
⭐️ 시간복잡도가 O(NlogN)인 정렬
시간복잡도가 O(NlogN)인 정렬은 퀵 정렬, 병합 정렬, 힙 정렬이 있다.
해당 정렬들은 시간복잡도가 O(N^2)인 정렬보다 대체로 구현하기 어렵다.
1️⃣ 퀵 정렬 (Quick Sort)
- 분할 정복 기법(devide and conquer)을 사용한 정렬로 평균적으로 아주 빠른 성능을 갖는 알고리즘이다.
- 기준 데이터를 설정하고 그 기준보다 큰 데이터와 작은 데이터의 위치를 바꾸는 방법이다.
- 일반적인 상황에서 가장 많이 사용되는 정렬 알고리즘 중 하나이다.
- 병합 정렬과 더불어 대부분의 프로그래밍 언어의 정렬 라이브러리의 근간이 되는 알고리즘이다.
- 퀵 정렬은 일반적으로 첫 번째 데이터를 기준 데이터(Pivot)로 설정한다.
👇 퀵 정렬
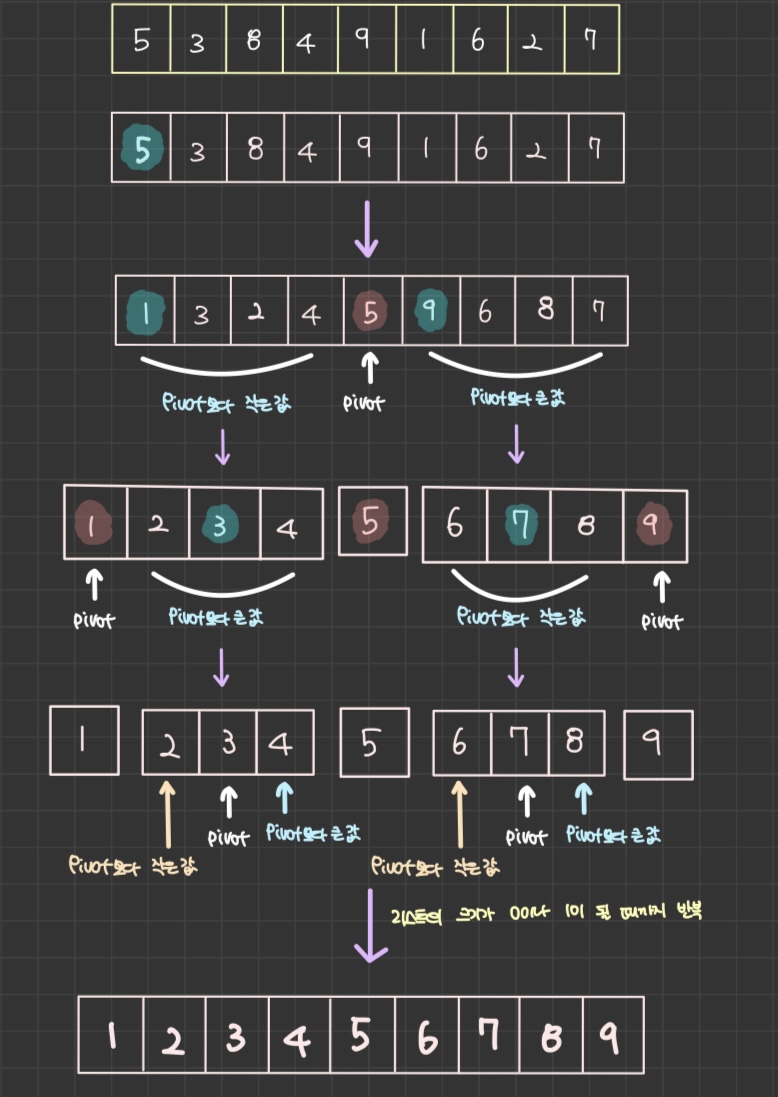
✅ 정렬방법
- 주어진 리스트에서 하나의 원소를 고른다. (피벗)
- 피벗을 기준으로 두 개의 파티션으로 분할한다. 파티션 1: 피벗보다 작은 원소, 파티션 2: 피벗보다 큰 원소
- 분할된 파티션에 대해서도 리스트의 크기가 0혹은 1이 될 때까지 1, 2 과정을 반복한다.
- 다른 원소와의 비교만으로 정렬을 수행하며 퀵 정렬은 n개의 데이터를 정렬할 때, 최악의 경우에는 O(n^2)번의 비교를 수행하고, 평균적으로 O(N log N) 번의 비교를 수행한다.
→ 분명한 반복적인 패턴이 있기 때문에 재귀를 이용해서 구현한다.
def quick_sort(arr):
if not arr:
return arr
# 임의로 하나의 피벗을 지정하며 해당 경우는 배열의 마지막 원소
pivot = arr.pop()
left = []
right = []
# 반복문을 사용해서 피벗 기준으로 배열을 2개로 나눔
for i in range(len(arr)):
if arr[i] < pivot:
left.append(arr[i])
else:
right.append(arr[i])
return quick_sort(left) + [pivot] + quick_sort(right)✨ 특징
- 제자리 정렬 알고리즘으로 정렬에 사용되는 추가적인 저장공간이 매우 작다.
- 불안정적인 정렬이기 때문에 같은 값일 때 순서가 변경될 수 있다.
2️⃣ 합병 정렬 (Merge Sort)
퀵 정렬과 마찬가지로 합병 정렬은 분할 정복 기법(divide and conquer)을 사용한 정렬이다. 일반적인 방법으로 구현했을 때 이 정렬은 안정 정렬에 속한다.
퀵 정렬과의 차이점은 퀵, 정렬의 경우 가장 큰 부분 리스트로부터 시작해서 가장 작은 부분 리스트에서 종료되지만 합병 정렬의 경우 가장 작은 부분 리스트로부터 시작해서 가장 큰 부분 리스트에서 종료된다.
퀵 정렬 - 스택 필요, 불안정적인 정렬, 정복 → 분할
합병 정렬 - 스택 불필요, 안정적인 정렬 (같은 값이어도 정렬 후 순서가 변하지 않음), 분할 → 정복
👇 합병 정렬
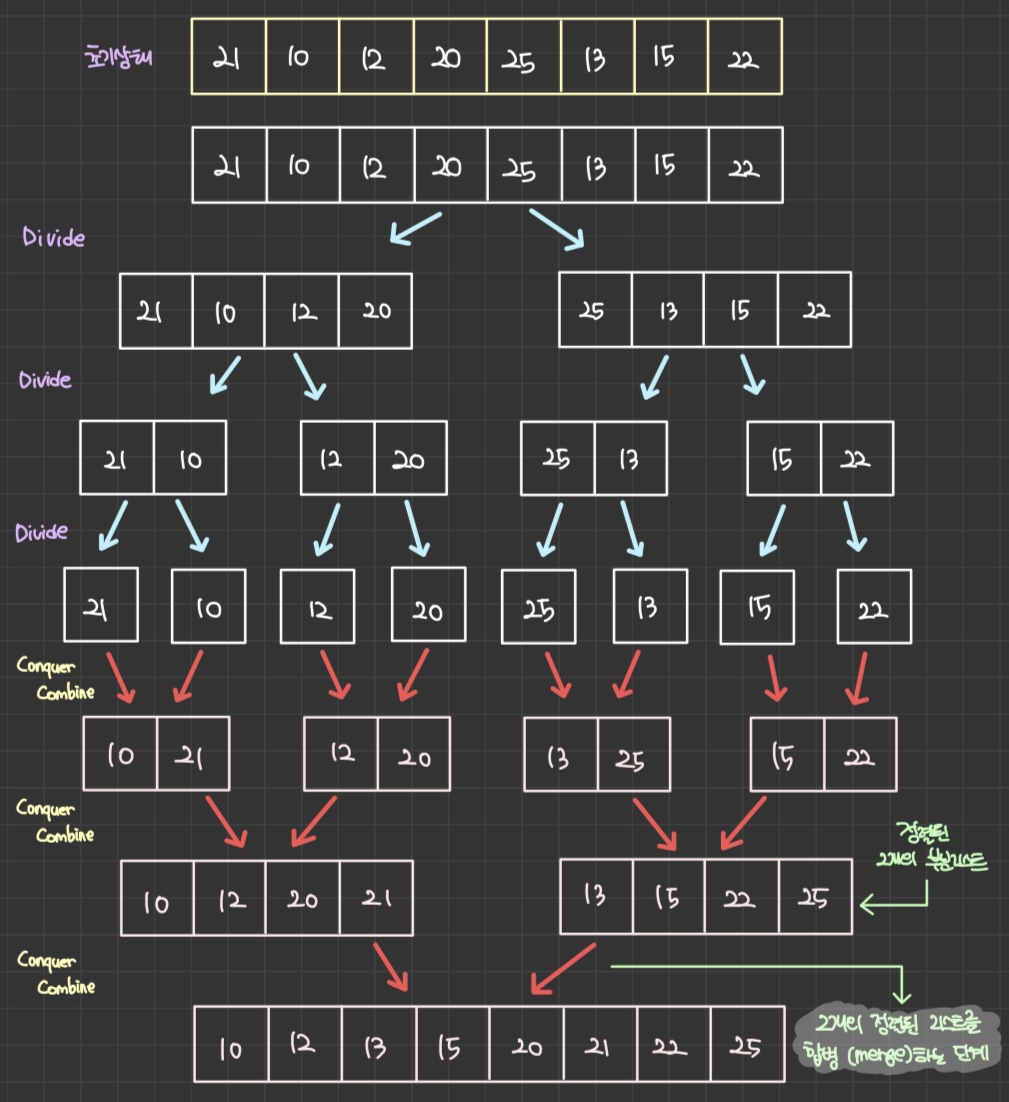
✅ 정렬 방법
- 리스트의 크기가 1이 될 때까지 분할한다.
- 부분 리스트를 합병한다.
- 이때 두 부분리스트 원소의 크기를 비교해가며 합병하기 때문에 정렬된 형태로 합병되어 나가진다.
def merge_sort(arr):
if len(arr) < 2:
return arr
mid = len(arr) // 2
low_arr = merge_sort(arr[:mid])
high_arr = merge_sort(arr[mid:])
merged_arr = []
low = high = 0
while low < len(low_arr) and high < len(high_arr):
if low_arr[low] < high_arr[high]:
merged_arr.append(low_arr[low])
low += 1
else:
merged_arr.append(high_arr[high])
high += 1
merged_arr += low_arr[low:]
merged_arr += high_arr[high:]
return merged_arr✨ 특징
- 안정적인 정렬로 같은 값이어도 정렬 후 순서가 변하지 않음
3️⃣ 힙 정렬 (Heap Sort)
최대 힙 트리나 최소 힙 트리를 구성해 정렬하는 방법으로, 내림차순 정렬을 위해서는 최대 힙을 구성하고 오름차순 정렬을 위해서는 최소 힙을 구성한다.
- 완전 이진 트리의 일종으로 우선순위 큐를 위하여 만들어진 자료구조
- 최댓 값, 최솟 값을 쉽게 추출할 수 있는 자료구조
👉 힙 정렬은 주어진 리스트를 최대 힙의 자료구조 형태로 만들고 정렬을 하는 것이다. 힙의 자료구조에서 배열의 첫 번째에는 배열의 가장 큰 수가 오게 된다. 그 후에는 배열의 첫 번째 원소를 가장 뒤로 보내고, 배열의 가장 마지막 원소를 제외한 배열을 다시 최대 힙을 만들어주는 것이다.
👇 힙 정렬
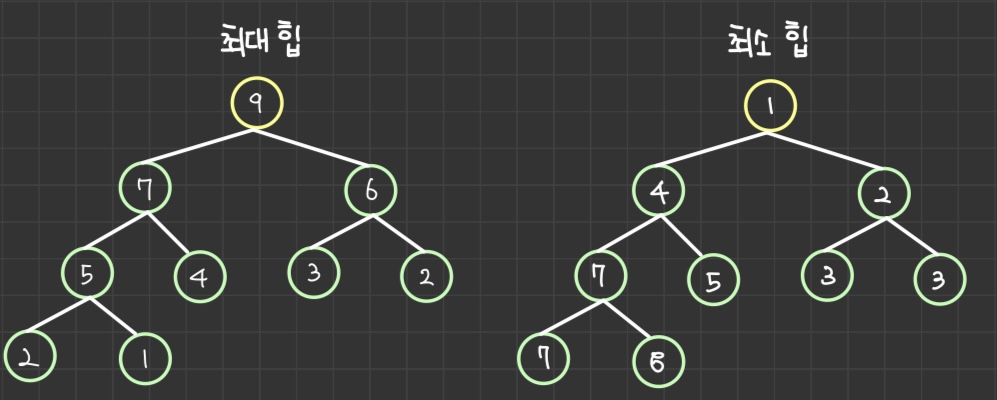
🔍 힙(Heap)이란?
- 최대 힙: 부모 노드 키 값이 자식 노드 키 값보다 커야하는 조건을 만족하는 완전 이진트리
- 최소 힙: 부모 노드 키 값이 자식 노드 키 값보다 작아야하는 조건을 만족하는 완전 이진트리
📌 완전이진트리 - 노드를 부모노드 → 왼쪽 자식노드 → 오른쪽 자식노드 순서로 추가한 이진 트리
✅ 정렬 방법
- n개의 노드에 대해 완전 이진트리 구성
- 최대 힙 구성
- 루트노드와 말단 노드 교환
- 최대 힙 구성
- 2~4 과정 반복
# 최대 힙을 만들어주는 함수
def heapify(arr, index, heap_size):
# 부모와 자식 노드의 index 간에 성립하는 식
largest = index
left_index = 2*index + 1
right_index = 2*index + 2
if left_index < heap_size and arr[left_index] > arr[largest]:
largest = left_index
if right_index < heap_size and arr[right_index] > arr[largest]:
largest = right_index
if largest != index:
arr[largest], arr[index] = arr[index], arr[largest]
heapify(arr, largest, heap_size)
def heap_sort(arr)
for i in range(len(arr) // 2-1, -1, -1):
heapify(arr, i, len(arr))
for i in range(len(arr)-1, 0, -1):
arr[0], arr[i] = ls[i], arr[0]
heapify(arr, 0, i)
return arr✨ 특징
- 제자리 정렬 알고리즘으로 정렬에 사용되는 추가적인 저장공간이 매우 작다
- 불안정적인 정렬로 같은 값일 때 순서가 변할 수 있다.
Reference
https://velog.io/@supergangho/4-Python-Onlogn-%EC%A0%95%EB%A0%AC%ED%80%B5-%EB%B3%91%ED%95%A9-%ED%9E%99
https://lsh424.tistory.com/69
https://ko.wikipedia.org/wiki/%ED%80%B5_%EC%A0%95%EB%A0%AC
https://ko.wikipedia.org/wiki/%ED%9E%99_%EC%A0%95%EB%A0%AC
https://ko.wikipedia.org/wiki/%ED%95%A9%EB%B3%91_%EC%A0%95%EB%A0%AC
(도서) 이것이 코딩 테스트다 with Python
