
자료구조는 두려운 존재일 수 있습니다. 특히 독학했다면요. 만약 자바스크립트의 자료구조를 공부하려고 시도한 적이 있다면 아마도 다음과 같은 경험을 했을겁니다.
- CS 이론이 무더기로 던져집니다.
- 링크드 리스트와 같은 자료구조를 직접 구현하는 코드들을 읽습니다.
- 모든 예시들은
foo와bar또는cats와dogs를 사용하며 추상적입니다.
게다가 다음과 같은 스마트해 보이는 다이어그램과 마주하게 됩니다.
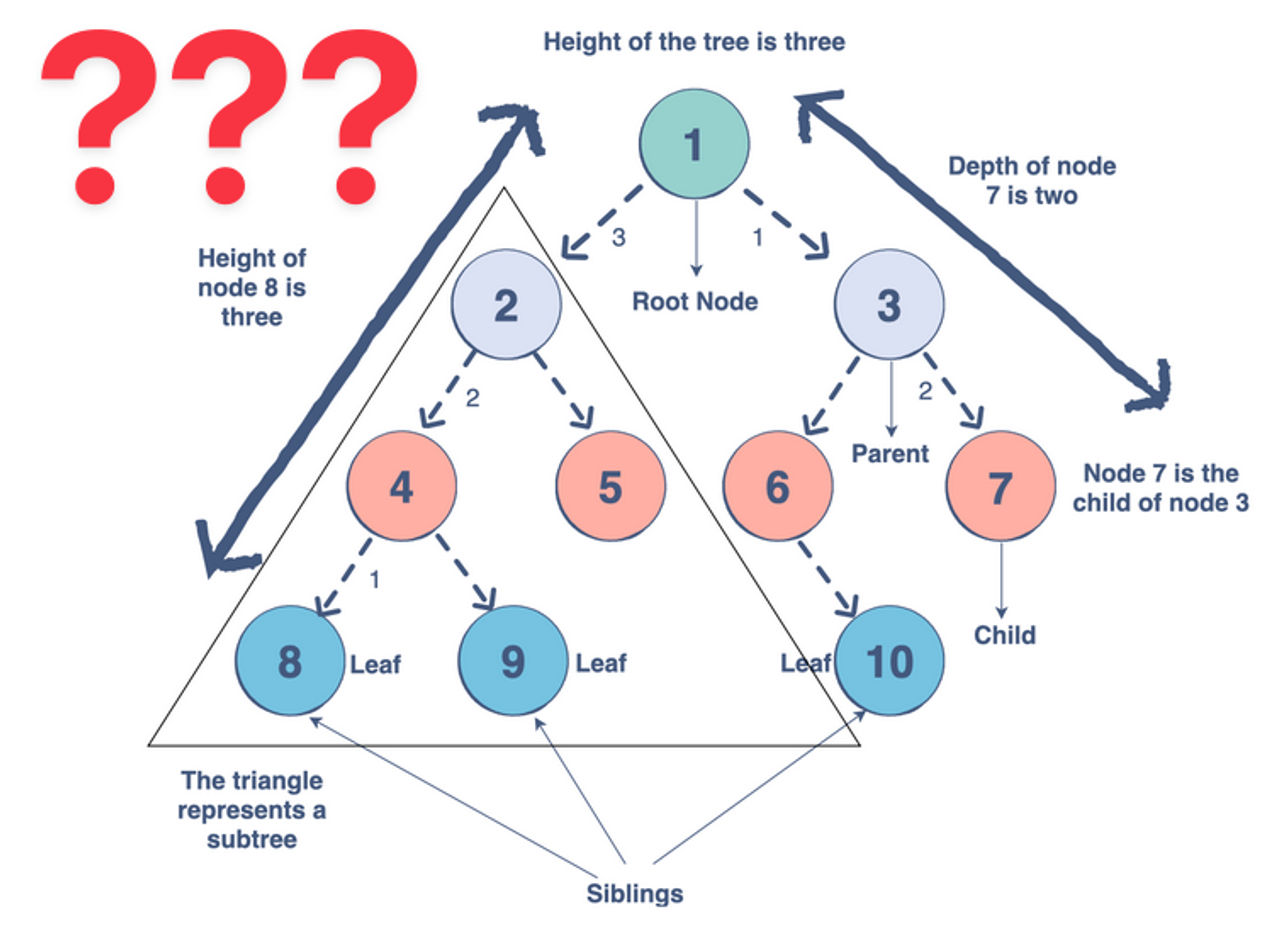
만약 실무 경험이 조금 있다면, "제 프런트엔드 프로젝트에서 이런 자료구조는 본 적이 없어요"라고 말하실 수도 있습니다. 네, 맞습니다. 사실 저도 없어요.
하지만 분명 이미 일부 자료구조를 사용하고 있을 겁니다. new HashMap()과 같이 명확한 형태는 아니지만 간단한 객체 혹은 배열로 위장하고 있을겁니다. 혹시라도 사용하고 있지 않으시다면, 이번 기회에 시도해보시면 좋을 것 같습니다.
이 글에서 우리는
- 자료구조를 공부해야 하는지, 언제 도움이 될 수 있는지에 대해 이야기합니다
- 실제 프런트엔드 프로젝트에서 찾아볼 수 있는 몇 가지 자료구조를 살펴볼 예정입니다.
걱정 마세요. 자료구조의 자체 구현과 같은 이야기는 하지 않을겁니다. 이미 이를 다루는 자료는 많이 존재합니다. 여기에선 이미 당신의 코드에서 찾아볼 수 있거나, 혹은 앞으로 프로젝트나 실무에서 사용할 수 있는 예제들을 살펴볼 것입니다.
프런트엔드 자바스크립트 개발자로서 자료구조 공부는 필요한가요?
이 질문은 논란의 여지가 있습니다. 아래와 같이 두 극단으로 나눌 수 있습니다.
- "네. 자료구조는 당신이 어떤 기술 스택을 가지고 있든 모든 개발자에게 필수적입니다"
- "제게 모든 자료구조는 이론만 늘어놓은 헛소리일 뿐 13년 이상 웹 개발자로 근무하면서 실제로 필요한 경우를 본 적이 없습니다"
많은 개발자들(특히 독학한 사람들)에게 두 번째 대답은 훨씬 위안이 됩니다. 그리고 적어도 부분적으로는 사실입니다. 자바스크립트 프런트엔드에서 자료구조를 많이 찾아보기 힘든 몇 가지 이유가 있습니다.
- 보통 프런트엔드의 데이터셋은 고급 자료구조를 사용하여 이득이 될 만큼 크지 않습니다.
- 기본적으로 자바스크립트에서 많은 자료구조를 지원하지 않습니다.
- 가장 널리 사용되는 프레임워크인 리액트는 불변의 상태 업데이트를 필요로 하기 때문에 커스텀 자료구조에서 잘 작동하지 않습니다. 커스텀 자료구조를 복제하면 성능상의 이점을 잃을 수 있습니다.
하지만 위에서 이야기했듯, "프런트엔드에서 자료구조는 필요하지 않습니다"라는 대답은 부분적으로만 사실입니다.
- 기술 인터뷰를 위해 자료구조를 알아야 할 수도 있습니다. ("할 수도" 를 강조하겠습니다)
- 더 중요한 것은 코드를 엉망으로 만드는 대부분의 경우는 잘못된 자료구조를 선택했기 때문입니다. (예시)
자료구조를 선택하는 것은 코드 품질의 성패를 결정할 수 있습니다. 자료구조는 렌더링 로직의 구조나 데이터 업데이트 방법을 결정합니다. 따라서 어떤 자료구조를 선택할지 몇 가지 옵션을 아는 것이 많은 도움이 될 수 있습니다.
Map
설명
(해시)맵, 해시 테이블 혹은 딕셔너리는 기본적으로 키-값 저장소입니다. 자바스크립트에서 항상 사용되는 자료구조이죠.
{
key1: "value 1",
key2: "value 2",
key3: "value 3",
}뿐만 아니라 내장된 Map형태의 대안도 존재합니다. Map은 Map.size와 같은 몇 가지 편리한 속성과 메서드를 가지고 있으며 키로 값을 접근하는 데에 있어 성능면에서 최적화되어 있습니다. 또한 객체를 포함한 어떠한 타입도 키로 사용될 수 있습니다.
Map의 또 다른 장점이 있습니다. 객체는 아래 예시에서 볼 수 있듯이 키 값이 문자열로 변환되지만 Map은 기존 type을 유지한다는 점입니다.
const numericKeys = {
1: "value-1",
2: "value-2",
};
console.log(Object.keys(numericKeys));
// ["1", "2"]현실 세계에서의 예시: 사용자 이름을 포함한 메시지
실무에서는 아래 채팅 컴포넌트처럼 두 데이터 셋이 서로를 참조할 때 map을 사용할 수 있습니다.

메시지와 사용자에 대한 두 개의 배열이 있습니다. 각 메시지는 userId 필드를 통해 작성자에 대한 참조를 갖습니다.
const messages = [
{
id: "message-1",
text: "Hey folks!",
userId: "user-1"
},
{
id: "message-2",
text: "Hi",
userId: "user-2"
},
...
];
const users = [
{
id: "user-1",
name: "Paul"
},
{
id: "user-2",
name: "Lisa"
},
...
];각 메세지를 렌더링할 때 대응되는 사용자를 찾을 수 있을 것입니다.
messages.map(({ id, text, userId }) => {
const name = users.find((user) => user.id === userId).name;
return ... // return JSX
}하지만 이 방법은 모든 메시지에 대해 전체 user 배열을 순회해야 하기 때문에 성능면에서 이상적이지 않습니다. 여기서 우리는 map을 사용할 수 있습니다.
간단한 키-값 객체부터 시작해봅시다. 목표는 아래와 같은 객체를 만드는 것입니다.
{
"user-1": "Paul",
"user-2": "Lisa",
...
}이 객체는 Array.reduce() 함수를 통해 생성할 수 있습니다. (전체 코드는 여기를 참고해주세요)
const messages = [
{
id: "message-1",
text: "Hey folks!",
userId: "user-1"
},
...
];
const users = [
{
id: "user-1",
name: "Paul"
},
...
];
function ChatUsingMap() {
const namesById = users.reduce(
(prev, user) => ({ ...prev, [user.id]: user.name }),
{}
);
return messages.map(({ id, text, userId }) => (
<div key={id}>
<div>{text}</div>
<div>{namesById[userId]}</div>
</div>
));
}또는 진짜 Map을 사용할 수도 있습니다. Map의 생성자는 키-값 쌍의 배열을 인자로 받기 때문에 reduce 함수를 사용하지 않아도 됩니다. (CodeSandbox의 코드는 여기를 참고해주세요)
function ChatUsingMap() {
const namesById = new Map(users.map(({ id, name }) => [id, name]));
return messages.map(({ id, text, userId }) => (
<div key={id}>
<div>{text}</div>
<div>{namesById.get(userId)}</div>
</div>
));
}명확히 짚고 넘어가자면, Map 생성자에 아래와 같은 배열들의 배열을 넘긴 것입니다.
[
["user-1", "Paul"],
["user-2", "Lisa"],
...
]Set
설명
Set 또한 자바스크립트에서 기본적으로 지원되는 키를 갖는 집합입니다. 하지만 Map은 간단하게 말하자면 객체라고 할 수 있지만, Set은 객체보단 배열에 더 가깝습니다. Set의 모든 값은 고유하다는 점에 유의해야 합니다. 값을 두 번 추가할 수 없습니다. 이것이 배열에서 중복 항목을 제거하는 데 Set이 사용되는 이유입니다.
const uniqueValues = [...new Set([1, 1, 2, 3, 3])];
// [1, 2, 3]배열과 비교할 때 주요한 장점은 Set이 값을 포함하고 있는지 더욱 효율적으로 확인할 수 있다는 것입니다.
현실 세계에서의 예시: 선택한 항목 추적
실무에서는 사용자가 선택한 항목을 추적하는 데에 Set을 사용할 수 있습니다. 아래와 같은 table이 있다고 생각해봅시다.
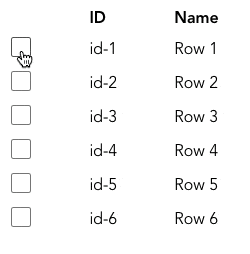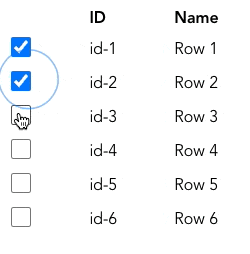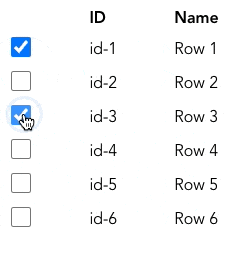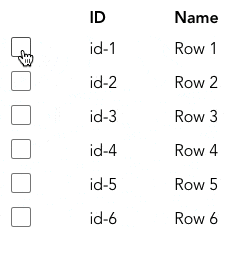
사용자가 항목을 선택하면 해당 항목의 id를 Set에 추가하여 추적합니다. 사용자가 선택을 취소하면 Set에서 제거합니다. (CodeSandbox의 코드는 여기를 참고해주세요)
import { useState } from "react";
const rows = [
{
id: "id-1",
name: "Row 1",
},
{
id: "id-2",
name: "Row 2",
},
...
];
function TableUsingSet() {
const [selectedIds, setSelectedIds] = useState(new Set());
const handleOnChange = (id) => {
const updatedIdToSelected = new Set(selectedIds);
if (updatedIdToSelected.has(id)) {
updatedIdToSelected.delete(id);
} else {
updatedIdToSelected.add(id);
}
setSelectedIds(updatedIdToSelected);
};
return (
<table>
<tbody>
{rows.map(({ id, name }) => (
<tr key={id}>
<td>
<input
type="checkbox"
checked={selectedIds.has(id)}
onChange={() => handleOnChange(id)}
/>
</td>
<td>{id}</td>
<td>{name}</td>
</tr>
))}
</tbody>
</table>
);
}마지막으로 언급하면, Set을 사용하는 것은 배열을 사용하는 것보다 더 좋은 대안이 될 수 있습니다. 우리는 종종 아래와 같이 문제가 있는 방법으로 "항목 선택" 기능을 구현하는 것을 확인할 수 있습니다.
const [selectedRows, setSelectedRows] = useState(
rows.map((row) => ({ selected: false }))
);
const handleOnChange = (index) => {
const updatedSelectedRows = [...selectedRows];
updatedSelectedRows[index] = !updatedSelectedRows[index];
setSelectedRows(updatedSelectedRows);
};얼핏 보았을 때는 직관적이라고 생각할 수 있습니다. 하지만 인덱스로 요소에 접근하는 것은 문제를 일으킬 수 있습니다. 예를 들어 만약 행들이 다른 순서로 정렬될 수 있다면 어떻게 될까요? 싱크를 맞추기 위해 selectedRows또한 같은 방법으로 계속 정렬해주어야 할 것입니다.
Set으로 마이그레이션 하는 것이 얼마나 더 깔끔하고 정제된 코드를 만드는지 확인하고 싶다면 이 세션을 참고해보세요.
Stack
설명
기본적인 stack은 두 가지 특징을 가집니다.
- stack의 상위에 아이템을 추가할 수 있습니다.
- stack의 상위에서부터 아이템을 제거할 수 있습니다.
다른 말로 "후입 선출"(LIFO)라고 하죠. 복잡하다고 생각할 수도 있지만 배열로 간단하게 구현할 수 있습니다(자바스크립트에서 내장하고 있지 않습니다).
const stack = [];
// "상위"에 item을 추가합니다
stack.push("value");
// "상위"에서부터 item을 제거합니다
const topItem = stack.pop();현실 세계에서의 예시: 이전 동작 취소
실무에서 사용자 인터렉션 기록을 추적하여 실행 취소 기능을 구현하고자 할 때 stack을 사용할 수 있습니다. 아래와 같은 사용자가 각 행을 삭제할 수 있는 table을 만드는 것처럼 말입니다.
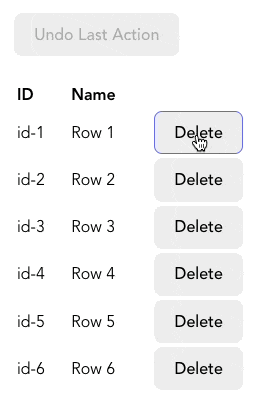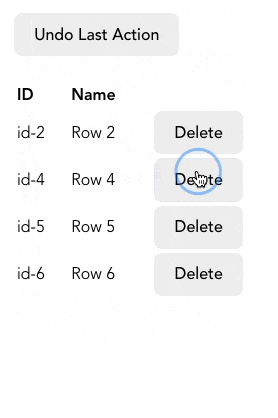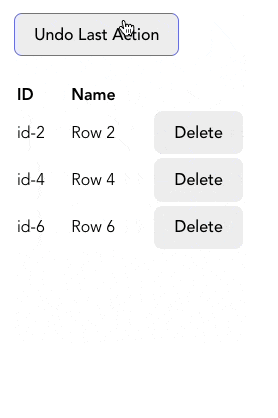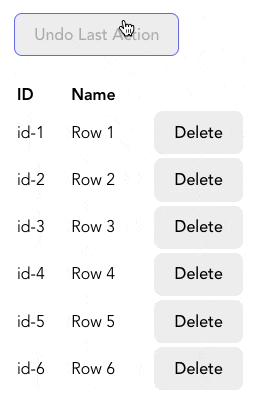
사용자가 행을 삭제할 때마다 history 배열(위에서 만들었던 stack)에 추가합니다. 만약 사용자가 삭제를 취소하고 싶다면 history에서 가장 최근에 추가된 행의 정보를 가져와 table에 다시 추가합니다. 몇몇 함수들은 아래 코드에 없으니 여기 CodeSandbox에서 전체 코드를 참고해주세요.
리액트에서는 데이터가 불변해야 하므로
Array.push()와Array.pop()은 사용할 수 없습니다. 대신 새로운 배열을 반환하는Array.concat()와Array.slice()를 사용합니다.
import { useReducer } from "react";
const rows = [
{
id: "id-1",
name: "Row 1",
},
{
id: "id-2",
name: "Row 2",
},
...
];
// "history"는 우리가 만든 stack입니다
const initialState = { rows, history: [] };
function reducer(state, action) {
switch (action.type) {
case "remove":
return {
rows: removeRow(state, action),
// Array.push() 대신 불변한 Array.concat()을 사용합니다
history: state.history.concat({
action,
row: state.rows[action.index]
})
};
case "undo":
return {
rows: addRowAtOriginalIndex(state),
// Array.pop() 대신 불변한 Array.slice()를 사용합니다
history: state.history.slice(0, -1)
};
default:
throw new Error();
}
}
function TableUsingStack() {
const [state, dispatch] = useReducer(reducer, initialState);
return (
<>
<button
onClick={() => dispatch({ type: "undo" })}
disabled={state.history.length === 0}
>
Undo Last Action
</button>
<table>
<thead>
<tr>
<th>ID</th>
<th>Name</th>
<th></th>
</tr>
</thead>
<tbody>
{state.rows.map(({ id, name }, index) => (
<tr key={id}>
<td>{id}</td>
<td>{name}</td>
<td>
<button onClick={() => dispatch({ type: "remove", id, index })}>
Delete
</button>
</td>
</tr>
))}
</tbody>
</table>
</>
);
}주석에도 적었듯이 여기서 history는 우리가 만든 stack입니다. 사용자가 "Remove" 버튼을 클릭하면 history에 action과 관련 데이터를 추가합니다. "Undo Last Action" 버튼을 클릭하면 제일 최근의 action을 history stack에서 제거한 후 다시 행에 추가합니다.
Queue
설명
queue는 stack과 굉장히 유사합니다. 하지만 마지막에 추가된 항목을 제거하는 대신 제일 먼저 queue에 추가된 항목을 제거합니다. 이는 "선입선출"(FIFO)라고도 부릅니다.
슈퍼마켓에서 줄을 서는 것과 비슷하죠.
queue도 자바스크립트에서 지원하지 않으므로 간단하게 배열을 사용해서 구현할 수 있습니다.
const queueu = [];
// item을 제일 "마지막"에 추가합니다
queueu.push("value");
// item을 제일 "앞부터" 제거합니다
const firstItem = queueu.shift();현실 세계에서의 예시: 알림
실무에서 계속해서 위에 쌓이는 알림을 표시할 때 queue를 사용할 수 있습니다. 화면 하단에 알림창이 나타났다가 일정 시간이 흐른 후에 사라지는 그런 알림이요.
사용자가 가상 커뮤니티에 가입할 때마다 알림창이 나타나는 경우를 생각해봅시다.
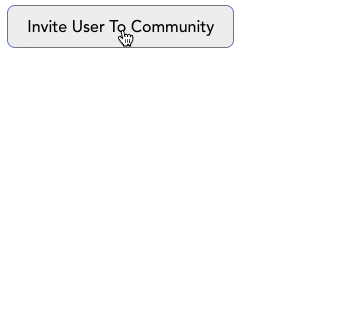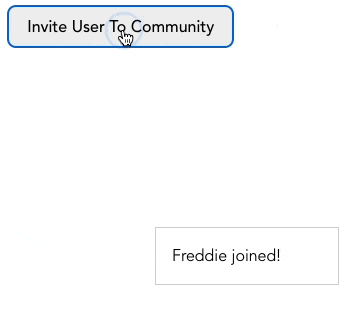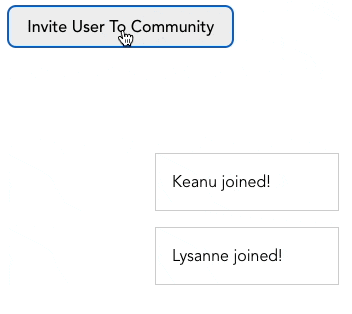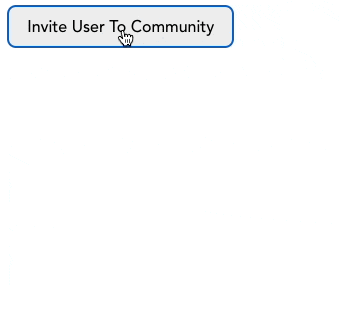
버튼을 클릭하면 notifications 배열(우리가 만든 queue)에 메세지가 추가됩니다. 또한 queue에서 알림을 삭제하는 timeout이 설정되어 있습니다. 전체 코드는 여기 CodeSandbox에서 확인하실 수 있습니다.
import { faker } from "@faker-js/faker";
import { useState } from "react";
function ButtonAddingNotifications() {
const [notifications, setNotifications] = useState([]);
const addNotification = () => {
setNotifications((previous) => {
// Array.push() 대신 불변한 Array.concat()를 사용합니다
= return previous.concat(`${faker.name.firstName()} joined!`);
});
setTimeout(() => {
// Array.shift() 대신 불변한 Array.slice()를 사용합니다
setNotifications((previous) => previous.slice(1));
}, 1000);
};
return (
<>
<button onClick={() => addNotification()}>
Invite User To Community
</button>
<aside>
{notifications.map((message, index) => (
<p key={index}>{message}</p>
))}
</aside>
</>
);
}Tree
설명
tree는 중첩된 자료구조입니다. 자식을 가진 부모로부터 출발하죠. 자식은 다시 자식을 가질 수 있습니다. tree는 종종 재귀 함수와 함께 이야기됩니다.
중첩된 객체에 대한 아래와 같은 예시가 있습니다.
{
name: "Parent",
children: [
{
name: "Child 1",
},
{
name: "Child 2",
children: [
{
name: "Grandchild 21",
}
]
}
]
}tree를 정의하는 방법은 다양합니다. 위 구조 대신 flat array를 사용할 수도 있습니다. 이 경우엔 모든 항목이 ID를 가지고 ID를 통해 참조합니다.
[
{
id: "parent-1",
name: "Parent",
// ID를 통해 자식에 대한 참조를 갖습니다
children: ["child-1", "child-2"],
},
{
id: "child-1",
// ID를 통해 부모에 대한 참조를 갖습니다
name: "Child 1",
parent: "parent-1",
},
{
id: "child-2",
name: "Child 2",
parent: "parent-1",
children: ["grandchild-2"],
},
{
id: "grandchild-21",
name: "Grandchild 21",
parent: "child-2",
},
];사람의 관점에서 한 가지 이상한 부분은 각 자식은 오직 하나의 부모만 가질 수 있다는 것입니다. 따라서 "node"(항목), "child" 및 "edge"(두 항목 사이의 연결)라는 용어도 종종 확인할 수 있습니다.
현실 세계에서의 예시: 중첩된 메뉴 혹은 댓글
위에서 이야기했던 것처럼 tree는 중첩된 자료구조입니다. CMS와 같은 백엔드에 정의된 중첩 메뉴가 있는 경우 tree 형태를 찾을 수 있습니다.

또 다른 일반적인 예는 많은 블로그나 Reddit에서 찾을 수 있는 중첩된 댓글입니다. 이 컴포넌트는 중첩된 tree 구조를 재귀적으로 렌더링합니다. (전체 CodeSandbox 코드는 여기서 확인하실 수 있습니다)
const menuItems = [
{
text: "Menu 1",
children: [
{
text: "Menu 1 1",
href: "#11",
},
{
text: "Menu 1 2",
href: "#12",
},
],
},
{
text: "Menu 2",
href: "#2",
},
{
text: "Menu 3",
children: [
{
text: "Menu 3 1",
children: [
{
id: "311",
text: "Menu 3 1 1",
href: "#311",
},
],
},
],
},
];
// Menu와 MenuItem은 재귀적으로 서로를 호출합니다
function Menu({ items }) {
return (
<ul>
{items.map((item, index) => (
<MenuItem key={index} {...item} />
))}
</ul>
);
}
function MenuItem({ text, href, children }) {
// 중단 조건:
// 해당 항목이 자식이 없을 경우 재귀를 중단합니다
if (!children) {
return (
<li>
<a href={href}>{text}</a>
</li>
);
}
// 재귀적으로 하위 메뉴를 만듭니다
return (
<li>
{text}
<Menu items={children} />
</li>
);
}
// 최상위 컴포넌트
function NestedMenu() {
return <Menu items={menuItems} />;
}위의 중첩된 트리 구조는 사람이 읽기에 비교적 쉽고 렌더링도 간단합니다. 하지만 데이터를 업데이트해야 할 경우 문제가 발생합니다. 특히 데이터를 불변으로 변경해야 할 때(리액트 상태와 마찬가지로) 특히 그렇습니다.
이 경우 좋은 대안은 flat 배열을 사용하는 것입니다. ID 참조를 해결해야 하기 때문에 프런트엔드 로직으로선 조금 더 무겁습니다. 하지만 백엔드와 상호 작용하기가 매우 쉽고 처리하기도 쉽습니다.
const menuItems = [
{
id: "1",
text: "Menu 1",
children: ["11", "12"],
isRoot: true,
},
{
id: "11",
text: "Menu 1 1",
href: "#11",
},
{
id: "12",
text: "Menu 1 2",
href: "#12",
},
{
id: "2",
text: "Menu 2",
href: "#2",
isRoot: true,
},
{
id: "3",
text: "Menu 3",
children: ["31"],
isRoot: true,
},
{
id: "31",
text: "Menu 3 1",
children: ["311"],
},
{
id: "311",
text: "Menu 3 1 1",
href: "#311",
},
];
function Menu({ itemIds, itemsById }) {
return (
<ul>
{itemIds.map((id) => (
<MenuItem key={id} itemId={id} itemsById={itemsById} />
))}
</ul>
);
}
function MenuItem({ itemId, itemsById }) {
const item = itemsById[itemId];
if (!item.children) {
return (
<li>
<a href={item.href}>{item.text}</a>
</li>
);
}
return (
<li>
{item.text}
<Menu itemIds={item.children} itemsById={itemsById} />
</li>
);
}
function NestedMenu() {
const itemsById = menuItems.reduce(
(prev, item) => ({ ...prev, [item.id]: item }),
{}
);
const rootIds = menuItems.filter(({ isRoot }) => isRoot).map(({ id }) => id);
return <Menu itemIds={rootIds} itemsById={itemsById} />;
}재귀 함수는 매우 우아하지만 매우 깊게 중첩된 트리의 경우 자바스크립트 엔진의 호출 스택 크기를 초과할 수 있습니다. 다음은 10962 깊이의 재귀에서 오류가 발생하는 예입니다.
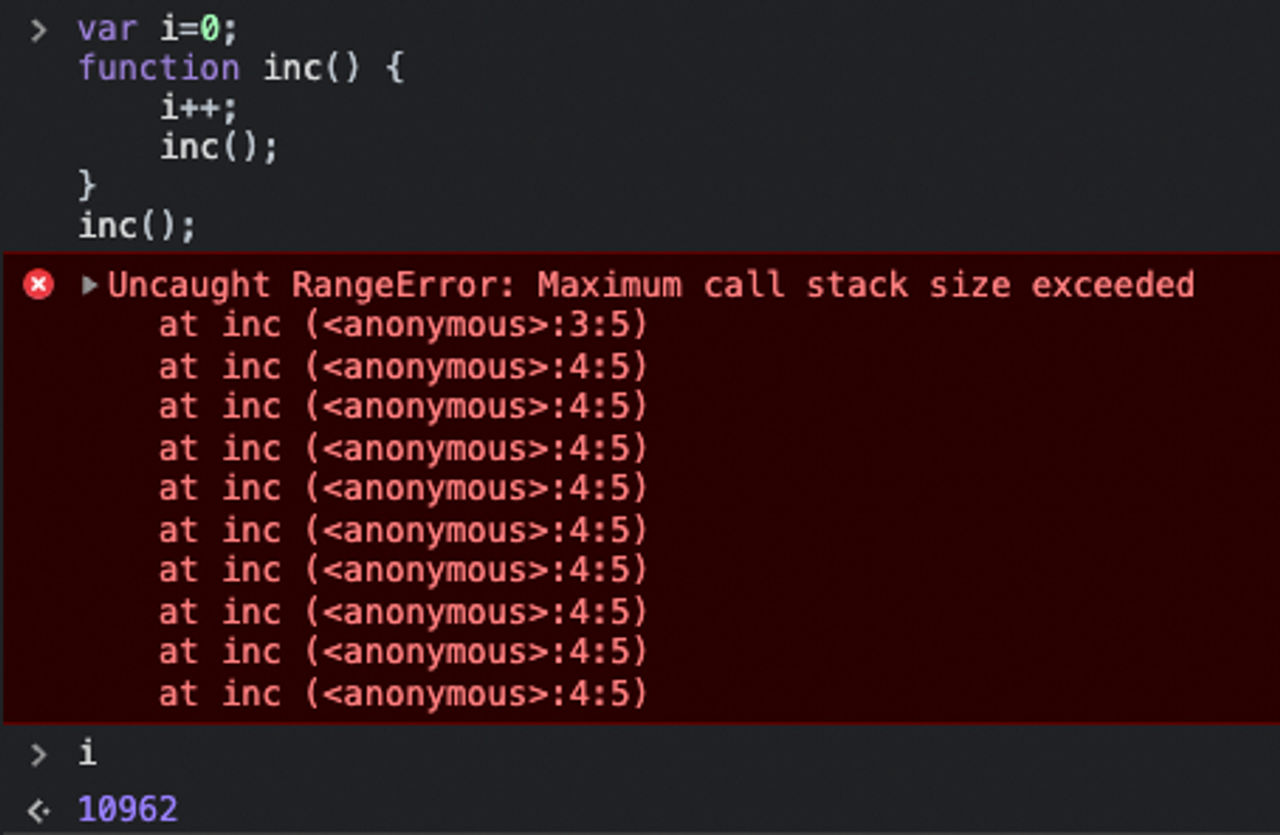
위의 경우에서는 수천 개의 메뉴를 중첩할 일이 없으므로 이러한 에러는 발생하지 않습니다.





좋은 글 잘 읽었습니다!