- 강남3구 범죄현황 데이터 개요 및 읽어오기
- [번외1] Pandas의 pivot_table
- 서울시 범죄현황 데이터 정리
- google maps에서 구별 정보를 얻어서 데이터 정리 <- here
- 구별 데이터로 변경하기
- 서울시 범죄현황 데이터 최종 정리
- [번외2] seaborn
- 범죄 현황 데이터 시각화
- [번외3] Folium 지도 시각화
- 서울시 범죄 현황 지도 시각화
3. google maps에서 구별 정보를 얻어서 데이터 정리
경찰서의 주소를 이용해
특정 구 이름을 얻어오고,
그것을 인덱스로 설정하는 작업을 하려 한다.
-> Google Cloud Platform 계정과 프로젝트 생성 후 Google maps API를 사용할 수 있다.
import googlemaps -> 발급받은 API key를 gmaps_key 변수에 담아주었다.
gmaps = googlemaps.Client(key=gmaps_key)
서울영등포경찰서 <-를 검색하면 상세 주소와 위도, 경도 등의 지리적 정보를 불러올 수 있다.
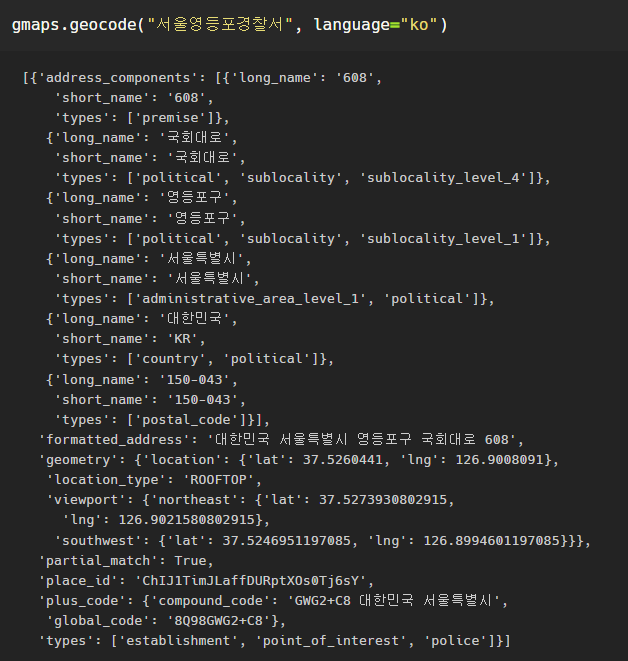
우리가 필요한 건 formatted_address에 있는 전체 주소이다.
tmp = gmaps.geocode("서울영등포경찰서", language="ko")
len(tmp)여러 줄의 주소 정보들이
리스트로 감싸진 하나의 데이터이다. (length is 1)
-> 리스트 0번째 선택, get 메서드로 formatted_address에 접근한다.
tmp[0].get("formatted_address")-> '대한민국 서울특별시 영등포구 국회대로 608'
우리는 이 경찰서가 위치한 구 이름만 필요하다.
split을 이용하여 띄어쓰기 기준으로 구분한 것을 리스트 형태로 나눠 가져온다.
tmp[0].get("formatted_address").split()[2]-> '영등포구'
다시 우리가 갖고 있는 데이터를 보면
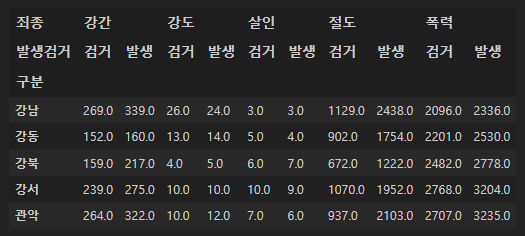
이거였는데
여기에 구별 데이터 추가할 것이고
일단 NaN값들로 설정해준 후
반복문을 이용해서 구 이름으로 NaN값을 바꿔주자!
NaN값들로 채워주기
crime_station["구별"] = np.nan
crime_station.head()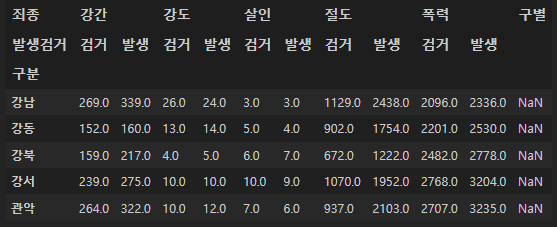
iterrows() 함수 사용하기
index, row 두 가지 값을 반환받을 수 있다.

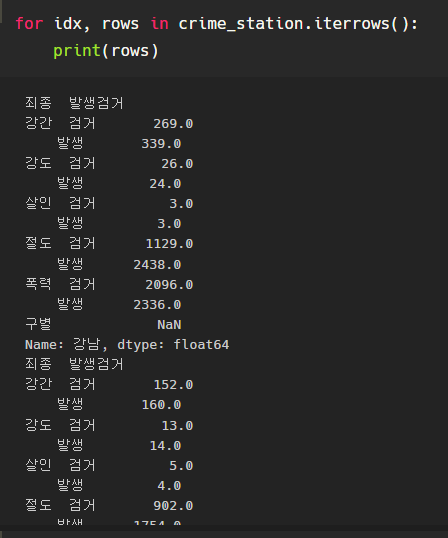
이 방식을 이용하여 인덱스를 이용하여 경찰서 이름을 만들어주고,
그 이름들을 사용하여 구글맵에서 위치정보를 받아올 수 있다.

이런 식으로 station_name을 가져온 것이고
그 변수를 gmaps.geocode에 지명으로 넣어주고
예시로 했던 것처럼 구글맵 주소 리스트에서 formatted_address를 가져와
loc를 사용하여 NaN이 들어간 공간에 값들을 채워준다~
for idx, rows in crime_station.iterrows():
station_name = '서울' + str(idx) + '경찰서'
tmp = gmaps.geocode(station_name, language = 'ko')
tmp_gu = tmp[0].get("formatted_address")
crime_station.loc[idx, "구별"] = tmp_gu.split()[2]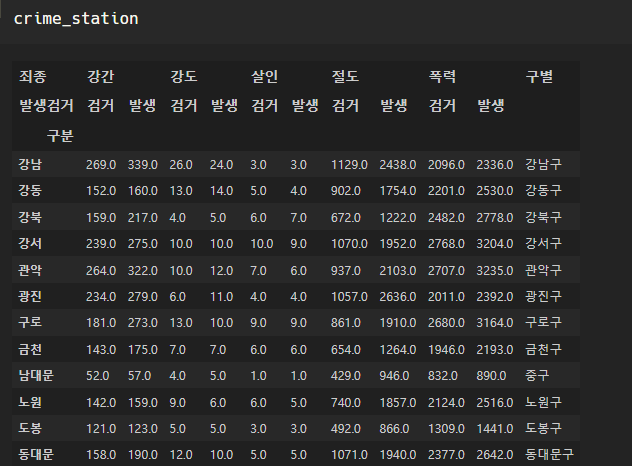
잘 정리됐다~~
컬럼 정리하기
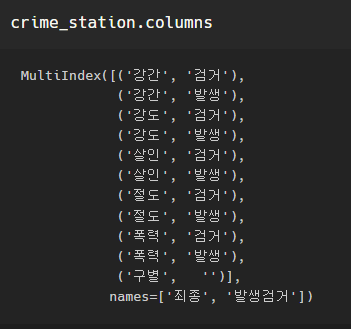
이제 상단 두줄로 되어있는 이상한 컬럼 모양을 정리해줄 것이다.
컬럼이 저런식으로 되어 있는 건데,
(강도, 검거), (강도, 발생)... 이렇게 되어 있는 것을 그냥 묶어서 한줄로
강도검거, 강도발생 이런 식으로 보고 싶다.
crime_station.columns.get_level_values(0)-> Index(['강간', '강간', '강도', '강도', '살인', '살인', '절도', '절도', '폭력', '폭력', '구별'], dtype='object', name='죄종')
crime_station.columns.get_level_values(0)[2] + crime_station.columns.get_level_values(1)[2]-> '강도검거'
tmp = [
crime_station.columns.get_level_values(0)[n] + crime_station.columns.get_level_values(1)[n]
for n in range(0, len(crime_station.columns.get_level_values(0)))
]
tmp-> ['강간검거',
'강간발생',
'강도검거',
'강도발생',
'살인검거',
'살인발생',
'절도검거',
'절도발생',
'폭력검거',
'폭력발생',
'구별']
이 단어들로 변경해주면 한 줄로 깔끔하게 된다.
crime_station.columns = tmp
crime_station.head() 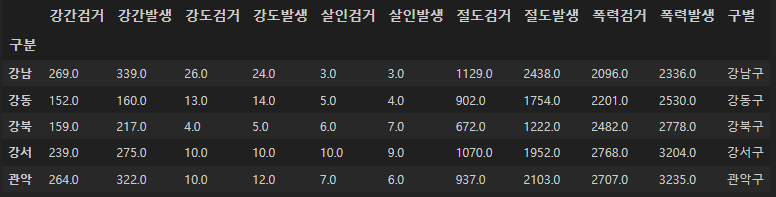
crime_station.to_csv("../data/02. crime_in_Seoul_raw.csv", sep=",", encoding="utf-8-sig")4. 구별 데이터로 변경하기
새로 저장한 데이터를 피벗테이블로 정리하였다.
crime_station2 = pd.read_csv("../data/02. crime_in_Seoul_raw.csv", thousands=",", index_col=0)
crime_gu = pd.pivot_table(crime_station2, index="구별", aggfunc=np.sum)
crime_gu.head() 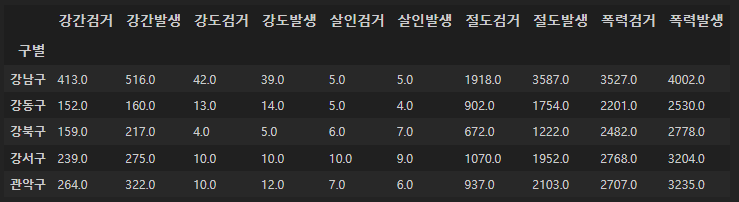
검거율 생성
crime_gu["강도검거"] / crime_gu["강도발생"] 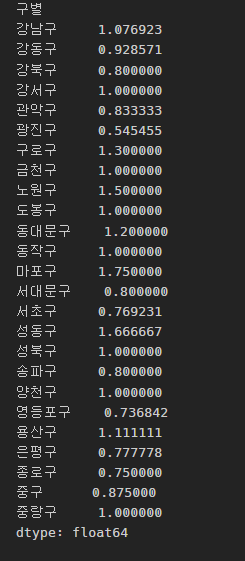
이런 방식인데
다수의 컬럼을 다수의 컬럼으로 각각 나눌 수 있다.
-> div
num = ["강간검거", "강도검거", "살인검거", "절도검거", "폭력검거"]
den = ["강간발생", "강도발생", "살인발생", "절도발생", "폭력발생"]
crime_gu[num].div(crime_gu[den].values).head() 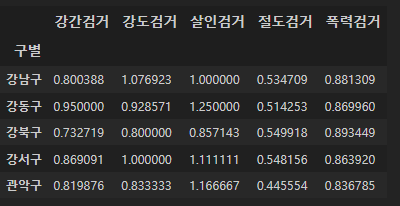
이제 원본 데이터에 적용하고,
검거 컬럼은 삭제함
target = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율"]
num = ["강간검거", "강도검거", "살인검거", "절도검거", "폭력검거"]
den = ["강간발생", "강도발생", "살인발생", "절도발생", "폭력발생"]
crime_gu[target] = crime_gu[num].div(crime_gu[den].values) * 100
crime_gu.drop(["강간검거", "강도검거", "살인검거", "절도검거", "폭력검거"], axis=1, inplace=True)
crime_gu.head()
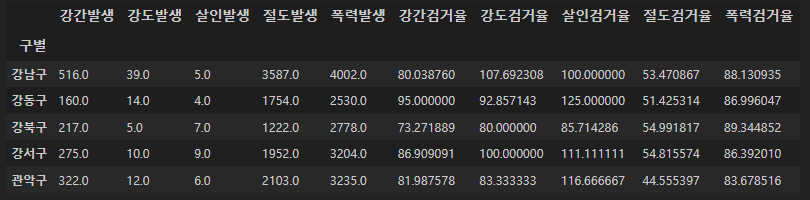
검거율 100이 넘어가는 숫자들이 좀 보인다.
데이터 수집 과정에서 생긴 오류인데 그냥 100으로 수정해줄 것이다
100보다 큰 숫자 찾아서 바꾸고,
crime_gu[crime_gu[target] > 100] = 100
crime_gu.head()컬럼명도 rename 메서드에 딕셔너리값으로 간단하게 바꾸어주었다.
crime_gu.rename(columns={"강간발생":"강간",
"강도발생":"강도",
"살인발생":"살인",
"절도발생":"절도",
"폭력발생":"폭력"},
inplace=True)
crime_gu.head() 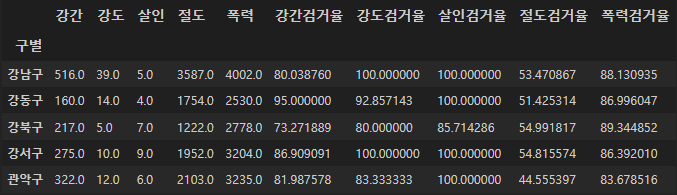
검거율까지는 잘 정리되었으나
범죄의 경중에 따라 발생건수의 차이가 크다.
강도, 살인 등은 한자리수인데 절도, 폭력은 네자리수 발생이다...
-> 정규화!
정규화된 데이터를 따로 만들어서,
최고값1 최소값0
---> 비교가 좀 쉬워짐
+
범죄/검거율,
그리고 인구수/CCTV데이터 했던 것까지
다 결합해보자.
5. 서울시 범죄현황 데이터 최종 정리
최고값은 1, 최소값은 0으로 정규화하는 건
max를 사용하여 간단하게 처리할 수 있다.
col = ["강간", "강도", "살인", "절도", "폭력"]
crime_gu_norm = crime_gu[col] / crime_gu[col].max()
crime_gu_norm.head()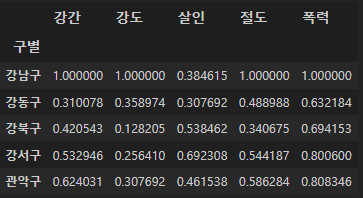
여기에 검거율 데이터를 추가하였다
col2 = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율"]
crime_gu_norm[col2] = crime_gu[col2]
crime_gu_norm.head()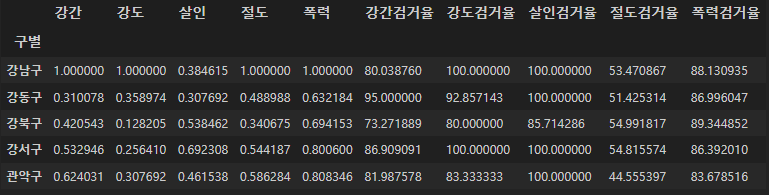
전에 했던 구별 CCTV 자료를 가져와 인구수와 CCTV수 추가해주고
result_CCTV = pd.read_csv("../data/01. CCTV_result.csv", index_col="구별", encoding="utf-8")
crime_gu_norm[["인구수", "CCTV"]] = result_CCTV[["인구수", "소계"]]
crime_gu_norm.head()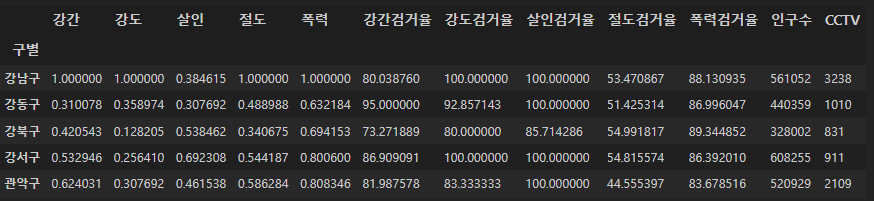
정규화된 범죄발생 건수 전체의 평균을 구해서 범죄 컬럼 대표값으로,
검거율의 평균을 구해서 검거 컬럼의 대표값으로 사용할 것이다.
col = ["강간", "강도", "살인", "절도", "폭력"]
crime_gu_norm["범죄"] = np.mean(crime_gu_norm[col], axis=1)
ol = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율"]
crime_gu_norm["검거"] = np.mean(crime_gu_norm[col], axis=1)
crime_gu_norm
최종적으로는 이런 형태로 정리하였다.
