딥러닝을 이용한 자연어 처리 입문
해당 사이트를 개인 공부 목적으로 재구성한 내용입니다.
워드 임베딩
01) 워드 임베딩
: 단어를 벡터로 표현하는 방법.
자연어를 컴퓨터가 이해할 수 있게 변환하는 작업을 의미한다.
One-Hot Encoding의 한계
-
저장 공간의 비효율성
단어의 개수가 늘어날 수록 벡터의 차원이 계속 늘어난다.
단어 집합의 크기가 곧 벡터의 차원 수가 되기 때문에!e.g. 1000개 단어를 가진 코퍼스
단어 각각이 1000개의 차원을 가진 벡터가 된다.
1000개 중 하나의 값만 1을 가지고, 999개의 값은 0을 가지는 벡터 -
단어의 유사도를 표현하지 못한다
해당 문제점을 해결하기 위해 단어의 잠재 의미를 반영하기 위해 벡터화하는 기법이 존재한다.
- 카운트 기법의 벡터화 기법 e.g. LSA, HAL
- 예측 기반 기법 e.g. Word2Vec
-
단어의 의미를 반영하지 못한다.
강아지라는 단어를 나타낸다고 해보자
코퍼스에 단어가 10,000개 있다고 가정해보자.
- One-Hot Encoding (희소 표현)
강아지 = [ 0 0 0 0 1 0 0 0 0 0 0 0 ... 중략 ... 0]
# 이 때 1 뒤의 0의 수는 9995개.
코퍼스 내 단어의 수가 벡터의 차원이 된다.
희소표현이라고도 칭한다. 결과물은 희소벡터라고 함.
- 새로운 방식 (밀집 표현)
강아지 = [0.2 1.8 1.1 -2.1 1.1 2.8 ... 중략 ...]
# 이 벡터의 차원은 128. 사용자가 128로 설정한 경우
사용자가 설정한 값으로 모든 단어의 벡터 표현의 차원을 맞춘다.
이 과정에서 더이상 0,1 이 아닌 실수값을 가지게 된다.
이러한 방식을 밀집표현이라고 칭한다. 결과물은 밀집벡터 혹은 임베딩벡터라고 함.
해당 방식으로 단어를 표현하는 방법이 바로 "워드 임베딩 "
그 방법론 중 하나가 Word2Vec
02) 워드투벡터(Word2Vec)
Word2Vec의 주요 아이디어
: '비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가진다' , 즉 자주 함께 등장할수록 두 단어는 비슷한 의미를 가질 것이다.
e.g. '강아지'라는 단어는 '귀엽다, 예쁘다, 애교' 등의 단어와 주로 함께 등장한다.
분포 가설에 따라 해당 내용을 가진 텍스트를 벡터화하면 해당 단어들은 의미적으로 가까운 단어가 된다.
분산 표현
- 분포 가설이라는 가정 하에 만들어진 표현 방법.
- 분산 표현은 분포 가설을 이용하여 단어들의 셋을 학습하고, 벡터에 단어의 의미를 여러 차원에 분산하여 표현한다.
- 저차원 벡터에 단어의 의미를 여러 차원에다 분산하여 표현한다. 분산 표현을 사용하면 단어 간 유사도를 계산할 수 있다.
- 해당 작업은 워드 임베딩 작업에 속하기 때문에 이렇게 표현된 벡터 또한 임베딩 벡터라고 한다. 밀집 벡터에도 속한다.
CBOW/ Skip-Gram
Word2Vec에는 이렇게 두 가지 모델이 존재한다.
CBOW: 주변 단어로 중심 단어를 예측
Skip-Gram: 중심 단어로 주변 단어를 예측
전반적으로 전자의 성능이 더 좋다고 알려져 있다.
CBOW
: 주변 단어에서 중심 단어를 예측하는 과정에서 학습된다.
"파리에 갔더니 ___를 볼 수 있었다." 주변 단어들을 통해 '__'를 예측
"The fat cat sat on the mat" 라는 문장에서
{"The", "fat", "cat", "on", "the", "mat"}으로부터 sat을 예측
-
중심 단어: 예측해야 하는 단어
주변 단어: 예측에 사용되는 단어 -
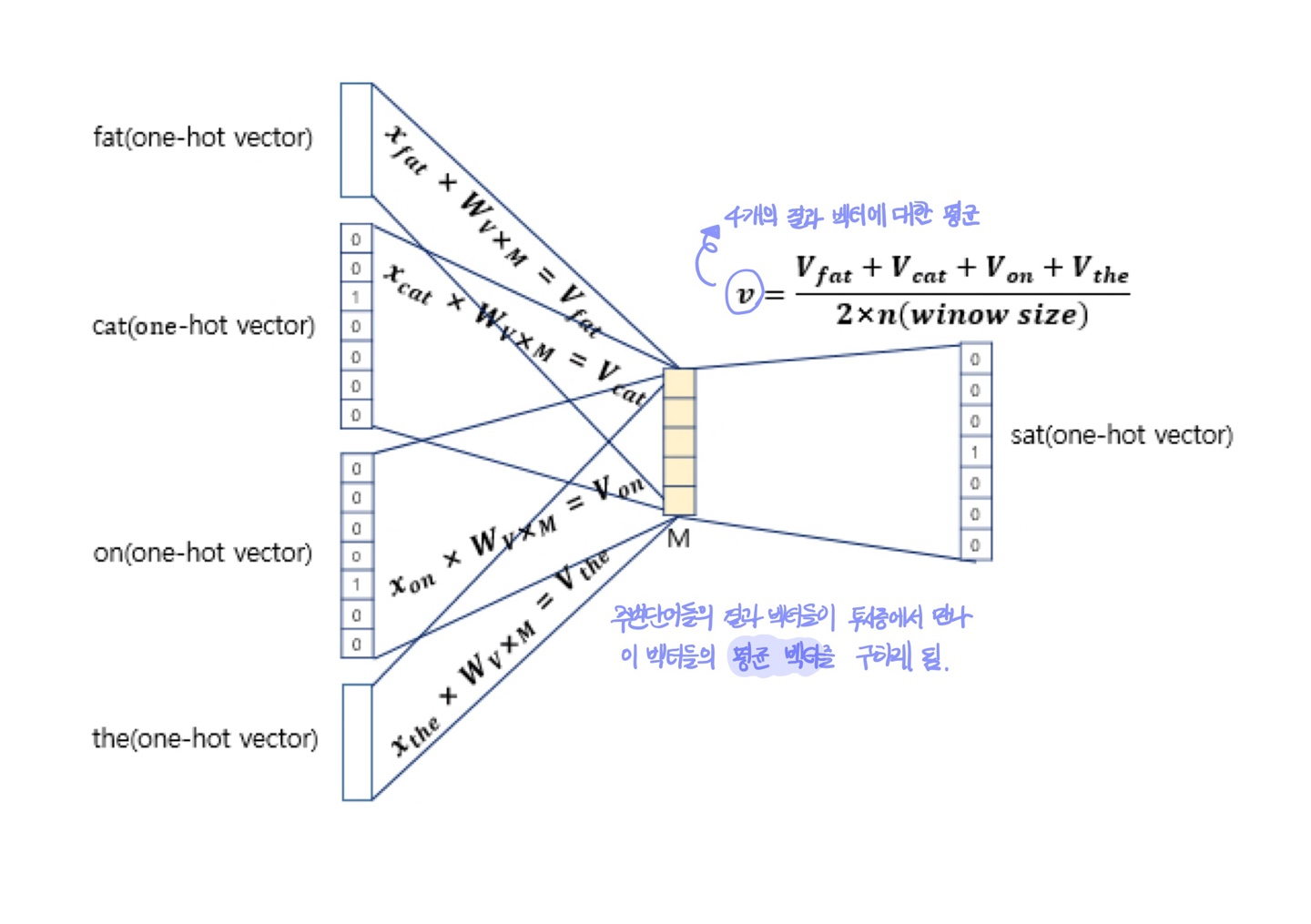
윈도우: 예측을 위해 앞, 뒤로 볼 단어의 범위
e.g. 윈도우=2: 중심단어 앞, 뒤로 2개씩, 총 4개의 단어를 참고해 중심단어를 예측하겠다

-
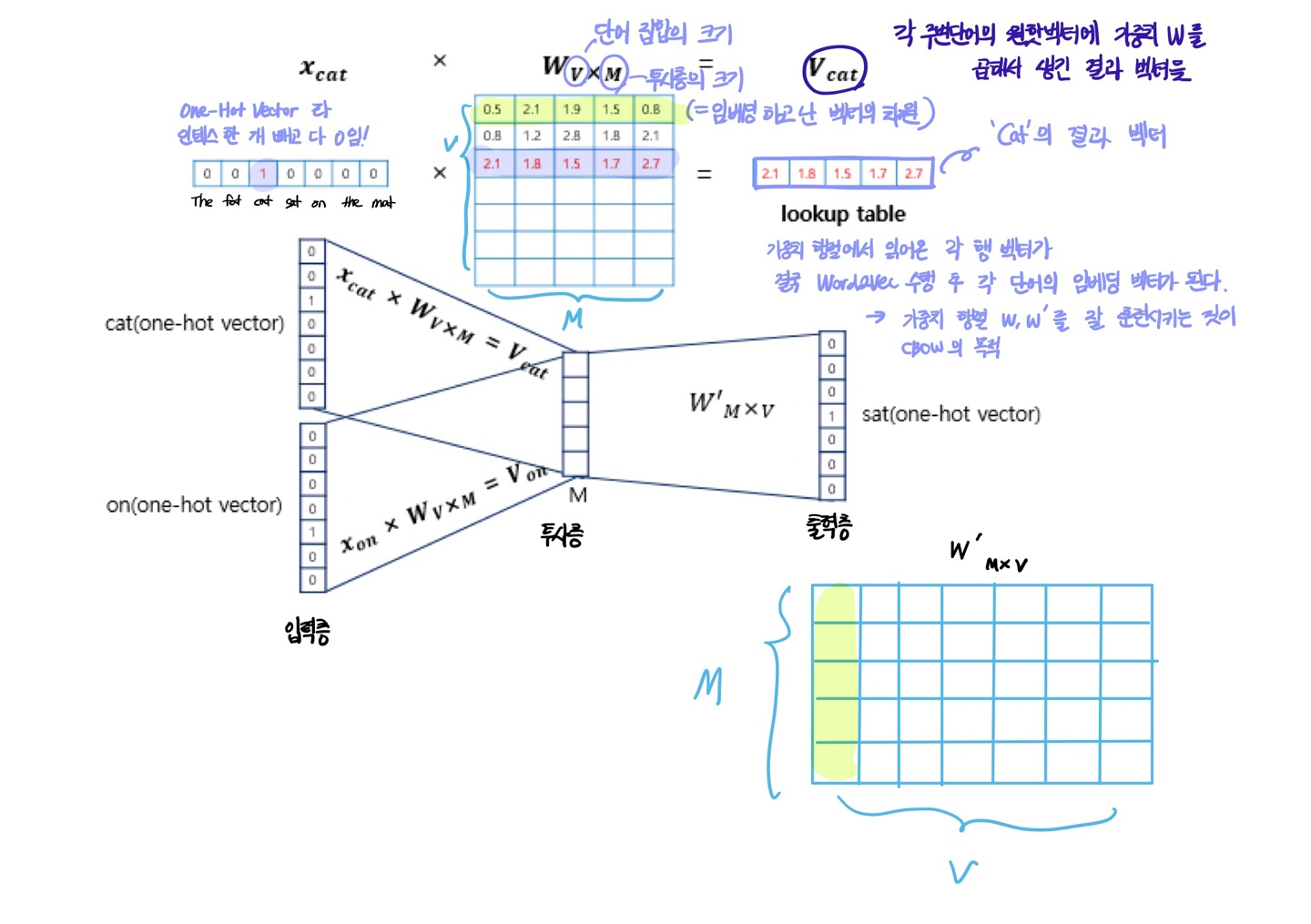
Word2Vec의 입력은 One-Hot Vector가 된다.
-
CBOW의 인공신경망의 도식

sat이라는 중심 단어를 예측하기 위해 앞 뒤로 두 개의 단어가 입력으로 사용된 것을 알 수 있음!
-
이렇게 구해진 평균 벡터는 두번째 가중치 행렬 W'와 곱해진다.
-
곱셈의 결과로는 차원이 V인 벡터가 나온다.
-
CBOW는 해당 벡터에 소프트맥스 함수를 취한다.
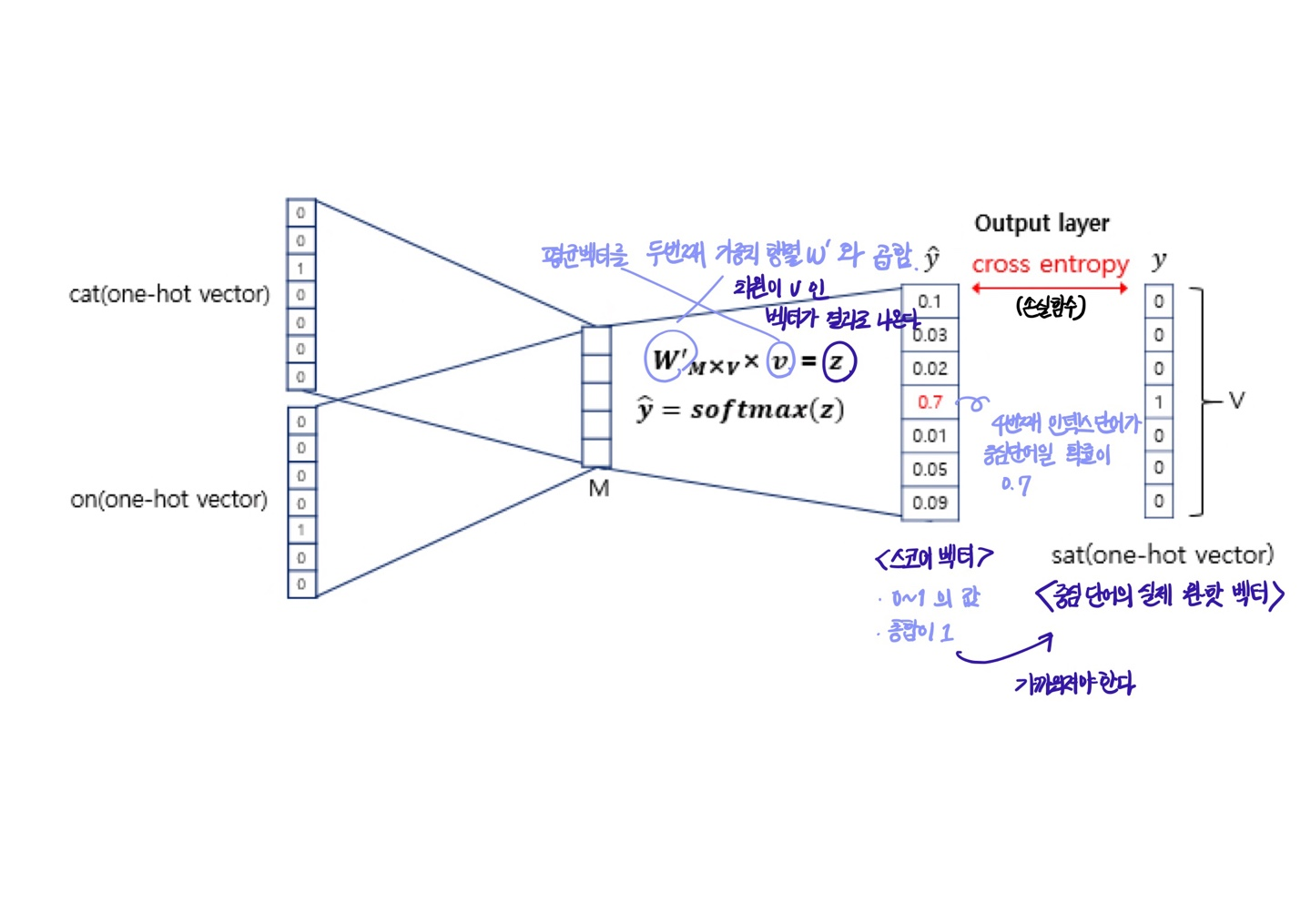
-
스코어벡터의 j번째 인덱스가 가지는 값 = j번째 단어가 중심 단어일 확률
-
cross-entropy의 값을 최소화하는 방향으로 학습해야 한다.
이제 역전파를 수행하면 W,W'가 학습된다.
학습이 다 되었다면 M차원의 크기를 갖는 W의 행이나, W'의 열로부터 어떤 것들 임베딩 벡터로 사용할지를 결정하면 된다.
