- 강남3구 범죄현황 데이터 개요 및 읽어오기
- [번외1] Pandas의 pivot_table
- 서울시 범죄현황 데이터 정리
- google maps에서 구별 정보를 얻어서 데이터 정리
- 구별 데이터로 변경하기
- 서울시 범죄현황 데이터 최종 정리
- [번외2] seaborn <- here
- 범죄 현황 데이터 시각화
- [번외3] Folium 지도 시각화
- 서울시 범죄 현황 지도 시각화
[번외2] seaborn
파이썬에서 matplotlib과 함께 시각화 도구로 많이 사용되는 seaborn의 기본기를 학습하였다.
필요한 모듈 임포트하고 시작해보자~
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rc
plt.rcParams["axes.unicode_minus"] = False # 마이너스 부호 때문에 한글 깨짐을 방지
rc("font", family="Malgun Gothic") # 한글 설정
%matplotlib inline예제 1. seaborn 기초
넘파이를 통해 0부터 14까지 100개의 데이터를 뽑았다.
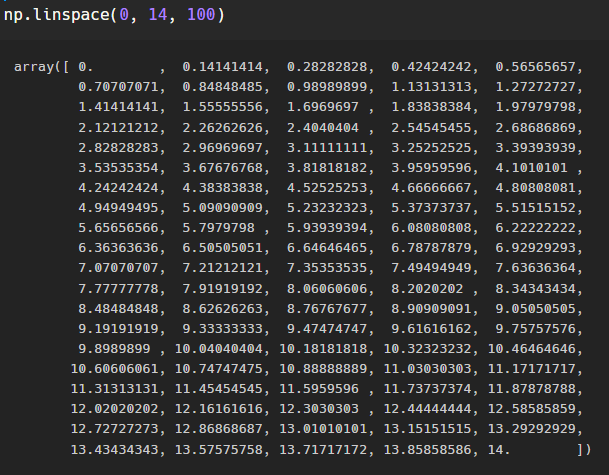
x = np.linspace(0, 14, 100)
y1 = np.sin(x)
y2 = 2 * np.sin(x + 0.5)
y3 = 3 * np.sin(x + 1.0)
y4 = 4 * np.sin(x + 1.5)seaborn은 matplotlib을 기반으로 작동하기 때문에 기본적인 원리는 유사하다.
plt.figure(figsize=(10, 6))
plt.plot(x, y1, x, y2, x, y3, x, y4)
plt.show()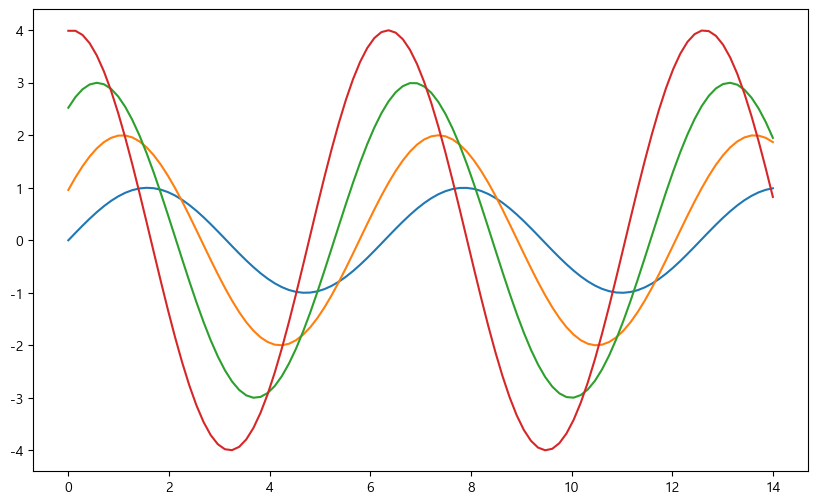
sns.set_style() 옵션 - 뒷배경 white, dark, whitegrid, darkgrid 등이 있다.
sns.set_style("darkgrid")
plt.figure(figsize=(10, 6))
plt.plot(x, y1, x, y2, x, y3, x, y4)
plt.show()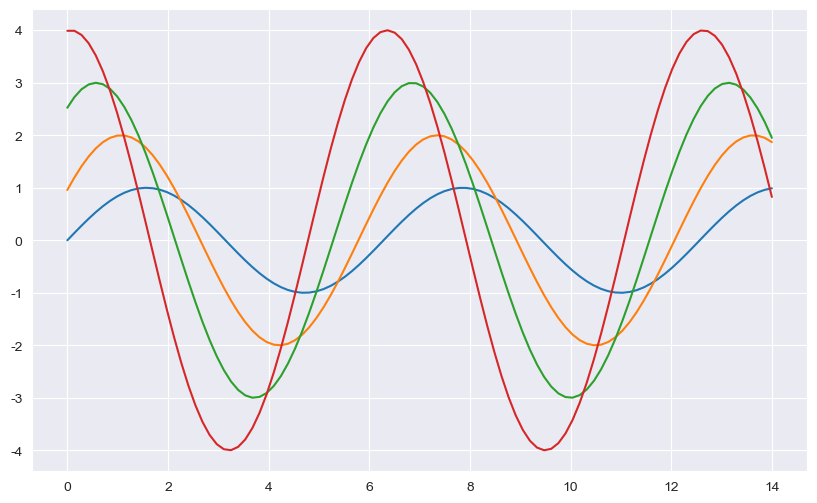
예제 2. seaborn tips data
- boxplot, swarmplot, lmplot
seaborn이 보유한 데이터 tips를 불러올 수 있다.
tips = sns.load_dataset("tips")
tips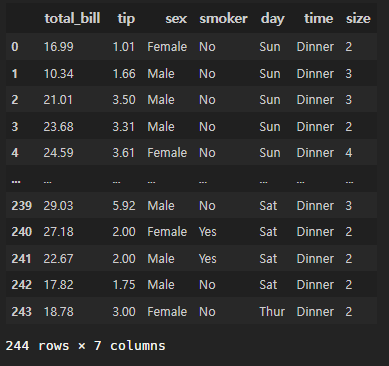
요렇게 생긴 애고...
(1) Boxplot
plt.figure(figsize=(8, 6))
sns.boxplot(x=tips["total_bill"])
plt.show()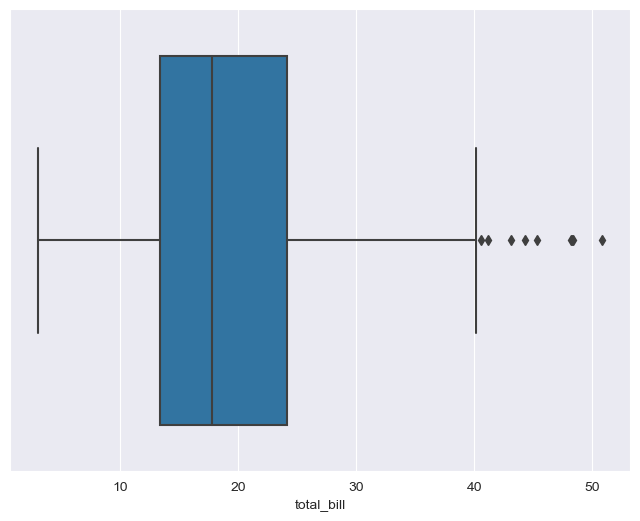
~~여담인데 boxplot을 boxenplot이라 오타를 쳐버렸는데
모양이 이상한 것이었다 내가 아는 박스플랏이 아닌데...
boxen plot 기능이 있단 것도 알게 되어서 재밌었다
~~
요일에 따른 bill:
plt.figure(figsize=(8, 6))
sns.boxplot(x="day", y="total_bill", data=tips)
plt.show()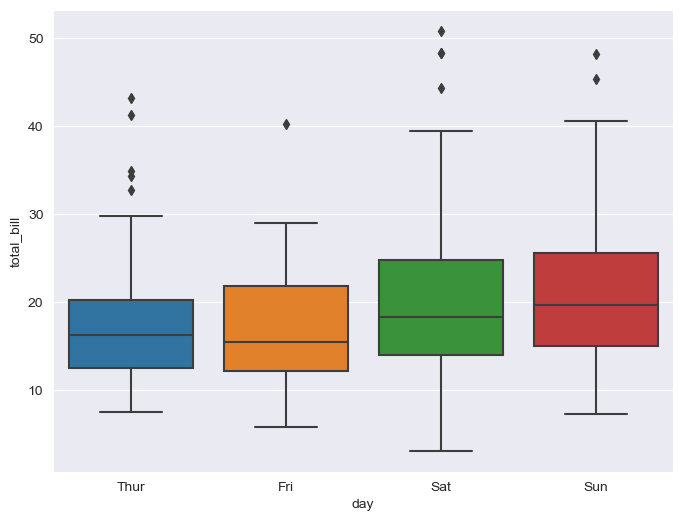
hue, palette:
hue <- 내가 보는 데이터셋에서 카테고리로 되어 있는 컬럼값 이름을 hue에 넣어주면 나눠서 볼 수 있는 옵션이다.
smoker 컬럼이 y/n로 되어 있으므로 구분하기 위해 hue에 넣었다.
palette <- 스타일 변경. Set1, Set2, Set3 이 있다.
plt.figure(figsize=(8, 6))
sns.boxplot(x="day", y="total_bill", data=tips, hue="smoker", palette="Set3")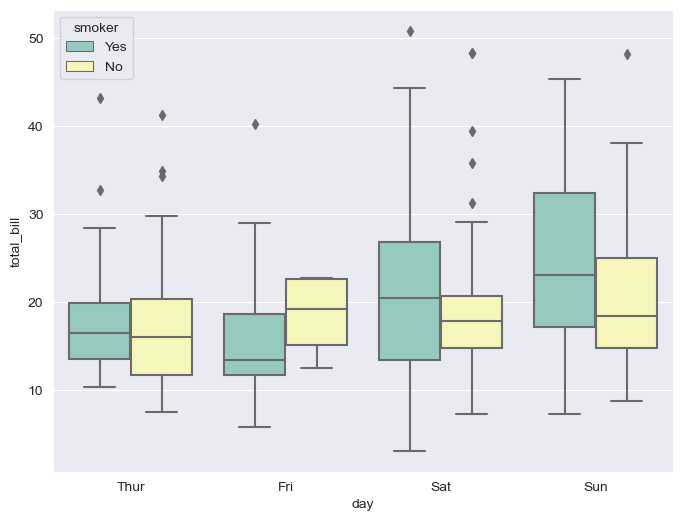
(2) Swarmplot
산점도 형태의 그래프이다.
color 옵션은 0에 가까워질 수록 검은색, 1은 흰색으로 설정해줌
plt.figure(figsize=(8, 6))
sns.swarmplot(x="day", y="total_bill", data=tips, color="0.5")
plt.show()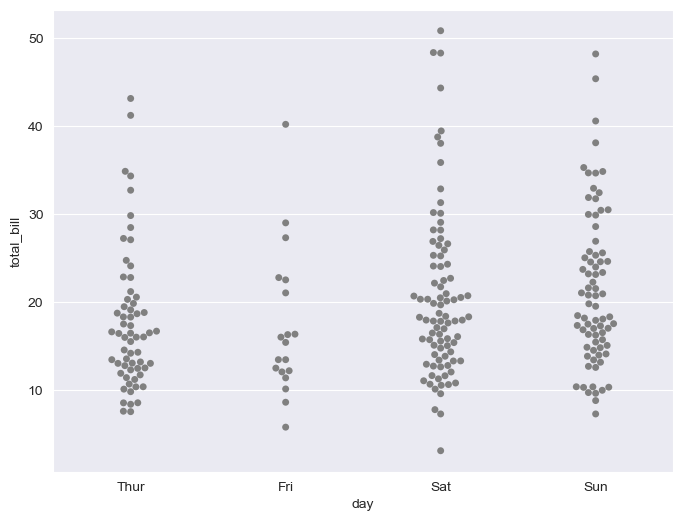
Mix boxplot and swarmplot:
plt.figure(figsize=(8, 6))
sns.boxplot(x="day", y="total_bill", data=tips)
sns.swarmplot(x="day", y="total_bill", data=tips, color="0.25")
plt.show()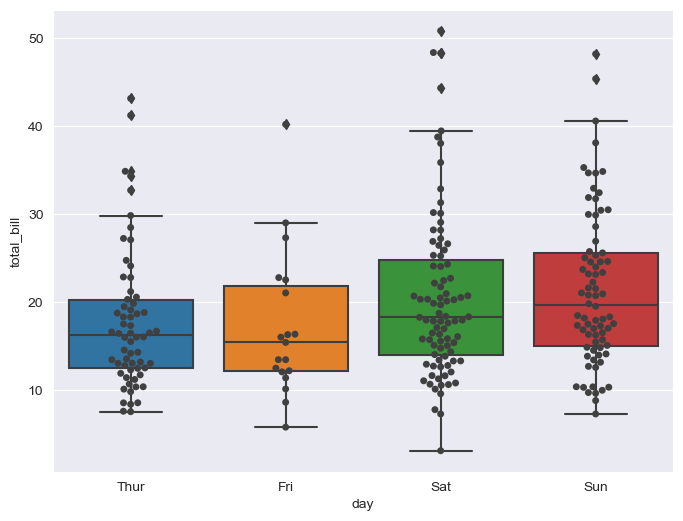
(3) lmplot
total_bill과 tip 사이의 관계를 파악할 때 사용하면 좋다.
점과 선 사이의 간격이 좁을수록 높은 상관관계를 의미한다.
sns.set_style("darkgrid")
sns.lmplot(x="total_bill", y="tip", data=tips, height=7)
plt.show()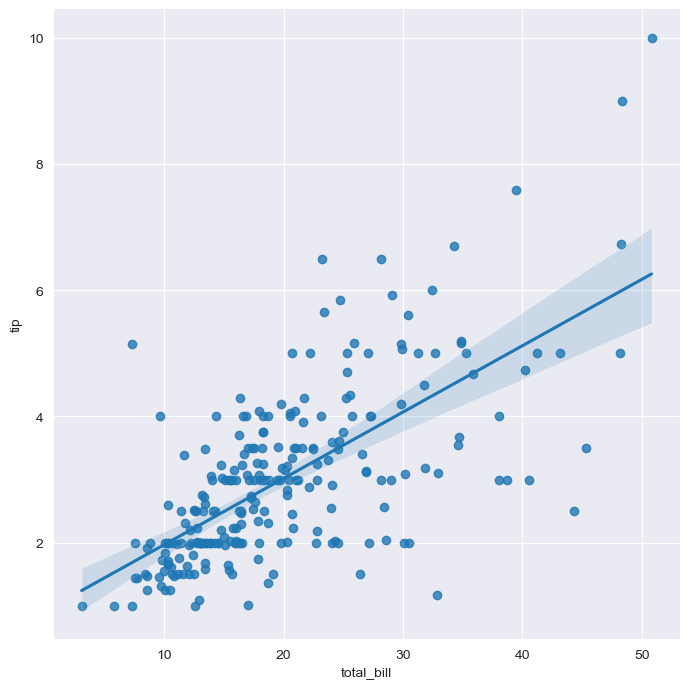
hue 옵션으로 흡연자/비흡연자를 구분해 나타낼 수 있다.
ns.set_style("darkgrid")
sns.lmplot(x="total_bill", y="tip", data=tips, hue="smoker")
plt.show()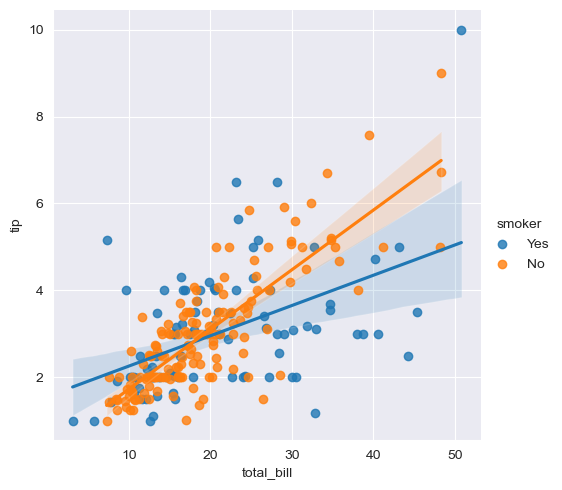
예제 3. Flights data
- heatmap
flights라는 데이터셋을 불러와보자.
flights = sns.load_dataset("flights")
flights.head()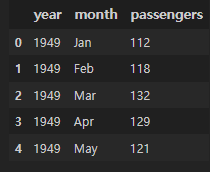
이런 데이터고,
month에 따른 구분을 하고 싶기에
피벗테이블을 사용하여
month를 인덱스로 한 표를 새로 만들어주었다.
flights = flights.pivot(index="month", columns="year", values="passengers")
flights.head()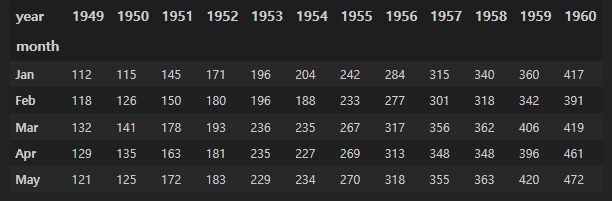
요걸 사용하여 히트맵을 만들 수 있다.
annot=True <- 데이터 값 표시
fmt="d" <- 정수형으로 출력
plt.figure(figsize=(10, 8))
sns.heatmap(data=flights, annot=True, fmt="d")
plt.show()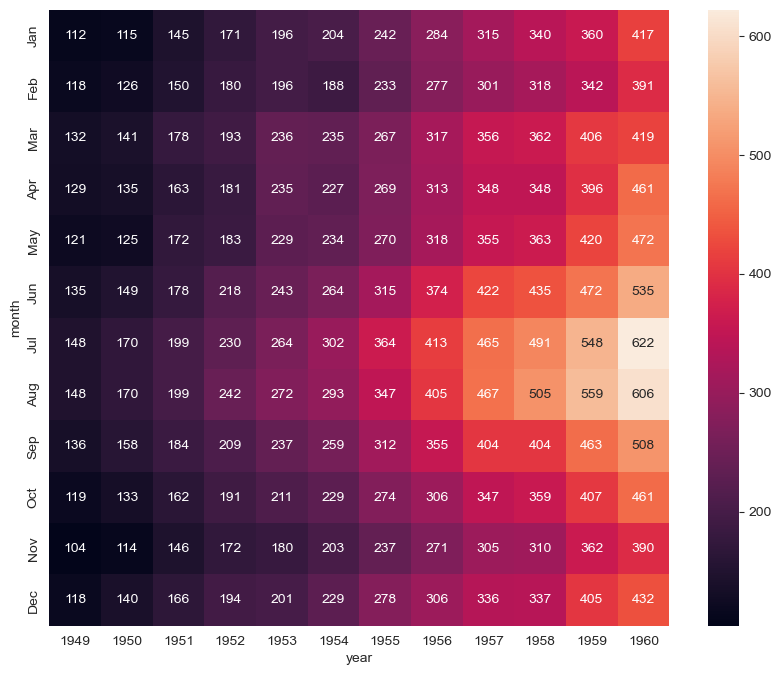
월별로 승객이 많고 적은 흐름을 볼 수 있고
연도에 따른 변화도 색깔로 눈에 잘 들어오게 보인다.
colormap <- seaborn에 내제된 컬러 차트
plt.figure(figsize=(10, 8))
sns.heatmap(flights, annot=True, fmt="d", cmap="YlGnBu")
plt.show()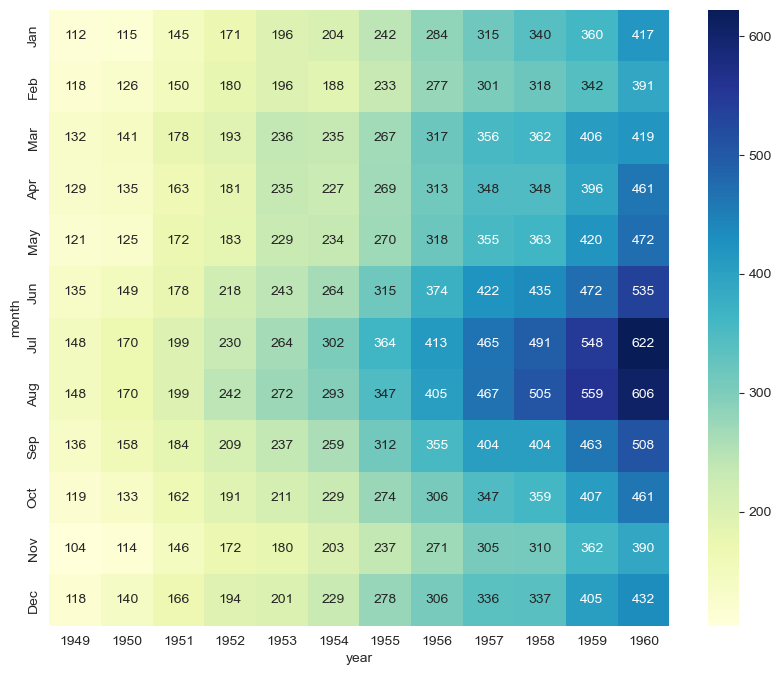
예제 4. Iris data
- pairplot
iris라는 데이터셋이 있다.
변수간 관계를 확인하는 pairplot은
전체 데이터에 대해 모든 경우의 수로 보여준다.
sns.set_style("ticks")
sns.pairplot(iris)
plt.show()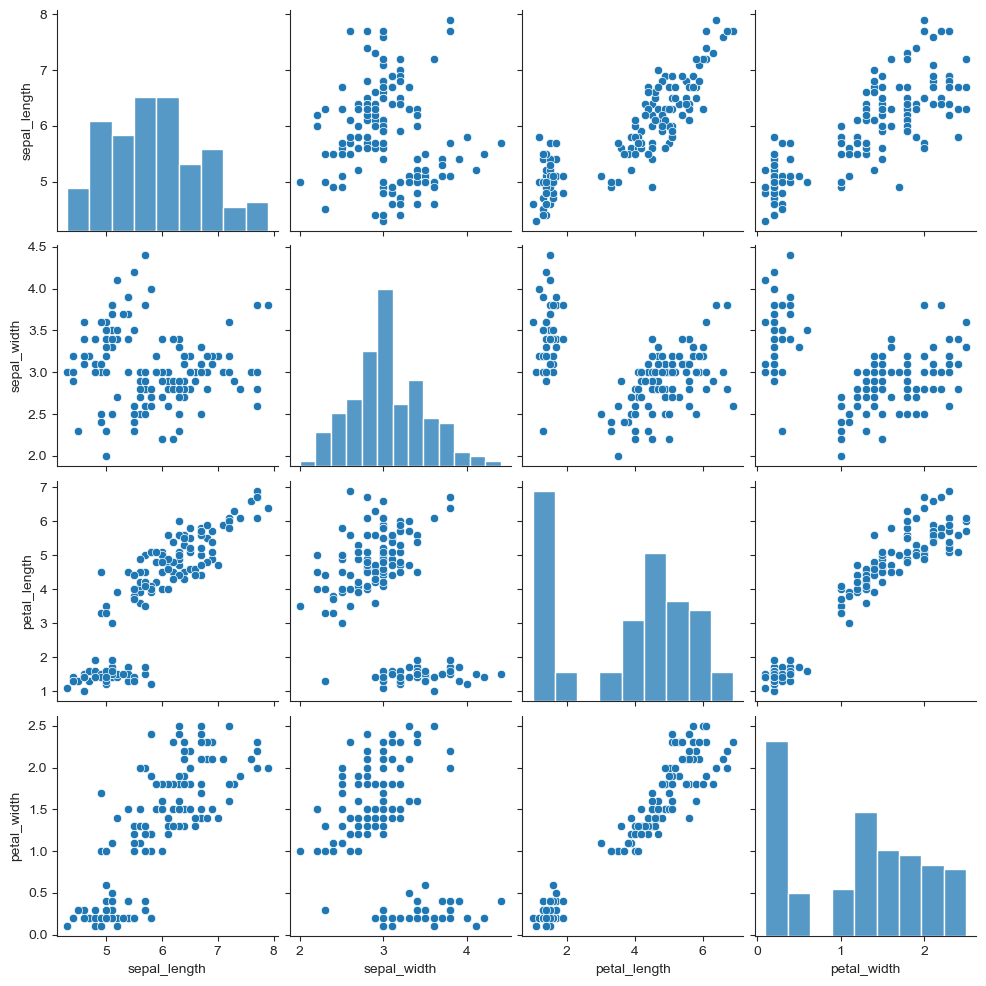
원하는 부분만 그리기:
iris["species"].unique()-> array(['setosa', 'versicolor', 'virginica'], dtype=object)
species는 세 가지 종류를 담은 카테고리 데이터인데, 이걸 hue로 써
세 가지 종류에 대한 pairplot을 그릴 수 있다.
sns.pairplot(iris, hue="species")
plt.show()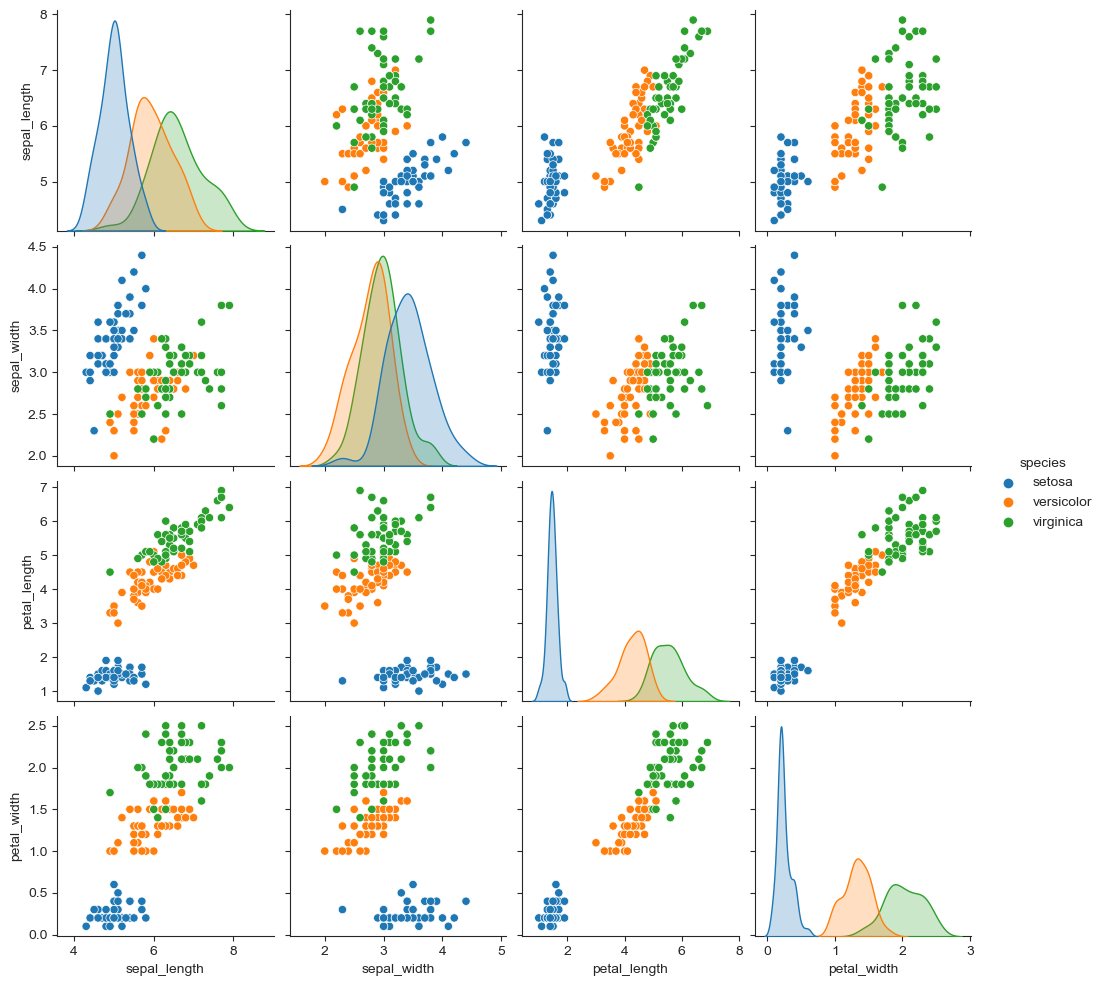
넘 좋은 기능이지...
원하는 컬럼만 pairplot으로 그리고 싶을 때는
x축, y축을 따로 설정해주면 된다.
sns.pairplot(iris,
x_vars=["sepal_width", "sepal_length"],
y_vars=["petal_width", "petal_length"])
plt.show()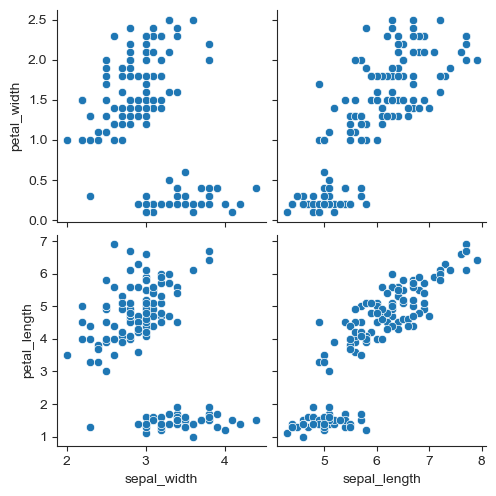
이러케~~
예제 5. anscombe data
- lmplot
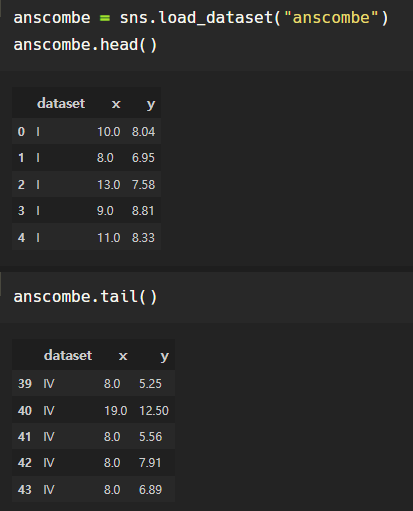
이번 예제는 이 데이터인데
카테고리형 부분은 dataset같아 보이지
anscombe["dataset"].unique()-> array(['I', 'II', 'III', 'IV'], dtype=object)
query 라는 메서드를 이용하여, anscombe의 데이터셋 중 dataset이 'I'와 일치하는 값만 가져온다.
ci <- 신뢰구간을 선택하는 옵션이다.
scatter_kws <- 딕셔너리 형태로 점의 크기를 정해줄 수 있다.
set_style("darkgrid")
sns.lmplot(
x="x",
y="y",
data=anscombe.query("dataset == 'I'"),
ci=None,
height=7,
scatter_kws={"s":100})
plt.show()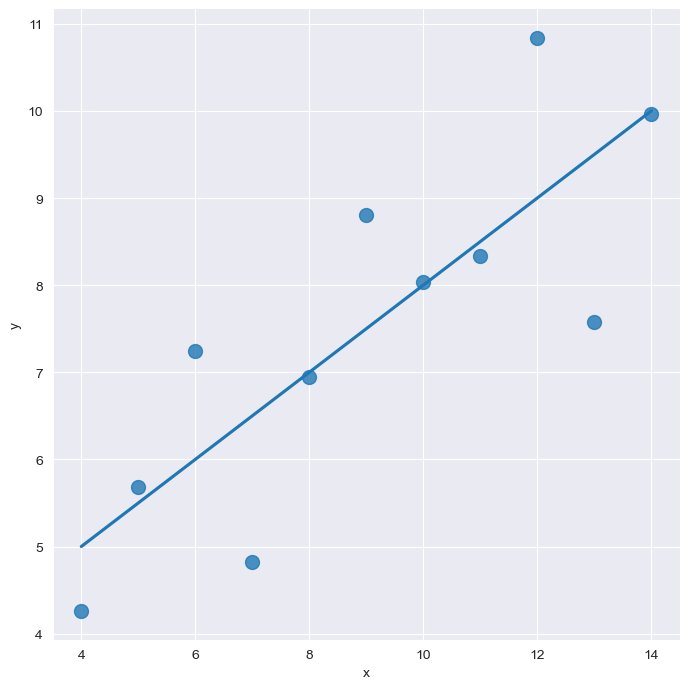
order로 차수를 지정할 수 있다. (1차, 2차...)
order=1
sns.set_style("darkgrid")
sns.lmplot(
x="x",
y="y",
data=anscombe.query("dataset == 'II'"),
order=1,
ci=None,
height=7,
scatter_kws={"s":100})
plt.show()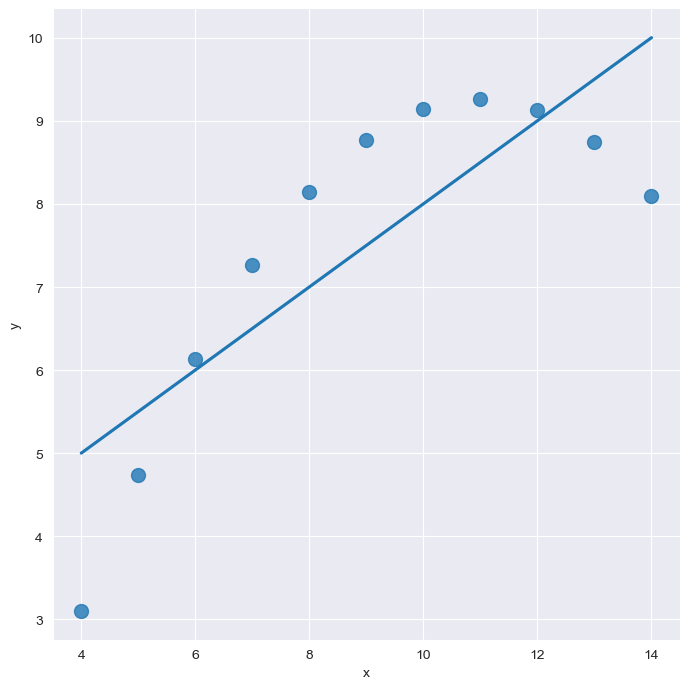
order=2
sns.set_style("darkgrid")
sns.lmplot(
x="x",
y="y",
data=anscombe.query("dataset == 'II'"),
order=2,
ci=None,
height=7,
scatter_kws={"s":100})
plt.show()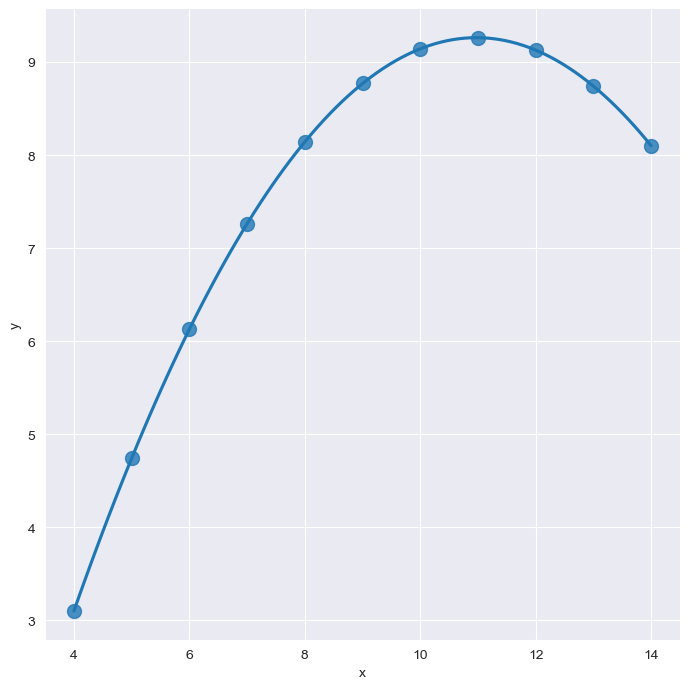
outlier 에 대해서...
sns.set_style("darkgrid")
sns.lmplot(
x="x",
y="y",
data=anscombe.query("dataset == 'III'"),
ci=None,
height=7,
scatter_kws={"s":100})
plt.show()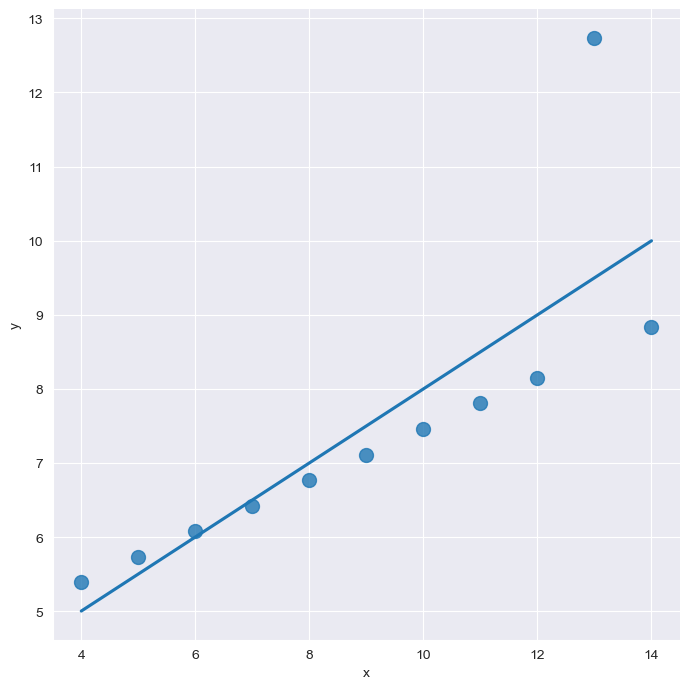
이런 경우의 그래프를 보면,
맨 위에 동떨어진 저 점 때문에 line이 좀 올라간 것이다.
robust 옵션으로 아웃라이어를 제외하여 그래프를 그려줄 수 있다!
sns.set_style("darkgrid")
sns.lmplot(
x="x",
y="y",
data=anscombe.query("dataset == 'III'"),
robust=True,
ci=None,
height=7,
scatter_kws={"s":100})
plt.show()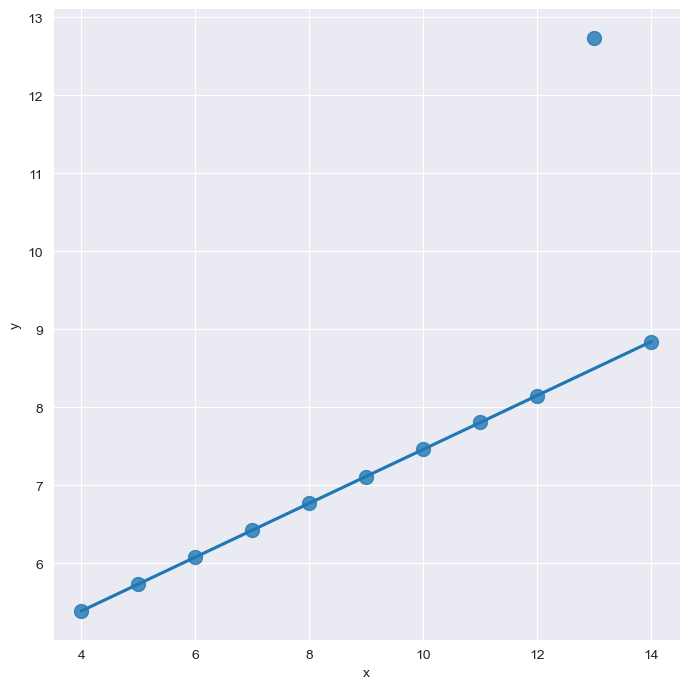
이제 서울시 범죄현황 데이터로 다시 돌아와서,
seaborn을 사용하여 여러 plot을 그려보는 시각화 작업을 해보자!!
6. 범죄 현황 데이터 시각화
마지막으로 작업했던 데이터 다시 불러와서 살펴보자.
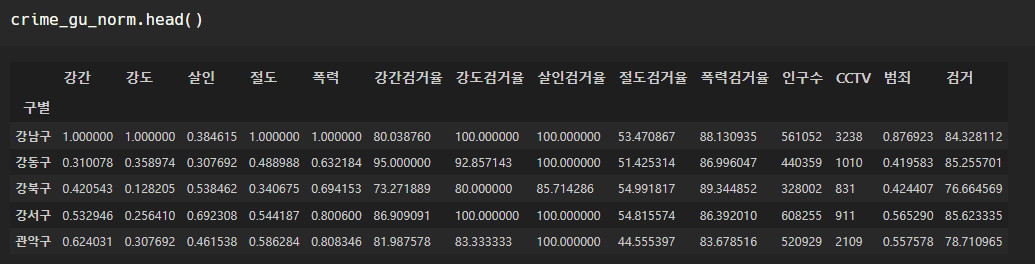
(1) 상관관계 확인하기 - pairplot
이것저것 시도하며
범죄 종류간의 상관관계에 대해 살펴보자.
강도, 살인, 폭력에 대한 상관관계:
kind=regression 으로 설정하여 회귀분석을 하고...
sns.pairplot(data=crime_gu_norm, vars=["살인", "강도", "폭력"], kind="reg", height=3)
plt.show()
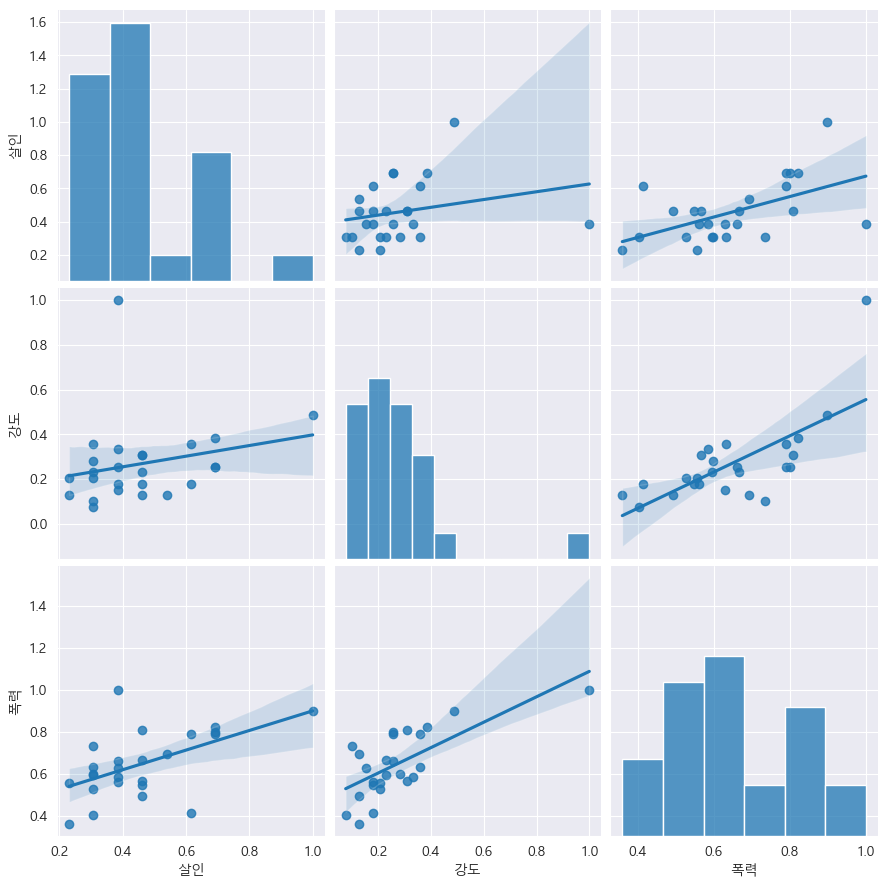
흠
강도 사건이 살인으로 연결되는 것보다는
폭력 사건이 살인으로 연결되는 경향이 높은 것 같다.
강도와 폭력은 연관이 있어 보인다.
인구수,CCTV를 x축에, 살인, 강도를 y축에 두어 상관관계를 파악:
def drawGraph():
sns.pairplot(
data=crime_gu_norm,
x_vars=["인구수", "CCTV"],
y_vars=["살인", "강도"],
kind="reg",
height=4
)
plt.show()
drawGraph()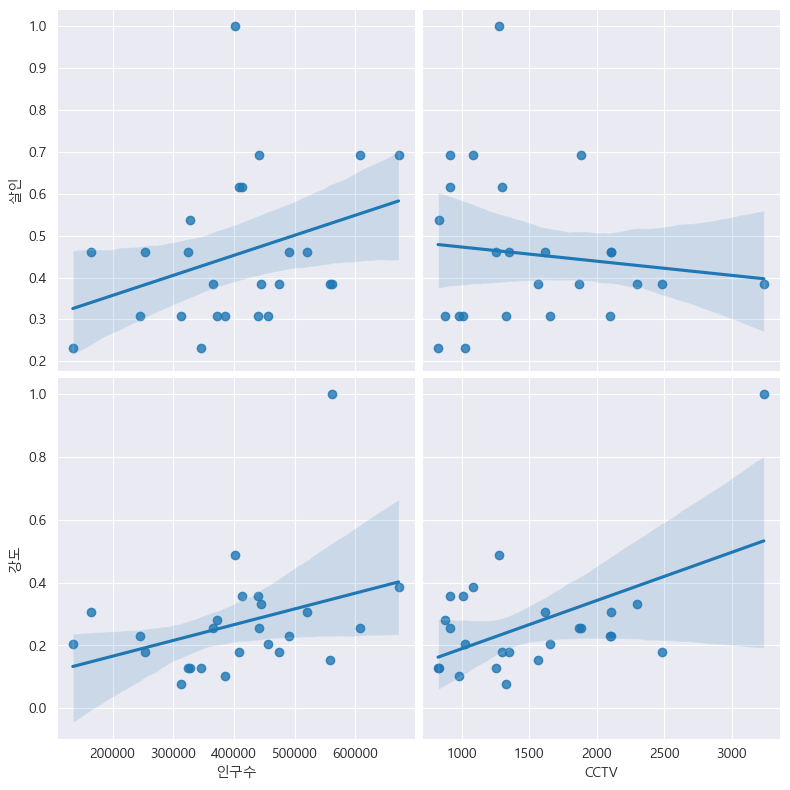
인구가 증가할수록 강도/살인 사건이 증가한다!!정도는 아닌 건데...
CCTV가 많아질수록 강도사건 증가? <- 이 말은
강도 사건이 많이 발생해서 CCTV를 늘렸다. <-이렇게 해석할 수도 있다.
인구수, CCTV 와 검거율(살인검거율, 폭력검거율)의 상관관계 확인:
def drawGraph():
sns.pairplot(
data=crime_gu_norm,
x_vars=["인구수", "CCTV"],
y_vars=["살인검거율", "폭력검거율"],
kind="reg",
height=4
)
plt.show()
drawGraph()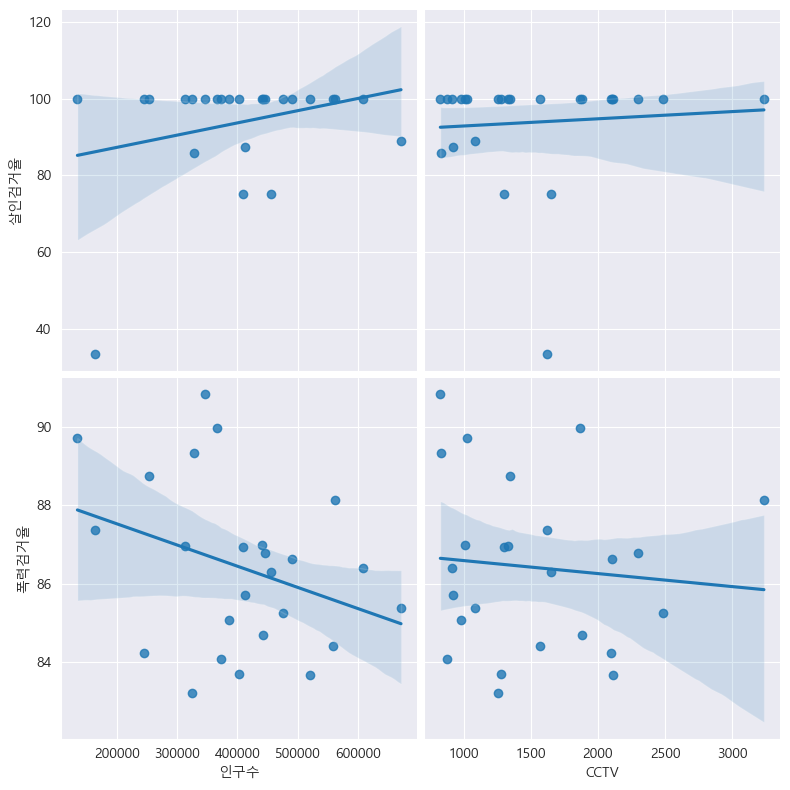
인구수가 증가할수록 폭력 검거율이 떨어진다.
인구수, CCTV 와 검거율(절도검거율, 강도검거율)의 상관관계 확인:
def drawGraph():
sns.pairplot(
data=crime_gu_norm,
x_vars=["인구수", "CCTV"],
y_vars=["절도검거율", "강도검거율"],
kind="reg",
height=4
)
plt.show()
drawGraph()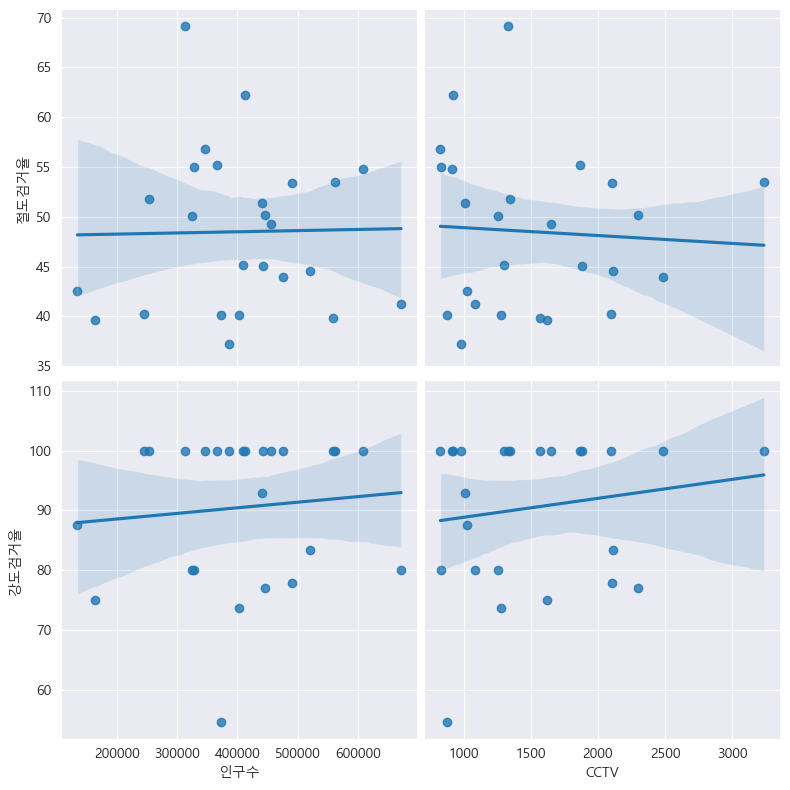
크게 연관된 것이 보이지는 않는다.
(2) 검거율, 범죄발생 건수 - heatmap
구마다의 검거율이나 범죄 비율은
검거 (검거율 평균) 컬럼/건수 컬럼을 내림차순 정렬하여
히트맵을 그려줄 데이터 프레임을 생성하면
한 눈에 볼 수 있다~
검거 컬럼 기준 상위 5개의 검거율 높은 구:
def drawGraph():
# 데이터 프레임 생성
target_col = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율", "검거"]
crime_gu_norm_sort = crime_gu_norm.sort_values(by="검거", ascending=False) # 내림차순
# 그래프 설정
plt.figure(figsize=(10, 10))
sns.heatmap(
data=crime_gu_norm_sort[target_col],
annot=True, # 데이터값 표현
fmt="f", # 실수형
linewidth=0.5, # 박스간 간격설정
cmap="RdPu"
)
plt.title("범죄 검거 비율 (정규화된 검거의 합으로 정렬)")
plt.show()
drawGraph()
도봉구, 성동구, 동대문구 등의 상위에 있는 구들이 검거를 잘 하는 구.
강남3구 애들은 좀 하위이다.
범죄발생 건수 heatmap:
# "범죄" 컬럼을 기준으로 정렬
def drawGraph():
# 데이터 프레임 생성
target_col = ["강간", "강도", "살인", "절도", "폭력", "범죄"]
crime_gu_norm_sort = crime_gu_norm.sort_values(by="범죄", ascending=False) # 내림차순
# 그래프 설정
plt.figure(figsize=(10, 10))
sns.heatmap(
data=crime_gu_norm_sort[target_col],
annot=True, # 데이터값 표현
fmt="f", # 실수형
linewidth=0.5, # 박스간 간격설정
cmap="RdPu"
)
plt.title("범죄 비율 (정규화된 발생 건수로 정렬)")
plt.show()
drawGraph()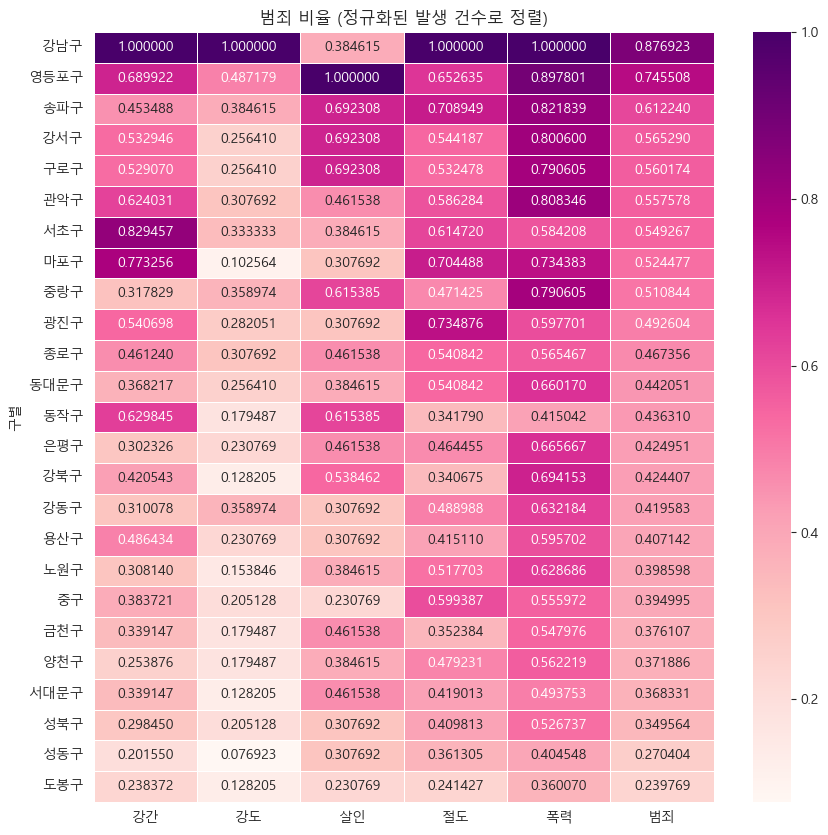
살인을 제외하면, 강남구가 범죄율 1위이다.
영등포구는 살인사건 1위.
"강남3구는 안전할 것 같아"라는 말에는
이런 분석을 통해
강남3구의 검거율이 높지 않고, 발생 건수는 높음을 볼 수 있었으므로
의문을 제기할 수 있었다~~~
데이터를 저장하며 마무리!!
crime_gu_norm.to_csv("../data/02. crime_in_Seoul_final.csv", sep=",", encoding="utf-8")