1. 결정 트리 학습과 시각화
Decision Tree : 분류, 회귀, 다중 출력 작업 모두 가능
iris 데이터셋 사용
1. 훈련
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris(as_frame=True)
X_iris = iris.data[["petal length (cm)", "petal width (cm)"]].values
y_iris = iris.target
tree_clf = DecisionTreeClassifier(max_depth=2, random_state=42)
tree_clf.fit(X_iris, y_iris)- 학습 결과 시각화
from sklearn.tree import export_graphviz
export_graphviz(
tree_clf,
out_file=str(IMAGES_PATH / "iris_tree.dot"), # 경로가 책과 다릅니다.
feature_names=["petal length (cm)", "petal width (cm)"],
class_names=iris.target_names,
rounded=True,
filled=True
)
from graphviz import Source
Source.from_file(IMAGES_PATH / "iris_tree.dot")2. Prediction
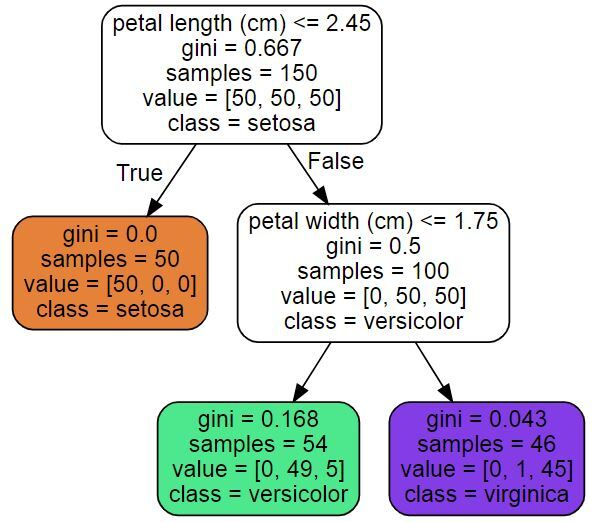
✅ 스케일링, 센터링 등의 전처리가 필요 없다. 기존 데이터 그대로 사용하면 됨
루트 노드 : 깊이 0, 맨 꼭대기 노드
리프 노드 : 자식 노드를 가지지 않는 노드
samples : 해당 노드로 분류된 훈련 샘플의 개수
value : samples의 훈련 샘플이 각 클래스에 몇 개씩 속해있는지 ➡ 실제 속해있는 클래스를 의미한다
✅ 가장 샘플 수가 많은 클래스로 분류한다.
gini : impurity(불순도)
- pure : gini=0 (해당 노드에서 모든 샘플이 같은 1개의 클래스에 속해 있을 때)
✔ = 해당 클래스에 속하는 샘플 수 / 전체 샘플 수- gini가 0에 가깝다 > pure에 가깝다 > 잘못 분류된 샘플 수가 적다
ex. depth=1의 왼쪽 노드
gini=1-(50/50)^2-(0/50)^2-(0/50)^2=0
ex. depth=2의 왼쪽 노드
gini=1-(0/54)^2-(49/54)^2-(5/54)^2=0.168

max_depth = 2로 설정했으므로, depth 2 까지만 분기하고 depth 2의 노드들은 leaf node가 된다(더이상 분기하지 않는다).
➡ 해당 트리의 최종 depth = 2
2.1 decision boundary
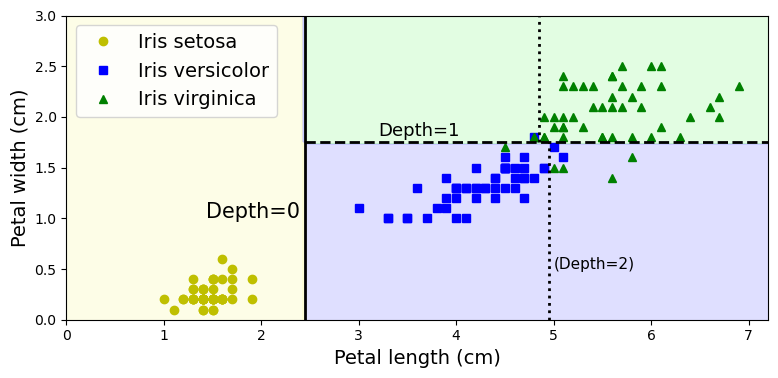
- [노란색] 루트 노드
pure node (gini=0) ➡ 더는 나눌 수 없다.
(굵은선) 루트 노드의 결정 경계 (petal length=2.45를 기준으로 depth0에서 depth1로 분기)=depth1의 왼쪽과 오른쪽 노드로 나눈다.
➡ Setosa/not Setosa 구분 - [초록색] depth=2의 왼쪽 노드 / [파란색] 오른쪽 노드
(굵은점선) petal width=1.75를 기준으로 depth1에서 depth2로 분기
✔ max_depth = 2 이면 여기서 더이상 분기하지 않는다
✔ max_depth = 3 이면 depth2에서 depth3으로 추가 분기(얇은점선)
decision tree는 몇 안 되는 화이트박스 모델 중 하나이다.
- 화이트박스
모델 내부의 동작을 확인할 수 있음
직관적이고 쉬운 해석 가능
DT를 보면서 직접 손으로 분류하는 것도 가능하다.- 블랙박스
모델 내부가 보이지 않기 때문에 예측 결과가 나온 이유를 알기 어렵다.
성능이 좋고, 계산을 통해 결과의 성능을 판단 가능
대부분의 머신러닝 모델 (ex. 랜덤 포레스트, 인공신경망)
3. 클래스 확률 추정
한 샘플이 특정 클래스 k에 속할 확률 추정
- 그 샘플의 특성에 해당하는 리프 노드를 찾는다
- 그 노드에 해당하는 확률 출력
ex. petal length=5cm, width=1.5cm
depth2의 왼쪽(초록색)노드에 속하는 샘플
- = 0%
- = 90.7%
- = 9.3%
predict_proba() : 특정 클래스일 확률 출력
predict() : 해당 샘플이 속하는 클래스 출력
tree_clf.predict_proba([[5, 1.5]]).round(3)
>> array([[0. , 0.907, 0.093]])
tree_clf.predict([[5, 1.5]])
>> array([1])4. 규제 매개변수
- 결정 트리는 훈련 데이터에 대한 제약이 거의 없음
- Nonparametic model : 훈련되기 전에 파라미터 수가 결정되지 않음
➡ 모델 구조가 고정되지 않고 자유로움
✅ overfitting 되기 쉬움 - 따라서 overfitting을 막기 위해 규제를 통해 자유도를 낮춰야한다.
Parametic model : 미리 정의된 파라미터 수를 가짐
➡ 자유도 제한, overfitting 위험 감소 (underfitting 위험 증가)
- 이때 파라미터 숫자를 충분히 크게 잡으면 overfitting이 발생할 수도 있으나, 그 개수를 미리 결정할 수 있으므로 nonparametic에 비해 발생 가능성이 낮다.
max_depth : 최대 깊이 지정 (default=None 으로, 무한대->과대적합 위험)
➡ 감소시키면, 규제가 커짐 (과대적합 위험 감소)
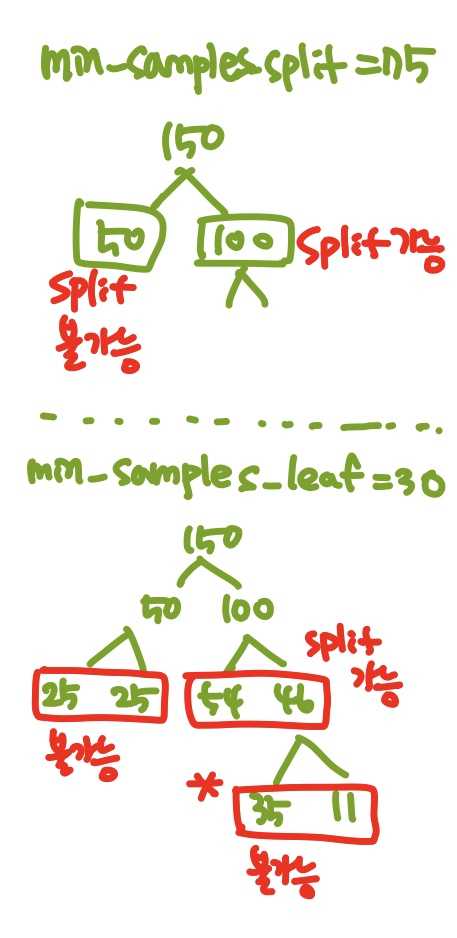
min_samples_split : 분할되기 위해 노드가 가져야 하는 최소 샘플 개수
➡ 증가시키면, 규제가 커짐
✔ 1이면 오차 데이터 하나만으로도 가지가 생긴다!
min_samples_leaf : 리프 노드가 가지고 있어야 할 최소 샘플 개수
➡ 증가시키면, 규제가 커짐
min_weight_fraction_leaf : min_samples_leaf와 같지만, 가중치가 부여된 전체 샘플 수에서의 비율
✔ 실제 개수가 아닌 %로 표현
➡ 증가시키면, 규제가 커짐
max_leaf_nodes : 리프 노드의 최대 개수
➡ 감소시키면, 규제가 커짐
max_features : 한 노드에서 평가 기준으로 삼는 특성의 개수 제한
➡ 감소시키면, split의 개수가 감소하므로, 규제가 커짐
min_을 증가시키거나, max_를 감소시키면 규제가 커진다.
min_samples_leaf = 30이라면, 분기했을 때 생기는 각각의 노드가 30개 이상의 샘플을 가지고 있어야 한다는 뜻이다.
[moons dataset]
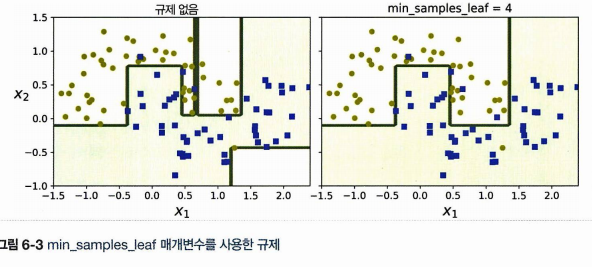
(왼) 규제 없음 ➡ overfitting 발생
(오) 리프 노드의 최대 개수 4개로 제한하여 규제 ➡ overfitting 없음
