- 강남3구 범죄현황 데이터 개요 및 읽어오기 <- here
- [번외1] Pandas의 pivot_table
- 서울시 범죄현황 데이터 정리
- google maps에서 구별 정보를 얻어서 데이터 정리
- 구별 데이터로 변경하기
- 서울시 범죄현황 데이터 최종 정리
- [번외2] seaborn
- 범죄 현황 데이터 시각화
- [번외3] Folium 지도 시각화
- 서울시 범죄 현황 지도 시각화
Intro
데이터 과학의 목적 - 가정(혹은 '인식')을 검증하고 표현하는 것!
서울 강남 3구의 체감 안전도가 높다는 기사가 있다.
정말로 강남3구가 범죄로부터 안전하다고 말할 수 있는지!!! 확인해보자.
+ GoogleMaps, Folium, Seaborn, Pandas의 Pivot_table 등을 익히자.
[데이터 출처] 서울특별시 관서별 5대 범죄 현황 - 공공데이터포털
https://www.data.go.kr/data/15054738/fileData.do
2016년도 자료를 기준으로 한다.
1. 강남3구 범죄현황 데이터 개요 및 읽어오기
데이터 읽어올 건데
숫자들이 콤마로 구분되어 있다.
-> 문자로 인식되므로, 숫자 분석을 할 수 없음
-> thousand="," 기능으로 구분!
import pandas as pd
import numpy as np
crime_raw_data = pd.read_csv("../data/02. crime_in_Seoul.csv", thousands=",", encoding="euc-kr")
crime_raw_data.head()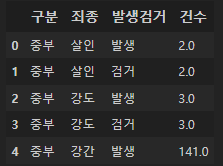
데이터의 개요를 확인하자.
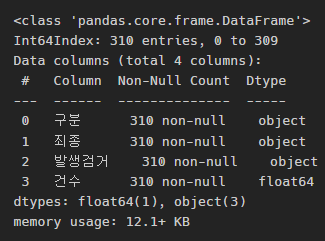
crime_raw_data.info()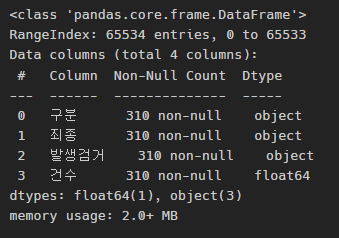
-> RangeIndex가 65534개인데, 우리가 가진 데이터는 310개이다.

unique로 컬럼을 조사해보았더니
nan값때문에 그런 것 같다.
isnull()을 이용하여 null 여부를 boolean으로 볼 수 있는데,
crime_raw_data[crime_raw_data["죄종"].isnull()]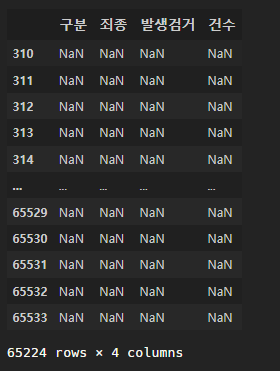
nan값이 굉장히 많다.
nan값이 아닌 것들만 가져와서 분석을 해야겠다.
-> notnull 사용, 원본데이터로 저장
crime_raw_data[crime_raw_data["죄종"].notnull()]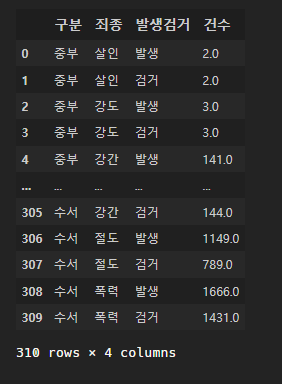
다시 info() 찍어보았더니, 아무 문제 없음을 확인하였다:
[번외1] Pandas의 pivot_table
Pandas pivot table
피벗테이블을 만들려면 index, columns, values, aggfunc(values를 표현하는 연산식) 이 필요하다.
이런 연습 데이터를 가져왔다.
인덱스 설정
df.pivot_table(index="Name")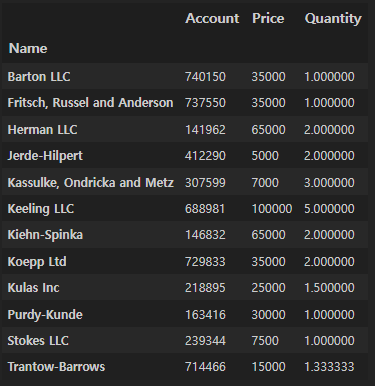
멀티 인덱스도 가능하다:
df.pivot_table(index=["Manager", "Rep"])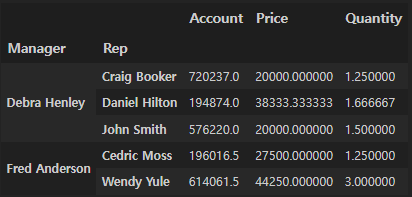
Values 설정
df.pivot_table(index=["Manager", "Rep"], values="Price")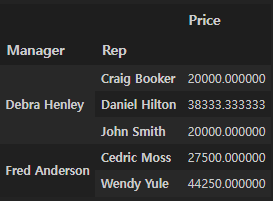
연산 적용하기 <- aggfunc
price 컬럼에 sum 연산을 적용하자!
(기본값은 평균이다)
df.pivot_table(index=["Manager", "Rep"], values="Price", aggfunc=np.sum)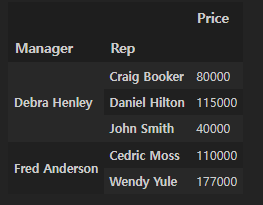
aggfunc도 두 개 이상 연산 가능하다. len을 사용해서 개수 표시
df.pivot_table(index=["Manager", "Rep"], values="Price", aggfunc=[np.sum, len])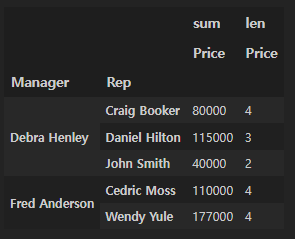
Columns 설정
컬럼을 product로 지정해보자:
df.pivot_table(index=["Manager", "Rep"], values="Price", columns="Product", aggfunc=np.sum)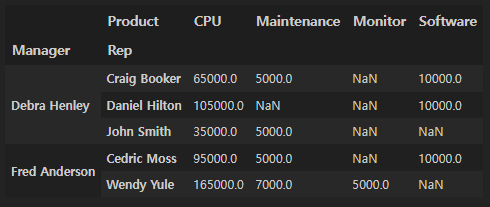
NaN값이 있다.
fill_value <- nan값이 있다면 0으로 채우겠다
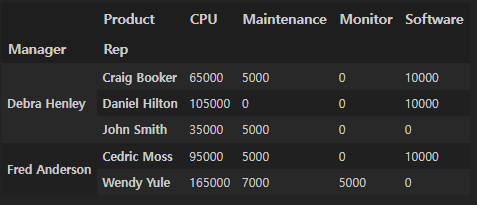
df.pivot_table(
index=["Manager", "Rep"],
values="Price",
columns="Product",
aggfunc=np.sum,
fill_value=0
)
이제 응용한 버전:
index, values 여러개 설정하고
aggfunc도 총합과 평균 두 개로 나타내보자,
NaN값은 0으로,
하단에 총계(All)를 추가하는 margins도 설정하면:
df.pivot_table(
index=["Manager", "Rep", "Product"],
values=["Price", "Quantity"],
aggfunc=[np.sum, np.mean],
fill_value=0,
margins=True
)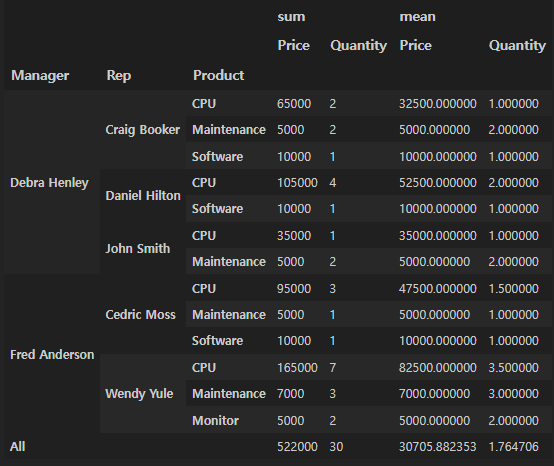
-> 이런 피벗테이블을 생성할 수 있다.
이제 다시 프로젝트로 돌아가 서울시 데이터에도 피벗테이블을 적용해보자.
2. 서울시 범죄현황 데이터 정리
우리가 이런 데이터를 가지고 있었는데,
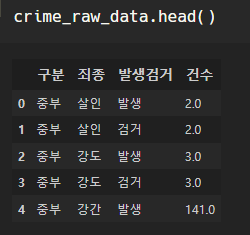
구분은 경찰서이다.
xx구, ㅇㅇ구 처럼 구 별로 범죄 건수를 보고 싶다.
-> 피벗테이블로 인덱스를 구분으로 잡아주고,
죄종, 발생검거를 컬럼으로,
값은 합계로 적용해주었다.
crime_station = crime_raw_data.pivot_table(
crime_raw_data,
index="구분",
columns=["죄종", "발생검거"],
aggfunc=np.sum
)
crime_station.head()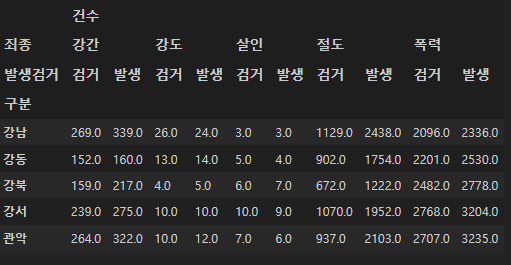
표 생긴 게, 건수가 맨 위에 있고 그 다음 죄종으로, 그 다음 발생검거
이런 식으로 구분되어 있다.
이걸 간단히 만들고 싶다.
crime_station.columns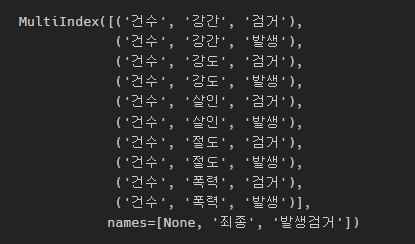
멀티 컬럼의 형식이다. droplevel을 사용하여 날리고 싶은 인덱스 번호를 넣어주면
상단의 '건수'를 날릴 수 있다.
crime_station.columns = crime_station.columns.droplevel(0)
crime_station.columns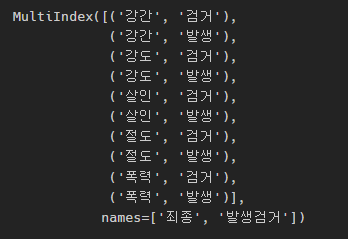
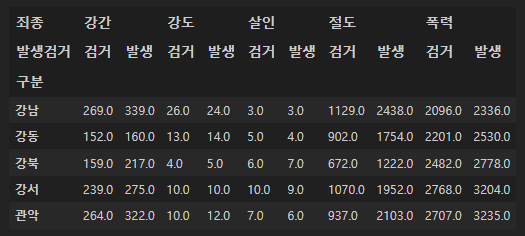
이런 모습이 된다.
컬럼 다음으로는 인덱스 조정을 할 것이다.
현재 인덱스는 경찰서 이름으로 되어 있는데,
경찰서 이름으로 구 이름을 알아내야 추후 작업을 진행할 수 있다.
crime_station.index
.
.
.
인덱스는 다음시간에~
