[K-Pop 오디오 특성 분석 대시보드] 외부 데이터 수집 (1) 차트 순위 크롤링


0. 배경 및 필요성
Spotify API를 이용해 아티스트별 곡 정보를 수집하였으나, track_popularity를 '인기도'를 판단하는 지표로 이용하기에는 적절하지 않다고 생각했다. 그 이유는

(출처: https://developer.spotify.com/documentation/web-api/reference/#/operations/get-track)
여기에서 볼 수 있듯이 어떤 2개의 곡이 같은 스트리밍 수를 기록하더라도, 상대적으로 최근에 발매된 곡이 더 이전에 발매된 곡보다 popularity가 높게 계산되도록 했기 때문이다.
그래서 인기도를 나타낼 수 있는 다른 지표들을 추가로 찾아보고 수집하기로 했고, https://kworb.net/ 에서 아티스트(아이돌 그룹)별 스포티파이 글로벌, 국가별 일간 차트의 스트리밍 수 및 피크 순위를 크롤링하였다.
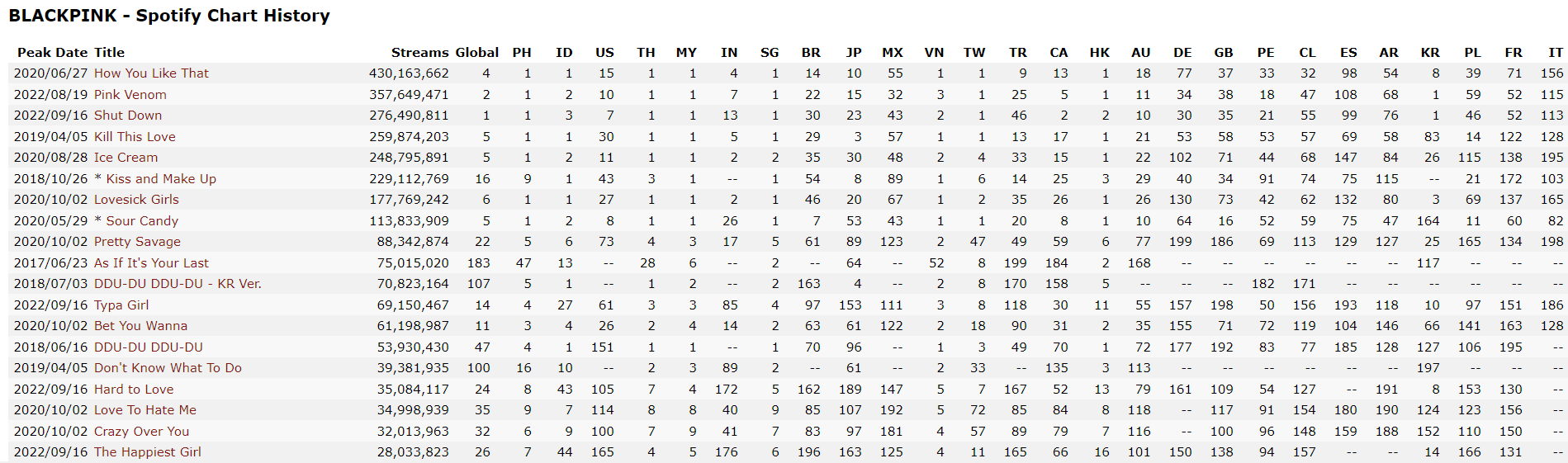

위의 BLACKPINK - Spotify Chart History와 NewJeans - Spotify Chart History를 비교해 보면 알 수 있듯이 아티스트별 페이지마다 열 이름에 해당하는 국가의 순서도 다르고 차트인을 했는지 여부에 따라 한 아티스트의 페이지에는 나와 있는 국가가 다른 아티스트의 페이지에는 나와 있지 않은 경우도 있었다.
즉 1개 테이블에 포함되어 있는 열의 개수를 이 경우와 다르게 알 수 없었기 때문에 다른 방법으로 크롤링을 진행하였다.
1. 크롤링 준비
라이브러리를 import 해주고 크롤링 할 아티스트 URL을 준비한다.
# import libraries
from bs4 import BeautifulSoup
from pandas.io.html import read_html
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
import time
import openpyxl
from tqdm import tqdm
import pandas as pd
import numpy as np
import osservice = Service(executable_path=ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)2. 크롤링 및 결과 저장
for artist in tqdm(artist_list):
driver.get(artist)
time.sleep(1)
table = driver.find_element(By.XPATH, "/html/body/div[2]/div[4]")
time.sleep(1)
table_html= table.get_attribute('innerHTML')
data = read_html(table_html)[0]
file_title = driver.find_element(By.XPATH, "/html/body/div[2]/div[4]/span").text.replace(' - ',"_").replace(' ',"_")
data.to_csv('data/spotify_chart_history/'+str(file_title)+'.csv', index=False, mode='w', encoding='utf-8-sig')
time.sleep(1)- XPath를 활용하여 테이블을 찾아서 table 변수에 저장하는 것까지는 똑같다.
- BeautifulSoup에서 제공하는 get_attribute()과 innerHTML을 사용한다는 점이 다르다.
get_attribute('속성 이름')는 변수로 지정된 요소의 괄호 안의 속성의 값을 반환한다.get_attribute('innerHTML')은 element 내에 있는 HTML 정보 전체를 반환한다.
- 이 HTML을
read_html함수로 읽어주면 리스트 안에 데이터프레임이 들어간 형식으로 출력된다. 그러므로read_html(table_html)[0]으로 인덱싱을 해주면 데이터프레임 형식으로 출력이 된다. - 아티스트별로 해당 데이터프레임을 data로 저장하고 각각 다른 csv 파일로 저장한다.
이런 식으로 저장된 것을 확인할 수 있다. (20개 그룹)
3. 아티스트별 파일 concat
20개 파일을 합치고 기존 데이터와 merge하기 위해서 20개 그룹에 대해 artist_name 열을 추가한 후 다시 저장했다.
df_newjeans = pd.read_csv('data/spotify_chart_history/NewJeans_Spotify_Chart_History.csv')
df_newjeans['artist_name'] = 'NewJeans'
df_newjeans.to_csv('data/spotify_chart_history/NewJeans_Spotify_Chart_History.csv', encoding='utf-8-sig', index=False)이런 식으로... (이것보다 더 효율적인 방식이 있을 것 같은데)
다음으로 20개 파일을 concat하고 필요없는 열을 삭제한다.
df_all_artists = pd.DataFrame()
for file in folders:
df_artist = pd.read_csv('data/spotify_chart_history/'+file)
df_all_artists = pd.concat([df_all_artists, df_artist])df_all_artists.drop(['Unnamed: 0', 'Unnamed: 0.1'], axis = 1, inplace = True)열 순서를 조정하고 인덱스를 리셋한다.
df_all_artists = df_all_artists[['artist_name', 'Peak Date', 'Title', 'Streams', 'Global', 'ID', 'TW', 'TH', 'PH', 'SG',
'MY', 'KR', 'US', 'HK', 'VN', 'BR', 'DE', 'JP', 'CA', 'RU', 'PL', 'CL',
'TR', 'AU', 'ES', 'SA', 'HU', 'RO', 'FR', 'PT', 'CZ', 'UA', 'BG', 'AT',
'DK', 'NZ', 'SE', 'EG', 'SK', 'GR', 'AE', 'NO', 'LT', 'AR', 'CH', 'GB',
'EE', 'LV', 'CR', 'FI', 'PA', 'BE', 'MA', 'CO', 'LU', 'UY', 'CY', 'MT',
'SV', 'IN', 'MX', 'PE', 'IT', 'NL', 'IE', 'EC', 'GT',
'BO', 'PY', 'HN', 'IL', 'NI', 'ZA', 'DO', 'IS', 'AD']]
df_all_artists.reset_index(drop=True, inplace=True)그 결과 아래와 같은 데이터프레임을 확인할 수 있다.
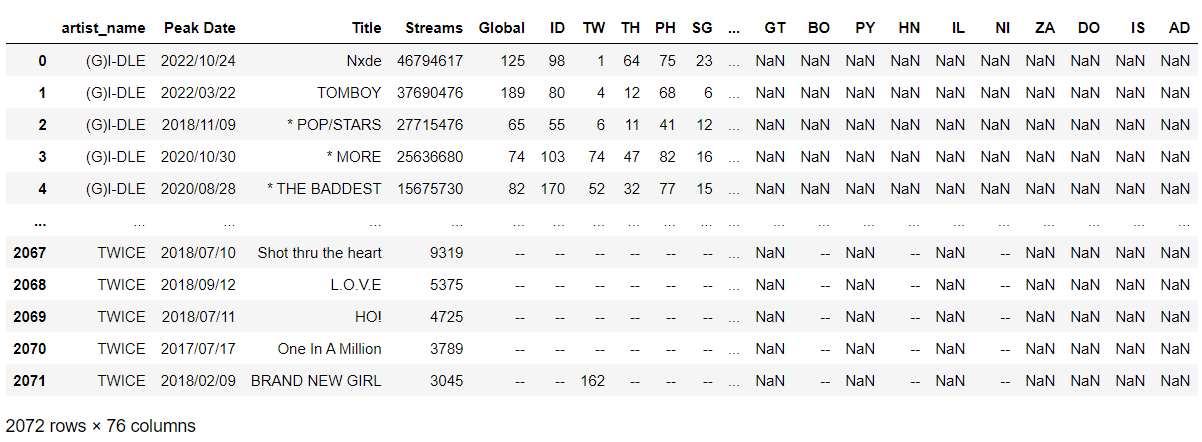
여기까지가 20개 그룹이 스포티파이 글로벌/국가별 일간 차트에서 한 번이라도 차트인 (200위 이내) 한 적 있는 곡들 목록이다.
4. 추가 전처리
기존 데이터와 merge하기 전에 위의 데이터에 대해 전처리를 진행했다.
기존 데이터와 다르게 Title 열에 해당 아티스트가 협업한 곡의 경우에는 *이 앞에 붙어 있었기 때문에 이것을 제거하였다.
for i in range(df_all_artists.shape[0]):
if '* ' in str(df_all_artists.loc[i, 'Title']):
df_all_artists.loc[i, 'Title'] = str(df_all_artists.loc[i, 'Title']).replace('* ', '')
else:
continue데이터 타입을 변경했다.
# 데이터 타입 바꾸기
df_all_artists['artist_name'] = df_all_artists['artist_name'].astype("string")
df_all_artists['Peak Date'] = df_all_artists['Peak Date'].astype("string")
df_all_artists['Title'] = df_all_artists['Title'].astype("string")기존 데이터와 똑같이 Title 열의 이름을 track_name으로 변경하였다.
df_all_artists.rename(columns={'Title':'track_name'}, inplace=True)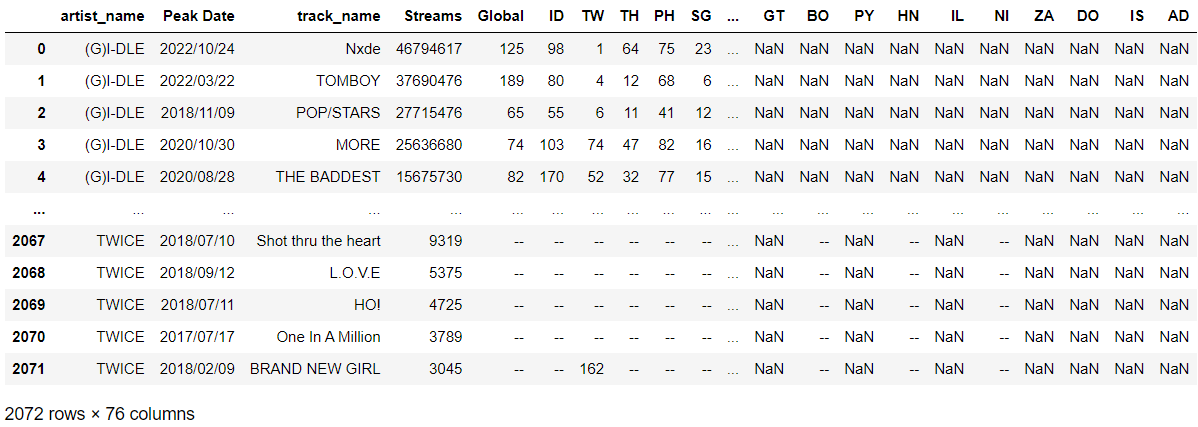
전처리가 완료된 데이터프레임을 csv파일로 저장하였다.
df_all_artists.to_csv('data/spotify_chart_history/all_Spotify_Chart_History.csv', encoding='utf-8-sig', index=False)5. 기존 데이터와 merge
Spotify API로 데이터를 수집한 후 전처리 완료한 데이터를 df로 불러왔다.
이 df는 '스포티파이 글로벌/국가별 차트에서 한 번이라도 차트인을 한 경험이 있는 그룹의 모든 곡'의 정보에 해당한다.
df = pd.read_csv('data/hard_old_drop_data_5.csv')
이 데이터프레임과, 전처리 완료한 데이터의 데이터프레임을 artist_name, track_name 기준으로 merge한 후 저장하였다.
df_merged4 = pd.merge(df, df_all_artists, how='inner', on=['track_name','artist_name'])
df_merged4.to_csv('data/df_merged4.csv', encoding='utf-8-sig', index=False)(왜 right merge가 아니라 inner merge를 했는가? kworb 차트에서 크롤링 한 것 중에 앞의 전처리 과정에서 drop해버린 곡들도 있어서. i.e. Remix, Inst.)
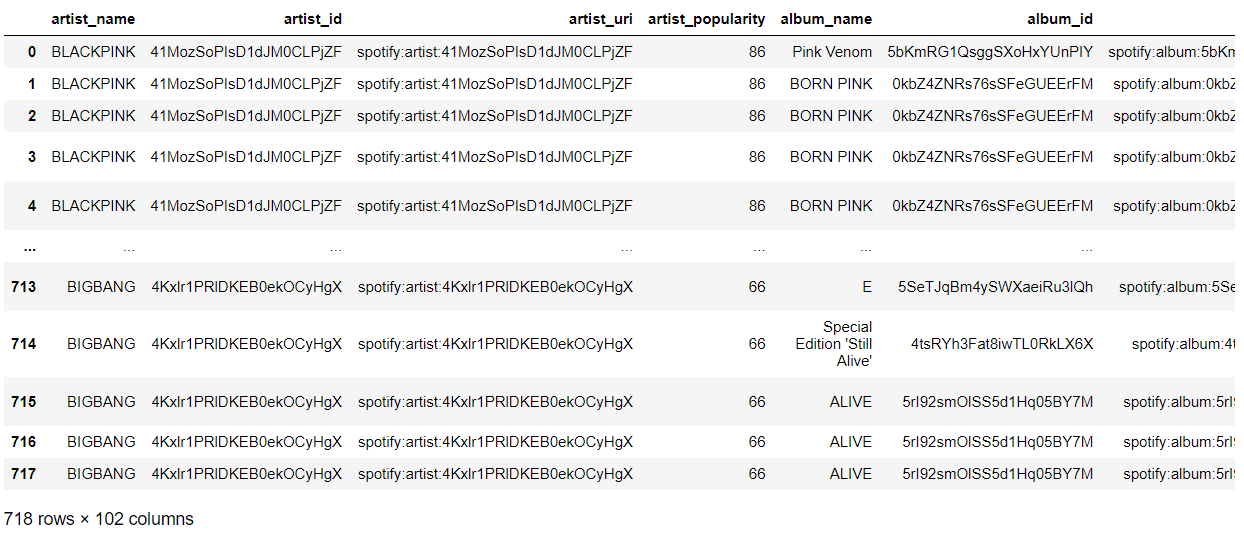
즉 df_merged4.csv는 '스포티파이 글로벌/국가별 차트에서 한 번이라도 차트인을 한 경험이 있는 그룹의 글로벌/국가별 차트인한 곡'의 곡 정보 및 글로벌/국가별 차트 피크 순위, 스트리밍 수에 해당한다.
6. To Do
- track_popularity, 스트리밍 수, 순위 중 어떤 것으로 분석할 것인지?
- 국가별로 분석한다면, 국가명이 줄임말로 되어 있는데 어떤 국가를 의미하는지 파악
- Tableau로 가능한 그래프 범위 확인 필요
참고 자료
네이버 블로그 - [python] Selenium library로 동적 웹 크롤링 : 후스코어드닷컴(whoscored.com)
