
이 문서는 로지스틱 회귀(Logistic Regression)에 대해 강의를 들으면서 정리한 내용입니다.
처음엔 선형 회귀랑 뭐가 다른지 혼동했는데, 확률 기반 분류라는 점과
시그모이드 함수, 코스트 펑션(Log Loss)의 구조가 꽤 직관적으로 이어져 있어서 따로 정리해두기로 했습니다.
로지스틱 회귀 (Logistic Regression) 정리
1. 기본 개념
로지스틱 회귀는 바이너리 분류(binary classification) 문제를 푸는 대표적인 알고리즘입니다.
- 선형 회귀 → 결과값이 연속적인 수치
- 로지스틱 회귀 → 결과값이 범주형(클래스)
(예: 0 또는 1, 스팸/정상, 합격/불합격)
2. 왜 선형 회귀로는 안 되는가?
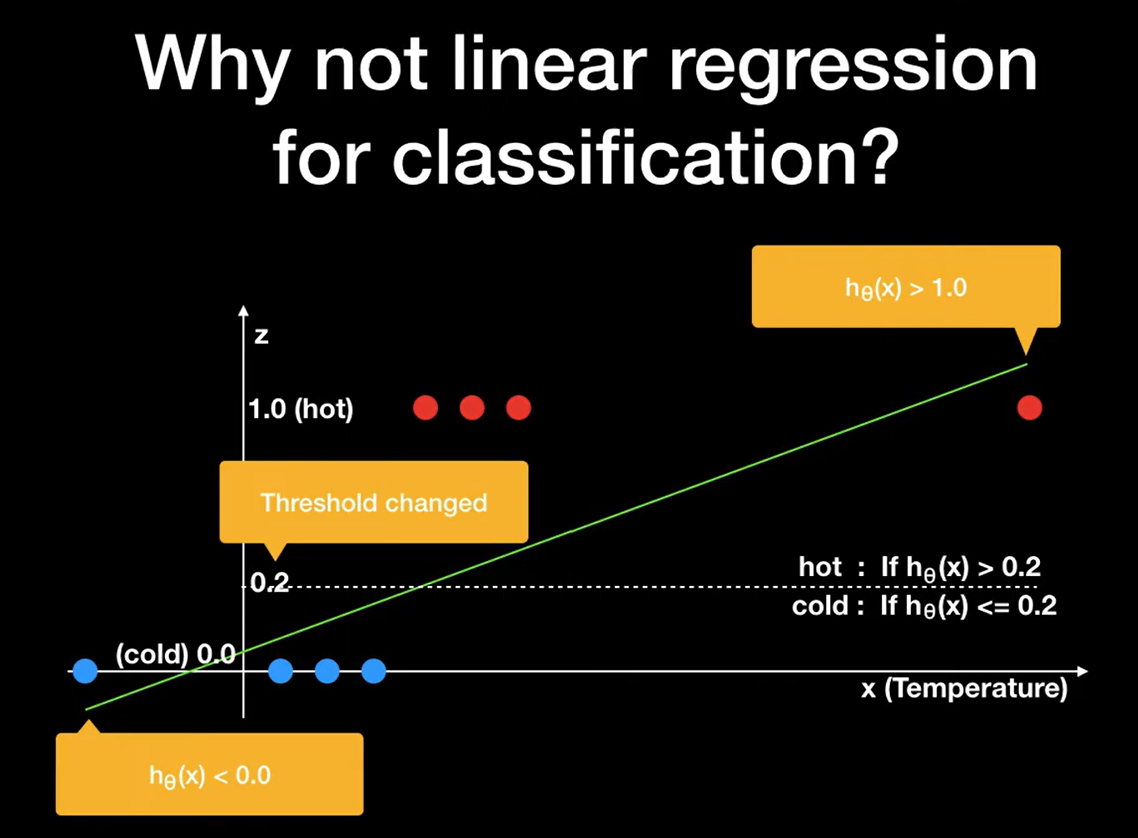
처음엔 선형 회귀를 써도 되지 않나 싶었는데,
중간에 깨달은 문제점들이 아래와 같음:
- 선형 회귀는 예측값이 0~1 범위를 벗어날 수 있음
- 클래스 경계를 명확하게 나누지 못함
- 확률 해석이 어려움
그래서 출력을 0~1 사이로 제한하는 시그모이드(Sigmoid) 함수를 적용해야 함.
3. 시그모이드 함수란?
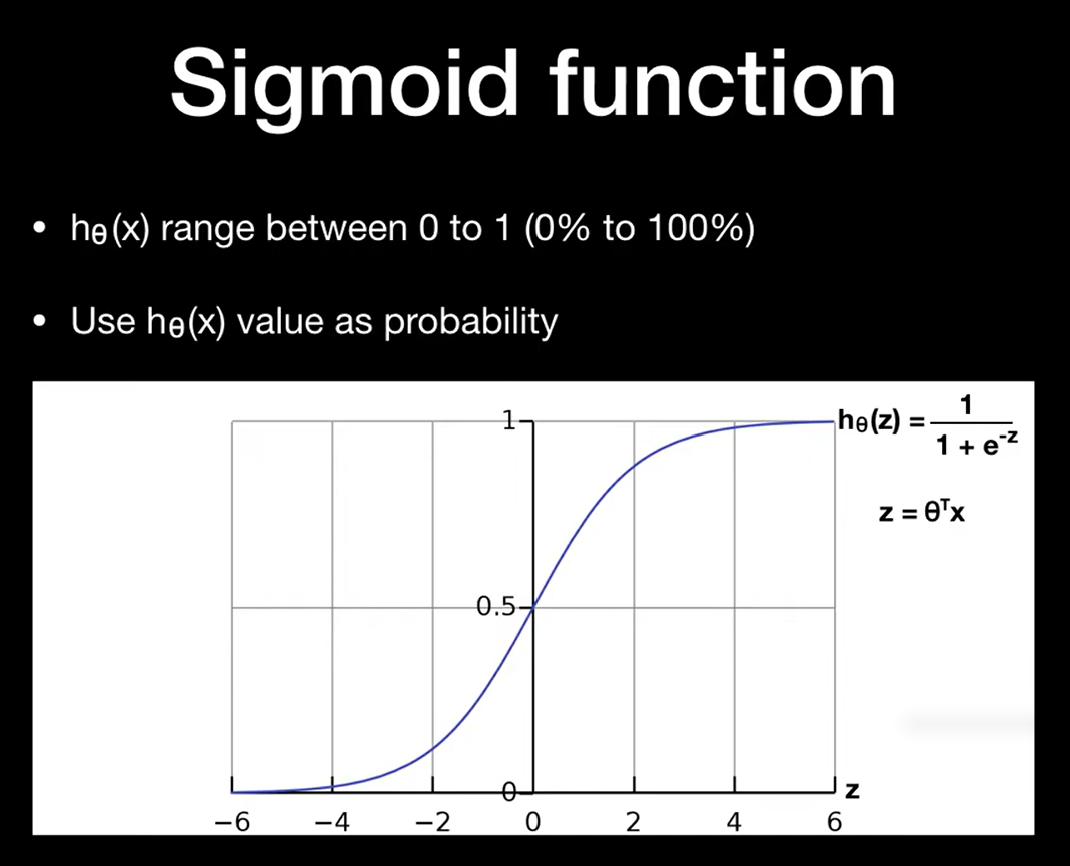
시그모이드는 아래와 같은 함수:
σ(z) = 1 / (1 + e^{-z})- z는 선형 모델의 출력값 (ex. θᵀx)
- 출력은 항상 0과 1 사이
→ 따라서 확률로 해석 가능
이 함수 덕분에 출력값이 0.5 이상이면 클래스 1,
아니면 클래스 0으로 분류할 수 있음
4. 최적화를 위한 Cost Function
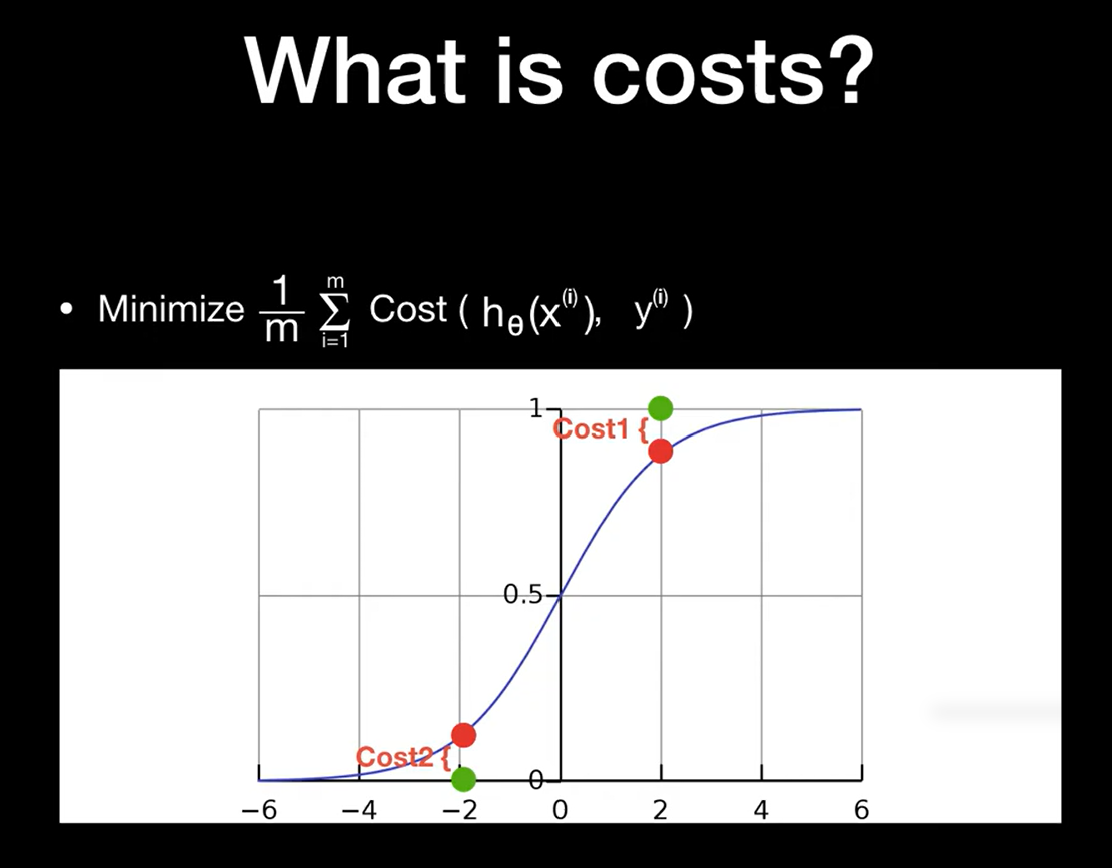
여기서 제일 중요한 게 "어떻게 좋은 가중치(θ)를 찾을 것인가"입니다.
선형 회귀에서는 MSE(Mean Squared Error)를 사용했지만,
로지스틱 회귀에서는 아래의 Log Loss (또는 Cross Entropy)를 사용합니다:
5. Log Loss 수식
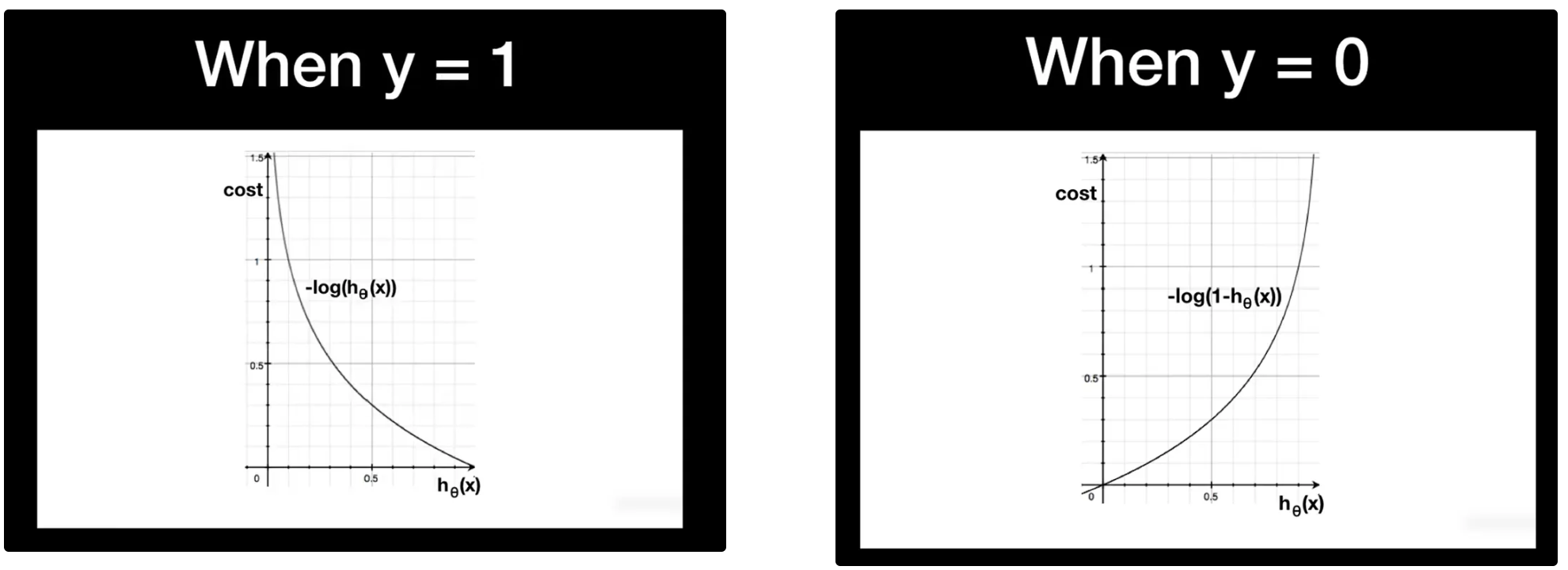
J(θ) = - [ y log(h_θ(x)) + (1 - y) log(1 - h_θ(x)) ]- y: 실제 클래스 (0 또는 1)
- h_θ(x): 시그모이드 출력값 (예측 확률)
이해 포인트:
- 예측이 정확할수록 → Log Loss는 작아짐 (최소는 0)
- 예측이 틀릴수록 → Log Loss는 커짐 (벌점)
6. 예제 상황별 해석
| 예측값(h) | 실제값(y) | Cost |
|---|---|---|
| 0.9 | 1 | 매우 낮음 |
| 0.1 | 1 | 매우 높음 |
| 0.5 | 0 or 1 | 중간 정도 |
| 1.0 | 1 | 0 (완벽 예측) |
그래서 확률 기반 판단이 가능함 (예: 50% 이상이면 1)
7. 한 줄 정리
- 로지스틱 회귀는 선형 모델의 출력값을 시그모이드에 넣어서
분류 경계(0 또는 1)로 해석함 - 그 출력은 확률로 생각할 수 있음
- MSE 대신 Log Loss를 사용해서 예측 정확도를 평가하고,
경사 하강법(Gradient Descent)으로 파라미터 θ를 학습함
8. 내가 느낀 점 요약
- 로지스틱 회귀는 "이진 분류"를 확률 기반으로 풀 수 있다는 점이 핵심
- 수식도 복잡하지 않고, 시그모이드 함수 하나로 분류 + 확률 해석을 동시에 할 수 있음
- 특히 Log Loss는 직관적으로 예측이 틀릴수록 페널티가 커져서
실제 문제에서 학습 효율을 높이기에 좋음

기록과 회고를 통해 성장하는 데이터, AI 엔지니어 지망생입니다.