
지난주 reactjs에는 프로미스를 일급(first class)으로서 지원하고자 하는 새로운 RFC가 작성되었는데요. 해당 스레드에는 만약 잘못 사용될 경우 페치 워터폴(waterfall)을 야기할 수 있음을 지적하며 논의가 진행되고 있습니다. 페치 워터폴이란 정확히 무엇일까요?
페치 워터폴 (Fetch waterfalls)
워터폴은 하나의 요청이 이루어지고 이 요청이 완료될 때까지 다른 요청을 실행하지 않고 기다리는 상황을 나타냅니다.
때때로 첫 번째 요청이 두 번째 요청을 실행하는 데 필요한 정보를 가지고 있는 경우, 이런 상황은 불가피합니다. Tanstack Query에서는 이런 경우를 종속 쿼리라고 합니다.
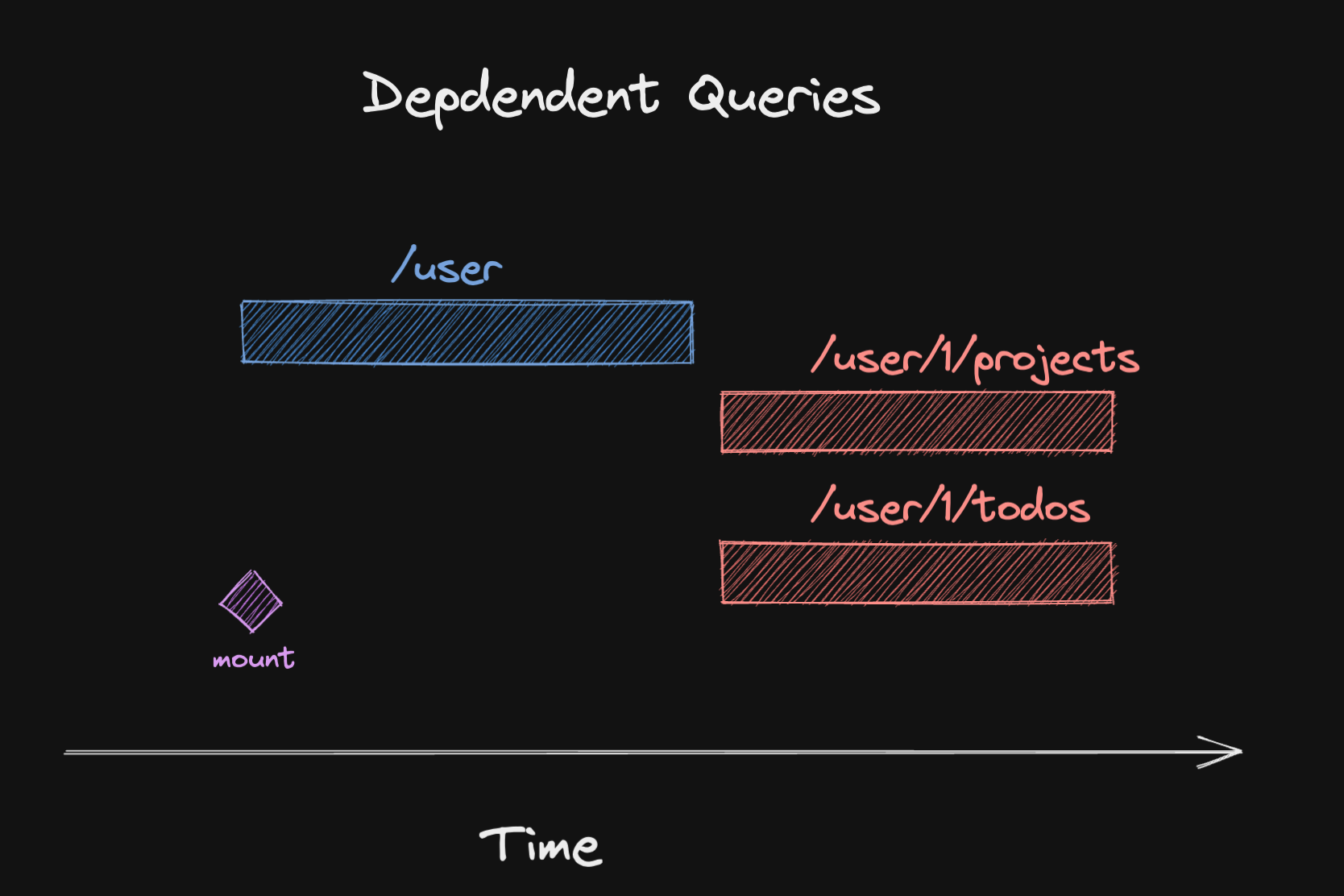
그러나 대부분의 경우는 독립적인 데이터이기 때문에 필요한 모든 데이터를 병렬로 페치할 수 있습니다.
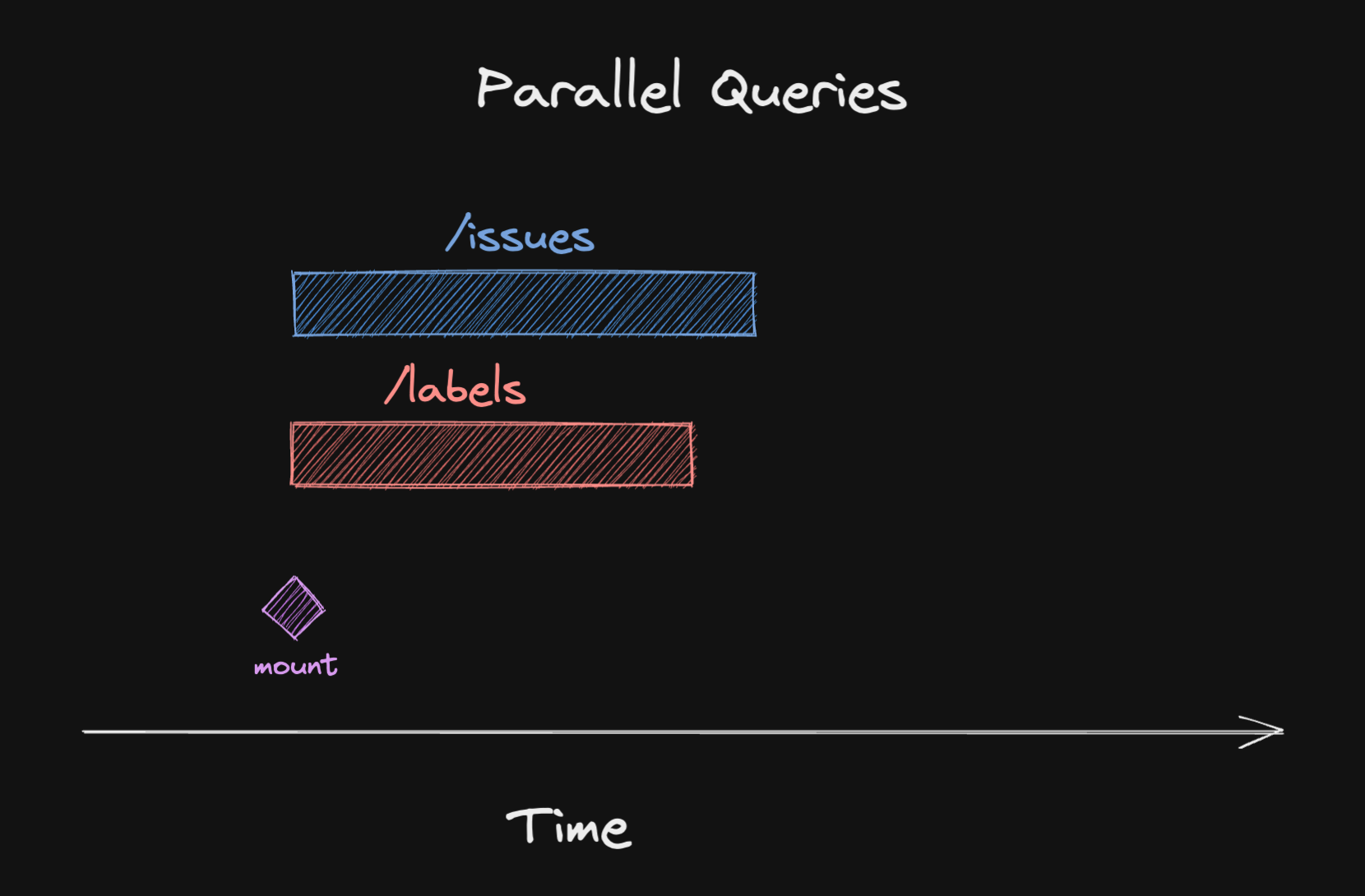
리액트 쿼리에서는 다음의 두 가지 방법으로 데이터를 병렬 페치할 수 있습니다.
// 1. useQuery를 두 번 사용합니다
const issues = useQuery({ queryKey: ["issues"], queryFn: fetchIssues });
const labels = useQuery({ queryKey: ["labels"], queryFn: fetchLabels });
// 2. useQueries 훅을 사용합니다
const [issues, labels] = useQueries([
{ queryKey: ["issues"], queryFn: fetchIssues },
{ queryKey: ["labels"], queryFn: fetchLabels },
]);두 가지 방법 모두 리액트 쿼리는 데이터를 병렬로 페칭할 것입니다. 그렇다면 어디서 워터폴이 발생하는 것일까요?
서스펜스(Suspense)
주의: 이 글을 쓰는 지금도 데이터 페칭에 대한 서스펜스는 여전히 실험적이라는 것을 명심하세요! 이어지는 예제는 RFC에 제안된 것이 아닌 이미 리액트 쿼리에서 사용 가능한 서스펜스 구현을 사용할 것입니다.(이 또한 실험 기능입니다)
위의 링크된 RFC에 설명된 것처럼, 서스펜스는 리액트에서 프로미스를 풀기 위한 방법입니다. 프로미스의 특성은 보류(pending), 이행(fulfilled), 거부(rejected)의 세 가지 상태에 있을 수 있다는 것입니다.
컴포넌트를 렌더링할 때 우리는 대부분 성공 시나리오에 관심이 있습니다. 각 컴포넌트에서 로딩 및 에러를 처리하는 것은 지루할 수 있으며 서스펜스는 이 문제를 해결하는 데 목적이 있습니다.
프로미스가 보류 중인 경우 리액트는 컴포넌트 트리를 언마운트 시키고 서스펜스 경계 컴포넌트에 정의되어 있는 폴백을 렌더링합니다. 에러의 경우엔 해당 에러가 가장 가까운 에러 경계까지 올라갑니다.
이로써 컴포넌트가 상태들을 관리하는 것으로부터 분리시킬 수 있으며 성공 시나리오에만 집중할 수 있게 됩니다. 이는 마치 캐시에서 값을 읽는 동기 코드처럼 동작합니다.
function Issues() {
// 👓 캐시에서 데이터를 읽어옵니다
const { data } = useQuery({
queryKey: ["issues"],
queryFn: fetchIssues,
// ⬇️ 해당 옵션으로 실험 기능인 서스펜스 모드를 사용할 수 있습니다
suspense: true,
});
// 🎉 로딩이나 에러 상태를 관리할 필요가 없습니다
return (
<div>
{data.map((issue) => (
<div>{issue.title}</div>
))}
</div>
);
}
function App() {
// 🚀 서스펜스와 에러 경계에서 로딩과 에러 상태를 처리합니다
return (
<Suspense fallback={<div>Loading...</div>}>
<ErrorBoundary fallback={<div>On no!</div>}>
<Issues />
</ErrorBoundary>
</Suspense>
);
}타입스크립트 관련 참고 사항
안타깝게도 타입스크립트를 사용할 때 suspense는 마음대로 켜고 끌 수 있는 useQuery의 플래그일 뿐이기 때문에 위의 예시에서 data가 잠재적으로 undefined일 수 있습니다. 또한 enabled 옵션과 결합하면 쿼리가 실행되지 않고, 따라서 컴포넌트가 아예 서스펜스 되지 않을 수도 있습니다.
React Query에서는 나중에 전용 useSuspenseQuery 훅을 만들어 변경할 것도 고려하고 있습니다.
서스펜스 워터폴(Suspense waterfalls)
하지만 서스펜스가 사용된 하나의 컴포넌트에서 여러 개의 쿼리를 사용할 경우엔 오히려 역효과가 날 수 있습니다. 다음과 같은 상황입니다.
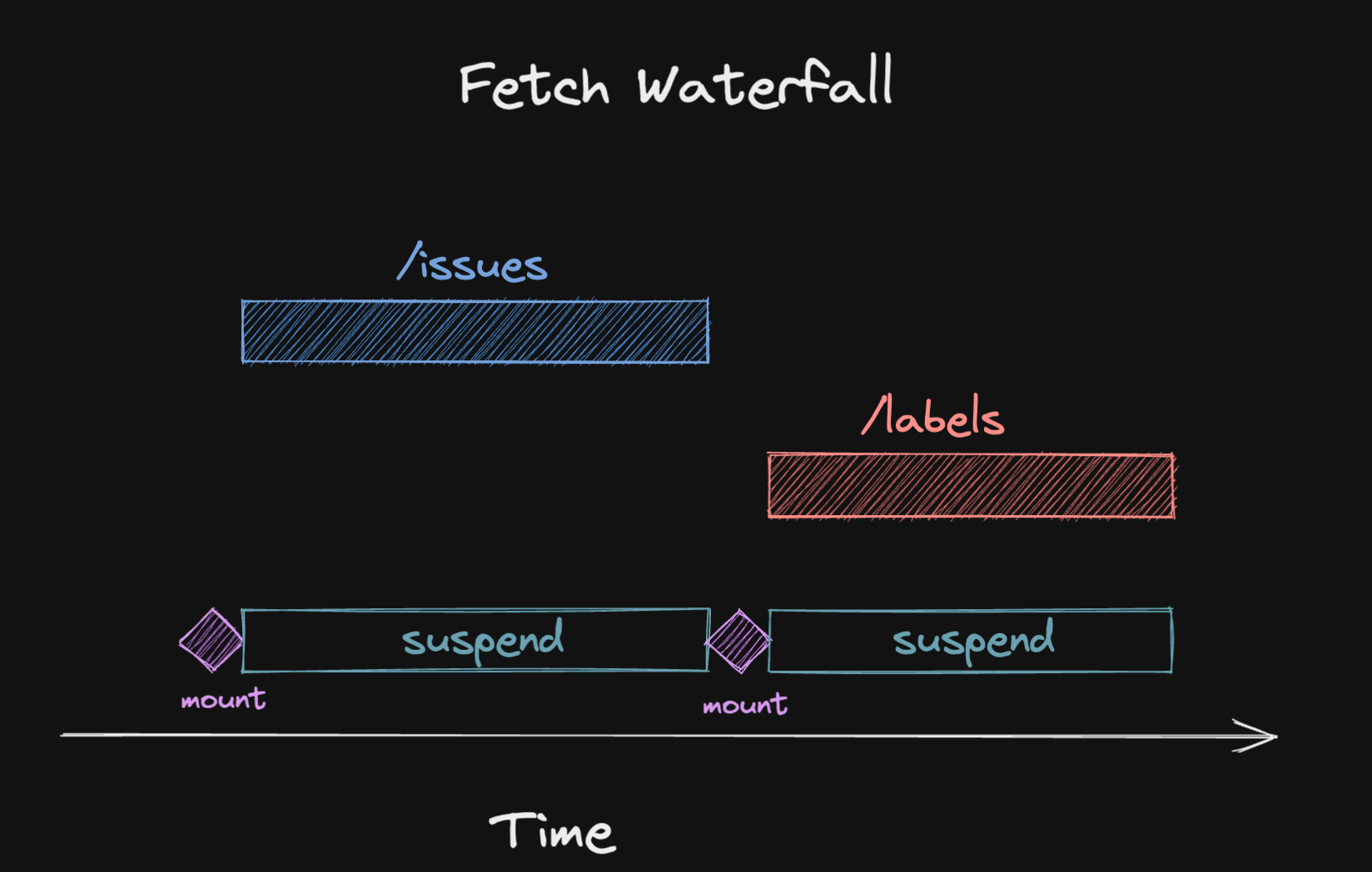
- 컴포넌트가 렌더링되고 첫 번째 쿼리를 읽으려 시도합니다
- 캐싱된 데이터가 아직 없다는 것을 확인하고 보류시킵니다
- 컴포넌트 트리를 언마운트 시키고 폴백을 렌더링 합니다
- 페칭이 완료되면 다시 컴포넌트 트리가 마운트 됩니다
- 이제 첫 번째 쿼리는 캐시로부터 데이터를 읽어올 수 있습니다
- 컴포넌트는 두 번째 쿼리를 만나고 읽으려 시도합니다
- 두 번째 쿼리는 캐싱된 데이터가 없으므로 (또) 보류합니다
- 두 번째 쿼리가 페칭됩니다
- 드디어 컴포넌트가 온전하게 렌더링 됩니다
필요 이상으로 너무 기이이인 시간 동안 폴백을 보게 되기 때문에 애플리케이션 성능에 상당한 영향을 미치게 됩니다.
이 문제를 피하는 가장 좋은 방법은 컴포넌트가 데이터를 읽으려 할 때 데이터가 이미 캐싱되어 있도록 하는 것입니다.
프리페칭(Prefetching)
페칭은 빨리 시작할수록 더 좋습니다. 빨리 시작할수록 더 빨리 완료될 수 있기 때문입니다. 🤓
- 만약 서버 사이드 렌더링을 지원한다면 - 서버에서 페칭하는 것을 고려해보세요
- 만약 loaders를 지원하는 라우터를 사용한다면, loader에서 프리페칭하는 것을 고려해보세요
이 두 가지가 아니더라도, prefetchQuery를 사용하면 컴포넌트가 렌더링 되기 전에 페칭을 시작할 수 있습니다.
const issuesQuery = { queryKey: ["issues"], queryFn: fetchIssues };
// ⬇️ 컴포넌트가 렌더링 되기 전에 페칭을 시작합니다
queryClient.prefetchQuery(issuesQuery);
function Issues() {
const issues = useQuery(issuesQuery);
}prefetchQueries는 자바스크립트 번들이 평가되는 즉시 실행됩니다. 이는 라우트 기반 코드 스플리팅을 적용하는 경우 매우 잘 동작하는데, 사용자가 해당 페이지로 이동하는 즉시, 코드가 지연 로딩되고 평가되기 때문입니다.
이는 컴포넌트가 렌더링 되기 전에 시작됩니다. 위의 예제에서 두 쿼리 모두에 대해 프리페칭을 적용하면 서스펜스를 사용하는 경우에도 병렬 쿼리를 다시 사용할 수 있게 됩니다.
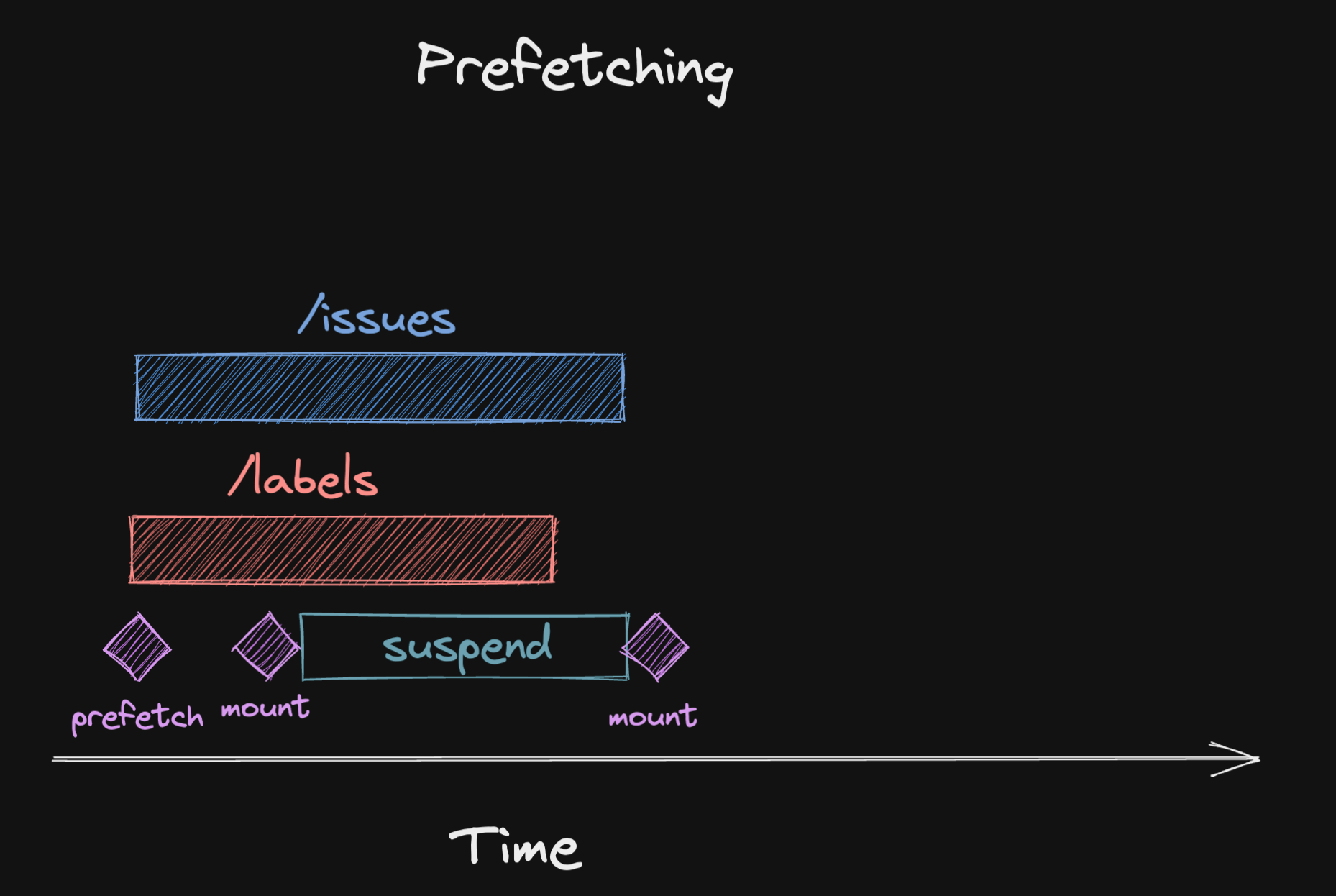
이미지에서 볼 수 있듯이 아예 보류하지 않는 것은 아닙니다. 두 쿼리 모두 페칭이 완료될 때까지 보류 시간은 존재하나, 병렬로 진행되기 때문에 대기 시간을 크게 단축시킬 수 있습니다.
주의: useQueries는 아직 suspense를 지원하지 않지만 추후에 추가될 가능성이 있습니다. 만약 지원하게 된다면 워터폴을 피하기 위해 모든 페치를 병렬적으로 실행시키는 것이 목표입니다.
use RFC
아직 제대로 코멘트할 수 있을 정도로 RFC에 대해 자세히 알지는 못합니다. 캐시 API가 어떻게 동작할 것인지와 같은 큰 부분이 여전히 빠져 있습니다. 개발자가 캐시를 초기에 명시적으로 주입하지 않는 한 기본 동작이 워터폴로 이어진다는 것은 조금 문제가 있다고 생각합니다. 하지만 React Query의 내부를 이해하고 유지하기 쉽게 만들 수 있기 때문에 기대가 됩니다. 사용자들에게 많이 활용될 수 있을지는 두고 봐야 할 것 같습니다.
리스트로 상세 데이터 채워 넣기
캐시가 읽힐 시점에 확실히 캐시가 존재하도록 하는 또 다른 좋은 방법은 다른 부분의 캐시에서 채워 넣는 것입니다. 항목의 상세 보기를 렌더링하는 경우, 이전에 항목의 리스트를 보여줘야 했기 때문에 이미 관련 데이터를 가지고 있을 것입니다.
리스트 캐시의 데이터로부터 상세 데이터의 캐시를 채울 수 있는 두 가지 방법이 있습니다.
Pull 접근법
이 방법은 공식 문서에도 적혀있는 방법입니다. 상세 보기를 렌더링할 때 리스트 캐시를 검색해 렌더링 하고자 하는 항목을 찾습니다. 해당 데이터가 있으면 상세 보기 쿼리의 초기 데이터로 사용합니다.
const useTodo = (id: number) => {
const queryClient = useQueryClient();
return useQuery({
queryKey: ["todos", "detail", id],
queryFn: () => fetchTodo(id),
initialData: () => {
// ⬇️ 리스트 캐시에서 아이템을 찾습니다\
return queryClient
.getQueryData(["todos", "list"])
?.find((todo) => todo.id === id);
},
});
};만약 initialData 함수가 undefined를 반환한다면 쿼리는 정상적으로 진행되고 서버에서 데이터를 가져옵니다. 만약 데이터를 찾았다면 캐시에 직접 저장됩니다.
staleTime이 설정되어 있다면 initialData가 fresh하다고 판단되기 때문에 더 이상 백그라운드에서 리페치가 일어나지 않는다는 점에 유의하세요. 20분 전에 리스트를 가져온 경우 원하는 정확한 데이터가 아닐 수 있습니다.
공식문서에 나와있는 것처럼, 상세 데이터 쿼리에 initialDataUpdatedAt을 명시할 수 있습니다. 이는 initialData로 전달하는 데이터가 페칭되었을 때 리액트 쿼리에게 알려주기 때문에 정확하게 stale 여부를 판단할 수 있습니다. 편리하게도 리액트 쿼리는 리스트가 언제 마지막으로 페칭되었는지 알기 때문에, 우리는 이를 전달해주기만 하면 됩니다.
const useTodo = (id: number) => {
const queryClient = useQueryClient();
return useQuery({
queryKey: ["todos", "detail", id],
queryFn: () => fetchTodo(id),
initialData: () => {
return queryClient
.getQueryData(["todos", "list"])
?.find((todo) => todo.id === id);
},
initialDataUpdatedAt: () =>
// ⬇️ 리스트가 마지막으로 페칭된 시간을 가져옵니다
queryClient.getQueryState(["todos", "list"])?.dataUpdatedAt,
});
};🟢 "시간에 맞춰" 캐시를 채워 넣습니다
🔴 staleness를 처리하기 위해 추가 작업이 필요합니다
Push 접근법
또 다른 방법으로는, 리스트 쿼리를 페치할 때마다 상세 데이터 캐시를 만들 수 있습니다. 이 방법은 리스트가 페치될 때마다 상세 데이터 캐시를 만들기 때문에 자동으로 staleness가 업데이트된다는 장점이 있습니다.
하지만 쿼리가 페치됐을 때 콜백을 받을 좋은 방법이 없다는 단점이 있습니다. useQuery의 onSuccess로 동작은 하겠지만 모든 useQuery 인스턴스에서 실행되게 됩니다. 만약 관찰자가 여러 명인 경우 동일한 데이터가 캐시에 여러 번 기록될 수 있습니다. 캐시 자체의 글로벌 onSuccess 콜백도 동작할 수는 있지만 모든 쿼리에 대해 실행되므로 올바른 쿼리 키로 범위를 좁혀야 합니다.
push 접근법을 실행하기 위해 제가 찾은 제일 좋은 방법은 queryFn에서 데이터가 페치된 후 직접 실행하는 것입니다.
const useTodos = () => {
const queryClient = useQueryClient();
return useQuery({
queryKey: ["todos", "list"],
queryFn: async () => {
const todos = await fetchTodos();
todos.forEach((todo) => {
// ⬇️ 각 아이템에 대한 상세 캐시를 만듭니다.
queryClient.setQueryData(["todos", "detail", todo.id], todo);
});
return todos;
},
});
};이렇게 하면 리스트로부터 각 아이템의 상세 내용을 바로 생성하게 됩니다. 당시는 해당 쿼리가 필요한 곳이 없으므로 정해진 캐싱시간(기본: 15분)이 지나면 가비지 콜렉팅되는 비활성 상태로 존재합니다.
따라서 push 접근법을 사용하면 사용자가 막상 상세 보기 뷰로 이동했을 때 해당 데이터가 더 이상 존재하지 않을 가능성도 있습니다. 또한 가지고 있는 리스트가 너무 길다면 필요로 하지 않는 엔트리를 너무 많이 만들게 될 가능성도 있습니다.
🟢 staleTime이 자동으로 적용됩니다
🟡 적절한 콜백이 존재하지 않습니다
🟡 필요하지 않은 캐시 엔트리를 생성할 가능성이 있습니다
🔴 푸시된 데이터가 너무 빨리 가비지 콜렉팅 될 수 있습니다
상세 데이터의 쿼리 구조가 리스트 쿼리의 구조와 정확히 동일한 경우(혹은 적어도 할당 가능한 경우)에만 두 가지 접근 방식이 모두 제대로 작동한다는 점에 유의하세요. 만약 상세 데이터에 필수적인 데이터가 리스트에 존재하지 않는다면 initialData에 데이터를 넣는 것은 좋은 아이디어가 아닙니다. 이것이 placeholderData가 존재하는 이유이며 두 가지에 대한 비교를 #9:리액트 쿼리에서 플레이스 홀더와 초기 데이터에 작성해두었으니 참고해주세요.

컴포넌트를 렌더링할 때 우리는 대부분 성공 시나리오에 관심이 있습니다. 각 컴포넌트에서 로딩 및 에러를 처리하는 것은 지루할 수 있으며 서스펜스는 이 문제를 해결하는 데 목적이 있습니다.
www.landstaronline.com