[라인맨 포지션 평가] 웹 페이지 테이블 크롤링
0
Kaggle에서 제공된 데이터 외에 추가 데이터로 spotrac.com에서 테이블 형식으로 정리된 라인맨의 연봉 정보를 크롤링하였다.
1. 크롤링 준비
먼저 필요한 라이브러리를 설치해주고
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager # 크롬드라이버 자동업데이트
import time
import openpyxl빈 시트를 생성해준다.
# sheet 생성
wb = openpyxl.Workbook()
sheet = wb.active
sheet.append(["no", "displayName", "team", "officialPosition", "averageSalary"])service = Service(executable_path=ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)웹페이지 주소로 이동한다.
# 웹페이지 주소 이동
driver.get("https://www.spotrac.com/nfl/rankings/2021/average/offensive-line/")
time.sleep(1)2. 웹페이지의 구성 파악
웹페이지에서 개발자 도구(Ctrl+Shift+I)를 열어 테이블의 위치를 찾아볼 수 있다.
Copy full XPath를 활용하여 테이블을 table 변수에 담아준다.
table = driver.find_element(By.XPATH, "/html/body/div[1]/div[2]/div[1]/div/div/div[1]/div/div[3]/div/table")table은 아래와 같이
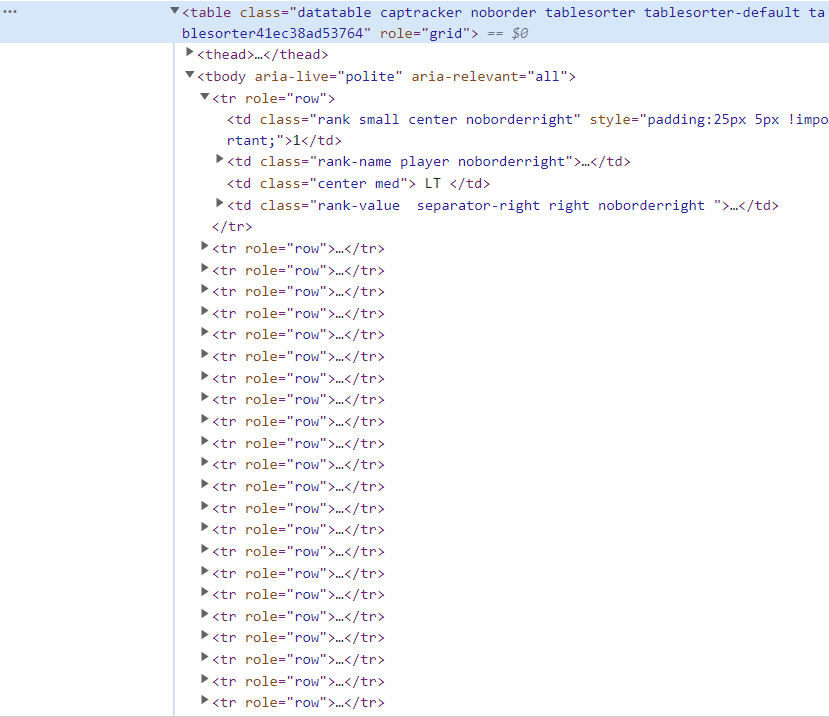
<table> 안에 <thead>와 <tbody>,
<tbody> 안에 <tr>,
<tr> 안에 <td> 순으로 포함되어 있다.
개발자 도구 상단의 파란색 버튼을 클릭하여 마우스오버 하는 부분이 각각 어떤 태그에 해당하는지 파악하면,
| 태그 이름 | 설명 |
|---|---|
<table> | 테이블 전체 |
<thead> | 테이블 헤딩 (열 이름) |
<tbody> | 테이블 바디 |
<tr> | 테이블 행 (row) |
<td> | 테이블 셀 (cell) |
이 된다.
3. 크롤링
우선 heading은 빈 시트에 다시 설정했으므로 tbody 변수만 생성한다.
tbody = table.find_element(By.TAG_NAME, "tbody")한 행씩 돌아가면서 순위, 선수 이름, 소속 팀, 포지션, 평균 연봉을 크롤링하면 된다. <tbody> 태그 내의 <tr> 개수가 크롤링하고자 하는 행 개수와 동일하므로 rows 변수를 <tr>로 지정해주고 enumerate()를 사용해서 for문을 생성한다.
또한 각 행별 <td> 개수는 동일하므로 <td>에 대한 인덱싱을 통해 각 셀에 접근 가능하다.
- 소속팀명이 Player 열의 선수 이름 아래에 위치하고 있기 때문에 split을 해 줘야 한다.
- 연봉은 가공을 쉽게 하기 위해서 달러 기호와 콤마를 제거한다.
i = 1
rows = tbody.find_elements(By.TAG_NAME, "tr")
for index, value in enumerate(rows):
displayName = value.find_elements(By.TAG_NAME, "td")[1].text.split("\n")[0]
team = value.find_elements(By.TAG_NAME, "td")[1].text.split("\n")[1]
officialPosition = value.find_elements(By.TAG_NAME, "td")[2].text
averageSalary = value.find_elements(By.TAG_NAME, "td")[-1].text.replace("$","").replace(",","")
sheet.append([i, displayName, team, officialPosition, averageSalary])
i += 1그 결과 이렇게
for row in sheet.iter_rows(max_col=5, values_only=True):
print(row)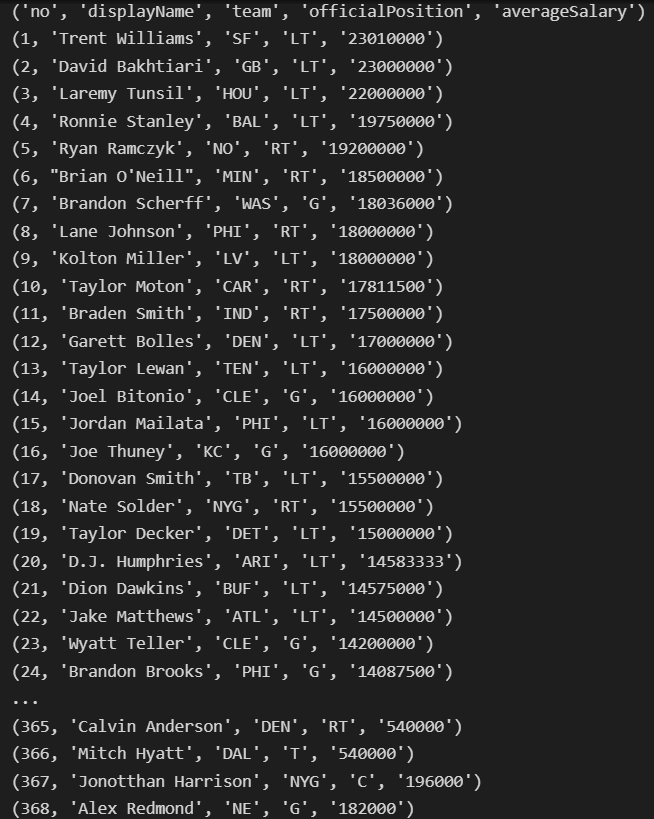
크롤링이 된다.
4. 크롤링 결과 저장, 드라이버 닫기
#크롤링 결과 저장
wb.save("offensivelinemen_crawling_results.xlsx")driver.close()
안녕하세요!