MySQL과 다른 부분만 정리 중!
그 외 SQL 문법은 [DB] MYSQL 문법 참고
SELECT
문자열 합치기
- concat(A, B)
- 매개변수 2개만 가능
select concat('문자열', '합치기') from test //문자열합치기- A||B||C||...
- 매개변수 여러 개 가능
select '010' || '-' || '0000' || '-' || '0000' from test //010-0000-0000문자열 자르기
- substr(문자열, 시작, 길이)
- 뒤에서부터 자르고 싶으면 시작을 음수로 부여
select left("thisistest", 2, 3) from dual; //his형 변환
- TO_CHAR : 숫자/날짜 → 문자열 변환
- TO_NUMBER : 문자 → 숫자 변환
- TO_DATE : 문자 → 날짜 변환
WHERE
ROWNUM
- Oracle에서는 limit 사용불가 → rownum 대체
- limit는 order by까지 쿼리 모두 실행 후 동작하지만, rownum은 아니기 때문에 유의할 것
- rownum은 <, <= 만 사용 가능 (but, =1 은 가능)
- limit와 동일하기 사용하기 위해서는 아래와 같이 사용
select * from ( select * from emp order by ename ) where rownum = 1
BETWEEN
- between a and b
- char between num and num 가능!
- (ex. to_char(datetime, 'hh24') between 9 and 19)
출력값 치환
NVL
- null 값 변경
nvl('값', '지정값')
nvl(name, 'eunhye') //name이 null이면 "eunhye"로 지정DATETIME
현재 날짜시간
- SYSDATE
date format 변경
- date to char
to_char(sysdate, 'yyyy-mm-dd hh24:mi:ss') //2023-02-24 10:00:34
to_char(sysdate, 'yyyymmdd') //20230224- char to date
to_date('2023-02-24', 'yyyy-mm-dd')형식 지정
- SCC : 세기를 표시 S는 기원전(BC)
- YEAR : 년도 (알파벳)
- YYYY : 4자리 년도 (1998)
- YY : 2자리 년도 (98)
- MONTH : 알파벳 월 (October)
- MON : 알파벳 약어 월 (Oct)
- MM : 2자리 숫자 월 (01~12)
- DAY : 알파벳 요일 (Monday)
- DY : 알파벳 약어 요일 (Mon)
- DDD/DD/D : 년도/월/일 날짜 숫자
- HH : 시간 (12시간)
- HH24 : 시간 (24시간)
- MI : 분
- SS : 초
- AM(A.M.)/PM(P.M.) : 오전/오후
- FMMM/DD : 날짜의 '0' 없애기! (ex. 9/4)
연산
- -, + 연산자 이용
select sysdate - to_date('20230201', 'YYYYMMDD')GROUP BY
- group by 하지 않은 column은 select 불가
select * from student group by name //불가능
select name from student group by name //가능ORACLE JOIN
개요
- Oracle에서는 Oracle Join, ANSI JOIN이 존재
- ~오라클 9i : Oracle Join만 사용 가능
- 오라클 10g~ : Oracle Join, ANSI JOIN 사용 가능
- ANSI JOIN은 SQL의 기본적인 JOIN
select * from a A join b B on A.id=B.id
INNER JOIN
- ANSI는 inner join 사용
select *
from a A, b B
where A.id = B.idOUTER JOIN
- ANSI는 left outer join, right outer join 사용
- 붙여지는 table에 (+) 표시
//left outer join
select *
from a A, b B
where A.id = B.id(+)
//right outer join
select *
from a A, b B
where A.id(+) = B.idCROSS JOIN
- ANSI는 cross join 사용
- where 조건 명시 X
select *
from a A, b BFULL OUTER JOIN
- ANSI는 full outer join 사용
- Oracle은 존재 X
REGEXP
- REGEXP 불가능! REGEXP_LIKE 가능!
MERGE
기본
- on 조건절에 사용한 컬럼을 업데이트하면 오류 발생
merge
into a A //테이블, 뷰
using b B //테이블, 뷰, 서브쿼리
on (A.id=B.id) //조건절
when matched then //일치하는 경우 → update, delete (where 사용 가능)
update set A.name = B.name
delete
when not matched then //일치하지 않는 경우 → insert
insert (A.name, A.age)
values (B.name, B.age);활용 (dual 사용)
merge
into a A
using dual
on age = 20
when matched then
update set grade=1
when not matched then
insert (A.name, A.age, A.grade)
values ('Anna', 20, 1);계층형 쿼리
- START WITH
- 계층 구조 단계의 시작점 지정
- IS NULL로 설정할 경우 최상위가 됨
- CONNECT BY
- 전개방향 지정
- 순방향 : 상위 = PRIOR 하위
- 역방향 : 하위 = PRIOR 상위
- 전개방향 지정
- ORDER SIBLINGS BY
- 계층 내 정렬 (일반 ORDER BY를 사용하면 계층 구조가 흐트러짐)
- SYS_CONNECT_BY_PATH(명칭, 구분자)
- 계층형 쿼리에서만 사용 가능
- 루트에서부터 자신까지의 경로를 반환
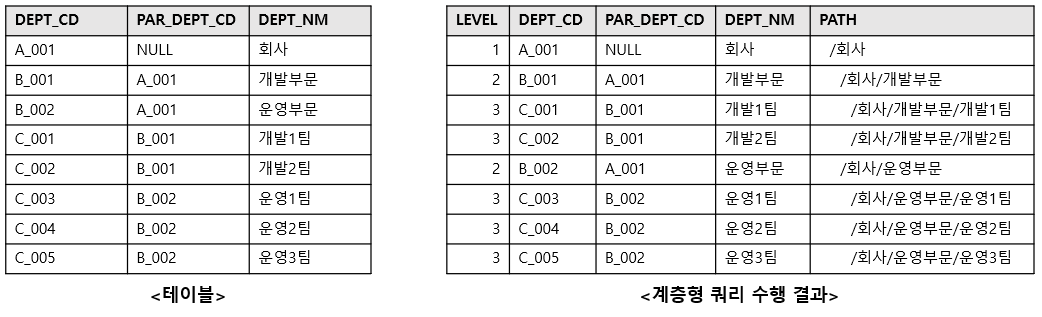
SELECT
LEVEL,
DEPT_NM,
LPAD(' ', 2*LEVEL-1) || SYS_CONNECT_BY_PATH(DEPT_NM, '/') PATH,
DEPT_CD,
PAR_DEPT_CD
FROM TB_DEPT
START WITH PAR_DEPT_CD IS NULL
CONNECT BY PAR_DEPT_CD = PRIOR DEPT_CD
ORDER SIBLINGS BY DEPT_CD;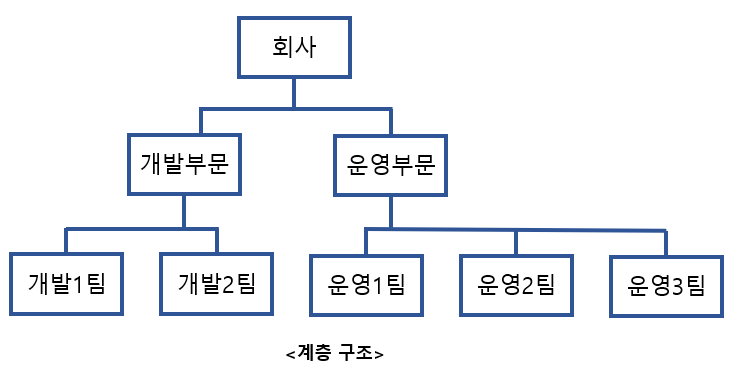
ETC
PARALLEL
- +parallel(테이블명, 병렬프로세스 갯수)
- 병렬 진행
- SQL문에 주석으로 힌트 삽입
select --+parallel(test, 4)
from test;
select /*parallel(test, 4)*/ from test;- +full(테이블명)
- 테이블에 대해 full scan 진행
select --+parallel(test, 4) full(test)
from test;
select /*parallel(test, 4) full(test)*/ from test;따옴표
- (')홑따옴표 : 문자열
- (")쌍따옴표 : 사용자명, 테이블명, 컬럼명 등
nvl(name, 'No name')
select stuName as "name" from studentETC
- 대소문자 구분 X
- 서브쿼리에 alias 지정하지 않아도 오류 X
- 테이블에 없는 값을 출력하기 위해서는 dual 사용
