
✅ 큐(Queue)란?
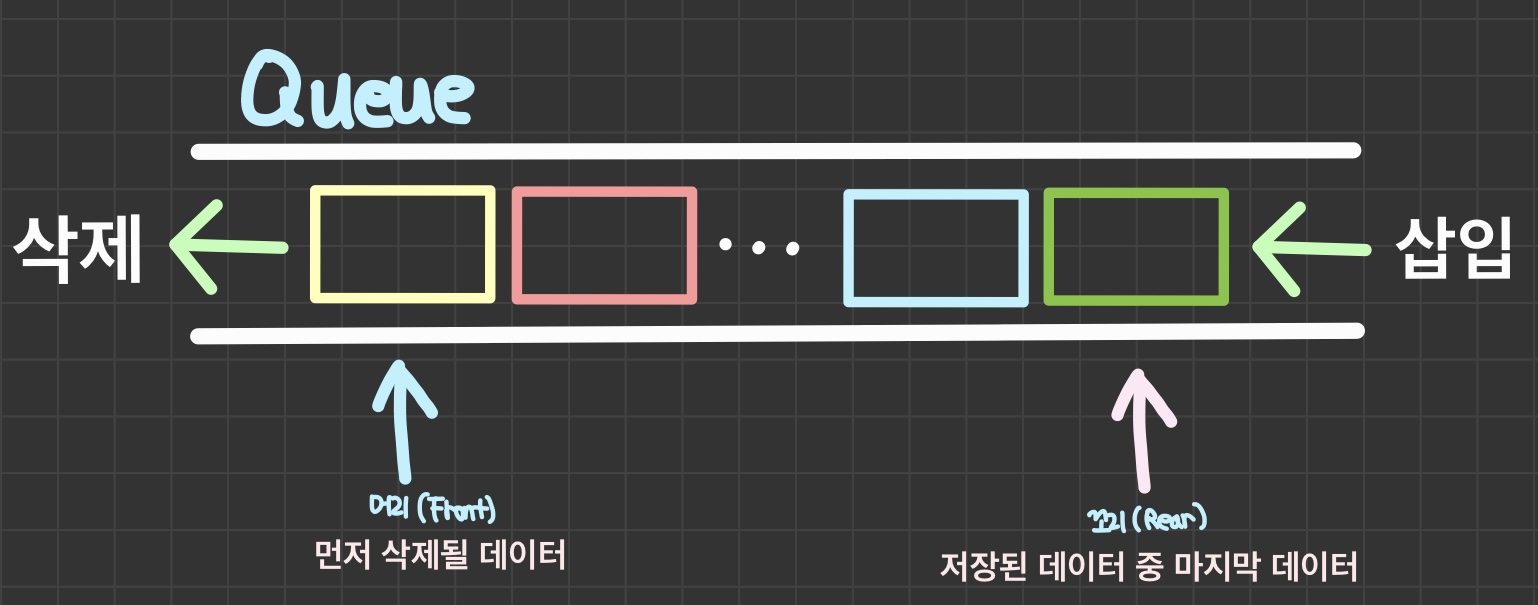
큐(Queue)란 양 쪽 끝에서만 데이터를 넣거나 뺄 수 있는 삽입과 삭제의 위치가 제한적인 형태의 선입선출(First-In-First-Out) 구조를 갖는 선형 자료구조이다.
✅ 큐의 특징
- 스택의 저장구조와 같지만 스택은 top을 통해서만 삽입, 삭제가 이루어졌다.
- 큐는 삽입, 삭제가 다른 방향에서 이루어진다.
- deque를 사용하여 큐 자료구조를 구현(doubly-ended-queue)
- deque는 내부적으로 doubly linked list 구현
- 이때, 삭제 연산만 수행되는 곳을 프론트(front), 삽입 연산만 수행되는 곳을 리어(rear)라고 한다.
- 프론트(front): 삭제 연산이 발생하며 디큐(deQueue)라고 한다.
- 리어(rear): 삽입 연산이 발생하고 인큐(enQueue)라고 한다.
→ Queue는 가장 먼저 삽입된 데이터가 가장 먼저 삭제된다는 특징을 가지고 있다.
✅ 큐의 연산 종류
- peek(): 큐의 가장 앞에 있는 데이터를 반환
- enqueue: 큐의 가장 뒤에 데이터를 삽입
- dequeue: 큐의 가장 앞에 데이터를 제거
- isEmpty(): 큐가 비어 있는 경우 True를 반환
- isFull(): 현재 큐가 가득 차 있는지 확인
✅ 큐의 구현 방법
- 배열
- 장점
- 배열 내 요소의 주로를 나타내는 인덱스를 통해 원하는 데이터를 빠르게 검색 가능
- 단점
- 선언할 때 크기가 고정되어 배열에 들어있는 데이터 양에 따라 배열의 크기조정이 필요하다.
- 데이터를 중간에 삽입하거나 삭제할 경우 해당 데이터 뒤에 있는 요소들의 위치를 모두 이동시켜야하는 비효율적인 상황이 발생
- 장점
📌 배열을 사용한 Queue 구현
class ListQueue(object):
def __init__(self):
self.queue = []
def dequeue(self):
if len(self.queue) == 0:
return -1
return self.queue.pop(0)
def enqueue(self, n):
self.queue.append(n)
pass
def printQueue(self):
print(self.queue)
if __name__ == "__main__":
queue_list = ListQueue()
queue_list.enqueue(1)
queue_list.enqueue(2)
queue_list.enqueue(3)
queue_list.enqueue(4)
queue_list.enqueue(5)
queue_list.printQueue()
print(queue_list.dequeue())
print(queue_list.dequeue())
print(queue_list.dequeue())
print(queue_list.dequeue())
print(queue_list.dequeue())
queue_list.printQueue()📌 dequeue 라이브러리 사용한 Queue 구현
from collections import deque
dq = deque([])
dq.append(1)
dq.append(2)
dq.append(3)
dq.append(4)
print(dq)
print(dq.popleft())
print(dq.popleft())
print(dq.popleft())
print(dq.popleft())
print(dq)-
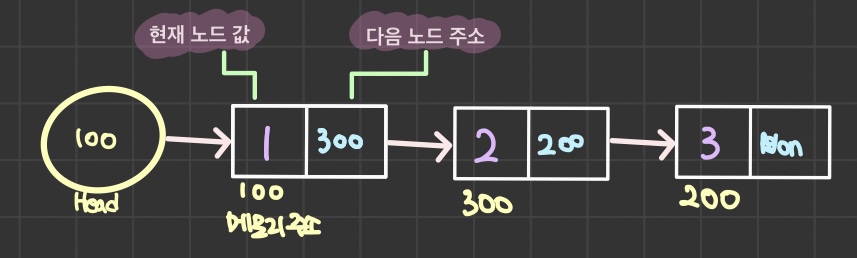
연결 리스트 (LinkedList)

- 장점
-
데이터 양에 상관없이 크기가 동적으로 조절
-
인덱스 대신 이전 데이터 그리고 다음 데이터의 위치를 기억하는 노드 형태를 이용
→ 배열 중간에 데이터 삽입, 삭제 시 노드들 사이에 연결된 링크들을 끊어주거나 이어주면 되기 때문에 그 과정이 용이하다.
-
- 단점
- 데이터에 접근할 때 연결되어 있는 노드를 따라 양 끝에서부터 순차적으로 접근해야하기 때문에 데이터 접근속도가 배열에 비해 느리다.
- 장점
특정 데이터에 접근하는 것이 목적이라면 배열을 이용
모든 원소의 값을 필요로 하더나 중간 데이터를 삽입 또는 삭제할 경우 연결리스트를 이용
📌 연결리스트(LinkedList) 사용한 Queue 구현
class Node(object):
def __init__(self, data):
self.data = data
self.next = None
class SingleyLinkedList(object):
def __init__(self):
self.head = None
self.tail = None
def enqueue(self, node):
if self.head == None:
self.head = node
self.tail = node
else:
self.tail.next = node
self.tail = self.tail.next
def dequeue(self):
if self.head == None:
return -1
v = self.head.data
self.head = self.head.next
if self.head == None:
self.tail = None
return v
# 출력
def print(self):
current = self.head
string = ""
while current:
string += str(current.data)
if current.next:
string += "->"
current = current.next
print(string)
if __name__ == "__main__":
s = SingleyLinkedList()
# 데이터 삽입
s.enqueue(Node(1))
s.enqueue(Node(2))
s.enqueue(Node(3))
s.enqueue(Node(4))
s.print()
# 데이터 제거
print(s.dequeue())
print(s.dequeue())
s.print()
print(s.dequeue())
print(s.dequeue())✅ 큐 자료구조를 사용할 때는 오버플로우(Overflow)와 언더플로우(Underflow)가 발생하지 않도록 유의해야 한다.
- 오버플로우(Overflow): 큐에 저장할 수 있는 데이터의 크기를 초과한 상태에서 데이터 삽입을 수행할 때 발생
- 언더플로우(Underflow): 큐에 데이터가 없는 상태에서 데이터 삭제 수행 시 발생
✅ 큐의 종류

- 선형 큐 (Linear Queue)
- 기본적인 큐 형태
- 문제점
- 배열로 구현 시 크기 제한
- 빈 공간을 사용하기 위해서 모든 데이터를 꺼내기 or 자료를 한 칸씩 옮겨야 함
- 연산량이 많은 enqueue와 dequeue 작업이 있는 경우 어느 시점에서 큐가 비어있어도 데이터를 추가하지 못하는 경우 발생
- 원형 큐 (Circular Queue)
- 선형 큐의 문제점을 보완
- 1차원 배열 형태의 큐를 원형으로 구성하여 배열의 처음과 끝을 연결
✅ 파이썬의 queue 라이브러리 활용
- import queue
- Queue: 일반적인 큐
- LifoQueue: 나중에 입력된 데이터가 먼저 출력되는 구조 → 스택과 유사
- PriorityQueue: 데이터에 우선순위를 매겨 우선순위가 높은 순서로 출력
📌 Queue 구현
import queue
data_queue = queue.Queue()
# 데이터 삽입
data_queue.put("data")
data_queue.put(7)
# 현재 큐에 데이터가 몇 개 인지 확인
data_queue.qsize()
# 데이터 제거
data_queue.get()
data_queue.qsize()
# 데이터 제거
data_queue.get()
data_queue.qsize()📌 LifoQueue 구현
import queue
data_queue = queue.Queue()
# 데이터 삽입
data_queue.put("data")
data_queue.put(7)
# 현재 큐에 데이터가 몇 개 인지 확인
data_queue.qsize()
# 데이터 제거
data_queue.get()
data_queue.qsize()
# 데이터 제거
data_queue.get()
data_queue.qsize()📌 PriorityQueue
import queue
data_queue = queue.PriorityQueue()
# 데이터 추가
# tuple 형식으로 데이터 추가(우선순위, 데이터)
# 우선순위는 숫자가 작을수록 높음
data_queue.put((10, "data1"))
data_queue.put((5, 7))
data_queue.put((15, "data2"))
# 현재 큐에 데이터가 몇 개인지 확인
data_queue.qsize()
# 데이터 제거
data_queue.get()
data_queue.get()📌 Enqueue와 Dequeue 구현
queue_list = list()
# 배열의 마지막에 데이터 삽입
def enqueue(data):
queue_list.append(data)
# 배열의 가장 앞에 있는 데이터 제거
def dequeue():
data = queue_list[0]
del queue_list[0]
return data
# 배열에 0부터 9까지 추가
for index in range(10):
enqueue(index)
print(len(queue_list))✅ 큐의 사용 사례
- 프로세스 관리
- 너비 우선 탐색(BFS, Breadth-First Search) 구현
- 캐시(Cache) 구현
- 대기열 순서와 같은 우선순위의 작업 예약

Welcome! This is cocoball world!