0. 앙상블 학습이란?
- 여러 개의 예측기를 생성하고, 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출
- 앙상블 : 여러 개의 예측기
- 앙상블 학습 : 앙상블을 이용한 학습
- 앙상블 방법method : 앙상블 학습 알고리즘
- 랜덤 포레스트 : decision tree의 앙상블
- 앙상블 학습의 유형 : bagging, boosting, stacking, ...
1. Voting Classifiers
각 분류기의 예측을 모아서 가장 많이 선택된 클래스를 예측
1.1 Hard Voting
다수결 투표로 결정
- 앙상블에 사용되는 개별 분류기 중 best model보다 정확도가 높음
- 개별 분류기가 (랜덤 추측보다 조금더 높은 성능을 내는)weak learner 일지라도, 충분히 많고 다양하다면 앙상블은 (높은 정확도를 내는)strong learner가 될 수 있음
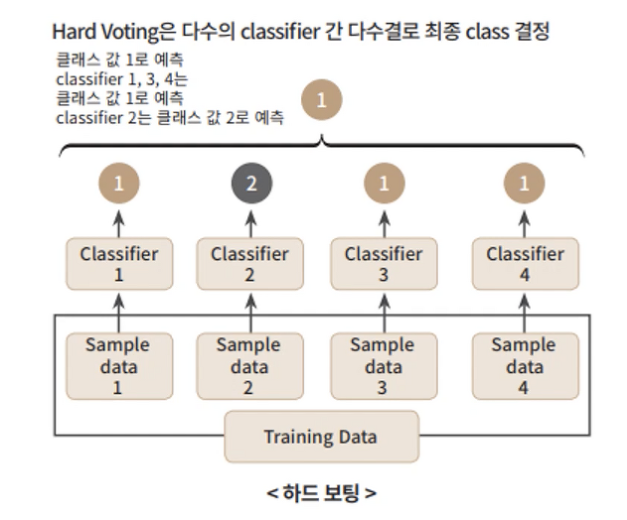
1.2 Soft Voting
- 모든 분류기가 클래스의 확률을 예측할 수 있으면(즉,
predict_proba()메소드가 있으면) 사용 가능- 모든 분류기의 예측을 평균내어, 확률이 가장 높은 클래스로 예측
- hard voting 보다 성능이 높고 더 자주 사용됨
- 확률값이 높은 분류기의 경우 가중치가 더 부여되는 방식
➡ 모든 분류기의 결과가 동일한 가중치를 갖지 않도록 한다.
확률의 평균을 계산하는 것이므로, 높은 확률(높은 정확도)를 가진 분류기의 결과에 더 가중치가 실리게 된다고 이해할 수 있다.
✔ hard voting은 예측한 클래스 결과값만으로 결정하기 때문에 그 결과의 정확도와는 연관이 없다.
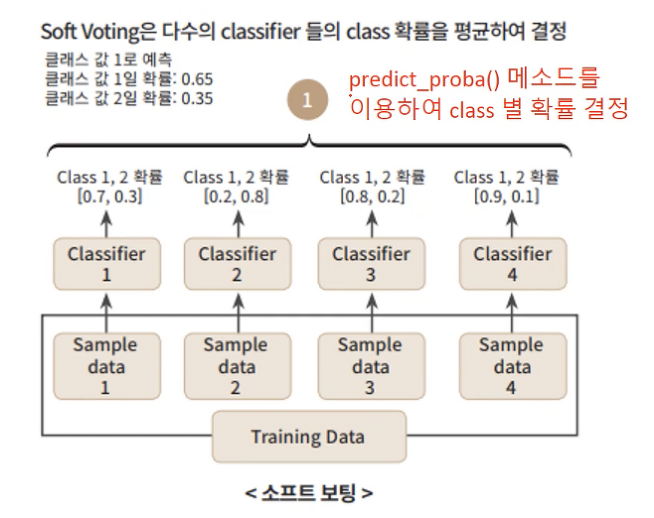
🤔 앙상블로 얻은 결과를 신뢰할 수 있는가?
- 던질 때마다 앞면 51%, 뒷면 49%가 나오는 동전 던지기
- 1000번 던지면 510 : 490 ➡ 앞면이 다수가 될 확률 75%
- 따라서 더 많이 던질수록 확률은 증가한다. (큰 수의 법칙)
🔽 던진 횟수가 증가할수록 앞면이 나올 확률인 51%에 가까워짐 (51%에 수렴)
➡ 비슷하게 (랜덤 추측보다 조금더 나은) 51%의 정확도를 갖는 분류기들의 앙상블로 75%의 정확도를 기대할 수 있다.- 모든 분류기가 완벽하게 독립적이고 오차에 상관관계가 없을 때 가능한 가정이다.
- 51%의 정확도는 모든 모델이 서로 다른 과정을 거쳐서 만들어진 것이어야 한다.
- 사용한 데이터셋이 동일한 경우
- (같은 데이터를 사용해서) 파라미터의 가중치가 거의 동일하게 나타나는 경우
➡ 독립적인 모델이라고 할 수 없다.
비슷한 형태의 error를 생성하기 때문에 앙상블의 정확도가 하락한다.- 동일한 데이터셋을 사용하더라도 결과를 만들어내는 과정(알고리즘)은 달라야지만 앙상블에 사용할 수 있다!
hard voting 구현 (Moons dataset 이용)
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
X, y = make_moons(n_samples=500, noise=0.30, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# voting classifier 내부에서 사용할 분류기 결정
log_clf = LogisticRegression(solver="lbfgs", random_state=42)
rnd_clf = RandomForestClassifier(n_estimators=100, random_state=42)
svm_clf = SVC(gamma="scale", random_state=42)
voting_clf = VotingClassifier(
estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)],
voting='hard' # hard voting
voting_clf.fit(X_train, y_train) # 내부의 분류기들도 자동으로 학습이 이루어짐
for name, clf in voting_clf.named_estimators_.items():
print(name, "=", clf.score(X_test, y_test))
# 각각의 분류기를 위한게 아닌,
# voting classifier를 최적화하기 위한 방향으로 각 분류기가 최적화됨
>> lr = 0.864
rf = 0.896
svc = 0.896
# voting 결과는 class 1로 분류
voting_clf.predict(X_test[:1])
>> array([1])
# 3개의 분류기에서 각각 예측한 class
[clf.predict(X_test[:1]) for clf in voting_clf.estimators_]
>> [array([1]), array([1]), array([0])]
# 다수결로 class 1로 결정된 것을 확인
# voting classifier의 정확도가 개별 분류기 3개보다 높음
voting_clf.score(X_test, y_test)
>> 0.912soft voting 구현
voting_clf.voting = "soft" # soft로 지정
voting_clf.named_estimators["svc"].probability = True # svc의 확률 메소드 활성화
voting_clf.fit(X_train, y_train)
voting_clf.score(X_test, y_test)
>>> 0.92
# hard voting보다 정확도가 높음만약 개별 분류기 1개가 class1로 예측 결과를 내놓았다면, class1일 확률은 0.5 이상이어야 한다(binary classification인 경우). class가 3개 이상이라면 0.5 이하여도 가능
2. Bagging and Pasting
✅ 다양한 분류기를 만드는 방법
- 각기 다른 훈련 알고리즘을 사용
- 같은 알고리즘을 사용하되 훈련 세트의 서브셋을 랜덤하게 구성
➡ 각기 다른 훈련 데이터로 학습 (=배깅과 페이스팅)
배깅Bagging
- 같은 알고리즘으로 여러 개의 분류기를 만들어 앙상블 학습
- 훈련 세트에서 중복을 허용하여 무작위 샘플링
➡ 각 분류기들이 알고리즘은 동일하지만 서로 다른 파라미터를 가지게 되어, 모두 독립적인 분류기가 된다.
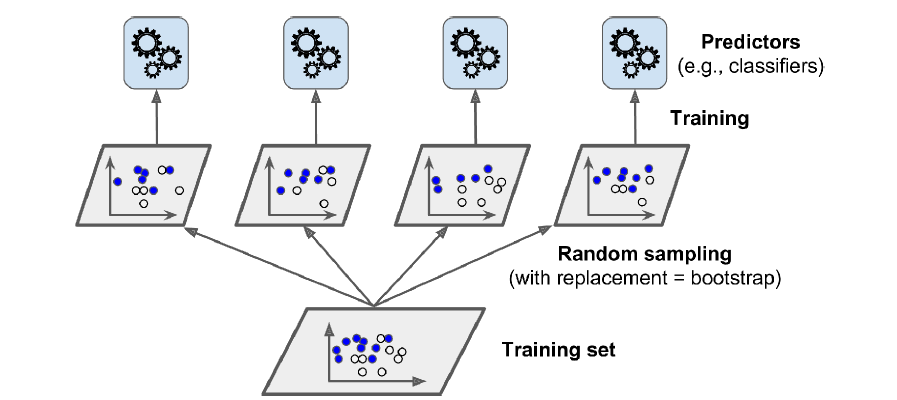
페이스팅Pasting
- 배깅과 유사
- 훈련 세트에서 중복을 허용하지 않고 무작위 샘플링
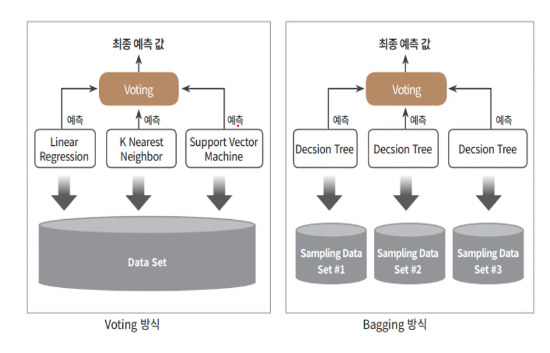
Voting vs. Bagging
- Voting : 같은 데이터셋으로, 다른 알고리즘을 가진 여러 개의 분류기를 학습
- Bagging : 데이터 샘플링을 다르게 하여 개별 분류기마다 학습 데이터셋이 다르다. 이를 기반하여 같은 알고리즘을 가진 여러 개의 분류기를 학습
이때 bagging은 학습 데이터셋 간에 중복되는 샘플이 허용된다.
앙상블 결과를 낼 때,
- 분류 : 통계적 최빈값statistical mode을 사용 ➡ (=hard voting) 다수결
- 회귀 : 평균 계산
- 개별 예측기는 (서로 다른 훈련 데이터셋을 사용하므로) 원본 훈련 세트로 훈련시킨 것보다 훨씬 편향되어 있음
- 앙상블 결과는 (원본 데이터셋으로 하나의 예측기를 훈련시켰을 때와 비교하면) 편향은 비슷하거나 더 낮고, 분산은 감소한다.
: 정답에 다다르는 정도는 비슷하지만, 예측 결과끼리의 거리(유사도)가 가까워진다.
2.1 사이킷런 구현
(분류) BaggingClassifier
(회귀) BaggingRegressor
bootstrap = True: bagging /bootstrap = False: pasting
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bag_clf = BaggingClassifier(DecisionTreeClassifier(), n_estimators=500,
max_samples=100, n_jobs=-1, random_state=42)
bag_clf.fit(X_train, y_train)n_estimators=500: decision tree 500개 사용max_samples=100: 중복을 허용하여(bagging) 무작위로 선택된 100개의 샘플로 훈련n_jobs=-1: CPU 코어 수 지정 (-1:모든 코어 사용)
[Moons dataset]
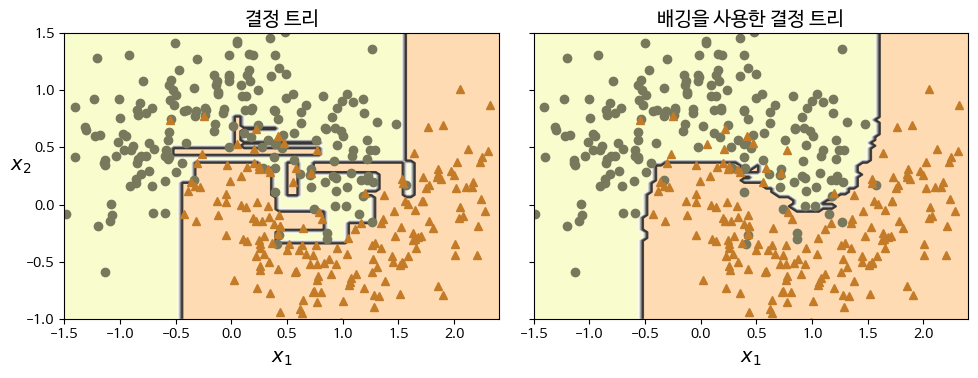
(왼) 단일 DT의 decision boundary
(오) 500개 DT 사용한 배깅 앙상블
- 편향은 비슷함, 분산은 더 작음
- 오차 수는 비슷하나, 결정 경계는 덜 불규칙함
(경계가 매끄럽지 않은 것을 보면 약간의 overfitting 경향을 보이기도 함)
2.2 Out-Of-Bag Evaluation : bagging
-
배깅을 사용하면 어떤 샘플은 여러번 샘플링되고, 어떤 샘플은 한 번도 선택되지 않을 수 있다.
-
각 예측기에 평균적으로 훈련 샘플의 63% 정도만 샘플링된다.
➡ 선택되지 않은 훈련 샘플 : oob 샘플 (37%)
✅ 예측기마다 남겨진 37%는 모두 다르다. -
oob 샘플은 훈련에 사용되지 않았기 때문에, 별도의 검증 세트를 사용하지 않고 oob 샘플을 사용해 평가 가능
-
앙상블의 평가는 각 예측기의 oob 평가의 평균
➡ 앙상블 자체에 대한 evaluation 결과로 사용 가능 -
oob 평가 구현 :
BaggingClassifier에서oob_score = True로 지정
bag_clf = BaggingClassifier(DecisionTreeClassifier(), n_estimators=500,
oob_score=True, n_jobs=-1, random_state=42)
bag_clf.fit(X_train, y_train)
bag_clf.oob_score_
>> 0.896- test dataset을 사용한 정확도와 비교
from sklearn.metrics import accuracy_score
y_pred = bag_clf.predict(X_test)
accuracy_score(y_test, y_pred)
>> 0.92oob 샘플만으로도 test data로 검증한 것과 상당히 유사하게 예측이 가능하다.
- oob 샘플에 대한 decision function 값 확인
:oob_decision_function_변수
➡ 각 훈련 샘플의 해당 클래스일 확률을 반환한다. (개별 예측기가predict_proba()메소드를 사용하기 때문)
# probas for the first 3 instances
bag_clf.oob_decision_function_[:3]
# [음성 클래스일 확률, 양성 클래스일 확률] * 샘플 개수만큼 출력
>> array([[0.32352941, 0.67647059],
[0.3375 , 0.6625 ],
[1. , 0. ]])3. Random Patches and Random Subspaces
BaggingClassifier 는 특성 샘플링도 지원한다.
특성 샘플링은 더 다양한 예측기를 만들며, 편향을 늘리고 분산을 낮춘다.
max_features: 무작위로 선택될 (훈련에서 사용할) 특성의 개수bootstrap_features: 특성 선택시 중복 허용/비허용 지정- 각 예측기는 무작위로 선택한 입력 특성의 일부분으로 훈련됨
- 매우 고차원 데이터셋(ex.이미지)에 유리 : 특성의 개수가 매우 많음
(특성의 개수가 적을 때는 불리 ex.iris)
랜덤 패치 방식
- 특성과 샘플을 모두 sampling
└bootstrap=Truebootstrap_features=True
랜덤 서브스페이스 방식- 훈련 샘플을 모두 사용
└bootstrap=False(pasting : 모든 샘플을 사용)
└max_samples=1.0(비율이 1.0 ➡ 각 예측기가 모든 샘플을 사용)- 특성만 sampling
└bootstrap_features=Truemax_features는 1.0보다 작게 설정
✅ 특성만 샘플링 = 각 예측기에 들어갈 데이터는 같지만, 그 데이터들이 가지고 있는 특성이 다름. (데이터가 갖고 있는 특성 중 선택된 특성만을 가지고 훈련) ➡ 예측기마다 서로 다른 특성으로 훈련한다.

4. Random Forest
배깅/페이스팅을 사용한 Decision Tree의 앙상블
- 사이킷런
RandomForestClassifierRandomForestRegressor - 훈련 세트(training subset)의 크기 :
max_samples
from sklearn.ensemble import RandomForestClassifier
rnd_clf = RandomForestClassifier(n_estimators=500, max_leaf_nodes=16,
n_jobs=-1, random_state=42)
rnd_clf.fit(X_train, y_train)
y_pred_rf = rnd_clf.predict(X_test)
# 랜덤 포레스트는 결정 트리의 배깅과 같습니다:
bag_clf = BaggingClassifier(
DecisionTreeClassifier(max_features="sqrt", max_leaf_nodes=16),
n_estimators=500, n_jobs=-1, random_state=42)max_leaf_nodes=16트리 1개는 최대 16개의 리프 노드를 가짐n_estimators=500500개 트리 사용n_jobs=-1모든 CPU 코어 사용
✔ BaggingClassifier와 DecisionTreeClassifier의 하이퍼파라미터를 모두 가지고 있음
- 트리의 노드를 분할할 때, 전체 특성 중에서 최선의 특성을 찾는 대신 무작위로 선택한 특성 후보 중에서 최적의 특성을 찾는다.
➡ 무작위성을 더 주입
➡ 트리를 다양하게 만들고, (특성을 선택하므로) 편향이 높아지는 대신 분산이 감소한다.
➡ 전체적으로 더 훌륭한 모델을 만들어낸다.
무슨말이냐?
✅ DT는 각 노드를 분할할 때 '특성'을 기준으로 해서 분할한다.
RF는 이때 전체 특성 중에서 무작위로 일부 특성을 고르고, 이 특성들에서 최선의 분할을 찾는다. (최선의 기준)
✅ 엑스트라 트리는 (RF에서) 가장 좋은 분할을 찾는 것이 아닌 무작위로 분할하는 무작위성이 추가된다.
4.1 Extra Tree
Extremely Randomized Trees ensemble
무작위로 분할한 다음 최상의 분할을 선택한다.
➡ 편향 증가, 분산 감소
- 일반적인 랜덤 포레스트보다 훨씬 빠르다.
ExtraTreesClassifier : 사용법은 RF와 동일
ExtraTreesRegressor : RF regressor와 동일한 API가짐
- RF와 ET를 모두 사용해본 후 교차 검증으로 비교해서 더 좋은 모델을 사용한다.
4.2 Feature importance
Single DT
- 중요한 특성이 루트 노드와 가깝게 나타남
- 덜 중요한 특성의 경우 leaf와 가깝게 나타나거나, 아예 안 나타나기도 함
Random Forest
- 특성의 상대적인 중요도를 측정하기 쉬움
- 어떤 특성을 사용한 노드가 (RF의 모든 트리에 걸쳐서) 평균적으로 불순도를 얼마나 감소시키는지 확인하여 특성의 중요도 측정
➡ 가중치의 평균 (각 노드의 가중치 = 연관된 훈련 샘플 수) feature_importances_
from sklearn.datasets import load_iris
iris = load_iris(as_frame=True)
rnd_clf = RandomForestClassifier(n_estimators=500, random_state=42)
rnd_clf.fit(iris.data, iris.target)
for score, name in zip(rnd_clf.feature_importances_, iris.data.columns):
print(round(score, 2), name)
>> 0.11 sepal length (cm) # 덜 중요
0.02 sepal width (cm) # 덜 중요
0.44 petal length (cm) # 가장 중요
0.42 petal width (cm) # 가장 중요- MNIST 데이터셋에 RF 훈련시키고 각 픽셀의 중요도 표시
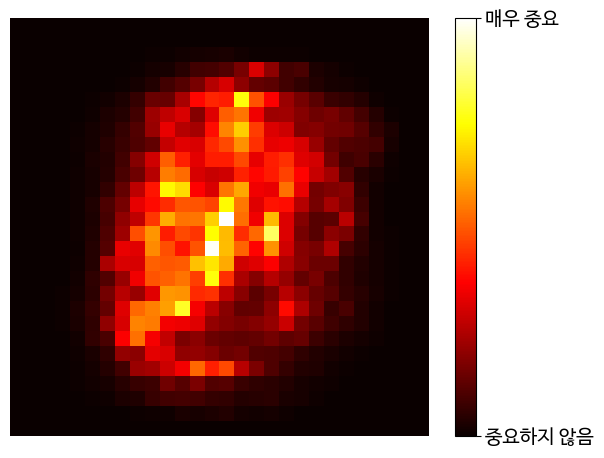
✅ 랜덤 포레스트는 특성을 선택해야 할 때 어떤 특성이 중요한지 빠르게 확인할 수 있어 편리하다.
