- 서울시 CCTV 현황 분석 데이터 읽기 <- here
- [번외1] Pandas 기초 - series, dataframe
- CCTV 데이터와 인구현황 데이터 훑어보기
- Pandas 데이터 합치기 - merge
- [번외2] matplotlib 기초
- CCTV 데이터 그래프로 표현하기
- 데이터 경향을 그려보자
- 경향에서 벗어난 데이터 강조하기
<전체 흐름에 집중하자>!!
1. 서울시 CCTV 현황 분석 데이터 읽기
[데이터 출처] CCTV 현황 분석 데이터, 인구 통계 데이터 - 서울 열린데이터 광장
https://data.seoul.go.kr/dataList/OA-2734/F/1/datasetView.do
https://data.seoul.go.kr/dataList/10718/S/2/datasetView.do
pandas를 불러오는 것으로 시작한다. csv파일은 read_csv 로 불러들이고, 파일명을 잘 입력해준다.
.. <-현재 폴더의 상위폴더
한글은 깨질 수도 있으므로 encoding 설정을 미리 해주면 좋다.
*모든 기능은 외우기보다는 설명을 읽으며 필요한 부분을 추가해가는 방식으로 사용하는 것이 좋다. shift + enter를 눌러 사용법과 예시를 참고하자
CCTV 현황분석 데이터를 불러와 CCTV_Seoul에 저장해 사용한다.
import pandas as pdCCTV_Seoul = pd.read_csv("../data/01. Seoul_CCTV.csv", encoding="utf-8") head(), tail()
상/하단 n개 데이터만 가져오기. 기본값은 5이다.
CCTV_Seoul.head()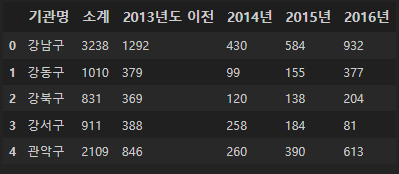
CCTV_Seoul.tail() 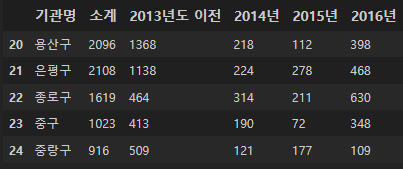
tail로 전체 데이터의 숫자를 파악할 수 있다. 우리는 25개의 기관명 데이터가 있다.
컬럼명은 리스트 형태로 반환할 수 있다.
CCTV_Seoul.columns-> Index(['기관명', '소계', '2013년도 이전', '2014년', '2015년', '2016년'], dtype='object')
CCTV_Seoul.columns[0]-> '기관명'
rename으로 컬럼명을 바꿀 수 있다.
구의 명확한 구분을 위해 컬럼명'기관명'을 '구분'으로 바꾸어주었다.
*inplace옵션을 true로 해주어야 바뀐 원본으로 저장된다 !!
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]: "구별"}, inplace=True)이제 서울시 인구 통계 데이터를 가져와 pop_Seoul이라는 변수에 저장해 주자.
pop_Seoul = pd.read_excel("../data/01. Seoul_Population.xls")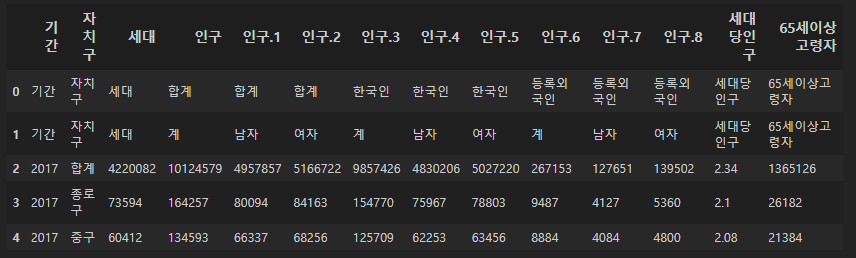
뭔가 이상하다 <-csv 원본 파일을 엑셀에서 보면서 분석하자
원본을 살펴보면, 상단의 셀들을 조정하고 싶다.
상위 2개의 행을 날리고,,, 남자, 여자 등도 날리고, '계'라는 종합적인 정보만 필요하다.
수정하기!
pop_Seoul = pd.read_excel(
"../data/01. Seoul_Population.xls", header=2, usecols="B, D, G, J, N"
)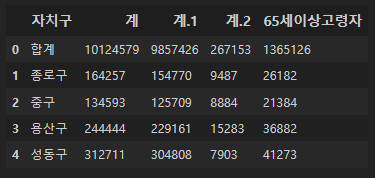
계1, 2,.. <- 정확하게 바꿔주자
pop_Seoul.rename(
columns={
pop_Seoul.columns[0]: '구별',
pop_Seoul.columns[1]: '인구수',
pop_Seoul.columns[2]: '한국인',
pop_Seoul.columns[3]: '외국인',
pop_Seoul.columns[4]: '고령자'
},
inplace=True
)
pop_Seoul.head()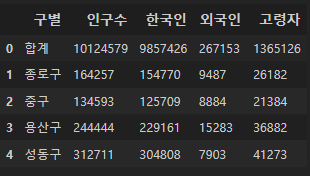
이렇게 분석하기 위해 필요한 정보들 위주로 데이터를 조정하였다.
[번외1] Pandas 기초
파이썬에서 R만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈이라 불리운다.
pandas는 통상 pd, numpy는 통상 np로 import한다.
import pandas as pd
import numpy as npSeries
pd.Series([1, 2, 3, 4])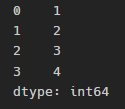
왼쪽은 0부터 인덱스, 오른쪽의 1,2,3,4는 우리가 넣어준 값이다.
날짜데이터
6일간의 날짜를 출력해보자.
pd.date_range("20210101", periods=6)
데이터프레임
pd.DataFrame()
데이터, 인덱스, 컬럼 세 가지가 필요하다.
넘파이를 이용하여, 표준정규분포에서 샘플링한 난수를 생성하자
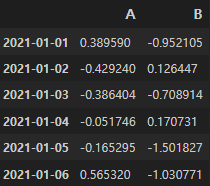
data = np.random.randn(6, 4)dates = pd.date_range("20210101", periods=6)
dates
df = pd.DataFrame(data, index=dates, columns=["A", "B", "C", "D"])
df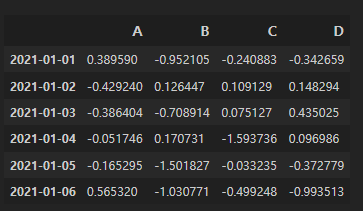
난수로 발생시킨 값들을 데이터프레임에 넣어 사용하였다.
우리가 6일까지 설정한 날짜를 인덱스에, 컬럼명은 A,B,C,D라 하였다.
info() , describe()
info()는 데이터프레임의 기본 정보를 확인하는 메서드이다.
# df.info()
df.info()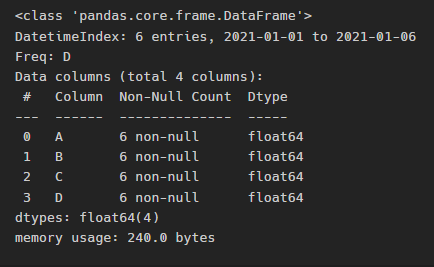
1월 1일부터 1월 6일까지 의 데이터고... 6개가 있으며 컬럼은 ABCD 각 컬럼마다 non-null (빈값이 없다)
데이터타입은 이렇다..이런정보.
describe()는 데이터프레임의 기술 통계 정보를 확인한다.
df.describe() 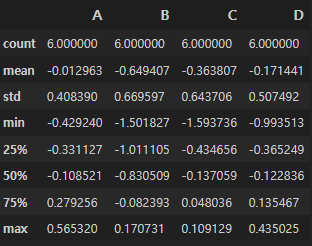
컬럼별로 개수, 평균, 표준편차, 최솟값 등에 대한 정보를 보여준다.
데이터 정렬
컬럼 B를 기준으로, 오름차순 정렬:
df.sort_values(by="B") 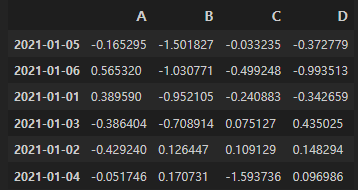
데이터 선택하기
간단하다. A컬럼 선택<- df["A"]
두 개 이상의 컬럼을 선택할시에는 리스트 안에 담아서 실행해야 한다.
df[["A", "B"]]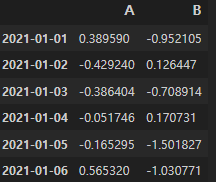
offest index
-> [n:m] 번호라면, n부터 m-1까지!
인덱스나 컬럼의 "이름"으로 슬라이스하는 경우는 n부터 m까지(끝까지 다 포함)
df[0:3]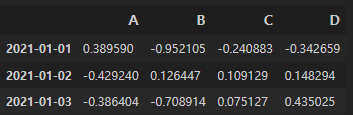
loc, iloc
loc <- location
컬럼의 위치를 명시하여 원하는 정보를 선택하여 볼 수 있다.
인덱스는 처음부터 끝까지, 컬럼은 A, B만 가져와라:
df.loc[:, ["A", "B"]]인덱스 번호 대신 값으로 표시 가능:
df.loc["20210102":"20210104", ["A", "D"]]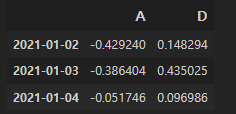
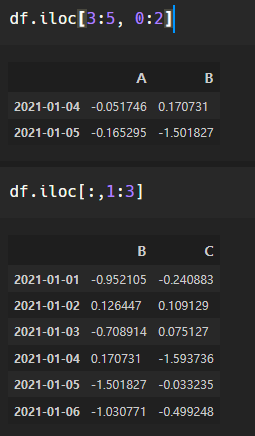
iloc <- integer location의 약자로, 컴퓨터가 인식하는 인덱스 값으로 선택하는 기능이다.
우리는 보이지 않지만 컴퓨터는 인덱스를 0부터 부여하여 인식해주고 있다.
C컬럼의 네번째값:
df.iloc[3,2] -> -1.5937357159111427
조건으로 필터링하기
앗 여기서 끊고 rerun해서. 난수 데이터의 정보가 바뀌었다.
...여기선 코드의 기능과 기본기가 중요한 거니까.
그냥 이어간다.
A 컬럼에서 0보다 큰 숫자(양수)만 선택 :
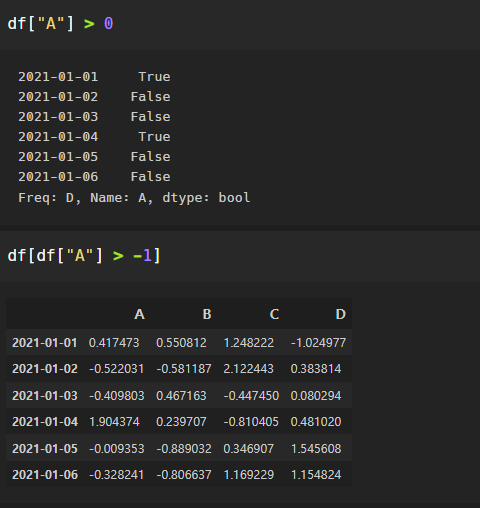
NaN <- 데이터가없다. Not a number.
df[df > 0]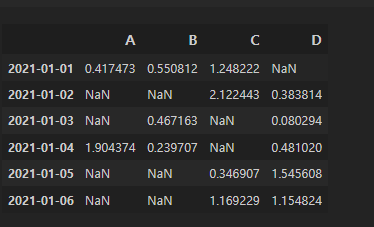
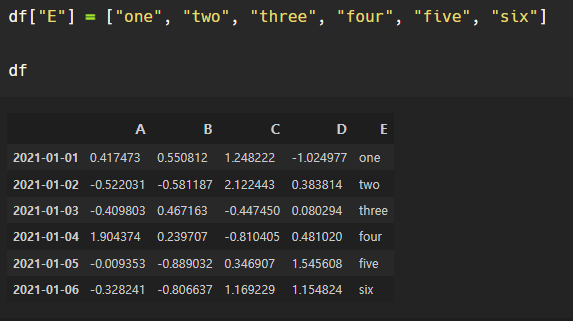
컬럼 추가
기존컬럼이 없으면 추가, 있으면 수정 !!
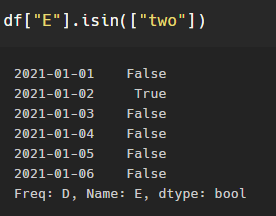
isin() 메서드 - 특정 요소가 있는지 확인 -> boolean 타입으로 반환
특정 컬럼 제거
del과 drop을 사용할 수 있다.
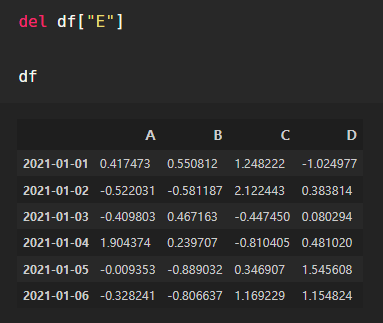
삭제되었다.
drop이용:
drop을 이용해 D컬럼 모두를 지운다면 ?
df.drop(["D"], axis=1)axis는 축이다. default는 0으로 되어있다.
axis=0은 가로, axis=1은 세로이다
행(인덱스 번호)을 제거해주고 싶으면 axis=0이여야 하고,
열을 지워주려면 axis=1이여야 한다.
apply()
함수 기능을 적용해주는 메서드.
a컬럼의 전체 합계를 알고싶다-> 원하는 기능을 문자형태로 apply안에 넣어준다.
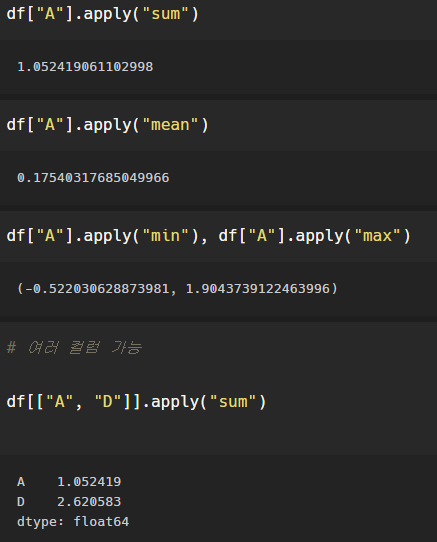
함수를 만들어서 적용할 수도 있다.
0보다 큰지 작은지를 기준으로 양/음수를 구분하는 함수 만들기:
def plusminus(num):
return "plus" if num > 0 else "minus"df["A"].apply(plusminus)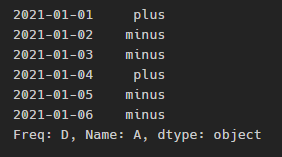
lambda함수를 써서 바로 적용할 수도 있다:
df["A"].apply(lambda num: "plus" if num >0 else "minus")똑같은 결과이다~
정말정말정말 오랜만에 데이터분석을 한다...ㅠㅠㅠㅠㅠ
오랜만에 기초부터 차근차근 하나씩 공부하니까 재밌다.
