1. 생물학적 비전
생물학적 Vision의 역사는 5억 4천만년 전부터 시작됐다. 지구 대부분은 물이고 일부 생물들만 있었으며 눈(eyes)이 없었다. 하지만 천만 년이라는 짧은 시간동안 생물 종이 기하급수적으로 늘어났고 가장 설득력있는 주장은 앤드류 파커의 5억 4천만전에 최초의 눈이 생겼다는 것이다. 현재 비전은 거의 모든 동물들의 가장 큰 감각 체계이다. 특히 지능을 가진 동물들에게 매우 중요하다.
2. 기계적 비전
공학적 Vision은 Obscura 카메라로 시작될 수 있다. 현재 카메라는 어느곳에서나 있다. 동시에 생물학자들은 비전의 매커님을 연구 했었는데 그 중 중요한 연구인 1950/60년대의 Hubel&Wiesel실험이 있다. 연구의 주된 발견은 시각처리가 처음에는 단순한 구조로 시작해 실제로 대상을 제대로 인식할 수 있을 때까지 시각 처리 통로를 거치면서 처음의 그 정보가 점점 복잡해진 다는 것이었다.
3. 컴퓨터 비전
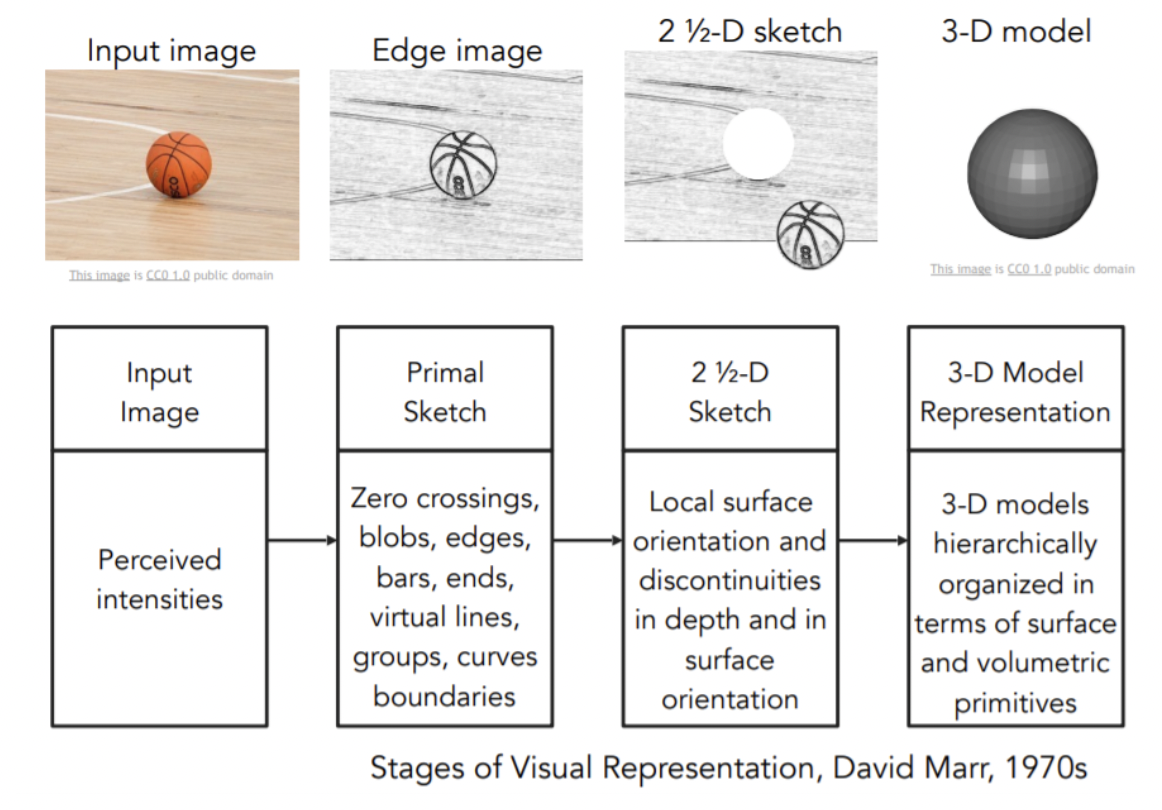
컴퓨터 비전의 역사는 60년대 초반에 태동했다. 70년대 후기에 David Marr은 VISION에 관련한 책을 저술했다. 그는 눈으로 본 ‘이미지’를 최종적인 ‘Full 3D’로 만들려면 몇개의 단계가 필요하다고 한다. 첫 단계는 Primal Sketch로 edges, bars, ends등이 표현되는 과정이다. 두번째 단계는 2.5-D sketch로 시각장면을 구성하는 surfaces, depth info등을 종합하는 과정이다. 마지막으로 이 모든 것을 모아서 surface and volumetric primitives 형태의 최종적 3D모델을 만든다.
70년대 또 다른 중요한 연구는 ‘모든 객체는 단순한 기하학적 형태로 표현할 수 있다’라는 개념의 Generalized Cylinder와 Pictorial Structure가 있다.
80년대는 David Lowe의 단순한 구조로 실제 세계를 재구성할 수 있을지에 관한 연구가 있다. 이런 초반의 연구들은 컴퓨터 비전으로 어떤 일을 할 수 있을까를 고민한 시대였다.
Image Segmentation
컴퓨터 비전 전문가들은 더딘 발전으로 인해 새로운 질문을 던졌다. Object recognition(객체인식)이 어려우면 Object Segmentation(객체분할)이 우선일 수도 있다는 것이다. 객체분할은 이미지의 각 픽셀을 의미있는 영역으로 그룹화하는 방법이다. 픽셀을 모아놔도 사람을 인식하진 못할 수 있지만, 배경에서 사람에 해당되는 픽셀들을 뽑을 수 있다는 것이다. 그리고 컴퓨터 비전에서 발전 속도가 빠른 분야로는 Face detection이 있다. 2006년에는 실시간 얼굴인식을 지원하는 최초의 디지털 카메라가 나오기도 했다.
이제 다시 “어떻게 객체를 잘 인식할 것인가?”라는 질문을 봐보자. 90년대 후반부터 2010년도까지 주목받은 알고리즘은 “특징기반 객체인식 알고리즘”이었다. 유명한 알고리즘 중 하나인 SIFT feature가 있다. 이것은 동일한 객체를 담고있는 별개의 이미지에서 (ex. STOP 사인) 일부 SIFT 특징들을 추출해 이를 식별하고 매칭한다.
이미지에 존재하는 “특징”을 사용하게 되면서 컴퓨터 비전은 장면전체를 인식하는 또 한번의 큰 발전을 했다. 예를 들어 Spatial Pyramid Matching의 아이디어는 우리가 특징들을 잘 뽑아낸다면 그것들이 일종의 “clue”(이미지가 부엌인지 고속도로인지 등)를 제공해줄 수 있다는 것이다. 이 연구는 이미지 내의 여러 부분과 해상도에서 추출한 특징을 하나의 feature descriptor로 넣어서 Support Vector Algorithm을 적용한다.
21세기에는 사진의 품질이 좋아지게 되어 더 좋은 데이터를 얻을 수 있게 되었다. 2000년대 초에는 드디어 컴퓨터 비전이 앞으로 풀어야할 문제가 무엇인지 어느정도 정의를 내릴 수 있게 되었다. 바로 “객체 인식”으로 어느정도의 수준인지 평가하기 위해 우리는 이제 Benchmark Dataset을 모으기 시작했다. 데이터셋 PASCAL VOC에서 객체인식 성능은 꾸준히 증가한걸 알 수 있었다. 한편 기계학습 알고리즘들의 트레이닝 과정시 Overfitting 문제의 원인 중 하나인 시각데이터가 복잡하다는 것과 모든 것들을 인식하고 싶다는 motivation에 따라서 ImageNet 프로젝트를 시작했다.
그리고 대규모 데이터셋 ImageNet 를 활용한 분류 성능 비교 챌린지에서 CNN모델인 AlexNet(2012)의 등장은 오류율을 급격히 낮추는 성능을 보여주었다.
이 강의에서는 Image classification에 초점을 두고 있고, 이에 기반한 다른 vision recognition도 살펴본다. 객체인식의 중요한 도구인 CNN은 2012년에 만들어진 것은 아니다. CNN알고리즘은 아주 오래전부터 있었지만 90년대부터 급격하게 발전했다. 그 배경으로는 컴퓨터의 계산능력 발전과, GPU의 진보, 데이터 양의 증가 등이 있다.
Sematic Segmentation, 3D understanding, Activity recognition등 다양한 문제가 아직 남아있고 컴퓨터 비전은 굉장히 흥미로운 분야라고 할 수 있다.
