Virtual DOM
가상의 DOM 객체.
실제 DOM의 사본 같은 개념으로,
React는 실제 DOM 객체에 접근하여 조작하는 대신 이 가상의 DOM 객체에 접근하여 변화 전과 변화 후를 비교하고 바뀐 부분을 적용함.
Virtual DOM이 나오게 된 배경
Real DOM (DOM)
DOM(Document Object Model): 문서 객체 모델.
여기서 문서 객체란 브라우저가 JavaScript와 같은 스크립팅 언어가 <html>, <head>, <body>와 같은 태그들에 접근하고 조작할 수 있도록 태그들을 트리 구조로 객체화 시킨 것.
다시 말하자면 DOM은 브라우저가 트리 구조로 만든 객체 모델입니다.
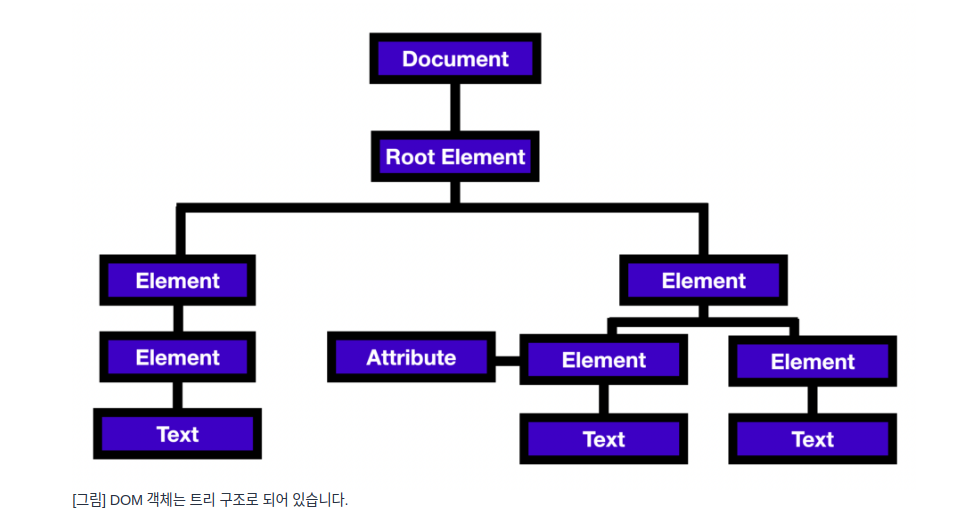
이렇게 트리 구조로 DOM 객체가 이뤄져 있기 때문에 JavaScript는 쉽게 DOM 객체에 접근할 수 있고, DOM 객체를 조작할 수 있게 됨.
이렇게 프로그래밍 언어로 조작하는 DOM은 애플리케이션의 UI 상태가 변경될 때마다 해당 변경 사항을 나타내기 위해 업데이트가 됨.
만약 이런 DOM을 조작하는 정도가 잦다면 성능에 영향을 미치게 될 것이고,
DOM의 렌더링은 브라우저의 파워, 즉 브라우저의 구동 능력에 의존하기 때문에 DOM의 조작 속도는 느려지게 됩니다.
DOM의 조작 속도가 느려지는 이유
DOM의 구조는 계층적 구조로 되어 있는 트리.
자료구조 중에서 특히 트리는 “데이터 저장"의 의미보다는 “저장된 데이터를 더 효과적으로 탐색”하기 위해 사용되므로, 빠른 자료 탐색 성능이 장점인 자료구조라고 볼 수 있음.
그렇기 때문에 그런 트리 구조로 된 DOM은 JavaScript와 같은 스크립팅 언어가 접근하고 탐색하는 속도가 빠르기 때문에 변경 및 업데이트 속도 또한 빠릅니다.
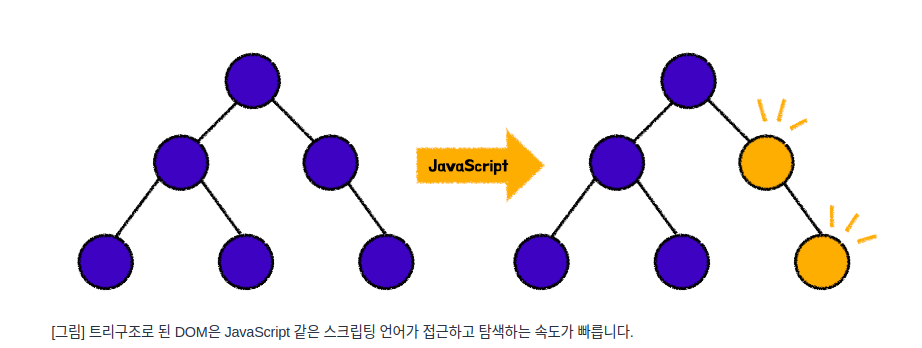
그러나 DOM이 변경되고 업데이트가 된다는 것은 결국 브라우저의 렌더링 엔진 또한 리플로우(Reflow)한다는 것을 의미함.
즉 업데이트 된 요소와 그에 해당하는 자식 요소들에 의해 DOM 트리를 재구축함으로써 재랜더링 과정을 거쳐 UI를 업데이트 해야함.
브라우저의 리플로우와 리페인트 과정은 다시금 레이아웃 및 페인트에 해당하는 재연산을 해야 하기 때문에 속도가 그만큼 느려지게됨.
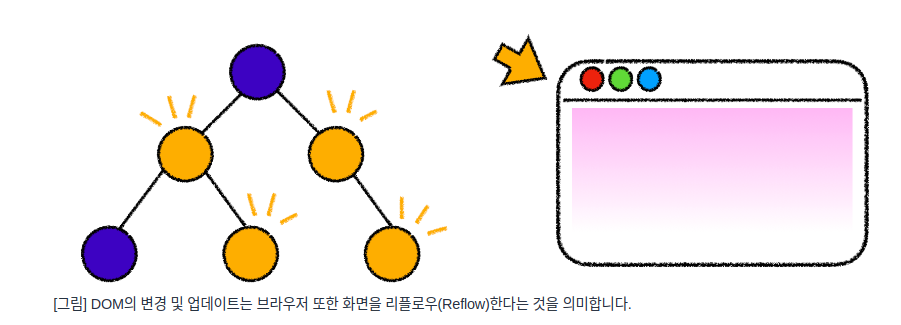
따라서 JavaScript로 조작하는 DOM의 요소가 많을수록 모든 DOM 업데이트에 대하여 리플로우를 해야 하므로 DOM의 업데이트에 대한 비용이 많이 들게됨.
왜일까?
DOM 조작은 모던 웹의 인터랙티브 요소에 빠질 수 없는 것이지만, 대부분의 JavaScript 프레임워크는 필요 이상으로 DOM을 업데이트 시킵니다.
예를 들어 지금 6개의 컨텐츠가 있는데 그 컨텐츠 중 단 1개의 컨텐츠만 색상이 바뀌는 동작을 한다고 가정하겠습니다. 나머지 5개의 컨텐츠는 내버려두고 그 1개의 컨텐츠만 색상을 바꿔 그리는 것이 가장 효율적이라는 걸 알지만, 대부분의 JavaScript 프레임워크는 그 1개의 컨텐츠만 색상을 바꿔 그릴 뿐 아니라 나머지 컨텐츠도 다시 그립니다.
이 예시는 브라우저의 성능에 크게 문제를 끼치지 않겠지만, 모던 웹은 이 외에도 엄청난 양의 DOM을 조작할 가능성이 있습니다.
계속해서 이런 비효율적인 업데이트를 반복한다면 극단적인 예로 프레임 드랍(frame drop)과 같은 치명적인 UX 문제가 발생할 수 있습니다.
결국 “바뀐 부분만 비교해서 그 부분만 렌더링을 할 수는 없을까?“ 라는 아이디어를 기반으로 React는 Virtual DOM을 세상에 내놓게 된 것입니다.
Virtual DOM이란
React에는 모든 DOM 객체에 대응하는 가상의 DOM 객체가 있습니다. 상대적으로 무거운 DOM에 비하여 React의 가상 DOM 객체는 실제 DOM 객체와 동일한 속성을 가지고 있음에도 “훨씬 가벼운 사본”이라고 표현할 수 있습니다. 다만 가상 DOM 객체는 화면에 표시되는 내용을 실제 DOM 객체처럼 직접 변경하는 것은 아닙니다.
가상 DOM은 가상의 UI 요소를 메모리에 유지시키고, 그 유지시킨 가상의 UI 요소를 ReactDOM과 같은 라이브러리를 통해 실제 DOM과 동기화시킵니다. 실제 DOM을 조작하는 것은 실제로 브라우저 화면에 그리기 때문에 느리지만, 가상 DOM을 조작하는 것은 실제 DOM처럼 실제로 브라우저 화면에 그리는 것이 아니기 때문에 훨씬 속도가 빠릅니다.
어떻게 가상 DOM이 더 빠를까?
React는 새로운 요소가 UI에 추가되면 트리 구조로 표현이 되는 가상의 DOM이 만들어집니다.
이러한 요소의 상태가 변경이 되면 다시 새로운 가상의 DOM 트리가 만들어집니다.
그리고 이전의 가상의 DOM과 이후의 가상의 DOM의 차이를 비교합니다.
이 작업이 완료가 되면 가상의 DOM은 실제 DOM에 변경을 수행할 수 있는 최상의 방법을 계산하기 시작합니다.
이렇게 하면 실제 DOM은 최소한의 작업만 수행해도 렌더링을 할 수 있게 됩니다.
따라서 실제 DOM의 업데이트 비용을 줄일 수 있게 됩니다. 업데이트 비용을 줄일 수 있다는 것은 브라우저의 파워를 덜 쓴다는 의미이므로, 더 빠른 렌더링이 가능해집니다.
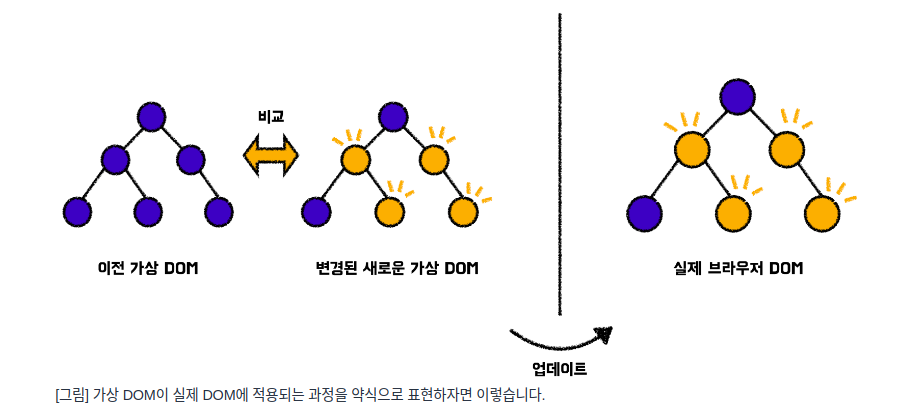
노란색 원들은 업데이트된 노드, 즉 UI 요소를 의미합니다.
React에서는 “상태가 변경된” UI 요소로 볼 수 있습니다.
그런 다음 가상의 DOM 트리의 이전 버전과 현재 가상 DOM 트리 간의 차이가 계산됩니다.
그런 다음 트리가 업데이트된 UI를 제공하기 위해 부분적으로 리렌더링 됩니다.
이렇게 업데이트된 트리는 실제 DOM으로 한꺼번에 업데이트가 됩니다.
Virtual DOM의 형태
가상 DOM은 추상화된 자바스크립트 객체의 형태를 가지고 있습니다. DOM 트리 하나를 예시로 들어 보겠습니다.
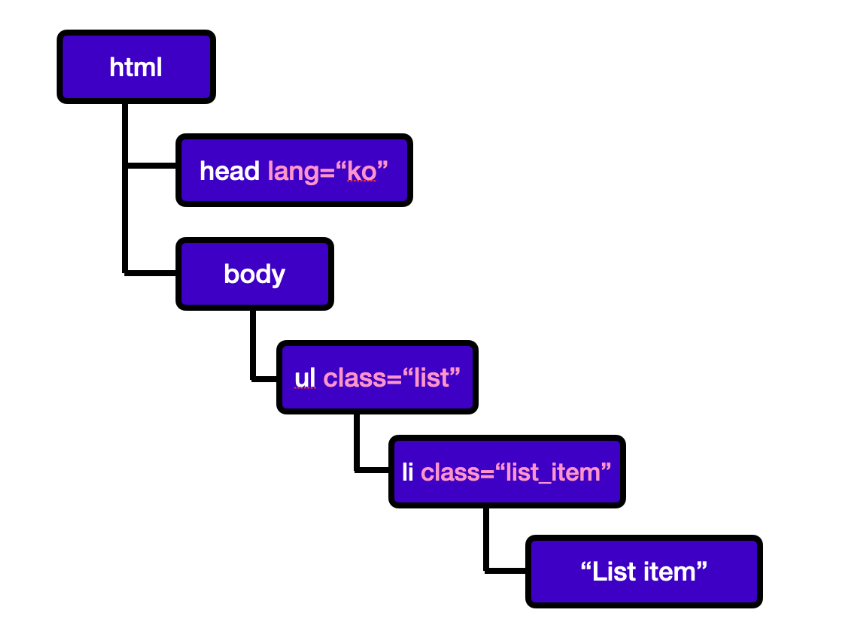
이 DOM 트리는 JavaScript 객체로도 표현할 수 있습니다.
const vDom = {
tagName: "html",
children: [
{ tagName: "head" },
{ tagName: "body",
children: [
tagName: "ul",
attributes: { "class": "list"},
children: [
{
tagName: "li",
attributes: { "class": "list_item" },
textContent: "List item"
}
]
]
}
]
}이것을 가상 DOM이라고 생각해 보겠습니다.
실제 DOM과 마찬가지로 가상 DOM 또한 HTML 문서 객체를 기반으로 합니다.
또한 추상화만 되었을 뿐 평범한 자바스크립트 객체이므로 실제 DOM을 건드리지 않고도 필요한 만큼 자유롭게 조작할 수 있습니다.
React Diffing Algorithm
React가 기존 가상 DOM과 변경된 새로운 가상 DOM을 비교할 때,
React 입장에서는 변경된 새로운 가상 DOM 트리에 부합하도록 기존의 UI를 효율적으로 갱신하는 방법을 알아낼 필요가 있었습니다.
즉 하나의 트리를 다른 트리로 변형을 시키는 가장 작은 조작 방식을 알아내야만 했는데, 알아낸 조작 방식 알고리즘은 O(n^3)의 복잡도를 가지고 있었습니다.
만약 이 알고리즘을 그대로 React에 적용한다면 1000개의 엘리먼트를 실제 화면에 표시하기 위해 10억(1000^3)번의 비교 연산을 해야만 합니다.
사실 이것은 너무 비싼 연산이기 때문에 React는 두 가지의 가정을 가지고 시간 복잡도 O(n)의 새로운 휴리스틱 알고리즘(Heuristic Algorithm)을 구현해냅니다.
두 가지 가정은 이것입니다.
- 각기 서로 다른 두 요소는 다른 트리를 구축할 것이다.
- 개발자가 제공하는 key 프로퍼티를 가지고, 여러 번 렌더링을 거쳐도 변경되지 말아야 하는 자식 요소가 무엇인지 알아낼 수 있을 것이다.
실제 이 두 가정은 거의 모든 실제 사용 사례에 들어맞게 됩니다. 여기서 React는 비교 알고리즘(Diffing Algorithm)을 사용합니다.
React가 DOM 트리를 탐색하는 방법
React는 기존의 가상 DOM 트리와 새롭게 변경된 가상 DOM 트리를 비교할 때, 트리의 레벨 순서대로 순회하는 방식으로 탐색합니다.
즉 같은 레벨(위치)끼리 비교한다는 뜻입니다.
이는 너비 우선 탐색(BFS)의 일종이라고 볼 수 있습니다.
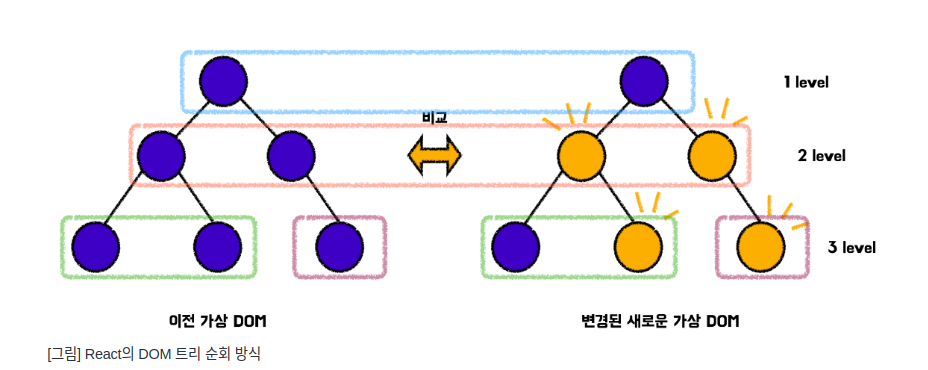
React는 이런 식으로 동일 선상에 있는 노드를 파악한 뒤 다음 자식 세대의 노드를 순차적으로 파악해 나갑니다.
다른 타입의 DOM 엘리먼트인 경우
그런데 DOM 트리는 각 HTML 태그마다 각각의 규칙이 있어 그 아래 들어가는 자식 태그가 한정적이라는 특징이 있습니다.
(예를 들어 <ul> 태그 밑에는 <li> 태그만 와야 한다던가, <p> 태그 안에 <p> 태그를 또 쓰지 못하는 것입니다.)
자식 태그의 부모 태그 또한 정해져 있다는 특징이 있기 때문에,
부모 태그가 달라진다면 React는 이전 트리를 버리고 새로운 트리를 구축해버립니다.
<div>
<Counter />
</div>
//부모 태그가 div에서 span으로 바뀝니다.
<span>
<Counter />
</span>이렇게 부모 태그가 바뀌어버리면, React는 기존의 트리를 버리고 새로운 트리를 구축하기 때문에 이전의 DOM 노드들은 전부 파괴됩니다.
부모 노드였던 <div>가 <span>으로 바뀌어버리면 자식 노드인 <Counter />는 완전히 해제됩니다.
즉 이전 <div> 태그 속 <Counter />는 파괴되고 <span> 태그 속 새로운 <Counter />가 다시 실행됩니다.
새로운 컴포넌트가 실행되면서 기존의 컴포넌트는 완전히 해제(Unmount)되어버리기 때문에 <Counter />가 갖고 있던 기존의 state 또한 파괴됩니다.
같은 타입의 DOM 엘리먼트인 경우
반대로 타입이 바뀌지 않는다면 React는 최대한 렌더링을 하지 않는 방향으로 최소한의 변경 사항만 업데이트합니다.
이것이 가능한 이유는 앞서 React가 실제 DOM이 아닌 가상 DOM을 사용해 조작하기 때문입니다.
업데이트 할 내용이 생기면 virtual DOM 내부의 프로퍼티만 수정한 뒤, 모든 노드에 걸친 업데이트가 끝나면 그때 단 한번 실제 DOM으로의 렌더링을 시도합니다.
<div className="before" title="stuff" />
//기존의 엘리먼트가 태그는 바뀌지 않은 채 className만 바뀌었습니다.
<div className="after" title="stuff" />React는 두 요소를 비교했을 때 className만 수정되고 있다는 것을 알게 됩니다.
className before와 after는 각자 이런 스타일을 갖고 있다고 해보겠습니다.
//className이 before인 컴포넌트
<div style={{color: 'red', fontWeight: 'bold"}} title="stuff" />
//className이 after인 컴포넌트
<div style={{color: 'green', fontWeight: 'bold"}} title="stuff" />두 엘리먼트를 비교했을 때 React는 정확히 color 스타일만 바뀌고 있음을 눈치챕니다.
따라서 React는 color 스타일만 수정하고 fontWeight 및 다른 요소는 수정하지 않습니다.
이렇게 하나의 DOM 노드를 처리한 뒤 React는 뒤이어서 해당 노드들 밑의 자식들을 순차적으로 동시에 순회하면서 차이가 발견될 때마다 변경합니다.
이를 재귀적으로 처리한다고 표현합니다.
자식 엘리먼트의 재귀적 처리
예를 들면 이렇게 자식 엘리먼트가 변경이 된다고 가정하겠습니다.
<ul>
<li>first</li>
<li>second</li>
</ul>
//자식 엘리먼트의 끝에 새로운 자식 엘리먼트를 추가했습니다.
<ul>
<li>first</li>
<li>second</li>
<li>third</li>
</ul>React는 기존 <ul>과 새로운 <ul>을 비교할 때 자식 노드를 순차적으로 위에서부터 아래로 비교하면서 바뀐 점을 찾습니다.
그렇기 때문에 예상대로 React는 첫 번째 자식 노드들과 두 번째 자식 노드들이 일치하는 걸 확인한 뒤 세 번째 자식 노드를 추가합니다.
이렇게 React는 위에서 아래로 순차적으로 비교하기 때문에, 이 동작 방식에 대해 고민하지 않고 리스트의 처음에 엘리먼트를 삽입하게 되면 이전의 코드에 비해 훨씬 나쁜 성능을 내게 됩니다.
<ul>
<li>Duke</li>
<li>Villanova</li>
</ul>
//자식 엘리먼트를 처음에 추가합니다.
<ul>
<li>Connecticut</li>
<li>Duke</li>
<li>Villanova</li>
</ul>이렇게 구현하게 되면 React는 우리의 기대대로 최소한으로 동작하지 못하게 됩니다.
React는 원래의 동작하던 방식대로 처음의 노드들을 비교하게 됩니다.
처음의 자식 노드를 비교할 때, <li>Duke</li> 와 <li>Connecticut</li>로 자식 노드가 서로 다르다고 인지하게 된 React는 리스트 전체가 바뀌었다고 받아들입니다.
즉 <li>Duke</li>와 <li>Villanova</li>는 그대로기 때문에 두 자식 노드는 유지시켜도 된다는 것을 깨닫지 못하고 전부 버리고 새롭게 렌더링 해버립니다.
이는 굉장히 비효율적인 동작 방식입니다.
그래서 React는 이 문제를 해결하기 위해 key라는 속성을 지원합니다.
이는 효율적으로 가상 DOM을 조작할 수 있도록 합니다.
만일 개발할 당시 key라는 속성을 사용하지 않으면 React 에서 key값을 달라고 경고문을 띄우는 것도 이 때문인 것입니다.
key값이 없는 노드는 비효율적으로 동작할 수 있기 때문입니다.
키(key)
만약 자식 노드들이 이 key를 갖고 있다면, React는 그 key를 이용해 기존 트리의 자식과 새로운 트리의 자식이 일치하는지 아닌지 확인할 수 있습니다.
<ul>
<li key="2015">Duke</li>
<li key="2016">Villanova</li>
</ul>
//key가 2014인 자식 엘리먼트를 처음에 추가합니다.
<ul>
<li key="2014">Connecticut</li>
<li key="2015">Duke</li>
<li key="2016">Villanova</li>
</ul>React는 key 속성을 통해 ‘2014’라는 자식 엘리먼트가 새롭게 생겼고, ‘2015’, ‘2016’ 키를 가진 엘리먼트는 그저 위치만 이동했다는 걸 알게 됩니다.
따라서 React는 기존의 동작 방식대로 다른 자식 엘리먼트는 변경하지 않고 추가된 엘리먼트만 변경합니다.
이 key 속성에는 보통 데이터 베이스 상의 유니크한 값(ex. Id)을 부여해주면 됩니다.
키는 전역적으로 유일할 필요는 없고, 형제 엘리먼트 사이에서만 유일하면 됩니다.
만약 이런 유니크한 값이 없다면 최후의 수단으로 배열의 인덱스를 key로 사용할 수 있습니다.
다만 배열이 다르게 정렬될 경우가 생긴다면 배열의 인덱스를 key로 선택했을 경우는 비효율적으로 동작할 것입니다.
왜냐하면 배열이 다르게 정렬되어도 인덱스는 그대로 유지되기 때문입니다.
인덱스는 그대로지만 그 요소가 바뀌어버린다면 React는 배열의 전체가 바뀌었다고 받아들일 것이고, 기존의 DOM 트리를 버리고 새로운 DOM 트리를 구축해버리기 때문에 비효율적으로 동작하는 것입니다.
