실습코드: https://colab.research.google.com/drive/1L_AYWzr3SsRaZF7yWOCV-dTnX-njMgBl?usp=sharing
1. Data Exploration
가. 개요: 데이터 분석 위한 데이터 변수들의 상태 파악
나. 종류
- head, tail
시작 또는 마지막 6개 record만 조회
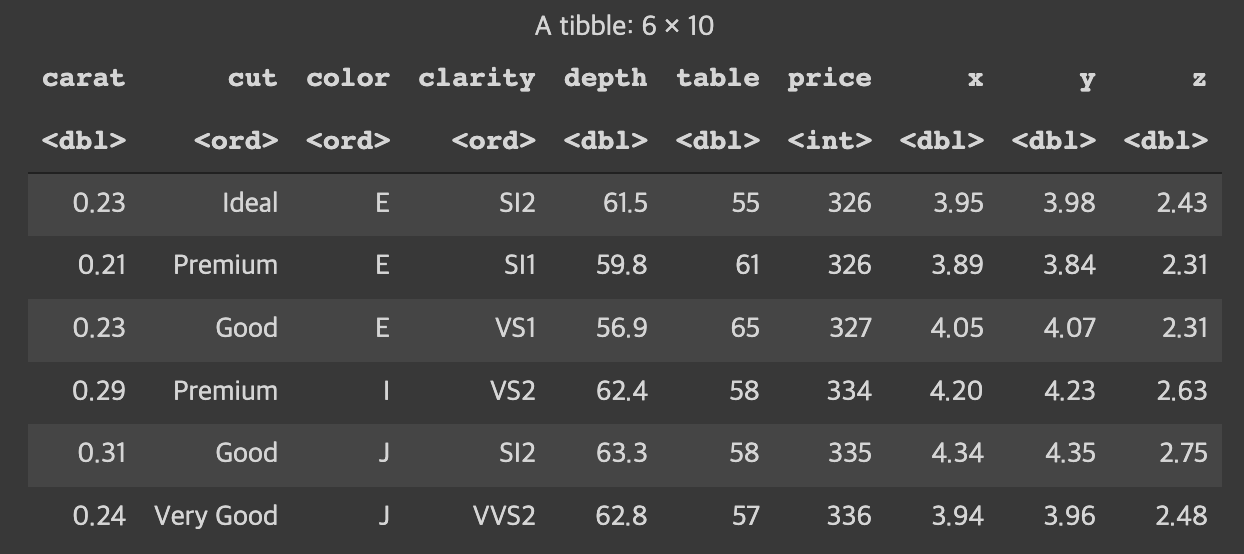
- summary
수치형변수: 최대값, 최소값, 평균, 1사분위수, 2사분위수(중앙값), 3사분위수
명목형변수: 명목값, 데이터개수
2. 변수중요도
가. 개요
- 모형을 생성하여 사용된 변수의 중요도를 살피는 과정
나. 종류
- klaR패키지: 특정변수가 주어졌을 때 클래스가 어떻게 분류되는지에 대한 에러율을 게산하고, 그래프로 결과 보여줌
- greedy.wilks(): 세분화를 위한 stepwise forward 변수선택을 위한 패키지, 종속변주에 가장 영향력을 미치는 변수를 silks labda를 활용해 변수 중요도 정리
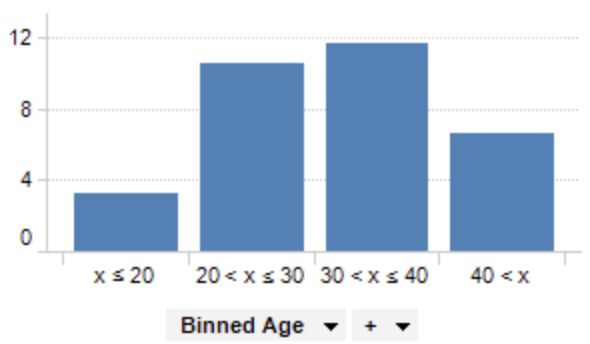
3. 변수의 구간화
가. 개요
연속형 변수를 분석 목적에 맞게 활요하기 위해 구간화하여 모델링함
(일반적으로 10진수 단위 구간화, 구간을 5개로 나누는 것이 보통, 7개 이상의 구간은 잘 만들지 않음)
나. 구간화 방법

데이터사이언티스트(NLP)