⭐Point⭐
✅ 한 속성에 있는 데이터 별 개수 보는 법
✅ bool변수 원핫인코딩 ➡️ 상관관계 돌리기 가능
✅ 등급이 실수형(1,2,3)으로 되어있어서 astype("category")로 범주화 시켜서 원핫인코딩 실시
✅ 그룹화 후 막대그래프 생성
✔️ 모델평가 test데이터셋으로 돌리는 법
데이터 속성
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
➡️ Ticket class(1 = 1st, 2 = 2nd, 3 = 3rd)
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
➡️ C = Cherbourg, Q = Queenstown, S = Southampton
Step1. 데이터 불러오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from google.colab import drive
drive.mount('/content/drive')
train = pd.read_csv('/content/drive/MyDrive/titanic_train.csv')
test = pd.read_csv('/content/drive/MyDrive/titanic_test.csv')
trainStep2. 데이터 확인하기
print(f"학습데이터 : {train.shape}")
print(f"테스트 데이터 : {test.shape}")
print(train.info() )
print(f"결측치 개수 : {train.isnull().sum()} \n")
print(f"데이터 개수 :{train['Embarked'].value_counts()}")
#나이 177개 누락데이터 -> 평균으로 대체 ..?
#Cabin 넘버는 속성삭제할거라서 전처리 불필요
#Embarked도 속성삭제 시킬 거긴한데 범주형 데이터처리 개념으로 숫자로 바꿔보기Step3. 데이터 전처리 및 상관관계 확인, 속성선택
# 나이는 평균값으로 대체 (누락데이터를 삭제하기에는 891개의 데이터중 177개가 날라가는 거라서,, 일단 대체)
train["Age"].fillna(train["Age"].mean(), inplace = True)
print(train.isnull().sum())
#Embarked,Sex 원핫인코딩
df = pd.get_dummies(train, columns = ['Embarked']) #원핫인코딩 -> bool변수로 바뀌지만 상관관계 비교 바로가능해짐
df = pd.get_dummies(df, columns = ['Sex'])
#Pclass가 실수형으로 1등급2등급3등급이라 관관계 분석을 할 때, 숫자가 연속형 변수처럼 처리되면
# 왜곡된 결과가 나올 수 있기에 범주형으로 변환
df["Pclass"] = train["Pclass"].astype("category")
#category는 Pandas에서 제공하는 데이터 타입(범주형)
df = pd.get_dummies(df, columns = ['Pclass'])
print(df.info())
df = df.drop(["PassengerId", "Name", "Ticket", "Cabin"], axis = 1)
print(df.corr())
#여성이 남성보다 생존확률 높응ㅁ
#1,2,3등석 순으로 생존률에 변화가있음
(상관관계 중 필요한 부분만 들고옴)
Step4. 시각화
- 여성/남성 별 생존 시각화 (막대그래프)
# 1. 여성/남성 별 생존수 시각화
train = pd.read_csv('/content/drive/MyDrive/titanic_train.csv')
train = train[["Sex", "Survived"]]
train = train.groupby('Sex').mean()
train.plot(kind='bar')
plt.show()
train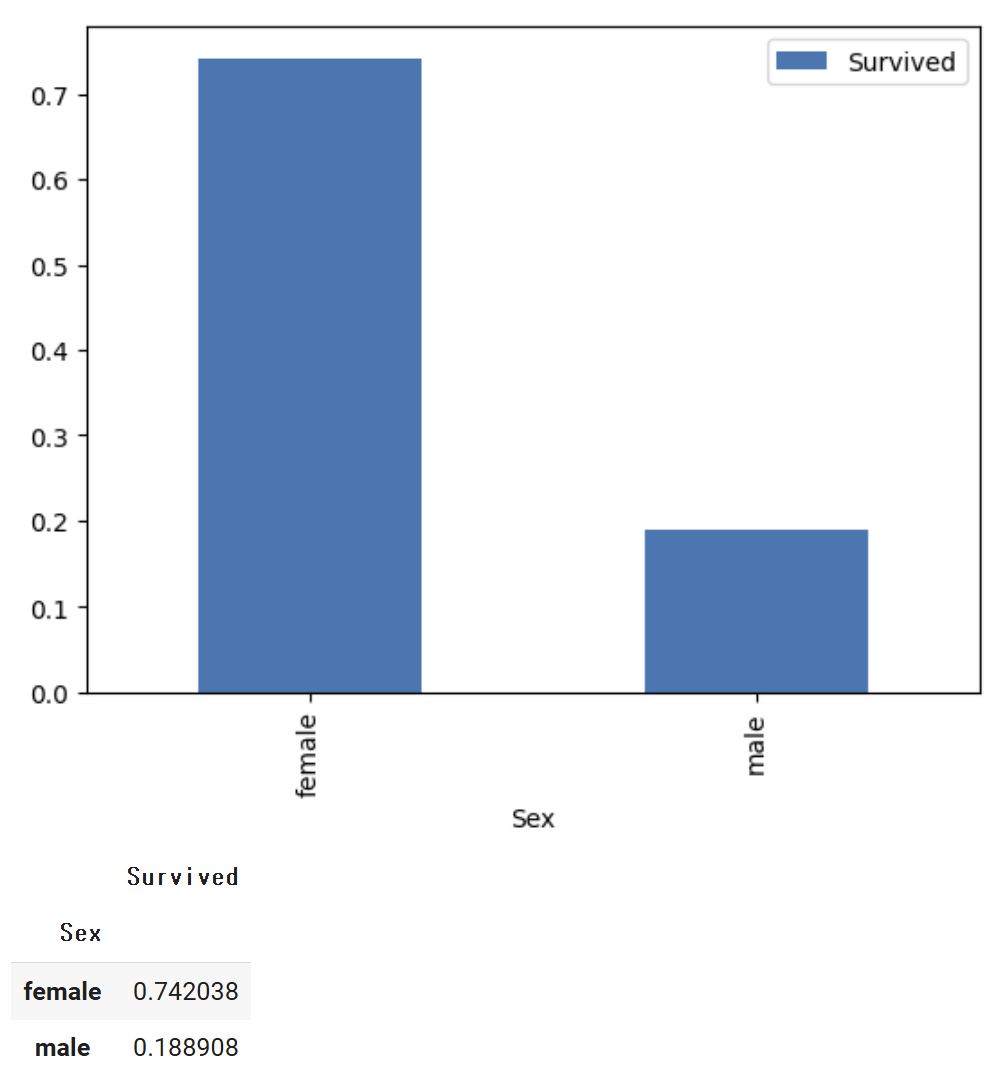
- 각 등급별 생존 시각화 (막대그래프)
#2. 등급별 생존 시각화
train = pd.read_csv('/content/drive/MyDrive/titanic_train.csv')
train = train[["Pclass", "Survived"]]
pclass_S = train.groupby("Pclass").mean()
pclass_S.plot(kind = 'bar')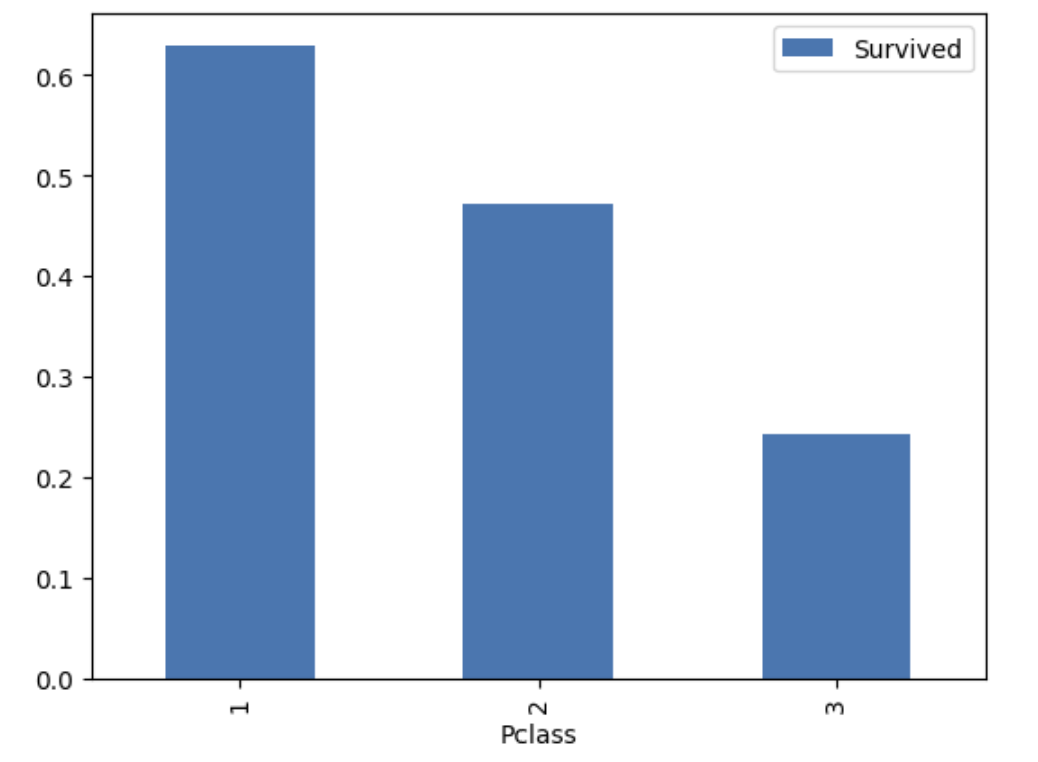
Step5. 모델학습
import tensorflow as tf
X = df[['Sex_female', 'Sex_male', 'Pclass_1', 'Pclass_2', 'Pclass_3']]
y = df['Survived']
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(16, activation='relu', input_shape=(5,))) #input_shape 잘 맞춰주기
model.add(tf.keras.layers.Dense(8, activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
# 케라스 모델을컴파일한다.
model.compile(loss='binary_crossentropy', optimizer='adam',metrics=['accuracy'])
model.fit(X, y, epochs=30, batch_size=1, verbose=1)
--------------------------------------------------------
891/891 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.7867 - loss: 0.4564
Step6. 모델평가(with test데이터)
test = pd.read_csv('/content/drive/MyDrive/titanic_test.csv')
test = test[["Sex", "Pclass"]]
#print(test.isnull().sum()) : 결측값없음
#test데이터도 동일한 속성으로 전처리
test = pd.get_dummies(test, columns = ['Sex'])
test["Pclass"] = test["Pclass"].astype("category")
test = pd.get_dummies(test, columns = ['Pclass'])
#예측
model.predict(test)
test