
WAL
데이터 베이스의 성능을 향상시키려면...
데이터베이스의 데이터는 결국 디스크에 저장된다. 즉 영속성이 있고 저렴하지만, 느리다는 성능에는 치명적인 단점이 있기에 데이터베이스 성능의 핵심은 디스크 I/O(접근)를 최소화 하는 것이라 할 수 있다.
디스크 접근을 줄이기 위해서는 메모리에 올라온 데이터로 최대한 요청을 처리해야한다. 즉 메모리 캐시 히트율을 높이는 것인데, 이는 읽기 뿐만 아니라 쓰기 시에도 동일하다.
그러나 메모리는 전원이 공급되지 않으면 휘발되는 데이터로, 전원 공급이 중단되거나 에러로 인해 데이터베이스 접속이 끊기게 된다면 데이터가 유실될 수 있다.
이러한 메모리의 데이터 유실을 막기위해 데이터베이스는 WAL(Write-Ahead-Logging)을 사용한다.
WAL의 기능
WAL을 사용하는 시스템이서 모든 수정은 적용전 먼저 로그에 기록된다. 트랜잭션 발생시 로그에 기입하여 기록을 남기고 적용을 지연시켜 랜덤I/O를 줄이고 순차적 I/O를 통해 정합성을 유지하며 일관성(Consistency)을 보장한다. 또한 서버가 다운되는 상황에서 기입된 로그를 통해 데이터의 유실을 막고, 중단된 지점 부터 다시 실행하여 원자성(Atomicity)을 보장할 수 있다.
Index
디스크 보다 메모리가 빠르다지만 모든 데이터를 메모리에 올려놓고 사용하는 것은 물리적으로 불가능에 가깝다. 그렇다면 어떻게 조회 속도를 향상시킬 수 있을까?
데이터베이스는 데이터와 데이터의 위치를 포함한 자료구조를 생성하여 빠르게 조회할 수 있도록 돕는다. 이것이 바로 인덱스(Index)이다.
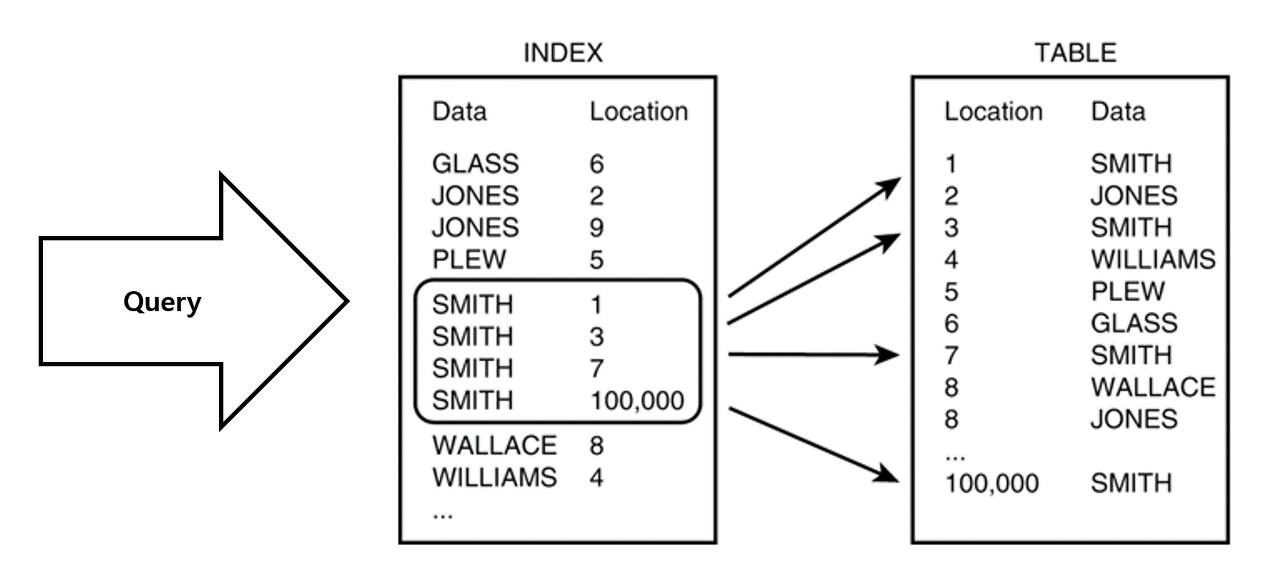
Index의 자료구조
데이터를 담기 위한 자료구조는 Map, List, Tree등 여러 선택지가 있을 것이다. 그렇다면 인덱스는 어떠한 자료구조로 이루어져있을까?
Map
먼저 Map형태는 단건 검색의 시간 복잡도가 O(1)로 월등히 빠르다는 장점이 있다. 그러나 범위 탐색은 O(N)의 시간 복잡도를 가지며, 무엇보다 LIKE 'TEST%'와 같은 전방 일치 탐색이 불가능하다는 치명적인 단점이 있다.
List
List는 정렬되지 않은 리스트의 탐색이 O(N), 정렬된 리스트의 탐색은 O(logN)의 시간 복잡도를 가진다. 정렬된 탐색이 매우 빠르지만 위의 장점을 살리기 위해서는 데이터가 정렬되어야 한다는 전제 조건이 있다. 그렇기에 실제 데이터를 정렬하고 탐색하는 시간 복잡도는 O(N) ~ O(N * logN)이 되어버린다. 또한 삽입과 삭제 비용이 매우 높다는 단점이 있어 적합하지 않다.
Tree
Tree 구조는 검색 속도와 삽입, 삭제 모두 효율적이다. 그러나 트리 높이에 따라 시간 복잡도가 결정되며 빠른 탐색을 위해서는 트리의 높이를 최소화하고, 한쪽으로 노드가 치우치지 않도록 균형을 잡아주어야 한다.
그렇기에 삽입/삭제시 항상 균형을 이루며 하나의 노드가 여러 자식 노드를 가질 수 있고, 마지막 리프노드에만 데이터가 존재하여 연속적인 데이터 접근시 유리한 B+Tree가 인덱스의 자료구조로 적합하다.
Index 사용시 주의점
인덱스는 데이터를 정렬하여 하나의 테이블로 생성하는 것이다. 그렇기에 기본적으로 디스크의 메모리를 차지하며, 데이터의 삽입/삭제시 인덱스 테이블에도 값이 추가되어야 하는 추가적인 연산이 들어가게 된다. 즉, 조회 성능을 얻는 대신 쓰기 성능을 희생하는 trade-off가 있는 것이다. 그렇기에 꼭 인덱스로만 해결할 수 있는 문제인가를 고려해보아야 한다.
또한 하나의 쿼리에는 하나의 인덱스만 타며, 여러 인덱스를 동시에 탐색하지 않는다. 그렇기에 해당 쿼리에 맞지 않는 인덱스를 타게 되면 오히려 성능이 저하되는 역효과가 발생할 수 있다. 특히 WHERE, ORDER BY, GROUP BY를 혼합해서 사용할 때에는 인덱스를 잘 고려해야 한다.
