노션정리 링크
🔁 암시적 vs 명시적 형변환
| 구분 | 설명 | 예시 |
|---|
| 암시적 형변환 | Oracle이 자동으로 데이터 타입을 변환 | WHERE salary = '5000' → 문자열이 자동으로 숫자로 변환됨 |
| 명시적 형변환 | 변환 함수를 사용하여 직접 타입 변경 | TO_CHAR(hire_date, 'YYYY-MM-DD')TO_DATE('2025-06-01', 'YYYY-MM-DD')TO_NUMBER('123.45') |
명시적 형변환 함수 요약
| 함수 | 설명 | 예시 |
|---|
TO_CHAR(date, 'fmt') | 날짜 → 문자열 | TO_CHAR(SYSDATE, 'YYYY-MM-DD') |
TO_DATE(str, 'fmt') | 문자열 → 날짜 | TO_DATE('2025-06-01', 'YYYY-MM-DD') |
TO_NUMBER(str) | 문자열 → 숫자 | TO_NUMBER('123.45') |
날짜 포맷 요소
날짜 관련
| 포맷 | 의미 | 예시 출력 |
|---|
YYYY | 연도 4자리 | 2025 |
YY | 연도 2자리 | 25 |
MM | 월 (2자리) | 06 |
MON | 월 약어 | JUN |
MONTH | 월 전체 이름 | JUNE |
DD | 일 (2자리) | 24 |
DY | 요일 약어 | MON |
DAY | 요일 전체 이름 | MONDAY |
시간 관련
| 포맷 | 의미 | 예시 출력 |
|---|
HH | 시 (12시간제) | 03 |
HH24 | 시 (24시간제) | 15 |
MI | 분 | 07 |
SS | 초 | 45 |
AM / PM | 오전/오후 | PM |
예제 SQL 코드
SELECT first_name,
TO_CHAR(hire_date, 'MM/YY/DD') AS month_hired,
hire_date
FROM employees
WHERE first_name = 'Steven';
SELECT TO_DATE('2025-06-01', 'YYYY-MM-DD') AS converted_date
FROM dual;
SELECT TO_NUMBER('123.45') AS converted_number
FROM dual;
🔍 FM이 없을 때 vs 있을 때
| 포맷 | 설명 | 출력 예시 |
|---|
'YYYY"년 MM월 DD일"' | 기본 포맷 (공백 포함) | 2025년 06월 01일 (← MM, DD는 항상 2자리) |
'FMYYYY"년 MM월 DD일"' | 연도 앞 공백 제거 | 2025년 06월 01일 |
'FMYyyy"년" FMMon"월" FMDd"일"' | 앞자리 0 제거 + 공백 제거 | 2025년 6월 1일 |
✅ 예제 비교
SELECT TO_CHAR(TO_DATE('2025-06-01', 'YYYY-MM-DD'), 'YYYY"년 MM월 DD일"') AS no_fm
FROM dual;
SELECT TO_CHAR(TO_DATE('2025-06-01', 'YYYY-MM-DD'), 'FMYyyy"년" FMMon"월" FMDd"일"') AS with_fm
FROM dual;
🔁 형 변환 함수
| 함수 | 설명 | 예시 | 결과 |
|---|
TO_CHAR | 날짜/숫자 → 문자열 | TO_CHAR(SYSDATE, 'YYYY-MM-DD') | '2025-06-25' |
TO_DATE | 문자열 → 날짜 | TO_DATE('2025-06-01', 'YYYY-MM-DD') | 2025-06-01 |
TO_NUMBER | 문자열 → 숫자 | TO_NUMBER('1,000', '9,999') | 1000 |
SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD') AS today_str,
TO_DATE('2025-06-01', 'YYYY-MM-DD') AS date_val,
TO_NUMBER('1,000', '9,999') AS num_val
FROM dual;
- TO_CHAR
📌 TO_CHAR 숫자 포맷 마스크 요약
| 기호 | 설명 | 예시 결과 |
|---|
9 | 숫자 자리 (공백 표시) | TO_CHAR(123, '9999') → ' 123' |
0 | 숫자 자리 (0으로 채움) | TO_CHAR(123, '0000') → '0123' |
. | 소수점 위치 | TO_CHAR(1234.56, '9,999.99') → '1,234.56' |
, | 천 단위 쉼표 | TO_CHAR(1234567, '9,999,999') → '1,234,567' |
$ | 통화 기호 | TO_CHAR(1234.5, '$9,999.99') → '$1,234.50' |
L | 로컬 통화 기호 | 한국 설정: ₩1,234.50 |
C | 국제 통화 기호 | 예: USD1,234.50 |
FM | 공백 제거, 앞자리 0 제거 | TO_CHAR(5, 'FM0000') → '5' |
✅ 예제 구문 분석
SELECT salary,
salary * 0.123456 AS salary1,
TO_CHAR(salary * 0.123456, '$999,999.99') AS salary2
FROM employees;
해석
- TO_NUMBER
🔢 TO_NUMBER 함수 요약
개요
문자열을 숫자(Number)로 변환할 때 사용합니다. 포맷 마스크를 지정하면 쉼표나 소수점 등도 처리할 수 있습니다.기본 문법
TO_NUMBER(char [, format_model])
포맷 마스크 주요 기호
| 기호 | 의미 | 예시 입력 | 결과 |
|---|
9 | 숫자 자리 (공백 허용) | ' 123' | 123 |
0 | 숫자 자리 (0 채움) | '0123' | 123 |
, | 천 단위 구분 | '1,234' | 1234 |
. | 소수점 | '123.45' | 123.45 |
$ | 통화 기호 | '$1,234.56' | 1234.56 |
예제
SELECT TO_NUMBER('1,234.56', '9,999.99') AS num1,
TO_NUMBER('$5,000.00', '$9,999.99') AS num2
FROM dual;
1234.56 5000
- TO_DATE
📅 TO_DATE 함수 요약
개요
문자열을 날짜(Date)로 변환할 때 사용합니다. 포맷 마스크를 지정해 문자열의 날짜 형식을 알려줘야 합니다.기본 문법
TO_DATE(char, format_model)
날짜 포맷 마스크 주요 기호
| 포맷 | 의미 | 예시 입력 | 결과 |
|---|
YYYY | 연도 4자리 | '2025' | 2025년 |
MM | 월 (2자리) | '06' | 6월 |
DD | 일 (2자리) | '01' | 1일 |
HH24 | 시 (24시간제) | '15' | 오후 3시 |
MI | 분 | '30' | 30분 |
SS | 초 | '45' | 45초 |
예제
SELECT TO_DATE('2025-06-01', 'YYYY-MM-DD') AS date1,
TO_DATE('06/01/25', 'MM/DD/YY') AS date2,
TO_DATE('20250601', 'YYYYMMDD') AS date3
FROM dual;
⚠️ 주의사항
-
TO_NUMBER는 문자열에 숫자 외 문자가 포함되면 오류 발생 (예: %, 원, abc)
-
TO_DATE는 문자열과 포맷이 정확히 일치해야 하며, 그렇지 않으면 ORA-01861 오류 발생
-
숫자를 날짜로 변환하려면 암시적 변환이 일어나므로 명시적으로 TO_CHAR로 감싸는 것이 안전합니다
예: TO_DATE(TO_CHAR(20250601), 'YYYYMMDD')
필요하다면 CAST, TRUNC, ROUND, EXTRACT 같은 날짜/숫자 관련 함수도 함께 정리해드릴 수 있어요. 이어서 확장해볼까요?
🧩 NULL 처리 함수
| 함수 | 설명 | 예시 | 결과 |
|---|
NVL(expr1, expr2) | expr1이 NULL이면 expr2 반환 | NVL(NULL, 0) | 0 |
NVL2(expr1, expr2, expr3) | expr1이 NULL이 아니면 expr2, NULL이면 expr3 | NVL2(comm, '있음', '없음') | '없음' |
COALESCE(e1, e2, ...) | 가장 먼저 NULL이 아닌 값 반환 | COALESCE(NULL, NULL, 'A') | 'A' |
NULLIF(e1, e2) | e1 = e2이면 NULL, 아니면 e1 반환 | NULLIF(100, 100) | NULL |
SELECT NVL(comm, 0) AS comm_fixed,
NVL2(phone, '전화 있음', '전화 없음') AS 연락처,
COALESCE(email, phone, '없음') AS 우선연락처,
NULLIF(length(first_name), length(last_name)) AS 이름길이차이
FROM employees;
🔀 조건 분기 함수
| 함수 | 설명 | 예시 | 결과 |
|---|
DECODE(expr, val1, res1, ..., default) | expr이 val1이면 res1 반환 | DECODE(deptno, 10, '회계', 20, '연구', '기타') | '회계' 등 |
CASE WHEN ... THEN ... ELSE ... END | 조건문 기반 분기 처리 | CASE WHEN salary > 5000 THEN '고소득' ELSE '보통' END | '고소득' 등 |
SELECT ename,
deptno,
DECODE(deptno, 10, '회계', 20, '연구', 30, '영업', '기타') AS 부서명
FROM emp;
SELECT ename,
salary,
CASE
WHEN salary >= 7000 THEN '상'
WHEN salary >= 5000 THEN '중'
ELSE '하'
END AS 급여등급
FROM emp;
🎯 고급 조건 함수 및 구문
| 구문 | 설명 | 예시 | 결과 |
|---|
CASE WHEN col IN (...) THEN ... | 다중 값 비교 | CASE WHEN deptno IN (10, 20) THEN '본사' ELSE '지사' END | '본사' |
EXISTS (subquery) | 서브쿼리 결과 존재 여부 확인 | WHERE EXISTS (SELECT 1 FROM orders WHERE emp_id = e.emp_id) | TRUE/FALSE |
LNNVL(condition) | 조건이 FALSE 또는 NULL이면 TRUE 반환 | LNNVL(salary > 5000) | 조건 반전 |
SELECT ename,
CASE WHEN deptno IN (10, 20) THEN '본사' ELSE '지사' END AS 근무지
FROM emp;
SELECT e.ename
FROM emp e
WHERE EXISTS (
SELECT 1 FROM orders o WHERE o.emp_id = e.emp_id
);
SELECT ename,
CASE WHEN LNNVL(salary > 5000) THEN '낮음' ELSE '높음' END AS 급여구간
FROM emp;
📌 그룹 함수 및 GROUP BY / HAVING 개념 정리
| 항목 | 설명 | 예제 코드 |
|---|
| GROUP BY | 지정된 열을 기준으로 레코드를 그룹화 | SELECT department_id, AVG(salary) FROM employees GROUP BY department_id; |
| AVG(컬럼) | 그룹별 평균 값 계산 | AVG(salary) → 부서별 평균 급여 |
| SUM(컬럼) | 그룹별 합계 계산 | SUM(salary) → 부서별 총 급여 |
| MIN(컬럼) | 그룹별 최소 값 | MIN(salary) → 부서별 가장 낮은 급여 |
| MAX(컬럼) | 그룹별 최대 값 | MAX(salary) → 부서별 가장 높은 급여 |
| COUNT(컬럼) | 그룹별 레코드 수 계산 | COUNT(*) → 부서별 직원 수 |
| HAVING | 그룹화된 결과에 조건 부여 | HAVING AVG(salary) > 5000 → 평균 급여가 5000 초과인 그룹만 선택 |
예제: 부서별 평균 급여와 직원 수 구하고, 평균 급여가 6000 이상인 부서만 보기
SELECT department_id,
AVG(salary) AS avg_salary,
COUNT(*) AS num_employees
FROM employees
GROUP BY department_id
HAVING AVG(salary) >= 6000
ORDER BY avg_salary DESC;
이 쿼리는 employees 테이블에서 부서별 평균 급여(AVG)와 직원 수(COUNT)를 구한 후, **평균 급여가 6000 이상인 부서만** 필터링해서 보여줘.
📌 GROUPING SETS 개념 정리
| 항목 | 설명 | 예제 |
|---|
| GROUPING SETS | GROUP BY와 UNION ALL을 조합한 것과 유사하게, 여러 그룹화 기준을 한 쿼리에서 처리할 수 있음 | GROUP BY GROUPING SETS ((a), (b), (a, b)) |
| 다중 그룹화 처리 | 열을 하나씩 또는 조합해서 다양한 그룹핑 결과 생성 | GROUPING SETS ((department_id), (job_id), (department_id, job_id)) |
| NULL 값이 의미하는 것 | 그룹 기준에서 제외된 항목은 결과에서 NULL로 표시됨 | NULL → 해당 그룹 기준이 적용되지 않았음을 의미 |
예제: 부서 ID와 직무 ID를 기준으로 다양한 방식으로 급여 평균 계산
SELECT department_id, job_id, AVG(salary) AS avg_salary
FROM employees
GROUP BY GROUPING SETS (
(department_id),
(job_id),
(department_id, job_id)
)
ORDER BY department_id, job_id;
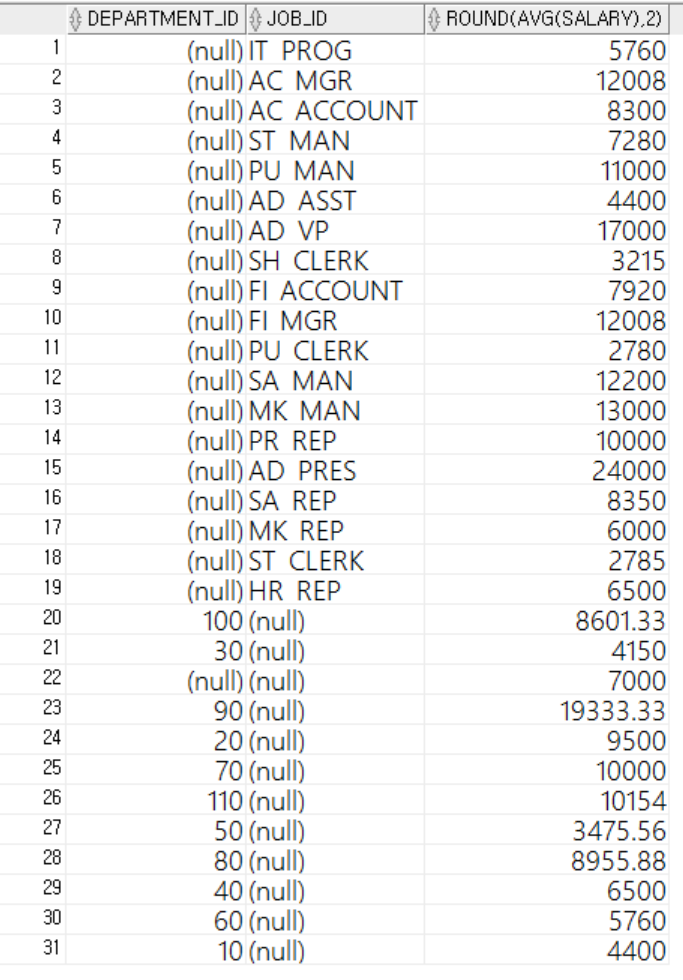
결과 설명:
(department_id) → 부서별 평균 급여(job_id) → 직무별 평균 급여(department_id, job_id) → 부서별+직무별 조합으로 평균 급여
📌 ROLLUP과 CUBE 개념 정리
| 항목 | 설명 | 예제 |
|---|
| ROLLUP | 계층적인 집계를 자동 생성. 가장 왼쪽 열부터 점진적으로 생략하며 그룹핑 | GROUP BY ROLLUP (a, b) → (a, b), (a), () |
| CUBE | 가능한 모든 조합의 그룹을 생성 | GROUP BY CUBE (a, b) → (a, b), (a), (b), () |
| NULL | 특정 그룹 기준이 생략된 경우 NULL로 표시 | NULL은 생략된 차원을 의미 |
예제 테이블 (employees)
| department_id | job_id | salary |
|---|
| 10 | IT_PROG | 6000 |
| 10 | IT_PROG | 7000 |
| 20 | SA_REP | 5000 |
| 20 | SA_REP | 5500 |
| 20 | SA_MAN | 9000 |
1. ROLLUP 예제
SELECT department_id, job_id, SUM(salary) AS total_salary
FROM employees
GROUP BY ROLLUP (department_id, job_id);
실행 결과 예시:
| department_id | job_id | total_salary |
|---|
| 10 | IT_PROG | 13000 |
| 10 | NULL | 13000 |
| 20 | SA_MAN | 9000 |
| 20 | SA_REP | 10500 |
| 20 | NULL | 19500 |
| NULL | NULL | 32500 |
→ ROLLUP은 부분 집계와 전체 합계를 포함함
2. CUBE 예제
SELECT department_id, job_id, SUM(salary) AS total_salary
FROM employees
GROUP BY CUBE (department_id, job_id);
실행 결과 예시:
| department_id | job_id | total_salary |
|---|
| 10 | IT_PROG | 13000 |
| 10 | NULL | 13000 |
| 20 | SA_MAN | 9000 |
| 20 | SA_REP | 10500 |
| 20 | NULL | 19500 |
| NULL | IT_PROG | 13000 |
| NULL | SA_MAN | 9000 |
| NULL | SA_REP | 10500 |
| NULL | NULL | 32500 |
→ CUBE는 가능한 모든 조합의 집계 결과를 생성
📌 GROUPING_ID 개념 정리
| 항목 | 설명 |
|---|
| GROUPING_ID(col1, col2, ...) | 각 열이 집계에 포함되지 않은 수준일수록 큰 값을 가짐 (이진수로 표현) |
| 용도 | ROLLUP, CUBE, GROUPING SETS의 결과에서 각 행이 어떤 그룹 레벨인지 확인 |
| 결과 값 | 각 열에 대해 0이면 실제 그룹 기준, 1이면 집계 레벨에서 생략된 기준 |
예제: ROLLUP + GROUPING_ID 사용
SELECT department_id, job_id,
SUM(salary) AS total_salary,
GROUPING_ID(department_id, job_id) AS grp_id
FROM employees
GROUP BY ROLLUP(department_id, job_id);
예상 결과:
| department_id | job_id | total_salary | grp_id |
|---|
| 10 | IT_PROG | 13000 | 0 |
| 10 | NULL | 13000 | 1 |
| 20 | SA_MAN | 9000 | 0 |
| 20 | SA_REP | 10500 | 0 |
| 20 | NULL | 19500 | 1 |
| NULL | NULL | 32500 | 3 |
GROUPING_ID 설명:
0 → 두 열 모두 그룹 기준에 포함됨1 → job_id만 생략3 → department_id, job_id 모두 생략 (총합)

