Array

같은 타입의 데이터를 여러 개 나열한 선형 자료구조이다.
순차적으로 데이터를 저장한다.
배열은 선언할 때 크기를 정하면, 그 크기로 고정이 되며
선언된 값은 재선언하지 않는 이상 변경할 수 없다.
장점
구현이 쉬우며 참조를 위한 추가적인 메모리가 필요하지 않다.
연속적이므로 메모리 관리가 편하다.
인덱스를 통해 접근하므로 검색이 빠르다.
단점
배열의 크기를 변경할 수 없다
--> 크기를 변경하려면 새로운 배열을 만든 후 데이터를 옮겨야 한다..
메모리 낭비가 발생하게 된다
--> 배열을 선언한다 하더라도 사용하지 않는 공간은 배열을 선언할 때 공간이 할당되어 있어 낭비가 된다.
Heap
완전 이진 트리의 일종인 자료 구조이다.
우선 순위 큐를 위해 만들어진 자료구조이며 여러 개의 값들 중 최대, 최솟값을 빠르게 찾아내도록 만들어졌다.
최대 힙 : 부모노드 >= 자식노드
최소 힙 : 부모노드 <= 자식노드
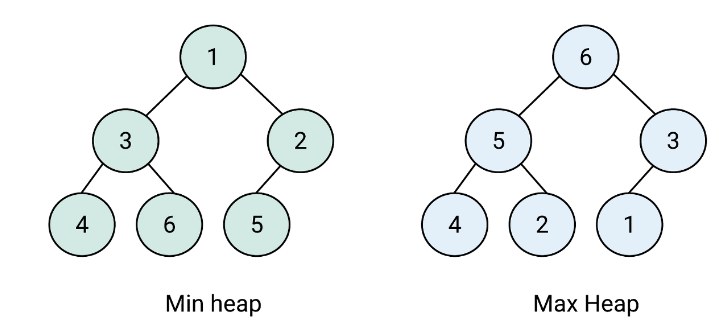
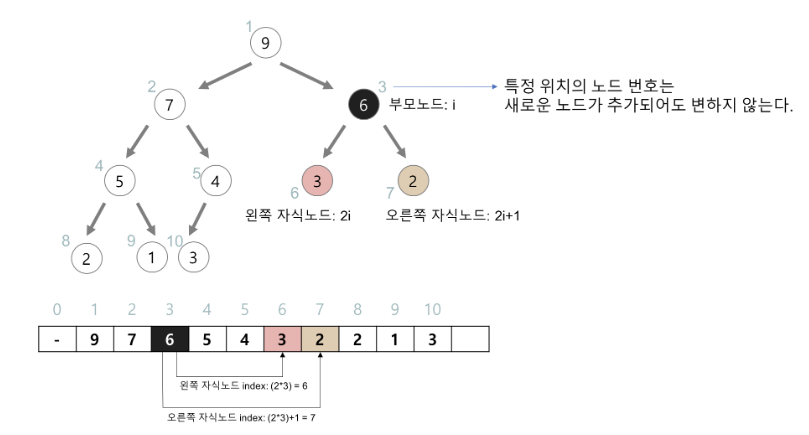
부모노드 index = 자식노드 인덱스 / 2
왼쪽 자식 index = 부모 index x 2
오른쪽 자식 index = 부모 index x 2 + 1
- 느슨한 정렬 상태 유지
- 이진 탐색 트리와 달리 중복 허용
힙 삽입
ex) 30 삽입
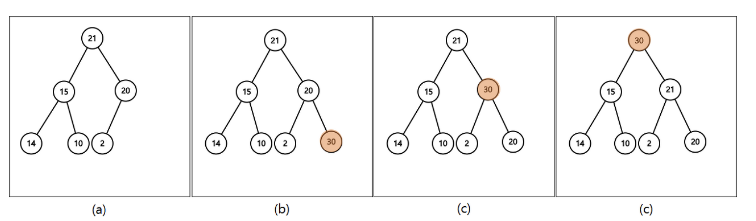
- 새로운 노드를 트리 맨 뒤에 추가한다.
- 추가된 노드와 부모 노드를 비교해 자식 노드가 크다면 서로의 위치를 바꾼다.
- 2번의 작업을 부모 노드가 더 클 때까지 반복한다.
힙 삭제
- 맨 위에 있는 root 노드가 빠지는 경우밖에 없다!
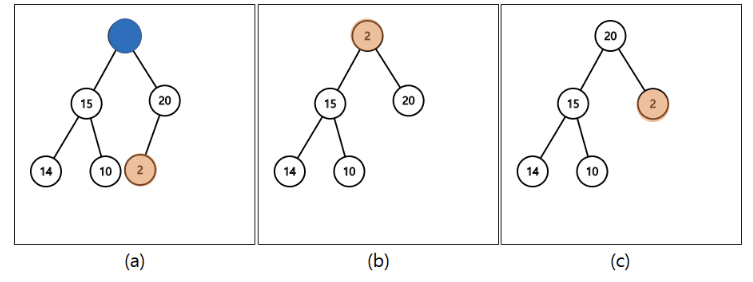
- 맨 뒤에 노드를 root자리로 옮긴다.
- 자식 노드 중 갑이 더 큰 노드와 비교해 자식 노드가 더 크다면 위치를 바꾼다.
- 2번의 작업을 자식노드보다 클 때까지 반복한다.
Stack
데이터를 차곡차곡 쌓아올린 형태의 구조이며
가장 마지막에 삽입된 자료가 가장 먼저 삭제되는 구조 (LIFO 후입선출)
ex) 책상에 책을 쌓은 경우

- 상단(stack top) : 스택에서 입출력이 이루어지는 부분
- 하단(stack bottom) : 반대쪽 바닥 부분
- 요소(element) : 스택에 저장되는 것
- 공백 스택(empty stack) : 공백 상태의 스택
- 포화 스택(full stack) : 포화 상태의 스택
장점
- 데이터의 삽입과 삭제가 빠르다
- 구현이 쉽다
단점
- 맨 위의 원소만 접근 가능하다.
- 탐색을 하려면 원소를 하나하나 꺼내서 옮겨가면서 해야한다.
stack 연산
1. push()
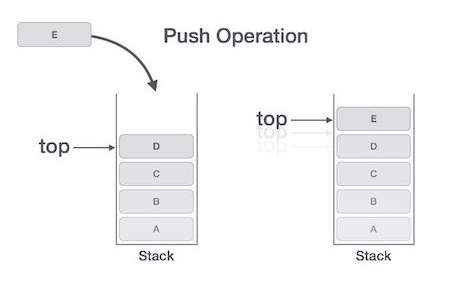
삽입하는 연산
- pop()
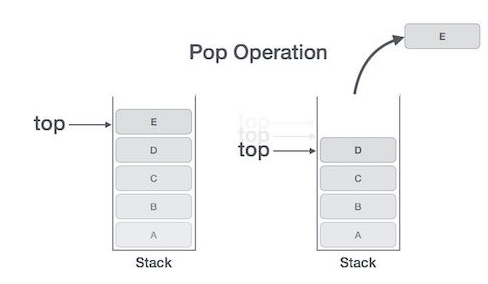
꺼내는 연산
-
peek()
현재 top이 가리키고 있는 데이터를 확인(읽기)하는 연산 -
isEmpty()
현재 stack이 비어있는지 확인하는 연산
비어있다면 true, 비어있지 않다면 false 반환
- 스택은 TOP으로 정한 곳을 통해서만 접근 가능 (삭제, 삽입 모두)
- Stack 사례 예시
- 웹 브라우저 방문기록 (뒤로가기)
- 실행 취소
- 역순 문자열 만들기
- 후위 표기법 계산
- 자바 stack 메모리 영역
Queue
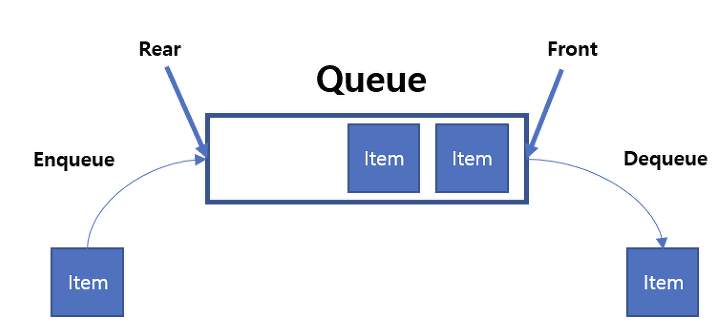
먼저 들어온 것이 먼저 나가는 선입선출 FIFO
삭제 연산이 수행되는 곳은 front (Enqueue), 삽입 연산이 수행되는 곳은 rear (Dequeue)
큐의 한 쪽 끝에서 삽입, 다른 쪽에서 삭제된다.
ex) 카페 주문 순서에 맞춰 커피 받음
장점
- 데이터의 삽입, 삭제가 빠르다.
- 순차적으로 되어 있어 입력 순서에 따라 처리할 때 유용하다.
단점
- 중간에 위치한 데이터에 접근이 어렵다.
- 배열로 구현하면 삽입, 삭제에 한계가 존재한다.
--> 이를 해결하고자 나온 것이 원형 큐
Queue 연산
1. add()
큐에 데이터를 추가하는 연산
만일 큐가 꽉 차게 된다면 더 이상 삽입할 수 없다.
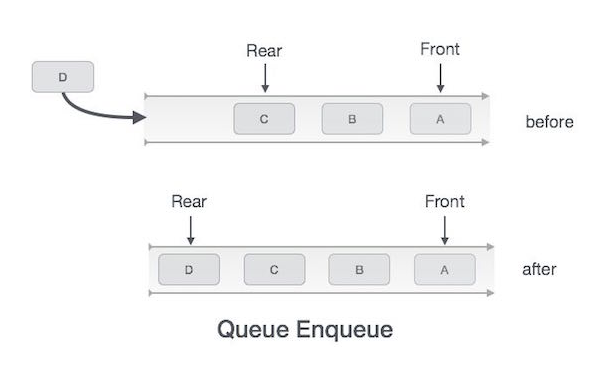
-
remove()
큐에서 데이터를 제거하는 연산
만일 rear, front의 위치가 동일하다면 큐에 남은 데이터가 없음을 의미하고 더이상 삭제할 수 없다.
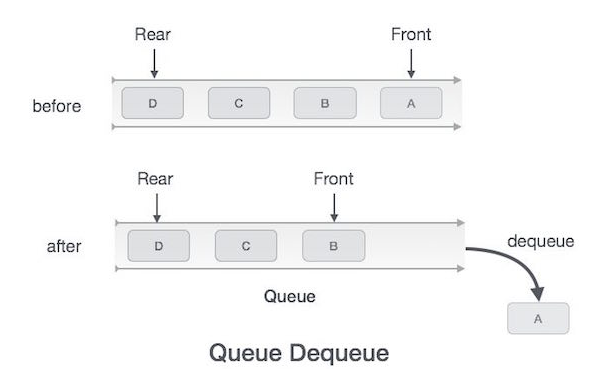
-
peek()
큐에서 가장 앞에 있는 데이터(가장 오래전에 삽입된 데이터)를 확인(읽기)하는 연산 -
isEmpty()
큐가 비어있는지 확인해주는 연산
- 큐 사례 예시
- 은행 업무
- 서비스 센터 대기 시간
- 프로세스 관리
- OS 스케쥴러
Deque
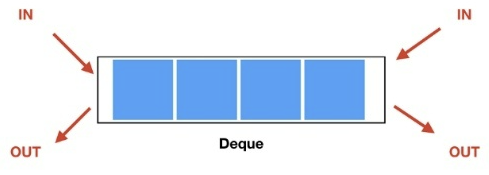
큐의 양쪽에서 데이터를 삽입하고 삭제할 수 있는 자료구조이다.
- 어느 쪽에서 입력하고 어느 쪽에서 출력하느냐에 따라 스택으로 또는 큐로 활용할 수 있다.
- null 사용 불가
우선 순위 큐 (Priority Queue)

우선 순위를 가진 데이터들을 저장하는 큐이다.
내부 요소는 힙으로 구성된 이진트리 형태이며 우선 순위 큐는 배열과 연결리스트, 힙으로 구현할 수 있다.
