- 서울시 CCTV 현황 분석 데이터 읽기
- [번외1] Pandas 기초 - series, dataframe
- CCTV 데이터와 인구현황 데이터 훑어보기 <- here
- 데이터 합치기 - merge
- [번외2] matplotlib 기초
- CCTV 데이터 그래프로 표현하기
- 데이터 경향을 그려보자
- 경향에서 벗어난 데이터 강조하기
2. CCTV 데이터와 인구현황 데이터 훑어보기
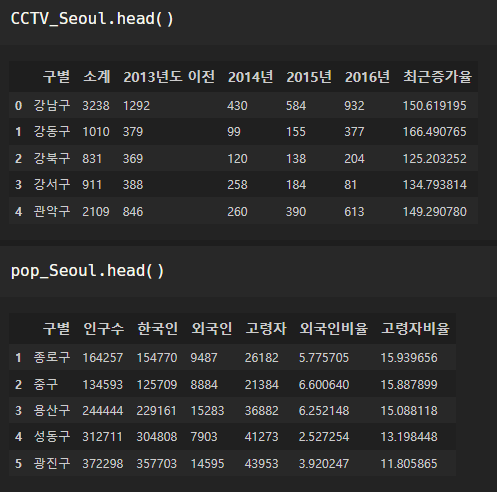
CCTV 데이터 훑어보기
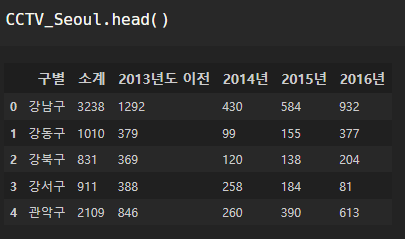
head, tail로 대략 훑어보기:
정렬하기 <- sort_values 함수 사용
"소계"를 기준으로 오름차순/내림차순 정렬하면 CCTV가 많이 설치된 구, 적게 설치된 구를 알 수 있다.
CCTV_Seoul.sort_values(by="소계", ascending=True).head(5)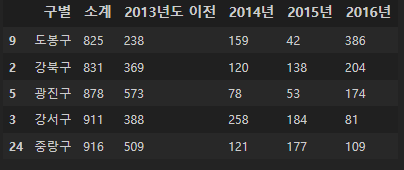
CCTV_Seoul.sort_values(by="소계", ascending=False).head(5)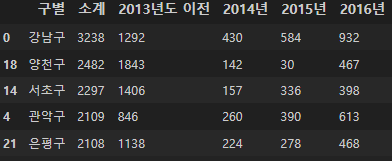
CCTV 증가율 컬럼 추가
CCTV_Seoul["최근증가율"] = (
(CCTV_Seoul["2016년"] + CCTV_Seoul["2015년"] + CCTV_Seoul["2014년"]) /
CCTV_Seoul["2013년도 이전"] * 100
)
CCTV_Seoul.sort_values(by="최근증가율", ascending=False).head()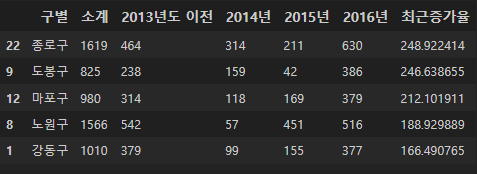
인구현황 데이터 훑어보기
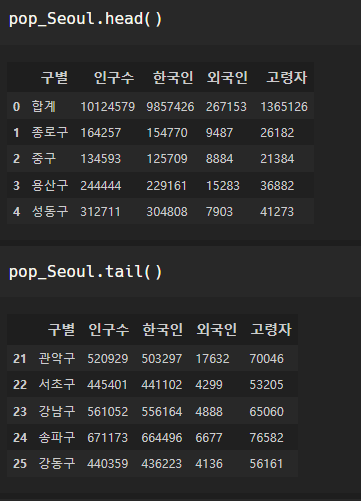
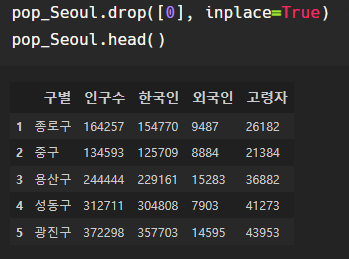
인덱스 0부터 25까지 26개의 행이 있다. 서울시의 자치구는 25갠데?
-> 맨 위의 합계 라는 행을 삭제해주자.
drop을 이용하였다.
unique 메서드
중복X, 한 번이라도 등장한 고유의 데이터 모든 값을 출력해준다.
pop_Seoul["구별"].unique()
len(pop_Seoul["구별"].unique())-> 25
25개의 구가 있다.
외국인비율, 고령자비율 컬럼 추가
외국인 컬럼, 고령자 컬럼, 전체 인구수를 이용하여
외국인 비율, 고령자 비율 컬럼을 추가해줄 수 있다.
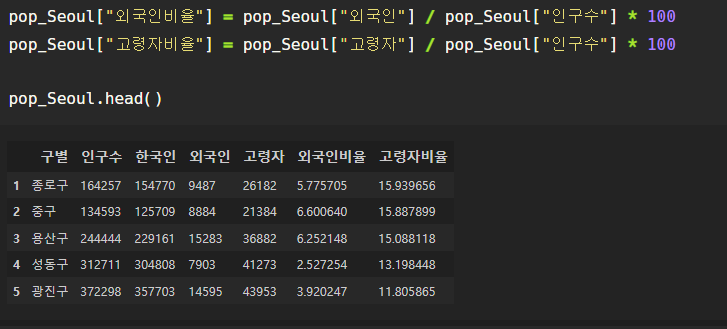
정렬을 이용하여 다양한 탐색을 할 수 있다.
외국인 비율이 높은 구:
pop_Seoul.sort_values(['외국인비율'], ascending=False).head()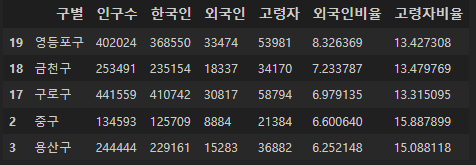
고령자 비율이 높은 구:
pop_Seoul.sort_values(['고령자비율'], ascending=False).head()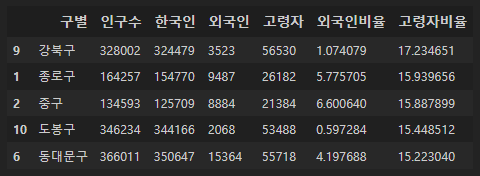
3. 데이터 합치기 - merge
본격적으로 들어가기 전에, 가벼운 번외로
pandas에서 데이터 프레임을 병합하는 방법에 대한 예시이다.
merge()를 사용하여, 두 데이터 기준 1데이터 / 2데이터 / 교집합 부분 / 합집합 등 다양한 출력 방식을 연습하였다.
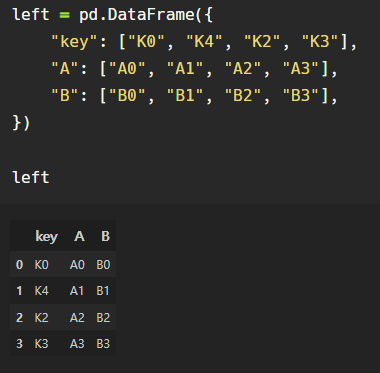
예시 데이터 만들기:
데이터프레임 만드는 건 딕셔너리 형태 안의 리스트 형태로 할 수도, 리스트 안의 딕셔너리 형태로 할 수도 있다.
left 데이터는 전자, right 데이터는 후자의 방식으로 만들었다.
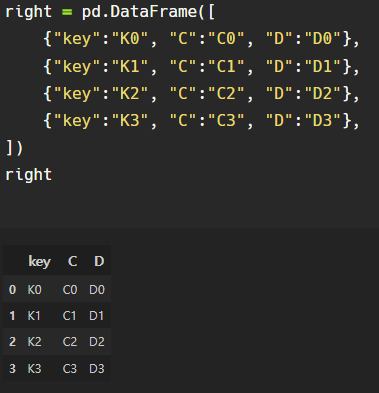
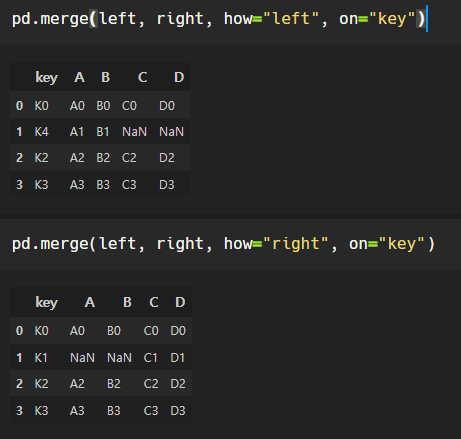
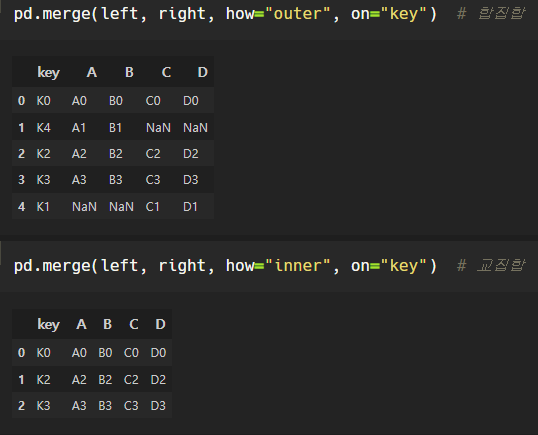
pd.merge()
두 데이터프레임에서 컬럼이나 인덱스를 기준으로 잡고 병합하는 방법으로,
기준이 되는 컬럼이나 인덱스를 키값이라고 한다.
필수 조건: 기준이 되는 키값은 두 데이터프레임에 모두 포함되어 있어야 한다!
how="방식" , on="기준"
how의 default 값은 inner이다.
이제 다시 프로젝트로 돌아와서,
CCTV 데이터와 인구 데이터를 병합하자!!
우리 주제는
인구 대비 상대적으로 CCTV가 적은 구를 찾는 것이다.
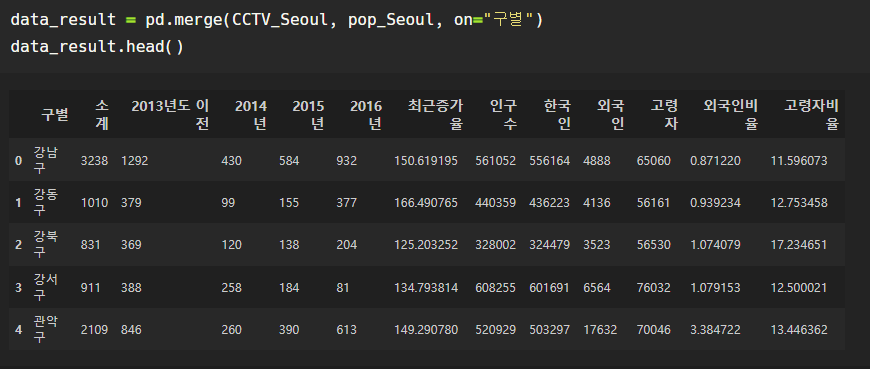
두 데이터 병합
두 데이터를 가지고 한다.
기준값은 "구별"이다.
깔끔하게 만들기 위해,
연도별 데이터 컬럼은 삭제하자.
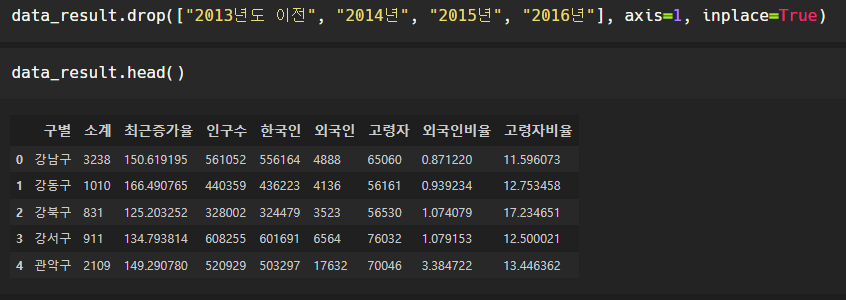
맨 왼쪽에 인덱스 번호 0, 1, 2,...로 행이 구별되어 있다.
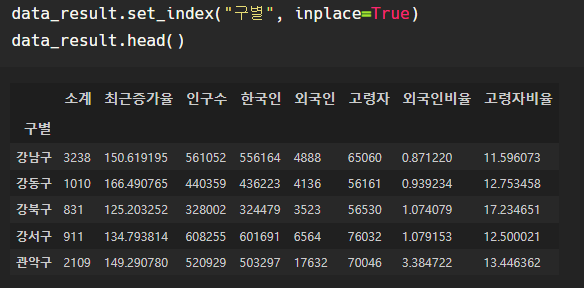
보기 쉽게 "구별"을 인덱스화하자.
인덱스 변경은 set_index()로 한다.
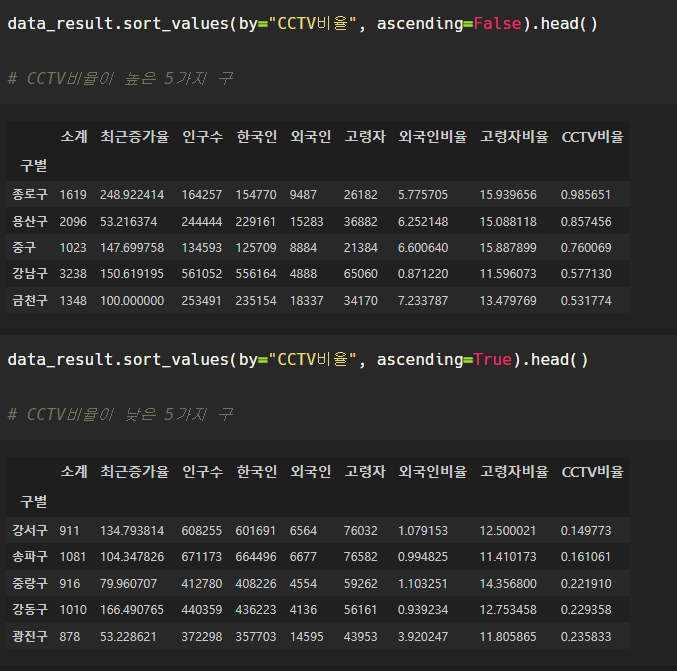
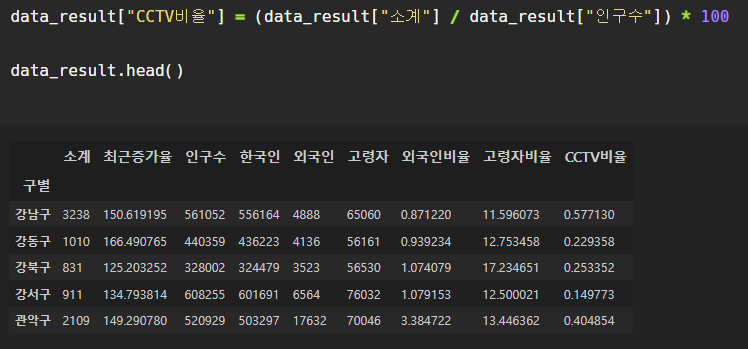
CCTV 비율 컬럼 추가
CCTV 개수와, 인구수를 이용하여 CCTV 비율 컬럼을 만들 수 있다.
정렬을 통해
CCTV 비율이 높은 구/낮은 구를 알 수 있다.