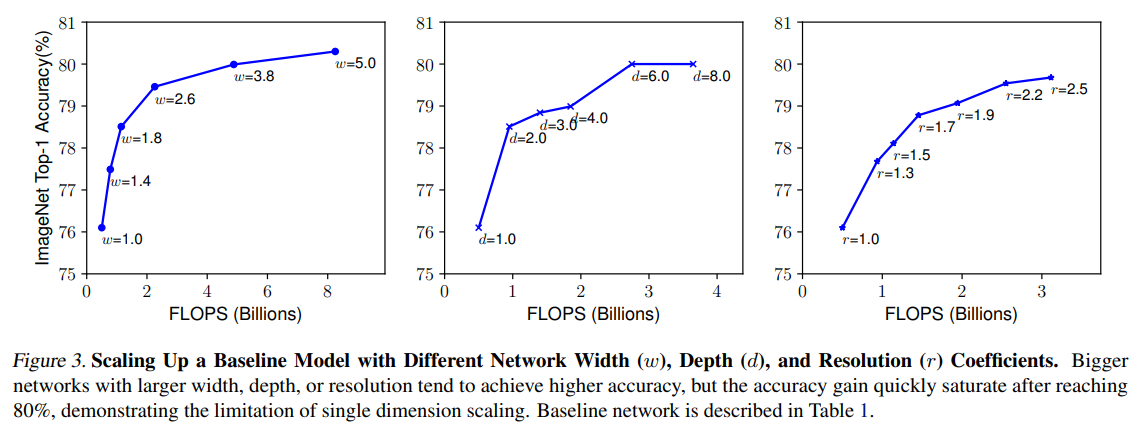
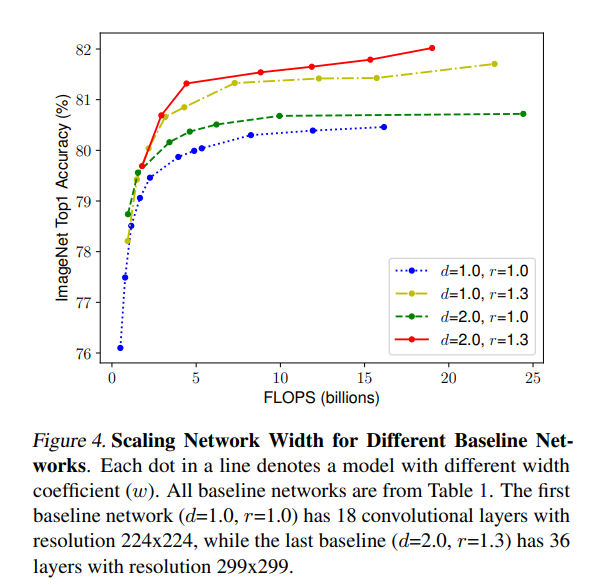
이 논문에서는 새로운 스케일링 방법인 compounding scaling을 소개하는데, Figure 3과 Figure 4 의 실험을 통해 알아낸 사실은 다음과 같다.
- network width, depth 또는 resolution의 모든 차원을 확대하면 정확도가 향상되지만 모델이 클수록 정확도 향상은 줄어든다.
- 정확성과 효율성을 높이기 위해서는 ConvNet 스케일링 중 network width, depth, resolution의 모든 차원을 균형 있게 조정하는 것이 중요하다.
이와 같은 사실을 기반으로, 이 논문에서는 다음과 같이 compound coefficient를 이용하여 network의 depth, width, resolution을 균등하게 조절하는 compound scaling method를 제안한다.
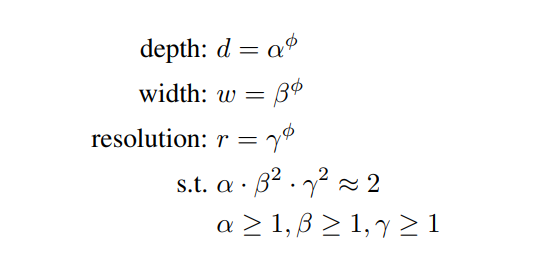
는 resourses를 얼마나 사용할지에 대해 사용자가 정하는 계수이며, 는 small grid research 방법으로 찾게 될 변수들이다. 이 때 로 설정되었기 때문에 총 FLOPS는 약 에 비례한다.
Efficient Architecture
이 절에서는 EfficientNet이라는 mobile-size baseline 모델을 개발한다. MnasNet에 기반한 baseline network를 사용하며 구체적인 모양은 다음과 같다.
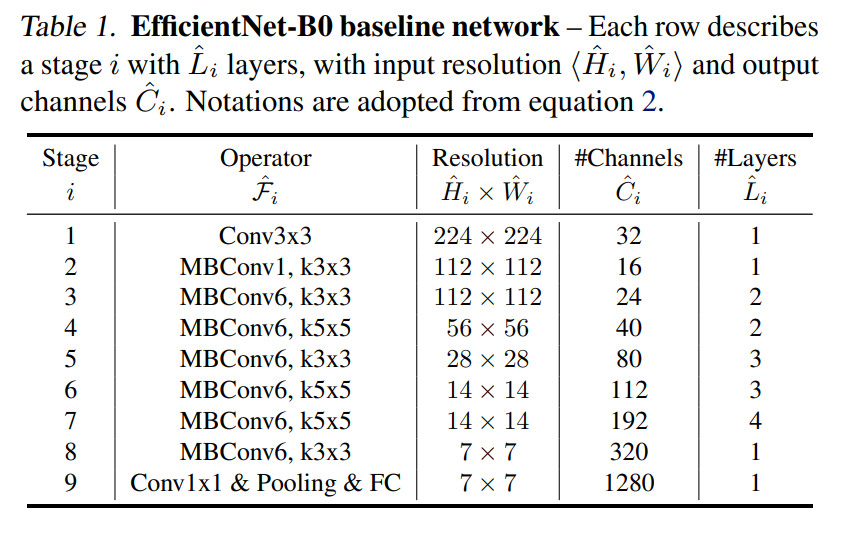
이 baseline network에 기반해서 시작한다.
- STEP 1 : 로 고정하고, 에 대해 grid search를 수행한다. 찾은 값은 로 이다.
- STEP 2 : 를 고정하고 를 변화시키면서 전체적인 크기를 키운다
를 직접 갖고 큰 모델에 실험해서 더 좋은 결과를 얻을 수도 있지만 큰 모델에 대해서는 그 실험에 들어가는 자원이 너무 많다. 그래서 작은 baseline network에 대해서 먼저 좋은 를 찾고(STEP 1) 그 다음에 전체적인 크기를 키운다(STEP 2).
Experiments
해당 절에서는 다양한 실험을 통해 ConvNets 및 EfficientNets에 대한 확장 방법을 평가한다.
Scaling Up MobileNets and ResNets
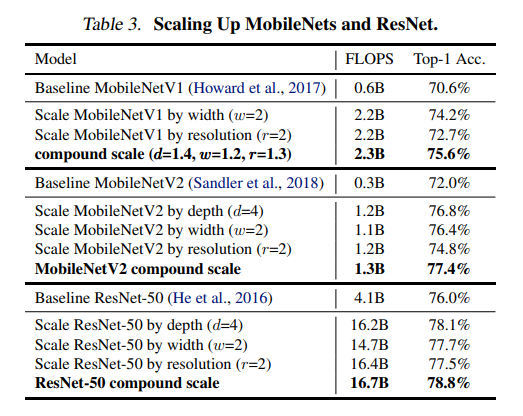
우선 MobileNets와 ResNet에 scaling method를 적용했다. Table 3는 다양한 방법으로 ImageNet을 스케일링한 결과이다. 다른 single-dimension scaling methods와 비교했을 때, compound scaling method는 모든 모델에서 정확도를 개선하여 일반적인 기존 ConvNet보다 EfficientNet이 우수함을 보여준다.
ImageNet Results for EfficientNet
Table 2는 동일한 baseline EfficientNet-B0에서 스케일링된 모든 EfficientNEt model의 성능을 보여준다. EfficientNet 모델은 유사한 정확도를 가진 ConvNets보다 훨씬 적은 파라미터와 FLOPS를 사용하는데, 특히 EfficientNet-B7은 66M parameters와 37B FLOPS로 84.3%의 top-1 accuracy를 달성하며 이전 최고의 GPipe보다 정확도는 높지만 8.4배나 작다.
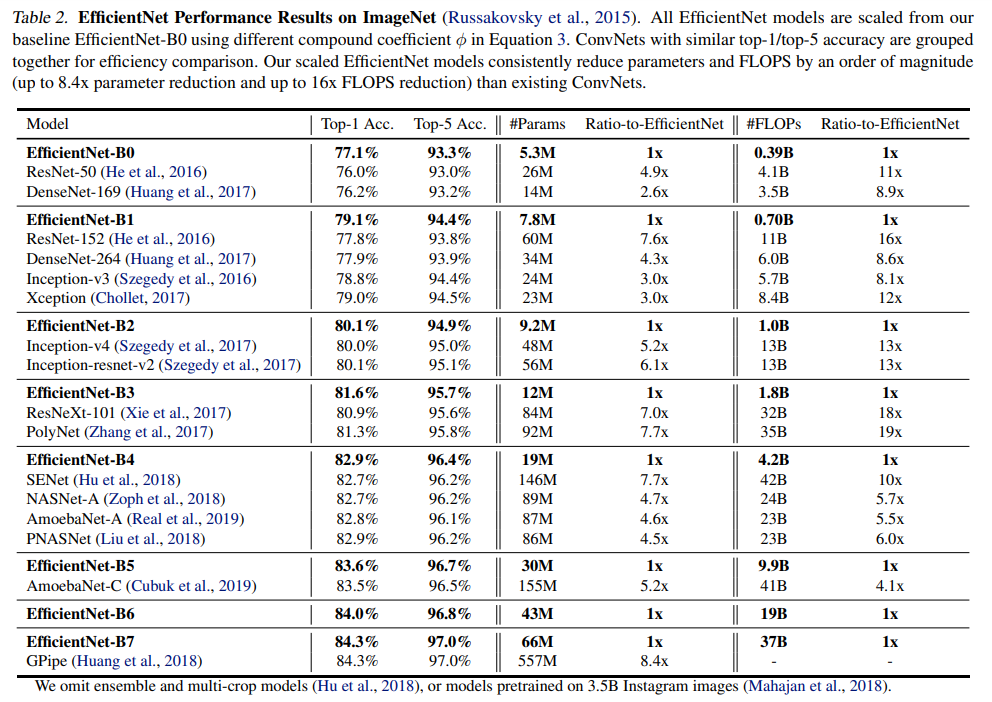
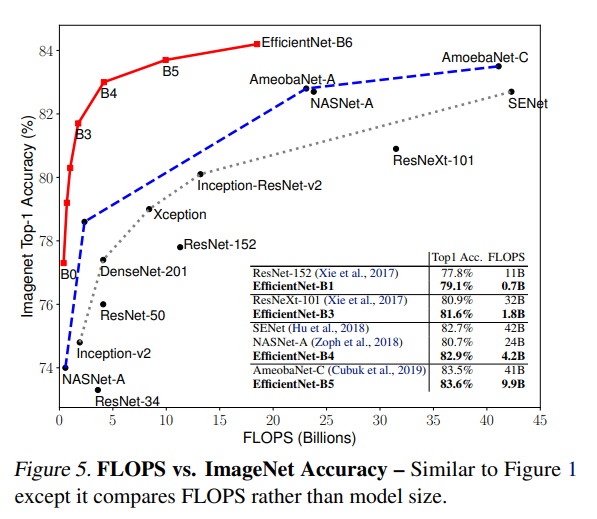
Figure 1과 Figure 5는 대표적인 ConvNet에 대한 매개변수 정확도 및 FLOPS 정확도 곡선을 보여준다. 여기에서 스케일링된 EfficientNet 모델은 다른 ConvNet보다 훨씬 적은 매개변수 및 FLOPS로 더 나은 접근성을 달성하며, 특히 EfficientNet 모델은 사이즈가 작을 뿐만 아니라 계산 비용도 저렴하다. 예를 들어, EfficientNet-B3는 18배 적은 FLOPS를 사용하여 ResNeXt- 101보다 높은 정확도를 달성한다.
또한 실제 CPU 상에서의 몇 가지 CovNet에 대한 latency 측정 결과를 Table 4에서 확인할 수 있다. NAT의 EfficientNet-B1은 ResNet-152보다 5.7배 더 빠르게 실행되는 반면, EfficientNet-B7은 GPipe보다 약 6.1배 더 빠르게 실행되므로 실제 하드웨어에서 EfficientNets가 실제로 더 빠르다는 것을 알 수 있다.

Transfer Learnig Results for EfficeintNet
해당 section에서는 자주 사용되는 학습 데이터셋에 대해 EfficientNet을 평가해 Table 5에 정리했다.
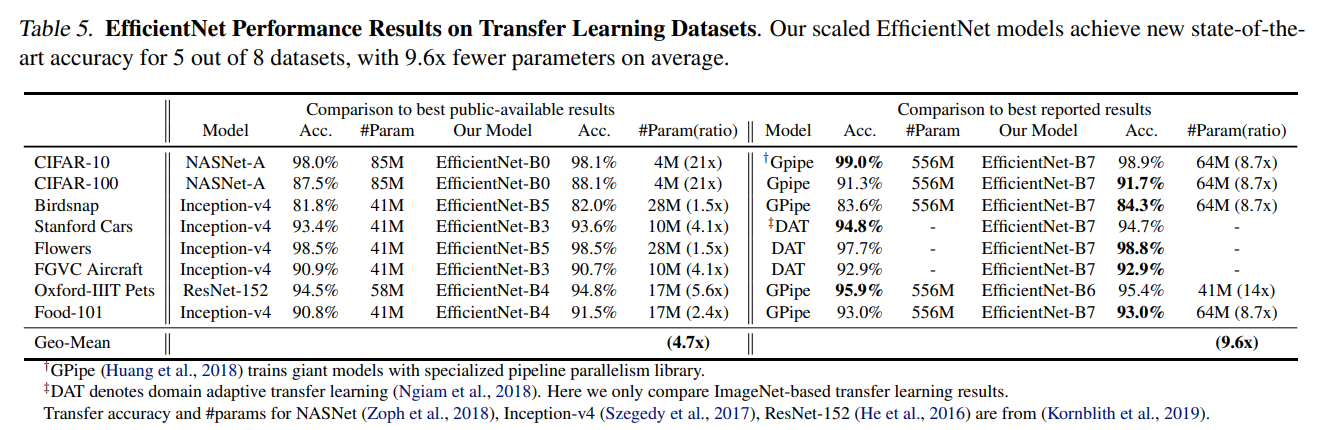
- NASNet-A 및 Inception-v4와 비교했을 때, EfficientNet은 평균 4.7배(최대 21배) parameter 감소로 더 나은 정확도를 달성했다.
- DAT과 GPipe 등의 SOTA 모델과 비교했을 때, EfficientNet 모델은 8개 중 5개 데이터셋에서 정확성을 여전히 능가하지만, parameter를 9.6배나 적게 사용한다.
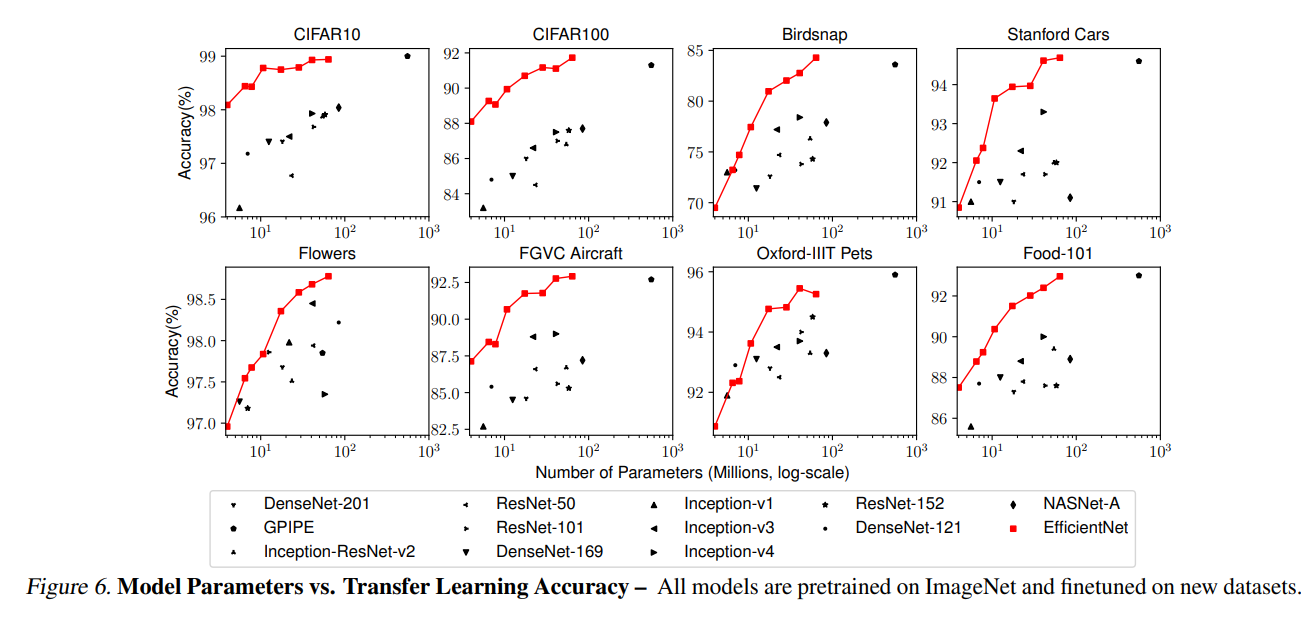
Figure 6에서는 모델에 따른 accuracy-parameters curve를 확인할 수 있는데, EfficientNets는 ResNet, DenseNet, Inception, NASNet 등의 기존 모델들보다 훨씬 적은 수의 파라미터로 더 나은 정확도를 달성함을 알 수 있다.
Conclusion
이 논문에서는 ConvNet 스케일링을 체계적으로 연구하여 네트워크의 width, depth, resoltion을 조절하는 compound scaling method를 제안했다. 이 방법을 통해 EfficientNet model이 5개의 데이터셋에서 적은 파라미터와 FLOPS로 SOTA를 달성하며 매우 효과적으로 scaling up 할 수 있기 때문에 매우 효율성 높고 지금까지도 유명한 논문이라고 생각된다.
