- 서울시 CCTV 현황 분석 데이터 읽기
- [번외1] Pandas 기초 - series, dataframe
- CCTV 데이터와 인구현황 데이터 훑어보기
- 데이터 합치기 - merge
- [번외2] matplotlib 기초
- CCTV 데이터 그래프로 표현하기
- 데이터 경향을 그려보자 <- here
- 경향에서 벗어난 데이터 강조하기
5. 데이터 경향을 그려보자
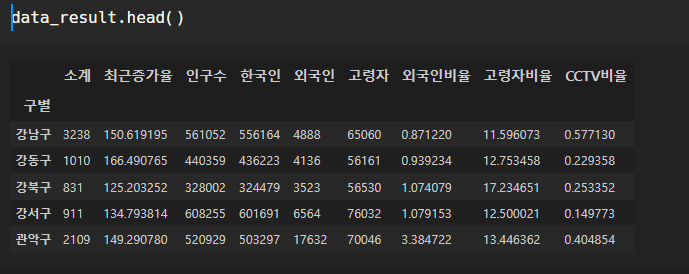
지난 시간에 이어서, 이 데이터를 가지고
데이터의 경향을 표시하는 방법을 알아볼 것이다.
인구수와 소계 컬럼을 이용해, 우선 scatter plot을 그렸다.
def drawGraph():
plt.figure(figsize=(14, 10))
plt.scatter(data_result["인구수"], data_result["소계"], s=50)
plt.xlabel("인구수")
plt.ylabel("소계")
plt.grid()
plt.show()
drawGraph()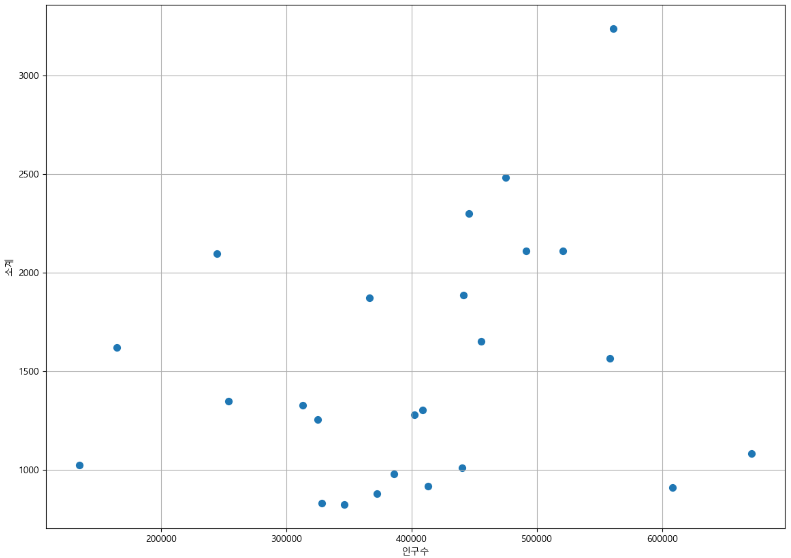
인구수와 CCTV개수가 비례하는 경향인 건 알겠는데...
경향선을 추가해주면 전체적인 경향을 한눈에 볼 수 있고,
차이가 많이 나는 값들도 알 수 있을 것이다.
-> 선형회귀선을 추가한다.
Numpy를 이용한 1차 직선 만들기
- np.polyfit() : 직선을 구성하기 위한 계수를 계산
- np.poly1d() : polyfit으로 찾은 계수를 파이썬에서 사용할 수 있는 함수로 만들어주는 기능
import numpy as np
fpl = np.polyfit(data_result["인구수"], data_result["소계"], 1)
fpl-> array([1.11155868e-03, 1.06515745e+03])
여기서 1 <- 1차식으로 표현하겠다
두 변수(인구수, 소계)에 대한 직선의 계수값을 구하고..
f1 = np.poly1d(fpl)
f1-> poly1d([1.11155868e-03, 1.06515745e+03])
계수를 집어넣어서 f1이라는 함수를 만들어주었다.
(f1은 직선이다. 인구수, 소계 에 대한 데이터를 표현하는 함수)
f1(400000)-> 1509.780925241333
이렇게 인구 40만에 적당한 cctv 개수를 구할 수 있다.
경향선을 그리기 위한 x 데이터를 생성해줄 건데,
np.linspace(a, b, n) : a부터 b까지 n개의 등간격 데이터 생성
우리가 그린 scatter plot 크기에 맞춰 설정해주었다.
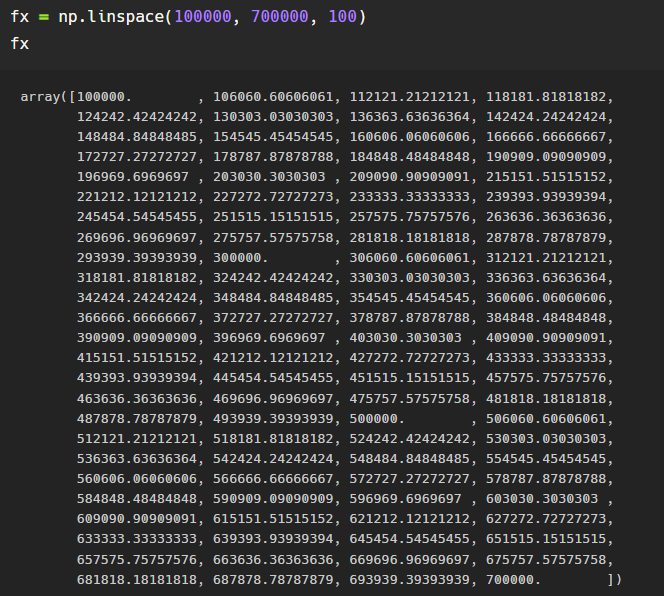
linspace로 범위와 개수 설정해주고
fx에 넣어주었다.
이제 아까 그린 scatter 그래프에 plot을 추가하기만 하면 된다.
plot의 데이터로 fx와 f1이 들어간다.
def drawGraph():
plt.figure(figsize=(14, 10))
plt.scatter(data_result["인구수"], data_result["소계"], s=50)
plt.plot(fx, f1(fx), ls="dashed", lw=3, color="g") # lw는 굵기임
plt.xlabel("인구수")
plt.ylabel("소계")
plt.grid()
plt.show()
drawGraph()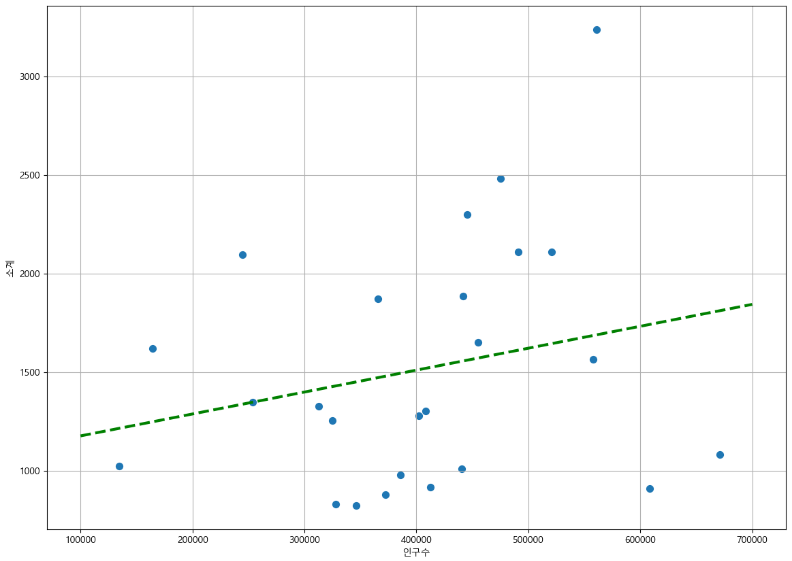
-> 인구수 40만에는 1500개의 CCTV <- 라는 경향이었고,
딱 봤을 때 경향을 너무 벗어난 (인구수 대비 CCTV가 많은, or 너무 적은) 점들이 몇개 보인다!!
유의미한 분석을 위해 이것들이 누군지 강조하자~
6. 경향에서 벗어난 데이터 강조하기
fp1 = np.polyfit(data_result["인구수"], data_result["소계"], 1)
f1 = np.poly1d(fp1)
fx = np.linspace(100000, 700000, 100)^얘네를 이용하여, 오차 컬럼을 만들 수 있다.
data_result["오차"] = data_result["소계"] - f1(data_result["인구수"])경향과 비교하여 데이터의 오차가 너무 나는 데이터를 볼 수 있다.
f_sort_f = data_result.sort_values(by="오차", ascending=False) # 내림차순
df_sort_t = data_result.sort_values(by="오차", ascending=True) # 오름차순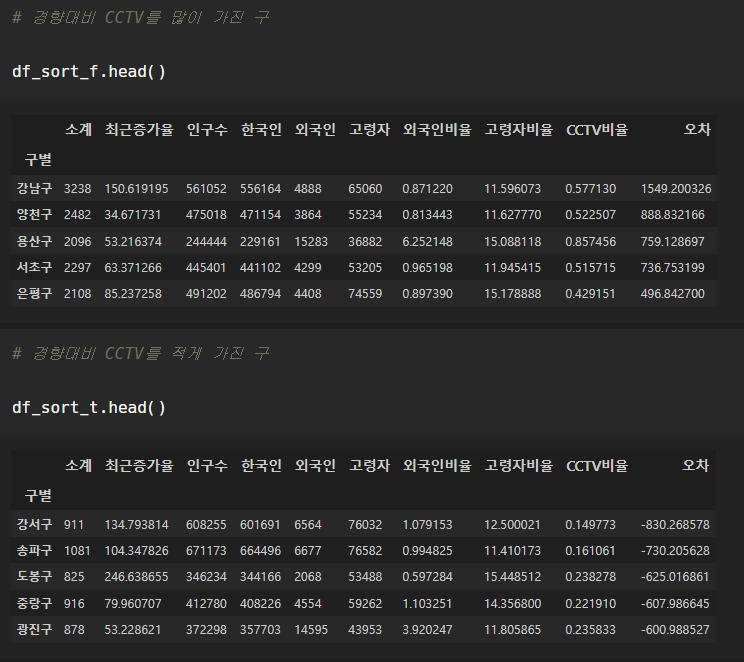
이 데이터들을 이용해 scatter plot에서 해당되는 점들에 표시를 해주자.
colormap 이용하여 사용자 정의로 세팅할 것이다.
색깔은 color picker<-구글링해서 원하는 코드값을 가져온다.
from matplotlib.colors import ListedColormap
color_step = ["#e74c3c", "#2ecc71", "#95a9a6", "#2ecc71", "#3498db", "#3498db"]
my_cmap = ListedColormap(color_step)plt.scatter안에서 색상 정보를 추가해준다.
c <- 색깔은 어떤 기준으로 구별할 것인지
text <- 이름을 점 위에 써주는데. * 0.98 등으로 위치도 조정 가능해 (점이 이름 안가리게)
그리고 for문으로 아까 만든 내림차순 데이터/오름차순 데이터를 가져와서,
상위 5개, 하위 5개씩 가져오고
plt.text를 이용하여 구 이름을 표시하는 글자를 입력할 수 있다. (인덱스값으로 입력)
* 1.02 등으로 위치를 조정하고, 폰트 사이즈도 조정해준다.
def drawGraph():
plt.figure(figsize=(14, 10))
plt.scatter(data_result["인구수"],
data_result["소계"],
s=50, c=data_result["오차"], cmap=my_cmap)
plt.plot(fx, f1(fx), ls="dashed", lw=3, color="g")
for n in range(5):
# 상위 5개
plt.text(
df_sort_f["인구수"][n] * 1.02, # x 좌표
df_sort_f["소계"][n] * 0.98, # y 좌표
df_sort_f.index[n], # title
fontsize=15
)
# 하위 5개
plt.text(
df_sort_t["인구수"][n] * 1.02, # x 좌표
df_sort_t["소계"][n] * 0.98, # y 좌표
df_sort_t.index[n], # title
fontsize=15
)
plt.xlabel("인구수")
plt.ylabel("CCTV")
plt.colorbar()
plt.grid()
plt.show()
drawGraph()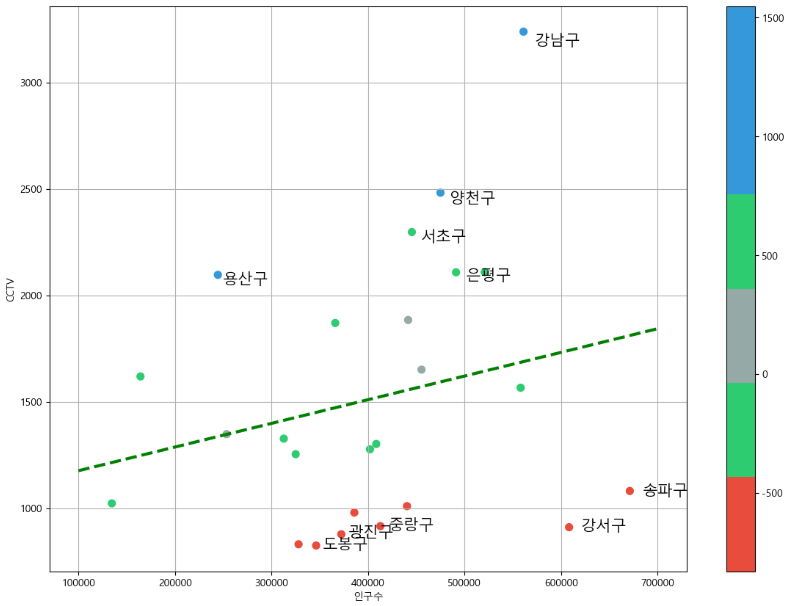
-> 이를 통해 경향과 멀어진 데이터들을 한눈에 볼 수 있다.
첫 결과물을 저장하자!!
data_result.to_csv("../data/01. CCTV_result.csv", sep=",", encoding="utf-8-sig").
.
.
(encoding utf-8으로 해줫더니 엑셀 열어봤는데 깨져있었엉...
utf-8-sig 로 해주었다.)
